Ustrukturyzowane dane (znaczniki) w erze sztucznej inteligencji ze Schema.org: co naprawdę myślą inżynierowie Google’a – Zdjęcie: Xpert.Digital
Sekret SEO Google: dlaczego sztuczna inteligencja zawodzi bez danych strukturalnych
Pomimo ChatGPT i spółki: dlaczego inżynierowie Google nadal przysięgają na Schema.org
Aktualizacja SEO: Dlaczego Schema.org zastępuje teraz Open Graph w Google
W świecie SEO krąży uporczywy mit: w dobie genialnych modeli językowych sztucznej inteligencji, które bez trudu rozumieją nawet niestrukturyzowany tekst, skrupulatnie utrzymywane dane strukturalne, takie jak Schema.org, po prostu stały się przestarzałe. Rzeczywistość jest jednak zupełnie inna. Podczas wydarzenia Google Search Central Live inżynier Google, Ryan Levering, obalił to błędne przekonanie i jednoznacznie wyjaśnił: znaczniki strukturalne nie są reliktem przeszłości, lecz fundamentem nowego wyszukiwania opartego na sztucznej inteligencji.
Od nowych przeglądów AI po autonomicznych agentów zakupowych, modele językowe potrzebują precyzyjnych, czytelnych dla maszyn wytycznych, aby uniknąć halucynacji i działać wydajnie obliczeniowo. Ci, którzy chcą pozostać widoczni w nowoczesnej sieci, muszą pomóc maszynom zrozumieć kontekst bez niejednoznaczności. Niniejszy artykuł analizuje strategiczną reorganizację Google, przedstawia rewolucyjne innowacje dla e-commerce i treści generowanych przez użytkowników oraz pokazuje, dlaczego techniczne SEO jest obecnie decydującą przewagą konkurencyjną w walce o widoczność maszyn.
Maszyny potrafią czytać sieć – ale tylko jeśli pomożesz im ją zrozumieć
21 kwietnia 2026 roku w Toronto odbyło się pierwsze wydarzenie Google Search Central Live na kanadyjskiej ziemi – i nie było to zwykłe spotkanie branżowe. Ryan Levering, inżynier z Google Search Engineering, wygłosił prawdopodobnie najbardziej skomplikowaną technicznie i strategicznie znaczącą prezentację dnia: „Ustrukturyzowane dane, jakość i sztuczna inteligencja”. Jego wystąpienie było czymś więcej niż tylko przeglądem technicznym. Było to jasne stwierdzenie na temat przyszłości sieci semantycznej w erze, w której sztuczna inteligencja coraz częściej przejmuje rolę pośrednika między użytkownikami a informacjami.
Pomiędzy dwoma skrajnościami: błędne albo-albo
Na początku swojej prezentacji Ryan Levering skontrastował dwie skrajnie przeciwstawne opinie krążące w środowisku SEO. Z jednej strony panuje przekonanie, że dane strukturalne są po prostu zbędne w dobie potężnych modeli językowych: skoro modele sztucznej inteligencji potrafią z łatwością interpretować niestrukturyzowany tekst, po co mozolnie dodawać znaczniki schema.org do kodu źródłowego? Z drugiej strony, niektórzy entuzjaści propagują ideę, że dane strukturalne to przyszłość internetu – uniwersalny, semantyczny protokół komunikacyjny między autonomicznymi agentami sztucznej inteligencji, który w dużej mierze zastąpi tradycyjną sieć.
Levering odrzucił obie skrajności i zamiast tego przedstawił zniuansowaną, empirycznie ugruntowaną perspektywę. Oba stanowiska zawierały ziarno prawdy, doszedł do wniosku, ale żadne z nich nie opisywało w pełni rzeczywistości. Ten niuans jest charakterystyczny dla obecnego podejścia Google do tego tematu: nie chodzi o dogmat, lecz o pragmatyczną wydajność.
