
Data terstruktur (markup) di era AI dengan Schema.org: Apa yang sebenarnya dipikirkan para insinyur Google
Xpert Pra-Rilis

Available in 27 languages 📢
Lebih suka Xpert.Digital di GoogleⓘDiterbitkan pada: 7 Mei 2026 / Diperbarui pada: 7 Mei 2026 – Penulis: Konrad Wolfenstein
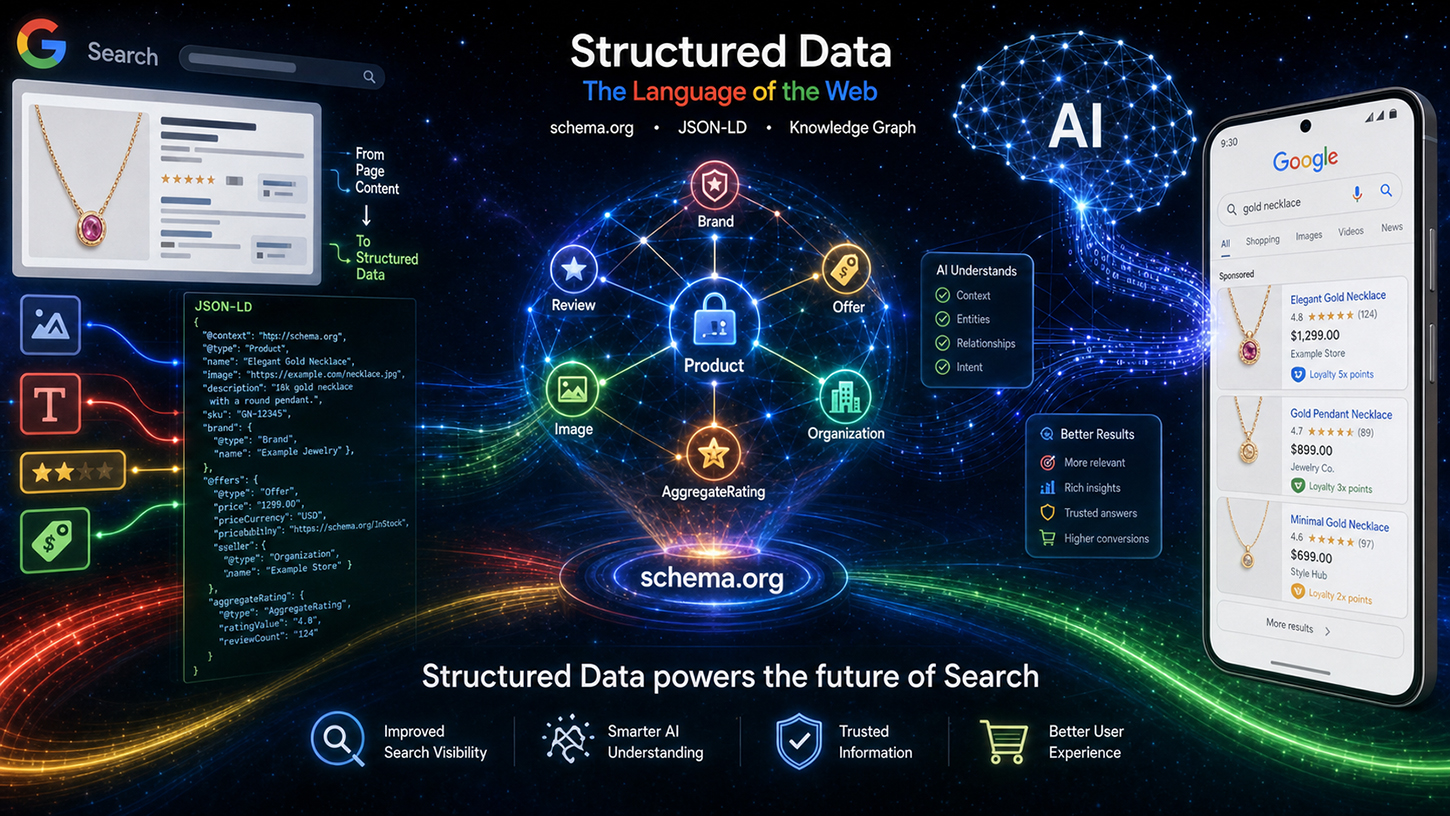
Data terstruktur (markup) di era AI dengan Schema.org: Apa yang sebenarnya dipikirkan para insinyur Google – Gambar: Xpert.Digital
Rahasia SEO Google: Mengapa AI gagal tanpa data terstruktur
Terlepas dari ChatGPT & Co.: Mengapa para insinyur Google terus mengandalkan Schema.org
Pembaruan SEO: Mengapa Schema.org kini menggantikan Open Graph di Google
Mitos yang terus beredar di dunia SEO adalah: Di era model bahasa AI yang brilian yang dengan mudah memahami bahkan teks yang tidak terstruktur, data terstruktur yang dipelihara dengan susah payah seperti Schema.org telah menjadi usang. Namun kenyataannya sangat berbeda. Pada acara Google Search Central Live, insinyur Google Ryan Levering membantah kesalahpahaman ini dan menegaskan dengan jelas: Markup terstruktur bukanlah peninggalan masa lalu, melainkan tulang punggung fundamental dari pencarian berbasis AI yang baru.
