
人工智能时代结构化数据(标记语言)与 Schema.org:谷歌工程师的真实想法
Xpert 预发布版

Available in 27 languages 📢
在 Google 上更倾向于选择 Xpert.Digital。ⓘ发布日期:2026年5月7日 / 更新日期:2026年5月7日 – 作者: Konrad Wolfenstein
人工智能时代结构化数据(标记语言)与 Schema.org:谷歌工程师的真实想法 – 图片来源:Xpert.Digital
谷歌的SEO秘诀:为什么人工智能在没有结构化数据的情况下会失败
尽管有 ChatGPT 等工具:为什么谷歌工程师仍然对 Schema.org 深信不疑
SEO 更新:为什么 Schema.org 现在正在取代 Google 上的 Open Graph?
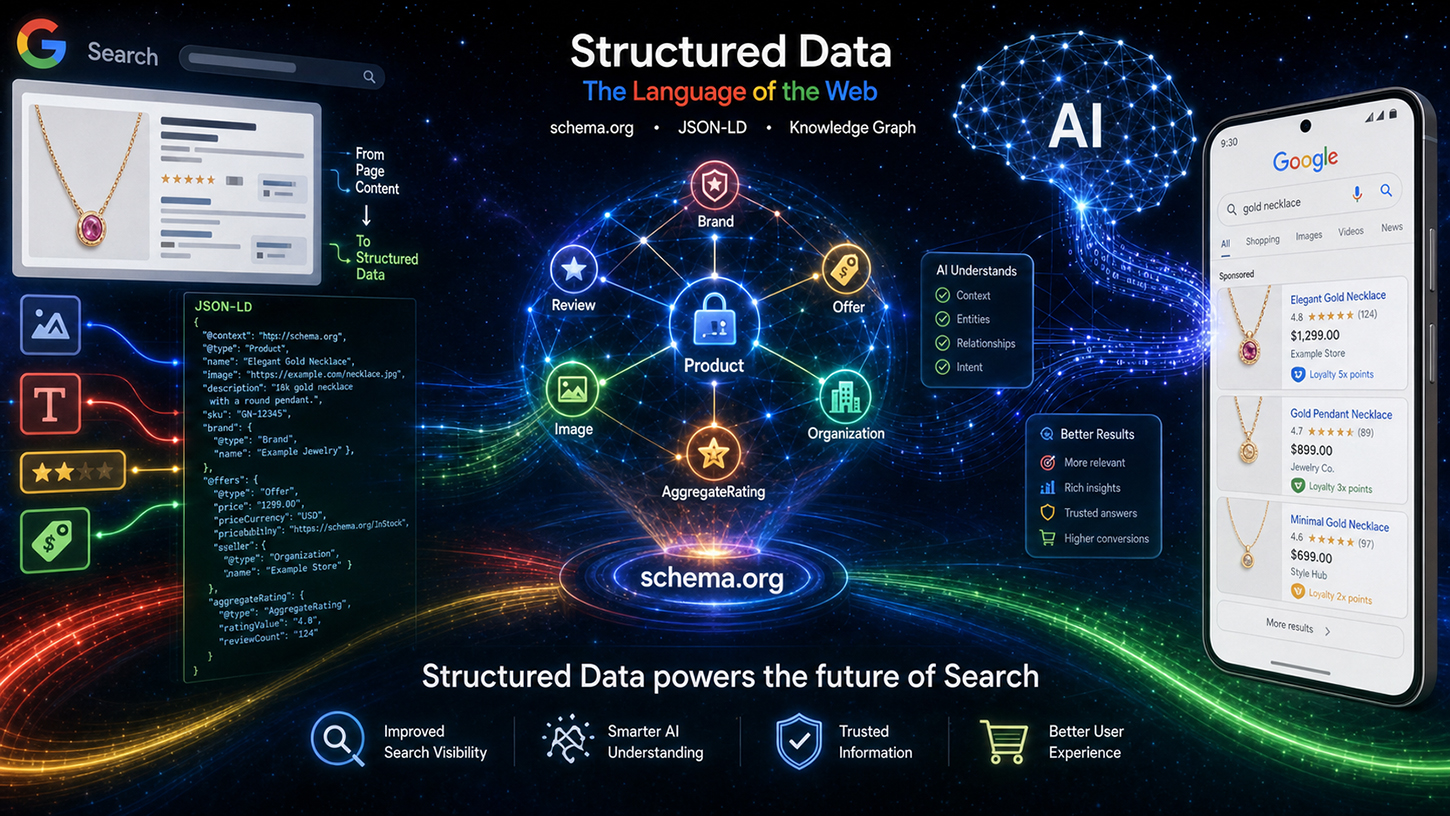
SEO 界一直流传着一个误解:在如今人工智能语言模型能够轻松理解非结构化文本的时代,像 Schema.org 这样精心维护的结构化数据已经过时了。但事实并非如此。在 Google Search Central Live 活动上,谷歌工程师 Ryan Levering 驳斥了这一误解,并明确指出:结构化标记并非过时的产物,而是新一代人工智能搜索的基石。.
从人工智能概览到自主购物代理,语言模型需要精确且机器可读的指导原则,以避免出现错误信息并高效运行。想要在现代网络上保持竞争力的企业必须帮助机器准确理解上下文。本文探讨了谷歌的战略调整,介绍了电子商务和用户生成内容领域的革命性创新,并阐述了技术搜索引擎优化(SEO)为何如今已成为争夺机器可见性的关键竞争优势。.
机器可以读取网络内容——但前提是你要帮助它们理解网络内容。
2026年4月21日,首届谷歌搜索中心现场活动在加拿大多伦多举行——这绝非一场普通的行业聚会。谷歌搜索工程工程师瑞恩·莱弗林发表了当天最具技术深度和战略意义的演讲:“结构化数据、质量与人工智能”。他的演讲不仅仅是对技术的回顾,更是对语义网未来的清晰阐述,尤其是在人工智能日益扮演用户与信息之间桥梁角色的时代。.
介于两个极端之间:非此即彼的错误选择
在演讲伊始,瑞恩·莱弗林对比了SEO圈内两种截然相反的观点。一方面,有人认为在强大的语言模型时代,结构化数据完全是多余的:如果人工智能模型能够轻松解读非结构化文本,又何必费力地在源代码中添加schema.org标记呢?另一方面,一些拥护者则大力宣传结构化数据是互联网的未来——一种用于自主人工智能代理之间的通用语义通信协议,它将在很大程度上取代传统的网络。.
莱弗林驳斥了两种极端观点,转而提出了一种细致入微、以实证为基础的视角。他总结道,两种立场都包含一些真理的内核,但都未能完全描述现实。这种细致入微的分析正是谷歌目前处理这一问题的方式:它不涉及教条,而是注重务实的效率。.
四个论点解释一切
莱弗林的核心论点可以概括为四个要点,他在题为“结构化数据的价值”的文章中对此进行了详细阐述。第一点是精确度:对于销售价格或会员计划等复杂模式,结构化数据比基于语言模型(LLM)的自由文本提取方法具有更高的准确率。语言模型可能会产生误导——它们会填充缺失的属性、错误地嵌套数据,或者访问脱离上下文的信息。例如,当从一个拥有数十种类似商品的大型电商网站中提取产品价格时,使用人工智能推理的错误率远高于使用清晰实现的结构化标记。.
第二点涉及附加内容:结构化数据通常包含不可见的元数据,这些元数据根本不存在于页面渲染后的 HTML 代码中。完整的 ISO 日期格式、用户生成内容的稳定标识符或内部实体 ID——这些信息仅存在于标记语言中。任何语言模型都无法提取文本之外的信息。.
第三,效率:解析结构化标记比处理大型语言模型以提取复杂数据要便宜得多。谷歌每天索引数十亿个网页。计算很简单:处理 JSON-LD 的普通解析器消耗的计算资源仅为 LLM 推理步骤的一小部分。因此,结构化数据不仅在语义上更胜一筹,而且从业务角度来看也效率更高。这一点与谷歌的基础设施直接相关。.
第四个方面,或许也是最容易被低估的方面,是焦点:结构化数据能够明确地突出显示页面上的相关信息,从而防止人工智能系统获取无关数据。在一个包含主文章、多个相关产品以及满是价格的导航栏的产品页面上,如果没有明确的标注,语言模型就无法确定应该参考哪个价格。结构化标记通过明确的赋值解决了这个问题。.
结构化数据实际是如何处理的
Levering 还使技术处理流程透明化。Schema.org 数据首先经过特定的清洗和过滤处理,然后被分类为索引数据——分为事件、购物和评论等领域。处理后的数据随后流入两个不同的输出渠道:一方面是传统的搜索结果页面 (SRP),另一方面是作为 Google 基于人工智能的系统(特别是所谓的 AI 概览 (AIO) 和 AI 模式 (AIM))的上下文信息。因此,结构化数据不再仅仅是丰富的搜索结果工具,而是生成式 AI 响应的直接输入。这标志着 schema.org 标记的战略重要性发生了根本性的转变。.
🎯🎯🎯 数据驱动的 B2B 行业中心,作为一种准内部解决方案

准内部解决方案:Xpert.Digital 如何弥合 B2B 营销和销售中的运营差距——智能内容驱动型业务——图片:Xpert.Digital
Xpert.Digital 是一个以数据驱动的 B2B 行业中心,由 Konrad Wolfenstein 领导。该公司为工业合作伙伴提供外部的、准内部解决方案,弥补其在市场营销、内容和销售方面的运营缺口,而无需客户投入额外资源。.
更多信息请点击这里:
为什么结构化数据正在成为人工智能代理的基础架构
购物聚焦:运费、会员积分和各种商品
演讲的大部分内容都集中在电子商务创新上。Levering解释说,根据Baymard研究所的数据,意外的配送信息是导致购物车放弃的第二和第三大常见原因。结构化的配送服务标记可以直接解决这个问题:商家现在可以在代码中直接精确定义始发地和目的地、尺寸和重量、订单金额阈值、处理时间以及会员计划关联信息。.
Google 使用的配送时间模型分为两个阶段:处理时间(即从收到订单到交给承运商的时间)和实际配送时间。这两个阶段都可以单独进行细粒度标注,细化到订单截止时间以及是否在工作日处理订单等细节。相应的 JSON-LD 示例展示了如何使用 `ShippingConditions` 类型来定义特定国家/地区(例如法国和德国)的免运费政策以及最低订单金额(例如 50 欧元)。.
将配送服务与会员计划整合在一起是一项极具创新性的做法。通过 `validForMemberTier` 属性,可以将配送服务显式地关联到会员计划及其特定等级。这样,就可以直接在标记中声明高级会员的配送优惠——这项功能以前只能通过 Google Merchant Center 进行配置。关联的会员计划本身被定义为 `Organization` 实体下的 `MemberProgram` 对象,其中包含“金卡”或“银卡”等等级,以及忠诚度奖励或积分奖励等相关权益。.
忠诚度计划作为语义实体
引入会员计划加价具有重要的经济意义。企业可以定义多个独立的会员计划,每个计划都包含多个等级和不同的福利——例如积分、会员价格、退货政策和运费优惠。这些信息会直接显示在谷歌搜索结果中,正如莱弗林通过实际案例所展示的那样,例如丝芙兰在购物摘要中直接显示了30%的会员折扣。莱弗林表示,下一步计划是实现跨页面ID链接,即从其他页面链接到会员计划定义,目前该计划的标题为“为跨页面@id链接铺平道路”。其目标是:加强产品页面和公司政策之间的关联性。.
用户生成内容:人工智能标注的难题
另一个重要议题是用户生成内容 (UGC) 模式类型的进一步发展。其中两项新功能尤为重要。首先,论坛和问答标记支持嵌入式帖子和转发,从而能够更准确地语义化地表示讨论结构。其次,也是更具战略意义的一点,引入了 `so#digitalSourceType` 属性,用于明确标识机器生成的内容。.
这项举措是对论坛和问答网站等平台上大量人工智能生成内容的直接回应。网站管理员现在可以声明帖子是由算法生成还是由语言模型生成。未明确说明的帖子会被谷歌默认为人类作者——这一规则鼓励透明的标注。`digitalSourceType`属性基于IPTC数字来源代码,用于区分算法生成的内容和模型生成的内容。.
图像选择:Schema 优于 Open Graph
一项不太引人注目但却切实有效的更新涉及谷歌的图片选择逻辑。该系统正在进行内部整合,并建立了清晰的优先级层级:Schema.org 标记,特别是 `primaryImageOfPage` 和 `mainEntity → image` 属性,优先级最高。只有在此之后,Open Graph 的 `og:image` 元标签才会被考虑。这一变化意味着,对于网站运营者而言,主图的 Schema.org 实现是否清晰,将直接影响其在谷歌搜索结果和 AI 概览中的显示——这是一个切实可衡量的优势。.
Schema.org 本身也获得了投资。
值得注意的是,谷歌宣布将重新投资 schema.org,将其打造为一个开放规范。其中提到了三项具体措施:公布各个 schema 术语的使用频率统计数据(如幻灯片所示,目前已有诸如 `digitalSourceType` 等术语的流行度数据,涵盖约 10,000 个域名);以机器可读的标准格式(例如 SHACL 或 ShEx)发布谷歌自身的验证规则;以及改进对排序规则的支持。这意义重大,因为它将允许外部开发者基于谷歌标准构建自己的验证工具,而无需依赖官方测试工具(后者有时会在高负载下崩溃)。.
验证:两种工具,一个目标
Levering 介绍了两个互补但测试标准不同的验证工具。位于 `search.google.com/test/rich-results` 的 Rich Result Test Tool 接受 URL 或纯 JSON 数据,并检查标记是否适用于 Google 搜索富媒体结果——因此,它基于 Google 的特定要求,而非 schema.org 标准本身。而 `validator.schema.org` 则检查标记是否符合 schema.org 标准,即是否遵循开放词汇表,无论 Google 是否能从中生成富媒体结果。这为 Web 开发人员提供了一个明确的建议:应该同时使用这两个工具,因为标记可能符合 schema 标准但无法生成富媒体结果,反之亦然。.
更宏观的视角:结构化数据作为人工智能基础设施
从多伦多活动的整体来看,一种转变显而易见,其影响远远超出了传统的搜索引擎优化(SEO)。结构化数据正从实现富媒体摘要的工具演变为人工智能系统的基础数据层标准。谷歌的AI概览和AI模式积极使用schema.org标记作为答案生成和实体验证的上下文。那些实施正确、完整和精确的结构化数据的人,不仅提高了在搜索结果中获得视觉亮点的机会,还能将他们的内容定位为人工智能答案的可靠主要来源。.
在此提及通用商业协议 (UCP) 和 WebMCP 并非偶然。这两个基于代理的通信标准(谷歌已于 2026 年发布了早期版本)都要求网站必须进行语义描述。Schema.org 正是这一标准的基础。在人工智能代理能够自主在网络上进行搜索、比较和发起交易的世界里,内容的机器可读性不再是可选项,而是经济价值的先决条件。因此,Ryan Levering 在多伦多的演讲不仅仅是一份技术更新报告,更是对未来网络基础设施的一次展望。.
你只需10秒钟就能自己找到答案。
如果您想了解您或其他网站对结构化数据的使用程度和全面性,您可以使用谷歌的 Ryan Levering(上文中提到的)推荐的两种工具:
Google 富媒体搜索结果测试(重点关注 Google 可见性):
访问 search.google.com/test/rich-results,复制任意一篇 xpert.digital 文章的网址,然后点击“测试网址”。该工具将准确显示 Google 在该页面上识别出的标记以及它们是否无误。
模式验证器(专注于纯粹的标准合规性):
请访问 validator.schema.org并粘贴相同的 URL。在这里,您可以直接在源代码中看到以颜色高亮显示的 xpert.digital 集成了哪些 JSON-LD 脚本(结构化数据)。
您的全球营销和业务拓展合作伙伴
☑️ 我们的业务语言是英语或德语。
☑️ 新增:用您的母语进行通信!

Konrad Wolfenstein
我和我的团队很乐意为您提供私人顾问服务。.
您可以通过填写此处的联系表格联系我 直接 致电 +49 7348 4088 965。 我的邮箱地址是 [email protected]:,或者
我期待着我们的合作项目。.
☑️ 为中小企业提供战略、咨询、规划和实施方面的支持
☑️ 制定或调整数字化战略和数字化
☑️ 拓展和优化国际销售流程
☑️ 全球及数字化 B2B 交易平台
☑️ 先锋业务拓展/市场营销/公关/展会
结合B2B支持和SEO及GEO(AI搜索)SaaS:面向B2B企业的一体化解决方案

集B2B支持和SaaS于一体的SEO和GEO(AI搜索):面向B2B企业的全方位解决方案 - 图片来源:Xpert.Digital
人工智能搜索改变一切:这款SaaS解决方案将如何彻底革新您的B2B排名。.
B2B企业的数字化格局正在经历快速变革。在人工智能的驱动下,在线曝光的规则正在被改写。对企业而言,挑战始终在于如何在浩瀚的数字信息海洋中脱颖而出,以及如何精准触达目标决策者。传统的搜索引擎优化(SEO)策略和本地营销(地理营销)复杂耗时,而且往往需要与不断变化的算法和激烈的市场竞争作斗争。.
但如果有一种解决方案,不仅能简化流程,还能使其更智能、更具预测性、效率更高呢?这正是将专业的B2B支持与强大的SaaS(软件即服务)平台相结合的优势所在,该平台专为满足人工智能搜索时代SEO和GEO的需求而设计。.
新一代工具不再仅仅依赖人工关键词分析和反向链接策略,而是利用人工智能更精准地理解搜索意图,自动优化本地排名因素,并进行实时竞品分析。最终形成一种积极主动、数据驱动的策略,为B2B企业带来决定性优势:它们不仅能被搜索到,还能被公认为所在细分领域和地区的权威领导者。.
这就是 B2B 支持与 AI 驱动的 SaaS 技术相结合,改变 SEO 和 GEO 营销的方式,以及您的公司如何从中受益,在数字领域实现可持续增长。.
更多信息请点击这里:

