Cztery argumenty, które wyjaśniają wszystko
Centralny argument Leveringa można streścić w czterech kluczowych punktach, które rozwinął pod tytułem „Wartość danych ustrukturyzowanych”. Pierwszym z nich jest precyzja: dane ustrukturyzowane zapewniają znacznie wyższą dokładność w przypadku złożonych schematów, takich jak ceny sprzedaży czy programy lojalnościowe, niż ekstrakcja oparta na LLM z tekstu swobodnego. Modele językowe mogą być mylące – uzupełniają brakujące atrybuty, nieprawidłowo zagnieżdżają dane lub uzyskują dostęp do informacji wyrwanych z kontekstu. Podczas ekstrakcji cen produktów z dużej witryny e-commerce z dziesiątkami podobnych produktów, wskaźnik błędów jest znacznie wyższy w przypadku wnioskowania opartego na sztucznej inteligencji niż w przypadku czysto zaimplementowanego, ustrukturyzowanego znacznika.
Drugi punkt dotyczy dodatkowej treści: dane strukturalne często zawierają niewidoczne metadane, których po prostu nie ma w renderowanym kodzie HTML strony. Pełne formaty dat ISO, stabilne identyfikatory treści generowanych przez użytkowników czy wewnętrzne identyfikatory encji – te informacje istnieją wyłącznie w znacznikach. Żaden model językowy nie jest w stanie wyodrębnić tego, czego nie ma w tekście.
Po trzecie, wydajność: Analiza składniowa znaczników strukturalnych jest wielokrotnie tańsza niż przetwarzanie dużego modelu językowego w celu wyodrębnienia złożonych danych. Google indeksuje miliardy stron dziennie. Rachunek jest prosty: standardowy parser przetwarzający JSON-LD zużywa ułamek zasobów obliczeniowych kroku wnioskowania LLM. Dane strukturalne są zatem nie tylko lepsze semantycznie, ale również znacznie wydajniejsze z perspektywy biznesowej. Ten punkt ma bezpośrednie znaczenie dla infrastruktury Google.
Czwartym, i być może najbardziej niedocenianym, aspektem jest koncentracja: dane strukturalne wyraźnie wskazują, które informacje są istotne na stronie, zapobiegając w ten sposób gromadzeniu przez systemy sztucznej inteligencji nieistotnych danych. Na stronie produktu z artykułem głównym, kilkoma produktami powiązanymi i paskiem nawigacyjnym pełnym cen, model języka bez wyraźnej adnotacji nie może być pewien, do której ceny się odnieść. Znaczniki strukturalne rozwiązują ten problem poprzez jednoznaczne przypisanie.