Dari tinjauan AI baru hingga agen belanja otonom, model bahasa membutuhkan panduan yang tepat dan dapat dibaca mesin untuk menghindari kesalahan interpretasi dan beroperasi secara efisien secara komputasi. Mereka yang ingin tetap terlihat di web modern harus membantu mesin memahami konteks tanpa ambiguitas. Artikel ini mengkaji penataan ulang strategis Google, menyajikan inovasi revolusioner untuk e-commerce dan konten yang dihasilkan pengguna, dan menunjukkan mengapa SEO teknis kini menjadi keunggulan kompetitif yang menentukan dalam persaingan untuk visibilitas mesin.
Mesin dapat membaca web – tetapi hanya jika Anda membantu mereka memahaminya
Pada tanggal 21 April 2026, acara Google Search Central Live pertama di Kanada berlangsung di Toronto – dan itu bukanlah pertemuan industri biasa. Ryan Levering, seorang insinyur dari Google Search Engineering, menyampaikan presentasi yang bisa dibilang paling padat secara teknis dan signifikan secara strategis pada hari itu: “Data Terstruktur, Kualitas & AI.” Apa yang dia presentasikan lebih dari sekadar tinjauan teknis. Itu adalah pernyataan yang jelas tentang masa depan web semantik di era di mana kecerdasan buatan semakin mengambil peran sebagai perantara antara pengguna dan informasi.
Di antara dua ekstrem: Pilihan yang salah, antara dua pilihan
Di awal presentasinya, Ryan Levering membandingkan dua pendapat yang bertentangan yang beredar di komunitas SEO. Di satu sisi, ada keyakinan bahwa data terstruktur hanyalah hal yang berlebihan di era model bahasa yang canggih: Jika model AI dapat dengan mudah menginterpretasikan teks yang tidak terstruktur, mengapa harus repot-repot menambahkan markup schema.org ke kode sumber? Di sisi lain, beberapa penggemar menyebarkan gagasan bahwa data terstruktur adalah masa depan internet – protokol komunikasi semantik universal antara agen AI otonom yang sebagian besar akan menggantikan web tradisional.
Levering menolak kedua ekstrem tersebut dan sebagai gantinya menyajikan perspektif yang bernuansa dan berlandaskan empiris. Ia menyimpulkan bahwa kedua posisi tersebut mengandung sedikit kebenaran, tetapi tidak sepenuhnya menggambarkan realitas. Nuansa ini merupakan ciri khas pendekatan Google saat ini terhadap topik tersebut: ini bukan tentang dogma, tetapi tentang efisiensi pragmatis.
