
Dados estruturados (marcação) na era da IA com Schema.org: O que os engenheiros do Google realmente pensam
Xpert Pré-lançamento

Available in 27 languages 📢
Prefira a Xpert.Digital no GoogleⓘPublicado em: 7 de maio de 2026 / Atualizado em: 7 de maio de 2026 – Autor: Konrad Wolfenstein
Dados estruturados (marcação) na era da IA com Schema.org: O que os engenheiros do Google realmente pensam – Imagem: Xpert.Digital
O segredo de SEO do Google: por que a IA falha sem dados estruturados
Apesar do ChatGPT e outras soluções similares: Por que os engenheiros do Google continuam a defender o Schema.org?
Atualização de SEO: Por que o Schema.org está substituindo o Open Graph no Google?
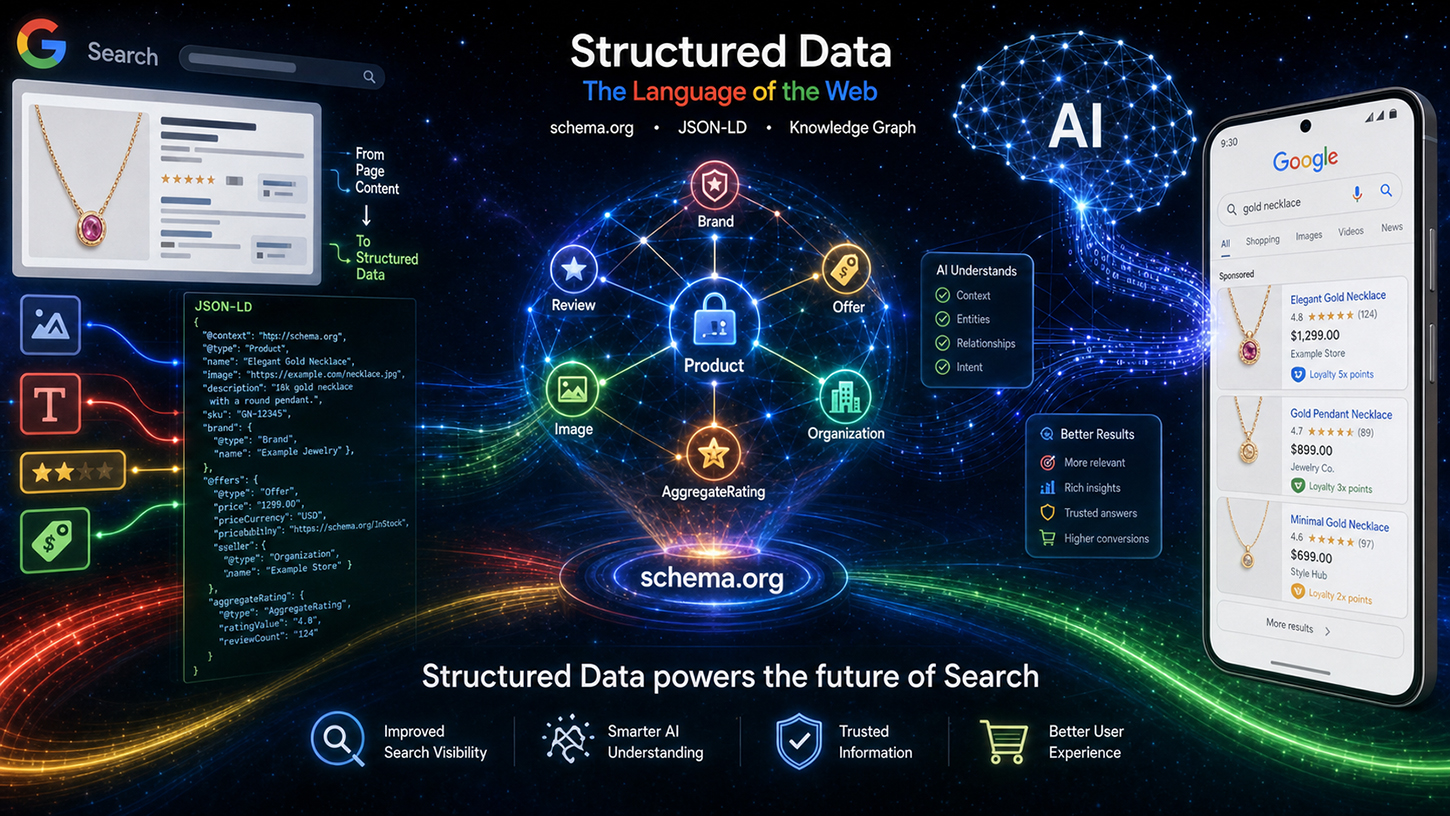
Um mito persistente circula no mundo do SEO: na era dos brilhantes modelos de linguagem de IA que entendem sem esforço até mesmo textos não estruturados, os dados estruturados meticulosamente mantidos, como o Schema.org, simplesmente se tornaram obsoletos. Mas a realidade é bem diferente. No evento Google Search Central Live, o engenheiro do Google, Ryan Levering, desmistificou essa ideia equivocada e deixou claro: a marcação estruturada não é uma relíquia do passado, mas sim a espinha dorsal fundamental da nova busca impulsionada por IA.
