
Strukturált adatok (jelölés) a mesterséges intelligencia korában a Schema.org segítségével: Mit gondolnak valójában a Google mérnökei?
Szakértői megjelenés előtti

Available in 27 languages 📢
Az Xpert.Digital előnyben részesítése a Google-benⓘMegjelent: 2026. május 7. / Frissítve: 2026. május 7. – Szerző: Konrad Wolfenstein
Strukturált adatok (jelölés) a mesterséges intelligencia korában a Schema.org segítségével: Mit gondolnak valójában a Google mérnökei – Kép: Xpert.Digital
A Google SEO titka: Miért vall kudarcot strukturált adatok nélkül a mesterséges intelligencia?
A ChatGPT és társai ellenére: Miért esküsznek továbbra is a Google mérnökei a Schema.org-ra?
SEO frissítés: Miért váltja ki most a Schema.org az Open Graph-ot a Google-ben?
Egy állandó mítosz kering a SEO világában: A briliáns mesterséges intelligencia által létrehozott nyelvi modellek korában, amelyek könnyedén megértik még a strukturálatlan szöveget is, a gondosan karbantartott strukturált adatok, mint például a Schema.org, egyszerűen elavultak. A valóság azonban egészen más. A Google Search Central Live eseményen Ryan Levering, a Google mérnöke cáfolta ezt a tévhitet, és egyértelműen világossá tette: a strukturált jelölőnyelv nem a múlt ereklyéje, hanem az új, mesterséges intelligencia által vezérelt keresés alapvető gerince.
Az új mesterséges intelligencia-áttekintésektől az autonóm vásárlási ügynökökig a nyelvi modelleknek pontos, géppel olvasható irányelvekre van szükségük a hallucinációk elkerülése és a számítási szempontból hatékony működés érdekében. Azoknak, akik láthatóak akarnak maradni a modern weben, segíteniük kell a gépeknek a kontextus félreérthetetlen megértésében. Ez a cikk a Google stratégiai átirányítását vizsgálja, forradalmi újításokat mutat be az e-kereskedelem és a felhasználók által generált tartalmak terén, és bemutatja, hogy miért a technikai SEO ma a döntő versenyelőny a gépi láthatóságért folytatott küzdelemben.
A gépek képesek olvasni az internetet – de csak akkor, ha segítesz nekik megérteni
2026. április 21-én Torontóban került megrendezésre az első kanadai Google Search Central Live esemény – és nem egy szokványos iparági összejövetel volt. Ryan Levering, a Google Search Engineering mérnöke tartotta a nap vitathatatlanul legszakmailag legrészletesebb és stratégiailag legjelentősebb előadását: „Strukturált adatok, minőség és mesterséges intelligencia”. Amit prezentált, az több volt, mint egy technikai áttekintés. Egyértelmű kijelentés volt a szemantikus web jövőjéről egy olyan korban, ahol a mesterséges intelligencia egyre inkább a felhasználók és az információk közötti közvetítő szerepét tölti be.
Két szélsőség között: a rossz vagy-vagy
Előadása elején Ryan Levering két, a SEO közösségben keringő, merőben ellentétes véleményt állított szembe egymással. Egyrészt az a meggyőződés uralkodik, hogy a strukturált adatok egyszerűen feleslegesek a hatékony nyelvi modellek korában: Ha a mesterséges intelligencia modelljei könnyen értelmezik a strukturálatlan szöveget, miért kellene fáradságosan schema.org jelölőnyelvet hozzáadni a forráskódhoz? Másrészt egyes lelkes hívek azt az elképzelést terjesztik, hogy a strukturált adatok az internet jövője – egy univerzális szemantikus kommunikációs protokoll az autonóm mesterséges intelligencia ágensek között, amely nagyrészt felváltja a hagyományos webet.
Levering mindkét szélsőséget elutasította, és ehelyett egy árnyalt, empirikusan megalapozott perspektívát mutatott be. Mindkét álláspont tartalmazott egy magot az igazságból, vonta le a következtetést, de egyik sem írta le teljes mértékben a valóságot. Ez az árnyaltság jellemző a Google jelenlegi megközelítésére a témához: nem a dogmáról, hanem a pragmatikus hatékonyságról van szó.