Empat argumen yang menjelaskan segalanya
Argumen utama Levering dapat diringkas dalam empat poin kunci, yang ia uraikan lebih lanjut di bawah judul "Nilai Data Terstruktur." Poin pertama adalah presisi: Data terstruktur memberikan akurasi yang jauh lebih tinggi untuk skema kompleks seperti harga penjualan atau program loyalitas daripada ekstraksi berbasis LLM dari teks bebas. Model bahasa dapat menyesatkan—mereka mengisi atribut yang hilang, menyusun data secara tidak benar, atau mengakses informasi di luar konteks. Saat mengekstrak harga produk dari situs e-commerce besar dengan puluhan item serupa, tingkat kesalahan jauh lebih tinggi dengan inferensi AI daripada dengan markup terstruktur yang diimplementasikan dengan baik.
Poin kedua berkaitan dengan konten tambahan: Data terstruktur sering kali mengandung metadata tak terlihat yang sama sekali tidak ada dalam HTML yang dihasilkan dari suatu halaman. Format tanggal ISO lengkap, pengidentifikasi stabil untuk konten yang dihasilkan pengguna, atau ID entitas internal—informasi ini hanya ada dalam markup. Tidak ada model bahasa yang dapat mengekstrak apa yang tidak ada dalam teks.
Ketiga, efisiensi: Mengurai markup terstruktur berkali-kali lebih murah daripada memproses model bahasa besar untuk mengekstrak data kompleks. Google mengindeks miliaran halaman setiap hari. Perhitungannya sederhana: Sebuah parser biasa yang memproses JSON-LD mengkonsumsi sebagian kecil sumber daya komputasi dari langkah inferensi LLM. Oleh karena itu, data terstruktur tidak hanya unggul secara semantik—tetapi juga jauh lebih efisien dari perspektif bisnis. Poin ini sangat relevan dengan infrastruktur Google.
Aspek keempat, dan mungkin yang paling diremehkan, adalah fokus: Data terstruktur secara eksplisit menyoroti informasi mana yang relevan pada suatu halaman, sehingga mencegah sistem AI mengambil data yang tidak relevan. Pada halaman produk dengan artikel utama, beberapa produk terkait, dan bilah navigasi yang penuh dengan harga, model bahasa tanpa anotasi eksplisit tidak dapat memastikan harga mana yang harus dirujuk. Markup terstruktur memecahkan masalah ini melalui penugasan yang tidak ambigu.
Bagaimana data terstruktur sebenarnya diproses
Levering juga membuat alur pemrosesan teknis menjadi transparan. Data Schema.org pertama-tama diproses melalui pembersihan dan penyaringan khusus sebelum dikategorikan sebagai data terindeks – dibagi menjadi area seperti acara, belanja, dan ulasan. Data yang telah disiapkan ini kemudian mengalir ke dua saluran keluaran yang berbeda: di satu sisi, halaman hasil pencarian klasik (SRP), dan di sisi lain, sebagai konteks untuk sistem berbasis AI Google, khususnya yang disebut AI Overviews (AIO) dan AI Mode (AIM). Dengan demikian, data terstruktur bukan lagi hanya alat hasil yang kaya, tetapi masukan langsung untuk respons AI generatif. Ini merupakan pergeseran mendasar dalam pentingnya strategis markup schema.org.
🎯🎯🎯 Pusat industri B2B berbasis data sebagai solusi semi-internal

Solusi semi-internal: Bagaimana Xpert.Digital menutup kesenjangan operasional dalam pemasaran dan penjualan B2B – Bisnis Cerdas Berbasis Konten - Gambar: Xpert.Digital
Xpert.Digital adalah pusat industri B2B berbasis data yang dipimpin oleh Konrad Wolfenstein . Perusahaan ini bertindak sebagai solusi eksternal, yang hampir bersifat internal, bagi mitra industri, menutup kesenjangan operasional dalam pemasaran, konten, dan penjualan – tanpa memerlukan sumber daya tambahan di pihak klien.
Informasi selengkapnya di sini:
Mengapa data terstruktur menjadi infrastruktur bagi agen AI?
Fokus belanja: Pengiriman, program loyalitas, dan variasi produk
Sebagian besar presentasi berfokus pada inovasi dalam e-commerce. Levering menjelaskan bahwa, menurut data dari Baymard Institute, informasi pengiriman yang tidak terduga menempati peringkat kedua dan ketiga di antara alasan paling umum untuk pembatalan keranjang belanja. Markup terstruktur untuk layanan pengiriman dapat langsung mengatasi masalah ini: Pedagang sekarang dapat secara tepat menentukan wilayah asal dan tujuan, dimensi dan berat, ambang batas nilai pesanan, waktu pemrosesan, dan afiliasi program loyalitas langsung dalam kode.
