
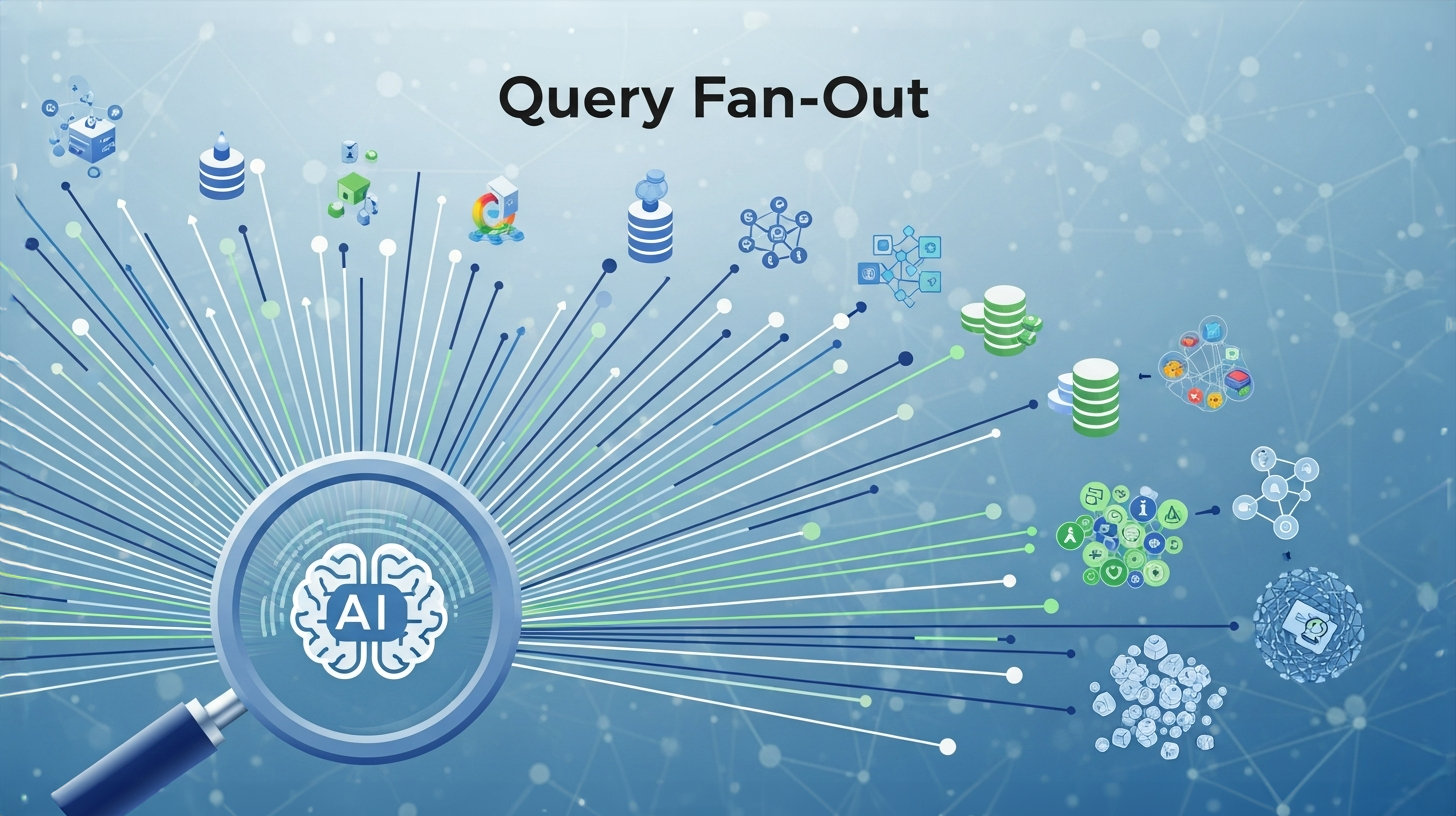
Query Fan-Out: Uma explicação abrangente desta técnica transformadora de busca por IA – Imagem: Xpert.Digital
A patente do Google que muda tudo: o que a 'Busca Temática' revela sobre o futuro do SEO
A nova arma secreta do Google: por que o Query Fan-Out revoluciona sua estratégia de SEO
A era das buscas simples por palavras-chave e dos dez links azuis está chegando ao fim. No centro dessa evolução está uma técnica revolucionária chamada "query fan-out", que está silenciosamente mudando o funcionamento de mecanismos de busca como o Google. Em vez de tratar uma consulta de busca como uma tarefa única e isolada, essa abordagem desdobra sistematicamente a consulta do usuário em uma rede completa de subconsultas relacionadas. O objetivo é entender não apenas o que você está perguntando explicitamente, mas também o que você implicitamente deseja saber, para antecipar perguntas subsequentes e sintetizar uma resposta abrangente diretamente na interface de busca.