Jak faktycznie przetwarzane są dane strukturalne
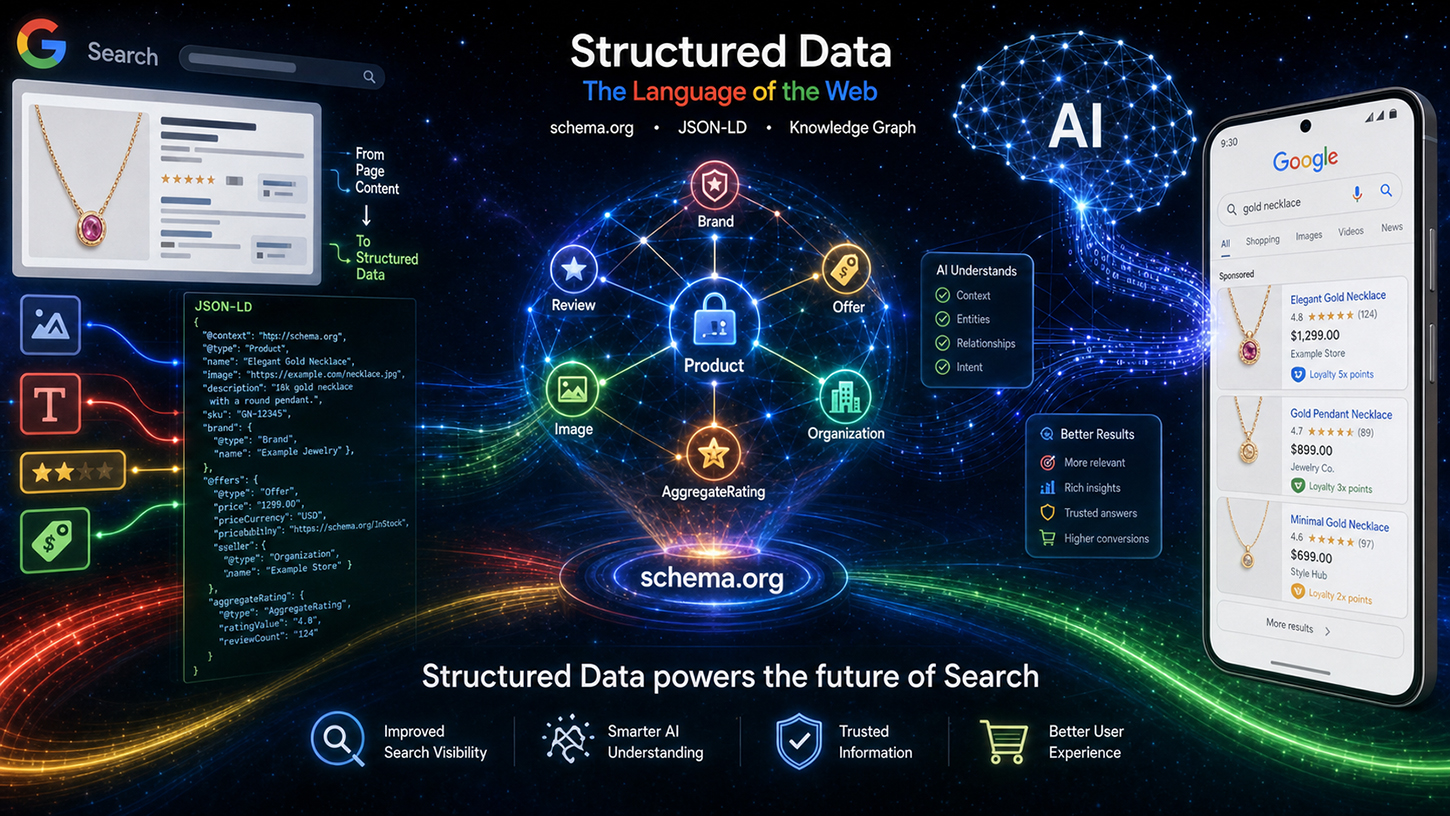
Levering zapewnił również transparentność technicznego przepływu przetwarzania. Dane Schema.org są najpierw przetwarzane poprzez specjalistyczne czyszczenie i filtrowanie, a następnie kategoryzowane jako dane indeksowane – podzielone na obszary takie jak wydarzenia, zakupy i recenzje. Tak przygotowane dane trafiają następnie do dwóch różnych kanałów wyjściowych: z jednej strony do klasycznej strony wyników wyszukiwania (SRP), a z drugiej strony, jako kontekst dla systemów Google opartych na sztucznej inteligencji, a konkretnie do tzw. Przeglądów AI (AIO) i Trybu AI (AIM). Ustrukturyzowane dane nie są już zatem jedynie bogatym narzędziem do generowania wyników, ale bezpośrednim źródłem generatywnych odpowiedzi AI. Stanowi to fundamentalną zmianę w strategicznym znaczeniu znaczników schema.org.
🎯🎯🎯 Centrum branżowe B2B oparte na danych jako rozwiązanie quasi-wewnętrzne


Rozwiązanie quasi-in-house: Jak Xpert.Digital zamyka luki operacyjne w marketingu i sprzedaży B2B – Inteligentny biznes oparty na treściach – Zdjęcie: Xpert.Digital
Xpert.Digital to branżowy hub B2B oparty na danych, kierowany przez Konrad Wolfenstein . Firma działa jako zewnętrzne, quasi-wewnętrzne rozwiązanie dla partnerów przemysłowych, eliminując luki operacyjne w obszarze marketingu, treści i sprzedaży – bez konieczności angażowania dodatkowych zasobów po stronie klienta.
Więcej informacji tutaj:
Dlaczego ustrukturyzowane dane stają się infrastrukturą dla agentów AI
Zakupy w centrum uwagi: wysyłka, lojalność i warianty
Znaczna część prezentacji poświęcona była innowacjom w e-commerce. Levering wyjaśnił, że według danych Baymard Institute, nieoczekiwane informacje o wysyłce zajmują drugie i trzecie miejsce wśród najczęstszych przyczyn porzucania koszyków. Znaczniki strukturalne dla usług wysyłkowych mogą bezpośrednio rozwiązać ten problem: sprzedawcy mogą teraz precyzyjnie definiować regiony pochodzenia i przeznaczenia, wymiary i wagę, progi wartości zamówienia, czasy realizacji oraz przynależność do programów lojalnościowych bezpośrednio w kodzie.
