
Struktureeritud andmed (märgistus) tehisintellekti ajastul koos Schema.org-iga: mida Google'i insenerid tegelikult arvavad
Xpert eelväljaanne

Available in 27 languages 📢
Eelista Google'is Xpert.DigitaliⓘAvaldatud: 7. mail 2026 / Uuendatud: 7. mail 2026 – Autor: Konrad Wolfenstein
Struktureeritud andmed (märgistus) tehisintellekti ajastul koos Schema.org-iga: mida Google'i insenerid tegelikult arvavad – Pilt: Xpert.Digital
Google'i SEO saladus: miks tehisintellekt ilma struktureeritud andmeteta ebaõnnestub
Vaatamata ChatGPT-le ja teistele: miks Google'i insenerid jätkavad Schema.org-i nimel vannutamist
SEO värskendus: miks Schema.org asendab nüüd Google'is Open Graphi
SEO maailmas levib püsiv müüt: ajastul, mil tehisintellektil põhinevad keelemudelid suudavad vaevata aru saada isegi struktureerimata tekstist, on hoolikalt hooldatud struktureeritud andmed, näiteks Schema.org, lihtsalt vananenud. Tegelikkus on aga hoopis teine. Google Search Central Live'i üritusel lükkas Google'i insener Ryan Levering selle eksiarvamuse ümber ja tegi ühemõtteliselt selgeks: struktureeritud märgistus ei ole mineviku reliikvia, vaid pigem uue tehisintellektil põhineva otsingu alustala.
Alates uutest tehisintellekti ülevaadetest kuni autonoomsete ostuagentideni vajavad keelemudelid hallutsinatsioonide vältimiseks ja arvutuslikult tõhusaks toimimiseks täpseid ja masinloetavaid juhiseid. Need, kes soovivad tänapäeva veebis nähtavaks jääda, peavad aitama masinatel konteksti mitmetähenduslikult mõista. See artikkel uurib Google'i strateegilist ümberkorraldust, tutvustab revolutsioonilisi uuendusi e-kaubanduse ja kasutajate loodud sisu valdkonnas ning näitab, miks tehniline SEO on nüüd masina nähtavuse võitluses otsustav konkurentsieelis.
Masinad saavad veebi lugeda – aga ainult siis, kui sa aitad neil seda mõista
21. aprillil 2026 toimus Torontos esimene Google Search Central Live'i üritus Kanada pinnal – ja see polnud tavaline tööstusharu kokkutulek. Google Search Engineeringu insener Ryan Levering pidas päeva vaieldamatult kõige tehniliselt tihedama ja strateegiliselt olulisema ettekande: „Struktureeritud andmed, kvaliteet ja tehisintellekt“. Tema esitlus oli enamat kui lihtsalt tehniline ülevaade. See oli selge avaldus semantilise veebi tuleviku kohta ajastul, kus tehisintellekt võtab üha enam enda kanda vahendaja rolli kasutajate ja teabe vahel.
Kahe äärmuse vahel: vale kas-või
Oma ettekande alguses vastandas Ryan Levering SEO-kogukonnas levivaid kahte diametraalselt vastandlikku arvamust. Ühelt poolt valitseb veendumus, et struktureeritud andmed on võimsate keelemudelite ajastul lihtsalt üleliigsed: kui tehisintellekti mudelid suudavad struktureerimata teksti hõlpsalt tõlgendada, miks siis vaeva näha schema.org märgistuse lisamisega lähtekoodile? Teiselt poolt levitavad mõned entusiastid ideed, et struktureeritud andmed on interneti tulevik – universaalne semantiline suhtlusprotokoll autonoomsete tehisintellekti agentide vahel, mis asendab suures osas traditsioonilise veebi.
Levering lükkas tagasi mõlemad äärmused ja esitas selle asemel nüansirikka, empiiriliselt põhjendatud vaatenurga. Mõlemas seisukohas oli tema arvates küll tõetera, kuid kumbki ei kirjeldanud tegelikkust täielikult. See nüanss on iseloomulik Google'i praegusele lähenemisele sellele teemale: asi pole dogmas, vaid pragmaatilises efektiivsuses.
Neli argumenti, mis selgitavad kõike
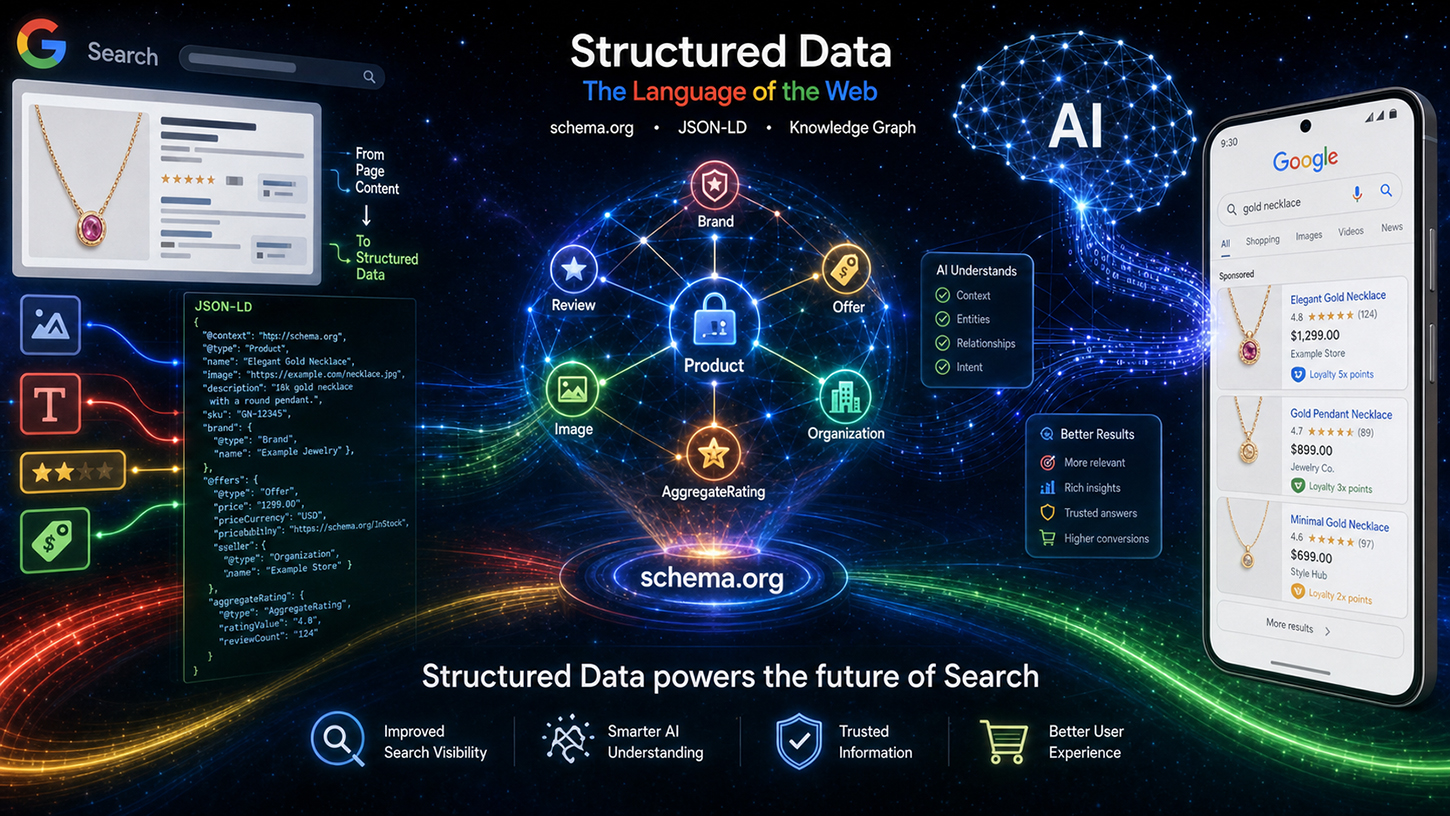
Leveringi keskset argumenti saab kokku võtta nelja põhipunktiga, mida ta täpsustas pealkirja all „Struktureeritud andmete väärtus“. Esimene punkt on täpsus: struktureeritud andmed pakuvad keerukate skeemide, näiteks müügihindade või lojaalsusprogrammide puhul oluliselt suuremat täpsust kui LLM-põhine ekstraheerimine vabast tekstist. Keelemudelid võivad olla eksitavad – need täidavad puuduvad atribuudid, pesastavad andmeid valesti või pääsevad teabele juurde kontekstist välja. Tootehindade ekstraheerimisel suurelt e-kaubanduse saidilt, kus on kümneid sarnaseid tooteid, on tehisintellekti abil tehtud järelduste puhul veamäär oluliselt kõrgem kui puhtalt rakendatud struktureeritud märgistuse puhul.
Teine punkt puudutab lisasisu: struktureeritud andmed sisaldavad sageli nähtamatuid metaandmeid, mida lehe renderdatud HTML-is lihtsalt pole. Täielikud ISO kuupäevavormingud, kasutajate loodud sisu stabiilsed identifikaatorid või sisemised üksuste ID-d – see teave eksisteerib ainult märgistuses. Ükski keelesuund ei suuda tekstist eraldada seda, mida seal pole.
Kolmandaks, efektiivsus: struktureeritud märgistuse parsimine on mitu korda odavam kui suure keelemudeli töötlemine keerukate andmete eraldamiseks. Google indekseerib iga päev miljardeid lehekülgi. Arvutus on lihtne: tavaline JSON-LD-d töötlev parser tarbib murdosa LLM-i järeldusetapi arvutusressurssidest. Seega on struktureeritud andmed mitte ainult semantiliselt paremad, vaid ka ärilisest vaatenurgast oluliselt tõhusamad. See punkt on otseselt seotud Google'i infrastruktuuriga.
Neljas ja võib-olla kõige alahinnatum aspekt on fookus: struktureeritud andmed toovad selgesõnaliselt esile, milline teave lehel on asjakohane, takistades seega tehisintellekti süsteemidel ebaolulise teabe valimist. Tootelehel, kus on põhiartikkel, mitu seotud toodet ja hindadega täidetud navigeerimisriba, ei saa keelemudel ilma selgesõnalise märkuseta kindlalt öelda, millisele hinnale viidata. Struktureeritud märgistus lahendab selle probleemi ühemõttelise omistamise abil.
Kuidas struktureeritud andmeid tegelikult töödeldakse
Levering muutis ka tehnilise töötlusvoo läbipaistvaks. Schema.org andmeid töödeldakse esmalt spetsiifilise puhastuse ja filtreerimise abil, enne kui need liigitatakse indekseeritud andmeteks – jagatakse valdkondadesse nagu sündmused, ostlemine ja arvustused. Seejärel voolavad need ettevalmistatud andmed kahte erinevasse väljundkanalisse: ühelt poolt klassikalisele otsingutulemuste lehele (SRP) ja teiselt poolt kontekstina Google'i tehisintellektil põhinevatele süsteemidele, täpsemalt nn tehisintellekti ülevaadetele (AIO) ja tehisintellekti režiimile (AIM). Struktureeritud andmed ei ole seega enam lihtsalt rikastatud tulemuste tööriist, vaid otsene sisend genereerivate tehisintellekti vastuste jaoks. See kujutab endast olulist nihet schema.org märgistuse strateegilises tähtsuses.
🎯🎯🎯 Andmepõhine B2B tööstuskeskus peaaegu ettevõttesisese lahendusena

Peaaegu ettevõttesisene lahendus: kuidas Xpert.Digital täidab B2B turunduse ja müügi operatiivseid lünki – nutikas sisupõhine äri - pilt: Xpert.Digital
Xpert.Digital on Konrad Wolfenstein juhitav andmepõhine B2B tööstuskeskus. Ettevõte tegutseb tööstuspartneritele välise, peaaegu sisemise lahendusena, täites turunduse, sisu ja müügi operatiivseid lünki – ilma kliendipoolsete lisaressurssideta.
Lisateavet leiate siit:
Miks struktureeritud andmetest on saamas tehisintellekti agentide infrastruktuur?
Ostlemine fookuses: saatmine, lojaalsus ja variatsioonid
Märkimisväärne osa ettekandest keskendus e-kaubanduse innovatsioonidele. Levering selgitas, et Baymard Instituudi andmete kohaselt on ootamatu saatmisinfo ostukorvi hülgamise levinuimate põhjuste seas teisel ja kolmandal kohal. Struktureeritud märgistus saatmisteenuste jaoks saab seda probleemi otseselt lahendada: kaupmehed saavad nüüd koodis täpselt määratleda päritolu- ja sihtpiirkonnad, mõõtmed ja kaalud, tellimuse väärtuse läved, töötlemisajad ja lojaalsusprogrammide kuuluvuse.
Google'i kasutatav tarneaja mudel jaguneb kaheks etapiks: käsitlusaeg ehk aeg tellimuse kättesaamisest kuni vedajale üleandmiseni ja tegelik tarneaeg. Mõlemat etappi saab eraldi ja suure detailsusega märkida – alates tellimuste esitamise tähtaegadest kuni selleni, kas töötlemine toimub ka tööpäeviti. Vastavad JSON-LD näited näitavad, kuidas tüüpi `ShippingConditions` saab kasutada tasuta saatmise määratlemiseks teatud riikidesse (nt Prantsusmaa ja Saksamaa) ja minimaalsete tellimuste väärtuste (nt 50 €) määramiseks.
Saatmisteenuste integreerimine lojaalsusprogrammidega on eriti uuenduslik. Omaduse `validForMemberTier` abil saab saatmisteenuse otseselt siduda liikmeprogrammi ja kindla tasemega. See võimaldab premium-liikmetele saatmishüvesid otse märgistuses deklareerida – funktsioon, mida varem sai konfigureerida ainult Google Merchant Centeri kaudu. Seotud lojaalsusprogramm ise on defineeritud kui `MemberProgram` objekt `Organization` üksuse all, millel on tasemed nagu "Kuld" või "Hõbe" ja seotud eelised nagu lojaalsusauhinnad või punktipreemiad.
Lojaalsusprogrammid semantiliste üksustena
Lojaalsusprogrammide märgistuse kasutuselevõtt on majanduslikult oluline. Organisatsioonid saavad määratleda mitu sõltumatut liikmeprogrammi, millel kõigil on mitu taset ja diferentseeritud eelised – punktid, liikmehinnad, tagastuspoliitika, saatmisboonused. See teave kuvatakse seejärel otse Google'i otsingutulemustes, nagu Levering demonstreeris reaalsete näidetega, sealhulgas Sephora pakkumisega, mis kuvas 30-protsendilist liikmesoodustust otse ostukoodis. Lehekülgedevaheline ID-linkimine, võimalus linkida lojaalsusprogrammide definitsioonidele teistelt lehtedelt, on Leveringi sõnul järgmine kavandatud samm, mille praegune pealkiri on „Tee sillutamine lehtedevahelisele @id-linkimisele“. Eesmärk: tugevamad organisatsioonilised seosed tootelehtede ja ettevõtte poliitikate vahel.
Kasutaja loodud sisu: tehisintellekti märgistamise probleem
Teine oluline teema oli kasutajate loodud sisu (UGC) skeemitüüpide edasiarendamine. Siin on eriti olulised kaks uut funktsiooni. Esiteks toetatakse foorumite ja küsimuste ja vastuste märgistuses manustatud postitusi ja korduspostitusi, mis võimaldab arutelustruktuuride täpsemat semantilist esitamist. Teiseks – ja see on strateegiliselt veelgi olulisem – on kasutusele võetud omadus `so#digitalSourceType`, et selgelt tuvastada masinloodud sisu.
See areng on otsene vastus tehisintellekti loodud sisu tulvale platvormidel nagu foorumid ja küsimuste ja vastuste saidid. Veebimeistrid saavad nüüd deklareerida, kas postitus genereeriti algoritmiliselt või keelemudeli abil. Need, kes seda ei täpsusta, eeldab Google kaudselt inimautoritena – reegel, mis soodustab läbipaistvat märgistamist. Omadus `digitalSourceType` põhineb digitaalsete allikate IPTC koodidel ja eristab muuhulgas algoritmiliselt ja mudeli abil loodud sisu.
Kujutise valik: skeem võidab avatud graafiku
Vähem tähelepanuväärne, kuid praktiliselt tõhus uuendus puudutab Google'i piltide valiku loogikat. Süsteemi konsolideeritakse sisemiselt selge prioriseerimishierarhiaga: Schema.org märgistus, täpsemalt omadused `primaryImageOfPage` ja `mainEntity → image`, on ülimuslik. Alles seejärel järgneb Open Graphi metasilt `og:image`. See muudatus tähendab, et veebisaitide operaatorite jaoks mõjutab põhipildi puhas schema.org implementatsioon otseselt selle kuvamist Google'i otsingutulemustes ja tehisintellekti ülevaadetes – see on konkreetne ja mõõdetav eelis.
Schema.org ise saab investeeringuid
Samuti väärib märkimist Google'i väljakuulutatud taasinvesteering schema.org-i kui avatud spetsifikatsiooni. Mainiti kolme konkreetset meedet: statistika avaldamine üksikute skeemiterminite kasutussageduse kohta (levimusandmed slaidiesitlusena on juba saadaval üksikute terminite, näiteks `digitalSourceType`, kohta, mis sisaldavad teavet umbes 10 000 domeeni kohta), Google'i enda valideerimisreeglite avaldamine masinloetavates standardvormingutes, näiteks SHACL või ShEx, ja parem tugi järjekorrareeglitele. See on oluline, sest see võimaldaks välistel arendajatel luua oma valideerimisvahendeid Google'i standardite põhjal – sõltumatult ametlikest testimisvahenditest, mis aeg-ajalt koormuse all kokku jooksevad.
Valideerimine: kaks tööriista, üks eesmärk
Levering esitles kahte valideerimistööriista, mis täiendavad teineteist, kuid rakendavad erinevaid testimiskriteeriume. Rikkalike tulemuste testimise tööriist aadressil `search.google.com/test/rich-results` aktsepteerib URL-e või puhast JSON-i ja kontrollib, kas märgistus sobib Google'i otsingu rikastatud tulemuste jaoks – seega põhineb see Google'i konkreetsetel nõuetel, mitte schema.org standardil endal. `validator.schema.org` seevastu kontrollib, kas märgistus on schema.org-iga ühilduv, st järgib avatud sõnavara, olenemata sellest, kas Google genereerib selle põhjal rikastatud tulemusi. See viib selge soovituseni veebiarendajatele: tuleks kasutada mõlemat tööriista, sest märgistus võib olla skeemiga ühilduv, kuid mitte rikastatud tulemuste võimekus – ja vastupidi.
Suurem pilt: struktureeritud andmed tehisintellekti infrastruktuurina
Toronto üritust tervikuna vaadates on ilmne nihe, mis ulatub tavapärasest SEO optimeerimisest kaugemale. Struktureeritud andmed arenevad rikaste väljavõtete loomise tööriistast tehisintellekti süsteemide fundamentaalseks andmekihi standardiks. Google'i tehisintellekti ülevaated ja tehisintellekti režiim kasutavad aktiivselt schema.org märgistust vastuste genereerimise ja üksuste kontrollimise kontekstina. Need, kes rakendavad korrektseid, täielikke ja täpseid struktureeritud andmeid, mitte ainult ei paranda oma võimalusi otsingutulemustes visuaalselt esile tõsta, vaid positsioneerivad oma sisu usaldusväärse esmase allikana tehisintellekti vastuste saamiseks.
Universaalse kaubandusprotokolli (UCP) ja WebMCP mainimine selles kontekstis ei ole juhuslik. Mõlemad agendipõhised suhtlusstandardid, mille Google avaldas varajastes versioonides 2026. aastal, nõuavad veebisaitide semantilist kirjeldamist. Schema.org on selle aluseks. Maailmas, kus tehisintellekti agendid tegutsevad veebis autonoomselt, otsides, võrreldes ja algatades tehinguid, ei ole sisu masinloetavus enam valikuline, vaid majandusliku olulisuse eeltingimus. Ryan Leveringi ettekanne Torontos ei olnud seega pelgalt tehniline värskendusaruanne – see oli pilguheit järgmise veebi infrastruktuuri.
Saate 10 sekundiga ise teada
Kui soovite teada, kui hästi ja põhjalikult teie või mõni teine veebisait struktureeritud andmeid kasutab, saate kasutada täpselt kahte tööriista, mida Ryan Levering Google'ist (meie ülaltoodud tekstist) soovitas:
Google'i rikastatud tulemuste test (keskendudes Google'i nähtavusele):
Mine aadressile search.google.com/test/rich-results, kopeeri suvalise xpert.digital artikli URL ja klõpsa nupul „Testi URL-i“. Tööriist näitab sulle täpselt, milliseid märgistusi Google sellel lehel tunneb ja kas need on veatud.
Skeemivalidaator (keskendutakse puhtalt standarditele vastavusele):
Mine aadressile validator.schema.orgja kleebi sama URL. Siin näed otse lähtekoodis värviliselt esile tõstetud JSON-LD skripte (struktureeritud andmed), mille xpert.digital on lisanud.
Teie globaalne turundus- ja äriarenduspartner
☑️ Meie ärikeel on inglise või saksa keel
☑️ UUS: Kirjavahetus teie emakeeles!

Konrad Wolfenstein
Mina ja minu meeskond oleme hea meelega teie käsutuses teie isikliku nõustajana.
Võite minuga ühendust võtta, täites siinse kontaktvormi helistades mulle numbril +49 7348 4088 965. Minu e-posti aadress on [email protected]:või
Ootan põnevusega meie ühist projekti.
☑️ VKEde tugi strateegia, konsultatsioonide, planeerimise ja rakendamise alal
☑️ Digitaalse strateegia loomine või ümberkorraldamine ja digitaliseerimine
☑️ Rahvusvaheliste müügiprotsesside laiendamine ja optimeerimine
☑️ Globaalsed ja digitaalsed B2B kauplemisplatvormid
☑️ Pioneer Äriarendus / Turundus / PR / Messid
B2B tugi ja SaaS SEO ja GEO (tehisintellekti otsingu) jaoks koos: kõik-ühes lahendus B2B ettevõtetele

B2B tugi ja SaaS SEO ja GEO (tehisintellekti otsingu) jaoks koos: kõik-ühes lahendus B2B-ettevõtetele - Pilt: Xpert.Digital
Tehisintellektil põhinev otsing muudab kõike: kuidas see SaaS-lahendus muudab teie B2B edetabelit igaveseks.
B2B-ettevõtete digitaalne maastik on kiirete muutuste läbimas. Tehisintellekti juhtimisel kirjutatakse ümber veebis nähtavuse reegleid. Ettevõtete jaoks on alati olnud väljakutseks mitte ainult olla digitaalses massis nähtav, vaid ka olla asjakohane õigete otsustajate jaoks. Traditsioonilised SEO strateegiad ja kohaliku kohaloleku haldamine (geograafiline turundus) on keerulised, aeganõudvad ning sageli võitlus pidevalt muutuvate algoritmide ja tiheda konkurentsi vastu.
Aga mis siis, kui oleks olemas lahendus, mis mitte ainult ei lihtsustaks seda protsessi, vaid muudaks selle ka nutikamaks, ennustavamaks ja palju tõhusamaks? Siin tulebki mängu spetsialiseeritud B2B-toe ja võimsa SaaS-platvormi (tarkvara teenusena) kombinatsioon, mis on spetsiaalselt loodud SEO ja GEO nõudmiste jaoks tehisintellekti otsingu ajastul.
See uue põlvkonna tööriistad ei tugine enam ainult käsitsi märksõnade analüüsile ja tagasilinkide strateegiatele. Selle asemel kasutab see tehisintellekti, et otsingu kavatsust täpsemalt mõista, kohalikke edetabeli tegureid automaatselt optimeerida ja reaalajas konkurentsianalüüsi teha. Tulemuseks on ennetav, andmepõhine strateegia, mis annab B2B-ettevõtetele otsustava eelise: neid mitte ainult ei leita, vaid tajutakse ka oma niši ja asukoha juhtiva autoriteedina.
Siin on B2B toe ja tehisintellektil põhineva SaaS-tehnoloogia sümbioos, mis muudab SEO ja GEO turundust, ning kuidas teie ettevõte saab sellest kasu, et digitaalses ruumis jätkusuutlikult kasvada.
Lisateavet leiate siit:
















