
Published on: April 15, 2025 / Updated on: April 15, 2025 – Author: Konrad Wolfenstein

AI Search Ranking: Perplexity Sonar's AI models are leaders in the AI search landscape – Image: Xpert.Digital
Sonar Reasoning Pro-High: Perplexity's leap to the top of AI search
AI search systems in transition: Perplexity's milestone in development
Perplexity's Sonar models have achieved impressive results in the latest LM Search Arena evaluation, with Sonar-Reasoning-Pro-High ranking alongside Google's Gemini-2.5-Pro-Grounding. This ranking represents a significant milestone in the evolution of AI search systems and underscores Perplexity's leading position in this highly competitive field.
Related to this:

The LM Search Arena Evaluation
The LM Search Arena is a novel evaluation platform developed by LM Arena to assess search-enhanced AI systems based on human preferences. Unlike previous benchmarks such as SimpleQA, which focused on narrow factual accuracy, the Search Arena evaluates how models perform on real-world user queries in areas such as programming, writing, research, and recommendations.
The evaluation took place between March 18 and April 13, 2025, and collected over 10,000 human preference votes for 11 models. Users were asked to submit queries and then rate which model response better met their information needs.
Outstanding performance of the sonar models
AI Search Ranking: Outstanding performance of sonar models – Image: Perplexity
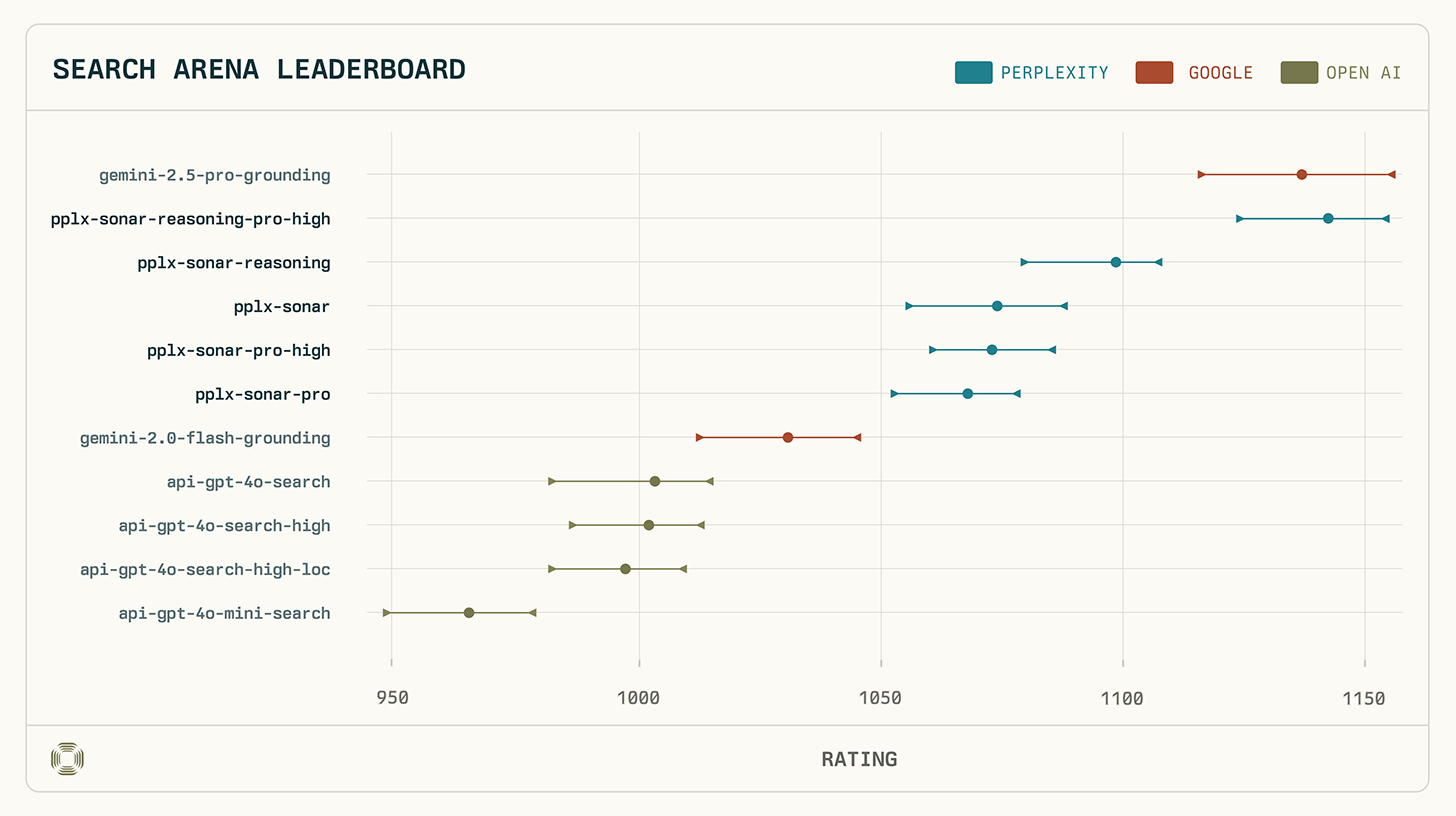
Perplexity's Sonar-Reasoning-Pro-High achieved an Arena score of 1136 (±21/−19), which is statistically equivalent to Google's Gemini-2.5-Pro-Grounding (1142 +14/-17), thus securing a shared top position. Particularly noteworthy is that in direct comparisons, Sonar-Reasoning-Pro-High outperformed Gemini-2.5-Pro-Grounding in 53% of cases.
The dominance of Perplexity in the evaluation is illustrated by the following ranking:
- Gemini 2.5 Pro Grounding (1142 points)
- Sonar Reasoning Pro-High (1136 points)
- Sonar reasoning (1097 points)
- Sonar (1072 points)
- Sonar-Pro-High (1071 points)
- Sonar-Pro (1066 points)
All Perplexity models occupied the top ranks, significantly outperforming other evaluated models from Google (Gemini-2.0-Flash-Grounding) and OpenAI (GPT-4o Search).
Key factors for success
Search Arena identified three factors that correlated strongly with human preference:
More comprehensive answers
Longer answers were preferred by users (coefficient 0.255, p<0.05). The Sonar models provide comprehensive, detailed information on a wide range of topics, leading to higher user satisfaction.
Superiority in source citations
A higher number of citations correlated strongly with user preference (coefficient 0.234, p<0.05). The Sonar models perform a deeper search and cite, on average, 2-3 times more sources than comparable Gemini models. This comprehensive use of sources ensures that the information provided is well-documented and trustworthy.
Using various sources
The evaluation showed that citations from community web sources were particularly valued. The Sonar models are characterized by the effective use of various sources, including YouTube, community platforms, and authoritative sources.
Control experiments confirmed these findings and showed that search depth is a significant performance difference between the models. When controlling for citations, the model rankings converged, suggesting that search depth is a crucial differentiating factor.
Related to this:

The technology behind sonar
Perplexity's sonar model is based on Llama 3.3 70B and has been specifically enhanced to optimize response quality and user experience. It has been trained to improve the factual accuracy and readability of responses.
Speed and performance
Sonar is powered by the Cerebras inference infrastructure and delivers responses at an impressive speed – 1200 tokens per second, enabling near-instantaneous response generation. This speed is almost 10 times faster than comparable models such as Gemini 2.0 Flash.
User preference and performance comparison
Extensive A/B tests showed that Sonar significantly outperforms models like the GPT-4o mini and Claude 3.5 Haiku, and even matches or surpasses the performance of top models like the GPT-4o and Claude 3.5 Sonnet in terms of user satisfaction.
Sonar API: Accessibility for developers
Perplexity also offers its sonar technology via APIs, allowing developers to integrate AI-powered search capabilities into their applications. There are two main versions of the API:
Sonar API
The standard Sonar API is lightweight, cost-effective, fast, and easy to use. It was designed for businesses that need straightforward question-and-answer functionality and are optimized for speed.
Sonar Pro API
For businesses requiring more advanced features, the Sonar Pro API offers the ability to handle more complex, multi-stage queries. It generates, on average, twice as many source citations per search as the standard version and features a larger context window for longer and more nuanced queries.
The pricing structure reflects these differences: Standard Sonar costs $5 per 1,000 searches plus $1 per 750,000 words (combined input and output). Sonar Pro retains the same $5 per 1,000 searches but charges $3 per 750,000 input words and $15 per 750,000 generated words.
From accuracy factors to user-friendliness: Perplexity's sonar impresses
The outstanding results in the LM Search Arena evaluation confirm that Perplexity's Sonar models are among the leading AI search systems. By combining factual accuracy, extensive source citations, and deep search capabilities, they offer a superior user experience.
These successes underscore Perplexity's position as an innovator in the field of AI-powered search and information delivery. The continuous improvement of its models based on user feedback indicates further potential for future developments.
For Perplexity users, these results mean they have access to top-tier accuracy, comprehensive source attribution, and high-quality answers across a wide range of topics. Pro users can further benefit from these powerful models by setting Sonar as their default model in the settings.
Sonar's strong performance in the Search Arena Evaluation not only underlines Perplexity's technological expertise, but also points the way for the future of AI search: more accurate, more comprehensive, and with a deeper understanding of users' information needs.
Related to this:
Your AI transformation, AI integration and AI platform industry expert
☑️ Our business language is English or German
☑️ NEW: Correspondence in your native language!

Konrad Wolfenstein
I and my team are happy to be available to you as your personal advisor.
You can contact me by filling out the contact form here or simply call me at +49 7348 4088 965. My email address is: [email protected]
I'm looking forward to our joint project.








