
AI and SEO with BERT – Bidirectional Encoder Representations from Transformers – model in the field of natural language processing (NLP)

Language selection 📢
Published on: October 4, 2024 / Update from: October 4, 2024 - Author: Konrad Wolfenstein

AI and SEO with BERT – Bidirectional Encoder Representations from Transformers – Model in the field of natural language processing (NLP) – Image: Xpert.Digital
🚀💬 Developed by Google: BERT and its importance for NLP - Why bidirectional text understanding is crucial
🔍🗣️ BERT, short for Bidirectional Encoder Representations from Transformers, is a major model in the field of natural language processing (NLP) developed by Google. It has revolutionized the way machines understand language. Unlike previous models that analyzed text sequentially from left to right or vice versa, BERT enables bidirectional processing. This means that it captures the context of a word from both the preceding and subsequent text sequence. This ability significantly improves the understanding of complex linguistic contexts.
🔍 The architecture of BERT
In recent years, one of the most significant developments in the field of Natural Language Processing (NLP) has occurred with the introduction of the Transformer model, as presented in the PDF 2017 - Attention is all you need - paper ( Wikipedia ). This model fundamentally changed the field by discarding the structures previously used, such as machine translation. Instead, it relies exclusively on attention mechanisms. Since then, the design of the Transformer has formed the basis for many models that represent the state of the art in various areas such as language generation, translation and beyond.
An illustration of the main components of the Transformer model - Image: Google
BERT is based on this Transformer architecture. This architecture uses so-called self-attention mechanisms to analyze the relationships between words in a sentence. Attention is paid to each word in the context of the entire sentence, resulting in a more precise understanding of syntactic and semantic relationships.
The authors of the paper “Attention is all you need” are:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Google Research)
- Aidan N. Gomez (University of Toronto, work partially done at Google Brain)
- Lukasz Kaiser (Google Brain)
- Illia Polosukhin (Independent, previous work at Google Research)
These authors contributed significantly to the development of the Transformer model presented in this paper.
🔄 Bidirectional processing
A standout feature of BERT is its bidirectional processing capability. While traditional models such as recurrent neural networks (RNNs) or Long Short-Term Memory (LSTM) networks only process text in one direction, BERT analyzes the context of a word in both directions. This allows the model to better capture subtle nuances of meaning and therefore make more accurate predictions.
🕵️♂️ Masked language modeling
Another innovative aspect of BERT is the Masked Language Model (MLM) technique. It involves masking randomly selected words in a sentence and training the model to predict these words based on the surrounding context. This method forces BERT to develop a deep understanding of the context and meaning of each word in the sentence.
🚀 Training and customization of BERT
BERT goes through a two-stage training process: pre-training and fine-tuning.
📚 Pre-training
In pre-training, BERT is trained with large amounts of text to learn general language patterns. This includes Wikipedia texts and other extensive text corpora. In this phase, the model learns basic linguistic structures and contexts.
🔧 Fine tuning
After pre-training, BERT is customized for specific NLP tasks, such as text classification or sentiment analysis. The model is trained with smaller, task-related data sets to optimize its performance for specific applications.
🌍 Areas of application of BERT
BERT has proven to be extremely useful in numerous areas of natural language processing:
Search Engine Optimization
Google uses BERT to better understand search queries and show more relevant results. This greatly improves the user experience.
Text classification
BERT can categorize documents by topic or analyze the mood in texts.
Named Entity Recognition (NER)
The model identifies and classifies named entities in texts, such as personal, place or organization names.
Question and answer systems
BERT is used to provide precise answers to questions asked.
🧠 The importance of BERT for the future of AI
BERT has set new standards for NLP models and paved the way for further innovations. Through its bidirectional processing capability and deep understanding of language context, it has significantly increased the efficiency and accuracy of AI applications.
🔜 Future developments
Further development of BERT and similar models will likely aim to create even more powerful systems. These could handle more complex language tasks and be used in a variety of new areas of application. Integrating such models into everyday technologies could fundamentally change the way we interact with computers.