Négy érv, ami mindent megmagyaráz
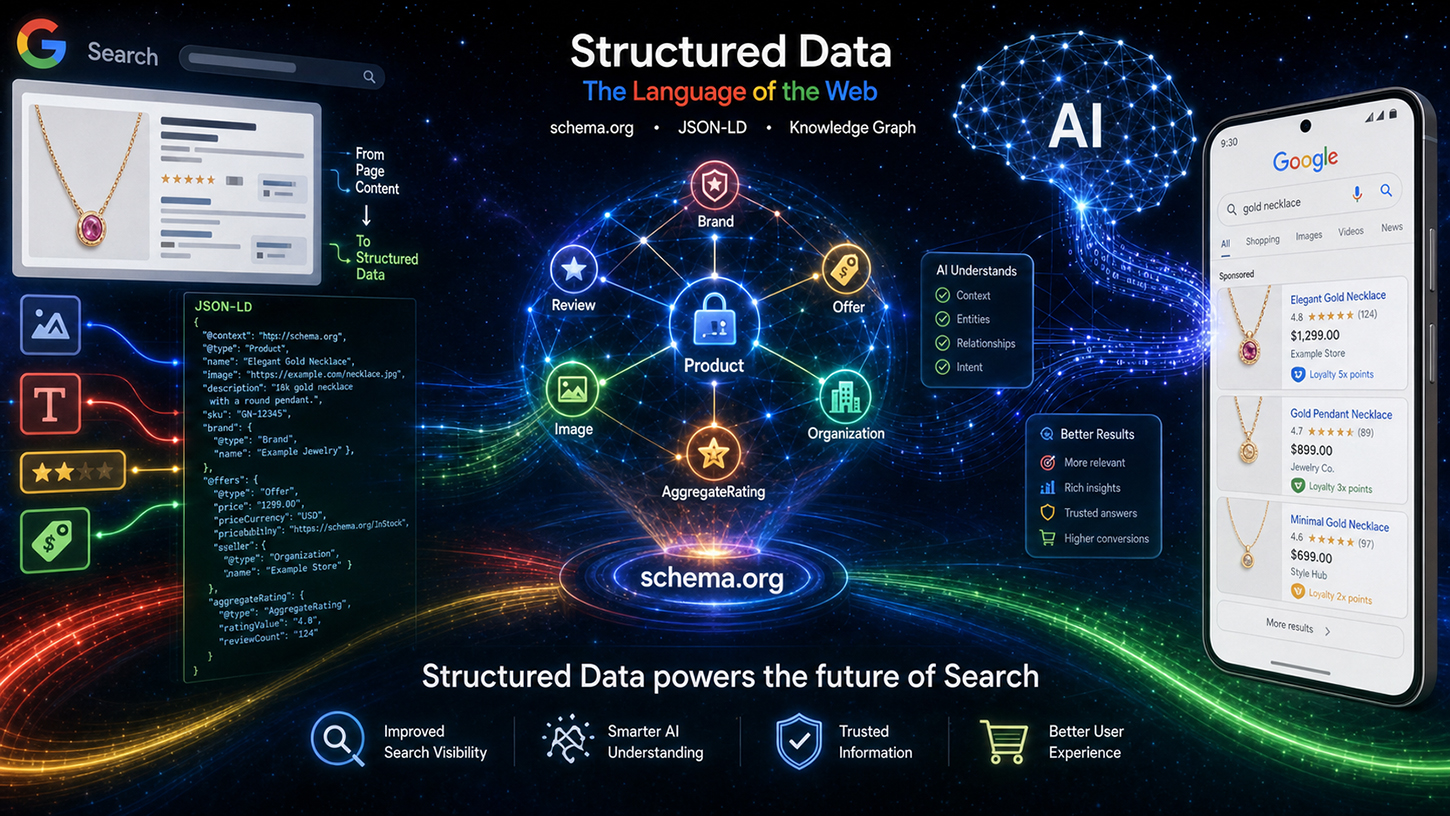
Levering központi érvelése négy fő pontban foglalható össze, amelyeket „A strukturált adatok értéke” címmel részletesebben kifejtett. Az első pont a pontosság: A strukturált adatok lényegesen nagyobb pontosságot biztosítanak az olyan összetett sémák esetében, mint az eladási árak vagy a hűségprogramok, mint a szabad szövegből történő LLM-alapú kinyerés. A nyelvi modellek félrevezetőek lehetnek – hiányzó attribútumokat töltenek ki, helytelenül ágyazzák be az adatokat, vagy kontextusból kiragadott információkhoz férnek hozzá. Amikor egy nagyméretű e-kereskedelmi webhelyről, amely több tucat hasonló terméket tartalmaz, kinyerjük a termékárakat, a hibaarány lényegesen magasabb a mesterséges intelligencia alapú következtetéssel, mint a tisztán megvalósított, strukturált jelöléssel.
