
AI og SEO med BERT – Bidirektionelle encoderrepræsentationer fra transformere – Model inden for naturlig sprogbehandling (NLP)

Available in 27 languages 📢
Foretræk Xpert.Digital på GoogleⓘUdgivet den: 4. oktober 2024 / Opdateret den: 4. oktober 2024 – Forfatter: Konrad Wolfenstein

AI og SEO med BERT – Bidirektionelle encoderrepræsentationer fra transformere – Model inden for naturlig sprogbehandling (NLP) – Billede: Xpert.Digital
🚀💬 Udviklet af Google: BERT og dets betydning for NLP - Hvorfor tovejs tekstforståelse er afgørende
🔍🗣️ BERT, en forkortelse for Bidirectional Encoder Representations from Transformers, er en betydelig model inden for naturlig sprogbehandling (NLP) udviklet af Google. Den har revolutioneret den måde, maskiner forstår sprog på. I modsætning til tidligere modeller, der analyserede tekst sekventielt fra venstre mod højre eller omvendt, muliggør BERT tovejsbehandling. Det betyder, at den forstår konteksten af et ord fra både de foregående og efterfølgende tekstsekvenser. Denne funktion forbedrer forståelsen af komplekse sproglige relationer betydeligt.
🔍 BERTs arkitektur
I de senere år har en af de mest betydningsfulde udviklinger inden for naturlig sprogbehandling (NLP) været introduktionen af Transformer-modellen, som beskrevet i PDF-artiklen "Attention is all you need" ( Wikipedia ) fra 2017. Denne model ændrede fundamentalt feltet ved at kassere tidligere anvendte strukturer, såsom maskinoversættelse. I stedet er den udelukkende afhængig af opmærksomhedsmekanismer. Transformer-designet har siden dannet grundlag for mange modeller, der repræsenterer den nyeste teknologi inden for forskellige områder, herunder talegenerering, oversættelse og mere.
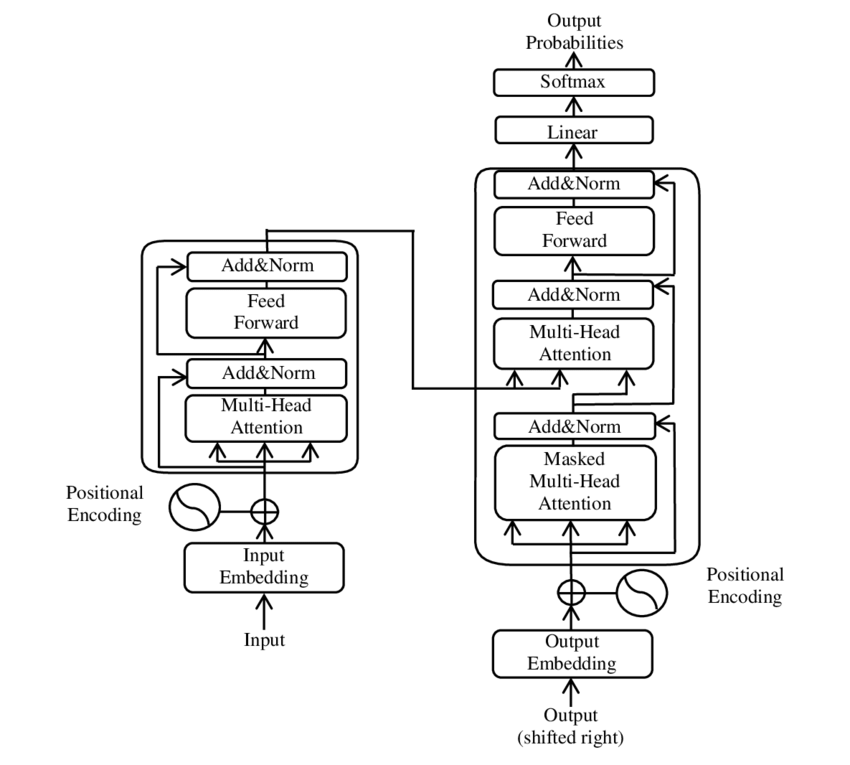
En illustration af hovedkomponenterne i Transformer-modellen – Billede: Google
BERT er baseret på denne transformerarkitektur. Denne arkitektur bruger såkaldte selvopmærksomhedsmekanismer til at analysere forholdet mellem ord i en sætning. Hvert ord får opmærksomhed inden for rammerne af hele sætningen, hvilket fører til en mere præcis forståelse af syntaktiske og semantiske forhold.
