
Strukturierte Daten (Markup) im KI-Zeitalter mit Schema.org: Was Googles Ingenieure wirklich denken
Xpert Pre-Release

Available in 27 languages 📢
Xpert.Digital bei Google bevorzugen ⓘVeröffentlicht am: 7. Mai 2026 / Update vom: 7. Mai 2026 – Verfasser: Konrad Wolfenstein
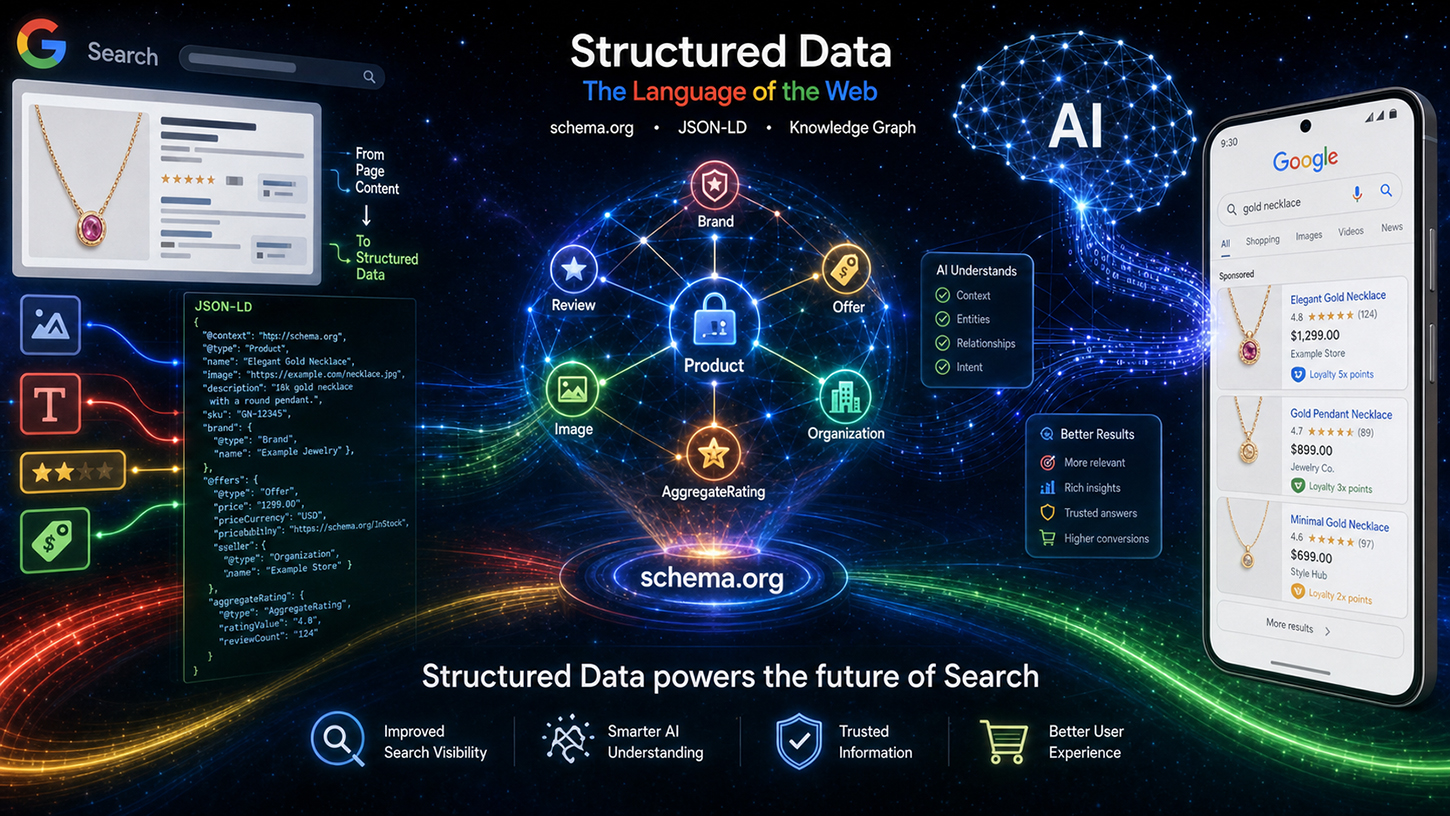
Strukturierte Daten (Markup) im KI-Zeitalter mit Schema.org: Was Googles Ingenieure wirklich denken – Bild: Xpert.Digital
Googles SEO-Geheimnis: Warum KI ohne strukturierte Daten scheitert
Trotz ChatGPT & Co.: Warum Google-Ingenieure weiterhin auf Schema.org schwören
SEO-Update: Darum verdrängt Schema.org bei Google jetzt Open Graph
In der SEO-Welt kursiert ein hartnäckiger Mythos: Im Zeitalter brillanter KI-Sprachmodelle, die selbst unstrukturierten Text problemlos verstehen, seien mühsam gepflegte strukturierte Daten wie Schema.org schlicht überflüssig geworden. Doch die Realität sieht völlig anders aus. Auf dem Google Search Central Live Event räumte Google-Ingenieur Ryan Levering mit diesem Irrglauben auf und machte unmissverständlich klar: Strukturiertes Markup ist kein Relikt aus der Vergangenheit, sondern das fundamentale Rückgrat der neuen KI-gestützten Suche.
