
Et forsøg på at forklare AI: Hvordan fungerer kunstig intelligens – hvordan trænes den?

Available in 27 languages 📢
Foretræk Xpert.Digital på GoogleⓘUdgivet den: 8. september 2024 / Opdateret den: 9. september 2024 – Forfatter: Konrad Wolfenstein

Et forsøg på at forklare AI: Hvordan fungerer kunstig intelligens, og hvordan trænes den? – Billede: Xpert.Digital
📊 Fra datainput til modelforudsigelse: AI-processen
Hvordan fungerer kunstig intelligens (AI)? 🤖
Funktionen af kunstig intelligens (AI) kan opdeles i flere klart definerede trin. Hvert af disse trin er afgørende for det endelige resultat, som AI'en leverer. Processen begynder med datainput og slutter med modelforudsigelse og eventuel feedback eller yderligere træningsrunder. Disse faser beskriver den proces, som næsten alle AI-modeller gennemgår, uanset om de er simple regelsæt eller meget komplekse neurale netværk.
1. Dataindtastning 📊
Fundamentet for enhver kunstig intelligens er de data, den arbejder med. Disse data kan eksistere i forskellige former, såsom billeder, tekst, lydfiler eller videoer. AI'en bruger disse rådata til at genkende mønstre og træffe beslutninger. Kvaliteten og mængden af data spiller en afgørende rolle her, da de i væsentlig grad påvirker, hvor godt eller dårligt modellen i sidste ende vil præstere.
Jo mere omfattende og præcise dataene er, desto bedre kan AI'en lære. For eksempel, når en AI trænes til billedbehandling, har den brug for en stor mængde billeddata for korrekt at identificere forskellige objekter. For sprogmodeller er det tekstdata, der hjælper AI'en med at forstå og generere menneskelig tale. Datainput er det første og et af de vigtigste trin, da kvaliteten af forudsigelser kun kan være så god som de underliggende data. Et berømt princip inden for datalogi beskriver dette med ordsproget "garbage in, garbage out" - dårlige data fører til dårlige resultater.
2. Dataforbehandling 🧹
Når dataene er indtastet, skal de forberedes, før de kan indføres i den egentlige model. Denne proces kaldes dataforbehandling. Målet her er at transformere dataene til et format, som modellen kan bearbejde optimalt.
Et almindeligt trin i forbehandling er datanormalisering. Det betyder at bringe dataene ind i et ensartet værdiområde, så de behandles ensartet af modellen. Et eksempel ville være at skalere alle pixelværdier i et billede til et område fra 0 til 1 i stedet for 0 til 255.
En anden vigtig del af forbehandling er funktionsudtrækning. Dette involverer udtrækning af specifikke funktioner fra rådataene, som er særligt relevante for modellen. I billedbehandling kan disse være kanter eller specifikke farvemønstre, mens relevante nøgleord eller sætningsstrukturer udtrækkes i tekstbehandling. Forbehandling er afgørende for at gøre AI'ens læringsproces mere effektiv og præcis.
3. Modellen 🧩
Modellen er kernen i enhver kunstig intelligens. Her analyseres og bearbejdes data baseret på algoritmer og matematiske beregninger. En model kan eksistere i forskellige former. En af de mest kendte modeller er det neurale netværk, som er baseret på den menneskelige hjernes funktion.
Neurale netværk består af flere lag af kunstige neuroner, der bearbejder og videregiver information. Hvert lag tager outputtet fra det foregående lag og bearbejder det videre. Læringsprocessen i et neuralt netværk involverer justering af vægtningen af forbindelserne mellem disse neuroner, så netværket kan foretage stadig mere præcise forudsigelser eller klassifikationer. Denne justering opnås gennem træning, hvor netværket tilgår store mængder eksempeldata og iterativt forbedrer sine interne parametre (vægte).
Udover neurale netværk anvendes mange andre algoritmer i AI-modeller. Disse omfatter beslutningstræer, tilfældige skove, supportvektormaskiner og mange flere. Hvilken algoritme der anvendes afhænger af den specifikke opgave og de tilgængelige data.
4. Modelprognosen 🔍
Når modellen er blevet trænet med data, er den i stand til at lave forudsigelser. Dette trin kaldes modelforudsigelse. AI'en modtager et input og returnerer, baseret på de mønstre, den har lært indtil videre, et output, det vil sige en forudsigelse eller beslutning.
Denne forudsigelse kan antage forskellige former. I en billedklassificeringsmodel kan AI'en for eksempel forudsige, hvilket objekt der vises på et billede. I en sprogmodel kan den forudsige, hvilket ord der kommer næste gang i en sætning. I finansielle forudsigelser kan AI'en forudsige, hvordan aktiemarkedet vil klare sig.
Det er vigtigt at understrege, at forudsigelsernes nøjagtighed i høj grad afhænger af kvaliteten af træningsdataene og modelarkitekturen. En model, der er trænet på utilstrækkelige eller forudindtagede data, vil med stor sandsynlighed lave forkerte forudsigelser.
5. Feedback og træning (valgfrit) ♻️
Et andet vigtigt aspekt af, hvordan en AI fungerer, er feedbackmekanismen. Her kontrolleres modellen regelmæssigt og optimeres yderligere. Denne proces finder sted enten under træning eller efter modellens forudsigelse.
Hvis modellen foretager forkerte forudsigelser, kan den gennem feedback lære at genkende disse fejl og justere sine interne parametre i overensstemmelse hermed. Dette gøres ved at sammenligne modellens forudsigelser med de faktiske resultater (f.eks. med kendte data, hvor de korrekte svar allerede findes). En typisk metode i denne sammenhæng er såkaldt superviseret læring, hvor AI'en lærer fra eksempeldata, der allerede indeholder de korrekte svar.
En almindelig feedbackmetode er backpropagation-algoritmen, der bruges i neurale netværk. Her forplantes de fejl, som modellen laver, bagud gennem netværket for at justere vægten af de neurale forbindelser. På denne måde lærer modellen af sine fejl og bliver mere og mere præcis i sine forudsigelser.
Træningens rolle 🏋️♂️
Træning af en AI er en iterativ proces. Jo flere data modellen ser, og jo oftere den trænes på disse data, desto mere præcise bliver dens forudsigelser. Der er dog begrænsninger: En overtrænet model kan udvikle såkaldte "overfitting"-problemer. Det betyder, at den husker træningsdataene så godt, at den leverer dårligere resultater på nye, ukendte data. Derfor er det vigtigt at træne modellen på en sådan måde, at den generaliserer, hvilket betyder, at den også kan lave gode forudsigelser på nye data.
Udover almindelig træning findes der også metoder som transfer learning. Her bruges en model, der allerede er trænet på et stort datasæt, til en ny, lignende opgave. Dette sparer tid og computerkraft, da modellen ikke behøver at trænes helt fra bunden.
Få mest muligt ud af dine styrker 🚀
Funktionen af kunstig intelligens (AI) er baseret på et komplekst samspil mellem forskellige trin. Fra datainput og forbehandling til modeltræning, forudsigelse og feedback påvirker mange faktorer AI's nøjagtighed og effektivitet. En veluddannet AI kan tilbyde enorme fordele på mange områder af livet – fra automatisering af simple opgaver til løsning af komplekse problemer. Det er dog lige så vigtigt at forstå begrænsningerne og potentielle faldgruber ved AI for at kunne udnytte dens styrker bedst muligt.
🤖📚 Enkelt forklaret: Hvordan trænes en AI?