A második pont a kiegészítő tartalomra vonatkozik: A strukturált adatok gyakran láthatatlan metaadatokat tartalmaznak, amelyek egyszerűen nincsenek jelen az oldal megjelenített HTML-kódjában. Teljes ISO dátumformátumok, stabil azonosítók a felhasználók által generált tartalomhoz vagy belső entitásazonosítók – ezek az információk kizárólag a jelölőnyelvben léteznek. Egyetlen nyelvi modell sem képes kinyerni azt, ami nincs benne a szövegben.
Harmadszor, a hatékonyság: A strukturált jelölőnyelv elemzése sokszor olcsóbb, mint egy nagy nyelvi modell feldolgozása az összetett adatok kinyerése érdekében. A Google naponta több milliárd oldalt indexel. A számítás egyszerű: Egy hagyományos, JSON-LD-t feldolgozó elemző egy LLM következtetési lépés számítási erőforrásainak töredékét használja fel. A strukturált adatok ezért nemcsak szemantikailag jobbak, hanem üzleti szempontból is jelentősen hatékonyabbak. Ez a pont közvetlenül kapcsolódik a Google infrastruktúrájához.
A negyedik, és talán leginkább alábecsült szempont a fókusz: A strukturált adatok explicit módon kiemelik, hogy mely információk relevánsak egy oldalon, így megakadályozzák, hogy a mesterséges intelligencia rendszerei irreleváns adatokat gyűjtsenek. Egy olyan termékoldalon, amelyen egy fő cikk, több kapcsolódó termék és egy árakkal teli navigációs sáv található, egy explicit annotáció nélküli nyelvi modell nem tudhatja biztosan, hogy melyik árra kell hivatkozni. A strukturált jelölőnyelv egyértelmű hozzárendeléssel oldja meg ezt a problémát.
Hogyan dolgozzák fel a strukturált adatokat valójában?
A Levering átláthatóvá tette a technikai feldolgozási folyamatot is. A Schema.org adatait először speciális tisztításnak és szűrésnek vetik alá, mielőtt indexelt adatokként kategorizálnák őket – olyan területekre osztva, mint az események, a vásárlások és az értékelések. Ezek az előkészített adatok ezután két különböző kimeneti csatornába áramlanak: egyrészt a klasszikus keresési eredményoldalra (SRP), másrészt pedig a Google mesterséges intelligencia alapú rendszereinek kontextusába, konkrétan az úgynevezett AI Overviews (AIO) és AI Mode (AIM) rendszereibe. A strukturált adatok így már nem csupán gazdag találati eszközök, hanem közvetlen bemenetet jelentenek a generatív AI-válaszokhoz. Ez alapvető változást jelent a schema.org jelölőnyelv stratégiai fontosságában.
🎯🎯🎯 Adatvezérelt B2B iparági központ, mint kvázi házon belüli megoldás

A kvázi házon belüli megoldás: Hogyan hidalja át az Xpert.Digital a B2B marketing és értékesítés működési réseit – Okos, tartalomvezérelt üzlet - Kép: Xpert.Digital
Az Xpert.Digital egy adatvezérelt B2B iparági központ, amelyet Konrad Wolfenstein vezet. A vállalat külső, kvázi házon belüli megoldásként működik az ipari partnerek számára, áthidalva a marketing, a tartalom és az értékesítés működési hiányosságait – anélkül, hogy további erőforrásokat igényelne az ügyféloldalon.
További információ itt:
Miért válik a strukturált adat az AI-ügynökök infrastruktúrájává?