Von den neuen AI Overviews bis hin zu autonomen Shopping-Agenten – Sprachmodelle brauchen präzise, maschinenlesbare Leitplanken, um nicht zu halluzinieren und recheneffizient zu arbeiten. Wer im modernen Web sichtbar bleiben will, muss den Maschinen helfen, Kontexte zweifelsfrei zu erfassen. Dieser Artikel beleuchtet Googles strategische Neuausrichtung, stellt revolutionäre Neuerungen für den E-Commerce sowie nutzergenerierte Inhalte vor und zeigt, warum technisches SEO heute der entscheidende Wettbewerbsvorteil im Kampf um die maschinelle Sichtbarkeit ist.
Maschinen lesen das Web – aber nur, wenn man ihnen beim Verstehen hilft
Am 21. April 2026 fand in Toronto das erste Google Search Central Live auf kanadischem Boden statt – und es war kein gewöhnliches Branchentreffen. Ryan Levering, Ingenieur beim Google Search Engineering, hielt dort den wohl technisch dichtesten und gleichzeitig strategisch bedeutsamsten Vortrag des Tages: „Structured Data, Quality & AI“. Was er präsentierte, war mehr als ein technischer Rückblick. Es war ein klares Statement über die Zukunft des semantischen Webs in einer Ära, in der künstliche Intelligenz zunehmend die Vermittlerrolle zwischen Nutzer und Information übernimmt.
Zwischen zwei Extremen: Das falsche Entweder-oder
Zu Beginn seiner Präsentation stellte Ryan Levering zwei diametral entgegengesetzte Meinungen gegenüber, die in der SEO-Community kursieren. Auf der einen Seite steht die Überzeugung, strukturierte Daten seien im Zeitalter leistungsfähiger Sprachmodelle schlicht überflüssig: Wenn KI-Modelle unstrukturierten Text problemlos interpretieren können, warum sollte man dann noch mühsam schema.org-Markup in den Quellcode einpflegen? Auf der anderen Seite propagieren manche Enthusiasten, strukturierte Daten seien die Zukunft des Internets schlechthin – ein universelles semantisches Kommunikationsprotokoll zwischen autonomen KI-Agenten, das das klassische Web weitgehend ablösen werde.
Levering lehnte beide Extreme ab und präsentierte stattdessen eine differenzierte, empirisch fundierte Perspektive. Beide Positionen enthielten einen wahren Kern, so sein Befund, aber keine von beiden beschreibe die Realität vollständig. Diese Nuancierung ist bezeichnend für Googles aktuellen Umgang mit dem Thema: Es geht nicht um Dogma, sondern um pragmatische Effizienz.