Essa mudança de paradigma, impulsionada por modelos de IA como o Gemini do Google, é mais do que uma simples inovação tecnológica — ela redefine as regras do jogo para otimização de mecanismos de busca (SEO), criação de conteúdo e todo o processo de coleta de informações digitais. Para criadores de conteúdo e profissionais de marketing, isso significa mudar o foco de palavras-chave individuais para agrupamentos de tópicos abrangentes e criar conteúdo que atenda a diversas intenções do usuário simultaneamente. Neste artigo completo, exploramos a fundo o mundo do Query Fan-Out. Explicamos sua funcionalidade técnica, a diferença fundamental em relação à busca tradicional, seu papel crucial nas estratégias de conteúdo e como você pode otimizar seu conteúdo hoje para o futuro das buscas.
O que é Query Fan-Out?
O termo "fan-out" refere-se a um método sofisticado de recuperação de informações no qual uma única consulta de pesquisa do usuário é sistematicamente dividida em várias subconsultas relacionadas. Essa técnica é usada principalmente por sistemas de busca modernos com inteligência artificial, como o Google AI Mode, o ChatGPT e outros grandes modelos de linguagem. O termo "fan-out" tem origem na eletrônica e na ciência da computação e descreve a distribuição de um sinal ou fluxo de dados de uma fonte para múltiplos destinos.
No contexto de otimização de mecanismos de busca e inteligência artificial, o termo "query fan-out" significa que o sistema não apenas busca a formulação exata da consulta do usuário, mas também a analisa semanticamente, decompondo-a em seus componentes e gerando simultaneamente diversas consultas de busca tematicamente relacionadas. Essas subconsultas são então executadas simultaneamente em diferentes fontes de dados para possibilitar uma resposta mais abrangente e rica em contexto.
O método baseia-se na compreensão de que os usuários frequentemente não formulam com precisão o que realmente procuram, ou que sua consulta contém diversas necessidades de informação implícitas. O Query Fan-Out busca reconhecer essas intenções ocultas e abordá-las proativamente antes mesmo que o usuário precise fazer perguntas adicionais.
Como funciona tecnicamente o Query Fan-Out?
A implementação técnica do Query Fan-Out ocorre em várias etapas sucessivas, exigindo uma interação complexa de diversos componentes de IA.
O processo começa com a análise da consulta de pesquisa original. Um Modelo de Linguagem Amplo como o Gemini primeiro interpreta a entrada do usuário e identifica a intenção principal e o contexto semântico. Isso envolve a captura de características linguísticas, entidades e a intenção subjacente do usuário. Essa fase é chamada de decomposição da consulta e forma a base para todas as etapas subsequentes.
A expansão propriamente dita da consulta ocorre então. O sistema gera entre cinco e quinze subconsultas relacionadas que abrangem diferentes facetas da necessidade de informação original. Essas consultas sintéticas são criadas de acordo com padrões estruturados com base na diversidade de intenções, variação lexical e reformulações baseadas em entidades. Por exemplo, se um usuário pesquisar por "melhores fones de ouvido Bluetooth", o sistema poderá gerar simultaneamente consultas como "melhores fones de ouvido Bluetooth supra-auriculares", "fones de ouvido Bluetooth mais confortáveis por menos de € 200", "fones de ouvido Bluetooth para esportes" e "fones de ouvido Bluetooth com cancelamento de ruído versus fones de ouvido Bluetooth comuns".
As subconsultas geradas são então executadas em paralelo em diversas fontes de dados. Isso inclui o índice da web em tempo real, o Knowledge Graph, bancos de dados especializados como o Google Shopping Graph e outros índices de pesquisa vertical. Esse processamento paralelo é um elemento central da arquitetura de ramificação e permite que o sistema reúna uma ampla base de informações em um curto período de tempo.
Na etapa seguinte, os resultados coletados são analisados e avaliados. O sistema utiliza o sistema de classificação e os indicadores de qualidade do Google para avaliar a relevância e a confiabilidade de cada informação encontrada. Isso envolve não apenas a análise de páginas da web inteiras, mas também a avaliação de trechos de texto individuais para verificar sua adequação à resposta a perguntas específicas.