Desde novas visões gerais de IA até agentes de compras autônomos, os modelos de linguagem precisam de diretrizes precisas e legíveis por máquina para evitar alucinações e operar computacionalmente de forma eficiente. Aqueles que desejam manter a visibilidade na web moderna devem ajudar as máquinas a entender o contexto sem ambiguidade. Este artigo examina o realinhamento estratégico do Google, apresenta inovações revolucionárias para o comércio eletrônico e o conteúdo gerado pelo usuário e mostra por que o SEO técnico é agora a vantagem competitiva decisiva na batalha pela visibilidade das máquinas.
As máquinas conseguem ler a internet, mas apenas se você as ajudar a entendê-la
Em 21 de abril de 2026, o primeiro evento Google Search Central Live em solo canadense aconteceu em Toronto – e não foi um encontro qualquer do setor. Ryan Levering, engenheiro da área de Engenharia de Busca do Google, apresentou aquela que foi, sem dúvida, a apresentação mais tecnicamente densa e estrategicamente significativa do dia: “Dados Estruturados, Qualidade e IA”. O que ele apresentou foi mais do que uma revisão técnica. Foi uma declaração clara sobre o futuro da web semântica em uma era em que a inteligência artificial assume cada vez mais o papel de intermediária entre usuários e informações.
Entre dois extremos: a escolha errada entre um ou outro
No início de sua apresentação, Ryan Levering contrastou duas opiniões diametralmente opostas que circulam na comunidade de SEO. Por um lado, há a convicção de que dados estruturados são simplesmente supérfluos na era dos poderosos modelos de linguagem: se os modelos de IA conseguem interpretar facilmente textos não estruturados, por que se dar ao trabalho de adicionar a marcação schema.org ao código-fonte? Por outro lado, alguns entusiastas propagam a ideia de que dados estruturados são o futuro da internet – um protocolo universal de comunicação semântica entre agentes de IA autônomos que substituirá em grande parte a web tradicional.
Levering rejeitou ambos os extremos e, em vez disso, apresentou uma perspectiva matizada e empiricamente fundamentada. Ambas as posições continham um núcleo de verdade, concluiu ele, mas nenhuma descrevia a realidade por completo. Essa nuance é característica da abordagem atual do Google sobre o tema: não se trata de dogmatismo, mas de eficiência pragmática.
Quatro argumentos que explicam tudo
O argumento central de Levering pode ser resumido em quatro pontos-chave, que ele elaborou sob o título "Valor dos Dados Estruturados". O primeiro ponto é a precisão: os dados estruturados proporcionam uma acurácia significativamente maior para esquemas complexos, como preços de venda ou programas de fidelidade, do que a extração baseada em modelos de linguagem natural (LLM) a partir de texto livre. Os modelos de linguagem podem ser enganosos — eles preenchem atributos ausentes, aninham dados incorretamente ou acessam informações fora de contexto. Ao extrair preços de produtos de um grande site de comércio eletrônico com dezenas de itens semelhantes, a taxa de erro é significativamente maior com inferência de IA do que com marcação estruturada implementada corretamente.
O segundo ponto diz respeito ao conteúdo adicional: os dados estruturados frequentemente contêm metadados invisíveis que simplesmente não estão presentes no HTML renderizado de uma página. Formatos de data ISO completos, identificadores estáveis para conteúdo gerado pelo usuário ou IDs de entidades internas — essas informações existem exclusivamente na marcação. Nenhum modelo de linguagem consegue extrair o que não está no texto.
