
An attempt to explain AI: How does artificial intelligence work and function – how is it trained?

Language selection 📢
Published on: September 8, 2024 / update from: September 9, 2024 - Author: Konrad Wolfenstein

An attempt to explain AI: How does artificial intelligence work and how is it trained? – Image: Xpert.Digital
📊 From data input to model prediction: The AI process
How does artificial intelligence (AI) work? 🤖
How artificial intelligence (AI) works can be divided into several clearly defined steps. Each of these steps is critical to the end result that AI delivers. The process begins with data entry and ends with model prediction and possible feedback or further training rounds. These phases describe the process that almost all AI models go through, regardless of whether they are simple sets of rules or highly complex neural networks.
1. The data input 📊
The basis of all artificial intelligence is the data it works with. This data can be in various forms, for example images, text, audio files or videos. The AI uses this raw data to recognize patterns and make decisions. The quality and quantity of the data play a central role here, because they have a significant influence on how well or poorly the model works later.
The more extensive and precise the data, the better the AI can learn. For example, when an AI is trained for image processing, it requires a large amount of image data to correctly identify different objects. With language models, it is text data that helps AI understand and generate human language. Data input is the first and one of the most important steps, as the quality of the predictions can only be as good as the underlying data. A famous principle in computer science describes this with the saying “Garbage in, garbage out” – bad data leads to bad results.
2. Data preprocessing 🧹
Once the data has been entered, it needs to be prepared before it can be fed into the actual model. This process is called data preprocessing. The aim here is to put the data into a form that can be optimally processed by the model.
A common step in preprocessing is data normalization. This means that the data is brought into a uniform range of values so that the model treats it evenly. An example would be to scale all pixel values of an image to a range of 0 to 1 instead of 0 to 255.
Another important part of preprocessing is so-called feature extraction. Certain features are extracted from the raw data that are particularly relevant to the model. In image processing, for example, this could be edges or certain color patterns, while in texts, relevant keywords or sentence structures are extracted. Preprocessing is crucial to making the AI’s learning process more efficient and precise.
3. The model 🧩
The model is the heart of every artificial intelligence. Here the data is analyzed and processed based on algorithms and mathematical calculations. A model can exist in different forms. One of the best-known models is the neural network, which is based on how the human brain works.
Neural networks consist of several layers of artificial neurons that process and pass on information. Each layer takes the outputs of the previous layer and processes them further. The learning process of a neural network consists of adjusting the weights of the connections between these neurons so that the network can make increasingly accurate predictions or classifications. This adaptation occurs through training, in which the network accesses large amounts of sample data and iteratively improves its internal parameters (weights).
In addition to neural networks, there are also many other algorithms used in AI models. These include decision trees, random forests, support vector machines and many others. Which algorithm is used depends on the specific task and the data available.
4. The model prediction 🔍
After the model is trained with data, it is able to make predictions. This step is called model prediction. The AI receives an input and returns an output, i.e. a prediction or decision, based on the patterns it has learned so far.
This prediction can take different forms. For example, in an image classification model, AI could predict which object is visible in an image. In a language model, it could make a prediction about which word comes next in a sentence. In financial predictions, AI could predict how the stock market will perform.
It is important to emphasize that the accuracy of the predictions depends heavily on the quality of the training data and the model architecture. A model trained on insufficient or biased data is likely to make incorrect predictions.
5. Feedback and training (optional) ♻️
Another important part of the work of an AI is the feedback mechanism. The model is regularly checked and further optimized. This process occurs either during training or after model prediction.
If the model makes incorrect predictions, it can learn through feedback to detect these errors and adjust its internal parameters accordingly. This is done by comparing the model predictions with the actual results (e.g. with known data for which the correct answers already exist). A typical procedure in this context is so-called supervised learning, in which the AI learns from example data that is already provided with the correct answers.
A common method of feedback is the backpropagation algorithm used in neural networks. The errors the model makes are propagated backwards through the network to adjust the weights of the neuron connections. The model learns from its mistakes and becomes more and more precise in its predictions.
The role of training 🏋️♂️
Training an AI is an iterative process. The more data the model sees and the more often it is trained based on this data, the more accurate its predictions become. However, there are also limits: an overly trained model can have so-called “overfitting” problems. This means that it memorizes the training data so well that it produces worse results on new, unknown data. It is therefore important to train the model so that it generalizes and makes good predictions even on new data.
In addition to regular training, there are also procedures such as transfer learning. Here, a model that has already been trained on a large amount of data is used for a new, similar task. This saves time and computing power because the model does not have to be trained from scratch.
Make the most of your strengths 🚀
The work of an artificial intelligence is based on a complex interaction of various steps. From data entry, preprocessing, model training, prediction and feedback, there are many factors that influence the accuracy and efficiency of AI. A well-trained AI can provide enormous benefits in many areas of life - from automating simple tasks to solving complex problems. But it is equally important to understand the limitations and potential pitfalls of AI in order to make the most of its strengths.