Model waktu pengiriman yang digunakan Google dibagi menjadi dua fase: waktu penanganan, yaitu waktu dari penerimaan pesanan hingga penyerahan kepada kurir, dan waktu pengiriman sebenarnya. Kedua fase tersebut dapat dianotasi secara terpisah dan dengan granularitas tinggi – hingga waktu batas akhir pemesanan dan apakah pemrosesan juga dilakukan pada hari kerja. Contoh JSON-LD yang terkait menunjukkan bagaimana tipe `ShippingConditions` dapat digunakan untuk menentukan pengiriman gratis untuk negara-negara tertentu (misalnya, Prancis dan Jerman) dan nilai pesanan minimum (misalnya, €50).
Integrasi layanan pengiriman dengan program loyalitas sangat inovatif. Dengan menggunakan properti `validForMemberTier`, layanan pengiriman dapat secara eksplisit dihubungkan ke program keanggotaan dan tingkatan tertentu. Hal ini memungkinkan untuk mendeklarasikan manfaat pengiriman untuk anggota premium langsung di markup – fitur yang sebelumnya hanya dapat dikonfigurasi melalui Google Merchant Center. Program loyalitas terkait itu sendiri didefinisikan sebagai objek `MemberProgram` di bawah entitas `Organization`, dengan tingkatan seperti "Gold" atau "Silver" dan manfaat terkait seperti penghargaan loyalitas atau poin hadiah.
Program loyalitas sebagai entitas semantik
Pengenalan markup program loyalitas memiliki signifikansi ekonomi. Organisasi dapat mendefinisikan beberapa program keanggotaan independen, masing-masing dengan beberapa tingkatan dan manfaat yang berbeda—poin, harga anggota, kebijakan pengembalian, bonus pengiriman. Informasi ini kemudian muncul langsung di hasil pencarian Google, seperti yang ditunjukkan Levering dengan contoh dunia nyata, termasuk penawaran Sephora yang menampilkan diskon anggota 30 persen langsung di cuplikan belanja. Penautan ID lintas halaman, kemampuan untuk menautkan ke definisi program loyalitas dari halaman lain, menurut Levering, adalah langkah selanjutnya yang direncanakan, yang saat ini berjudul "Merintis jalan untuk penautan @id lintas halaman." Tujuannya: referensi organisasi yang lebih kuat antara halaman produk dan kebijakan perusahaan.
Konten Buatan Pengguna: Masalah Pelabelan AI
Topik penting lainnya adalah pengembangan lebih lanjut dari tipe skema untuk konten yang dihasilkan pengguna (UGC). Dua fitur baru sangat relevan di sini. Pertama, postingan dan posting ulang yang disematkan didukung dalam markup forum dan tanya jawab, memungkinkan representasi semantik yang lebih akurat dari struktur diskusi. Kedua—dan ini bahkan lebih penting secara strategis—properti `so#digitalSourceType` diperkenalkan untuk secara eksplisit mengidentifikasi konten yang dihasilkan mesin.
Perkembangan ini merupakan respons langsung terhadap banjir konten yang dihasilkan AI di platform seperti forum dan situs tanya jawab. Webmaster kini dapat menyatakan apakah sebuah postingan dihasilkan secara algoritmik atau oleh model bahasa. Mereka yang tidak menentukan hal ini secara implisit dianggap oleh Google sebagai penulis manusia – sebuah aturan yang mendorong pelabelan yang transparan. Properti `digitalSourceType` didasarkan pada kode IPTC untuk sumber digital dan membedakan, antara lain, antara konten yang dihasilkan secara algoritmik dan konten yang dihasilkan oleh model.
