
Query Fan-Out: En omfattende forklaring af denne transformative AI-søgeteknik
Xpert-forhåndsudgivelse

Available in 27 languages 📢
Foretræk Xpert.Digital på GoogleⓘUdgivet den: 11. november 2025 / Opdateret den: 11. november 2025 – Forfatter: Konrad Wolfenstein
Query Fan-Out: En omfattende forklaring af denne transformative AI-søgeteknik – Billede: Xpert.Digital
Google-patentet, der ændrer alt: Hvad 'Tematisk søgning' afslører om SEO's fremtid
Googles nye vidundervåben: Hvorfor Query Fan-Out vender din SEO-strategi på hovedet
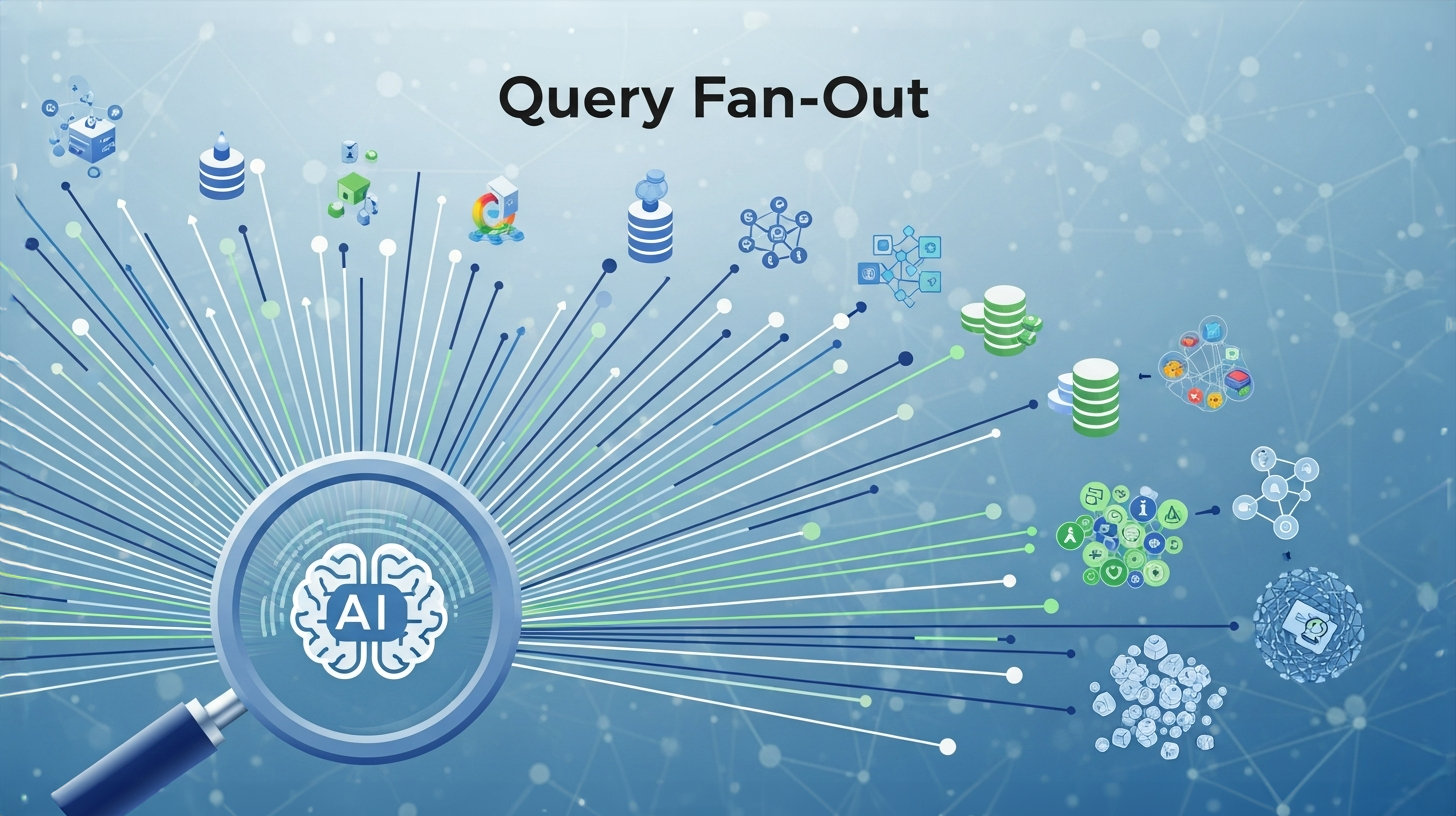
Æraen med simple søgeord og ti blå links er ved at være slut. Kernen i denne udvikling er en revolutionerende teknik kaldet query fan-out, som stille og roligt ændrer, hvordan søgemaskiner som Google fungerer. I stedet for at behandle en søgeforespørgsel som en enkelt, isoleret opgave, spreder denne tilgang systematisk en brugerforespørgsel ud i et helt netværk af relaterede underforespørgsler. Målet er ikke kun at forstå, hvad du eksplicit spørger om, men også hvad du implicit ønsker at vide, for at kunne forudse opfølgende spørgsmål og syntetisere et omfattende svar direkte i søgegrænsefladen.