Em terceiro lugar, a eficiência: analisar marcação estruturada é muitas vezes mais barato do que processar um grande modelo de linguagem para extrair dados complexos. O Google indexa bilhões de páginas diariamente. O cálculo é simples: um analisador sintático comum que processa JSON-LD consome uma fração dos recursos computacionais de uma etapa de inferência de um modelo de linguagem. Portanto, os dados estruturados não são apenas semanticamente superiores, como também são significativamente mais eficientes do ponto de vista comercial. Este ponto é de relevância direta para a infraestrutura do Google.
O quarto aspecto, e talvez o mais subestimado, é o foco: os dados estruturados destacam explicitamente quais informações são relevantes em uma página, impedindo assim que os sistemas de IA identifiquem dados irrelevantes. Em uma página de produto com um artigo principal, vários produtos relacionados e uma barra de navegação repleta de preços, um modelo de linguagem sem anotações explícitas não consegue determinar com certeza a qual preço se referir. A marcação estruturada resolve esse problema por meio de uma atribuição inequívoca.
Como os dados estruturados são efetivamente processados
A alavancagem também tornou o fluxo de processamento técnico transparente. Os dados do Schema.org são primeiramente processados por meio de limpeza e filtragem específicas antes de serem categorizados como dados indexados – divididos em áreas como eventos, compras e avaliações. Esses dados preparados fluem então para dois canais de saída diferentes: por um lado, a página de resultados de pesquisa (SRP) clássica e, por outro, como contexto para os sistemas de IA do Google, especificamente as chamadas Visões Gerais de IA (AIO) e Modo de IA (AIM). Os dados estruturados, portanto, deixam de ser apenas uma ferramenta para resultados avançados e se tornam entrada direta para respostas generativas de IA. Isso representa uma mudança fundamental na importância estratégica da marcação do Schema.org.
🎯🎯🎯 Hub de dados para o setor B2B como uma solução quase interna

A solução quase interna: como a Xpert.Digital elimina as lacunas operacionais no marketing e vendas B2B – Negócios inteligentes orientados por conteúdo - Imagem: Xpert.Digital
A Xpert.Digital é um hub industrial B2B orientado por dados, liderado por Konrad Wolfenstein . A empresa atua como uma solução externa, quase interna, para parceiros industriais, preenchendo lacunas operacionais em marketing, conteúdo e vendas – sem exigir recursos adicionais por parte do cliente.
Mais informações aqui:
Por que os dados estruturados estão se tornando a infraestrutura para agentes de IA?
Compras em foco: Envio, programa de fidelidade e variações
Uma parte significativa da apresentação focou em inovações no comércio eletrônico. Levering explicou que, segundo dados do Baymard Institute, informações inesperadas sobre o frete ocupam o segundo e o terceiro lugar entre os motivos mais comuns para o abandono de carrinhos de compras. A marcação estruturada para serviços de frete pode resolver esse problema diretamente: os lojistas agora podem definir com precisão regiões de origem e destino, dimensões e pesos, limites de valor do pedido, tempos de processamento e afiliações a programas de fidelidade diretamente no código.
O modelo de tempo de envio usado pelo Google é dividido em duas fases: o tempo de processamento, ou seja, o tempo decorrido desde o recebimento do pedido até a entrega à transportadora, e o tempo de entrega propriamente dito. Ambas as fases podem ser anotadas separadamente e com alta granularidade – até mesmo horários limite para pedidos e se o processamento ocorre também em dias úteis. Os exemplos correspondentes em JSON-LD mostram como o tipo `ShippingConditions` pode ser usado para definir frete grátis para determinados países (por exemplo, França e Alemanha) e valores mínimos de pedido (por exemplo, € 50).
A integração de serviços de entrega com programas de fidelidade é particularmente inovadora. Utilizando a propriedade `validForMemberTier`, um serviço de entrega pode ser explicitamente vinculado a um programa de fidelidade e a um nível específico. Isso possibilita declarar benefícios de entrega para membros premium diretamente na marcação HTML — um recurso anteriormente configurável apenas pelo Google Merchant Center. O próprio programa de fidelidade associado é definido como um objeto `MemberProgram` na entidade `Organization`, com níveis como "Ouro" ou "Prata" e benefícios associados, como prêmios de fidelidade ou recompensas em pontos.
Programas de fidelidade como entidades semânticas
A introdução da marcação de preço em programas de fidelidade é economicamente significativa. As organizações podem definir vários programas de fidelidade independentes, cada um com diversos níveis e benefícios diferenciados — pontos, preços para membros, políticas de devolução, bônus de frete. Essas informações aparecem diretamente nos resultados de busca do Google, como Levering demonstrou com exemplos reais, incluindo uma oferta da Sephora que exibia um desconto de 30% para membros diretamente no snippet de compras. A vinculação por ID entre páginas, a capacidade de criar links para as definições do programa de fidelidade a partir de outras páginas, é, segundo Levering, o próximo passo planejado, atualmente intitulado "Abrindo caminho para a vinculação por @id entre páginas". O objetivo: referências organizacionais mais fortes entre as páginas de produtos e as políticas da empresa.