Pemilihan gambar: Skema mengalahkan Open Graph
Pembaruan yang kurang diperhatikan tetapi secara praktis efektif menyangkut logika pemilihan gambar Google. Sistem ini sedang dikonsolidasikan secara internal, dengan hierarki prioritas yang jelas: markup Schema.org, khususnya properti `primaryImageOfPage` dan `mainEntity → image`, didahulukan. Baru kemudian tag meta `og:image` dari Open Graph menyusul. Perubahan ini berarti bahwa bagi operator situs web, implementasi schema.org yang bersih untuk gambar utama secara langsung memengaruhi tampilannya di hasil pencarian Google dan Ikhtisar AI – sebuah keuntungan konkret dan terukur.
Schema.org sendiri menerima investasi
Hal lain yang patut diperhatikan adalah pengumuman Google tentang investasi ulang pada schema.org sebagai spesifikasi terbuka. Tiga langkah konkret disebutkan: publikasi statistik tentang frekuensi penggunaan istilah skema individual (data prevalensi, seperti yang ditunjukkan dalam slide, sudah tersedia untuk istilah individual seperti `digitalSourceType` dengan informasi tentang sekitar 10.000 domain), publikasi aturan validasi Google sendiri dalam format standar yang dapat dibaca mesin seperti SHACL atau ShEx, dan peningkatan dukungan untuk aturan urutan. Ini penting karena akan memungkinkan pengembang eksternal untuk membangun alat validasi mereka sendiri berdasarkan standar Google – terlepas dari alat pengujian resmi, yang terkadang mengalami kerusakan saat beban kerja tinggi.
Validasi: Dua alat, satu tujuan
Levering memperkenalkan dua alat validasi yang saling melengkapi tetapi menerapkan kriteria pengujian yang berbeda. Alat Uji Hasil Kaya (Rich Result Test Tool) di `search.google.com/test/rich-results` menerima URL atau JSON murni dan memeriksa apakah markup tersebut sesuai untuk Hasil Pencarian Kaya Google – oleh karena itu, alat ini didasarkan pada persyaratan khusus Google, bukan pada standar schema.org itu sendiri. Sebaliknya, `validator.schema.org` memeriksa apakah markup tersebut sesuai dengan schema.org, yaitu, mematuhi kosakata terbuka, terlepas dari apakah Google menghasilkan hasil kaya darinya. Hal ini mengarah pada rekomendasi yang jelas bagi pengembang web: kedua alat tersebut harus digunakan, karena markup dapat sesuai dengan skema tetapi tidak mampu menghasilkan hasil kaya – dan sebaliknya.
Gambaran yang lebih besar: Data terstruktur sebagai infrastruktur AI
Jika dilihat dari keseluruhan peristiwa di Toronto, terlihat pergeseran yang jauh melampaui optimasi SEO tradisional. Data terstruktur berkembang dari alat untuk mendapatkan cuplikan kaya (rich snippets) menjadi standar lapisan data fundamental untuk sistem AI. Ikhtisar AI dan Mode AI Google secara aktif menggunakan markup schema.org sebagai konteks untuk pembuatan jawaban dan verifikasi entitas. Mereka yang menerapkan data terstruktur yang benar, lengkap, dan tepat tidak hanya meningkatkan peluang mereka untuk mendapatkan sorotan visual dalam hasil pencarian—mereka juga memposisikan konten mereka sebagai sumber utama yang andal untuk jawaban AI.
Penyebutan Universal Commerce Protocol (UCP) dan WebMCP dalam konteks ini bukanlah suatu kebetulan. Kedua standar komunikasi berbasis agen ini, yang dirilis Google dalam versi awal pada tahun 2026, mengharuskan situs web untuk dideskripsikan secara semantik. Schema.org menjadi dasar untuk hal ini. Di dunia di mana agen AI bertindak secara otonom di web, mencari, membandingkan, dan memulai transaksi, keterbacaan konten oleh mesin bukan lagi pilihan, tetapi prasyarat untuk relevansi ekonomi. Oleh karena itu, presentasi Ryan Levering di Toronto bukan hanya laporan pembaruan teknis—tetapi juga sekilas tentang infrastruktur web masa depan.