🌟 Milestone in the development of artificial intelligence
BERT is a milestone in the development of artificial intelligence and has revolutionized the way machines process natural language. Its bidirectional architecture enables a deeper understanding of linguistic relationships, making it indispensable for a variety of applications. As research advances, models like BERT will continue to play a central role in improving AI systems and opening up new possibilities for their use.
📣 Similar topics
- 📚 Introducing BERT: The Breakthrough NLP Model
- 🔍 BERT and the role of bidirectionality in NLP
- 🧠 The Transformer model: cornerstone of BERT
- 🚀 Masked Language Modeling: BERT's Key to Success
- 📈 Customization of BERT: From pre-training to fine-tuning
- 🌐 The areas of application of BERT in modern technology
- 🤖 BERT's influence on the future of artificial intelligence
- 💡 Future prospects: Further developments of BERT
- 🏆 BERT as a milestone in AI development
- 📰 Authors of the Transformer paper “Attention Is All You Need”: The minds behind BERT
#️⃣ Hashtags: #NLP #ArtificialIntelligence #Language Modeling #Transformer #MachineLearning
🎯🎯🎯 Benefit from Xpert.Digital's extensive, fivefold expertise in a comprehensive service package | R&D, XR, PR & SEM

AI & XR 3D Rendering Machine: Fivefold expertise from Xpert.Digital in a comprehensive service package, R&D XR, PR & SEM - Image: Xpert.Digital
Xpert.Digital has in-depth knowledge of various industries. This allows us to develop tailor-made strategies that are tailored precisely to the requirements and challenges of your specific market segment. By continually analyzing market trends and following industry developments, we can act with foresight and offer innovative solutions. Through the combination of experience and knowledge, we generate added value and give our customers a decisive competitive advantage.
More about it here:
BERT: Revolutionary 🌟 NLP technology
🚀 BERT, short for Bidirectional Encoder Representations from Transformers, is an advanced language model developed by Google that has become a significant breakthrough in the field of Natural Language Processing (NLP) since its launch in 2018. It is based on the Transformer architecture, which has revolutionized the way machines understand and process text. But what exactly makes BERT so special and what exactly is it used for? To answer this question, we need to delve deeper into the technical principles, functionality, and application areas of BERT.
📚 1. The basics of natural language processing
To fully grasp the meaning of BERT, it is helpful to briefly review the basics of natural language processing (NLP). NLP deals with the interaction between computers and human language. The goal is to teach machines to analyze, understand and respond to text data. Before the introduction of models like BERT, machine processing of language often presented significant challenges, particularly due to the ambiguity, context dependency, and complex structure of human language.
📈 2. The development of NLP models
Before BERT came onto the scene, most NLP models were based on so-called unidirectional architectures. This means that these models only read text from either left to right or right to left, which meant they could only take into account a limited amount of context when processing a word in a sentence. This limitation often resulted in the models not fully capturing the full semantic context of a sentence. This made it difficult to accurately interpret ambiguous or context-sensitive words.
Another important development in NLP research before BERT was the word2vec model, which allowed computers to translate words into vectors that reflected semantic similarities. But here too the context was limited to the immediate surroundings of a word. Later, Recurrent Neural Networks (RNNs) and in particular Long Short-Term Memory (LSTM) models were developed, which made it possible to better understand text sequences by storing information across multiple words. However, these models also had their limitations, particularly when dealing with long texts and understanding context in both directions at the same time.
🔄 3. The revolution through Transformer architecture
The breakthrough came with the introduction of the Transformer architecture in 2017, which forms the basis for BERT. Transformer models are designed to enable parallel processing of text, taking into account the context of a word from both the preceding and subsequent text. This is done through so-called self-attention mechanisms, which assign a weight value to each word in a sentence based on how important it is in relation to the other words in the sentence.