Forfatterne til artiklen “Opmærksomhed er alt, hvad du behøver” er:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Google Research)
- Aidan N. Gomez (University of Toronto, arbejde delvist udført hos Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (Uafhængig, tidligere arbejde hos Google Research)
Disse forfattere har ydet betydelige bidrag til udviklingen af Transformer-modellen, der præsenteres i denne artikel.
🔄 Tovejsbehandling
En central funktion ved BERT er dens evne til at behandle tekst i begge retninger. Mens traditionelle modeller som tilbagevendende neurale netværk (RNN'er) eller lange korttidshukommelsesnetværk (LSTM) kun behandler tekst i én retning, analyserer BERT konteksten af et ord i begge retninger. Dette gør det muligt for modellen bedre at indfange subtile nuancer af betydning og dermed foretage mere præcise forudsigelser.
🕵️♂️ Maskeret talemodellering
Et andet innovativt aspekt ved BERT er Masked Language Model (MLM)-teknikken. Her maskeres tilfældigt udvalgte ord i en sætning, og modellen trænes til at forudsige disse ord baseret på den omgivende kontekst. Denne metode tvinger BERT til at udvikle en dyb forståelse af konteksten og betydningen af hvert ord i sætningen.
🚀 Træning og tilpasning af BERT
BERT gennemgår en to-trins træningsproces: forberedende træning og finjustering.
📚 Før træning
I fortræningen trænes BERT med store mængder tekst for at lære generelle sprogmønstre. Dette inkluderer Wikipedia-artikler og andre omfattende tekstkorpora. I denne fase lærer modellen grundlæggende sproglige strukturer og kontekster.
🔧 Finjustering
Efter fortræning tilpasses BERT til specifikke NLP-opgaver, såsom tekstklassificering eller sentimentanalyse. Modellen trænes med mindre, opgaverelaterede datasæt for at optimere dens ydeevne til specifikke applikationer.
🌍 Anvendelsesområder for BERT
BERT har vist sig yderst nyttigt inden for adskillige områder af naturlig sprogbehandling:
Søgemaskineoptimering
Google bruger BERT til bedre at forstå søgeforespørgsler og vise mere relevante resultater. Dette forbedrer brugeroplevelsen betydeligt.
Tekstklassificering
BERT kan kategorisere dokumenter efter emne eller analysere stemningen i tekster.
Genkendelse af navngivne enheder (NER)
Modellen identificerer og klassificerer navngivne enheder i tekster, såsom navne på personer, steder eller organisationer.
Spørgsmål-svar-systemer
BERT bruges til at give præcise svar på stillede spørgsmål.
🧠 BERT's betydning for AI's fremtid
BERT har sat nye standarder for NLP-modeller og banet vejen for yderligere innovationer. Gennem sin evne til tovejsbehandling og sin dybe forståelse af sproglige kontekster har det øget effektiviteten og nøjagtigheden af AI-applikationer betydeligt.
🔜 Fremtidige udviklinger
Videreudvikling af BERT og lignende modeller forventes at sigte mod at skabe endnu mere kraftfulde systemer. Disse vil kunne håndtere mere komplekse sprogopgaver og blive brugt i en bred vifte af nye anvendelsesområder. Integration af sådanne modeller i hverdagsteknologier kan fundamentalt ændre, hvordan vi interagerer med computere.