Model czasu dostawy używany przez Google jest podzielony na dwie fazy: czas obsługi zamówienia, czyli czas od otrzymania zamówienia do przekazania przewoźnikowi, oraz rzeczywisty czas dostawy. Obie fazy można opisać oddzielnie i z dużą szczegółowością – aż do ostatecznych terminów składania zamówień i tego, czy przetwarzanie odbywa się również w dni robocze. Odpowiednie przykłady JSON-LD pokazują, jak typ „ShippingConditions” można wykorzystać do zdefiniowania darmowej dostawy dla wybranych krajów (np. Francji i Niemiec) oraz minimalnej wartości zamówienia (np. 50 EUR).
Integracja usług wysyłkowych z programami lojalnościowymi jest szczególnie innowacyjna. Za pomocą właściwości `validForMemberTier` usługę wysyłkową można jawnie powiązać z programem członkowskim i określonym poziomem. Umożliwia to deklarowanie korzyści z wysyłki dla członków Premium bezpośrednio w znacznikach – funkcja ta była wcześniej konfigurowalna tylko za pośrednictwem Google Merchant Center. Sam powiązany program lojalnościowy jest definiowany jako obiekt `MemberProgram` w ramach jednostki `Organizacja`, z poziomami takimi jak „Złoty” lub „Srebrny” oraz powiązanymi korzyściami, takimi jak nagrody lojalnościowe lub punkty.
Programy lojalnościowe jako byty semantyczne
Wprowadzenie marży w programach lojalnościowych ma istotne znaczenie ekonomiczne. Organizacje mogą definiować wiele niezależnych programów członkowskich, każdy z kilkoma poziomami i zróżnicowanymi korzyściami – punktami, cenami dla członków, zasadami zwrotów, bonusami za wysyłkę. Informacje te pojawiają się bezpośrednio w wynikach wyszukiwania Google, co Levering pokazał na przykładach z życia wziętych, w tym na ofercie Sephora, która wyświetlała 30-procentową zniżkę dla członków bezpośrednio w kodzie produktu. Linkowanie identyfikatorów między stronami, czyli możliwość linkowania do definicji programów lojalnościowych z innych stron, to według Leveringa kolejny planowany krok, obecnie zatytułowany „Wytyczanie drogi dla linkowania @id między stronami”. Celem jest silniejsze powiązanie organizacyjne między stronami produktów a polityką firmy.
Treści generowane przez użytkowników: problem etykietowania przez sztuczną inteligencję
Kolejnym ważnym tematem był dalszy rozwój typów schematów dla treści generowanych przez użytkowników (UGC). Dwie nowe funkcje są tu szczególnie istotne. Po pierwsze, osadzone posty i reposty są obsługiwane w znacznikach forum i pytań i odpowiedzi, co umożliwia dokładniejsze przedstawienie semantyczne struktur dyskusji. Po drugie – i to ma jeszcze większe znaczenie strategiczne – wprowadzono właściwość `so#digitalSourceType`, która umożliwia jawną identyfikację treści generowanych maszynowo.
To rozwiązanie jest bezpośrednią odpowiedzią na zalew treści generowanych przez sztuczną inteligencję na platformach takich jak fora i serwisy pytań i odpowiedzi. Webmasterzy mogą teraz deklarować, czy post został wygenerowany algorytmicznie, czy przez model językowy. Google domyślnie zakłada, że autorami treści są ludzie – zasada ta sprzyja transparentnemu etykietowaniu. Właściwość `digitalSourceType` opiera się na kodach IPTC dla źródeł cyfrowych i rozróżnia między innymi treści generowane algorytmicznie i generowane przez model.
Wybór obrazu: Schemat pokonuje Open Graph
Mniej zauważalna, ale praktycznie skuteczna aktualizacja dotyczy logiki wyboru obrazów Google. System jest konsolidowany wewnętrznie, z jasną hierarchią priorytetów: znaczniki Schema.org, a konkretnie właściwości `primaryImageOfPage` i `mainEntity → image`, mają pierwszeństwo. Dopiero potem następuje metatag `og:image` z Open Graph. Ta zmiana oznacza, że dla operatorów witryn czysta implementacja głównego obrazu w schema.org bezpośrednio wpływa na jego wyświetlanie w wynikach wyszukiwania Google i w Przeglądach AI – co stanowi konkretną, mierzalną korzyść.