🤖📚 Simply explained: How is an AI trained?
🤖📊 AI learning process: capture, link and save
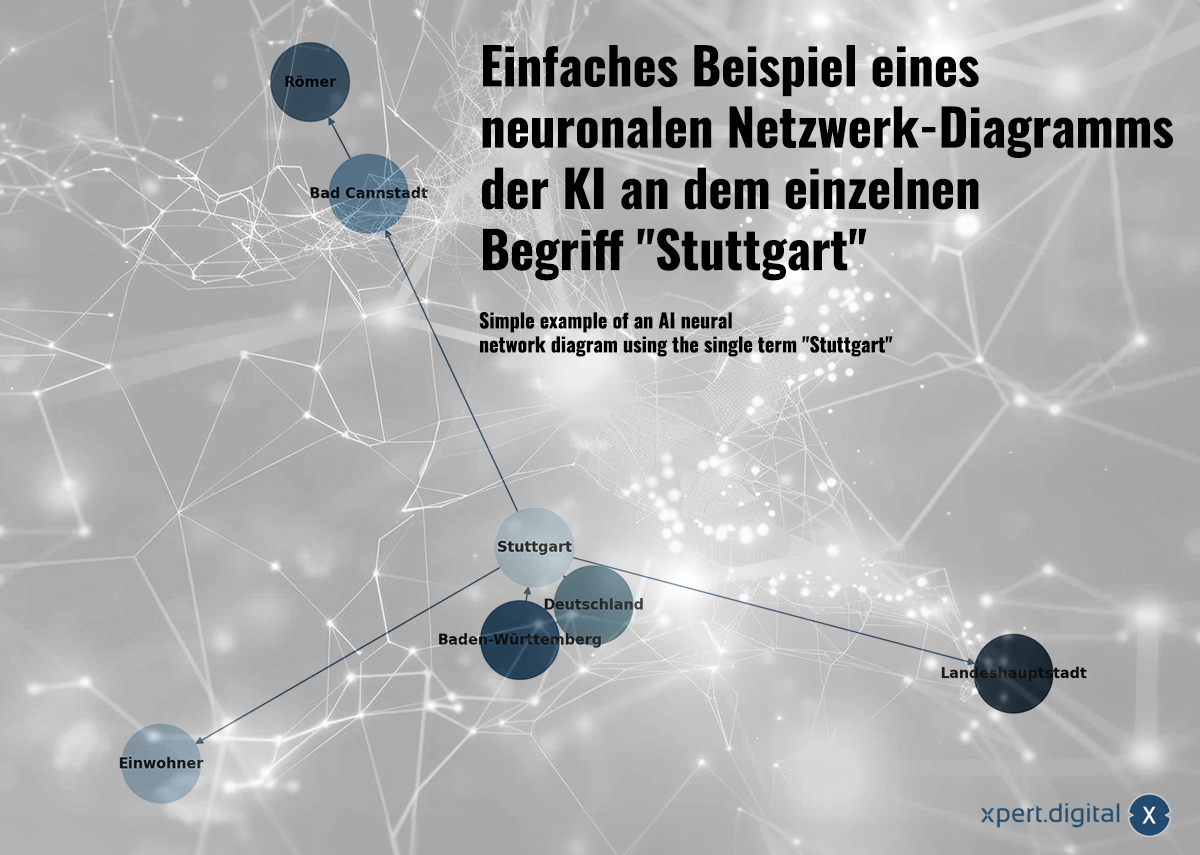
Simple example of a neuronal network diagram of the AI on the individual term “Stuttgart”-Image: Xpert.digital
🌟 Collect and prepare data
The first step in the AI learning process is collecting and preparing the data. This data can come from various sources, such as databases, sensors, texts or images.
🌟 Relating data (Neural Network)
The data collected is related to each other in a neural network. Each data package is shown by connections in a network of “neurons” (node). A simple example with the city of Stuttgart could look like this:
a) Stuttgart is a city in Baden-Württemberg
b) Baden-Württemberg is a federal state in Germany
c) Stuttgart is a city in Germany
d) Stuttgart has a population of 633,484 in 2023
e) Bad Cannstatt is a district of Stuttgart
f) Bad Cannstatt was founded by the Romans
g) Stuttgart is the state capital of Baden-Württemberg
Depending on the size of the data volume, the parameters for potential expenses are created using the AI model used. As an example: GPT-3 has approximately 175 billion parameters!
🌟 Storage and customization (learning)
The data is fed to the neural network. They go through the AI model and are processed via connections (similar to synapses). The weights (parameters) between the neurons are adjusted to train the model or carry out a task.
In contrast to conventional memory forms such as direct access, indicated access, sequential or stack storage, neural networks store the data in an unconventional way. The “data” are stored in the weights and biases of the connections between the neurons.
The actual "storage" of the information in a neuronal network takes place by adapting the connection weights between the neurons. The AI model “learns” by constantly adapting these weights and biases based on the input data and a defined learning algorithm. This is a continuous process in which the model can make precise predictions due to recurring adjustments.
The AI model can be considered a type of programming because it is created through defined algorithms and mathematical calculations and continuously improves the adjustment of its parameters (weights) to make accurate predictions. This is an ongoing process.
Biases are additional parameters in neural networks that are added to the weighted input values of a neuron. They allow the parameters to be weighted (important, less important, important, etc.), making the AI more flexible and accurate.
Neural networks can not only store individual facts, but also recognize connections between the data through pattern recognition. The Stuttgart example illustrates how knowledge can be introduced into a neural network, but neural networks do not learn through explicit knowledge (as in this simple example) but through the analysis of data patterns. Neural networks can not only store individual facts, but also learn weights and relationships between the input data.
This flow provides an understandable introduction to how AI and neural networks in particular work, without diving too deeply into technical details. It shows that the storage of information in neural networks is not done as in traditional databases, but by adjusting the connections (weights) within the network.
🤖📚 More detailed: How is an AI trained?
🏋️♂️ Training an AI, especially a machine learning model, takes place in several steps. Training an AI is based on continuously optimizing model parameters through feedback and adjustment until the model shows the best performance on the data provided. Here is a detailed explanation of how this process works:
1. 📊 Collect and prepare data
Data is the foundation of AI training. They typically consist of thousands or millions of examples for the system to analyze. Examples are images, texts, or time series data.
The data must be cleaned and normalized to avoid unnecessary sources of error. Often the data is converted into features that contain the relevant information.
2. 🔍 Define model
A model is a mathematical function that describes the relationships in the data. In neural networks, which are often used for AI, the model consists of multiple layers of neurons connected together.
Each neuron performs a mathematical operation to process the input data and then passes a signal to the next neuron.
3. 🔄 Initialize weights
The connections between neurons have weights that are initially set randomly. These weights determine how strongly a neuron responds to a signal.
The goal of training is to adjust these weights so that the model makes better predictions.
4. ➡️ Forward Propagation
The forward pass passes the input data through the model to produce a prediction.
Each layer processes the data and passes it to the next layer until the last layer delivers the result.
5. ⚖️ Calculate loss function
The loss function measures how good the model's predictions are compared to the actual values (the labels). A common measure is the error between the predicted and actual response.
The higher the loss, the worse the model's prediction was.
6. 🔙 Backpropagation
In the backward pass, the error is fed back from the output of the model to the previous layers.
The error is redistributed to the weights of the connections and the model adjusts the weights so that the errors become smaller.
This is done using gradient descent: the gradient vector is calculated, which indicates how the weights should be changed in order to minimize the error.
7. 🔧 Update weights
After the error is calculated, the weights of the connections are updated with a small adjustment based on the learning rate.
The learning rate determines how much the weights are changed with each step. Changes that are too large can make the model unstable, and changes that are too small lead to a slow learning process.
8. 🔁 Repeat (Epoch)
This process of forward pass, error calculation, and weight update is repeated, often over multiple epochs (passes through the entire data set), until the model reaches acceptable accuracy.
With each epoch, the model learns a little more and further adjusts its weights.
9. 📉 Validation and testing
After the model is trained, it is tested on a validated dataset to check how well it generalizes. This ensures that it not only has “memorized” the training data, but makes good predictions on unknown data.
Test data helps measure the final performance of the model before it is used in practice.
10. 🚀 Optimization
Additional steps to improve the model include hyperparameter tuning (e.g. adjusting the learning rate or network structure), regularization (to avoid overfitting), or increasing the amount of data.
📊🔙 Artificial intelligence: Make the black box of AI understandable, comprehensible and explainable with Explainable AI (XAI), heatmaps, surrogate models or other solutions