Finalmente, todas as informações coletadas são sintetizadas em uma resposta coerente. Um modelo de linguagem generativo combina as informações mais relevantes das diversas fontes e cria uma resposta abrangente e rica em contexto para a consulta original. Essa resposta considera aspectos explícitos e implícitos da intenção do usuário e, frequentemente, fornece informações adicionais que o usuário poderá precisar em seguida.
Que tipos de variantes de consulta são geradas?
A técnica de ramificação de consultas gera sistematicamente diferentes tipos de subconsultas para abranger diferentes aspectos da necessidade de informação.
As expansões semânticas formam uma primeira categoria e incluem sinônimos, bem como formulações alternativas da consulta original. Se alguém pesquisar por "veículo motorizado", o sistema também considerará variantes como "carro", "carro de passageiros" ou "veículo".
As variantes baseadas em intenção focam em diferentes intenções do usuário. Isso inclui consultas comparativas, que comparam diferentes opções; consultas exploratórias, que aprofundam a compreensão básica de um tópico; e consultas orientadas à decisão, que visam auxiliar em decisões de compra específicas. Uma consulta original como "Python Threading" poderia gerar tanto consultas tutoriais para um contexto de programação quanto consultas biológicas sobre o comportamento de cobras.
Consultas conversacionais e de acompanhamento formam outra categoria importante. O sistema antecipa quais perguntas de acompanhamento o usuário provavelmente fará e integra proativamente as respostas à resposta inicial. Isso cria uma experiência de busca semelhante a um diálogo, onde o usuário não precisa enviar várias consultas consecutivas.
Reformulações baseadas em entidades focam em marcas, produtos, locais ou pessoas específicas que possam ser relevantes no contexto da consulta original. Se alguém pesquisar por "software de gerenciamento de projetos", entidades específicas como "Asana", "Trello" ou "Monday.com" serão incluídas na subconsulta.
As variações regionais e contextuais levam em consideração características geográficas e aspectos temporais. Uma busca por "restaurantes perto de mim" às 11h45 em um dia de semana priorizaria especificamente opções para almoço, enquanto a mesma busca à noite destacaria opções para jantar.
Como o fan-out de consultas difere da busca tradicional?
A diferença entre o Query Fan-out e a otimização tradicional para mecanismos de busca é fundamental e altera a forma como o conteúdo deve ser criado e otimizado.
Os mecanismos de busca tradicionais operam com base no princípio da correspondência direta de palavras-chave. Uma consulta de busca é tratada como uma consulta única e isolada, e o sistema procura páginas da web que contenham esses termos exatos ou variações próximas deles. Os resultados são apresentados como uma lista hierarquizada de links, nos quais o usuário deve clicar um após o outro para encontrar a informação desejada.
Por outro lado, o Query Fan-Out expande uma única consulta em uma rede de consultas de pesquisa relacionadas. Em vez de procurar correspondências exatas, o sistema analisa o significado semântico e o contexto da consulta. Ele tenta compreender a intenção subjacente e considera várias interpretações possíveis simultaneamente.
A forma como os resultados são apresentados também difere fundamentalmente. Enquanto a busca tradicional exibe uma lista de links azuis, um sistema de ramificação de consultas apresenta uma resposta sintetizada e conversacional diretamente na interface de busca. Essa resposta combina informações de múltiplas fontes e é estruturada para atender de forma abrangente às necessidades de informação do usuário, sem exigir que ele visite diversos sites.
Outra diferença fundamental reside no tratamento da intenção. A busca tradicional concentra-se em palavras-chave explícitas e só consegue captar a intenção implícita de forma limitada. A ramificação de consultas, por outro lado, considera tanto a intenção explícita quanto a implícita do usuário e pode antecipar perguntas subsequentes antes mesmo de serem feitas.
A personalização atinge uma nova dimensão com o Query Fan-Out. Enquanto a busca tradicional se baseia principalmente no histórico de buscas, o Query Fan-Out integra um contexto abrangente, como localização, tarefas atuais na agenda, padrões de comunicação e tipo de dispositivo. Uma busca por "tomilho" apresentaria resultados diferentes para um usuário que está cozinhando no momento do que para alguém interessado em botânica.
Qual o papel do fan-out de consultas em sistemas RAG?
O desdobramento de consultas é parte integrante dos modernos sistemas de geração aumentada por recuperação e funciona como um mecanismo de recuperação altamente sofisticado.
Os sistemas RAG combinam os pontos fortes da recuperação de informação e da IA generativa. Em vez de dependerem exclusivamente do conhecimento pré-treinado de um modelo de linguagem, eles o ampliam por meio do acesso em tempo real a fontes de dados externas. Isso reduz o problema da alucinação, em que os sistemas de IA geram informações que soam plausíveis, mas são factualmente incorretas.
Nesse contexto, o desdobramento de consultas funciona como um processo de recuperação em múltiplos estágios. Em vez de uma única consulta simples, na qual o sistema busca documentos que correspondam à consulta original, o desdobramento executa um processo de coleta de informações paralelo e em múltiplas camadas. Ao decompor a consulta, o sistema identifica todas as diferentes facetas de informação necessárias e, em seguida, coleta um conjunto significativamente mais rico e diversificado de documentos contextuais e pontos de dados.
Essa base de contexto expandida é então passada para o componente generativo do sistema RAG. O modelo de linguagem recebe não apenas informações sobre a consulta original, mas também um contexto multifacetado pré-processado que abrange várias perspectivas e aspectos do tópico. Isso melhora drasticamente a qualidade, a precisão e a completude da resposta final.
A abordagem de ramificação também permite que os sistemas RAG respondam a consultas complexas e multifacetadas que antes não tinham respostas claras online. Ao combinar múltiplas fontes de informação, é possível chegar a novas conclusões que vão além das fontes individuais.
Outra vantagem reside na melhoria da atualidade. Enquanto o conhecimento pré-treinado de um modelo de linguagem está fixo a um ponto específico no tempo, a combinação com o desdobramento de consultas permite o acesso a informações atuais da web em tempo real, grafos de conhecimento e bancos de dados especializados.
Qual a importância da patente do Google sobre Busca Temática?
A patente registrada pelo Google em dezembro de 2024, intitulada "Busca Temática", fornece informações importantes sobre a implementação técnica da técnica de ramificação de consultas.
A patente descreve um sistema de busca temática que organiza os resultados de busca relacionados a uma consulta em categorias chamadas temas. Um breve resumo é gerado para cada um desses temas, permitindo que os usuários compreendam as respostas às suas perguntas sem precisar clicar em links para diversos sites.
A identificação automática de tópicos a partir de resultados de busca tradicionais, utilizando inteligência artificial, é particularmente inovadora. O sistema gera resumos informativos para cada tópico, considerando tanto o conteúdo quanto o contexto dos resultados da busca.
Um aspecto fundamental da patente é a geração de subconsultas. Uma única consulta do usuário pode desencadear múltiplas consultas de pesquisa com base em subtópicos específicos da consulta original. Por exemplo, se alguém pesquisar por "morar na cidade X", o sistema poderá gerar automaticamente subtópicos como "bairro A", "bairro B", "bairro C", "custo de vida", "atividades de lazer" e "vantagens e desvantagens".
A patente também descreve um processo iterativo. A seleção de um subtópico pode fazer com que o sistema recupere outro conjunto de resultados de pesquisa e gere tópicos ainda mais específicos. Isso permite uma exploração gradual de aspectos cada vez mais específicos de um assunto.
Os paralelos com a descrição oficial do Google da técnica Query Fan-Out são impressionantes. Ambas as abordagens envolvem a execução simultânea de múltiplas consultas de pesquisa relacionadas em diferentes subtópicos e fontes de dados, seguida da síntese dos resultados em uma resposta facilmente compreensível.
A patente também demonstra como a apresentação dos resultados de busca muda fundamentalmente. Em vez de exibir links ordenados de acordo com os fatores de classificação tradicionais, os resultados são agrupados por temas. Isso significa que um site que não esteja em primeiro lugar na busca original ainda pode ser exibido com destaque se contribuir para um subtema relevante.
Suporte B2B e SaaS para SEO e GEO (busca com IA) combinados: a solução completa para empresas B2B


Suporte B2B e SaaS para SEO e GEO (busca com IA) combinados: a solução completa para empresas B2B - Imagem: Xpert.Digital
A busca por IA muda tudo: como essa solução SaaS revolucionará para sempre seu posicionamento B2B.
O cenário digital para empresas B2B está passando por rápidas transformações. Impulsionadas pela inteligência artificial, as regras da visibilidade online estão sendo reescritas. Para as empresas, sempre foi um desafio não apenas se destacar na massa digital, mas também ser relevante para os tomadores de decisão certos. As estratégias tradicionais de SEO e o gerenciamento da presença local (geomarketing) são complexos, demorados e, muitas vezes, uma batalha contra algoritmos em constante mudança e uma concorrência acirrada.