🤖📊 AI-læringsproces: Optag, link og gem
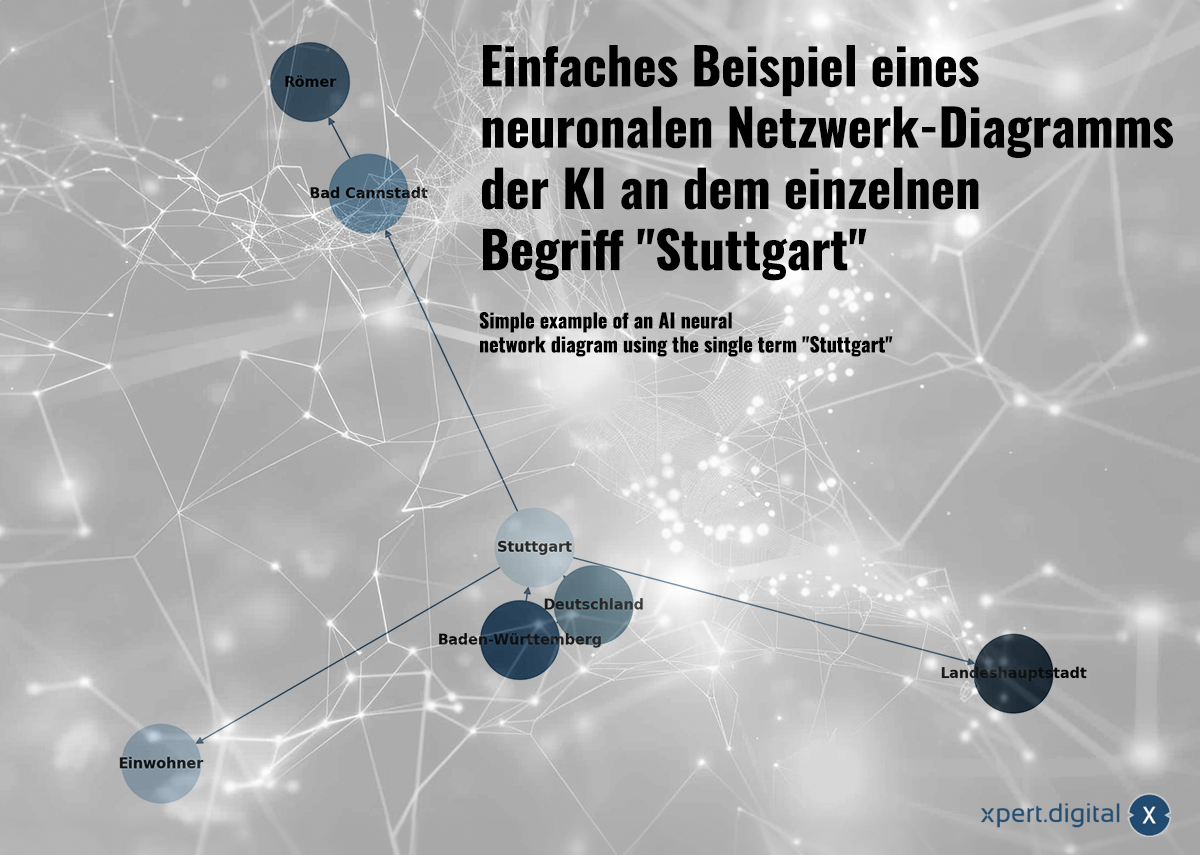
Simpelt eksempel på et AI-neuralt netværksdiagram, der bruger det enkelte udtryk "Stuttgart" – Billede: Xpert.Digital
🌟 Indsaml og forbered data
Det første trin i AI-læringsprocessen er at indsamle og forberede data. Disse data kan komme fra forskellige kilder, såsom databaser, sensorer, tekster eller billeder.
🌟 Relationsdata (Neuralt netværk)
De indsamlede data er forbundet i et neuralt netværk. Hver datapakke er repræsenteret af forbindelser i et netværk af "neuroner" (noder). Et simpelt eksempel med byen Stuttgart kunne se sådan ud:
a) Stuttgart er en by i Baden-Württemberg
b) Baden-Württemberg er en delstat i Tyskland
c) Stuttgart er en by i Tyskland
d) Stuttgart havde en befolkning på 633.484 i 2023
e) Bad Cannstatt er en bydel i Stuttgart
f) Bad Cannstatt blev grundlagt af romerne
g) Stuttgart er delstatshovedstaden i Baden-Württemberg
Afhængigt af datamængdens størrelse genereres parametrene for potentielle output ved hjælp af AI-modellen. For eksempel har GPT-3 cirka 175 milliarder parametre!
🌟 Lagring og tilpasning (læring)
Dataene føres ind i det neurale netværk. De passerer gennem AI-modellen og behandles via forbindelser (svarende til synapser). Vægtene (parametrene) mellem neuronerne justeres for at træne modellen eller for at udføre en opgave.