🌟 Milepæl i udviklingen af kunstig intelligens
BERT er en milepæl i udviklingen af kunstig intelligens og har revolutioneret den måde, maskiner bearbejder naturligt sprog på. Dens tovejsarkitektur muliggør en dybere forståelse af sproglige relationer, hvilket gør den uundværlig for en bred vifte af anvendelser. Efterhånden som forskningen skrider frem, vil modeller som BERT fortsat spille en central rolle i at forbedre AI-systemer og åbne op for nye muligheder for deres anvendelse.
📣 Lignende emner
- 📚 Introduktion til BERT: Den banebrydende NLP-model
- 🔍 BERT og rollen af bidirektionalitet i NLP
- 🧠 Transformer-modellen: Grundlæggelsen af BERT
- 🚀 Maskeret sprogmodellering: BERTs nøgle til succes
- 📈 BERT-tilpasning: Fra forberedelse til finjustering
- 🌐 Anvendelsesområderne for BERT inden for moderne teknologi
- 🤖 BERTs indflydelse på fremtiden for kunstig intelligens
- 💡 Fremtidsudsigter: Yderligere udvikling af BERT
- 🏆 BERT som en milepæl i AI-udvikling
- 📰 Forfattere til Transformer-artiklen “Attention Is All You Need”: Tankerne bag BERT
#️⃣ Hashtags: #NLP #KunstigIntelligens #Sprogmodellering #Transformer #Maskinlæring
🎯🎯🎯 Drag fordel af Xpert.Digital's omfattende, femdobbelte ekspertise i én omfattende servicepakke | BD, R&D, XR, PR & optimering af digital synlighed

Drag fordel af Xpert.Digital's omfattende, femdobbelte ekspertise i en omfattende servicepakke | R&D, XR, PR & optimering af digital synlighed - Billede: Xpert.Digital
Xpert.Digital besidder dybdegående viden på tværs af forskellige brancher. Dette giver os mulighed for at udvikle skræddersyede strategier, der er præcist afstemt med kravene og udfordringerne i dit specifikke markedssegment. Ved løbende at analysere markedstendenser og overvåge brancheudviklingen kan vi handle proaktivt og tilbyde innovative løsninger. Kombinationen af erfaring og ekspertise skaber merværdi og giver vores kunder en afgørende konkurrencefordel.
Mere information her:
BERT: Revolutionerende 🌟 NLP-teknologi
🚀 BERT, en forkortelse for Bidirectional Encoder Representations from Transformers, er en avanceret sprogmodel udviklet af Google, der har været et betydeligt gennembrud inden for naturlig sprogbehandling (NLP) siden introduktionen i 2018. Den er baseret på Transformer-arkitekturen, som revolutionerede, hvordan maskiner forstår og behandler tekst. Men hvad gør BERT præcist så specielt, og hvad bruges det til? For at besvare dette spørgsmål skal vi se nærmere på BERTs tekniske grundlag, hvordan det fungerer, og dets anvendelser.
📚 1. Grundlæggende om naturlig sprogbehandling
For fuldt ud at forstå betydningen af BERT er det nyttigt kort at gennemgå det grundlæggende i naturlig sprogbehandling (NLP). NLP beskæftiger sig med interaktionen mellem computere og menneskeligt sprog. Målet er at lære maskiner at analysere, forstå og reagere på tekstdata. Før introduktionen af modeller som BERT var maskinsprogbehandling ofte fyldt med betydelige udfordringer, især på grund af tvetydigheden, kontekstafhængigheden og den komplekse struktur i menneskeligt sprog.
📈 2. Udviklingen af NLP-modeller
Før BERT opstod, var de fleste NLP-modeller baseret på såkaldte ensrettede arkitekturer. Det betød, at disse modeller læste tekst enten fra venstre mod højre eller fra højre mod venstre, hvilket betød, at de kun kunne tage en begrænset mængde kontekst i betragtning, når de behandlede et ord i en sætning. Denne begrænsning resulterede ofte i, at modellerne ikke fuldt ud indfangede den semantiske kontekst i en sætning. Dette gjorde den nøjagtige fortolkning af tvetydige eller kontekstfølsomme ord vanskelig.
