


Die neue digitale Sichtbarkeit – Eine Entschlüsselung von SEO, LLMO, GEO, AIO und AEO – SEO alleine ist nicht mehr ausreichend – Bild: Xpert.Digital
Ein strategischer Leitfaden für Generative Engine Optimization (GEO) und Large Language Model Optimization (LLMO) (Lesezeit: 30 min / Keine Werbung / Keine Paywall)
Der Paradigmenwechsel: Von der Suchmaschinenoptimierung zur Generative Engine Optimization
Die Neudefinition der digitalen Sichtbarkeit im Zeitalter der KI
Die digitale Informationslandschaft durchläuft derzeit ihre tiefgreifendste Transformation seit der Einführung der grafischen Websuche. Der traditionelle Mechanismus, bei dem Suchmaschinen eine Liste potenzieller Antworten in Form von blauen Links präsentieren und es dem Nutzer überlassen, diese zu sichten, zu vergleichen und die relevanten Informationen zu synthetisieren, wird zunehmend durch ein neues Paradigma ersetzt. An seine Stelle tritt ein „Ask-and-Receive“-Modell, das von generativen KI-Systemen angetrieben wird. Diese Systeme übernehmen die Synthesearbeit für den Nutzer und liefern eine direkte, kuratierte und in natürlicher Sprache formulierte Antwort auf eine gestellte Frage.
Diese fundamentale Veränderung hat weitreichende Konsequenzen für die Definition von digitaler Sichtbarkeit. Erfolg bedeutet nicht mehr nur, auf der ersten Ergebnisseite zu erscheinen; er wird zunehmend dadurch definiert, ein integraler Bestandteil der KI-generierten Antwort zu sein – sei es als direkt zitierte Quelle, als erwähnte Marke oder als Grundlage für die synthetisierten Informationen. Diese Entwicklung beschleunigt den bereits bestehenden Trend zu „Zero-Click Searches“, bei denen Nutzer ihre Informationsbedürfnisse direkt auf der Suchergebnisseite befriedigen, ohne eine Website besuchen zu müssen. Für Unternehmen und Content-Ersteller ist es daher unerlässlich, die neuen Spielregeln zu verstehen und ihre Strategien anzupassen.
Passend dazu:


Das neue Vokabular der Optimierung: Eine Entschlüsselung von SEO, LLMO, GEO, AIO und AEO
Mit dem Aufkommen dieser neuen Technologien hat sich ein komplexes und oft verwirrendes Vokabular entwickelt. Eine klare Abgrenzung der Begriffe ist die Voraussetzung für eine zielgerichtete Strategie.
SEO (Search Engine Optimization): Dies ist die etablierte, grundlegende Disziplin der Optimierung von Webinhalten für klassische Suchmaschinen wie Google und Bing. Das Hauptziel ist es, in den traditionellen, linkbasierten Suchergebnislisten (SERPs) hohe Rankings zu erzielen. SEO bleibt auch im KI-Zeitalter von entscheidender Bedeutung, da es das Fundament für jede weiterführende Optimierung bildet.
LLMO (Large Language Model Optimization): Dieser präzise Fachbegriff beschreibt die Optimierung von Inhalten speziell dafür, dass sie von textbasierten großen Sprachmodellen (Large Language Models, LLMs) wie OpenAIs ChatGPT oder Googles Gemini effektiv verstanden, verarbeitet und zitiert werden können. Das Ziel ist nicht mehr das Ranking, sondern die Aufnahme als glaubwürdige Quelle in die von der KI generierten Antworten.
GEO (Generative Engine Optimization): Ein etwas breiter gefasster und oft synonym zu LLMO verwendeter Begriff. GEO konzentriert sich auf die Optimierung für das gesamte generative System oder die „Engine“ (z. B. Perplexity, Google AI Overviews), die eine Antwort erzeugt, und nicht nur auf das Sprachmodell selbst. Es geht darum, sicherzustellen, dass die Botschaft einer Marke korrekt dargestellt und über diese neuen Kanäle verbreitet wird.
AIO (AI Optimization): Dies ist ein Überbegriff mit mehreren Bedeutungen, was zu Verwirrung führen kann. Im Kontext der Content-Optimierung bezeichnet AIO die allgemeine Strategie zur Anpassung von Inhalten für jegliche Art von KI-Systemen. Der Begriff kann sich jedoch auch auf die technische Optimierung der KI-Modelle selbst oder auf den Einsatz von KI zur Automatisierung von Geschäftsprozessen beziehen. Diese Mehrdeutigkeit macht ihn für die spezifische Content-Strategie weniger präzise.
AEO (Answer Engine Optimization): Ein spezialisierter Teilbereich von GEO/LLMO, der sich auf die Optimierung für direkte Antwort-Features innerhalb von Suchsystemen konzentriert, wie sie beispielsweise in Googles AI Overviews zu finden sind.
Für die Zwecke dieses Berichts werden GEO und LLMO als primäre Begriffe für die neuen Content-Optimierungsstrategien verwendet, da sie das Phänomen am treffendsten beschreiben und in der Branche zunehmend als Standard etabliert werden.
Warum traditionelles SEO grundlegend, aber nicht mehr ausreichend ist
Ein weit verbreitetes Missverständnis ist, dass die neuen Optimierungsdisziplinen SEO ersetzen werden. Tatsächlich ergänzen und erweitern LLMO und GEO die klassische Suchmaschinenoptimierung. Die Beziehung ist symbiotisch: Ohne eine solide SEO-Basis ist eine effektive Optimierung für generative KI kaum möglich.
SEO als Fundament: Kernaspekte der technischen SEO – wie eine schnelle Ladezeit, eine saubere Seitenarchitektur und die Sicherstellung der Crawlbarkeit – sind die absolute Voraussetzung dafür, dass KI-Systeme eine Website überhaupt erst finden, lesen und verarbeiten können. Ebenso bleiben etablierte Qualitätssignale wie hochwertige Inhalte und themenrelevante Backlinks entscheidend, um als vertrauenswürdige Quelle eingestuft zu werden.
Die RAG-Verbindung: Viele generative Suchmaschinen nutzen eine Technologie namens Retrieval-Augmented Generation (RAG), um ihre Antworten mit aktuellen Informationen aus dem Web anzureichern. Dabei greifen sie häufig auf die Top-Ergebnisse klassischer Suchmaschinen zurück. Ein hohes Ranking in der traditionellen Suche erhöht somit direkt die Wahrscheinlichkeit, von einer KI als Quelle für eine generierte Antwort herangezogen zu werden.
Die Lücke der alleinigen SEO: Trotz seiner fundamentalen Bedeutung reicht SEO allein nicht mehr aus. Ein Top-Ranking ist keine Garantie mehr für Sichtbarkeit oder Traffic, da die KI-generierte Antwort oft über den traditionellen Ergebnissen thront und die Nutzeranfrage direkt beantwortet. Das neue Ziel ist die Nennung und Synthese innerhalb dieser KI-Antwort. Dies erfordert eine zusätzliche Optimierungsebene, die auf maschinelle Lesbarkeit, kontextuelle Tiefe und nachweisbare Autorität abzielt – Aspekte, die über die traditionelle Keyword-Optimierung hinausgehen.
Die Fragmentierung der Terminologie ist mehr als eine semantische Debatte; sie ist ein Symptom für einen Paradigmenwechsel in seinen Anfängen. Die verschiedenen Akronyme spiegeln unterschiedliche Perspektiven wider, die darum wetteifern, das neue Feld zu definieren – von einer technischen (AIO, LLMO) bis zu einer marketingorientierten Sichtweise (GEO, AEO). Diese Unklarheit und der Mangel an einem fest etablierten Standard schaffen ein strategisches Zeitfenster. Während größere, stärker in Silos arbeitende Organisationen noch über Terminologie und Strategie debattieren, können agilere Unternehmen die Kernprinzipien von maschinenlesbaren, autoritativen Inhalten übernehmen und sich einen signifikanten Vorsprung als „First Mover“ sichern. Die aktuelle Unbestimmtheit ist keine Barriere, sondern eine Chance.
Vergleich der Optimierungsdisziplinen
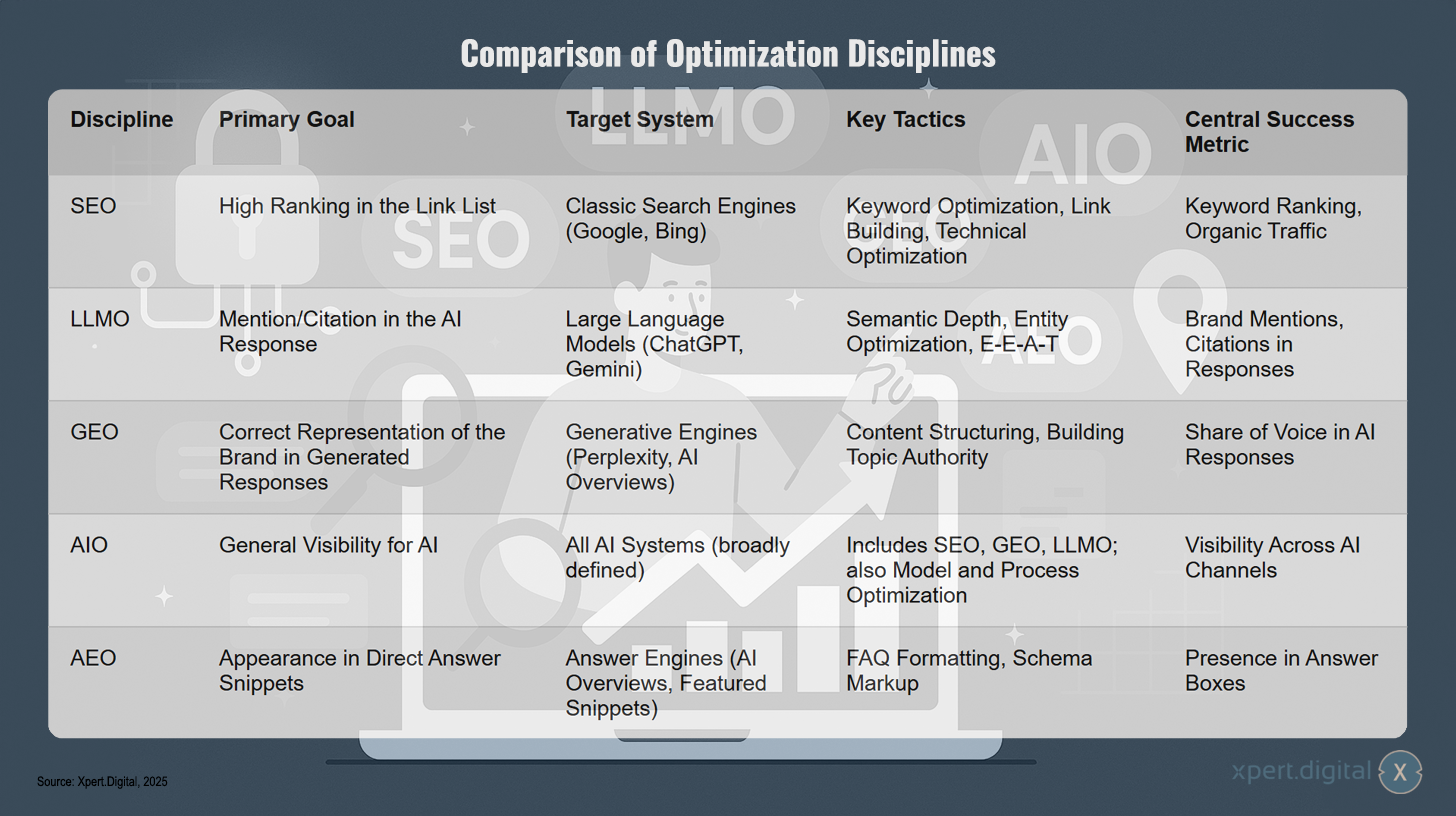
Vergleich der Optimierungsdisziplinen – Bild: Xpert.Digital
Die verschiedenen Optimierungsdisziplinen verfolgen unterschiedliche Ziele und Strategien. SEO konzentriiert sich auf hohe Rankings in klassischen Suchmaschinen wie Google und Bing durch Keyword-Optimierung, Linkaufbau und technische Verbesserungen, wobei der Erfolg anhand von Keyword-Rankings und organischem Traffic gemessen wird. LLMO hingegen zielt darauf ab, in KI-Antworten großer Sprachmodelle wie ChatGPT oder Gemini genannt oder zitiert zu werden, indem semantische Tiefe, Entitäten-Optimierung und E-E-A-T-Faktoren eingesetzt werden – der Erfolg zeigt sich in Markennennungen und Zitierungen. GEO strebt die korrekte Darstellung der Marke in generierten Antworten von Engines wie Perplexity oder AI Overviews an, wobei inhaltliche Strukturierung und der Aufbau von Themenautorität im Vordergrund stehen und der Share of Voice in KI-Antworten als Erfolgsmessung dient. AIO verfolgt das umfassendste Ziel einer allgemeinen Sichtbarkeit für alle KI-Systeme und kombiniert dabei SEO, GEO und LLMO mit zusätzlicher Modell- und Prozessoptimierung, gemessen an der Sichtbarkeit über verschiedene KI-Kanäle hinweg. AEO schließlich fokussiert sich auf das Erscheinen in direkten Antwort-Snippets von Antwortmaschinen durch FAQ-Formatierung und Schema Markup, wobei die Präsenz in Antwort-Boxen den Erfolg definiert.