Sama Schema.org otrzymuje inwestycje
Na uwagę zasługuje również zapowiedziana przez Google reinwestycja w schema.org jako otwartą specyfikację. Wspomniano o trzech konkretnych działaniach: publikacji statystyk dotyczących częstotliwości użycia poszczególnych terminów schematu (dane o rozpowszechnieniu, prezentowane w formie slajdów, są już dostępne dla poszczególnych terminów, takich jak „digitalSourceType”, wraz z informacjami o około 10 000 domen), publikacji własnych reguł walidacji Google w standardowych formatach czytelnych maszynowo, takich jak SHACL lub ShEx, oraz ulepszonej obsłudze reguł kolejności. Jest to istotne, ponieważ umożliwiłoby zewnętrznym programistom tworzenie własnych narzędzi walidacyjnych opartych na standardach Google – niezależnie od oficjalnych narzędzi testowych, które czasami ulegają awarii pod obciążeniem.
Walidacja: dwa narzędzia, jeden cel
Levering przedstawił dwa narzędzia walidacyjne, które się uzupełniają, ale stosują różne kryteria testowania. Narzędzie do testowania wyników rozszerzonych (Rich Result Test Tool) dostępne pod adresem `search.google.com/test/rich-results` akceptuje adresy URL lub czysty JSON i sprawdza, czy znaczniki są odpowiednie dla wyników rozszerzonych w wyszukiwarce Google – opiera się zatem na specyficznych wymaganiach Google, a nie na samym standardzie schema.org. Z kolei `validator.schema.org` sprawdza, czy znaczniki są zgodne ze standardem schema.org, tj. czy spełniają wymogi otwartego słownika, niezależnie od tego, czy Google generuje na ich podstawie wyniki rozszerzonych. Prowadzi to do jasnej rekomendacji dla twórców stron internetowych: należy używać obu narzędzi, ponieważ znaczniki mogą być zgodne ze schematem, ale nie mogą generować wyników rozszerzonych – i odwrotnie.
Szerszy obraz: Ustrukturyzowane dane jako infrastruktura sztucznej inteligencji
Patrząc na całe wydarzenie w Toronto, widoczna jest zmiana wykraczająca daleko poza tradycyjną optymalizację SEO. Dane strukturalne ewoluują z narzędzia do generowania rozbudowanych fragmentów kodu (rich snippets) w fundamentalny standard warstwy danych dla systemów AI. Funkcje Google AI Overviews i AI Mode aktywnie wykorzystują znaczniki schema.org jako kontekst do generowania odpowiedzi i weryfikacji encji. Ci, którzy wdrażają poprawne, kompletne i precyzyjne dane strukturalne, nie tylko zwiększają swoje szanse na wizualne wyróżnienie w wynikach wyszukiwania, ale także pozycjonują swoje treści jako wiarygodne, podstawowe źródło odpowiedzi AI.
Wzmianka o protokole UCP (Universal Commerce Protocol) i WebMCP w tym kontekście nie jest przypadkowa. Oba standardy komunikacji oparte na agentach, które Google opublikował we wczesnych wersjach w 2026 roku, wymagają semantycznego opisu stron internetowych. Schema.org stanowi podstawę tego rozwiązania. W świecie, w którym agenci AI działają autonomicznie w sieci, wyszukując, porównując i inicjując transakcje, maszynowa czytelność treści nie jest już opcjonalna, lecz warunkiem koniecznym dla znaczenia ekonomicznego. Prezentacja Ryana Leveringa w Toronto nie była zatem jedynie raportem z aktualizacji technicznej – była wglądem w infrastrukturę przyszłej sieci.