En anden vigtig udvikling inden for NLP-forskning før BERT var word2vec-modellen, som gjorde det muligt for computere at oversætte ord til vektorer, der afspejlede semantiske ligheder. Men selv her var konteksten begrænset til ordets umiddelbare omgivelser. Senere blev der udviklet modeller for tilbagevendende neurale netværk (RNN'er) og især Long Short-Term Memory (LSTM), som gjorde det muligt bedre at forstå tekstsekvenser ved at lagre information på tværs af flere ord. Disse modeller havde dog også deres begrænsninger, især når man beskæftiger sig med lange tekster og samtidig forstår kontekst i begge retninger.
🔄 3. Revolutionen gennem transformerarkitektur
Gennembruddet kom med introduktionen af Transformer-arkitekturen i 2017, som danner grundlag for BERT. Transformer-modeller er designet til at muliggøre parallel tekstbehandling, hvor konteksten af et ord fra både den foregående og efterfølgende tekst tages i betragtning. Dette opnås gennem såkaldte selvopmærksomhedsmekanismer, som tildeler en vægtværdi til hvert ord i en sætning baseret på dets betydning i forhold til de andre ord i sætningen.
I modsætning til tidligere tilgange er transformermodeller ikke ensrettede, men tovejs. Det betyder, at de kan trække information fra både venstre og højre kontekst af et ord for at skabe en mere komplet og præcis repræsentation af ordet og dets betydning.
🧠 4. BERT: En tovejsmodel
BERT tager Transformer-arkitekturens ydeevne til et nyt niveau. Modellen er designet til at indfange konteksten af et ord, ikke kun fra venstre mod højre eller højre mod venstre, men i begge retninger samtidigt. Dette gør det muligt for BERT at overveje den komplette kontekst af et ord i en sætning, hvilket resulterer i betydeligt forbedret nøjagtighed i opgaver med naturlig sprogbehandling.
En central funktion ved BERT er brugen af den såkaldte Masked Language Model (MLM). Under BERT-træning erstattes tilfældigt udvalgte ord i en sætning med en maske, og modellen trænes til at gætte disse maskerede ord baseret på konteksten. Denne teknik gør det muligt for BERT at lære dybere og mere præcise relationer mellem ordene i en sætning.
Derudover bruger BERT en metode kaldet Next Sentence Prediction (NSP), hvor modellen lærer at forudsige, om én sætning følger efter en anden. Dette forbedrer BERTs evne til at forstå længere tekster og genkende mere komplekse sammenhænge mellem sætninger.
🌐 5. Praktisk anvendelse af BERT
BERT har vist sig yderst nyttigt til en bred vifte af NLP-opgaver. Her er nogle af de vigtigste anvendelsesområder:
📊 a) Tekstklassificering
En af de mest almindelige anvendelser af BERT er tekstklassificering, hvor tekster opdeles i foruddefinerede kategorier. Eksempler omfatter sentimentanalyse (f.eks. genkendelse af, om en tekst er positiv eller negativ) eller kategorisering af kundefeedback. På grund af sin dybe forståelse af ords kontekst kan BERT levere mere præcise resultater end tidligere modeller.
❓ b) Spørgsmål-svar-systemer
BERT bruges også i spørgsmålsbesvarelsessystemer, hvor modellen udtrækker svar på stillede spørgsmål fra en tekst. Denne funktion er især vigtig i applikationer som søgemaskiner, chatbots og virtuelle assistenter. Takket være sin tovejsarkitektur kan BERT udtrække relevante oplysninger fra en tekst, selvom spørgsmålet er formuleret indirekte.
🌍 c) Tekstoversættelse
Selvom BERT i sig selv ikke direkte er designet som en oversættelsesmodel, kan den bruges i kombination med andre teknologier til at forbedre maskinoversættelse. Ved bedre at forstå de semantiske relationer i en sætning kan BERT hjælpe med at generere mere præcise oversættelser, især med tvetydig eller kompleks formulering.
