
AI 和 SEO 与 BERT – 来自 Transformer 的双向编码器表示 – 自然语言处理 (NLP) 领域的模型

Available in 27 languages 📢
在 Google 上更倾向于选择 Xpert.Digital。ⓘ发布日期:2024年10月4日 / 更新日期:2024年10月4日 – 作者:Konrad Wolfenstein

AI 和 SEO 与 BERT – 来自 Transformer 的双向编码器表示 – 自然语言处理 (NLP) 领域的模型 – 图片来源:Xpert.Digital
🚀💬 由谷歌开发:BERT及其对自然语言处理的重要性——为什么双向文本理解至关重要
🔍🗣️ BERT,全称为双向编码器表示模型(Bidirectional Encoder Representations from Transformers),是谷歌开发的自然语言处理(NLP)领域的重要模型。它彻底改变了机器理解语言的方式。与以往从左到右或从右到左依次分析文本的模型不同,BERT 支持双向处理。这意味着它可以同时从前后文本序列中理解单词的上下文。这种能力显著提高了对复杂语言关系的理解。.
🔍 BERT 的架构
近年来,自然语言处理(NLP)领域最重要的进展之一是Transformer模型的引入,正如2017年发表的PDF论文《Attention is all you need》 (维基百科)中所述。该模型从根本上改变了NLP领域,摒弃了以往使用的结构,例如机器翻译。取而代之的是,它完全依赖于注意力机制。Transformer的设计此后成为众多模型的基础,这些模型代表了语音生成、翻译等各个领域的最新技术。
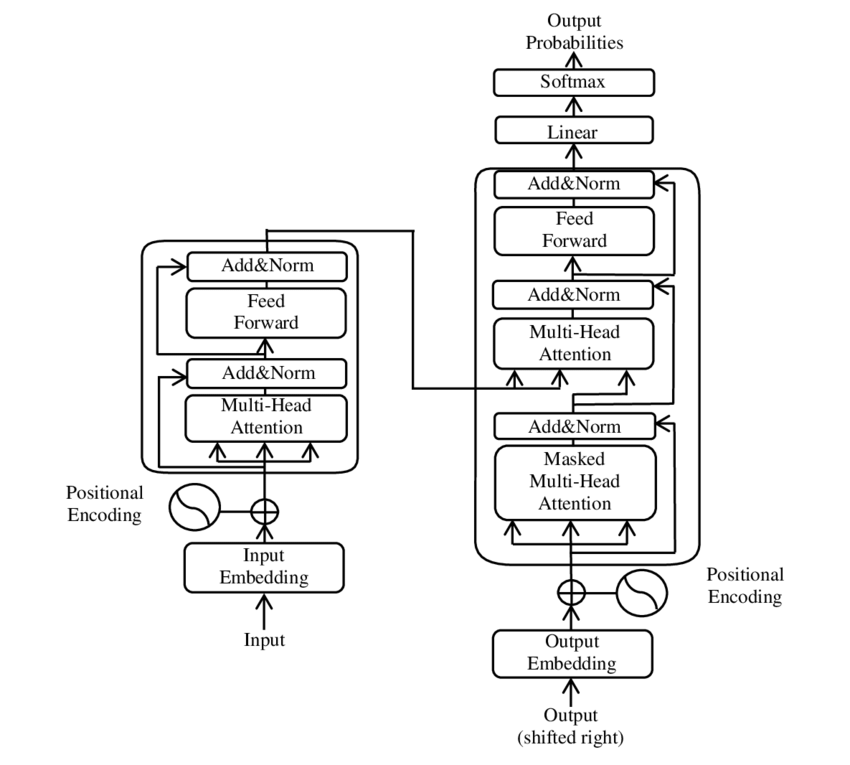
Transformer 模型主要组成部分的示意图 – 图片来源:谷歌
BERT正是基于Transformer架构。该架构利用所谓的自注意力机制来分析句子中词语之间的关系。每个词语都会在整个句子的上下文中获得关注,从而更精确地理解句法和语义关系。.
论文《你只需要注意力》的作者是:
- 阿什什·瓦斯瓦尼(谷歌大脑)
- 诺姆·沙泽尔(谷歌大脑)
- 妮基·帕尔玛(谷歌研究院)
- Jakob Uszkoreit(谷歌研究院)
- 莱昂·琼斯(谷歌研究院)
- 艾丹·N·戈麦斯(多伦多大学,部分工作在谷歌大脑完成)
- 卢卡什·凯泽(谷歌大脑)
- 伊利亚·波洛苏欣(独立研究员,曾就职于谷歌研究院)
这些作者对本文提出的 Transformer 模型的发展做出了重大贡献。.
🔄 双向处理
BERT 的一个关键特性是其双向文本处理能力。传统的模型,例如循环神经网络 (RNN) 或长短期记忆 (LSTM) 网络,只能单向处理文本,而 BERT 可以双向分析词语的上下文。这使得模型能够更好地捕捉细微的含义差别,从而做出更准确的预测。.
🕵️♂️掩码语音建模
BERT 的另一项创新之处在于掩码语言模型(MLM)技术。该技术通过对句子中随机选择的词语进行掩码处理,并训练模型根据上下文预测这些被掩码的词语。这种方法迫使 BERT 深入理解句子中每个词语的上下文和含义。.
🚀 BERT的训练和适应
BERT 的训练过程分为两个阶段:预训练和微调。.
📚 预备训练
在预训练阶段,BERT模型会使用大量文本进行训练,以学习通用的语言模式。这些文本包括维基百科文章和其他大型文本语料库。在此阶段,模型会学习基本的语言结构和上下文。.
🔧 微调
经过预训练后,BERT 会被针对特定的自然语言处理任务进行调整,例如文本分类或情感分析。该模型使用规模较小、与任务相关的数据集进行训练,以优化其在特定应用中的性能。.
🌍 BERT的应用领域
BERT 已被证明在自然语言处理的众多领域都非常有用:
搜索引擎优化
谷歌使用 BERT 来更好地理解搜索查询并显示更相关的结果。这显著提升了用户体验。.
文本分类
BERT 可以按主题对文档进行分类,也可以分析文本的语气。.
命名实体识别(NER)
该模型能够识别和分类文本中的命名实体,例如人名、地名或组织名称。.
问答系统
BERT 用于为提出的问题提供精确的答案。.
🧠 BERT 对人工智能未来的重要性
BERT 为自然语言处理模型树立了新的标准,并为进一步的创新铺平了道路。凭借其双向处理能力和对语言上下文的深刻理解,它显著提高了人工智能应用的效率和准确性。.
🔜 未来发展
BERT及类似模型的进一步发展旨在创建功能更强大的系统。这些系统能够处理更复杂的语言任务,并应用于各种新兴领域。将此类模型集成到日常技术中,可能会从根本上改变我们与计算机的交互方式。.
🌟 人工智能发展史上的里程碑
BERT是人工智能发展史上的一个里程碑,它彻底改变了机器处理自然语言的方式。其双向架构能够更深入地理解语言关系,使其成为众多应用领域不可或缺的工具。随着研究的不断深入,像BERT这样的模型将继续在改进人工智能系统和开拓其应用新领域方面发挥核心作用。.
📣 类似主题
- 📚 BERT简介:突破性的自然语言处理模型
- 🔍 BERT 和双向性在自然语言处理中的作用
- 🧠 Transformer 模型:BERT 的基础
- 🚀 掩码语言建模:BERT 成功的关键
- 📈 BERT 定制:从预训练到微调
- 🌐 BERT 在现代技术中的应用领域
- 🤖 BERT 对人工智能未来的影响
- 💡 未来展望:BERT 的进一步发展
- 🏆 BERT 是人工智能发展史上的一个里程碑
- 📰 Transformer论文《注意力就是你所需要的一切》的作者:BERT背后的策划者
#️⃣ 标签:#自然语言处理 #人工智能 #语言建模 #Transformer #机器学习
🎯🎯🎯 受益于 Xpert.Digital 全面的五重专业知识和全面的服务包 | BD、研发、XR、PR 和数字可视性优化

受益于 Xpert.Digital 全面的五重专业知识和全面的服务包 | 研发、XR、PR 和数字可视性优化 - 图片:Xpert.Digital
Xpert.Digital 对各个行业都有深入的了解。 这使我们能够制定量身定制的策略,专门针对您特定细分市场的要求和挑战。 通过不断分析市场趋势并跟踪行业发展,我们可以前瞻性地采取行动并提供创新的解决方案。 通过经验和知识的结合,我们创造附加值并为客户提供决定性的竞争优势。
更多相关信息请点击这里:
BERT:革命性的🌟自然语言处理技术
🚀 BERT,全称为双向编码器表示模型(Bidirectional Encoder Representations from Transformers),是谷歌开发的一种高级语言模型,自2018年推出以来,已成为自然语言处理(NLP)领域的一项重大突破。它基于Transformer架构,彻底改变了机器理解和处理文本的方式。但究竟是什么让BERT如此特别,它又有哪些用途呢?要回答这些问题,我们需要深入了解BERT的技术基础、工作原理及其应用。.
📚 1. 自然语言处理基础
为了充分理解 BERT 的重要性,简要回顾一下自然语言处理 (NLP) 的基础知识很有帮助。NLP 处理的是计算机与人类语言之间的交互。其目标是教会机器分析、理解和响应文本数据。在 BERT 等模型出现之前,机器语言处理常常面临诸多挑战,尤其因为人类语言本身就具有歧义性、上下文依赖性和复杂结构。.
📈 2. NLP模型的发展
在BERT出现之前,大多数自然语言处理模型都基于所谓的单向架构。这意味着这些模型只能从左到右或从右到左读取文本,因此在处理句子中的单词时,它们只能考虑有限的上下文信息。这种局限性常常导致模型无法完整地捕捉句子的语义上下文,从而难以准确理解含义模糊或对上下文敏感的词语。.
在BERT出现之前,自然语言处理研究领域的另一项重要进展是word2vec模型,它允许计算机将单词转换为反映语义相似性的向量。然而,即使在这种情况下,上下文信息也仅限于单词的直接上下文。后来,循环神经网络(RNN),特别是长短期记忆(LSTM)模型被开发出来,通过存储跨多个单词的信息,使得更好地理解文本序列成为可能。然而,这些模型也存在局限性,尤其是在处理长文本以及同时理解双向上下文时。.
🔄 3. Transformer架构带来的革命
2017 年 Transformer 架构的引入带来了突破性进展,它也是 BERT 的基础。Transformer 模型旨在实现并行文本处理,同时考虑单词前后上下文。这是通过所谓的自注意力机制实现的,该机制会根据每个单词在句子中的重要性为其分配权重值。.
与以往的方法不同,Transformer 模型不是单向的,而是双向的。这意味着它们可以从单词的左右上下文中获取信息,从而创建更完整、更准确的单词及其含义的表示。.
🧠 4. BERT:双向模型
BERT 将 Transformer 架构的性能提升到了一个新的水平。该模型旨在同时捕捉单词在左右两个方向上的上下文信息,而不仅仅是从左到右或从右到左。这使得 BERT 能够考虑单词在句子中的完整上下文,从而显著提高自然语言处理任务的准确率。.
BERT 的一个关键特性是使用了所谓的掩码语言模型(MLM)。在 BERT 训练过程中,句子中随机选择的词语会被替换成掩码,模型会根据上下文猜测这些被替换后的词语。这项技术使得 BERT 能够学习句子中词语之间更深层次、更精确的关系。.
此外,BERT 还使用了一种名为“下一句预测”(NSP)的方法,该方法使模型能够预测一个句子是否紧接着另一个句子。这提高了 BERT 理解长文本和识别句子间更复杂关系的能力。.
🌐 5. BERT的实际应用
BERT已被证明在各种自然语言处理任务中都非常有用。以下是一些最重要的应用领域:
📊 a) 文本分类
BERT最常见的应用之一是文本分类,它将文本划分为预定义的类别。例如,情感分析(例如,识别文本是正面还是负面)或客户反馈分类。由于BERT能够深入理解词语的上下文,因此它比以往的模型能够提供更精确的结果。.
❓ b) 问答系统
BERT 也被用于问答系统,该模型可以从文本中提取问题的答案。这项功能在搜索引擎、聊天机器人和虚拟助手等应用中尤为重要。由于其双向架构,即使问题表述间接,BERT 也能从文本中提取相关信息。.
🌍 c) 文本翻译
虽然 BERT 本身并非直接设计为翻译模型,但它可以与其他技术结合使用,以提升机器翻译的质量。通过更好地理解句子中的语义关系,BERT 可以帮助生成更准确的翻译,尤其是在处理含义模糊或复杂的语句时。.
🏷️ d) 命名实体识别 (NER)
另一个应用领域是命名实体识别(NER),它涉及识别文本中的特定实体,例如人名、地名或组织机构。BERT 在这项任务中已被证明特别有效,因为它能够充分考虑句子的上下文,从而更好地识别实体,即使这些实体在不同的上下文中具有不同的含义。.
✂️ e) 文本摘要
BERT能够理解文本的完整上下文,这使其成为自动文本摘要的强大工具。它可以用来从长篇文本中提取最重要的信息,并生成简洁的摘要。.
🌟 6. BERT 对研究和产业的重要性
BERT的出现开启了自然语言处理研究的新纪元。它是最早充分利用双向Transformer架构的模型之一,为后续众多模型树立了标杆。众多公司和研究机构已将BERT集成到其自然语言处理流程中,以提升应用程序的性能。.
此外,BERT 为语言模型领域的进一步创新铺平了道路。例如,随后开发了 GPT(生成式预训练 Transformer)和 T5(文本到文本迁移 Transformer)等模型,它们基于类似的原理,但针对不同的应用场景提供了特定的改进。.
🚧 7. BERT 的挑战和局限性
尽管BERT模型有很多优点,但也存在一些挑战和局限性。其中最大的障碍之一是训练和应用该模型所需的计算资源非常庞大。由于BERT模型非常庞大,拥有数百万个参数,因此需要强大的硬件和大量的计算资源,尤其是在处理大型数据集时。.
另一个问题是训练数据中可能存在的潜在偏差。由于BERT模型是基于大量文本数据进行训练的,因此它有时会反映出这些数据中存在的偏见和刻板印象。不过,研究人员正在不断努力识别和解决这些问题。.
🔍 现代语音处理应用中不可或缺的工具
BERT显著提升了机器理解人类语言的能力。凭借其双向架构和创新的训练方法,它能够深入、准确地把握句子中词语的上下文,从而在许多自然语言处理任务中实现更高的精度。无论是文本分类、问答系统还是实体识别,BERT都已成为现代自然语言处理应用中不可或缺的工具。.
自然语言处理领域的研究无疑将持续推进,而BERT为未来的诸多创新奠定了基础。尽管目前仍存在一些挑战和局限性,但BERT令人印象深刻地展现了这项技术在短时间内取得的巨大进步,以及未来将涌现的诸多激动人心的机遇。.
🌀 Transformer:自然语言处理的革命
🌟 近年来,自然语言处理 (NLP) 领域最重要的进展之一是 Transformer 模型的引入,正如 2017 年发表的论文《Attention Is All You Need》中所述。该模型从根本上改变了这一领域,摒弃了以往用于序列转换任务(例如机器翻译)的循环或卷积结构,转而完全依赖于注意力机制。Transformer 的设计此后成为众多模型的基础,这些模型代表了语音生成、翻译等各个领域的最新技术。.
🔄 变形金刚:范式转变
在Transformer出现之前,大多数序列任务模型都基于循环神经网络(RNN)或长短期记忆(LSTM)网络,这些网络本质上是顺序运行的。这些模型逐步处理输入数据,创建隐藏状态并沿着序列传播。虽然这种方法有效,但计算成本高昂且难以并行化,尤其是在处理长序列时。此外,由于梯度消失问题,RNN难以学习长期依赖关系。.
Transformer模型的关键创新在于其采用了自注意力机制,该机制允许模型根据句子中不同词语的位置,权衡它们之间的相对重要性。这使得模型能够比RNN或LSTM更有效地捕捉相距较远的词语之间的关系,并且能够并行而非串行地完成这一过程。这不仅提高了训练效率,也提升了机器翻译等任务的性能。.
🧩 模型架构
Transformer 由两个主要组件构成:编码器和解码器,这两个组件都由多个层组成,并且严重依赖于多头注意力机制。.
⚙️编码器
编码器由六个相同的层组成,每个层有两个子层:
1. 多头自我关注
这种机制使得模型在处理每个词时能够关注输入句子的不同部分。多头注意力机制并非在单一空间中计算注意力,而是将输入投射到多个不同的空间,从而捕捉词与词之间的各种关系。.
2. 位置全连接前馈网络
在注意力层之后,每个位置都独立应用一个全连接前馈网络。这有助于模型处理上下文中的每个词,并利用来自注意力机制的信息。.
为了保持输入序列的结构,该模型还包含了位置编码。由于Transformer并非按顺序处理单词,这些编码对于向模型提供句子中词序信息至关重要。位置编码被添加到词嵌入中,以便模型能够区分序列中的不同位置。.
🔍解码器
与编码器类似,解码器也由六层组成,每一层都包含一个额外的注意力机制,使模型能够在生成输出的同时关注输入序列的相关部分。解码器还使用掩码技术来防止其考虑未来的位置,从而保持序列生成的自回归特性。.
🧠 多头注意力机制和标量积注意力机制
Transformer 的核心是多头注意力机制,它是更简单的标量积注意力机制的扩展。注意力函数可以看作是查询与一组键值对之间的映射,其中每个键代表序列中的一个词,值代表相应的上下文信息。.
多头注意力机制使模型能够同时关注序列的不同部分。通过将输入投影到多个子空间,模型可以捕捉到更丰富的词语间关系。这对于机器翻译等任务尤为重要,因为理解词语的上下文需要考虑诸多因素,例如句法结构和语义含义。.
标量积注意力的公式为:
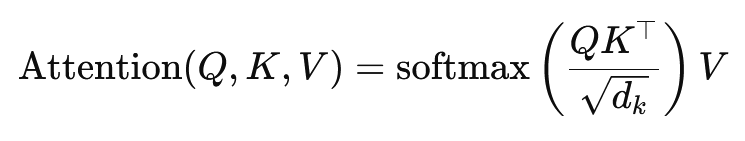
这里,(Q) 是查询矩阵,(K) 是键矩阵,(V) 是值矩阵。(sqrt{d_k}) 是一个缩放因子,用于防止标量积过大,否则会导致梯度过小,学习速度变慢。softmax 函数用于确保注意力权重之和为 1。.
🚀 变压器的优势
与 RNN 和 LSTM 等传统模型相比,Transformer 具有几个关键优势:
1. 并行化
由于 Transformer 可以同时处理序列中的所有标记,因此可以高度并行化,训练速度比 RNN 或 LSTM 快得多,尤其是在处理大型数据集时。.
2. 长期依赖性
自注意力机制使模型能够比 RNN 更有效地捕捉远距离词语之间的关系,而 RNN 则受限于其计算的顺序性。.
3. 可扩展性
Transformer 可以轻松扩展到非常大的数据集和更长的序列,而不会受到与 RNN 相关的性能瓶颈的影响。.
🌍 应用与效果
自问世以来,Transformer 已成为众多自然语言处理模型的基础。其中最著名的例子之一是 BERT(基于 Transformer 的双向编码器表示),它使用改进的 Transformer 架构,在包括问答和文本分类在内的许多自然语言处理任务中取得了最先进的性能。.
另一项重大进展是GPT(生成式预训练Transformer),它使用解码器受限的Transformer版本进行文本生成。包括GPT-3在内的GPT模型现在已被应用于众多领域,从内容创作到代码补全。.
🔍 功能强大且灵活的模型
Transformer 从根本上改变了我们处理自然语言处理任务的方式。它提供了一个强大而灵活的模型,可以应用于各种各样的问题。它处理长期依赖关系的能力以及高效的训练效率,使其成为许多现代模型的首选架构。随着研究的深入,我们很可能会看到 Transformer 的进一步改进和扩展,尤其是在图像和语音处理等领域,注意力机制在这些领域展现出了令人瞩目的成果。.
我们随时为您服务 - 建议 - 规划 - 实施 - 项目管理
☑️ 行业专家,这里有他自己的 Xpert。数字行业中心拥有超过 2,500 篇专业文章

Konrad Wolfenstein
我很乐意担任您的个人顾问。
您可以通过填写下面的联系表与我联系,或者直接致电+49 89 89 674 804 (慕尼黑) 。
我很期待我们的联合项目。
写给我

Xpert.Digital—— Konrad Wolfenstein
Xpert.Digital 是一个专注于数字化、机械工程、物流/内部物流和光伏的工业中心。
凭借我们的360°业务发展解决方案,我们为知名企业提供从新业务到售后的支持。
市场情报、营销、营销自动化、内容开发、公关、邮件活动、个性化社交媒体和潜在客户培育是我们数字工具的一部分。
您可以通过以下网址了解更多信息: www.xpert.digital - www.xpert.solar - www.xpert.plus
保持联系


