Anda bisa mengetahuinya sendiri dalam 10 detik
Jika Anda ingin mengetahui seberapa baik dan komprehensif situs web Anda atau situs web lain menggunakan data terstruktur, Anda dapat menggunakan tepat dua alat yang direkomendasikan oleh Ryan Levering dari Google (dari teks di atas):
Tes Hasil Kaya Google (fokus pada visibilitas Google):
Buka search.google.com/test/rich-results, salin URL artikel xpert.digital mana pun, dan klik "Uji URL". Alat ini akan menunjukkan kepada Anda dengan tepat markup mana yang dikenali Google di halaman tersebut dan apakah markup tersebut bebas dari kesalahan.
Validator Skema (fokus pada kepatuhan standar murni):
Buka validator.schema.orgdan tempel URL yang sama. Di sana Anda dapat melihat langsung di kode sumber, yang disorot dengan warna, skrip JSON-LD (data terstruktur) mana yang telah diintegrasikan oleh xpert.digital.
Mitra pemasaran dan pengembangan bisnis global Anda
☑️ Bahasa bisnis kami adalah bahasa Inggris atau Jerman
☑️ BARU: Korespondensi dalam bahasa ibu Anda!

Konrad Wolfenstein
Saya dan tim saya dengan senang hati siap membantu Anda sebagai penasihat pribadi Anda.
Anda dapat menghubungi saya dengan mengisi formulir kontak di sini cukup hubungi saya di +49 7348 4088 965. Alamat email saya adalah [email protected]:atau
Saya sangat menantikan proyek bersama kita.
☑️ Dukungan UKM dalam strategi, konsultasi, perencanaan, dan implementasi
☑️ Pembuatan atau penyesuaian kembali strategi digital dan digitalisasi
☑️ Perluasan dan optimalisasi proses penjualan internasional
☑️ Platform perdagangan B2B global & digital
☑️ Pelopor Pengembangan Bisnis / Pemasaran / Humas / Pameran Dagang
Dukungan B2B dan SaaS untuk SEO dan GEO (pencarian AI) terpadu: Solusi lengkap untuk perusahaan B2B

Dukungan B2B dan SaaS untuk SEO dan GEO (pencarian AI) yang terintegrasi: Solusi lengkap untuk perusahaan B2B - Gambar: Xpert.Digital
Pencarian berbasis AI mengubah segalanya: Bagaimana solusi SaaS ini akan merevolusi peringkat B2B Anda selamanya.
Lanskap digital untuk perusahaan B2B mengalami perubahan yang pesat. Didorong oleh kecerdasan buatan, aturan visibilitas online sedang ditulis ulang. Bagi perusahaan, selalu menjadi tantangan bukan hanya untuk terlihat di khalayak digital, tetapi juga untuk relevan bagi para pengambil keputusan yang tepat. Strategi SEO tradisional dan pengelolaan kehadiran lokal (geomarketing) rumit, memakan waktu, dan seringkali merupakan perjuangan melawan algoritma yang terus berubah dan persaingan yang ketat.
Namun bagaimana jika ada solusi yang tidak hanya menyederhanakan proses ini tetapi juga membuatnya lebih cerdas, lebih prediktif, dan jauh lebih efektif? Di sinilah kombinasi dukungan B2B khusus dengan platform SaaS (Software as a Service) yang andal berperan, yang dirancang khusus untuk memenuhi tuntutan SEO dan GEO di era pencarian AI.
Generasi baru perangkat ini tidak lagi hanya bergantung pada analisis kata kunci manual dan strategi backlink. Sebaliknya, ia memanfaatkan kecerdasan buatan untuk lebih akurat memahami maksud pencarian, secara otomatis mengoptimalkan faktor peringkat lokal, dan melakukan analisis kompetitif secara real-time. Hasilnya adalah strategi proaktif berbasis data yang memberikan perusahaan B2B keunggulan yang menentukan: mereka tidak hanya ditemukan, tetapi juga dianggap sebagai otoritas terkemuka di niche dan lokasi mereka.
Inilah simbiosis antara dukungan B2B dan teknologi SaaS berbasis AI yang mentransformasi SEO dan pemasaran GEO, serta bagaimana perusahaan Anda dapat memanfaatkannya untuk tumbuh secara berkelanjutan di ruang digital.
Informasi selengkapnya di sini:

