Vier Argumente, die alles erklären
Das zentrale Argument Leverings lässt sich in vier Kernpunkten zusammenfassen, die er unter dem Titel „Value of Structured Data“ ausführte. Der erste Punkt ist Präzision: Strukturierte Daten liefern für komplexe Schemata wie Verkaufspreise oder Treueprogramme eine deutlich höhere Genauigkeit als die LLM-basierte Extraktion aus Freitext. Sprachmodelle halluzinieren – sie ergänzen fehlende Eigenschaften, verschachteln Daten falsch oder greifen auf kontextfremde Informationen zurück. Beim Auslesen von Produktpreisen aus einer umfangreichen E-Commerce-Seite mit Dutzenden ähnlicher Artikel ist die Fehlerquote durch KI-Inferenz signifikant höher als bei sauber implementiertem, strukturiertem Markup.
Der zweite Punkt betrifft zusätzliche Inhalte: Strukturierte Daten enthalten häufig nicht sichtbare Metadaten, die im gerenderten HTML einer Seite schlicht nicht vorhanden sind. Vollständige ISO-Datumsformate, stabile Identifikatoren für User-Generated-Content oder interne Entitäts-IDs – diese Informationen existieren ausschließlich im Markup. Kein Sprachmodell kann extrahieren, was nicht im Text steht.
Drittens die Effizienz: Das Parsen von strukturiertem Markup ist um ein Vielfaches günstiger als das Durchlaufen eines großen Sprachmodells zur Extraktion komplexer Daten. Google indexiert täglich Milliarden von Seiten. Die Rechnung ist einfach: Ein regulärer Parser, der JSON-LD verarbeitet, verbraucht einen Bruchteil der Rechenressourcen eines LLM-Inferenzschritts. Strukturierte Daten sind also nicht nur semantisch überlegen – sie sind auch betriebswirtschaftlich erheblich effizienter. Dieser Punkt ist für Googles Infrastruktur von unmittelbarer Relevanz.
Der vierte und vielleicht am meisten unterschätzte Aspekt ist der Fokus: Strukturierte Daten heben explizit hervor, welche Informationen auf einer Seite relevant sind, und verhindern so, dass KI-Systeme kontextfremde Daten aufgreifen. Auf einer Produktseite mit einem Hauptartikel, mehreren verwandten Produkten und einer Navigationsleiste voller Preise weiß ein Sprachmodell ohne explizite Annotation nicht mit Sicherheit, auf welchen Preis es sich beziehen soll. Strukturiertes Markup löst dieses Problem durch eindeutige Zuweisung.
Wie strukturierte Daten tatsächlich verarbeitet werden
Levering machte auch den technischen Verarbeitungsfluss transparent. Schema.org-Daten werden zunächst durch spezifische Reinigung und Filterung verarbeitet, bevor sie als indexierte Daten kategorisiert werden – aufgeteilt in Bereiche wie Events, Shopping und Reviews. Diese aufbereiteten Daten fließen dann in zwei unterschiedliche Ausgabekanäle: einerseits in die klassische Suchergebnisseite (SRP), andererseits als Kontext für Googles KI-basierte Systeme, konkret die sogenannten AI Overviews (AIO) und den AI Mode (AIM). Strukturierte Daten sind damit kein reines Rich-Results-Instrument mehr, sondern direkte Eingabe für generative KI-Antworten. Dies ist eine fundamentale Verschiebung in der strategischen Bedeutung von schema.org-Markup.
🎯🎯🎯 Datengetriebener B2B-Industry-Hub als Quasi-Inhouse-Lösung

Die Quasi-Inhouse-Lösung: Wie Xpert.Digital operative Lücken in B2B-Marketing und Vertrieb schließt – Smart Content-Driven Business - Bild: Xpert.Digital
Xpert.Digital ist ein von Konrad Wolfenstein geführter, datengetriebener B2B-Industry-Hub. Das Unternehmen agiert als externe Quasi-Inhouse-Lösung für Industriepartner und schließt operative Lücken in Marketing, Content und Vertrieb – ohne zusätzlichen Ressourcenaufbau auf Kundenseite.
Mehr dazu hier:
Warum strukturierte Daten zur Infrastruktur für KI‑Agenten werden
Shopping im Fokus: Versand, Loyalität und Varianten
Einen erheblichen Teil der Präsentation nahmen Neuerungen im Bereich E-Commerce ein. Levering führte aus, dass unerwartete Versandinformationen nach Daten des Baymard Institute Platz zwei und drei unter den häufigsten Gründen für Warenkorbabbrüche belegen. Strukturiertes Markup für Versanddienste kann dieses Problem direkt adressieren: Händler können nun präzise Angaben zu Herkunfts- und Zielregionen, Maßen und Gewichten, Bestellwert-Schwellenwerten, Bearbeitungszeiten und Treueprogramm-Zugehörigkeit direkt im Code hinterlegen.
Das Versandzeit-Modell, das Google dabei verfolgt, gliedert sich in zwei Phasen: die Bearbeitungszeit (Handling Time), also die Zeitspanne vom Bestelleingang bis zur Übergabe an den Carrier, sowie die eigentliche Lieferzeit (Delivery Time). Beide Phasen können separat und mit hoher Granularität annotiert werden – bis hin zu Cutoff-Zeiten für die Bestellannahme und der Angabe, ob die Bearbeitung auch an Wochentagen erfolgt. Die zugehörigen JSON-LD-Beispiele zeigen, wie mit dem Typ `ShippingConditions` kostenloser Versand für bestimmte Länder (z. B. Frankreich und Deutschland) und Mindestbestellwerte (z. B. 50 Euro) kombiniert definiert werden können.
Besonders innovativ ist die Verknüpfung von Versanddiensten mit Treueprogrammen. Über die Eigenschaft `validForMemberTier` kann ein Versandservice explizit an ein Mitgliedschaftsprogramm und eine spezifische Stufe gebunden werden. So wird es möglich, Versandvorteile für Premium-Mitglieder direkt im Markup zu deklarieren – ein Feature, das bisher nur über das Google Merchant Center konfigurierbar war. Das zugehörige Treueprogramm selbst wird als `MemberProgram`-Objekt unter der `Organization`-Entität definiert, mit Tiers wie „Gold“ oder „Silver“ und zugehörigen Vorteilen wie Loyalitätspreisen oder Punktevergabe.
Treueprogramme als semantische Entitäten
Die Einführung von Treueprogramm-Markup ist ökonomisch bedeutsam. Organisationen können mehrere eigenständige Mitgliedsprogramme mit jeweils mehreren Stufen und differenzierten Vorteilen definieren – Punkte, Mitgliederpreise, Rückgabekonditionen, Versandboni. Diese Informationen erscheinen dann direkt in den Google-Suchergebnissen, wie Levering an realen Beispielen zeigte, unter anderem mit einem Sephora-Angebot, das einen Mitgliederrabatt von 30 Prozent direkt im Shopping-Snippet auswies. Die Cross-Page-ID-Verlinkung, also die Möglichkeit, auf Treueprogramm-Definitionen von anderen Seiten aus zu verweisen, ist laut Levering ein nächster geplanter Schritt unter dem Arbeitstitel „Blazing the path for cross-page @id linkage“. Das Ziel: stärkere organisatorische Referenzen zwischen Produktseiten und Unternehmensrichtlinien.
User-Generated Content: Das Problem der KI-Kennzeichnung
Ein weiteres wichtiges Thema war die Weiterentwicklung der Schema-Typen für nutzergenerierten Inhalt (UGC). Zwei Neuerungen sind hier besonders relevant. Erstens werden eingebettete Beiträge und Reposts in Forum- und Q&A-Markup unterstützt, was eine genauere semantische Abbildung von Diskussionsstrukturen ermöglicht. Zweitens – und dies ist von noch größerer strategischer Tragweite – wird die Eigenschaft `so#digitalSourceType` eingeführt, um maschinengenerierten Inhalt explizit auszuweisen.
Diese Entwicklung ist eine direkte Reaktion auf die Flut KI-generierter Inhalte auf Plattformen wie Foren und Q&A-Seiten. Webmaster können nun deklarieren, ob ein Beitrag algorithmisch oder durch ein Sprachmodell erzeugt wurde. Wer keine Angabe macht, dem unterstellt Google implizit menschliche Urheberschaft – eine Regelung, die Anreize zur transparenten Kennzeichnung setzt. Die `digitalSourceType`-Eigenschaft basiert auf den IPTC-Codes für digitale Quellen und unterscheidet unter anderem zwischen algorithmisch generiertem und modell-generiertem Inhalt.
Bildauswahl: Schema schlägt Open Graph
Ein weniger beachtetes, aber praktisch wirksames Update betrifft die Bildauswahllogik von Google. Das System wird intern konsolidiert, mit einer klaren Priorisierungshierarchie: An erster Stelle steht schema.org-Markup, konkret die Eigenschaften `primaryImageOfPage` und `mainEntity → image`. Erst danach folgt der `og:image`-Meta-Tag aus Open Graph. Diese Änderung bedeutet für Webseitenbetreiber, dass eine saubere schema.org-Implementierung des Hauptbildes direkten Einfluss auf die Darstellung in Google-Suchergebnissen und AI Overviews hat – ein konkreter, messbarer Vorteil.
Schema.org selbst bekommt Investitionen
Bemerkenswert ist auch Googles angekündigte Wiederinvestition in schema.org als offene Spezifikation. Drei konkrete Maßnahmen wurden genannt: die Veröffentlichung von Statistiken zur Nutzungshäufigkeit einzelner Schema-Terme (Prevalence-Daten, wie ein Folienbild zeigt, bereits für einzelne Terme wie `digitalSourceType` mit Angabe von ca. 10.000 Domains verfügbar), die Publikation von Googles eigenen Validierungsregeln in maschinenlesbaren Standardformaten wie SHACL oder ShEx sowie verbesserte Unterstützung für Reihenfolgen (Order). Dies ist insofern bedeutsam, als externe Entwickler damit eigene, auf Google-Standards basierte Validierungstools bauen könnten – unabhängig von den offiziellen Testing-Tools, die gelegentlich unter Last zusammenbrechen.
Validierung: Zwei Werkzeuge, ein Ziel
Levering stellte zwei Validierungswerkzeuge vor, die sich ergänzen, aber unterschiedliche Prüfkriterien anlegen. Das Rich Result Test Tool unter `search.google.com/test/rich-results` akzeptiert URLs oder reines JSON und prüft, ob das Markup für Google Search-Rich-Results geeignet ist – es orientiert sich also an Googles spezifischen Anforderungen, nicht am schema.org-Standard als solchem. Der `validator.schema.org` hingegen prüft, ob das Markup schema.org-konform ist, also dem offenen Vokabular entspricht, unabhängig davon, ob Google daraus Rich Results generiert. Für Webentwickler ergibt sich daraus eine klare Empfehlung: Beide Tools sollten genutzt werden, denn ein Markup kann schema-konform, aber nicht rich-result-fähig sein – und umgekehrt.
Die größere Perspektive: Strukturierte Daten als KI-Infrastruktur
In der Gesamtschau des Toronto-Events wird eine Verschiebung sichtbar, die weit über klassische SEO-Optimierung hinausgeht. Strukturierte Daten entwickeln sich von einem Instrument zur Erlangung von Rich Snippets zu einem fundamentalen Datenschicht-Standard für KI-Systeme. Googles AI Overviews und der AI Mode nutzen schema.org-Markup aktiv als Kontext für Antwortgenerierung und Entitätsverifizierung. Wer korrekte, vollständige und präzise strukturierte Daten implementiert, verbessert nicht nur seine Chancen auf visuelle Hervorhebungen in der Suche – er positioniert seine Inhalte als zuverlässige Primärquelle für KI-Antworten.
Die Erwähnung des Universal Commerce Protocol (UCP) und WebMCP in diesem Kontext ist kein Zufall. Beide agentenorientierten Kommunikationsstandards, die Google in frühen Versionen 2026 veröffentlicht hat, setzen voraus, dass Webseiten semantisch beschrieben sind. Schema.org bildet dabei die Grundlage. In einer Welt, in der KI-Agenten autonom im Web agieren, suchen, vergleichen und Transaktionen initiieren, ist die Maschinenlesbarkeit von Inhalten keine Kür mehr, sondern eine Voraussetzung für wirtschaftliche Relevanz. Ryan Leverings Vortrag in Toronto war damit nicht nur ein technischer Update-Report – er war ein Fingerzeig auf die Infrastruktur des nächsten Webs.
So kannst du es in 10 Sekunden selbst herausfinden
Wenn du wissen willst, wie gut und umfassend deine oder eine andere Website strukturierte Daten nutzt, kannst du genau die beiden Tools verwenden, die Ryan Levering von Google (aus unserem Text oben) empfohlen hat:
Google Rich Results Test (Fokus auf Google-Sichtbarkeit):
Gehe auf search.google.com/test/rich-results, kopiere die URL eines beliebigen Fachartikels von xpert.digital hinein und drücke auf „URL testen“. Das Tool zeigt dir genau an, welche Markups Google auf dieser Seite erkennt und ob sie fehlerfrei sind.
Schema Validator (Fokus auf reine Standard-Konformität):
Gehe auf validator.schema.org, füge dieselbe URL ein. Hier siehst du direkt im Quellcode farblich markiert, welche JSON-LD-Scripte (strukturierte Daten) xpert.digital eingebaut hat.
Ihr globaler Marketing und Business Development Partner
☑️ Unsere Geschäftssprache ist Englisch oder Deutsch
☑️ NEU: Schriftverkehr in Ihrer Landessprache!

Konrad Wolfenstein
Gerne stehe ich Ihnen und mein Team als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie hier das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 7348 4088 965 an. Meine E-Mail Adresse lautet: wolfenstein∂xpert.digital
Ich freue mich auf unser gemeinsames Projekt.
☑️ KMU Support in der Strategie, Beratung, Planung und Umsetzung
☑️ Erstellung oder Neuausrichtung der Digitalstrategie und Digitalisierung
☑️ Ausbau und Optimierung der internationalen Vertriebsprozesse
☑️ Globale & Digitale B2B-Handelsplattformen
☑️ Pioneer Business Development / Marketing / PR / Messen
B2B Support und SaaS für SEO und GEO (KI-Suche) vereint: Die All-in-One-Lösung, für B2B-Unternehmen

B2B Support und SaaS für SEO und GEO (KI-Suche) vereint: Die All-in-One-Lösung, für B2B-Unternehmen - Bild: Xpert.Digital
KI-Suche verändert alles: Wie diese SaaS-Lösung Ihr B2B-Ranking für immer revolutioniert.
Die digitale Landschaft für B2B-Unternehmen befindet sich in einem rasanten Wandel. Angetrieben durch Künstliche Intelligenz werden die Spielregeln der Online-Sichtbarkeit neu geschrieben. Für Unternehmen war es schon immer eine Herausforderung, in der digitalen Masse nicht nur sichtbar, sondern auch für die richtigen Entscheidungsträger relevant zu sein. Klassische SEO-Strategien und das Management der lokalen Präsenz (GEO-Marketing) sind komplex, zeitaufwendig und oft ein Kampf gegen sich ständig ändernde Algorithmen und einen intensiven Wettbewerb.
Doch was wäre, wenn es eine Lösung gäbe, die diesen Prozess nicht nur vereinfacht, sondern ihn intelligenter, prädiktiver und weitaus effektiver macht? Hier kommt die Verknüpfung von spezialisiertem B2B-Support mit einer leistungsstarken SaaS-Plattform (Software as a Service) ins Spiel, die speziell für die Anforderungen von SEO und GEO im Zeitalter der KI-Suche entwickelt wurde.
Diese neue Generation von Tools verlässt sich nicht mehr nur auf manuelle Keyword-Analysen und Backlink-Strategien. Stattdessen nutzt sie künstliche Intelligenz, um Suchintentionen präziser zu verstehen, lokale Ranking-Faktoren automatisiert zu optimieren und Wettbewerbsanalysen in Echtzeit durchzuführen. Das Ergebnis ist eine proaktive, datengesteuerte Strategie, die B2B-Unternehmen einen entscheidenden Vorteil verschafft: Sie werden nicht nur gefunden, sondern als die maßgebliche Autorität in ihrer Nische und an ihrem Standort wahrgenommen.
Hier die Symbiose aus B2B-Support und KI-gestützter SaaS-Technologie, das SEO- und GEO-Marketing transformiert und wie Ihr Unternehmen davon profitieren kann, um nachhaltig im digitalen Raum zu wachsen.
Mehr dazu hier:
