In contrast to previous approaches, Transformer models are not unidirectional, but bidirectional. This means they can pull information from both the left and right context of a word, producing a more complete and accurate representation of the word and its meaning.
🧠 4. BERT: A bidirectional model
BERT takes the performance of the Transformer architecture to a new level. The model is designed to capture the context of a word not just from left to right or right to left, but in both directions simultaneously. This allows BERT to consider the full context of a word within a sentence, resulting in significantly improved accuracy in language processing tasks.
A central feature of BERT is the use of the so-called Masked Language Model (MLM). In training BERT, randomly selected words in a sentence are replaced with a mask, and the model is trained to guess these masked words based on the context. This technique allows BERT to learn deeper and more precise relationships between the words in a sentence.
Additionally, BERT uses a method called Next Sentence Prediction (NSP), where the model learns to predict whether one sentence follows another or not. This improves BERT's ability to understand longer texts and recognize more complex relationships between sentences.
🌐 5. Application of BERT in practice
BERT has proven to be extremely useful for a variety of NLP tasks. Here are some of the main areas of application:
📊 a) Text classification
One of the most common uses of BERT is text classification, where texts are divided into predefined categories. Examples of this include sentiment analysis (e.g. recognizing whether a text is positive or negative) or the categorization of customer feedback. BERT can provide more precise results than previous models through its deep understanding of the context of words.
❓ b) Question-answer systems
BERT is also used in question-answer systems, where the model extracts answers to posed questions from a text. This ability is particularly important in applications such as search engines, chatbots or virtual assistants. Thanks to its bidirectional architecture, BERT can extract relevant information from a text, even if the question is formulated indirectly.
🌍 c) Text translation
While BERT itself is not directly designed as a translation model, it can be used in combination with other technologies to improve machine translation. By better understanding the semantic relationships in a sentence, BERT can help generate more accurate translations, especially for ambiguous or complex wording.
🏷️ d) Named Entity Recognition (NER)
Another area of application is Named Entity Recognition (NER), which involves identifying specific entities such as names, places or organizations in a text. BERT has proven particularly effective at this task because it fully takes into account the context of a sentence, making it better at recognizing entities even if they have different meanings in different contexts.
✂️ e) Text summary
BERT's ability to understand the entire context of a text also makes it a powerful tool for automatic text summarization. It can be used to extract the most important information from a long text and create a concise summary.
🌟 6. The importance of BERT for research and industry
The introduction of BERT ushered in a new era in NLP research. It was one of the first models to take full advantage of the power of the bi-directional Transformer architecture, setting the bar for many subsequent models. Many companies and research institutes have integrated BERT into their NLP pipelines to improve the performance of their applications.
In addition, BERT has paved the way for further innovations in the area of language models. For example, models such as GPT (Generative Pretrained Transformer) and T5 (Text-to-Text Transfer Transformer) were subsequently developed, which are based on similar principles but offer specific improvements for different use cases.
🚧 7. Challenges and limitations of BERT
Despite its many advantages, BERT also has some challenges and limitations. One of the biggest hurdles is the high computational effort required to train and apply the model. Because BERT is a very large model with millions of parameters, it requires powerful hardware and significant computing resources, especially when processing large amounts of data.
Another issue is the potential bias that may exist in the training data. Because BERT is trained on large amounts of text data, it sometimes reflects the biases and stereotypes present in that data. However, researchers are continually working to identify and address these issues.
🔍 Essential tool for modern language processing applications
BERT has significantly improved the way machines understand human language. With its bidirectional architecture and innovative training methods, it is able to deeply and accurately capture the context of words in a sentence, resulting in higher accuracy in many NLP tasks. Whether in text classification, question-answer systems or entity recognition – BERT has established itself as an indispensable tool for modern language processing applications.
Research in natural language processing will undoubtedly continue to advance, and BERT has laid the foundation for many future innovations. Despite the existing challenges and limitations, BERT impressively shows how far the technology has come in a short time and what exciting opportunities will still open up in the future.