Vásárlás fókuszban: Szállítás, hűségprogram és változatok
Az előadás jelentős része az e-kereskedelem innovációira összpontosított. Levering kifejtette, hogy a Baymard Intézet adatai szerint a váratlan szállítási információk a második és harmadik leggyakoribb okok a bevásárlókosár-elhagyásra. A szállítási szolgáltatások strukturált jelölése közvetlenül megoldhatja ezt a problémát: A kereskedők mostantól pontosan meghatározhatják a származási és célállomási régiókat, a méreteket és súlyokat, a rendelési érték küszöbértékeit, a feldolgozási időket és a hűségprogramokhoz való tartozásokat közvetlenül a kódban.
A Google által használt szállítási idő modell két fázisra oszlik: a kezelési időre, azaz a megrendelés kézhezvételétől a szállítónak való átadásig eltelt időre, és a tényleges kézbesítési időre. Mindkét fázis külön-külön és nagy részletességgel annotálható – egészen a megrendelések határidejéig és ahhoz, hogy a feldolgozás hétköznapokon is történik-e. A megfelelő JSON-LD példák bemutatják, hogyan használható a `ShippingConditions` típus bizonyos országok (pl. Franciaország és Németország) ingyenes szállításának és minimális rendelési értékek (pl. 50 €) meghatározására.
A szállítási szolgáltatások hűségprogramokkal való integrációja különösen innovatív. A `validForMemberTier` tulajdonság használatával egy szállítási szolgáltatás explicit módon összekapcsolható egy tagsági programmal és egy adott szinttel. Ez lehetővé teszi a prémium tagok szállítási előnyeinek közvetlen deklarálását a jelölésben – ez a funkció korábban csak a Google Merchant Centeren keresztül volt konfigurálható. Maga a kapcsolódó hűségprogram egy `MemberProgram` objektumként van definiálva az `Organization` entitás alatt, olyan szintekkel, mint az "Arany" vagy az "Ezüst", és a kapcsolódó előnyökkel, mint a hűségjutalmak vagy a pontjutalmak.
Hűségprogramok mint szemantikai entitások
A hűségprogram-jelölés bevezetése gazdaságilag jelentős. A szervezetek több független tagsági programot is meghatározhatnak, amelyek mindegyike több szinttel és differenciált előnyökkel rendelkezik – pontokkal, tagsági árakkal, visszaküldési szabályzatokkal, szállítási bónuszokkal. Ez az információ ezután közvetlenül megjelenik a Google keresési eredményei között, ahogy azt Levering valós példákkal is bemutatta, többek között egy Sephora-ajánlattal, amely 30 százalékos tagsági kedvezményt jelenített meg közvetlenül a vásárlási kódrészletben. A keresztoldalas azonosító-összekapcsolás, azaz a hűségprogram-definíciókhoz más oldalakról való kapcsolódás lehetősége, Levering szerint a következő tervezett lépés, amelynek jelenlegi címe: „Útvonalat nyitni az oldalak közötti @id-összekapcsoláshoz”. A cél: erősebb szervezeti hivatkozások a termékoldalak és a vállalati szabályzatok között.
Felhasználó által generált tartalom: A mesterséges intelligencia általi címkézés problémája
Egy másik fontos téma a felhasználók által generált tartalmak (UGC) sématípusainak továbbfejlesztése volt. Két új funkció különösen releváns itt. Először is, a beágyazott bejegyzések és újraposztolások támogatottak a fórum- és kérdés-válasz jelölésekben, lehetővé téve a beszélgetési struktúrák pontosabb szemantikai ábrázolását. Másodszor – és ez még nagyobb stratégiai jelentőséggel bír – bevezetésre került a `so#digitalSourceType` tulajdonság, amely explicit módon azonosítja a géppel generált tartalmat.
Ez a fejlesztés közvetlen válasz a mesterséges intelligencia által generált tartalmak áradatára olyan platformokon, mint a fórumok és a kérdések és válaszok oldalak. A webmesterek mostantól kijelenthetik, hogy egy bejegyzést algoritmus vagy nyelvi modell generált-e. Azokat, akik ezt nem adják meg, a Google implicit módon emberi szerzőknek tekinti – ez a szabály ösztönzi az átlátható címkézést. A `digitalSourceType` tulajdonság a digitális források IPTC kódjain alapul, és többek között különbséget tesz az algoritmus által generált és a modell által generált tartalom között.