Dette paradigmeskift, drevet af AI-modeller som Googles Gemini, er mere end blot en teknologisk innovation – det omdefinerer spillereglerne for søgemaskineoptimering (SEO), indholdsskabelse og hele processen med digital informationsindsamling. For indholdsskabere og marketingfolk betyder det at flytte fokus fra individuelle søgeord til omfattende emneklynger og skabe indhold, der adresserer forskellige brugerintentioner samtidigt. I denne omfattende artikel dykker vi dybt ned i query fan-out-verdenen. Vi forklarer dens tekniske funktionalitet, den grundlæggende forskel fra traditionel søgning, dens afgørende rolle i indholdsstrategier, og hvordan du kan optimere dit indhold i dag til fremtidens søgning.
Hvad er Query Fan-Out?
Query fan-out refererer til en sofistikeret metode til informationssøgning, hvor en enkelt brugers søgeforespørgsel systematisk opdeles i flere relaterede underforespørgsler. Denne teknik bruges især af moderne AI-drevne søgesystemer såsom Google AI Mode, ChatGPT og andre store sprogmodeller. Udtrykket "fan-out" stammer oprindeligt fra elektronik og datalogi og beskriver distributionen af et signal eller en datastrøm fra én kilde til flere destinationer.
I forbindelse med søgemaskineoptimering og kunstig intelligens betyder query fan-out, at systemet ikke kun søger efter den nøjagtige ordlyd af brugerens forespørgsel, men også analyserer denne forespørgsel semantisk, opdeler den i dens komponenter og samtidig genererer flere tematisk relaterede søgeforespørgsler. Disse underforespørgsler udføres derefter samtidigt på tværs af forskellige datakilder for at muliggøre et mere omfattende og kontekstrigt svar.
Metoden er baseret på forståelsen af, at brugerne ofte ikke præcist formulerer, hvad de rent faktisk leder efter, eller at deres forespørgsel indeholder adskillige implicitte informationsbehov. Query Fan-Out forsøger at genkende disse skjulte intentioner og proaktivt adressere dem, før brugeren overhovedet behøver at stille opfølgende spørgsmål.
Hvordan fungerer Query Fan-Out teknisk set?
Den tekniske implementering af Query Fan-Out foregår i flere på hinanden følgende trin, hvilket kræver et komplekst samspil mellem forskellige AI-komponenter.
Processen begynder med analysen af den oprindelige søgeforespørgsel. En stor sprogmodel som Gemini fortolker først brugerens input og identificerer den centrale intention og semantiske kontekst. Dette involverer indfangning af sproglige træk, enheder og den underliggende brugerintention. Denne fase kaldes forespørgselsdekomposition og danner grundlag for alle efterfølgende trin.
Den egentlige udvidelse af forespørgslen finder derefter sted. Systemet genererer mellem fem og femten relaterede underforespørgsler, der dækker forskellige facetter af det oprindelige informationsbehov. Disse syntetiske forespørgsler oprettes i henhold til strukturerede mønstre baseret på intentionsdiversitet, leksikalsk variation og entitetsbaserede omformuleringer. Hvis en bruger f.eks. søger efter "bedste Bluetooth-hovedtelefoner", kan systemet samtidig generere forespørgsler som "bedste over-ear Bluetooth-hovedtelefoner", "mest komfortable Bluetooth-hovedtelefoner under €200", "Bluetooth-hovedtelefoner til sport" og "støjreducerende versus almindelige Bluetooth-hovedtelefoner".
De genererede underforespørgsler udføres derefter parallelt på tværs af forskellige datakilder. Dette inkluderer det aktive webindeks, vidensgrafen, specialiserede databaser såsom Google Shopping Graph og andre vertikale søgeindekser. Denne parallelle behandling er et kerneelement i fan-out-arkitekturen og gør det muligt for systemet at indsamle en bred informationsbase på meget kort tid.