🏷️ d) Genkendelse af navngivne enheder (NER)
Et andet anvendelsesområde er Named Entity Recognition (NER), som involverer identifikation af specifikke enheder såsom navne, steder eller organisationer i en tekst. BERT har vist sig særligt effektivt til denne opgave, fordi det fuldt ud tager højde for konteksten i en sætning og dermed bedre kan genkende enheder, selvom de har forskellige betydninger i forskellige kontekster.
✂️ e) Tekstoversigt
BERTs evne til at forstå hele konteksten i en tekst gør det også til et effektivt værktøj til automatisk tekstopsummering. Det kan bruges til at udtrække de vigtigste oplysninger fra en lang tekst og skabe et kortfattet resumé.
🌟 6. BERT's betydning for forskning og industri
Introduktionen af BERT indledte en ny æra inden for NLP-forskning. Det var en af de første modeller, der fuldt ud udnyttede kraften i den tovejstransformerende arkitektur og satte standarden for mange efterfølgende modeller. Talrige virksomheder og forskningsinstitutioner har integreret BERT i deres NLP-pipelines for at forbedre ydeevnen af deres applikationer.
Derudover banede BERT vejen for yderligere innovationer inden for sprogmodeller. For eksempel blev modeller som GPT (Generative Pretrained Transformer) og T5 (Text-to-Text Transfer Transformer) efterfølgende udviklet, som er baseret på lignende principper, men tilbyder specifikke forbedringer til forskellige anvendelsesscenarier.
🚧 7. Udfordringer og begrænsninger ved BERT
Trods sine mange fordele har BERT også nogle udfordringer og begrænsninger. En af de største hindringer er den store beregningsmæssige indsats, der kræves for at træne og anvende modellen. Fordi BERT er en meget stor model med millioner af parametre, kræver den kraftig hardware og betydelige computerressourcer, især når man behandler store datasæt.
Et andet problem er den potentielle bias, der kan være til stede i træningsdataene. Fordi BERT er trænet på store mængder tekstdata, afspejler det nogle gange de fordomme og stereotyper, der findes i disse data. Forskere arbejder dog løbende på at identificere og adressere disse problemer.
🔍 Et uundværligt værktøj til moderne talebehandlingsapplikationer
BERT har forbedret den måde, maskiner forstår menneskeligt sprog på, betydeligt. Med sin tovejsarkitektur og innovative træningsmetoder er den i stand til at forstå konteksten af ord i en sætning dybt og præcist, hvilket fører til større præcision i mange NLP-opgaver. Uanset om det drejer sig om tekstklassificering, spørgsmålsbesvarelsessystemer eller entitetsgenkendelse, har BERT etableret sig som et uundværligt værktøj til moderne applikationer til behandling af naturligt sprog.
Forskningen inden for naturlig sprogbehandling vil utvivlsomt fortsætte med at udvikle sig, og BERT har lagt grundlaget for mange fremtidige innovationer. Trods de eksisterende udfordringer og begrænsninger demonstrerer BERT imponerende, hvor langt teknologien er kommet på kort tid, og hvilke spændende muligheder der stadig vil åbne sig i fremtiden.
🌀 Transformeren: En revolution inden for naturlig sprogbehandling
🌟 I de senere år har en af de mest betydningsfulde udviklinger inden for naturlig sprogbehandling (NLP) været introduktionen af Transformer-modellen, som beskrevet i artiklen "Attention Is All You Need" fra 2017. Denne model ændrede fundamentalt feltet ved at kassere de tidligere anvendte tilbagevendende eller konvolutionelle strukturer til sekvenstransduktionsopgaver, såsom maskinoversættelse. I stedet er den udelukkende afhængig af opmærksomhedsmekanismer. Transformer-designet har siden dannet grundlag for mange modeller, der repræsenterer den nyeste teknologi inden for forskellige områder, herunder talegenerering, oversættelse og mere.
