
Struktureret data (markup) i AI-alderen med Schema.org: Hvad Googles ingeniører virkelig mener
Xpert-forhåndsudgivelse

Available in 27 languages 📢
Foretræk Xpert.Digital på GoogleⓘUdgivet den: 7. maj 2026 / Opdateret den: 7. maj 2026 – Forfatter: Konrad Wolfenstein
Struktureret data (markup) i AI-alderen med Schema.org: Hvad Googles ingeniører virkelig mener – Billede: Xpert.Digital
Googles SEO-hemmelighed: Hvorfor AI fejler uden strukturerede data
Trods ChatGPT & Co.: Hvorfor Googles ingeniører fortsætter med at sværge til Schema.org
SEO-opdatering: Hvorfor Schema.org nu fortrænger Open Graph på Google
En vedvarende myte cirkulerer i SEO-verdenen: I en tid med geniale AI-sprogmodeller, der ubesværet forstår selv ustruktureret tekst, er omhyggeligt vedligeholdte strukturerede data som Schema.org simpelthen blevet forældede. Men virkeligheden er en helt anden. Ved Google Search Central Live-arrangementet aflivede Google-ingeniør Ryan Levering denne misforståelse og gjorde det utvetydigt klart: Struktureret markup er ikke en levn fra fortiden, men snarere den grundlæggende rygrad i den nye AI-drevne søgning.
Fra nye AI-oversigter til autonome shoppingagenter har sprogmodeller brug for præcise, maskinlæsbare retningslinjer for at undgå hallucinationer og for at fungere beregningsmæssigt effektivt. De, der ønsker at forblive synlige på det moderne web, skal hjælpe maskiner med at forstå kontekst uden tvetydighed. Denne artikel undersøger Googles strategiske omlægning, præsenterer revolutionerende innovationer inden for e-handel og brugergenereret indhold og viser, hvorfor teknisk SEO nu er den afgørende konkurrencefordel i kampen om maskiners synlighed.
Maskiner kan læse nettet – men kun hvis du hjælper dem med at forstå det
Den 21. april 2026 fandt den første Google Search Central Live-begivenhed på canadisk jord sted i Toronto – og det var ikke nogen almindelig brancheforsamling. Ryan Levering, ingeniør hos Google Search Engineering, leverede det, der uden tvivl var dagens mest teknisk tætte og strategisk betydningsfulde præsentation: "Structured Data, Quality & AI." Det, han præsenterede, var mere end en teknisk gennemgang. Det var en klar erklæring om fremtiden for det semantiske web i en æra, hvor kunstig intelligens i stigende grad påtager sig rollen som mellemled mellem brugere og information.
Mellem to yderpunkter: Det forkerte enten-eller
I begyndelsen af sin præsentation satte Ryan Levering to diametralt modsatte meninger i SEO-miljøet op. På den ene side er der overbevisningen om, at strukturerede data simpelthen er overflødige i en tidsalder med kraftfulde sprogmodeller: Hvis AI-modeller nemt kan fortolke ustruktureret tekst, hvorfor så besvære sig med at tilføje schema.org-markup til kildekoden? På den anden side udbreder nogle entusiaster ideen om, at strukturerede data er internettets fremtid – en universel semantisk kommunikationsprotokol mellem autonome AI-agenter, der i vid udstrækning vil erstatte det traditionelle web.
Levering afviste begge yderpunkter og præsenterede i stedet et nuanceret, empirisk funderet perspektiv. Begge positioner indeholdt en kerne af sandhed, konkluderede han, men ingen af dem beskrev virkeligheden fuldt ud. Denne nuance er karakteristisk for Googles nuværende tilgang til emnet: det handler ikke om dogmer, men om pragmatisk effektivitet.