Képkiválasztás: A séma legyőzi az Open Graph-ot
Egy kevésbé észrevehető, de gyakorlatilag hatékony frissítés a Google képkiválasztási logikáját érinti. A rendszert belsőleg konszolidálják, egyértelmű priorizálási hierarchiával: a Schema.org jelölőnyelv, konkrétan a `primaryImageOfPage` és a `mainEntity → image` tulajdonságok elsőbbséget élveznek. Csak ezt követi az Open Graph `og:image` metacímkéje. Ez a változás azt jelenti, hogy a weboldalak üzemeltetői számára a fő kép tiszta schema.org implementációja közvetlenül befolyásolja annak megjelenését a Google keresési eredményeiben és az AI Overviews-ben – ami kézzelfogható, mérhető előnyt jelent.
Maga a Schema.org is befektetéseket kap
Szintén említésre méltó a Google bejelentett újbóli befektetése a schema.org-ba, mint nyílt specifikációba. Három konkrét intézkedést említettek: az egyes sémakifejezések használati gyakoriságára vonatkozó statisztikák közzététele (a prevalenciaadatok diavetítés formájában már elérhetők olyan egyes kifejezésekre, mint a `digitalSourceType`, körülbelül 10 000 domainre vonatkozó információkkal), a Google saját validációs szabályainak közzététele géppel olvasható szabványos formátumokban, például SHACL-ben vagy ShEx-ben, valamint a sorrendi szabályok támogatásának javítása. Ez azért jelentős, mert lehetővé tenné a külső fejlesztők számára, hogy saját validációs eszközöket építsenek a Google szabványai alapján – függetlenül a hivatalos tesztelőeszközöktől, amelyek időnként összeomlanak terhelés alatt.
Validáció: Két eszköz, egy cél
Levering két olyan validációs eszközt mutatott be, amelyek kiegészítik egymást, de eltérő tesztelési kritériumokat alkalmaznak. A `search.google.com/test/rich-results` címen található Rich Result Test Tool URL-eket vagy tiszta JSON-t fogad el, és ellenőrzi, hogy a jelölőnyelv alkalmas-e a Google Search Rich Results találataihoz – tehát a Google konkrét követelményein alapul, nem magán a schema.org szabványon. A `validator.schema.org` ezzel szemben azt ellenőrzi, hogy a jelölőnyelv schema.org-kompatibilis-e, azaz megfelel-e a nyílt szókincsnek, függetlenül attól, hogy a Google generál-e belőle rich találatokat. Ez egyértelmű ajánlást fogalmaz meg a webfejlesztők számára: mindkét eszközt használni kell, mivel a jelölőnyelv lehet séma-kompatibilis, de nem képes rich result-okra – és fordítva.
A nagyobb kép: Strukturált adatok, mint mesterséges intelligencia infrastruktúra
A torontói eseményt egészében tekintve egyértelmű elmozdulás figyelhető meg, amely messze túlmutat a hagyományos SEO optimalizáláson. A strukturált adatok a rich snippetsek létrehozására szolgáló eszközből az AI-rendszerek alapvető adatréteg-szabványává fejlődnek. A Google AI Overviews és AI Mode aktívan használja a schema.org jelöléseket kontextusként a válaszok generálásához és az entitások ellenőrzéséhez. Azok, akik helyes, teljes és pontos strukturált adatokat alkalmaznak, nemcsak a vizuális kiemelések esélyeit javítják a keresési eredmények között, hanem tartalmukat a mesterséges intelligencia által adott válaszok megbízható elsődleges forrásaként pozicionálják.
Az Univerzális Kereskedelmi Protokoll (UCP) és a WebMCP említése ebben az összefüggésben nem véletlen. Mindkét ügynökalapú kommunikációs szabvány, amelyeket a Google 2026-ban korai verziókban adott ki, megköveteli, hogy a weboldalakat szemantikailag leírják. Ennek alapját a Schema.org képezi. Egy olyan világban, ahol a mesterséges intelligencia alapú ügynökök önállóan cselekszenek a weben, keresnek, összehasonlítanak és tranzakciókat kezdeményeznek, a tartalom gépi olvashatósága már nem opcionális, hanem a gazdasági relevancia előfeltétele. Ryan Levering torontói előadása tehát nem csupán egy technikai frissítési jelentés volt – betekintést nyújtott a következő web infrastruktúrájába.