🌀 The Transformer: A Revolution in Natural Language Processing
🌟 In recent years, one of the most significant developments in the field of Natural Language Processing (NLP) has been the introduction of the Transformer model, as described in the 2017 paper “Attention Is All You Need.” This model fundamentally changed the field by discarding the previously used recurrent or convolutional structures for sequence transduction tasks such as machine translation. Instead, it relies exclusively on attention mechanisms. Since then, the design of the Transformer has formed the basis for many models that represent the state of the art in various areas such as language generation, translation and beyond.
🔄 The Transformer: A paradigm shift
Before the introduction of the Transformer, most models for sequencing tasks were based on recurrent neural networks (RNNs) or long short-term memory networks (LSTMs), which are inherently sequential. These models process input data step by step, creating hidden states that are propagated along the sequence. Although this method is effective, it is computationally expensive and difficult to parallelize, especially for long sequences. In addition, RNNs have difficulty learning long-term dependencies due to the so-called “vanishing gradient” problem.
The Transformer's central innovation lies in the use of self-attention mechanisms, which allow the model to weight the importance of different words in a sentence relative to each other, regardless of their position. This allows the model to capture relationships between widely spaced words more effectively than RNNs or LSTMs, and to do so in a parallel manner rather than sequentially. This not only improves training efficiency, but also performance on tasks such as machine translation.
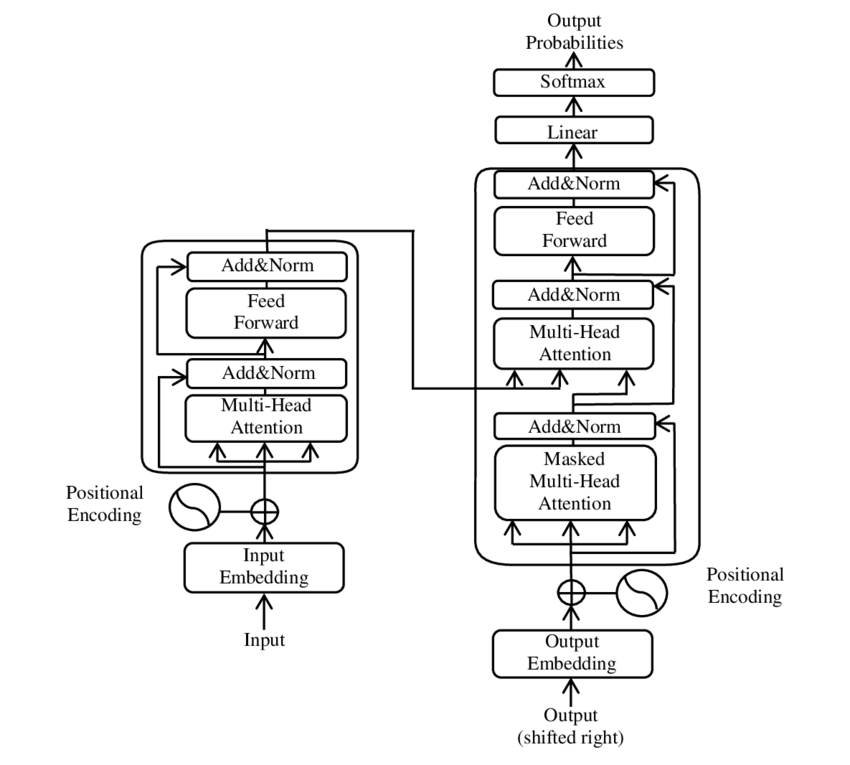
🧩 Model architecture
The Transformer consists of two main components: an encoder and a decoder, both of which consist of multiple layers and rely heavily on multi-head attention mechanisms.
⚙️ Encoder
The encoder consists of six identical layers, each with two sublayers:
1. Multi-Head Self-Attention
This mechanism allows the model to focus on different parts of the input sentence as it processes each word. Instead of computing attention in a single space, multi-head attention projects the input into several different spaces, allowing different types of relationships between words to be captured.