Fire argumenter, der forklarer alt
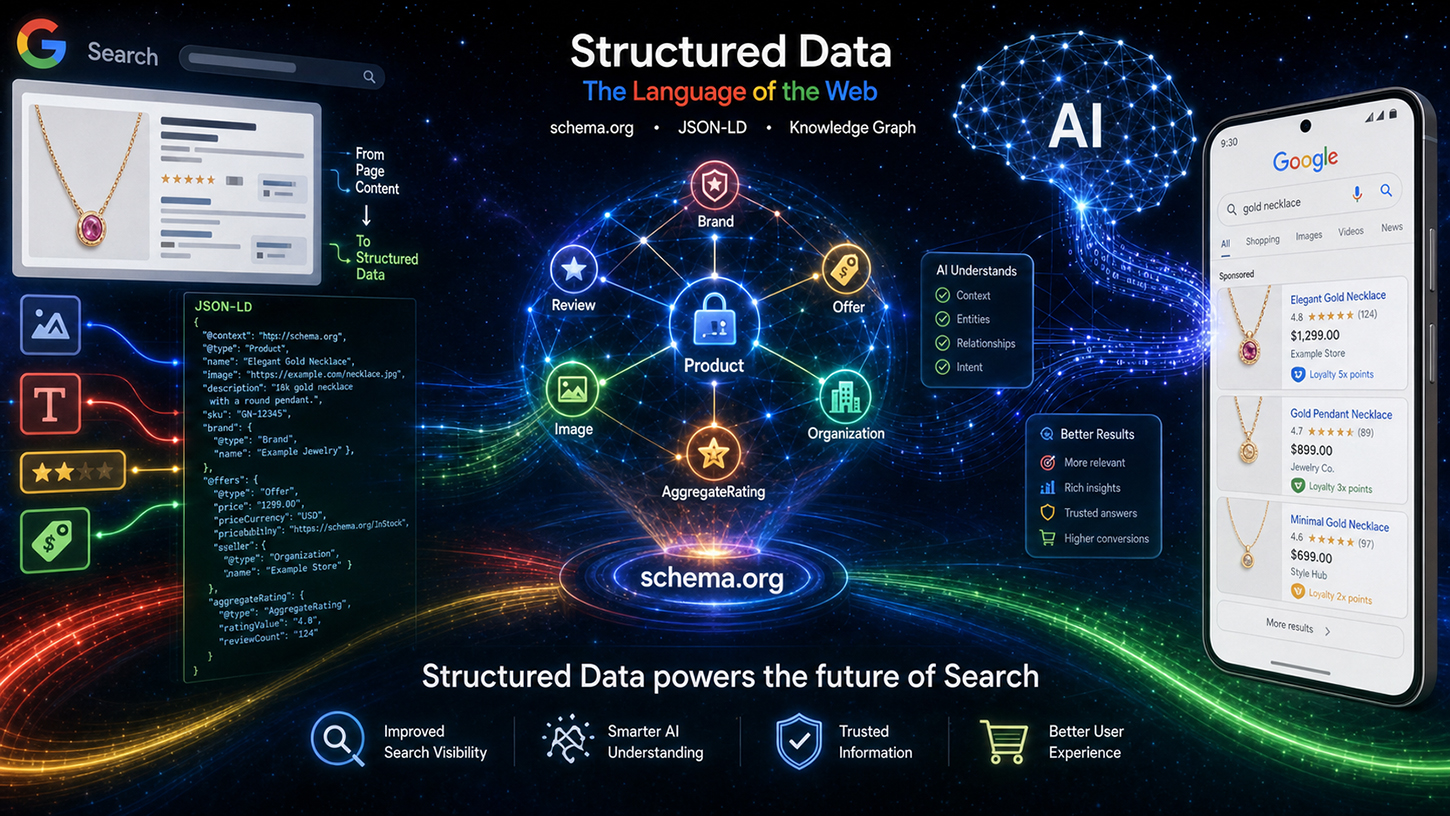
Leverings centrale argument kan opsummeres i fire hovedpunkter, som han uddybede under titlen "Værdi af strukturerede data". Det første punkt er præcision: Strukturerede data giver betydeligt højere nøjagtighed for komplekse skemaer såsom salgspriser eller loyalitetsprogrammer end LLM-baseret udtrækning fra fritekst. Sprogmodeller kan være misvisende - de udfylder manglende attributter, indlejrer data forkert eller tilgår information ude af kontekst. Når man udtrækker produktpriser fra en stor e-handelsside med snesevis af lignende varer, er fejlraten betydeligt højere med AI-inferens end med rent implementeret, struktureret markup.
Det andet punkt vedrører yderligere indhold: Strukturerede data indeholder ofte usynlige metadata, der simpelthen ikke findes i den gengivne HTML på en side. Komplette ISO-datoformater, stabile identifikatorer for brugergenereret indhold eller interne enheds-ID'er – disse oplysninger findes udelukkende i markup'en. Ingen sprogmodel kan udtrække det, der ikke er i teksten.