Mas e se houvesse uma solução que não apenas simplificasse esse processo, mas também o tornasse mais inteligente, preditivo e muito mais eficaz? É aqui que entra em cena a combinação de suporte B2B especializado com uma poderosa plataforma SaaS (Software como Serviço), projetada especificamente para as demandas de SEO e GEO na era da busca por IA.
Essa nova geração de ferramentas não depende mais exclusivamente da análise manual de palavras-chave e estratégias de backlinks. Em vez disso, utiliza inteligência artificial para compreender com mais precisão a intenção de busca, otimizar automaticamente os fatores de ranqueamento local e realizar análises competitivas em tempo real. O resultado é uma estratégia proativa e orientada por dados que proporciona às empresas B2B uma vantagem decisiva: elas não apenas são encontradas, mas também percebidas como a principal autoridade em seu nicho e região.
Eis a simbiose entre o suporte B2B e a tecnologia SaaS com inteligência artificial que transforma o SEO e o marketing geográfico, e como sua empresa pode se beneficiar disso para crescer de forma sustentável no espaço digital.
Mais informações aqui:
Explicação sobre o conceito de "Query Fan-Out": Por que sua estratégia de conteúdo agora precisa de tópicos em vez de palavras-chave?
Como o Query Fan-Out influencia a estratégia de conteúdo?
O impacto da ramificação de consultas nas estratégias de conteúdo é profundo e exige uma reformulação da abordagem de otimização para mecanismos de busca.
A mudança de paradigma mais significativa envolve a transição do foco de palavras-chave individuais para agrupamentos de tópicos. Enquanto o SEO tradicional se concentrava em ranquear para palavras-chave específicas, os criadores de conteúdo agora precisam abordar áreas temáticas inteiras de forma abrangente. Um único artigo não deve apenas responder à pergunta principal, mas também antecipar possíveis perguntas subsequentes e aspectos relacionados.
A importância das páginas pilar e dos agrupamentos de tópicos está aumentando significativamente. Uma página pilar aborda de forma abrangente um tópico central, enquanto o conteúdo de um agrupamento de tópicos se aprofunda em subtópicos específicos. Essa estrutura reflete naturalmente a forma como o desdobramento de consultas organiza e recupera informações.
O conteúdo agora deve abordar consultas com múltiplas intenções. Em vez de otimizar para uma única intenção do usuário, o conteúdo deve abordar várias intenções simultaneamente. Por exemplo, um artigo sobre "software de gerenciamento de projetos" deve abordar comparações, estruturas de preços, opções de integração, adoção pelo usuário e casos de uso para diferentes tamanhos de equipe.
A estruturação de conteúdo está se tornando cada vez mais importante. Títulos claros, seções de perguntas frequentes, tabelas e marcadores ajudam os sistemas de IA a extrair informações específicas rapidamente. O conteúdo deve ser organizado de forma que cada seção possa servir como resposta completa a perguntas específicas.
Entidades e seus relacionamentos estão se tornando cada vez mais importantes. O conteúdo deve nomear claramente as entidades relevantes e declarar explicitamente seus relacionamentos. Isso ajuda os sistemas de IA a localizar corretamente o conteúdo dentro do grafo de conhecimento e a considerá-lo para subconsultas relevantes.
A profundidade da abordagem do tema está se tornando mais importante do que a densidade de palavras-chave. O foco deve ser responder ao máximo de perguntas possíveis sobre um tópico, e não repetir frequentemente uma palavra-chave específica. Conteúdo abrangente e bem pesquisado, que explore um tópico sob diversas perspectivas, é o ideal.
Isso representa um desafio particular para os profissionais de marketing B2B. Como as decisões de compra geralmente envolvem várias partes interessadas com prioridades diferentes, o conteúdo deve abordar as questões de vários tomadores de decisão simultaneamente. Um diretor financeiro está interessado em estruturas de preços, o departamento de TI em integrações e os executivos em aspectos de retorno sobre o investimento (ROI).
Qual o papel dos dados estruturados e da marcação de esquema?
Dados estruturados e marcação de esquema desempenham um papel central na otimização em um ambiente de ramificação de consultas.
A marcação de esquema funciona como um código que identifica e categoriza o conteúdo para sistemas de IA. Enquanto os humanos conseguem ler um texto e compreender seu significado, os sistemas de IA precisam de pistas explícitas para distinguir entre diferentes tipos de informação. Se uma avaliação de produto for marcada com esquema, o sistema de IA entenderá que "isto é uma avaliação", em vez de um texto genérico.