10 másodperc alatt magad is megtudhatod
Ha szeretné tudni, hogy az Ön vagy egy másik webhelye mennyire jól és átfogóan használja a strukturált adatokat, pontosan azt a két eszközt használhatja, amelyeket Ryan Levering a Google-től (a fenti szövegünkből) ajánlott:
Google Rich Results teszt (a Google láthatóságára összpontosítva):
Lépj a search.google.com/test/rich-results, másold ki egy xpert.digital cikk URL-jét, és kattints az „URL tesztelése” gombra. Az eszköz pontosan megmutatja, hogy a Google mely jelöléseket ismeri fel az adott oldalon, és hogy azok hibátlanok-e.
Séma-validátor (a tiszta szabványoknak való megfelelésre összpontosít):
Menj a validator.schema.org, és illeszd be ugyanazt az URL-t. Itt közvetlenül a forráskódban, színessel kiemelve láthatod, hogy az xpert.digital mely JSON-LD szkripteket (strukturált adatokat) építette be.
Globális marketing- és üzletfejlesztési partnere
☑️ Üzleti nyelvünk az angol vagy a német
☑️ ÚJ: Levelezés az anyanyelveden!

Konrad Wolfenstein
Én és a csapatom örömmel állunk rendelkezésére személyes tanácsadóként.
Kapcsolatba léphetsz velem a kapcsolatfelvételi űrlap kitöltésével itt egyszerűen hívj a +49 7348 4088 965 Az e-mail címem [email protected]:, vagy
Alig várom a közös projektünket.
☑️ KKV-támogatás a stratégiában, tanácsadásban, tervezésben és megvalósításban
☑️ Digitális stratégia létrehozása vagy átalakítása és digitalizáció
☑️ Nemzetközi értékesítési folyamatok bővítése és optimalizálása
☑️ Globális és digitális B2B kereskedési platformok
☑️ Pioneer Üzletfejlesztés / Marketing / PR / Vásárok
B2B támogatás és SaaS SEO és GEO (AI keresés) kombinációja: Mindent egyben megoldás B2B vállalatok számára

B2B támogatás és SaaS SEO és GEO (AI keresés) kombinációja: Az all-in-one megoldás B2B vállalatok számára - Kép: Xpert.Digital
A mesterséges intelligencia általi keresés mindent megváltoztat: Hogyan forradalmasítja ez a SaaS-megoldás a B2B rangsorolását örökre?.
A B2B vállalatok digitális környezete gyors változásokon megy keresztül. A mesterséges intelligencia hatására az online láthatóság szabályai átíródnak. A vállalatok számára mindig is kihívást jelentett nemcsak az, hogy láthatóak legyenek a digitális tömegben, hanem az is, hogy relevánsak legyenek a megfelelő döntéshozók számára. A hagyományos SEO stratégiák és a helyi jelenlét kezelése (geomarketing) összetett, időigényes, és gyakran a folyamatosan változó algoritmusok és az intenzív verseny elleni küzdelmet jelentik.
De mi lenne, ha létezne egy olyan megoldás, amely nemcsak leegyszerűsíti ezt a folyamatot, hanem intelligensebbé, prediktívebbé és sokkal hatékonyabbá is teszi? Itt jön képbe a specializált B2B támogatás és egy hatékony SaaS (Software as a Service) platform kombinációja, amelyet kifejezetten a SEO és a GEO igényeire terveztek a mesterséges intelligencia alapú keresés korában.
Ez az új generációs eszköz már nem kizárólag a manuális kulcsszóelemzésre és a backlink stratégiákra támaszkodik. Ehelyett mesterséges intelligenciát használ a keresési szándék pontosabb megértéséhez, a helyi rangsorolási tényezők automatikus optimalizálásához és valós idejű versenyelemzés elvégzéséhez. Az eredmény egy proaktív, adatvezérelt stratégia, amely döntő előnyt biztosít a B2B vállalatoknak: nemcsak megtalálhatók, hanem a piaci résük és a helyük vezető szakértőjeként is érzékelik őket.
Íme a B2B támogatás és a mesterséges intelligencia által vezérelt SaaS technológia szimbiózisa, amely átalakítja a SEO és a GEO marketinget, és hogy vállalata hogyan profitálhat belőle a fenntartható növekedés érdekében a digitális térben.
További információ itt:

