I næste trin analyseres og evalueres de indsamlede resultater. Systemet bruger Googles rangerings- og kvalitetssignaler til at vurdere relevansen og troværdigheden af hver enkelt funden information. Dette involverer ikke kun at overveje hele websider, men også at undersøge individuelle tekstpassager for at sikre, at de er egnet til at besvare specifikke underspørgsmål.
Endelig syntetiseres al den indsamlede information til et sammenhængende svar. En generativ sprogmodel kombinerer den mest relevante information fra de forskellige kilder og skaber et omfattende, kontekstrigt svar på den oprindelige forespørgsel. Dette svar tager hensyn til både eksplicitte og implicitte aspekter af brugerens intention og giver ofte yderligere information, som brugeren muligvis har brug for som det næste.
Hvilke typer forespørgselsvarianter genereres?
Query fan-out-teknikken genererer systematisk forskellige typer underforespørgsler for at dække forskellige aspekter af informationsbehovet.
Semantiske udvidelser udgør en første kategori og omfatter synonymer såvel som alternative formuleringer af den oprindelige forespørgsel. Hvis nogen søger efter "motorkøretøj", vil systemet også overveje varianter som "bil", "personbil" eller "køretøj".
Intentionsbaserede varianter fokuserer på forskellige brugerintentioner. Disse omfatter sammenlignende forespørgsler, som sammenligner forskellige muligheder; udforskende forespørgsler, som uddyber den grundlæggende forståelse af et emne; og beslutningsorienterede forespørgsler, der har til formål at hjælpe med specifikke købsbeslutninger. En original forespørgsel som "Python Threading" kan generere både tutorialforespørgsler til en programmeringskontekst og biologiske forespørgsler om slangeadfærd.
Samtale- og opfølgende forespørgsler udgør en anden vigtig kategori. Systemet forudser, hvilke opfølgende spørgsmål brugeren sandsynligvis vil stille, og integrerer proaktivt svarene i det indledende svar. Dette skaber en dialoglignende søgeoplevelse, hvor brugeren ikke behøver at indsende flere forespørgsler i træk.
Enhedsbaserede omformuleringer fokuserer på specifikke brands, produkter, steder eller personer, der kan være relevante i konteksten af den oprindelige forespørgsel. Hvis nogen søger efter "projektledelsessoftware", vil specifikke enheder som "Asana", "Trello" eller "Monday.com" blive inkluderet i underforespørgslen.
Regionale og kontekstuelle variationer tager højde for geografiske træk og tidsmæssige aspekter. En forespørgsel efter "restauranter i nærheden" kl. 11:45 på en hverdag ville specifikt prioritere frokostmuligheder, mens den samme forespørgsel om aftenen ville fremhæve middagsmuligheder.
Hvordan adskiller forespørgselsfanout sig fra traditionel søgning?
Forskellen mellem query fan-out og traditionel søgemaskineoptimering er fundamental og ændrer den måde, indhold skal oprettes og optimeres på.
Traditionelle søgemaskiner fungerer ud fra princippet om direkte søgeordsmatchning. En søgeforespørgsel behandles som en enkelt, isoleret forespørgsel, og systemet søger efter websider, der indeholder disse præcise termer eller lignende variationer. Resultaterne præsenteres som en rangeret liste over links, som brugeren skal klikke igennem et efter et for at finde de ønskede oplysninger.
Query Fan-Out udvider derimod en enkelt forespørgsel til et netværk af relaterede søgeforespørgsler. I stedet for at søge efter præcise matches analyserer systemet den semantiske betydning og kontekst af forespørgslen. Det forsøger at forstå den underliggende hensigt og overvejer forskellige mulige fortolkninger samtidigt.
Måden resultaterne præsenteres på er også fundamentalt forskellig. Mens traditionel søgning leverer en liste med blå links, præsenterer et forespørgselsbaseret fan-out-system et syntetiseret, samtalebaseret svar direkte i søgegrænsefladen. Dette svar kombinerer information fra flere kilder og er struktureret til omfattende at imødekomme brugerens informationsbehov uden at kræve, at de besøger flere websteder.
En anden vigtig forskel ligger i håndteringen af intention. Traditionel søgning fokuserer på eksplicitte søgeord og kan kun i begrænset omfang indfange implicit intention. Query fan-out tager derimod hensyn til både eksplicit og implicit brugerintention og kan forudse opfølgende spørgsmål, før de stilles.
Personalisering når en ny dimension med Query Fan-Out. Mens traditionel søgning primært er baseret på søgehistorik, integrerer Query Fan-Out omfattende kontekst såsom placering, aktuelle kalenderopgaver, kommunikationsmønstre og enhedstype. En søgning efter "timian" ville give andre resultater for en bruger, der i øjeblikket laver mad, end for en person, der er interesseret i botanik.
Hvilken rolle spiller query fan-out i RAG-systemer?
Forespørgselsfan-out er en integreret del af moderne systemer til udvidet hentning og fungerer som en yderst sofistikeret hentningsmekanisme.
RAG-systemer kombinerer styrkerne ved informationssøgning og generativ kunstig intelligens. I stedet for udelukkende at stole på den forudtrænede viden om en sprogmodel, supplerer de den gennem adgang til eksterne datakilder i realtid. Dette reducerer problemet med hallucinationer, hvor kunstig intelligens-systemer genererer plausibelt lydende, men faktuelt ukorrekte oplysninger.
I denne ramme fungerer forespørgselsfan-out som en flertrins hentningsproces. I stedet for en enkelt, simpel forespørgsel, hvor systemet søger efter dokumenter, der matcher den oprindelige forespørgsel, udfører fan-out en flerlags, parallel informationsindsamlingsproces. Ved at opdele forespørgslen identificerer systemet alle de forskellige nødvendige informationsfacetter og indsamler derefter et betydeligt rigere og mere forskelligartet sæt af kontekstuelle dokumenter og datapunkter.
Denne udvidede kontekstbase sendes derefter til den generative komponent i RAG-systemet. Sprogmodellen modtager ikke kun information om den oprindelige forespørgsel, men også en forbehandlet, mangesidet kontekst, der dækker forskellige perspektiver og aspekter af emnet. Dette forbedrer kvaliteten, nøjagtigheden og fuldstændigheden af det endelige svar dramatisk.
Fan-out-tilgangen gør det også muligt for RAG-systemer at besvare komplekse, flerlagede forespørgsler, der tidligere ikke blev besvaret klart online. Ved at kombinere flere informationskilder kan der drages nye konklusioner, der rækker ud over de enkelte kilder.
En anden fordel ligger i den forbedrede aktualitet. Mens den forudtrænede viden om en sprogmodel er fastsat til et specifikt tidspunkt, giver kombinationen med query fan-out adgang til aktuelle oplysninger fra det live web, vidensgrafer og specialiserede databaser.
Hvad er betydningen af Googles patent på tematisk søgning?
Patentet, der blev indgivet af Google i december 2024 med titlen "Tematisk søgning", giver vigtig indsigt i den tekniske implementering af query fan-out-teknikken.
Patentet beskriver et tematisk søgesystem, der organiserer relaterede søgeresultater for en forespørgsel i kategorier kaldet temaer. Der genereres et kort resumé for hvert af disse temaer, hvilket giver brugerne mulighed for at forstå svarene på deres spørgsmål uden at skulle klikke på links til forskellige websteder.
Den automatiske identifikation af emner fra traditionelle søgeresultater ved hjælp af kunstig intelligens er særligt innovativ. Systemet genererer informative resuméer for hvert emne ved at tage hensyn til både indholdet og konteksten af søgeresultaterne.
Et centralt aspekt ved patentet er genereringen af underforespørgsler. En enkelt brugerforespørgsel kan udløse flere søgeforespørgsler baseret på specifikke underemner i den oprindelige forespørgsel. Hvis nogen f.eks. søger efter "at bo i by X", kan systemet automatisk generere underemner som "kvarter A", "kvarter B", "kvarter C", "leveomkostninger", "fritidsaktiviteter" og "fordele og ulemper".
Patentet beskriver også en iterativ proces. Valg af et underemne kan få systemet til at hente et andet sæt søgeresultater og generere endnu mere specifikke emner. Dette muliggør en gradvis udforskning af stadig mere specifikke aspekter af et emne.
Parallellerne til Googles officielle beskrivelse af Query Fan-Out-teknikken er slående. Begge tilgange involverer samtidig udførelse af flere relaterede søgeforespørgsler på tværs af forskellige underemner og datakilder, efterfulgt af syntetisering af resultaterne til et letforståeligt svar.
Patentet demonstrerer også, hvordan præsentationen af søgeresultater fundamentalt ændrer sig. I stedet for at vise links sorteret efter traditionelle rangeringsfaktorer, grupperes resultaterne efter tematiske klynger. Det betyder, at et websted, der muligvis ikke rangerer først for den oprindelige forespørgsel, stadig kan vises fremtrædende, hvis det bidrager til et relevant underemne.
B2B-support og SaaS til SEO og GEO (AI-søgning) kombineret: Alt-i-én-løsningen til B2B-virksomheder

B2B-support og SaaS til SEO og GEO (AI-søgning) kombineret: Alt-i-én-løsningen til B2B-virksomheder - Billede: Xpert.Digital
AI-søgning ændrer alt: Hvordan denne SaaS-løsning vil revolutionere din B2B-rangering for altid.
Det digitale landskab for B2B-virksomheder er under hastig forandring. Drevet af kunstig intelligens omskrives reglerne for online synlighed. For virksomheder har det altid været en udfordring ikke kun at være synlig i den digitale masse, men også at være relevant for de rigtige beslutningstagere. Traditionelle SEO-strategier og håndtering af lokal tilstedeværelse (geo-marketing) er komplekse, tidskrævende og ofte en kamp mod konstant skiftende algoritmer og intens konkurrence.
Men hvad nu hvis der fandtes en løsning, der ikke blot forenklede denne proces, men også gjorde den smartere, mere prædiktiv og langt mere effektiv? Det er her, kombinationen af specialiseret B2B-support med en kraftfuld SaaS-platform (Software as a Service) kommer i spil, specifikt designet til kravene fra SEO og GEO i AI-søgningens tidsalder.
Denne nye generation af værktøjer er ikke længere udelukkende afhængige af manuel søgeordsanalyse og backlink-strategier. I stedet udnytter den kunstig intelligens til mere præcist at forstå søgeintention, automatisk optimere lokale rangeringsfaktorer og udføre konkurrenceanalyser i realtid. Resultatet er en proaktiv, datadrevet strategi, der giver B2B-virksomheder en afgørende fordel: De bliver ikke kun fundet, men opfattet som den førende autoritet inden for deres niche og placering.
Her er symbiosen mellem B2B-support og AI-drevet SaaS-teknologi, der transformerer SEO- og GEO-marketing, og hvordan din virksomhed kan drage fordel af den for at vokse bæredygtigt i det digitale rum.
Mere information her:
Forklaring af Query Fan-Out: Hvorfor din indholdsstrategi nu har brug for emner i stedet for søgeord
Hvordan påvirker Query Fan-Out indholdsstrategi?
Indvirkningen af forespørgselsfan-out på indholdsstrategier er dybtgående og kræver en gentænkning af tilgangen til søgemaskineoptimering.
Det mest betydningsfulde paradigmeskift involverer fokusskiftet fra individuelle søgeord til emneklynger. Hvor traditionel SEO fokuserede på rangering for specifikke søgeord, skal indholdsskabere nu dække hele emneområder på en omfattende måde. En enkelt artikel bør ikke kun besvare hovedspørgsmålet, men også forudse sandsynlige opfølgende spørgsmål og relaterede aspekter.
Betydningen af søjlesider og emneklynger stiger markant. En søjlesider dækker omfattende et kernemne, mens indhold fra sammenkædede klynger dykker dybere ned i specifikke underemner. Denne struktur afspejler naturligt, hvordan forespørgselsopdeling organiserer og henter information.
Indhold skal nu adressere anmodninger fra flere intentioner. I stedet for at optimere til en enkelt brugerintention, bør indhold adressere forskellige intentioner samtidigt. For eksempel bør en artikel om "projektstyringssoftware" dække sammenligninger, prisstrukturer, integrationsmuligheder, brugeradoption og use cases for forskellige teamstørrelser.
Strukturering af indhold bliver stadig vigtigere. Tydelige overskrifter, FAQ-sektioner, tabeller og punktopstillinger hjælper AI-systemer med hurtigt at udtrække specifikke oplysninger. Indhold bør organiseres, så individuelle sektioner kan fungere som selvstændige svar på underspørgsmål.
Enheder og deres relationer bliver stadig vigtigere. Indhold bør tydeligt navngive relevante enheder og eksplicit angive deres relationer. Dette hjælper AI-systemer med korrekt at finde indhold i vidensgrafen og tage det i betragtning i relevante underforespørgsler.
Emnedækningens dybde bliver vigtigere end søgeordstætheden. Fokus bør være på at besvare så mange forventede spørgsmål om et emne som muligt, ikke på hyppig gentagelse af et specifikt søgeord. Omfattende, velundersøgt indhold, der udforsker et emne fra forskellige perspektiver, foretrækkes.
Dette udgør en særlig udfordring for B2B-marketingfolk. Da købsbeslutninger ofte involverer flere interessenter med forskellige prioriteter, skal indhold behandle spørgsmål fra forskellige beslutningstagere samtidigt. En CFO er interesseret i prisstrukturer, IT-afdelingen i integrationer, og ledere i ROI-aspekter.
Hvilken rolle spiller strukturerede data og skemamarkup?
Strukturerede data og skemamarkup spiller en central rolle i optimering i et forespørgselsfan-out-miljø.
Schema-markup fungerer som en kode, der identificerer og kategoriserer indhold for AI-systemer. Mens mennesker kan læse tekst og forstå dens betydning, har AI-systemer brug for eksplicitte signaler for at skelne mellem forskellige typer information. Hvis en produktanmeldelse er markeret med et skema, forstår AI-systemet "dette er en anmeldelse" i modsætning til generisk tekst.
FAQ-skemaer er særligt værdifulde til udbredelse af forespørgsler, fordi de strukturerer ofte stillede spørgsmål og deres svar. Undersøgelser viser, at FAQ-skemaer optræder i 73 procent af AI-genererede svar, fordi de præcist matcher, hvordan AI-systemer håndterer forespørgsler med flere intentioner. Dette format giver AI-systemer mulighed for hurtigt at identificere relevante spørgsmål-svar-par og integrere dem i syntetiserede svar.
Et vejledningsskema strukturerer trinvise instruktioner og er ideelt til procesorienterede søgeforespørgsler. Dette skema bør indeholde klare trinbeskrivelser, estimerede behandlingstider, nødvendige værktøjer og forventede resultater.
Et produktskema identificerer produktspecifikationer, priser og vurderinger og hjælper AI-systemer med at udtrække detaljer til sammenligningsforespørgsler. Alle relevante produktegenskaber bør inkluderes – funktioner, dimensioner, kompatibilitet og prispunkter.
Organisationsskemaet identificerer forretningsdetaljer og ekspertiseområder og opbygger autoritetssignaler, som AI-systemer bruger til at vurdere kildens troværdighed. Det bør specificere ekspertiseområder, kontaktoplysninger og branchefokus.
Anmeldelsesskemaet fremhæver kundefeedback, som AI-platforme prioriterer, fordi de foretrækker kilder med verificeret socialt bevis. Artikelskemaet hjælper AI-systemer med at forstå indholdstype, udgivelsesdato og forfatterekspertise.
For at opnå maksimal effekt kan flere skematyper kombineres på relevante sider. Produktsider kan for eksempel samtidig indeholde produkt-, anmeldelses- og organisationsskemaer for at give omfattende oplysninger, som AI-systemer kan referere til.
Undersøgelser viser, at 61 procent af de sider, der citeres af ChatGPT, bruger schema markup. Dette understreger vigtigheden af strukturerede data for synlighed i AI-drevne søgesystemer.
Hvordan kan jeg optimere til forespørgselsfanout?
Optimering til forespørgselsudbredelse kræver en holistisk tilgang, der kombinerer tekniske, indholdsrelaterede og strategiske elementer.
Omfattende emnedækning danner fundamentet. Indholdet bør ikke kun dække et emne overfladisk, men også dykke ned i det og udforske dets forskellige facetter. Det betyder at skabe søjlesider, der omfattende behandler et kerneemne, suppleret med klyngeindhold, der beskriver specifikke underaspekter.
FAQ-sektioner bør bruges strategisk til at behandle relaterede spørgsmål og underforespørgsler. Disse bør ikke være vilkårlige, men snarere systematisk forudse sandsynlige opfølgende spørgsmål, som en bruger måtte have. Hver kombination af spørgsmål og svar bør give komplette, selvstændige oplysninger, som AI-systemer nemt kan udtrække og citere.
Der skal opbygges semantisk infrastruktur. Indhold bør optimeres med hensyn til mening, kontekst og intention, ikke kun nøgleord. Det betyder at udforske underemner, besvare relaterede spørgsmål og gøre den samlede dækning så omfattende som muligt.
En klar indholdsstruktur er afgørende. Brug af tydelige overskrifter (H2, H3), punktopstillinger til lister, korte afsnit og tabeller til sammenligninger gør det lettere for AI-systemer at analysere information. Indhold bør organiseres på en sådan måde, at AI-værktøjer hurtigt kan finde specifikke svar.
Enhedsdefinition og relationskortlægning hjælper AI-systemer med korrekt at forstå og lokalisere indhold. Relevante enheder bør navngives tydeligt, og deres relationer til hinanden bør gøres eksplicitte. Dette gør det muligt for AI-systemer at overveje indhold på tværs af forskellige relaterede underforespørgsler.
Det er især vigtigt at give svarene på forhånd. De mest relevante oplysninger bør være i begyndelsen, uden lange introduktioner eller irrelevante detaljer. En direkte tilgang som: "For at forny dit pas skal du bruge en udfyldt DS-82-formular, et nyligt foto og betaling. Her er hele processen:" går direkte til sagen.
Implementering af omfattende skemaopmærkning på tværs af hele webstedet er ikke valgfrit, men en strategisk nødvendighed. Dette inkluderer et FAQ-skema for ofte stillede spørgsmål, et vejledningsskema for instruktioner, et produktskema for produktinformation og et organisationsskema for virksomhedsdetaljer.
Fokus bør være på optimering på klyngeniveau. I stedet for at målrette individuelle søgeord bør bredere søgeordsgrupper og overordnede emner tages op. Dette skaber et stærkere indholdsfundament, der er mindre modtageligt for ændringer i individuelle søgeord og variationen i udskiftninger.
Det er afgørende at undgå indholdskannibalisering. Efterhånden som der skabes mere indhold, er det vigtigt at sikre, at siderne ikke konkurrerer om de samme søgeord. Dette forvirrer søgemaskiner og udvander autoritet.
Hvilke udfordringer præsenterer forespørgselsfanout?
Udbredelse af forespørgsler præsenterer betydelige udfordringer for både indholdsskabere og tekniske implementeringer.
Den ikke-deterministiske natur af fan-out-forespørgsler er en central udfordring. De genererede underforespørgsler kan variere, selv for den samme forespørgsel på den samme enhed. Denne variabilitet betyder, at i modsætning til traditionelle SEO-rangeringer, som er relativt stabile, kan synligheden under forespørgselsfan-out svinge betydeligt fra bruger til bruger og fra forespørgsel til forespørgsel.
Det bliver fundamentalt vanskeligere at forudsige rangeringer. Mens traditionel SEO giver mulighed for relativt præcise vurderinger af ens position for specifikke søgeord gennem løbende overvågning, gør forespørgselsopdeling dette betydeligt mere komplekst. Indhold rangerer muligvis ikke fremtrædende for den oprindelige forespørgsel, men bliver stadig citeret for en specifik underforespørgsel.
Øget latenstid kan forekomme med synkron fan-out, fordi den samlede svartid afhænger af den langsomste downstream-anmodning. Hvis en af de parallelle underanmodninger tager særlig lang tid, vil hele svaret blive forsinket.
Fejludbredelse udgør en risiko. En enkelt fejl i en downstream-anmodning kan kaskadere opad og påvirke hele anmodningen. Dette nødvendiggør robuste fejlhåndteringsmekanismer såsom afbrydere og timeouts.
Kompleksiteten af overvågning stiger betydeligt. Sporing og fejlfinding af flerforgrenede anmodningstræer er vanskeligere. Dette kræver end-to-end-sporing og avancerede observationsværktøjer såsom OpenTelemetry, Jaeger eller Zipkin.
Indholdskannibalisering bliver et større problem. Med behovet for at skabe bredere indholdsklynger øges risikoen for, at forskellige websteder konkurrerer om lignende emner og stjæler hinandens synlighed.
Det bliver mere komplekst at måle succes. Traditionelle SEO-målinger som søgeordsrangeringer og organisk trafik giver ikke længere det komplette billede. Der skal udvikles nye målinger, der indfanger synlighed på tværs af forskellige udbredelsesscenarier.
Ressourceforbruget stiger. Det kræver mere tid, ekspertise og budget at skabe virkelig omfattende indhold, der adresserer forskellige underspørgsmål, end at optimere for individuelle søgeord. Organisationer skal tilpasse deres indholdsstrategier og -processer i overensstemmelse hermed.
Personalisering tilføjer endnu et lag af kompleksitet. Da anmodninger om udbredelse kan variere afhængigt af brugerkontekst, placering, enhedstype og andre faktorer, bliver det endnu vanskeligere at forudsige, hvilket indhold der vil være synligt for hvilken brugergruppe.
Hvordan ændrer Query Fan-Out fremtiden for søgning?
Query Fan-Out repræsenterer et fundamentalt paradigmeskift i udviklingen af søgemaskiner og har vidtrækkende konsekvenser for fremtiden for informationssøgning.
Skiftet fra søgeordsmatchning til forståelse af intentioner er allerede godt i gang. Fremtidige søgesystemer vil blive endnu bedre til at forstå den underliggende intention bag forespørgsler, selvom de er upræcise eller ufuldstændige. Det betyder, at brugerne vil bruge mindre tid på at forfine deres forespørgsler og vil få brugbare svar hurtigere.
Integrationen af personlig kontekst vil blive dybere. Søgesystemer vil i stigende grad levere personlige resultater baseret ikke kun på søgehistorik, men også på en omfattende forståelse af brugeren, herunder aktuelle opgaver, placering, præferencer og social kontekst. Dette vil gøre søgeresultaterne endnu mere dynamiske og individualiserede.
Rollen af brands og autoriteter vil ændre sig. Mens rangering for specifikke søgeord traditionelt var altafgørende, vil fokus i stigende grad skifte til at etablere sig som en pålidelig kilde på tværs af et helt emneområde. Brands, der leverer omfattende indhold af høj kvalitet på tværs af emneklynger, vil blive foretrukket i udbredelsesscenarier.
Synligheden bliver mere fragmenteret og mangfoldig. I stedet for at rangere for en håndfuld hovednøgleord, bliver succesfulde hjemmesider citeret på tværs af mange forskellige underordnede søgeord. Dette nødvendiggør en bredere indholdsstrategi og gør nicheindhold mere værdifuldt.
Brugeradfærd vil fortsætte med at ændre sig. Med stadig mere direkte, syntetiserede svar i søgegrænsefladen vil brugerne klikke sjældnere på eksterne websteder. Dette har konsekvenser for webstedstrafik og monetiseringsmodeller, som skal tilpasses denne nye virkelighed.
Multimodal søgning bliver stadig vigtigere. Fremtidige fan-out-systemer vil ikke kun tage hensyn til tekst, men også integrere billeder, videoer, lyd og andre medieformater i deres underforespørgsler og syntese. Dette kræver indholdsstrategier, der går ud over ren tekst.
Sammenlægningen af søgning og samtale vil fortsætte. Udbredelse af forespørgsler muliggør allerede dialoglignende søgeoplevelser, der forudser opfølgende spørgsmål. I fremtiden vil grænsen mellem søgemaskiner og samtalebaserede AI-assistenter blive endnu mere sløret.
Betydningen af strukturerede data og det semantiske web vil vokse eksponentielt. Jo bedre indhold er semantisk annoteret og struktureret, desto mere effektivt kan AI-systemer bruge det i fan-out-scenarier. Dette vil gøre standarder som Schema.org endnu mere afgørende.
Query Fan-Out markerer således ikke blot en teknisk innovation, men et fundamentalt skift i forholdet mellem brugere, information og teknologi. Evnen til at forudse og proaktivt imødekomme komplekse informationsbehov vil definere den næste generation af intelligente søgesystemer.
Din globale marketing- og forretningsudviklingspartner
☑️ Vores forretningssprog er engelsk eller tysk
☑️ NYT: Korrespondance på dit modersmål!

Konrad Wolfenstein
Jeg og mit team er glade for at stå til rådighed for dig som din personlige rådgiver.
Du kan kontakte mig ved at udfylde kontaktformularen her eller blot ringe til mig på +49 89 89 674 804 ( München) . Min e-mailadresse er: [email protected]
Jeg glæder mig til vores fælles projekt.
☑️ SMV-support inden for strategi, rådgivning, planlægning og implementering
☑️ Oprettelse eller omlægning af den digitale strategi og digitalisering
☑️ Udvidelse og optimering af internationale salgsprocesser
☑️ Globale og digitale B2B-handelsplatforme
☑️ Pioner inden for forretningsudvikling / marketing / PR / messer
Vores globale branche- og økonomiske ekspertise inden for forretningsudvikling, salg og marketing

Vores globale branche- og økonomiske ekspertise inden for forretningsudvikling, salg og marketing - Billede: Xpert.Digital
Branchefokusområder: B2B, digitalisering (fra AI til XR), maskinteknik, logistik, vedvarende energi og industri
Mere information her:
Et tematisk knudepunkt, der tilbyder indsigt og ekspertise:
- Vidensplatform, der dækker globale og regionale økonomier, innovation og branchespecifikke tendenser
- En samling af analyser, indsigter og baggrundsinformation fra vores vigtigste fokusområder
- Et sted for ekspertise og information om aktuelle udviklinger inden for erhvervsliv og teknologi
- Et knudepunkt for virksomheder, der søger information om markeder, digitalisering og brancheinnovationer
🎯🎯🎯 Drag fordel af Xpert.Digital's omfattende, femdobbelte ekspertise i én omfattende servicepakke | BD, R&D, XR, PR & optimering af digital synlighed

Drag fordel af Xpert.Digital's omfattende, femdobbelte ekspertise i en omfattende servicepakke | R&D, XR, PR & optimering af digital synlighed - Billede: Xpert.Digital
Xpert.Digital besidder dybdegående viden på tværs af forskellige brancher. Dette giver os mulighed for at udvikle skræddersyede strategier, der er præcist afstemt med kravene og udfordringerne i dit specifikke markedssegment. Ved løbende at analysere markedstendenser og overvåge brancheudviklingen kan vi handle proaktivt og tilbyde innovative løsninger. Kombinationen af erfaring og ekspertise skaber merværdi og giver vores kunder en afgørende konkurrencefordel.
Mere information her:













