
Штучний інтелект та SEO з BERT – представлення двонаправлених енкодерів від Transformers – модель у сфері обробки природної мови (NLP)

Вибір голосу 📢
Опубліковано: 4 жовтня 2024 р. / Оновлено: 4 жовтня 2024 р. – Автор: Konrad Wolfenstein

Штучний інтелект та SEO з BERT – Представлення двонаправлених енкодерів від Transformers – Модель у галузі обробки природної мови (NLP) – Зображення: Xpert.Digital
🚀💬 Розроблено Google: BERT та його значення для NLP - Чому двонаправлене розуміння тексту є критично важливим
🔍🗣️ BERT, скорочення від Bidirectional Encoder Representations from Transformers (Двонаправлені представлення кодувальника від Transformers), — це значна модель у галузі обробки природної мови (NLP), розроблена Google. Вона революціонізувала спосіб розуміння мови машинами. На відміну від попередніх моделей, які аналізували текст послідовно зліва направо або навпаки, BERT забезпечує двонаправлену обробку. Це означає, що він схоплює контекст слова як з попередньої, так і з наступної текстової послідовності. Ця здатність значно покращує розуміння складних лінгвістичних зв'язків.
🔍 Архітектура BERT
В останні роки одним із найважливіших досягнень у обробці природної мови (NLP) стало поява моделі Transformer, описаної в PDF-документі 2017 року «Attention is all you need» ( Вікіпедія ). Ця модель фундаментально змінила галузь, відмовившись від раніше використовуваних структур, таких як машинний переклад. Натомість вона спирається виключно на механізми уваги. Модель Transformer з того часу лягла в основу багатьох моделей, які представляють собою сучасний рівень у різних галузях, включаючи генерацію мовлення, переклад тощо.
Ілюстрація основних компонентів моделі Трансформера – Зображення: Google
BERT базується на цій трансформаторній архітектурі. Ця архітектура використовує так звані механізми самоуваги для аналізу зв'язків між словами в реченні. Кожному слову приділяється увага в контексті всього речення, що призводить до точнішого розуміння синтаксичних та семантичних зв'язків.
Автори статті «Увага – це все, що вам потрібно»:
- Ашіш Васвані (Google Brain)
- Ноам Шазір (Google Brain)
- Нікі Пармар (Google Research)
- Якоб Ушкорейт (Google Research)
- Лайон Джонс (Google Research)
- Айдан Н. Гомес (Університет Торонто, робота частково виконана в Google Brain)
- Лукаш Кайзер (Google Brain)
- Ілля Полосухін (незалежний, попередня робота в Google Research)
Ці автори зробили значний внесок у розробку моделі Трансформера, представленої в цій статті.
🔄 Двонаправлена обробка
Ключовою особливістю BERT є її здатність обробляти текст двонаправлено. У той час як традиційні моделі, такі як рекурентні нейронні мережі (RNN) або мережі довгої короткочасної пам'яті (LSTM), обробляють текст лише в одному напрямку, BERT аналізує контекст слова в обох напрямках. Це дозволяє моделі краще вловлювати тонкі нюанси значення та, таким чином, робити точніші прогнози.
🕵️♂️ Моделювання мовлення під маскою
Ще одним інноваційним аспектом BERT є метод маскованої мовної моделі (MLM). Тут випадково вибрані слова в реченні маскуються, і модель навчається передбачати ці слова на основі навколишнього контексту. Цей метод змушує BERT розвивати глибоке розуміння контексту та значення кожного слова в реченні.
🚀 Навчання та адаптація BERT
BERT проходить двоетапний процес навчання: попереднє навчання та точне налаштування.
📚 Попереднє тренування
На попередньому навчанні BERT навчається з великими обсягами тексту для вивчення загальних мовних шаблонів. Це включає статті Вікіпедії та інші великі текстові корпуси. Під час цього етапу модель вивчає основні лінгвістичні структури та контексти.
🔧 Точне налаштування
Після попереднього навчання BERT адаптується для конкретних завдань NLP, таких як класифікація тексту або аналіз настроїв. Модель навчається на менших наборах даних, пов'язаних із завданнями, для оптимізації її продуктивності для конкретних застосувань.
🌍 Галузі застосування BERT
BERT виявився надзвичайно корисним у багатьох сферах обробки природної мови:
Пошукова оптимізація
Google використовує BERT для кращого розуміння пошукових запитів та відображення більш релевантних результатів. Це значно покращує взаємодію з користувачем.
Класифікація тексту
BERT може класифікувати документи за темами або аналізувати настрій у текстах.
Розпізнавання іменованих об'єктів (NER)
Модель ідентифікує та класифікує іменовані сутності в текстах, такі як імена людей, місць або організацій.
Системи питань і відповідей
BERT використовується для надання точних відповідей на поставлені запитання.
🧠 Значення BERT для майбутнього ШІ
BERT встановив нові стандарти для моделей NLP та проклав шлях для подальших інновацій. Завдяки своїй здатності до двонаправленої обробки та глибокому розумінню мовних контекстів, він значно підвищив ефективність та точність застосувань штучного інтелекту.
🔜 Майбутні розробки
Очікується, що подальший розвиток BERT та подібних моделей буде спрямований на створення ще потужніших систем. Вони зможуть обробляти складніші мовні завдання та використовуватися в широкому спектрі нових застосувань. Інтеграція таких моделей у повсякденні технології може докорінно змінити те, як ми взаємодіємо з комп'ютерами.
🌟 Віха в розвитку штучного інтелекту
BERT є важливою віхою в розвитку штучного інтелекту та революціонізував спосіб обробки природної мови машинами. Його двонаправлена архітектура дозволяє глибше зрозуміти лінгвістичні зв'язки, що робить його незамінним для широкого кола застосувань. У міру розвитку досліджень такі моделі, як BERT, продовжуватимуть відігравати центральну роль у вдосконаленні систем штучного інтелекту та відкритті нових можливостей для їх використання.
📣 Подібні теми
- 📚 Вступ до BERT: Новаторська модель НЛП
- 🔍 BERT та роль двонаправленості в НЛП
- 🧠 Модель Трансформера: Основа BERT
- 🚀 Моделювання маскованої мови: ключ до успіху BERT
- 📈 Налаштування BERT: від попереднього навчання до точного налаштування
- 🌐 Галузі застосування BERT у сучасних технологіях
- 🤖 Вплив BERT на майбутнє штучного інтелекту
- 💡 Перспективи на майбутнє: Подальший розвиток BERT
- 🏆 BERT як віха в розвитку ШІ
- 📰 Автори статті про Трансформерів «Увага — це все, що вам потрібно»: Розуми, що стоять за BERT
#️⃣ Хештеги: #НЛП #ШтучнийІнтелект #МоделюванняМови #Трансформер #МашиннеНавчання
🎯🎯🎯 Скористайтеся перевагами великої, п'ятикратної експертизи Xpert.Digital у комплексному пакеті послуг | BD, R&D, XR, PR та оптимізація цифрової видимості

Скористайтеся перевагами великого, п'ятикратного досвіду Xpert.Digital у комплексному пакеті послуг | Дослідження та розробки, XR, PR та оптимізація цифрової видимості - Зображення: Xpert.Digital
Xpert.digital має глибокі знання в різних галузях. Це дозволяє нам розробити кравці, розроблені стратегії, пристосовані до вимог та проблем вашого конкретного сегменту ринку. Постійно аналізуючи тенденції на ринку та здійснюючи розвиток галузі, ми можемо діяти з передбаченням та пропонувати інноваційні рішення. З поєднанням досвіду та знань ми створюємо додаткову цінність та надаємо своїм клієнтам вирішальну конкурентну перевагу.
Детальніше про це тут:
BERT: Революційна 🌟 технологія НЛП
🚀 BERT, скорочення від Bidirectional Encoder Representations from Transformers (Двонаправлені представлення кодувальників від Transformers), — це вдосконалена мовна модель, розроблена Google, яка стала значним проривом в обробці природної мови (NLP) з моменту її появи у 2018 році. Вона базується на архітектурі Transformer, яка революціонізувала те, як машини розуміють та обробляють текст. Але що саме робить BERT таким особливим і для чого він використовується? Щоб відповісти на це питання, нам потрібно детальніше розглянути технічні основи BERT, принципи його роботи та його застосування.
📚 1. Основи обробки природної мови
Щоб повністю зрозуміти значення BERT, корисно коротко розглянути основи обробки природної мови (NLP). NLP займається взаємодією між комп'ютерами та людською мовою. Його мета — навчити машини аналізувати, розуміти та реагувати на текстові дані. До появи таких моделей, як BERT, обробка машинної мови часто була пов'язана зі значними труднощами, зокрема через неоднозначність, контекстну залежність та складну структуру людської мови.
📈 2. Розробка моделей НЛП
До появи BERT більшість моделей NLP базувалися на так званих однонаправлених архітектурах. Це означало, що ці моделі читали текст або зліва направо, або справа наліво, а це означало, що вони могли враховувати лише обмежену кількість контексту під час обробки слова в реченні. Це обмеження часто призводило до того, що моделі не могли повністю охопити семантичний контекст речення. Це ускладнювало точну інтерпретацію неоднозначних або контекстно-залежних слів.
Ще одним важливим розвитком у дослідженнях НЛП до BERT була модель word2vec, яка дозволяла комп'ютерам перетворювати слова у вектори, що відображають семантичну схожість. Однак навіть тут контекст обмежувався безпосереднім оточенням слова. Пізніше були розроблені рекурентні нейронні мережі (RNN) та, зокрема, моделі довгої короткочасної пам'яті (LSTM), які дозволили краще розуміти текстові послідовності, зберігаючи інформацію в кількох словах. Однак ці моделі також мали свої обмеження, особливо при роботі з довгими текстами та одночасному розумінні контексту в обох напрямках.
🔄 3. Революція через трансформаторну архітектуру
Прорив відбувся з появою архітектури Transformer у 2017 році, яка є основою для BERT. Моделі Transformer розроблені для забезпечення паралельної обробки тексту з урахуванням контексту слова як з попереднього, так і з наступного тексту. Це досягається за допомогою так званих механізмів самоуваги, які призначають вагове значення кожному слову в реченні на основі його важливості відносно інших слів у реченні.
На відміну від попередніх підходів, трансформаторні моделі є не однонаправленими, а двонаправленими. Це означає, що вони можуть отримувати інформацію як з лівого, так і з правого контекстів слова, щоб створити більш повне та точне представлення слова та його значення.
🧠 4. BERT: Двонаправлена модель
BERT виводить продуктивність архітектури Transformer на новий рівень. Модель розроблена для захоплення контексту слова не лише зліва направо або справа наліво, а й в обох напрямках одночасно. Це дозволяє BERT враховувати повний контекст слова в реченні, що призводить до значного підвищення точності в завданнях обробки природної мови.
Ключовою особливістю BERT є використання так званої моделі маскованої мови (MLM). Під час навчання BERT випадково вибрані слова в реченні замінюються маскою, і модель навчається вгадувати ці замасковані слова на основі контексту. Цей метод дозволяє BERT вивчати глибші та точніші зв'язки між словами в реченні.
Крім того, BERT використовує метод під назвою «Предбачання наступного речення» (NSP), за допомогою якого модель навчається передбачати, чи одне речення йде за іншим. Це покращує здатність BERT розуміти довші тексти та розпізнавати складніші зв'язки між реченнями.
🌐 5. Практичне застосування BERT
BERT виявився надзвичайно корисним для широкого кола завдань NLP. Ось деякі з найважливіших сфер застосування:
📊 а) Класифікація тексту
Одним із найпоширеніших застосувань BERT є класифікація текстів, де тексти поділяються на заздалегідь визначені категорії. Прикладами є аналіз настроїв (наприклад, розпізнавання того, чи є текст позитивним чи негативним) або категоризація відгуків клієнтів. Завдяки глибокому розумінню контексту слів, BERT може надавати точніші результати, ніж попередні моделі.
❓ б) Системи питань і відповідей
BERT також використовується в системах відповідей на запитання, де модель витягує відповіді на поставлені запитання з тексту. Ця можливість особливо важлива в таких додатках, як пошукові системи, чат-боти та віртуальні помічники. Завдяки своїй двонаправленій архітектурі BERT може витягувати релевантну інформацію з тексту, навіть якщо запитання сформульовано опосередковано.
🌍 c) Переклад тексту
Хоча сама BERT не розроблена безпосередньо як модель перекладу, її можна використовувати в поєднанні з іншими технологіями для покращення машинного перекладу. Завдяки кращому розумінню семантичних зв'язків у реченні, BERT може допомогти створювати точніші переклади, особливо з неоднозначними або складними фразами.
🏷️ d) Розпізнавання іменованих об'єктів (NER)
Ще однією сферою застосування є розпізнавання іменованих сутностей (NER), яке передбачає ідентифікацію конкретних сутностей, таких як імена, місця чи організації, в тексті. BERT виявився особливо ефективним у цьому завданні, оскільки він повністю враховує контекст речення і, таким чином, може краще розпізнавати сутності, навіть якщо вони мають різні значення в різних контекстах.
✂️ e) Короткий зміст тексту
Здатність BERT розуміти весь контекст тексту також робить його потужним інструментом для автоматичного підсумовування тексту. Його можна використовувати для вилучення найважливішої інформації з довгого тексту та створення стислого підсумку.
🌟 6. Важливість BERT для досліджень та промисловості
Впровадження BERT започаткувало нову еру в дослідженнях NLP. Це була одна з перших моделей, яка повністю використала можливості двонаправленої архітектури трансформатора, встановивши стандарт для багатьох наступних моделей. Численні компанії та дослідницькі установи інтегрували BERT у свої конвеєри NLP для підвищення продуктивності своїх застосувань.
Крім того, BERT проклав шлях для подальших інновацій у галузі мовних моделей. Наприклад, згодом були розроблені такі моделі, як GPT (Generative Pretrained Transformer - генеративний попередньо навчений трансформатор) та T5 (Text-to-Text Transfer Transformer - трансформатор передачі тексту в текст), які базуються на подібних принципах, але пропонують специфічні покращення для різних випадків використання.
🚧 7. Проблеми та обмеження BERT
Незважаючи на численні переваги, BERT також має деякі проблеми та обмеження. Однією з найбільших перешкод є високі обчислювальні зусилля, необхідні для навчання та застосування моделі. Оскільки BERT — це дуже велика модель з мільйонами параметрів, вона вимагає потужного обладнання та значних обчислювальних ресурсів, особливо під час обробки великих наборів даних.
Ще однією проблемою є потенційна упередженість, яка може бути присутня в навчальних даних. Оскільки BERT навчається на великих обсягах текстових даних, він іноді відображає упередження та стереотипи, присутні в цих даних. Однак дослідники постійно працюють над виявленням та вирішенням цих проблем.
🔍 Незамінний інструмент для сучасних програм обробки мовлення
BERT значно покращив спосіб розуміння машинами людської мови. Завдяки своїй двонаправленій архітектурі та інноваційним методам навчання він здатний глибоко та точно сприймати контекст слів у реченні, що призводить до більшої точності в багатьох завданнях NLP. Чи то в класифікації тексту, чи в системах відповідей на запитання, чи в розпізнаванні сутностей, BERT зарекомендував себе як незамінний інструмент для сучасних застосувань обробки природної мови.
Дослідження в галузі обробки природної мови, безсумнівно, продовжуватимуть розвиватися, і BERT заклав основу для багатьох майбутніх інновацій. Незважаючи на існуючі виклики та обмеження, BERT вражаюче демонструє, наскільки далеко просунулася технологія за короткий час і які захопливі можливості ще відкриються в майбутньому.
🌀 Трансформер: Революція в обробці природної мови
🌟 В останні роки одним із найважливіших досягнень у обробці природної мови (НЛП) стало поява моделі Трансформера, описаної в статті 2017 року «Увага — це все, що вам потрібно». Ця модель фундаментально змінила галузь, відмовившись від раніше використовуваних рекурентних або згорткових структур для завдань перетворення послідовностей, таких як машинний переклад. Натомість вона спирається виключно на механізми уваги. Модель Трансформера з того часу лягла в основу багатьох моделей, які представляють собою сучасний рівень у різних галузях, включаючи генерацію мовлення, переклад тощо.
🔄 Трансформер: Зміна парадигми
До появи Transformer більшість моделей для задач послідовності базувалися на рекурентних нейронних мережах (RNN) або мережах довгої короткочасної пам'яті (LSTM), які за своєю суттю працюють послідовно. Ці моделі обробляють вхідні дані крок за кроком, створюючи приховані стани, які поширюються вздовж послідовності. Хоча цей метод ефективний, він є обчислювально дорогим і складним для паралелізації, особливо для довгих послідовностей. Крім того, RNN мають труднощі з навчанням довгострокових залежностей через проблему зникнення градієнта.
Ключова інновація Transformer полягає у використанні механізмів самоуважності, які дозволяють моделі зважувати важливість різних слів у реченні відносно одне одного, незалежно від їхньої позиції. Це дозволяє моделі фіксувати зв'язки між широко розділеними словами ефективніше, ніж RNN або LSTM, і робити це паралельно, а не послідовно. Це не лише підвищує ефективність навчання, але й продуктивність у таких завданнях, як машинний переклад.
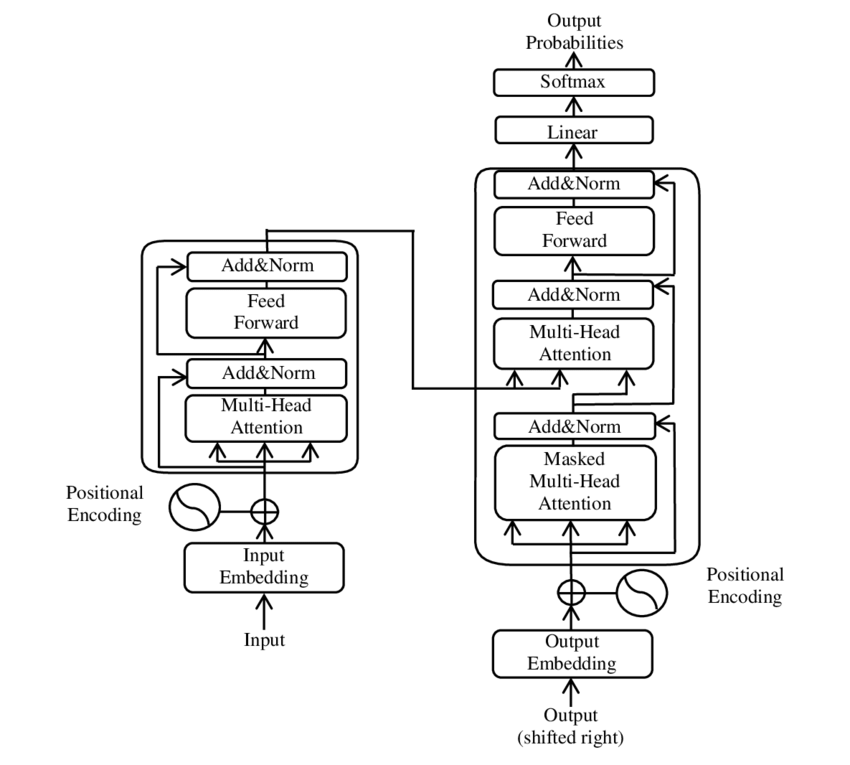
🧩 Архітектура моделі
Трансформатор складається з двох основних компонентів: кодера та декодера, обидва з яких складаються з кількох шарів і значною мірою залежать від механізмів багатоголової уваги.
⚙️ Енкодер
Кодер складається з шести однакових шарів, кожен з яких має два підшари:
1. Багатоголова самоувага
Цей механізм дозволяє моделі зосереджуватися на різних частинах вхідного речення під час обробки кожного слова. Замість того, щоб обчислювати увагу в одному просторі, багатоголова увага проектує вхідні дані в кілька різних просторів, тим самим фіксуючи різні типи зв'язків між словами.
2. Позиційно повністю зв'язані мережі прямого зв'язку
Після рівня уваги, повністю зв'язана мережа прямого зв'язку застосовується незалежно в кожній позиції. Це допомагає моделі обробляти кожне слово в контексті та використовувати інформацію з механізму уваги.
Щоб зберегти структуру вхідної послідовності, модель також включає позиційні кодування. Оскільки перетворювач не обробляє слова послідовно, ці кодування є вирішальними для надання моделі інформації про порядок слів у реченні. Позиційні кодування додаються до вбудовування слів, щоб модель могла розрізняти різні позиції в послідовності.
🔍 Декодер
Як і кодер, декодер також складається з шести шарів, кожен з яких має додатковий механізм уваги, що дозволяє моделі зосереджуватися на відповідних частинах вхідної послідовності під час генерації виходу. Декодер також використовує техніку маскування, щоб запобігти врахуванню майбутніх позицій, таким чином зберігаючи авторегресивний характер генерації послідовності.
🧠 Багатоголова увага та скалярна увага до продукту
Основою Трансформера є механізм багатоголової уваги, який є розширенням простішої скалярної уваги на основі добутку. Функцію уваги можна розглядати як відображення між запитом та набором пар ключ-значення, де кожен ключ представляє слово в послідовності, а значення представляє відповідну контекстну інформацію.
Механізм багатоголової уваги дозволяє моделі зосереджуватися на різних частинах послідовності одночасно. Проектуючи вхідні дані в кілька підпросторів, модель може фіксувати багатший набір зв'язків між словами. Це особливо корисно для таких завдань, як машинний переклад, де розуміння контексту слова вимагає багатьох різних факторів, таких як синтаксична структура та семантичне значення.
Формула для скалярного добутку уваги така:
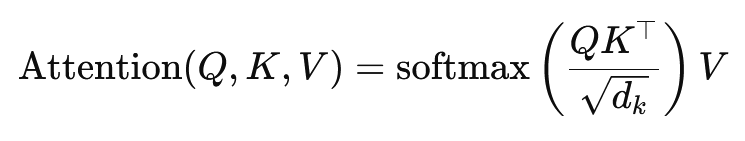
Тут (Q) – матриця запитів, (K) – матриця ключів, а (V) – матриця значень. Член (sqrt{d_k}) – це коефіцієнт масштабування, який запобігає занадто великому розміру скалярних добутків, що може призвести до дуже малих градієнтів та повільнішого навчання. Функція softmax застосовується для забезпечення того, щоб вагові коефіцієнти уваги дорівнювали одиниці.
🚀 Переваги трансформатора
Трансформер пропонує кілька важливих переваг порівняно з традиційними моделями, такими як RNN та LSTM:
1. Паралелізація
Оскільки трансформатор обробляє всі токени послідовності одночасно, він може бути високопаралелізованим і тому набагато швидше навчається, ніж RNN або LSTM, особливо з великими наборами даних.
2. Довгострокові залежності
Механізм самоуваги дозволяє моделі ефективніше фіксувати зв'язки між віддаленими словами, ніж RNN, які обмежені послідовним характером своїх обчислень.
3. Масштабованість
Трансформатор може легко масштабуватися до дуже великих наборів даних і довших послідовностей, не страждаючи від вузьких місць у продуктивності, пов'язаних з RNN.
🌍 Застосування та ефекти
З моменту своєї появи Transformer став основою для широкого спектру моделей NLP. Одним з найяскравіших прикладів є BERT (Bidirectional Encoder Representations from Transformers), який використовує модифіковану архітектуру Transformer для досягнення найсучаснішої продуктивності в багатьох завданнях NLP, включаючи відповіді на запитання та класифікацію тексту.
Ще однією важливою розробкою є GPT (Генеративний попередньо навчений трансформатор), який використовує версію трансформатора з обмеженим декодером для генерації тексту. Моделі GPT, включаючи GPT-3, зараз використовуються для численних застосувань, від створення контенту до автодоповнення коду.
🔍 Потужна та гнучка модель
Трансформер докорінно змінив наш підхід до завдань НЛП. Він пропонує потужну та гнучку модель, яку можна застосовувати до широкого кола проблем. Його здатність обробляти довгострокові залежності та ефективність у навчанні зробили його кращим архітектурним підходом для багатьох найсучасніших моделей. У міру розвитку досліджень ми, ймовірно, побачимо подальші вдосконалення та адаптації Трансформера, особливо в таких галузях, як обробка зображень та мовлення, де механізми уваги демонструють багатообіцяючі результати.
Ми там для вас - поради - планування - впровадження - управління проектами
☑ Експерт з галузі, тут зі своїм власним промисловим центром Xpert.digital з понад 2500 спеціалізованих внесків

Konrad Wolfenstein
Я радий допомогти вам як особистого консультанта.
Ви можете зв’язатися зі мною, заповнивши контактну форму нижче або просто зателефонуйте мені за номером +49 89 674 804 (Мюнхен) .
Я з нетерпінням чекаю нашого спільного проекту.
Напишіть мені

Xpert.Digital - Konrad Wolfenstein
Xpert.digital - це центр для промисловості з фокусом, оцифруванням, машинобудуванням, логістикою/внутрішньологічною та фотоелектричною.
За допомогою нашого рішення щодо розвитку бізнесу на 360 ° ми підтримуємо відомі компанії від нового бізнесу до після продажу.
Ринкова розвідка, маха, автоматизація маркетингу, розвиток контенту, PR, поштові кампанії, персоналізовані соціальні медіа та виховання свинцю є частиною наших цифрових інструментів.
Ви можете знайти більше на: www.xpert.digital - www.xpert.solar - www.xpert.plus
Підтримувати зв’язок

