Artificial intelligence: Making the black box of AI understandable, comprehensible and explainable with Explainable AI (XAI), heatmaps, surrogate models or other solutions - Image: Xpert.Digital
The so-called “black box” of artificial intelligence (AI) represents a significant and current problem. Even experts are often faced with the challenge of not being able to fully understand how AI systems arrive at their decisions. This lack of transparency can cause significant problems, particularly in critical areas such as economics, politics or medicine. A doctor or medical professional who relies on an AI system to diagnose and recommend therapy must have confidence in the decisions made. However, if an AI's decision-making is not sufficiently transparent, uncertainty and potentially a lack of trust arise - in situations where human lives could be at stake.
More about it here:
We are there for you - advice - planning - implementation - project management
☑️ SME support in strategy, consulting, planning and implementation
☑️ Creation or realignment of the digital strategy and digitalization
☑️ Expansion and optimization of international sales processes
☑️ Global & Digital B2B trading platforms
☑️ Pioneer Business Development

Konrad Wolfenstein
I would be happy to serve as your personal advisor.
You can contact me by filling out the contact form below or simply call me on +49 89 89 674 804 (Munich) .
I'm looking forward to our joint project.
Write to me

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital is a hub for industry with a focus on digitalization, mechanical engineering, logistics/intralogistics and photovoltaics.
With our 360° business development solution, we support well-known companies from new business to after sales.
Market intelligence, smarketing, marketing automation, content development, PR, mail campaigns, personalized social media and lead nurturing are part of our digital tools.
You can find out more at: www.xpert.digital - www.xpert.solar - www.xpert.plus
Keep in touch


