I modsætning til konventionelle lagringsmetoder som direkte adgang, indekseret adgang, sekventiel eller batchlagring, lagrer neurale netværk data på en ukonventionel måde. "Dataene" lagres i vægte og bias af forbindelserne mellem neuronerne.
Selve "lagringen" af information i et neuralt netværk sker gennem justering af forbindelsesvægtene mellem neuronerne. AI-modellen "lærer" ved løbende at justere disse vægte og bias baseret på inputdataene og en defineret læringsalgoritme. Dette er en kontinuerlig proces, hvor modellen kan lave mere præcise forudsigelser gennem gentagne justeringer.
AI-modellen kan ses som en slags programmering, da den skabes gennem definerede algoritmer og matematiske beregninger, og justeringen af dens parametre (vægte) forbedres løbende for at lave præcise forudsigelser. Dette er en løbende proces.
Biaser er yderligere parametre i neurale netværk, der lægges til en neurons vægtede inputværdier. De gør det muligt at vægte parametrene (vigtige, mindre vigtige osv.), hvilket gør AI'en mere fleksibel og præcis.
Neurale netværk kan ikke kun lagre individuelle fakta, men også genkende relationer mellem data gennem mønstergenkendelse. Eksemplet med Stuttgart illustrerer, hvordan viden kan føres ind i et neuralt netværk, men neurale netværk lærer ikke gennem eksplicit viden (som i dette simple eksempel), men snarere gennem analyse af datamønstre. Derfor kan neurale netværk ikke kun lagre individuelle fakta, men også lære vægte og relationer mellem inputdataene.
Denne proces giver en forståelig introduktion til, hvordan AI, og især neurale netværk, fungerer, uden at dykke for dybt ned i tekniske detaljer. Den demonstrerer, at information ikke lagres i neurale netværk som i konventionelle databaser, men snarere ved at justere forbindelserne (vægtene) i netværket.
🤖📚 Mere detaljeret: Hvordan trænes en AI?
🏋️♂️ Træning af en AI, især en maskinlæringsmodel, involverer flere trin. AI-træning er baseret på kontinuerlig optimering af modelparametre gennem feedback og justering, indtil modellen præsterer bedst muligt på de leverede data. Her er en detaljeret forklaring af, hvordan denne proces fungerer:
1. 📊 Indsaml og forbered data
Data er fundamentet for AI-træning. Det består typisk af tusindvis eller millioner af eksempler, som systemet er beregnet til at analysere. Eksempler omfatter billeder, tekst eller tidsseriedata.
Dataene skal renses og normaliseres for at undgå unødvendige fejlkilder. Ofte omdannes dataene til funktioner, der indeholder de relevante oplysninger.
2. 🔍 Definer model
En model er en matematisk funktion, der beskriver sammenhængene i dataene. I neurale netværk, som ofte bruges til AI, består modellen af flere lag af neuroner, der er forbundet med hinanden.
Hver neuron udfører en matematisk operation for at behandle inputdataene og sender derefter et signal til den næste neuron.
3. 🔄 Initialiser vægte
Forbindelserne mellem neuroner har vægte, der i starten er sat tilfældigt. Disse vægte bestemmer, hvor stærkt en neuron reagerer på et signal.
Målet med træningen er at justere disse vægte, så modellen laver bedre forudsigelser.
4. ➡️ Fremadrettet udbredelse
Under den fremadrettede passage behandles inputdataene af modellen for at opnå en forudsigelse.
Hvert lag bearbejder dataene og sender dem videre til det næste lag, indtil det sidste lag leverer resultatet.
5. ⚖️ Beregn tabsfunktionen
Tabsfunktionen måler, hvor godt modellens forudsigelser stemmer overens med de faktiske værdier (mærkningerne). Et almindeligt mål er fejlen mellem den forudsagte og den faktiske respons.
Jo højere tabet er, desto dårligere er modellens forudsigelse.
6. 🔙 Tilbagepropagering
Ved omvendt iteration spores fejlen tilbage fra modellens output til de foregående lag.