For det tredje, effektivitet: Det er mange gange billigere at parse struktureret markup end at behandle en stor sprogmodel for at udtrække komplekse data. Google indekserer milliarder af sider dagligt. Beregningen er enkel: En almindelig parser, der behandler JSON-LD, forbruger en brøkdel af computerressourcerne i et LLM-inferenstrin. Strukturerede data er derfor ikke kun semantisk bedre – de er også betydeligt mere effektive fra et forretningsperspektiv. Dette punkt er af direkte relevans for Googles infrastruktur.
Det fjerde, og måske mest undervurderede, aspekt er fokus: Strukturerede data fremhæver eksplicit, hvilke oplysninger der er relevante på en side, og forhindrer dermed AI-systemer i at opfange irrelevante data. På en produktside med en hovedartikel, flere relaterede produkter og en navigationslinje fuld af priser kan en sprogmodel uden eksplicit annotering ikke være sikker på, hvilken pris der skal henvises til. Struktureret markup løser dette problem gennem entydig tildeling.
Hvordan strukturerede data faktisk behandles
Levering gjorde også den tekniske behandlingsproces transparent. Schema.org-data behandles først gennem specifik rensning og filtrering, før de kategoriseres som indekserede data – opdelt i områder som events, shopping og anmeldelser. Disse forberedte data flyder derefter ind i to forskellige outputkanaler: på den ene side den klassiske søgeresultatside (SRP), og på den anden side som kontekst for Googles AI-baserede systemer, specifikt de såkaldte AI Overviews (AIO) og AI Mode (AIM). Strukturerede data er således ikke længere blot et rich results-værktøj, men direkte input til generative AI-responser. Dette repræsenterer et fundamentalt skift i den strategiske betydning af schema.org-markup.
🎯🎯🎯 Datadrevet B2B-industrihub som en næsten intern løsning

Den nærmest interne løsning: Hvordan Xpert.Digital lukker operationelle huller i B2B-marketing og -salg – Smart Content-Driven Business - Billede: Xpert.Digital
Xpert.Digital er et datadrevet B2B-industricenter ledet af Konrad Wolfenstein . Virksomheden fungerer som en ekstern, nærmest intern løsning for industrielle partnere og lukker operationelle huller i marketing, indhold og salg – uden at kræve yderligere ressourcer fra klientsiden.
Mere information her:
Hvorfor strukturerede data er ved at blive infrastrukturen for AI-agenter
Shopping i fokus: Forsendelse, loyalitet og variationer
En betydelig del af præsentationen fokuserede på innovationer inden for e-handel. Levering forklarede, at ifølge data fra Baymard Institute er uventet forsendelsesinformation henholdsvis nummer to og tre blandt de mest almindelige årsager til, at indkøbskurve forlades. Struktureret markup til forsendelsestjenester kan direkte løse dette problem: Forhandlere kan nu præcist definere oprindelses- og destinationsregioner, dimensioner og vægte, ordreværdigrænser, behandlingstider og loyalitetsprogramtilhørsforhold direkte i koden.
Den leveringstidsmodel, som Google bruger, er opdelt i to faser: ekspeditionstiden, dvs. tiden fra ordremodtagelse til overdragelse til transportøren, og den faktiske leveringstid. Begge faser kan annoteres separat og med høj granularitet – helt ned til ordrefrister og om behandlingen også finder sted på hverdage. De tilsvarende JSON-LD-eksempler viser, hvordan typen `ShippingConditions` kan bruges til at definere gratis fragt for bestemte lande (f.eks. Frankrig og Tyskland) og minimumsbestillingsværdier (f.eks. €50).
Integrationen af forsendelsestjenester med loyalitetsprogrammer er særligt innovativ. Ved at bruge egenskaben `validForMemberTier` kan en forsendelsestjeneste eksplicit linkes til et medlemskabsprogram og et specifikt niveau. Dette gør det muligt at deklarere forsendelsesfordele for premium-medlemmer direkte i markup'en – en funktion, der tidligere kun kunne konfigureres via Google Merchant Center. Selve det tilknyttede loyalitetsprogram er defineret som et `MemberProgram`-objekt under `Organization`-enheden med niveauer som "Guld" eller "Sølv" og tilhørende fordele som loyalitetsbelønninger eller pointbelønninger.