🔄 Transformeren: Et paradigmeskift
Før introduktionen af Transformeren var de fleste modeller til sekvensopgaver baseret på tilbagevendende neurale netværk (RNN'er) eller lange korttidshukommelsesnetværk (LSTM), som i sagens natur fungerer sekventielt. Disse modeller behandler inputdata trin for trin og skaber skjulte tilstande, der udbredes langs sekvensen. Selvom denne metode er effektiv, er den beregningsmæssigt dyr og vanskelig at parallelisere, især for lange sekvenser. Desuden har RNN'er svært ved at lære langsigtede afhængigheder på grund af forsvindingsgradientproblemet.
Transformerens vigtigste innovation ligger i dens brug af selvopmærksomhedsmekanismer, som gør det muligt for modellen at afveje vigtigheden af forskellige ord i en sætning i forhold til hinanden, uanset deres placering. Dette gør det muligt for modellen at indfange relationer mellem vidt adskilte ord mere effektivt end RNN'er eller LSTM'er, og at gøre det parallelt snarere end sekventielt. Dette forbedrer ikke kun træningseffektiviteten, men også ydeevnen i opgaver som maskinoversættelse.
🧩 Modelarkitektur
Transformeren består af to hovedkomponenter: en encoder og en dekoder, som begge er opbygget af flere lag og i høj grad er afhængige af flerhovedopmærksomhedsmekanismer.
⚙️ Encoder
Encoderen består af seks identiske lag, hver med to underlag:
1. Selvopmærksomhed med flere hoveder
Denne mekanisme gør det muligt for modellen at fokusere på forskellige dele af inputsætningen, når den behandler hvert ord. I stedet for at beregne opmærksomhed i et enkelt rum, projicerer multi-head attention inputtet ind i flere forskellige rum og indfanger derved forskellige typer relationer mellem ord.
2. Positionsmæssigt fuldt forbundne feedforward-netværk
Efter opmærksomhedslaget anvendes et fuldt forbundet feedforward-netværk uafhængigt på hver position. Dette hjælper modellen med at bearbejde hvert ord i kontekst og udnytte informationen fra opmærksomhedsmekanismen.
For at bevare strukturen i inputsekvensen inkluderer modellen også positionskodninger. Da transformeren ikke behandler ordene sekventielt, er disse kodninger afgørende for at give modellen information om ordrækkefølgen i en sætning. Positionskodningerne tilføjes til ordindlejringerne, så modellen kan skelne mellem de forskellige positioner i sekvensen.
🔍 Dekoder
Ligesom encoderen består dekoderen også af seks lag, der hvert har en ekstra opmærksomhedsmekanisme, der gør det muligt for modellen at fokusere på relevante dele af inputsekvensen, mens outputtet genereres. Dekoderen bruger også en maskeringsteknik til at forhindre den i at overveje fremtidige positioner og dermed bevare sekvensgenereringens autoregressive karakter.
🧠 Flerhovedopmærksomhed og skalar produktopmærksomhed
Kernen i Transformer er multi-head attention-mekanismen, som er en udvidelse af den enklere skalære produkt-attention. Attention-funktionen kan ses som en kortlægning mellem en forespørgsel og et sæt nøgle-værdi-par, hvor hver nøgle repræsenterer et ord i sekvensen, og værdien repræsenterer den tilsvarende kontekstuelle information.
Multi-head-opmærksomhedsmekanismen gør det muligt for modellen at fokusere på forskellige dele af sekvensen samtidigt. Ved at projicere inputtet ind i flere underrum kan modellen indfange et rigere sæt af relationer mellem ord. Dette er især nyttigt til opgaver som maskinoversættelse, hvor forståelsen af et ords kontekst kræver mange forskellige faktorer, såsom syntaktisk struktur og semantisk betydning.