Fejlen omfordeles til forbindelsernes vægte, og modellen justerer vægtene, så fejlene bliver mindre.
Dette gøres ved hjælp af gradient descent: Gradientvektoren beregnes, som angiver, hvordan vægtene skal ændres for at minimere fejlen.
7. 🔧 Opdater vægte
Efter fejlen er beregnet, opdateres forbindelsernes vægte med en lille justering baseret på læringshastigheden.
Læringshastigheden bestemmer, hvor meget vægtene ændres i hvert trin. Ændringer, der er for store, kan gøre modellen ustabil, mens ændringer, der er for små, fører til en langsom læringsproces.
8. 🔁 Gentag (epoker)
Denne proces med fremadrettet gennemløb, fejlberegning og vægtopdatering gentages, ofte over flere epoker (passerer gennem hele datasættet), indtil modellen opnår acceptabel nøjagtighed.
Med hver æra lærer modellen lidt mere og justerer yderligere sine vægte.
9. 📉 Validering og testning
Efter modellen er blevet trænet, testes den på et valideret datasæt for at kontrollere, hvor godt den generaliserer. Dette sikrer, at den ikke kun har "gemt" træningsdataene, men også laver gode forudsigelser på ukendte data.
Testdata hjælper med at måle modellens endelige ydeevne, før den anvendes i praksis.
10. 🚀 Optimering
Yderligere trin til at forbedre modellen inkluderer hyperparameterjustering (f.eks. justering af læringshastigheden eller netværksstrukturen), regularisering (for at undgå overfitting) eller forøgelse af datamængden.
📊🔙 Kunstig intelligens: Gør den sorte boks inden for kunstig intelligens forståelig, forståelig og forklarlig med Explainable AI (XAI), heatmaps, surrogatmodeller eller andre løsninger

Kunstig intelligens: Gør den sorte boks af AI forståelig, forståelig og forklarlig med Explainable AI (XAI), heatmaps, surrogatmodeller eller andre løsninger – Billede: Xpert.Digital
Den såkaldte "sorte boks" inden for kunstig intelligens (AI) repræsenterer et betydeligt og presserende problem. Selv eksperter står ofte over for udfordringen med ikke fuldt ud at kunne forstå, hvordan AI-systemer træffer deres beslutninger. Denne mangel på gennemsigtighed kan forårsage betydelige problemer, især inden for kritiske områder som økonomi, politik og medicin. En læge, der er afhængig af et AI-system til diagnose og behandlingsanbefalinger, skal have tillid til de beslutninger, der træffes. Men hvis en AI's beslutningsproces ikke er tilstrækkelig gennemsigtig, opstår der usikkerhed, hvilket potentielt kan føre til manglende tillid – og dette i situationer, hvor menneskeliv kan være på spil.
Mere information her:
Vi er her for dig - Rådgivning - Planlægning - Implementering - Projektledelse
☑️ SMV-support inden for strategi, rådgivning, planlægning og implementering
☑️ Oprettelse eller omlægning af den digitale strategi og digitalisering
☑️ Udvidelse og optimering af internationale salgsprocesser
☑️ Globale og digitale B2B-handelsplatforme
☑️ Pioner inden for forretningsudvikling

Konrad Wolfenstein
Jeg vil med glæde fungere som din personlige rådgiver.
Du kan kontakte mig ved at udfylde kontaktformularen nedenfor eller blot ringe til mig på +49 89 89 674 804 (München) .
Jeg glæder mig til vores fælles projekt.
Skriv til mig

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital er et knudepunkt for industrien med fokus på digitalisering, maskinteknik, logistik/intralogistik og solceller.
Med vores 360° forretningsudviklingsløsning understøtter vi anerkendte virksomheder fra nye forretninger til eftersalg.
Markedsinformation, smarketing, marketingautomatisering, indholdsudvikling, PR, postkampagner, personlige sociale medier og lead nurturing er en del af vores digitale værktøjer.
Du kan finde mere information på: www.xpert.digital - www.xpert.solar - www.xpert.plus
Hold kontakten
















