
Структуровані дані (розмітка) в епоху штучного інтелекту за допомогою Schema.org: що насправді думають інженери Google
Попередній реліз Xpert

Available in 27 languages 📢
Віддавайте перевагу Xpert.Digital у GoogleⓘОпубліковано: 7 травня 2026 р. / Оновлено: 7 травня 2026 р. – Автор: Konrad Wolfenstein
Структуровані дані (розмітка) в епоху штучного інтелекту за допомогою Schema.org: що насправді думають інженери Google – Зображення: Xpert.Digital
Секрет SEO від Google: чому штучний інтелект не працює без структурованих даних
Незважаючи на ChatGPT та компанію: Чому інженери Google продовжують вірити Schema.org
Оновлення SEO: Чому Schema.org тепер витісняє Open Graph у Google
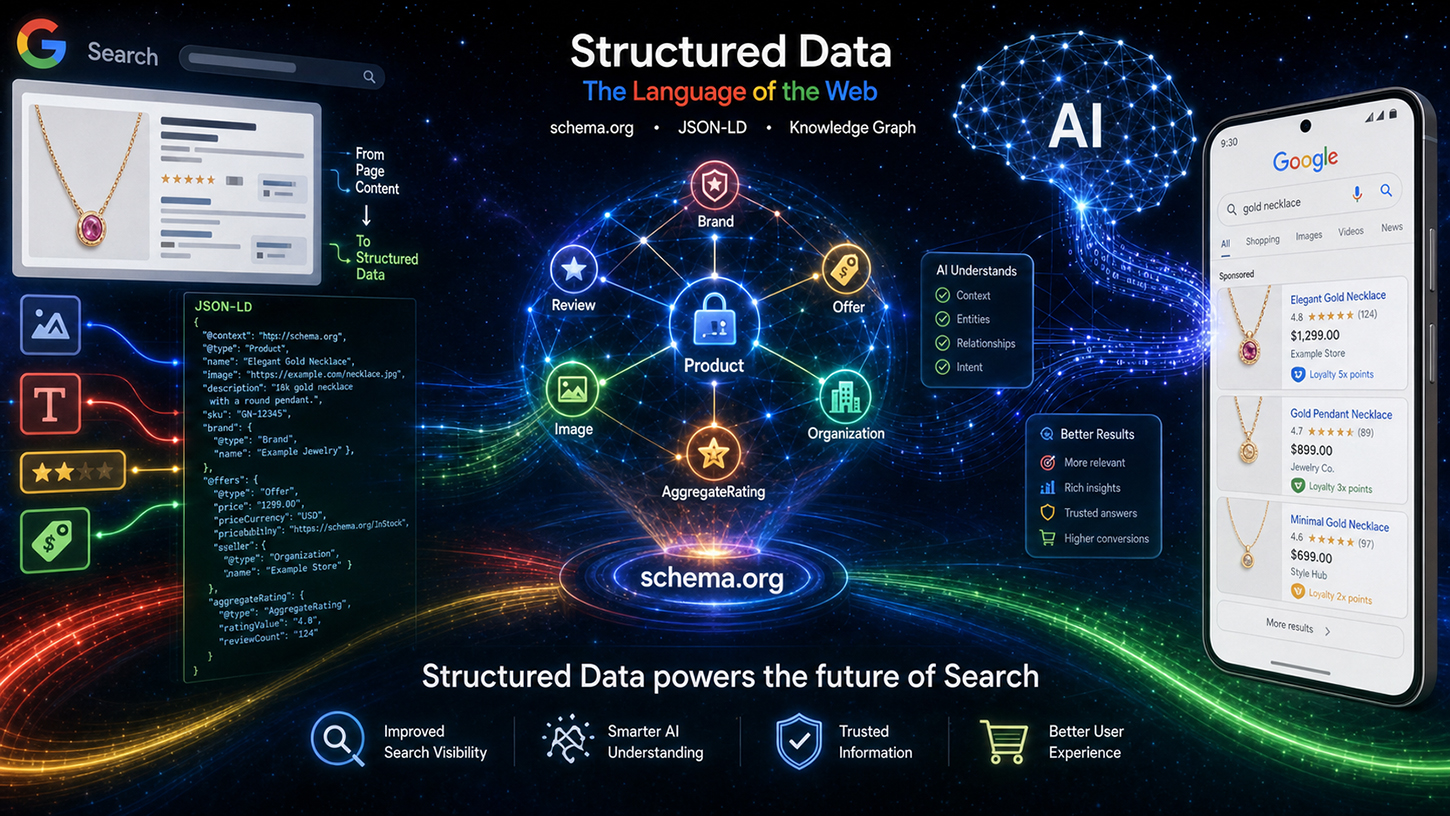
У світі SEO поширюється стійкий міф: в епоху блискучих моделей мов штучного інтелекту, які без зусиль розуміють навіть неструктурований текст, ретельно підтримувані структуровані дані, такі як Schema.org, просто стали застарілими. Але реальність зовсім інша. На заході Google Search Central Live інженер Google Райан Леверінг розвінчав цю помилку та однозначно заявив: структурована розмітка — це не пережиток минулого, а фундаментальна основа нового пошуку на базі штучного інтелекту.
Від нових оглядів штучного інтелекту до автономних торгових агентів, мовні моделі потребують точних, машиночитаних інструкцій, щоб уникнути галюцинацій та ефективно працювати з обчислювальною ефективністю. Ті, хто хоче залишатися помітними в сучасному Інтернеті, повинні допомагати машинам розуміти контекст без двозначності. У цій статті розглядається стратегічна переорієнтація Google, представлені революційні інновації для електронної комерції та контенту, створеного користувачами, а також показано, чому технічне SEO зараз є вирішальною конкурентною перевагою в боротьбі за машинну видимість.
Машини можуть читати інтернет, але лише якщо ви допоможете їм його зрозуміти
21 квітня 2026 року в Торонто відбувся перший захід Google Search Central Live на канадській землі – і це був не звичайний галузевий зібрання. Раян Леверінг, інженер з Google Search Engineering, виступив з, мабуть, найтехнічно насиченішою та стратегічно важливою презентацією дня: «Структуровані дані, якість та штучний інтелект». Те, що він представив, було більше, ніж просто технічним оглядом. Це була чітка заява про майбутнє семантичної мережі в епоху, коли штучний інтелект все частіше бере на себе роль посередника між користувачами та інформацією.
Між двома крайнощами: неправильне або-або
На початку своєї презентації Райан Леверінг протиставив дві діаметрально протилежні думки, що поширюються в SEO-спільноті. З одного боку, існує переконання, що структуровані дані просто зайві в епоху потужних мовних моделей: якщо моделі штучного інтелекту можуть легко інтерпретувати неструктурований текст, навіщо додавати розмітку schema.org до вихідного коду? З іншого боку, деякі ентузіасти поширюють ідею, що структуровані дані — це майбутнє Інтернету, універсальний протокол семантичного зв'язку між автономними агентами штучного інтелекту, який значною мірою замінить традиційний Інтернет.
Леверінг відкинув обидві крайнощі та натомість запропонував нюансовану, емпірично обґрунтовану перспективу. Обидві позиції містили зерно істини, дійшов висновку він, але жодна з них повністю не описувала реальність. Цей нюанс характерний для нинішнього підходу Google до цієї теми: йдеться не про догму, а про прагматичну ефективність.
Чотири аргументи, які пояснюють усе
Центральний аргумент Леверінга можна підсумувати у чотирьох ключових пунктах, які він детальніше розкрив під назвою «Цінність структурованих даних». Перший пункт — це точність: структуровані дані забезпечують значно вищу точність для складних схем, таких як ціни продажу чи програми лояльності, ніж вилучення з вільного тексту на основі LLM. Мовні моделі можуть вводити в оману — вони заповнюють відсутні атрибути, неправильно вкладають дані або отримують доступ до інформації поза контекстом. Під час вилучення цін на товари з великого сайту електронної комерції з десятками подібних товарів рівень помилок значно вищий при виведенні на основі штучного інтелекту, ніж при чітко реалізованій, структурованій розмітці.
Другий момент стосується додаткового контенту: структуровані дані часто містять невидимі метадані, яких просто немає у відображеному HTML-коді сторінки. Повні формати дати ISO, стабільні ідентифікатори для контенту, створеного користувачем, або внутрішні ідентифікатори сутностей — ця інформація існує виключно в розмітці. Жодна мовна модель не може витягти те, чого немає в тексті.
По-третє, ефективність: парсинг структурованої розмітки у багато разів дешевший, ніж обробка великої мовної моделі для вилучення складних даних. Google індексує мільярди сторінок щодня. Розрахунок простий: звичайний парсер, що обробляє JSON-LD, споживає лише частку обчислювальних ресурсів кроку виводу LLM. Тому структуровані дані не тільки семантично кращі, але й значно ефективніші з точки зору бізнесу. Цей момент має безпосереднє відношення до інфраструктури Google.
Четвертий, і, мабуть, найбільш недооцінений, аспект – це фокус: структуровані дані чітко виділяють, яка інформація є релевантною на сторінці, тим самим запобігаючи системам штучного інтелекту виявляти нерелевантні дані. На сторінці продукту з основною статтею, кількома пов'язаними продуктами та панеллю навігації, повною цін, мовна модель без чітких анотацій не може точно визначити, до якої ціни посилатися. Структурована розмітка вирішує цю проблему шляхом однозначного призначення.
Як насправді обробляються структуровані дані
Завдяки Levering процес технічної обробки був прозорим. Дані Schema.org спочатку проходять спеціальну обробку та фільтрацію, перш ніж класифікуватися як індексовані дані – поділені на такі області, як події, покупки та відгуки. Ці підготовлені дані потім надходять до двох різних вихідних каналів: з одного боку, класична сторінка результатів пошуку (SRP), а з іншого – як контекст для систем Google на основі штучного інтелекту, зокрема так званих оглядів штучного інтелекту (AIO) та режиму штучного інтелекту (AIM). Таким чином, структуровані дані – це вже не просто інструмент для створення розширених результатів, а прямий вхід для генеративних відповідей штучного інтелекту. Це являє собою фундаментальну зміну в стратегічній важливості розмітки schema.org.
🎯🎯🎯 Галузевий центр B2B, керований даними, як квазі-внутрішнє рішення

Квазі-власне рішення: Як Xpert.Digital усуває операційні прогалини в B2B-маркетингу та продажах – Розумний контент-орієнтований бізнес - Зображення: Xpert.Digital
Xpert.Digital — це галузевий центр B2B, що базується на даних, який очолює Konrad Wolfenstein . Компанія виступає зовнішнім, квазі-внутрішнім рішенням для промислових партнерів, усуваючи операційні прогалини в маркетингу, контенті та продажах, не вимагаючи додаткових ресурсів з боку клієнта.
Більше інформації тут:
Чому структуровані дані стають інфраструктурою для агентів штучного інтелекту
Фокус на покупках: доставка, лояльність та різноманітність
Значна частина презентації була присвячена інноваціям в електронній комерції. Леверінг пояснив, що, згідно з даними Інституту Баймарда, неочікувані дані про доставку посідають друге та третє місця серед найпоширеніших причин відмови від покупок у кошику. Структурована розмітка для служб доставки може безпосередньо вирішити цю проблему: продавці тепер можуть точно визначати регіони відправлення та призначення, розміри та вагу, порогові значення вартості замовлення, час обробки та приналежність до програм лояльності безпосередньо в коді.
Модель часу доставки, яку використовує Google, поділена на дві фази: час обробки, тобто час від отримання замовлення до передачі перевізнику, та фактичний час доставки. Обидві фази можна анотувати окремо та з високою деталізацією – аж до кінцевого терміну виконання замовлень та того, чи відбувається обробка також у будні дні. Відповідні приклади JSON-LD показують, як тип `ShippingConditions` можна використовувати для визначення безкоштовної доставки для певних країн (наприклад, Франції та Німеччини) та мінімальної вартості замовлення (наприклад, €50).
Інтеграція служб доставки з програмами лояльності є особливо інноваційною. Використовуючи властивість `validForMemberTier`, службу доставки можна явно пов’язати з програмою членства та певним рівнем. Це дає змогу оголошувати переваги доставки для преміум-учасників безпосередньо в розмітці – функція, яку раніше можна було налаштувати лише через Google Merchant Center. Сама пов’язана програма лояльності визначається як об’єкт `MemberProgram` в сутності `Organization` з такими рівнями, як «Золотий» або «Срібний», та пов’язаними перевагами, такими як нагороди за лояльність або винагороди у вигляді балів.
Програми лояльності як семантичні сутності
Впровадження розмітки програм лояльності має економічне значення. Організації можуть визначати кілька незалежних програм членства, кожна з яких має кілька рівнів та диференційовані переваги — бали, ціни для учасників, політику повернення, бонуси за доставку. Ця інформація потім відображається безпосередньо в результатах пошуку Google, як продемонстрував Леверінг на реальних прикладах, зокрема на пропозиції Sephora, яка відображала 30-відсоткову знижку для учасників безпосередньо у фрагменті коду покупки. Міжсторінкове посилання на ідентифікатори, можливість посилатися на визначення програм лояльності з інших сторінок, за словами Леверінга, є наступним запланованим кроком, який наразі називається «Прокладання шляху для міжсторінкового посилання @id». Мета: сильніші організаційні посилання між сторінками товарів та політикою компанії.
Контент, створений користувачем: проблема маркування за допомогою штучного інтелекту
Ще однією важливою темою був подальший розвиток типів схем для користувацького контенту (UGC). Дві нові функції тут особливо актуальні. По-перше, вбудовані публікації та репости підтримуються у розмітці форуму та питань і відповідей, що забезпечує точніше семантичне представлення структур обговорення. По-друге, і це має ще більше стратегічне значення, введено властивість `so#digitalSourceType` для явної ідентифікації машинно-згенерованого контенту.
Ця розробка є прямою відповіддю на потік контенту, згенерованого штучним інтелектом, на таких платформах, як форуми та сайти запитань і відповідей. Веб-майстри тепер можуть вказувати, чи був допис згенерований алгоритмічно, чи за допомогою мовної моделі. Ті, хто не вказує це, неявно вважаються Google авторами-людьми – правило, яке стимулює прозоре маркування. Властивість `digitalSourceType` базується на кодах IPTC для цифрових джерел і розрізняє, серед іншого, контент, згенерований алгоритмічно, та контент, згенерований моделлю.
Вибір зображення: Схема перевершує Open Graph
Менш помітне, але практично ефективне оновлення стосується логіки вибору зображень Google. Система консолідується внутрішньо, з чіткою ієрархією пріоритетів: розмітка Schema.org, зокрема властивості `primaryImageOfPage` та `mainEntity → image`, має пріоритет. Тільки потім йде метатег `og:image` з Open Graph. Ця зміна означає, що для операторів веб-сайтів чиста реалізація основного зображення в schema.org безпосередньо впливає на його відображення в результатах пошуку Google та оглядах штучного інтелекту – це конкретна, вимірювана перевага.
Schema.org сама отримує інвестиції
Також варто відзначити оголошене Google реінвестування у schema.org як відкриту специфікацію. Було згадано три конкретні заходи: публікація статистики щодо частоти використання окремих термінів схеми (дані про поширеність, як показано на слайді, вже доступні для окремих термінів, таких як `digitalSourceType` з інформацією приблизно про 10 000 доменів), публікація власних правил перевірки Google у машинозчитуваних стандартних форматах, таких як SHACL або ShEx, та покращена підтримка правил порядку. Це важливо, оскільки дозволить зовнішнім розробникам створювати власні інструменти перевірки на основі стандартів Google – незалежно від офіційних інструментів тестування, які іноді аварійно завершують роботу під навантаженням.
Валідація: два інструменти, одна мета
Леверінг представив два інструменти валідації, які доповнюють один одного, але застосовують різні критерії тестування. Інструмент тестування розширених результатів пошуку за адресою `search.google.com/test/rich-results` приймає URL-адреси або чистий JSON і перевіряє, чи підходить розмітка для розширених результатів пошуку Google – тому він базується на конкретних вимогах Google, а не на самому стандарті schema.org. `validator.schema.org`, з іншого боку, перевіряє, чи сумісна розмітка зі schema.org, тобто чи дотримується відкритого словника, незалежно від того, чи Google генерує з неї розширені результати. Це призводить до чіткої рекомендації для веб-розробників: слід використовувати обидва інструменти, оскільки розмітка може бути сумісною зі схемою, але не здатною до розширених результатів, і навпаки.
Загальна картина: структуровані дані як інфраструктура штучного інтелекту
Розглядаючи подію в Торонто в цілому, можна побачити зрушення, яке виходить далеко за межі традиційної SEO-оптимізації. Структуровані дані еволюціонують від інструменту для отримання розширених фрагментів до фундаментального стандарту рівня даних для систем штучного інтелекту. Огляди штучного інтелекту та режим штучного інтелекту від Google активно використовують розмітку schema.org як контекст для генерації відповідей та перевірки сутностей. Ті, хто впроваджує правильні, повні та точні структуровані дані, не лише збільшують свої шанси на візуальне виділення в результатах пошуку, але й позиціонують свій контент як надійне первинне джерело відповідей на основі штучного інтелекту.
Згадка Універсального комерційного протоколу (UCP) та WebMCP у цьому контексті не є випадковою. Обидва стандарти комунікації на основі агентів, ранні версії яких Google випустив у 2026 році, вимагають семантичного опису веб-сайтів. Schema.org є основою для цього. У світі, де агенти штучного інтелекту діють автономно в Інтернеті, шукаючи, порівнюючи та ініціюючи транзакції, машиночитаність контенту більше не є необов'язковою, а є необхідною умовою для економічної значущості. Тому презентація Райана Леверінга в Торонто була не просто звітом про технічне оновлення, а й поглядом на інфраструктуру майбутнього Інтернету.
Ви можете переконатися самі за 10 секунд
Якщо ви хочете знати, наскільки добре та комплексно ваш чи інший вебсайт використовує структуровані дані, ви можете скористатися саме тими двома інструментами, які рекомендував Райан Леверінг з Google (з нашого тексту вище):
Тест розширених результатів пошуку Google (фокус на видимості в Google):
Перейдіть на сторінку search.google.com/test/rich-results, скопіюйте URL-адресу будь-якої статті з xpert.digital і натисніть «Перевірити URL-адресу». Інструмент покаже вам, які саме розмітки Google розпізнає на цій сторінці та чи не містять вони помилок.
Валідатор схеми (орієнтований на чисту відповідність стандартам):
Перейдіть на сторінку validator.schema.orgта вставте ту саму URL-адресу. Тут ви можете безпосередньо у вихідному коді, виділеному кольором, побачити, які скрипти JSON-LD (структуровані дані) включив xpert.digital.
Ваш глобальний партнер з маркетингу та розвитку бізнесу
☑️ Наша ділова мова – англійська або німецька
☑️ НОВИНКА: Листування вашою рідною мовою!

Konrad Wolfenstein
Я та моя команда раді бути вашим особистим консультантом.
Ви можете зв'язатися зі мною, заповнивши контактну форму тут просто зателефонувавши мені за номером +49 7348 4088 965. Моя адреса електронної пошти [email protected]:, або
Я з нетерпінням чекаю нашого спільного проєкту.
☑️ Підтримка МСП у стратегії, консалтингу, плануванні та впровадженні
☑️ Створення або переорієнтація цифрової стратегії та діджиталізації
☑️ Розширення та оптимізація процесів міжнародних продажів
☑️ Глобальні та цифрові торгові платформи B2B
☑️ Розвиток бізнесу Pioneer / Маркетинг / PR / Виставки
Підтримка B2B та SaaS для SEO та GEO (пошук зі штучним інтелектом) поєднання: універсальне рішення для B2B-компаній

Підтримка B2B та SaaS для SEO та GEO (пошук зі штучним інтелектом) поєднані: універсальне рішення для B2B-компаній - Зображення: Xpert.Digital
Пошук зі штучним інтелектом змінює все: як це SaaS-рішення назавжди революціонізує ваш рейтинг B2B.
Цифровий ландшафт для B2B-компаній зазнає швидких змін. Під впливом штучного інтелекту правила онлайн-видимості переписуються. Для компаній завжди було викликом не лише бути помітними в цифровій масі, але й бути релевантними для потрібних осіб, які приймають рішення. Традиційні SEO-стратегії та управління локальною присутністю (геомаркетинг) є складними, трудомісткими та часто є боротьбою з постійно мінливими алгоритмами та жорсткою конкуренцією.
Але що, якби існувало рішення, яке не лише спростило б цей процес, але й зробило б його розумнішим, більш прогнозованим та набагато ефективнішим? Саме тут вступає в гру поєднання спеціалізованої підтримки B2B з потужною платформою SaaS (програмне забезпечення як послуга), спеціально розробленою для потреб SEO та GEO в епоху пошуку на основі штучного інтелекту.
Це нове покоління інструментів більше не покладається виключно на ручний аналіз ключових слів та стратегії зворотних посилань. Натомість воно використовує штучний інтелект для точнішого розуміння мети пошуку, автоматичної оптимізації локальних факторів ранжування та проведення конкурентного аналізу в режимі реального часу. Результатом є проактивна стратегія, заснована на даних, яка надає B2B-компаніям вирішальну перевагу: їх не лише знаходять, але й сприймають як провідного авторитета у своїй ніші та регіоні.
Ось симбіоз підтримки B2B та SaaS-технології на базі штучного інтелекту, яка трансформує SEO та GEO-маркетинг, а також як ваша компанія може отримати від цього вигоду для сталого зростання в цифровому просторі.
Більше інформації тут:
