Loyalitetsprogrammer som semantiske enheder
Introduktionen af loyalitetsprogram-markup er økonomisk betydningsfuld. Organisationer kan definere flere uafhængige medlemsprogrammer, hver med flere niveauer og differentierede fordele – point, medlemspriser, returpolitikker, forsendelsesbonusser. Disse oplysninger vises derefter direkte i Googles søgeresultater, som Levering demonstrerede med eksempler fra den virkelige verden, herunder et Sephora-tilbud, der viste en medlemsrabat på 30 procent direkte i shopping-kodestykket. Cross-page ID-linking, muligheden for at linke til loyalitetsprogramdefinitioner fra andre sider, er ifølge Levering det næste planlagte skridt, der i øjeblikket har titlen "Blazing the path for cross-page @id linking". Målet: stærkere organisatoriske referencer mellem produktsider og virksomhedspolitikker.
Brugergenereret indhold: Problemet med AI-mærkning
Et andet vigtigt emne var videreudviklingen af skematyper til brugergenereret indhold (UGC). To nye funktioner er særligt relevante her. For det første understøttes indlejrede opslag og reposts i forum- og Q&A-markup, hvilket muliggør en mere præcis semantisk repræsentation af diskussionsstrukturer. For det andet – og dette er af endnu større strategisk betydning – introduceres egenskaben `so#digitalSourceType` for eksplicit at identificere maskingenereret indhold.
Denne udvikling er en direkte reaktion på strømmen af AI-genereret indhold på platforme som fora og Q&A-sider. Webmastere kan nu erklære, om et indlæg er genereret algoritmisk eller af en sprogmodel. De, der ikke specificerer dette, antages implicit af Google at være menneskelige forfattere – en regel, der fremmer transparent mærkning. Egenskaben `digitalSourceType` er baseret på IPTC-koderne for digitale kilder og skelner blandt andet mellem algoritmisk genereret og modelgenereret indhold.
Billedvalg: Skema bedre end Open Graph
En mindre bemærket, men praktisk effektiv opdatering vedrører Googles billedvalgslogik. Systemet konsolideres internt med et klart prioriteringshierarki: Schema.org-markup, specifikt egenskaberne `primaryImageOfPage` og `mainEntity → image`, har forrang. Først derefter følger `og:image`-metatagget fra Open Graph. Denne ændring betyder, at for webstedsoperatører påvirker en ren schema.org-implementering af hovedbilledet direkte dets visning i Googles søgeresultater og AI Overviews – en konkret, målbar fordel.
Schema.org modtager selv investeringer
Det er også værd at bemærke Googles annoncerede geninvestering i schema.org som en åben specifikation. Tre konkrete tiltag blev nævnt: offentliggørelse af statistikker om brugsfrekvensen af individuelle skematermer (prævalensdata er, som et slideshow, allerede tilgængelige for individuelle termer som `digitalSourceType` med information om cirka 10.000 domæner), offentliggørelse af Googles egne valideringsregler i maskinlæsbare standardformater som SHACL eller ShEx, og forbedret understøttelse af ordensregler. Dette er vigtigt, fordi det ville give eksterne udviklere mulighed for at bygge deres egne valideringsværktøjer baseret på Googles standarder – uafhængigt af de officielle testværktøjer, som lejlighedsvis går ned under belastning.
Validering: To værktøjer, ét mål
Levering præsenterede to valideringsværktøjer, der supplerer hinanden, men anvender forskellige testkriterier. Rich Result Test Tool på `search.google.com/test/rich-results` accepterer URL'er eller ren JSON og kontrollerer, om markup'en er egnet til Google Search Rich Results – den er derfor baseret på Googles specifikke krav, ikke på selve schema.org-standarden. `validator.schema.org` kontrollerer derimod, om markup'en er schema.org-kompatibel, dvs. overholder det åbne vokabular, uanset om Google genererer rich results ud fra den. Dette fører til en klar anbefaling til webudviklere: begge værktøjer bør bruges, fordi markup kan være skema-kompatibel, men ikke rich-result-kompatibel – og omvendt.
Det større billede: Strukturerede data som AI-infrastruktur
Ser man på Toronto-begivenheden som helhed, er der et tydeligt skift, der rækker langt ud over traditionel SEO-optimering. Strukturerede data udvikler sig fra et værktøj til at opnå rich snippets til en grundlæggende datalagsstandard for AI-systemer. Googles AI Overviews og AI Mode bruger aktivt schema.org-markup som kontekst til svargenerering og entitetsverifikation. De, der implementerer korrekte, komplette og præcise strukturerede data, forbedrer ikke kun deres chancer for at opnå visuelle fremhævelser i søgeresultaterne – de positionerer også deres indhold som en pålidelig primær kilde til AI-svar.