2. Position-wise fully connected feedforward networks
After the attention layer, a fully connected feedforward network is applied independently at each position. This helps the model process each word in context and utilize the information from the attention mechanism.
To preserve the structure of the input sequence, the model also contains positional inputs (positional encodings). Since the Transformer does not process the words sequentially, these encodings are crucial in giving the model information about the order of the words in a sentence. The position inputs are added to the word embeddings so that the model can distinguish between the different positions in the sequence.
🔍 Decoders
Like the encoder, the decoder also consists of six layers, with each layer having an additional attention mechanism that allows the model to focus on relevant parts of the input sequence while generating the output. The decoder also uses a masking technique to prevent it from considering future positions, preserving the autoregressive nature of sequence generation.
🧠 Multi-head attention and dot product attention
The heart of the Transformer is the Multi-Head Attention mechanism, which is an extension of the simpler dot product attention. The attention function can be viewed as a mapping between a query and a set of key-value pairs (keys and values), where each key represents a word in the sequence and the value represents the associated contextual information.
The multi-head attention mechanism allows the model to focus on different parts of the sequence at the same time. By projecting the input into multiple subspaces, the model can capture a richer set of relationships between words. This is particularly useful in tasks such as machine translation, where understanding a word's context requires many different factors, such as syntactic structure and semantic meaning.
The formula for dot product attention is:

Here (Q) is the query matrix, (K) is the key matrix and (V) is the value matrix. The term (sqrt{d_k}) is a scaling factor that prevents the dot products from becoming too large, which would lead to very small gradients and slower learning. The softmax function is applied to ensure that the attention weights sum to one.
🚀 Advantages of the Transformer
The Transformer offers several key advantages over traditional models such as RNNs and LSTMs:
1. Parallelization
Because the Transformer processes all tokens in a sequence at the same time, it can be highly parallelized and is therefore much faster to train than RNNs or LSTMs, especially on large data sets.
2. Long-term dependencies
The self-attention mechanism allows the model to capture relationships between distant words more effectively than RNNs, which are limited by the sequential nature of their computations.
3. Scalability
The Transformer can easily scale to very large datasets and longer sequences without suffering from the performance bottlenecks associated with RNNs.
🌍 Applications and effects
Since its introduction, the Transformer has become the basis for a wide range of NLP models. One of the most notable examples is BERT (Bidirectional Encoder Representations from Transformers), which uses a modified Transformer architecture to achieve state-of-the-art in many NLP tasks, including question answering and text classification.
Another significant development is GPT (Generative Pretrained Transformer), which uses a decoder-limited version of the Transformer for text generation. GPT models, including GPT-3, are now used for a variety of applications, from content creation to code completion.
🔍 A powerful and flexible model
The Transformer has fundamentally changed the way we approach NLP tasks. It provides a powerful and flexible model that can be applied to a variety of problems. Its ability to handle long-term dependencies and training efficiency have made it the preferred architectural approach for many of the most modern models. As research progresses, we will likely see further improvements and adjustments to the Transformer, particularly in areas such as image and language processing, where attention mechanisms show promising results.
We are there for you - advice - planning - implementation - project management
☑️ Industry expert, here with his own Xpert.Digital industry hub with over 2,500 specialist articles

Konrad Wolfenstein
I would be happy to serve as your personal advisor.
You can contact me by filling out the contact form below or simply call me on +49 89 89 674 804 (Munich) .
I'm looking forward to our joint project.
Write to me

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital is a hub for industry with a focus on digitalization, mechanical engineering, logistics/intralogistics and photovoltaics.
With our 360° business development solution, we support well-known companies from new business to after sales.
Market intelligence, smarketing, marketing automation, content development, PR, mail campaigns, personalized social media and lead nurturing are part of our digital tools.
You can find out more at: www.xpert.digital - www.xpert.solar - www.xpert.plus
Keep in touch




