O formato de FAQ é particularmente valioso para o desdobramento de consultas, pois estrutura as perguntas frequentes e suas respostas. Estudos mostram que o formato de FAQ aparece em 73% das respostas geradas por IA, pois corresponde precisamente à forma como os sistemas de IA lidam com consultas de múltiplas intenções. Esse formato permite que os sistemas de IA identifiquem rapidamente pares de perguntas e respostas relevantes e os integrem em respostas sintetizadas.
Um esquema de instruções passo a passo é ideal para consultas de pesquisa orientadas a processos. Esse esquema deve incluir descrições claras das etapas, tempos estimados de processamento, ferramentas necessárias e resultados esperados.
Um esquema de produto identifica as especificações, preços e avaliações do produto, e ajuda os sistemas de IA a extrair detalhes para consultas de comparação. Todos os atributos relevantes do produto devem ser incluídos – características, dimensões, compatibilidade e faixas de preço.
O esquema organizacional identifica detalhes comerciais e áreas de especialização, além de construir sinais de autoridade que os sistemas de IA utilizam para avaliar a credibilidade da fonte. Ele deve especificar áreas de especialização, informações de contato e foco no setor.
O esquema de avaliação destaca o feedback dos clientes, que as plataformas de IA priorizam por preferirem fontes com comprovação social verificada. O esquema de artigo ajuda os sistemas de IA a entender o tipo de conteúdo, a data de publicação e a especialização do autor.
Para obter o máximo impacto, vários tipos de esquemas podem ser combinados em páginas relevantes. As páginas de produtos, por exemplo, podem conter simultaneamente esquemas de Produto, Avaliação e Organização para fornecer informações abrangentes que os sistemas de IA podem consultar.
Estudos mostram que 61% das páginas citadas pelo ChatGPT utilizam marcação de esquema. Isso reforça a importância dos dados estruturados para a visibilidade em sistemas de busca baseados em IA.
Como posso otimizar para o desdobramento de consultas?
A otimização para ramificação de consultas requer uma abordagem holística que combine elementos técnicos, relacionados ao conteúdo e estratégicos.
A cobertura abrangente do tema é fundamental. O conteúdo não deve apenas abordar um tópico superficialmente, mas sim aprofundá-lo e explorar suas diversas facetas. Isso significa criar páginas principais que abordem um tópico central de forma completa, complementadas por conteúdo complementar que detalhe subaspectos específicos.
As seções de perguntas frequentes (FAQ) devem ser usadas estrategicamente para abordar dúvidas e subconsultas relacionadas. Elas não devem ser arbitrárias, mas sim antecipar sistematicamente possíveis perguntas subsequentes que um usuário possa ter. Cada combinação de pergunta e resposta deve fornecer informações completas e autossuficientes que os sistemas de IA possam extrair e citar facilmente.
É necessário construir uma infraestrutura semântica. O conteúdo deve ser otimizado para significado, contexto e intenção, e não apenas para palavras-chave. Isso significa explorar subtópicos, responder a perguntas relacionadas e tornar a cobertura geral o mais abrangente possível.
Uma estrutura de conteúdo clara é essencial. O uso de títulos claros (H2, H3), marcadores para listas, parágrafos curtos e tabelas para comparações facilita a análise de informações por sistemas de IA. O conteúdo deve ser organizado de forma que as ferramentas de IA possam encontrar respostas específicas rapidamente.
A definição de entidades e o mapeamento de relacionamentos ajudam os sistemas de IA a compreender e localizar conteúdo corretamente. As entidades relevantes devem ser claramente nomeadas e seus relacionamentos entre si devem ser explicitados. Isso permite que os sistemas de IA considerem o conteúdo em diversas subconsultas relacionadas.
Apresentar as respostas de forma clara e objetiva é fundamental. As informações mais relevantes devem vir no início, sem longas introduções ou detalhes irrelevantes. Uma abordagem direta como: "Para renovar seu passaporte, você precisará do formulário DS-82 preenchido, uma foto recente e o pagamento. Veja o processo completo aqui:" vai direto ao ponto.
Implementar uma estrutura de marcação abrangente em todo o site não é opcional, mas sim uma necessidade estratégica. Isso inclui um esquema de FAQ para perguntas frequentes, um esquema de instruções, um esquema de produto para informações sobre o produto e um esquema de organização para detalhes da empresa.