Nævnelsen af Universal Commerce Protocol (UCP) og WebMCP i denne sammenhæng er ikke tilfældig. Begge agentbaserede kommunikationsstandarder, som Google udgav i tidlige versioner i 2026, kræver, at hjemmesider beskrives semantisk. Schema.org danner grundlag for dette. I en verden, hvor AI-agenter agerer autonomt på nettet, søger, sammenligner og initierer transaktioner, er maskinlæsbarhed af indhold ikke længere valgfri, men en forudsætning for økonomisk relevans. Ryan Leverings præsentation i Toronto var derfor ikke blot en teknisk opdateringsrapport – det var et glimt ind i infrastrukturen for det næste web.
Du kan finde ud af det selv på 10 sekunder
Hvis du vil vide, hvor godt og omfattende din eller en anden hjemmeside bruger struktureret data, kan du bruge præcis de to værktøjer, som Ryan Levering fra Google (fra vores tekst ovenfor) anbefalede:
Google Rich Results Test (fokus på Google-synlighed):
Gå til search.google.com/test/rich-results, kopier URL'en til en hvilken som helst xpert.digital-artikel, og klik på "Test URL". Værktøjet viser dig præcis, hvilke markeringer Google genkender på den pågældende side, og om de er fejlfri.
Schema Validator (fokus på ren standardoverholdelse):
Gå til validator.schema.orgog indsæt den samme URL. Her kan du se direkte i kildekoden, fremhævet med farve, hvilke JSON-LD-scripts (strukturerede data) xpert.digital har indarbejdet.
Din globale marketing- og forretningsudviklingspartner
☑️ Vores forretningssprog er engelsk eller tysk
☑️ NYT: Korrespondance på dit modersmål!

Konrad Wolfenstein
Jeg og mit team er glade for at stå til rådighed for dig som din personlige rådgiver.
Du kan kontakte mig ved at udfylde kontaktformularen her blot ringe til mig på +49 7348 4088 965. Min e-mailadresse er [email protected]:eller
Jeg glæder mig til vores fælles projekt.
☑️ SMV-support inden for strategi, rådgivning, planlægning og implementering
☑️ Oprettelse eller omlægning af den digitale strategi og digitalisering
☑️ Udvidelse og optimering af internationale salgsprocesser
☑️ Globale og digitale B2B-handelsplatforme
☑️ Pioner inden for forretningsudvikling / marketing / PR / messer
B2B-support og SaaS til SEO og GEO (AI-søgning) kombineret: Alt-i-én-løsningen til B2B-virksomheder

B2B-support og SaaS til SEO og GEO (AI-søgning) kombineret: Alt-i-én-løsningen til B2B-virksomheder - Billede: Xpert.Digital
AI-søgning ændrer alt: Hvordan denne SaaS-løsning vil revolutionere din B2B-rangering for altid.
Det digitale landskab for B2B-virksomheder er under hastig forandring. Drevet af kunstig intelligens omskrives reglerne for online synlighed. For virksomheder har det altid været en udfordring ikke kun at være synlig i den digitale masse, men også at være relevant for de rigtige beslutningstagere. Traditionelle SEO-strategier og håndtering af lokal tilstedeværelse (geo-marketing) er komplekse, tidskrævende og ofte en kamp mod konstant skiftende algoritmer og intens konkurrence.
Men hvad nu hvis der fandtes en løsning, der ikke blot forenklede denne proces, men også gjorde den smartere, mere prædiktiv og langt mere effektiv? Det er her, kombinationen af specialiseret B2B-support med en kraftfuld SaaS-platform (Software as a Service) kommer i spil, specifikt designet til kravene fra SEO og GEO i AI-søgningens tidsalder.
Denne nye generation af værktøjer er ikke længere udelukkende afhængige af manuel søgeordsanalyse og backlink-strategier. I stedet udnytter den kunstig intelligens til mere præcist at forstå søgeintention, automatisk optimere lokale rangeringsfaktorer og udføre konkurrenceanalyser i realtid. Resultatet er en proaktiv, datadrevet strategi, der giver B2B-virksomheder en afgørende fordel: De bliver ikke kun fundet, men opfattet som den førende autoritet inden for deres niche og placering.
Her er symbiosen mellem B2B-support og AI-drevet SaaS-teknologi, der transformerer SEO- og GEO-marketing, og hvordan din virksomhed kan drage fordel af den for at vokse bæredygtigt i det digitale rum.
Mere information her:
