Formlen for skalær produktopmærksomhed er:
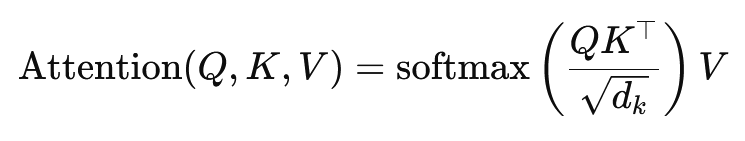
Her er (Q) forespørgselsmatricen, (K) nøglematricen og (V) værdimatricen. Termen (sqrt{d_k}) er en skaleringsfaktor, der forhindrer skalarprodukterne i at blive for store, hvilket ville føre til meget små gradienter og langsommere læring. Softmax-funktionen anvendes for at sikre, at opmærksomhedsvægtene summerer til én.
🚀 Fordele ved transformeren
Transformeren tilbyder adskillige afgørende fordele i forhold til traditionelle modeller som RNN'er og LSTM'er:
1. Parallelisering
Da transformeren behandler alle tokens i en sekvens samtidigt, kan den paralleliseres i høj grad og er derfor meget hurtigere at træne end RNN'er eller LSTM'er, især med store datasæt.
2. Langvarige afhængigheder
Selvopmærksomhedsmekanismen gør det muligt for modellen at indfange relationer mellem fjerne ord mere effektivt end RNN'er, som er begrænset af den sekventielle karakter af deres beregninger.
3. Skalerbarhed
Transformeren kan nemt skalere til meget store datasæt og længere sekvenser uden at lide af de ydeevneflaskehalse, der er forbundet med RNN'er.
🌍 Anvendelser og effekter
Siden introduktionen er Transformer blevet fundamentet for en bred vifte af NLP-modeller. Et af de mest bemærkelsesværdige eksempler er BERT (Bidirectional Encoder Representations from Transformers), som bruger en modificeret Transformer-arkitektur til at opnå den nyeste ydeevne i mange NLP-opgaver, herunder besvarelse af spørgsmål og tekstklassificering.
En anden væsentlig udvikling er GPT (Generative Pretrained Transformer), som bruger en dekoderbegrænset version af transformeren til tekstgenerering. GPT-modeller, herunder GPT-3, bruges nu til adskillige applikationer, fra indholdsoprettelse til kodefærdiggørelse.
🔍 En kraftfuld og fleksibel model
Transformeren har fundamentalt ændret den måde, vi griber NLP-opgaver an på. Den tilbyder en kraftfuld og fleksibel model, der kan anvendes på en bred vifte af problemer. Dens evne til at håndtere langvarige afhængigheder og dens effektivitet i træning har gjort den til den foretrukne arkitektoniske tilgang til mange af de mest moderne modeller. Efterhånden som forskningen skrider frem, vil vi sandsynligvis se yderligere forbedringer og tilpasninger af Transformeren, især inden for områder som billed- og talebehandling, hvor opmærksomhedsmekanismer viser lovende resultater.
Vi er her for dig - Rådgivning - Planlægning - Implementering - Projektledelse
☑️ Brancheekspert, her med sin egen Xpert.Digital branchehub med over 2.500 fagartikler

Konrad Wolfenstein
Jeg vil med glæde fungere som din personlige rådgiver.
Du kan kontakte mig ved at udfylde kontaktformularen nedenfor eller blot ringe til mig på +49 89 89 674 804 (München) .
Jeg glæder mig til vores fælles projekt.
Skriv til mig

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital er et knudepunkt for industrien med fokus på digitalisering, maskinteknik, logistik/intralogistik og solceller.
Med vores 360° forretningsudviklingsløsning understøtter vi anerkendte virksomheder fra nye forretninger til eftersalg.
Markedsinformation, smarketing, marketingautomatisering, indholdsudvikling, PR, postkampagner, personlige sociale medier og lead nurturing er en del af vores digitale værktøjer.
Du kan finde mere information på: www.xpert.digital - www.xpert.solar - www.xpert.plus
Hold kontakten

