Conteúdo gerado pelo usuário: o problema da rotulagem por IA
Outro tópico importante foi o desenvolvimento de tipos de esquema para conteúdo gerado pelo usuário (CGU). Duas novas funcionalidades são particularmente relevantes aqui. Primeiro, posts e republicações incorporados são suportados na marcação de fóruns e perguntas e respostas, permitindo uma representação semântica mais precisa das estruturas de discussão. Segundo — e isso é de importância estratégica ainda maior — a propriedade `so#digitalSourceType` é introduzida para identificar explicitamente conteúdo gerado por máquina.
Essa novidade é uma resposta direta à enxurrada de conteúdo gerado por IA em plataformas como fóruns e sites de perguntas e respostas. Os administradores de sites agora podem declarar se uma publicação foi gerada algoritmicamente ou por um modelo de linguagem. Aqueles que não especificam isso são implicitamente considerados autores humanos pelo Google — uma regra que incentiva a rotulagem transparente. A propriedade `digitalSourceType` é baseada nos códigos IPTC para fontes digitais e distingue, entre outras coisas, entre conteúdo gerado algoritmicamente e conteúdo gerado por modelo.
Seleção de imagens: Schema supera Open Graph
Uma atualização menos notada, mas praticamente eficaz, diz respeito à lógica de seleção de imagens do Google. O sistema está sendo consolidado internamente, com uma hierarquia de priorização clara: a marcação Schema.org, especificamente as propriedades `primaryImageOfPage` e `mainEntity → image`, tem precedência. Somente em seguida vem a meta tag `og:image` do Open Graph. Essa mudança significa que, para os operadores de sites, uma implementação Schema.org limpa da imagem principal influencia diretamente sua exibição nos resultados de pesquisa do Google e nas Visões Gerais de IA — uma vantagem concreta e mensurável.
A própria Schema.org recebe investimentos
Vale destacar também o anúncio do Google de reinvestimento no schema.org como uma especificação aberta. Três medidas concretas foram mencionadas: a publicação de estatísticas sobre a frequência de uso de termos individuais do schema (dados de prevalência, como mostra um slide, já estão disponíveis para termos individuais como `digitalSourceType`, com informações sobre aproximadamente 10.000 domínios), a publicação das próprias regras de validação do Google em formatos padrão legíveis por máquina, como SHACL ou ShEx, e suporte aprimorado para regras de ordenação. Isso é significativo porque permitiria que desenvolvedores externos criassem suas próprias ferramentas de validação com base nos padrões do Google – independentemente das ferramentas de teste oficiais, que ocasionalmente apresentam falhas sob carga.
Validação: Duas ferramentas, um objetivo
Levering apresentou duas ferramentas de validação que se complementam, mas aplicam critérios de teste diferentes. A ferramenta Rich Result Test Tool, disponível em `search.google.com/test/rich-results`, aceita URLs ou JSON puro e verifica se a marcação é adequada para os Resultados Avançados da Pesquisa Google — portanto, ela se baseia nos requisitos específicos do Google, e não no padrão schema.org em si. Já o `validator.schema.org` verifica se a marcação é compatível com o schema.org, ou seja, se adere ao vocabulário aberto, independentemente de o Google gerar resultados avançados a partir dela. Isso leva a uma recomendação clara para desenvolvedores web: ambas as ferramentas devem ser usadas, pois a marcação pode ser compatível com o schema.org, mas não ser capaz de gerar resultados avançados — e vice-versa.
Em linhas gerais: Dados estruturados como infraestrutura de IA
Ao analisar o evento de Toronto como um todo, fica evidente uma mudança que vai muito além da otimização de SEO tradicional. Os dados estruturados estão evoluindo de uma ferramenta para obter snippets relevantes para um padrão fundamental de camada de dados para sistemas de IA. Os recursos Visão Geral de IA e Modo de IA do Google utilizam ativamente a marcação schema.org como contexto para geração de respostas e verificação de entidades. Aqueles que implementam dados estruturados corretos, completos e precisos não apenas aumentam suas chances de obter destaque visual nos resultados de pesquisa, como também posicionam seu conteúdo como uma fonte primária confiável para respostas de IA.
A menção ao Protocolo Universal de Comércio (UCP) e ao WebMCP neste contexto não é coincidência. Ambos os padrões de comunicação baseados em agentes, que o Google lançou em versões iniciais em 2026, exigem que os sites sejam descritos semanticamente. O Schema.org serve de base para isso. Em um mundo onde agentes de IA atuam de forma autônoma na web, pesquisando, comparando e iniciando transações, a legibilidade automática do conteúdo não é mais opcional, mas um pré-requisito para a relevância econômica. A apresentação de Ryan Levering em Toronto, portanto, não foi apenas um relatório de atualização técnica — foi um vislumbre da infraestrutura da próxima geração da web.
Você pode descobrir por si mesmo em 10 segundos
Se você quiser saber o quão bem e de forma abrangente seu site ou outro site utiliza dados estruturados, você pode usar exatamente as duas ferramentas que Ryan Levering, do Google (citado no texto acima), recomendou:
Teste de resultados avançados do Google (com foco na visibilidade do Google):
Acesse search.google.com/test/rich-results, copie o URL de qualquer artigo da xpert.digital e clique em "Testar URL". A ferramenta mostrará exatamente quais marcações o Google reconhece nessa página e se elas estão corretas.
Validador de esquema (com foco na conformidade com os padrões):
Acesse validator.schema.orge cole o mesmo URL. Lá, você poderá ver diretamente no código-fonte, destacado em cores, quais scripts JSON-LD (dados estruturados) o xpert.digital incorporou.
Seu parceiro global de marketing e desenvolvimento de negócios
☑️ Nosso idioma comercial é inglês ou alemão
☑️ NOVO: Correspondência em seu idioma nativo!

Konrad Wolfenstein
Eu e minha equipe teremos o prazer de estar à sua disposição como seu consultor pessoal.
Você pode entrar em contato comigo preenchendo o formulário de contato aqui simplesmente ligando para +49 7348 4088 965. Meu endereço de e-mail é [email protected]:ou
Estou ansioso pelo nosso projeto conjunto.
☑️ Apoio a PMEs em estratégia, consultoria, planejamento e implementação
☑️ Criação ou realinhamento da estratégia digital e digitalização
☑️ Expansão e otimização dos processos de vendas internacionais
☑️ Plataformas de negociação B2B globais e digitais
☑️ Desenvolvimento de Negócios / Marketing / Relações Públicas / Feiras Comerciais Pioneiras
Suporte B2B e SaaS para SEO e GEO (busca com IA) combinados: a solução completa para empresas B2B

Suporte B2B e SaaS para SEO e GEO (busca com IA) combinados: a solução completa para empresas B2B - Imagem: Xpert.Digital
A busca por IA muda tudo: como essa solução SaaS revolucionará para sempre seu posicionamento B2B.
O cenário digital para empresas B2B está passando por rápidas transformações. Impulsionadas pela inteligência artificial, as regras da visibilidade online estão sendo reescritas. Para as empresas, sempre foi um desafio não apenas se destacar na massa digital, mas também ser relevante para os tomadores de decisão certos. As estratégias tradicionais de SEO e o gerenciamento da presença local (geomarketing) são complexos, demorados e, muitas vezes, uma batalha contra algoritmos em constante mudança e uma concorrência acirrada.
Mas e se houvesse uma solução que não apenas simplificasse esse processo, mas também o tornasse mais inteligente, preditivo e muito mais eficaz? É aqui que entra em cena a combinação de suporte B2B especializado com uma poderosa plataforma SaaS (Software como Serviço), projetada especificamente para as demandas de SEO e GEO na era da busca por IA.
Essa nova geração de ferramentas não depende mais exclusivamente da análise manual de palavras-chave e estratégias de backlinks. Em vez disso, utiliza inteligência artificial para compreender com mais precisão a intenção de busca, otimizar automaticamente os fatores de ranqueamento local e realizar análises competitivas em tempo real. O resultado é uma estratégia proativa e orientada por dados que proporciona às empresas B2B uma vantagem decisiva: elas não apenas são encontradas, mas também percebidas como a principal autoridade em seu nicho e região.
Eis a simbiose entre o suporte B2B e a tecnologia SaaS com inteligência artificial que transforma o SEO e o marketing geográfico, e como sua empresa pode se beneficiar disso para crescer de forma sustentável no espaço digital.
Mais informações aqui:

