A otimização em nível de cluster deve ser o foco. Em vez de segmentar palavras-chave individuais, deve-se abordar grupos de palavras-chave mais amplos e tópicos abrangentes. Isso cria uma base de conteúdo mais sólida, menos suscetível a alterações em palavras-chave individuais e à variabilidade de ramificações.
Evitar a canibalização de conteúdo é crucial. À medida que mais conteúdo é criado, é essencial garantir que as páginas não estejam competindo pelas mesmas palavras-chave. Isso confunde os mecanismos de busca e dilui a autoridade.
Quais são os desafios apresentados pela ramificação de consultas?
A ramificação de consultas apresenta desafios significativos tanto para os criadores de conteúdo quanto para as implementações técnicas.
A natureza não determinística das consultas ramificadas é um desafio crucial. As subconsultas geradas podem variar, mesmo para a mesma consulta no mesmo dispositivo. Essa variabilidade significa que, ao contrário dos rankings de SEO tradicionais, que são relativamente estáveis, a visibilidade em consultas ramificadas pode flutuar significativamente de usuário para usuário e de consulta para consulta.
Prever rankings torna-se fundamentalmente mais difícil. Enquanto o SEO tradicional permite avaliações relativamente precisas da posição de alguém para palavras-chave específicas por meio de monitoramento contínuo, o desdobramento de consultas torna isso significativamente mais complexo. O conteúdo pode não ter uma classificação proeminente para a consulta original, mas ainda ser citado para uma subconsulta específica.
A latência pode aumentar com o fan-out síncrono porque o tempo de resposta geral depende da solicitação downstream mais lenta. Se uma das sub-solicitações paralelas demorar muito tempo, toda a resposta será atrasada.
A propagação de falhas representa um risco. Um único erro em uma requisição subsequente pode se propagar para cima e afetar toda a requisição. Isso exige mecanismos robustos de tratamento de erros, como disjuntores e tempos limite.
A complexidade do monitoramento aumenta significativamente. Rastrear e depurar árvores de requisições com múltiplas ramificações torna-se mais difícil. Isso exige rastreamento de ponta a ponta e ferramentas avançadas de observabilidade, como OpenTelemetry, Jaeger ou Zipkin.
A canibalização de conteúdo está se tornando um problema cada vez maior. Com a necessidade de criar agrupamentos de conteúdo mais amplos, aumenta o risco de diferentes sites competirem por tópicos semelhantes e roubarem a visibilidade uns dos outros.
Medir o sucesso está se tornando mais complexo. As métricas tradicionais de SEO, como rankings de palavras-chave e tráfego orgânico, já não oferecem uma visão completa. É preciso desenvolver novas métricas que capturem a visibilidade em diversos cenários de ramificação.
Aumento dos gastos com recursos. Criar conteúdo verdadeiramente abrangente que aborde diversas subquestões exige mais tempo, conhecimento especializado e orçamento do que otimizar para palavras-chave individuais. As organizações precisam adaptar suas estratégias e processos de conteúdo de acordo com essa realidade.
A personalização adiciona mais uma camada de complexidade. Como as solicitações de distribuição podem variar de acordo com o contexto do usuário, localização, tipo de dispositivo e outros fatores, torna-se ainda mais difícil prever qual conteúdo será visível para qual grupo de usuários.
Como o Query Fan-Out muda o futuro das buscas?
O Query Fan-Out representa uma mudança de paradigma fundamental na evolução dos mecanismos de busca e tem implicações de longo alcance para o futuro da recuperação de informações.
A transição da correspondência de palavras-chave para a compreensão da intenção já está bem encaminhada. Os futuros sistemas de busca serão ainda melhores em entender a intenção subjacente às consultas, mesmo que sejam imprecisas ou incompletas. Isso significa que os usuários gastarão menos tempo refinando suas consultas e obterão respostas úteis mais rapidamente.
A integração do contexto pessoal se aprofundará. Os sistemas de busca fornecerão cada vez mais resultados personalizados com base não apenas no histórico de buscas, mas também em uma compreensão abrangente do usuário, incluindo tarefas atuais, localização, preferências e contexto social. Isso tornará os resultados de busca ainda mais dinâmicos e individualizados.
O papel das marcas e da autoridade vai mudar. Enquanto tradicionalmente o ranqueamento para palavras-chave específicas era fundamental, o foco irá se deslocar cada vez mais para o estabelecimento de uma posição como fonte confiável em toda uma área temática. Marcas que fornecem conteúdo abrangente e de alta qualidade em diversos tópicos serão favorecidas em cenários de ramificação.
A visibilidade está se tornando mais fragmentada e diversificada. Em vez de se posicionarem bem para um punhado de palavras-chave principais, os sites de sucesso são citados em diversas subconsultas. Isso exige uma estratégia de conteúdo mais abrangente e torna o conteúdo de nicho mais valioso.
O comportamento do usuário continuará a mudar. Com respostas cada vez mais diretas e sintetizadas na interface de busca, os usuários clicarão em sites externos com menos frequência. Isso tem implicações para o tráfego de sites e os modelos de monetização, que precisam se adaptar a essa nova realidade.
A busca multimodal está se tornando cada vez mais importante. Os futuros sistemas de ramificação não considerarão apenas o texto, mas também integrarão imagens, vídeos, áudio e outros formatos de mídia em suas subconsultas e síntese. Isso exige estratégias de conteúdo que vão além do texto puro.
A fusão entre busca e conversação continuará. O recurso de ramificação de consultas já possibilita experiências de busca semelhantes a diálogos, que antecipam perguntas subsequentes. No futuro, a linha divisória entre mecanismos de busca e assistentes de IA conversacionais ficará ainda mais tênue.
A importância dos dados estruturados e da web semântica crescerá exponencialmente. Quanto melhor o conteúdo for anotado e estruturado semanticamente, mais eficazmente os sistemas de IA poderão utilizá-lo em cenários de ramificação. Isso tornará padrões como o Schema.org ainda mais cruciais.
O Query Fan-Out representa, portanto, não apenas uma inovação técnica, mas uma mudança fundamental na relação entre usuários, informações e tecnologia. A capacidade de antecipar e atender proativamente a necessidades complexas de informação definirá a próxima geração de sistemas de busca inteligentes.
Seu parceiro global de marketing e desenvolvimento de negócios
☑️ Nosso idioma comercial é inglês ou alemão
☑️ NOVO: Correspondência em seu idioma nativo!

Konrad Wolfenstein
Eu e minha equipe teremos o prazer de estar à sua disposição como seu consultor pessoal.
Você pode entrar em contato comigo preenchendo o formulário de contato aqui wolfenstein@xpert.digital:ou simplesmente ligando para +49 7348 4088 965. Meu endereço de e-mail é
Estou ansioso pelo nosso projeto conjunto.
☑️ Apoio a PMEs em estratégia, consultoria, planejamento e implementação
☑️ Criação ou realinhamento da estratégia digital e digitalização
☑️ Expansão e otimização dos processos de vendas internacionais
☑️ Plataformas de negociação B2B globais e digitais
☑️ Desenvolvimento de Negócios / Marketing / Relações Públicas / Feiras Comerciais Pioneiras
Nossa experiência global nos setores industrial e econômico em desenvolvimento de negócios, vendas e marketing

Nossa experiência global nos setores industrial e econômico em desenvolvimento de negócios, vendas e marketing - Imagem: Xpert.Digital
Áreas de atuação: B2B, digitalização (de IA a XR), engenharia mecânica, logística, energias renováveis e indústria
Mais informações aqui:
Um centro temático que oferece informações e conhecimento especializado:
- Plataforma de conhecimento que abrange economias globais e regionais, inovação e tendências específicas do setor
- Uma coletânea de análises, insights e informações contextuais sobre nossas principais áreas de atuação
- Um espaço para conhecimento especializado e informações sobre os desenvolvimentos atuais em negócios e tecnologia
- Um centro para empresas que buscam informações sobre mercados, digitalização e inovações do setor
🎯🎯🎯 Aproveite a vasta experiência da Xpert.Digital em cinco áreas, reunida em um pacote de serviços completo: Desenvolvimento de Negócios, P&D, Realidade Estendida, Relações Públicas e Otimização da Visibilidade Digital

Aproveite a vasta experiência da Xpert.Digital em cinco frentes, num pacote de serviços abrangente: P&D, XR, RP e Otimização da Visibilidade Digital. - Imagem: Xpert.Digital
A Xpert.Digital possui conhecimento profundo em diversos setores. Isso nos permite desenvolver estratégias personalizadas, precisamente alinhadas às necessidades e aos desafios do seu segmento de mercado específico. Ao analisar continuamente as tendências de mercado e monitorar os desenvolvimentos do setor, podemos agir de forma proativa e oferecer soluções inovadoras. A combinação de experiência e conhecimento especializado gera valor agregado e proporciona aos nossos clientes uma vantagem competitiva decisiva.
Mais informações aqui: