
Katse tehisintellekti selgitada: kuidas tehisintellekt töötab ja toimib – kuidas seda treenitakse?

Available in 27 languages 📢
Eelista Google'is Xpert.DigitaliⓘAvaldatud: 8. september 2024 / Uuendatud: 9. september 2024 – Autor: Konrad Wolfenstein

Katse tehisintellekti selgitada: kuidas tehisintellekt töötab ja kuidas seda treenitakse? – Pilt: Xpert.Digital
📊 Andmete sisestamisest mudeli ennustamiseni: tehisintellekti protsess
Kuidas tehisintellekt (AI) töötab? 🤖
Tehisintellekti (TI) toimimise saab jagada mitmeks selgelt määratletud etapiks. Igaüks neist etappidest on TI lõpptulemuse seisukohalt ülioluline. Protsess algab andmete sisestamisega ja lõpeb mudeli ennustamise ning tagasiside või edasiste treeningvoorudega. Need etapid kirjeldavad protsessi, mida peaaegu kõik TI mudelid läbivad, olenemata sellest, kas tegemist on lihtsate reeglite või väga keerukate närvivõrkudega.
1. Andmete sisestamine 📊
Iga tehisintellekti aluseks on andmed, millega see töötab. Need andmed võivad esineda mitmel kujul, näiteks piltide, teksti, helifailide või videote kujul. Tehisintellekt kasutab neid toorandmeid mustrite äratundmiseks ja otsuste langetamiseks. Andmete kvaliteet ja kvantiteet mängivad siin olulist rolli, kuna need mõjutavad oluliselt seda, kui hästi või halvasti mudel lõpuks toimib.
Mida põhjalikumad ja täpsemad on andmed, seda paremini suudab tehisintellekt õppida. Näiteks piltide töötlemiseks tehisintellekti treenimisel vajab see erinevate objektide õigeks tuvastamiseks suurt hulka pildiandmeid. Keelemudelite puhul aitavad tekstiandmed tehisintellektil inimkõnet mõista ja genereerida. Andmete sisestamine on esimene ja üks olulisemaid samme, kuna ennustuste kvaliteet saab olla sama hea kui alusandmed. Arvutiteaduses on tuntud põhimõte, mis kirjeldab seda ütlusega „prügi sisse, prügi välja“ – halvad andmed viivad halbade tulemusteni.
2. Andmete eeltöötlus 🧹
Kui andmed on sisestatud, tuleb need enne mudelisse sisestamist ette valmistada. Seda protsessi nimetatakse andmete eeltöötluseks. Eesmärk on teisendada andmed vormingusse, mida mudel saab optimaalselt töödelda.
Eeltöötluse tavaline samm on andmete normaliseerimine. See tähendab andmete viimist ühtsesse väärtusvahemikku, et mudel neid järjepidevalt käsitleks. Näiteks pildi kõigi piksliväärtuste skaleerimine vahemikku 0 kuni 1, mitte vahemikku 0 kuni 255.
Teine oluline osa eeltöötlusest on tunnuste eraldamine. See hõlmab toorandmetest mudeli jaoks eriti oluliste tunnuste eraldamist. Pilditöötluses võivad need olla servad või kindlad värvimustrid, tekstitöötluses aga olulised märksõnad või lauseehitus. Eeltöötlus on tehisintellekti õppeprotsessi tõhusamaks ja täpsemaks muutmiseks ülioluline.
3. Modell 🧩
Mudel on iga tehisintellekti tuum. Siin analüüsitakse ja töödeldakse andmeid algoritmide ja matemaatiliste arvutuste põhjal. Mudel võib esineda mitmel kujul. Üks tuntumaid mudeleid on närvivõrk, mis põhineb inimaju tööl.
Neuraalvõrgud koosnevad mitmest tehisneuronite kihist, mis töötlevad ja edastavad teavet. Iga kiht võtab eelmise kihi väljundid ja töötleb neid edasi. Neuraalvõrgu õppeprotsess hõlmab nende neuronite vaheliste ühenduste kaalude kohandamist, et võrk saaks teha üha täpsemaid ennustusi või klassifikatsioone. See kohandamine saavutatakse treenimise teel, mille käigus võrk pääseb juurde suurele hulgale näidisandmetele ja parandab iteratiivselt oma sisemisi parameetreid (kaalusid).
Lisaks närvivõrkudele kasutatakse tehisintellekti mudelites paljusid teisi algoritme. Nende hulka kuuluvad otsustuspuud, juhuslikud metsad, tugivektormasinad ja palju muud. Kasutatav algoritm sõltub konkreetsest ülesandest ja saadaolevatest andmetest.
4. Mudeli prognoos 🔍
Kui mudel on andmetega treenitud, on see võimeline tegema ennustusi. Seda sammu nimetatakse mudeli ennustamiseks. Tehisintellekt saab sisendi ja tagastab seni õpitud mustrite põhjal väljundi, st ennustuse või otsuse.
See ennustus võib esineda erinevates vormides. Näiteks piltide klassifitseerimise mudelis võib tehisintellekt ennustada, millist objekti pildil kujutatakse. Keelemudelis võib see ennustada, milline sõna lauses järgmisena tuleb. Finantsennustustes võib tehisintellekt ennustada aktsiaturu toimimist.
Oluline on rõhutada, et ennustuste täpsus sõltub suuresti treeningandmete kvaliteedist ja mudeli arhitektuurist. Ebapiisavate või kallutatud andmetega treenitud mudel annab suure tõenäosusega valesid ennustusi.
5. Tagasiside ja koolitus (valikuline) ♻️
Teine oluline aspekt tehisintellekti toimimises on tagasisidemehhanism. Siin kontrollitakse ja optimeeritakse mudelit regulaarselt. See protsess toimub kas treeningu ajal või pärast mudeli ennustust.
Kui mudel annab valesid ennustusi, saab see tagasiside abil õppida neid vigu ära tundma ja oma sisemisi parameetreid vastavalt kohandama. Seda tehakse mudeli ennustuste võrdlemisel tegelike tulemustega (nt teadaolevate andmetega, millele on õiged vastused juba olemas). Tüüpiline meetod selles kontekstis on nn juhendatud õpe, mille puhul tehisintellekt õpib näidisandmetest, mis juba sisaldavad õigeid vastuseid.
Levinud tagasisidemeetod on närvivõrkudes kasutatav tagasilevitamise algoritm. Selle puhul levitatakse mudeli tehtud vigu võrgus tagasi, et reguleerida närviühenduste kaalusid. Sel viisil õpib mudel oma vigadest ja muutub oma ennustustes üha täpsemaks.
Treeningu roll 🏋️♂️
Tehisintellekti treenimine on iteratiivne protsess. Mida rohkem andmeid mudel näeb ja mida sagedamini seda nende andmete põhjal treenitakse, seda täpsemaks muutuvad selle ennustused. Siiski on ka piirangud: ületreenitud mudel võib tekitada nn "ülesobitamise" probleeme. See tähendab, et see mäletab treeningandmeid nii hästi, et annab uute, tundmatute andmete puhul kehvemaid tulemusi. Seetõttu on oluline mudelit treenida nii, et see üldistaks, mis tähendab, et see suudaks teha häid ennustusi ka uute andmete põhjal.
Lisaks tavapärasele treenimisele on olemas ka selliseid meetodeid nagu ülekandeõpe. Siin kasutatakse uue sarnase ülesande jaoks mudelit, mis on juba suurel andmestikul treenitud. See säästab aega ja arvutusvõimsust, kuna mudelit ei pea täielikult nullist treenima.
Kasuta oma tugevusi maksimaalselt ära 🚀
Tehisintellekti (AI) toimimine põhineb erinevate sammude keerulisel koosmõjul. Alates andmete sisestamisest ja eeltöötlusest kuni mudeli treenimise, ennustamise ja tagasisideni mõjutavad tehisintellekti täpsust ja tõhusust paljud tegurid. Hästi treenitud tehisintellekt võib pakkuda tohutuid eeliseid paljudes eluvaldkondades – alates lihtsate ülesannete automatiseerimisest kuni keerukate probleemide lahendamiseni. Sama oluline on aga mõista tehisintellekti piiranguid ja võimalikke lõkse, et selle tugevusi parimal viisil ära kasutada.
🤖📚 Lihtsalt seletatuna: kuidas tehisintellekti treenitakse?
🤖📊 Tehisintellekti õppeprotsess: jäädvustamine, linkimine ja salvestamine
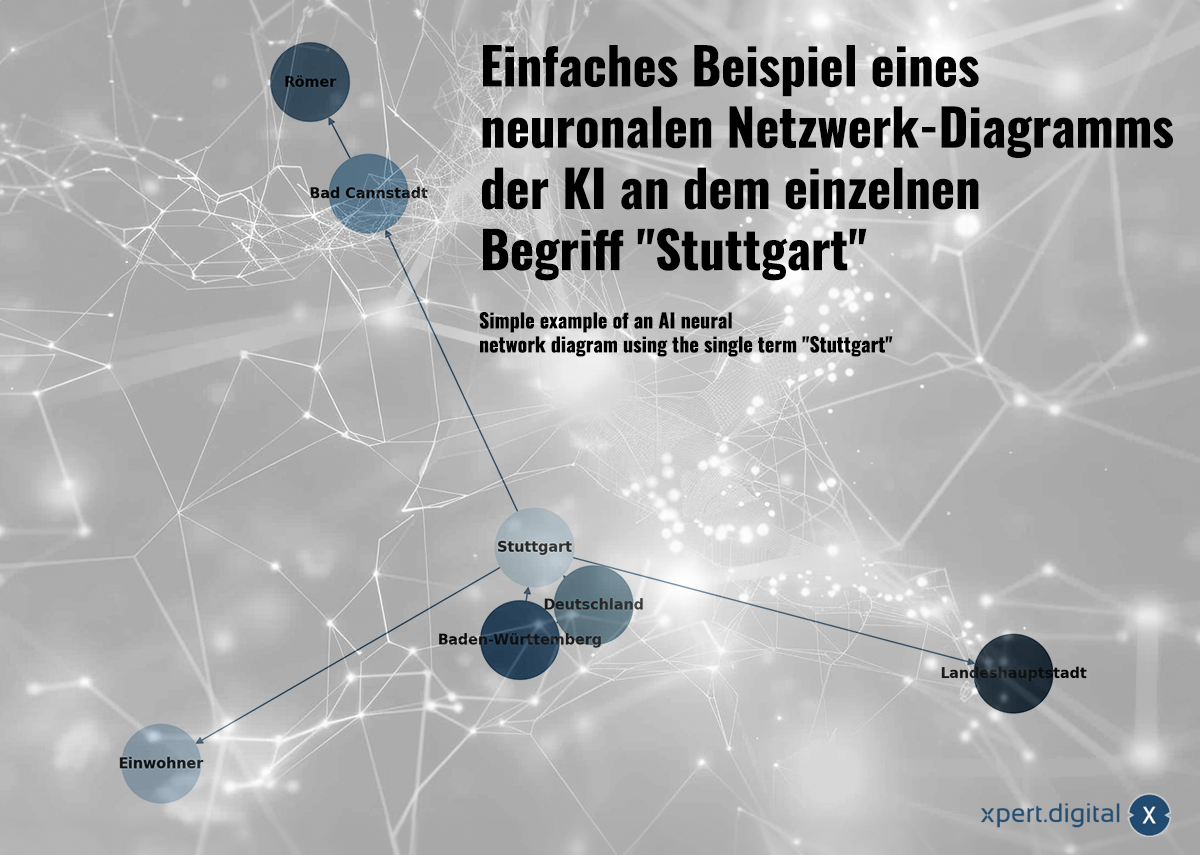
Lihtne näide tehisintellekti närvivõrgu diagrammist, mis kasutab ühte terminit „Stuttgart” – pilt: Xpert.Digital
🌟 Andmete kogumine ja ettevalmistamine
Tehisintellekti õppimisprotsessi esimene samm on andmete kogumine ja ettevalmistamine. Need andmed võivad pärineda erinevatest allikatest, näiteks andmebaasidest, anduritest, tekstidest või piltidest.
🌟 Seostatud andmed (närvivõrk)
Kogutud andmed on omavahel ühendatud närvivõrgus. Iga andmepaketti esindavad ühendused "neuronite" (sõlmede) võrgustikus. Lihtne näide Stuttgarti linna abil võiks välja näha selline:
a) Stuttgart on linn Baden-Württembergis
b) Baden-Württemberg on Saksamaa liidumaa
c) Stuttgart on linn Saksamaal
d) Stuttgartis elas 2023. aastal 633 484 inimest
e) Bad Cannstatt on Stuttgarti ringkond
f) Bad Cannstatti asutasid roomlased
g) Stuttgart on Baden-Württembergi liidumaa pealinn
Sõltuvalt andmemahu suurusest genereeritakse tehisintellekti mudeli abil potentsiaalsete väljundite parameetrid. Näiteks GPT-3-l on ligikaudu 175 miljardit parameetrit!
🌟 Salvestamine ja kohandamine (õppimine)
Andmed suunatakse närvivõrku. Need läbivad tehisintellekti mudeli ja töödeldakse ühenduste kaudu (sarnaselt sünapsidega). Neuronite vahelisi kaalusid (parameetreid) kohandatakse mudeli treenimiseks või ülesande täitmiseks.
Erinevalt tavapärastest salvestusmeetoditest, nagu otsejuurdepääs, indekseeritud juurdepääs, järjestikune või partiisalvestus, salvestavad närvivõrgud andmeid ebatavalisel viisil. „Andmed” salvestatakse neuronite vaheliste ühenduste kaaludesse ja eelpingetesse.
Neuraalvõrgus toimub teabe tegelik "talletamine" neuronite vaheliste ühenduste kaalude kohandamise kaudu. Tehisintellekti mudel "õpib", kohandades neid kaalusid ja eelarvamusi pidevalt sisendandmete ja määratletud õppealgoritmi põhjal. See on pidev protsess, mille käigus mudel saab korduvate kohanduste abil teha täpsemaid ennustusi.
Tehisintellekti mudelit võib vaadelda kui omamoodi programmeerimist, kuna see luuakse määratletud algoritmide ja matemaatiliste arvutuste abil ning selle parameetrite (kaalude) kohandamist täiustatakse pidevalt, et teha täpseid ennustusi. See on pidev protsess.
Eelarvamused on närvivõrkudes täiendavad parameetrid, mis lisatakse neuroni kaalutud sisendväärtustele. Need võimaldavad parameetreid kaaluda (oluline, vähem oluline jne), muutes tehisintellekti paindlikumaks ja täpsemaks.
Neuraalvõrgud ei suuda mitte ainult salvestada üksikuid fakte, vaid ka mustrituvastuse abil tuvastada andmete vahelisi seoseid. Stuttgarti näide illustreerib, kuidas teadmisi saab närvivõrku sisestada, kuid närvivõrgud ei õpi mitte ainult selgesõnaliste teadmiste kaudu (nagu selles lihtsas näites), vaid pigem andmemustrite analüüsi kaudu. Seega ei suuda närvivõrgud mitte ainult salvestada üksikuid fakte, vaid õppida ka sisendandmete vahelisi kaalusid ja seoseid.
See protsess annab arusaadava sissejuhatuse tehisintellekti ja eriti närvivõrkude toimimisse, ilma et peaks tehnilistesse üksikasjadesse liiga süvenema. See demonstreerib, et teavet ei salvestata närvivõrkudes nagu tavapärastes andmebaasides, vaid pigem võrgusiseste ühenduste (kaalude) kohandamise teel.
🤖📚 Täpsemalt: Kuidas tehisintellekti treenitakse?
🏋️♂️ Tehisintellekti, eriti masinõppe mudeli treenimine hõlmab mitut etappi. Tehisintellekti treenimine põhineb mudeli parameetrite pideval optimeerimisel tagasiside ja kohandamise kaudu, kuni mudel toimib esitatud andmete põhjal kõige paremini. Siin on üksikasjalik selgitus selle protsessi toimimise kohta:
1. 📊 Andmete kogumine ja ettevalmistamine
Andmed on tehisintellekti treenimise alus. Tavaliselt koosneb see tuhandetest või miljonitest näidetest, mida süsteem peaks analüüsima. Näideteks on pildid, tekst või aegridade andmed.
Andmeid tuleb puhastada ja normaliseerida, et vältida ebavajalikke veaallikaid. Sageli teisendatakse andmed funktsioonideks, mis sisaldavad asjakohast teavet.
2. 🔍 Määrake mudel
Mudel on matemaatiline funktsioon, mis kirjeldab andmetes esinevaid seoseid. Neuraalvõrkudes, mida tehisintellekti jaoks sageli kasutatakse, koosneb mudel mitmest omavahel ühendatud neuronite kihist.
Iga neuron teeb sisendandmete töötlemiseks matemaatilise operatsiooni ja edastab seejärel signaali järgmisele neuronile.
3. 🔄 Kaalude initsialiseerimine
Neuronite vahelistel ühendustel on algselt juhuslikult määratud kaalud. Need kaalud määravad, kui tugevalt neuron signaalile reageerib.
Treeningu eesmärk on neid kaalusid kohandada nii, et mudel annaks paremaid ennustusi.
4. ➡️ Edasisuunaline levimine
Edasisuunamise ajal töötleb mudel sisendandmeid ennustuse saamiseks.
Iga kiht töötleb andmeid ja edastab need järgmisele kihile, kuni viimane kiht tulemuse annab.
5. ⚖️ Arvutage kaotusfunktsioon
Kahjumisfunktsioon mõõdab, kui hästi mudeli ennustused vastavad tegelikele väärtustele (märgistele). Levinud mõõt on ennustatud ja tegeliku vastuse vaheline viga.
Mida suurem on kaotus, seda halvem on mudeli ennustus.
6. 🔙 Tagasilevi
Pöörditeratsioonis jälgitakse viga mudeli väljundist eelmistesse kihtidesse.
Viga jaotatakse ümber ühenduste kaaludele ja mudel kohandab kaalusid nii, et vead väheneksid.
Seda tehakse gradiendi laskumise abil: arvutatakse gradiendi vektor, mis näitab, kuidas kaalusid tuleks vea minimeerimiseks muuta.
7. 🔧 Kaalude uuendamine
Pärast vea arvutamist uuendatakse ühenduste kaalusid väikese korrigeerimisega, mis põhineb õppimiskiirusel.
Õppimiskiirus määrab, kui palju kaalusid igal sammul muudetakse. Liiga suured muutused võivad muuta mudeli ebastabiilseks, samas kui liiga väikesed muutused aeglustavad õppimisprotsessi.
8. 🔁 Korda (ajastud)
Seda edasiliikumise, vea arvutamise ja kaalu uuendamise protsessi korratakse, sageli mitme epohhi jooksul (läbib kogu andmestiku), kuni mudel saavutab vastuvõetava täpsuse.
Iga ajastuga õpib mudel veidi rohkem ja kohandab oma kaalusid veelgi.
9. 📉 Valideerimine ja testimine
Pärast mudeli treenimist testitakse seda valideeritud andmestiku peal, et kontrollida selle üldistusvõimet. See tagab, et see mitte ainult ei "mälesta" treeningandmeid, vaid teeb ka häid ennustusi tundmatute andmete põhjal.
Testiandmed aitavad mõõta mudeli lõplikku toimivust enne selle praktikas kasutamist.
10. 🚀 Optimeerimine
Mudeli täiustamise edasiste sammude hulka kuuluvad hüperparameetrite häälestamine (nt õppimiskiiruse või võrgustruktuuri reguleerimine), regulariseerimine (ülesobitamise vältimiseks) või andmete hulga suurendamine.
📊🔙 Tehisintellekt: Tehisintellekti musta kasti arusaadavaks, haaratavaks ja selgitatavaks muutmine selgitatava tehisintellekti (XAI), soojuskaartide, asendusmudelite või muude lahenduste abil

Tehisintellekt: tehisintellekti musta kasti arusaadavaks, haaratavaks ja selgitatavaks muutmine selgitatava tehisintellekti (XAI), soojuskaartide, asendusmudelite või muude lahenduste abil – pilt: Xpert.Digital
Tehisintellekti (TI) niinimetatud „must kast“ kujutab endast olulist ja pakilist probleemi. Isegi eksperdid seisavad sageli silmitsi väljakutsega, et nad ei suuda täielikult mõista, kuidas tehisintellekti süsteemid oma otsusteni jõuavad. See läbipaistvuse puudumine võib põhjustada märkimisväärseid probleeme, eriti sellistes kriitilistes valdkondades nagu majandus, poliitika ja meditsiin. Arst, kes tugineb diagnoosimiseks ja ravisoovituste andmiseks tehisintellekti süsteemile, peab oma otsuste tegemisel usaldama. Kui aga tehisintellekti otsustusprotsess ei ole piisavalt läbipaistev, tekib ebakindlus, mis võib viia usalduse puudumiseni – ja seda olukordades, kus inimelud võivad olla ohus.
Lisateavet selle kohta siin:
Oleme teie jaoks olemas - nõuanne - planeerimine - rakendamine - projektijuhtimine
☑️ VKE tugi strateegia, nõuannete, planeerimise ja rakendamise alal
☑️ digitaalse strateegia loomine või ümberpaigutamine ja digiteerimine
☑️ Rahvusvaheliste müügiprotsesside laiendamine ja optimeerimine
☑️ Globaalsed ja digitaalsed B2B kauplemisplatvormid
☑️ teerajaja ettevõtluse arendamine

Konrad Wolfenstein
Aitan teid hea meelega isikliku konsultandina.
Võite minuga ühendust võtta, täites alloleva kontaktvormi või helistage mulle lihtsalt telefonil +49 89 674 804 (München) .
Ootan meie ühist projekti.
Kirjutage mulle

Xpert.Digital - Konrad Wolfenstein
Xpert.digital on tööstuse keskus, mille fookus, digiteerimine, masinaehitus, logistika/intralogistics ja fotogalvaanilised ained.
Oma 360 ° ettevõtluse arendamise lahendusega toetame hästi tuntud ettevõtteid uuest äritegevusest pärast müüki.
Turuluure, hammastamine, turunduse automatiseerimine, sisu arendamine, PR, postkampaaniad, isikupärastatud sotsiaalmeedia ja plii turgutamine on osa meie digitaalsetest tööriistadest.
Lisateavet leiate aadressilt: www.xpert.digital - www.xpert.solar - www.xpert.plus
Ühendust võtma
