Możesz się o tym przekonać sam w 10 sekund
Jeśli chcesz dowiedzieć się, jak dobrze i kompleksowo Twoja lub inna strona internetowa wykorzystuje dane strukturalne, możesz wykorzystać dokładnie te dwa narzędzia, które polecił Ryan Levering z Google (w naszym tekście powyżej):
Test wyników rozszerzonych Google (skupienie się na widoczności w Google):
Przejdź do search.google.com/test/rich-results, skopiuj adres URL dowolnego artykułu z xpert.digital i kliknij „Testuj adres URL”. Narzędzie pokaże Ci dokładnie, jakie znaczniki Google rozpoznaje na danej stronie i czy są one wolne od błędów.
Walidator schematów (skupiony na czystej zgodności ze standardami):
Przejdź na stronę validator.schema.orgi wklej ten sam adres URL. Tutaj możesz bezpośrednio zobaczyć w kodzie źródłowym, wyróżnione kolorem, które skrypty JSON-LD (dane strukturalne) włączył xpert.digital.
Twój globalny partner w zakresie marketingu i rozwoju biznesu
☑️ Naszym językiem biznesowym jest angielski lub niemiecki
☑️ NOWOŚĆ: Korespondencja w Twoim ojczystym języku!

Konrad Wolfenstein
Ja i mój zespół chętnie będziemy do Państwa dyspozycji jako osobisty doradca.
Możesz się ze mną skontaktować, wypełniając formularz kontaktowy tutaj wolfenstein@xpert.digital:lub po prostu dzwoniąc pod numer +49 7348 4088 965. Mój adres e-mail to
Nie mogę się doczekać naszego wspólnego projektu.
☑️ Wsparcie dla MŚP w zakresie strategii, doradztwa, planowania i wdrażania
☑️ Tworzenie lub reorganizacja strategii cyfrowej i digitalizacji
☑️ Rozszerzenie i optymalizacja procesów sprzedaży międzynarodowej
☑️ Globalne i cyfrowe platformy handlowe B2B
☑️ Rozwój biznesu pionierskiego / Marketing / PR / Targi
Wsparcie B2B i SaaS dla SEO i GEO (wyszukiwanie AI) w jednym: kompleksowe rozwiązanie dla firm B2B


Wsparcie B2B i SaaS dla SEO i GEO (wyszukiwanie AI) w jednym: kompleksowe rozwiązanie dla firm B2B — Zdjęcie: Xpert.Digital
Wyszukiwanie oparte na sztucznej inteligencji zmienia wszystko: w jaki sposób to rozwiązanie SaaS na zawsze zrewolucjonizuje Twój ranking B2B.
Cyfrowy krajobraz firm B2B ulega dynamicznym zmianom. Kierowane sztuczną inteligencją, zasady widoczności online ulegają przedefiniowaniu. Dla firm zawsze wyzwaniem było nie tylko bycie widocznym w cyfrowym tłumie, ale także bycie istotnym dla właściwych decydentów. Tradycyjne strategie SEO i zarządzanie lokalną obecnością (geomarketing) są złożone, czasochłonne i często stanowią walkę z ciągle zmieniającymi się algorytmami i silną konkurencją.
A co, gdyby istniało rozwiązanie, które nie tylko uprościłoby ten proces, ale także uczyniło go inteligentniejszym, bardziej przewidywalnym i znacznie skuteczniejszym? Właśnie tutaj pojawia się połączenie specjalistycznego wsparcia B2B z wydajną platformą SaaS (oprogramowanie jako usługa), zaprojektowaną specjalnie z myślą o potrzebach SEO i GEO w erze wyszukiwania opartego na sztucznej inteligencji.
Ta nowa generacja narzędzi nie opiera się już wyłącznie na ręcznej analizie słów kluczowych i strategiach pozyskiwania linków zwrotnych. Zamiast tego wykorzystuje sztuczną inteligencję, aby dokładniej rozumieć intencje wyszukiwania, automatycznie optymalizować lokalne czynniki rankingowe i przeprowadzać analizę konkurencji w czasie rzeczywistym. Rezultatem jest proaktywna strategia oparta na danych, która daje firmom B2B zdecydowaną przewagę: nie tylko są one znajdowane, ale także postrzegane jako wiodący autorytet w swojej niszy i lokalizacji.
Oto symbioza wsparcia B2B i technologii SaaS opartej na sztucznej inteligencji, która przekształca SEO i marketing GEO, i jak Twoja firma może na tym skorzystać, aby rozwijać się w sposób zrównoważony w przestrzeni cyfrowej.
Więcej informacji tutaj: