
'n Poging om KI te verduidelik: Hoe werk en funksioneer kunsmatige intelligensie – hoe word dit opgelei?

Available in 27 languages 📢
Verkies Xpert.Digital op GoogleⓘGepubliseer op: 8 September 2024 / Opgedateer op: 9 September 2024 – Outeur: Konrad Wolfenstein

'n Poging om KI te verduidelik: Hoe werk kunsmatige intelligensie en hoe word dit opgelei? – Beeld: Xpert.Digital
📊 Van data-invoer tot modelvoorspelling: Die KI-proses
Hoe werk kunsmatige intelligensie (KI)? 🤖
Die werking van kunsmatige intelligensie (KI) kan in verskeie duidelik gedefinieerde stappe verdeel word. Elk van hierdie stappe is van kritieke belang vir die finale resultaat wat deur die KI gelewer word. Die proses begin met data-invoer en eindig met modelvoorspelling en enige terugvoer of verdere opleidingsrondtes. Hierdie fases beskryf die proses waardeur byna alle KI-modelle gaan, ongeag of dit eenvoudige reëlstelle of hoogs komplekse neurale netwerke is.
1. Die data-invoer 📊
Die fondament van enige kunsmatige intelligensie is die data waarmee dit werk. Hierdie data kan in verskeie vorme bestaan, soos beelde, teks, klanklêers of video's. Die KI gebruik hierdie rou data om patrone te herken en besluite te neem. Die kwaliteit en kwantiteit van die data speel hier 'n deurslaggewende rol, aangesien dit 'n beduidende invloed het op hoe goed of swak die model uiteindelik sal presteer.
Hoe meer omvattend en akkuraat die data is, hoe beter kan die KI leer. Byvoorbeeld, wanneer 'n KI vir beeldverwerking opgelei word, benodig dit 'n groot hoeveelheid beelddata om verskillende voorwerpe korrek te identifiseer. Vir taalmodelle is dit teksdata wat die KI help om menslike spraak te verstaan en te genereer. Data-invoer is die eerste en een van die belangrikste stappe, aangesien die kwaliteit van voorspellings net so goed kan wees soos die onderliggende data. 'n Bekende beginsel in rekenaarwetenskap beskryf dit met die gesegde "vullis in, vullis uit" - slegte data lei tot slegte resultate.
2. Datavoorverwerking 🧹
Sodra die data ingevoer is, moet dit voorberei word voordat dit in die werklike model ingevoer kan word. Hierdie proses word data-voorverwerking genoem. Die doel hier is om die data te omskep in 'n formaat wat die model optimaal kan verwerk.
'n Algemene stap in voorverwerking is datanormalisering. Dit beteken om die data in 'n uniforme waardebereik te bring sodat dit konsekwent deur die model behandel word. 'n Voorbeeld sou wees om alle pixelwaardes van 'n beeld na 'n reeks van 0 tot 1 te skaal, in plaas van 0 tot 255.
Nog 'n belangrike deel van voorverwerking is kenmerkonttrekking. Dit behels die onttrekking van spesifieke kenmerke uit die rou data wat veral relevant is vir die model. In beeldverwerking kan dit rande of spesifieke kleurpatrone wees, terwyl in teksverwerking relevante sleutelwoorde of sinstrukture onttrek word. Voorverwerking is van kardinale belang om die KI se leerproses meer doeltreffend en presies te maak.
3. Die model 🧩
Die model is die kern van elke kunsmatige intelligensie. Hier word data geanaliseer en verwerk op grond van algoritmes en wiskundige berekeninge. 'n Model kan in verskeie vorme bestaan. Een van die bekendste modelle is die neurale netwerk, wat gebaseer is op die werking van die menslike brein.
Neurale netwerke bestaan uit verskeie lae kunsmatige neurone wat inligting verwerk en deurgee. Elke laag neem die uitsette van die vorige laag en verwerk dit verder. Die leerproses van 'n neurale netwerk behels die aanpassing van die gewigte van die verbindings tussen hierdie neurone sodat die netwerk toenemend akkurate voorspellings of klassifikasies kan maak. Hierdie aanpassing word bereik deur opleiding, waarin die netwerk toegang tot groot hoeveelhede voorbeelddata verkry en iteratief sy interne parameters (gewigte) verbeter.
Behalwe neurale netwerke, word baie ander algoritmes in KI-modelle gebruik. Dit sluit in besluitbome, ewekansige woude, ondersteuningsvektormasjiene en vele meer. Watter algoritme gebruik word, hang af van die spesifieke taak en die beskikbare data.
4. Die modelvoorspelling 🔍
Sodra die model met data opgelei is, kan dit voorspellings maak. Hierdie stap word modelvoorspelling genoem. Die KI ontvang 'n invoer en, gebaseer op die patrone wat dit tot dusver geleer het, gee dit 'n uitvoer terug, dit wil sê 'n voorspelling of besluit.
Hierdie voorspelling kan verskillende vorme aanneem. In 'n beeldklassifikasiemodel kan die KI byvoorbeeld voorspel watter voorwerp in 'n prent getoon word. In 'n taalmodel kan dit voorspel watter woord volgende in 'n sin sal verskyn. In finansiële voorspellings kan die KI voorspel hoe die aandelemark sal presteer.
Dit is belangrik om te beklemtoon dat die akkuraatheid van die voorspellings sterk afhang van die kwaliteit van die opleidingsdata en die modelargitektuur. 'n Model wat op onvoldoende of bevooroordeelde data opgelei is, is hoogs geneig om verkeerde voorspellings te maak.
5. Terugvoer en opleiding (opsioneel) ♻️
Nog 'n belangrike aspek van hoe 'n KI werk, is die terugvoermeganisme. Hier word die model gereeld nagegaan en verder geoptimaliseer. Hierdie proses vind plaas tydens opleiding of na die model se voorspelling.
Indien die model verkeerde voorspellings maak, kan dit deur terugvoer leer om hierdie foute te herken en sy interne parameters dienooreenkomstig aan te pas. Dit word gedoen deur die modelvoorspellings met die werklike resultate te vergelyk (bv. met bekende data waarvoor die korrekte antwoorde reeds bestaan). 'n Tipiese metode in hierdie konteks is sogenaamde gemonitorde leer, waarin die KI leer uit voorbeelddata wat reeds die korrekte antwoorde bevat.
'n Algemene terugvoermetode is die terugpropagasie-algoritme wat in neurale netwerke gebruik word. Hier word die foute wat deur die model gemaak word, terugwaarts deur die netwerk gepropageer om die gewigte van die neurale verbindings aan te pas. Op hierdie manier leer die model uit sy foute en word dit toenemend akkuraat in sy voorspellings.
Die rol van opleiding 🏋️♂️
Die opleiding van 'n KI is 'n iteratiewe proses. Hoe meer data die model sien en hoe meer gereeld dit op daardie data opgelei word, hoe akkurater word die voorspellings daarvan. Daar is egter beperkings: 'n Ooropgeleide model kan sogenaamde "oorpassings"-probleme ontwikkel. Dit beteken dat dit die opleidingsdata so goed memoriseer dat dit swakker resultate op nuwe, onbekende data lewer. Daarom is dit belangrik om die model so op te lei dat dit veralgemeen, wat beteken dat dit ook goeie voorspellings op nuwe data kan maak.
Benewens gereelde opleiding, is daar ook metodes soos oordragleer. Hier word 'n model wat reeds op 'n groot datastel opgelei is, vir 'n nuwe, soortgelyke taak gebruik. Dit bespaar tyd en rekenaarkrag, aangesien die model nie heeltemal van nuuts af opgelei hoef te word nie.
Benut jou sterk punte ten volle 🚀
Die werking van kunsmatige intelligensie (KI) is gebaseer op 'n komplekse wisselwerking van verskeie stappe. Van data-invoer en voorverwerking tot modelopleiding, voorspelling en terugvoer, beïnvloed baie faktore die akkuraatheid en doeltreffendheid van KI. 'n Goed opgeleide KI kan enorme voordele in baie lewensareas bied – van die outomatisering van eenvoudige take tot die oplossing van komplekse probleme. Dit is egter ewe belangrik om die beperkings en potensiële slaggate van KI te verstaan om die beste gebruik te maak van sy sterk punte.
🤖📚 Eenvoudig verduidelik: Hoe word 'n KI opgelei?
🤖📊 KI-leerproses: Vang vas, skakel en stoor
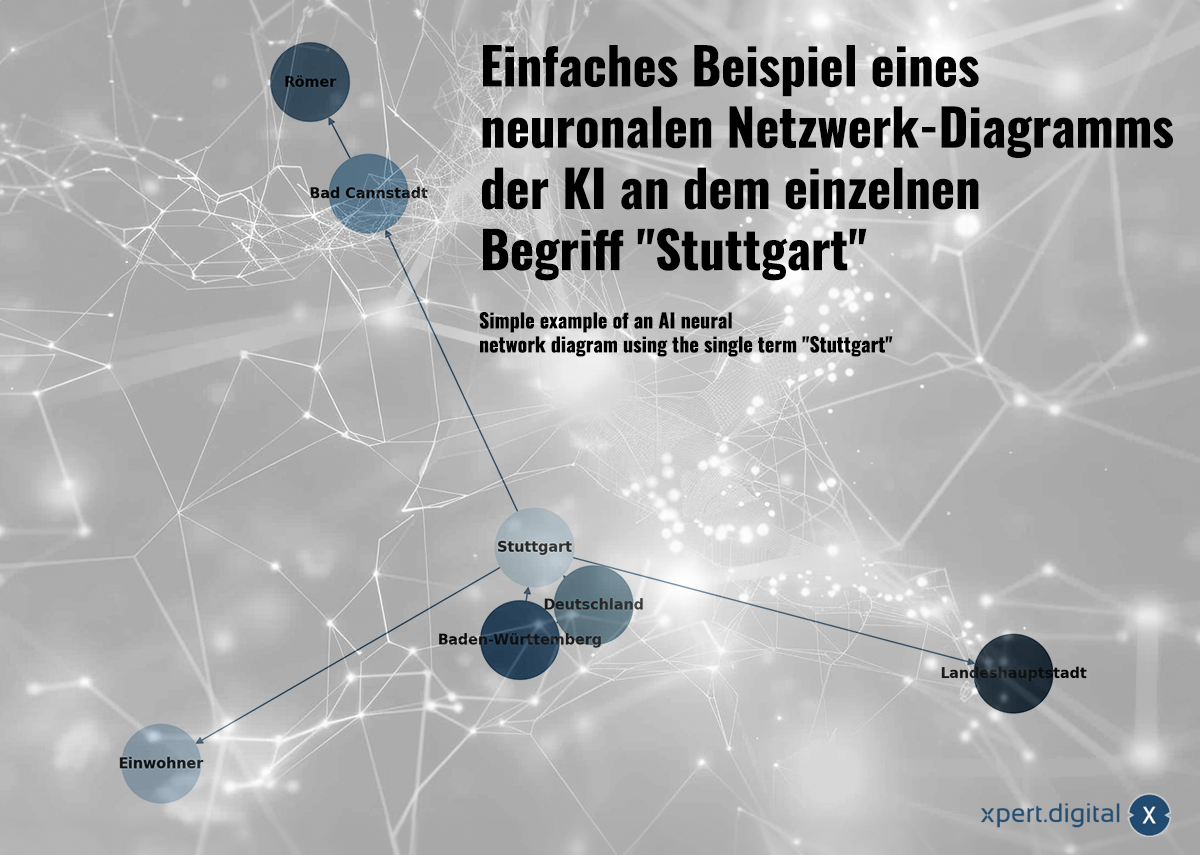
Eenvoudige voorbeeld van 'n KI-neurale netwerkdiagram met die enkele term "Stuttgart" - Beeld: Xpert.Digital
🌟 Versamel en berei data voor
Die eerste stap in die KI-leerproses is die insameling en voorbereiding van data. Hierdie data kan van verskeie bronne kom, soos databasisse, sensors, tekste of beelde.
🌟 Verwantskapsdata (Neurale netwerk)
Die versamelde data word in 'n neurale netwerk aan mekaar gekoppel. Elke datapakket word deur verbindings in 'n netwerk van "neurone" (nodusse) verteenwoordig. 'n Eenvoudige voorbeeld met die stad Stuttgart kan so lyk:
a) Stuttgart is 'n stad in Baden-Württemberg
b) Baden-Württemberg is 'n federale staat in Duitsland
c) Stuttgart is 'n stad in Duitsland
d) Stuttgart het 'n bevolking van 633 484 in 2023 gehad
e) Bad Cannstatt is 'n distrik van Stuttgart
f) Bad Cannstatt is deur die Romeine gestig
g) Stuttgart is die hoofstad van Baden-Württemberg
Afhangende van die grootte van die datavolume, word die parameters vir potensiële uitsette gegenereer met behulp van die KI-model. GPT-3 het byvoorbeeld ongeveer 175 miljard parameters!
🌟 Stoor en pasmaak (leer)
Die data word in die neurale netwerk ingevoer. Dit gaan deur die KI-model en word verwerk via verbindings (soortgelyk aan sinapse). Die gewigte (parameters) tussen die neurone word aangepas om die model op te lei of 'n taak uit te voer.
Anders as konvensionele bergingsmetodes soos direkte toegang, geïndekseerde toegang, opeenvolgende of bondelberging, berg neurale netwerke data op 'n onkonvensionele manier. Die "data" word gestoor in die gewigte en vooroordele van die verbindings tussen die neurone.
Die werklike "berging" van inligting in 'n neurale netwerk vind plaas deur die aanpassing van die verbindingsgewigte tussen die neurone. Die KI-model "leer" deur hierdie gewigte en vooroordele voortdurend aan te pas gebaseer op die invoerdata en 'n gedefinieerde leeralgoritme. Dit is 'n deurlopende proses waarin die model meer akkurate voorspellings kan maak deur herhaalde aanpassings.
Die KI-model kan as 'n soort programmering beskou word, aangesien dit deur gedefinieerde algoritmes en wiskundige berekeninge geskep word, en die aanpassing van die parameters (gewigte) daarvan word voortdurend verbeter om akkurate voorspellings te maak. Dit is 'n voortdurende proses.
Vooroordele is bykomende parameters in neurale netwerke wat by die geweegde invoerwaardes van 'n neuron gevoeg word. Hulle laat die parameters toe om geweeg te word (belangrik, minder belangrik, ens.), wat die KI meer buigsaam en akkuraat maak.
Neurale netwerke kan nie net individuele feite stoor nie, maar ook verwantskappe tussen data herken deur patroonherkenning. Die voorbeeld met Stuttgart illustreer hoe kennis in 'n neurale netwerk ingevoer kan word, maar neurale netwerke leer nie deur eksplisiete kennis nie (soos in hierdie eenvoudige voorbeeld), maar eerder deur die analise van datapatrone. Daarom kan neurale netwerke nie net individuele feite stoor nie, maar ook gewigte en verwantskappe tussen die invoerdata leer.
Hierdie proses bied 'n verstaanbare inleiding tot hoe KI, en veral neurale netwerke, werk, sonder om te diep in tegniese besonderhede te delf. Dit demonstreer dat inligting nie in neurale netwerke gestoor word soos in konvensionele databasisse nie, maar eerder deur die verbindings (gewigte) binne die netwerk aan te pas.
🤖📚 In meer besonderhede: Hoe word 'n KI opgelei?
🏋️♂️ Die opleiding van 'n KI, veral 'n masjienleermodel, behels verskeie stappe. KI-opleiding is gebaseer op die voortdurende optimalisering van modelparameters deur terugvoer en aanpassing totdat die model die beste presteer op die verskafde data. Hier is 'n gedetailleerde verduideliking van hoe hierdie proses werk:
1. 📊 Versamel en berei data voor
Data is die fondament van KI-opleiding. Dit bestaan tipies uit duisende of miljoene voorbeelde wat die stelsel bedoel is om te analiseer. Voorbeelde sluit in beelde, teks of tydreeksdata.
Die data moet skoongemaak en genormaliseer word om onnodige bronne van foute te vermy. Dikwels word die data omskep in kenmerke wat die relevante inligting bevat.
2. 🔍 Definieer model
'n Model is 'n wiskundige funksie wat die verwantskappe in die data beskryf. In neurale netwerke, wat gereeld vir KI gebruik word, bestaan die model uit verskeie lae neurone wat met mekaar verbind is.
Elke neuron voer 'n wiskundige bewerking uit om die invoerdata te verwerk en gee dan 'n sein aan die volgende neuron deur.
3. 🔄 Inisialiseer gewigte
Die verbindings tussen neurone het gewigte wat aanvanklik ewekansig gestel word. Hierdie gewigte bepaal hoe sterk 'n neuron op 'n sein reageer.
Die doel van die opleiding is om hierdie gewigte aan te pas sodat die model beter voorspellings maak.
4. ➡️ Voorwaartse Voortplanting
Tydens die vorentoe-deurgang word die invoerdata deur die model verwerk om 'n voorspelling te verkry.
Elke laag verwerk die data en gee dit deur aan die volgende laag totdat die laaste laag die resultaat lewer.
5. ⚖️ Bereken die verliesfunksie
Die verliesfunksie meet hoe goed die model se voorspellings vergelyk met die werklike waardes (die etikette). 'n Algemene maatstaf is die fout tussen die voorspelde en die werklike respons.
Hoe hoër die verlies, hoe swakker die model se voorspelling.
6. 🔙 Terugpropagasie
In omgekeerde iterasie word die fout teruggevoer vanaf die model se uitvoer na die vorige lae.
Die fout word herverdeel na die gewigte van die verbindings, en die model pas die gewigte aan sodat die foute kleiner word.
Dit word gedoen deur gradiëntafdaling te gebruik: Die gradiëntvektor word bereken, wat aandui hoe die gewigte verander moet word om die fout te minimaliseer.
7. 🔧 Opdateer gewigte
Nadat die fout bereken is, word die gewigte van die verbindings opgedateer met 'n klein aanpassing gebaseer op die leertempo.
Die leertempo bepaal hoeveel die gewigte by elke stap verander word. Veranderinge wat te groot is, kan die model onstabiel maak, terwyl veranderinge wat te klein is, tot 'n stadige leerproses lei.
8. 🔁 Herhaal (Epogge)
Hierdie proses van vorentoe-deurgang, foutberekening en gewigsopdatering word herhaal, dikwels oor verskeie epogge (gaan deur die hele datastel), totdat die model aanvaarbare akkuraatheid bereik.
Met elke era leer die model 'n bietjie meer en pas sy gewigte verder aan.
9. 📉 Validering en Toetsing
Nadat die model opgelei is, word dit op 'n gevalideerde datastel getoets om te kyk hoe goed dit veralgemeen. Dit verseker dat dit nie net die opleidingsdata "gememoriseer" het nie, maar ook goeie voorspellings op onbekende data maak.
Toetsdata help om die finale prestasie van die model te meet voordat dit in die praktyk gebruik word.
10. 🚀 Optimalisering
Verdere stappe om die model te verbeter, sluit in hiperparameter-afstemming (bv. die aanpassing van die leertempo of netwerkstruktuur), regularisering (om oorpassing te vermy), of die verhoging van die hoeveelheid data.
📊🔙 Kunsmatige Intelligensie: Maak die swart boks van KI verstaanbaar, begryplik en verduidelikbaar met Verklaarbare KI (XAI), hittekaarte, surrogaatmodelle of ander oplossings

Kunsmatige Intelligensie: Die swart boks van KI verstaanbaar, begryplik en verklaarbaar maak met Verklaarbare KI (XAI), hittekaarte, surrogaatmodelle of ander oplossings – Beeld: Xpert.Digital
Die sogenaamde "swart boks" van kunsmatige intelligensie (KI) verteenwoordig 'n beduidende en dringende probleem. Selfs kenners staar dikwels die uitdaging in die gesig om nie ten volle te verstaan hoe KI-stelsels tot hul besluite kom nie. Hierdie gebrek aan deursigtigheid kan aansienlike probleme veroorsaak, veral in kritieke gebiede soos ekonomie, politiek en medisyne. 'n Dokter of geneesheer wat op 'n KI-stelsel staatmaak vir diagnose en behandelingsaanbevelings, moet vertroue hê in die besluite wat geneem word. As 'n KI se besluitnemingsproses egter nie voldoende deursigtig is nie, ontstaan onsekerheid, wat moontlik tot 'n gebrek aan vertroue kan lei – en dit in situasies waar menselewens op die spel kan wees.
Meer daaroor hier:
Ons is daar vir jou - advies - beplanning - implementering - projekbestuur
☑️ KMO-ondersteuning in strategie, konsultasie, beplanning en implementering
☑️ Skep of herbelyning van die digitale strategie en digitalisering
☑️ Uitbreiding en optimalisering van internasionale verkoopsprosesse
☑️ Globale en digitale B2B-handelsplatforms
☑️ Pionier Besigheidsontwikkeling

Konrad Wolfenstein
Ek sal graag as jou persoonlike adviseur dien.
Jy kan my kontak deur die kontakvorm hieronder in te vul of my eenvoudig by +49 89 89 674 804 (München) .
Ek sien uit na ons gesamentlike projek.
Skryf aan my

Xpert.Digitaal - Konrad Wolfenstein
Xpert.Digital is 'n spilpunt vir die industrie met 'n fokus op digitalisering, meganiese ingenieurswese, logistiek/intralogistiek en fotovoltaïese.
Met ons 360° besigheidsontwikkelingsoplossing ondersteun ons bekende maatskappye van nuwe besigheid tot naverkope.
Markintelligensie, smarketing, bemarkingsoutomatisering, inhoudontwikkeling, PR, posveldtogte, persoonlike sosiale media en loodversorging is deel van ons digitale hulpmiddels.
Jy kan meer uitvind by: www.xpert.digital - www.xpert.solar - www.xpert.plus
Behou kontak

