Der Maschinenraum: Einblicke in die Technologie hinter der KI-Suche
Um Inhalte effektiv für KI-Systeme zu optimieren, ist ein grundlegendes Verständnis der zugrundeliegenden Technologien unerlässlich. Diese Systeme sind keine magischen Blackboxes, sondern basieren auf spezifischen technischen Prinzipien, die ihre Funktionsweise und damit auch die Anforderungen an den zu verarbeitenden Content bestimmen.
Große Sprachmodelle (LLMs): Die Kernmechanik
Im Zentrum der generativen KI stehen große Sprachmodelle (Large Language Models, LLMs).
- Vortraining mit riesigen Datenmengen: LLMs werden auf Basis gewaltiger Textdatensätze trainiert, die aus Quellen wie Wikipedia, dem gesamten öffentlich zugänglichen Internet (z. B. über den Common Crawl Datensatz) und digitalen Buchsammlungen stammen. Durch die Analyse von Billionen von Wörtern lernen diese Modelle statistische Muster, grammatikalische Strukturen, Faktenwissen und semantische Zusammenhänge der menschlichen Sprache.
- Das Problem des Wissens-Cutoffs: Eine entscheidende Einschränkung von LLMs ist, dass ihr Wissen auf dem Stand der Trainingsdaten eingefroren ist. Sie haben ein sogenanntes „Knowledge Cutoff Date“ und können von sich aus nicht auf Informationen zugreifen, die nach diesem Datum entstanden sind. Ein LLM, das bis 2023 trainiert wurde, weiß nicht, was gestern passiert ist. Dies ist das fundamentale Problem, das für Suchanwendungen gelöst werden muss.
- Tokenisierung und probabilistische Generierung: LLMs verarbeiten Text nicht Wort für Wort, sondern zerlegen ihn in kleinere Einheiten, sogenannte „Tokens“. Ihre Kernfunktion besteht darin, auf Basis des bisherigen Kontexts das wahrscheinlichste nächste Token vorherzusagen und so sequenziell einen kohärenten Text zu generieren. Sie sind hochentwickelte statistische Mustererkenner und verfügen nicht über ein menschliches Bewusstsein oder Verständnis.
Retrieval-Augmented Generation (RAG): Die Brücke zum Live-Web
Retrieval-Augmented Generation (RAG) ist die Schlüsseltechnologie, die es LLMs ermöglicht, als aktuelle Suchmaschinen zu fungieren. Sie überbrückt die Lücke zwischen dem statischen, vortrainierten Wissen des Modells und den dynamischen Informationen des Internets.
Der RAG-Prozess lässt sich in vier Schritte unterteilen:
- Anfrage (Query): Ein Nutzer stellt eine Frage an das System.
- Abruf (Retrieval): Anstatt sofort zu antworten, aktiviert das System eine „Retriever“-Komponente. Diese Komponente, oft eine semantische Suchmaschine, durchsucht eine externe Wissensbasis – typischerweise den Index einer großen Suchmaschine wie Google oder Bing – nach Dokumenten, die für die Anfrage relevant sind. An dieser Stelle wird die Bedeutung hoher traditioneller SEO-Rankings offensichtlich: Inhalte, die in der klassischen Suche gut platziert sind, haben eine höhere Wahrscheinlichkeit, vom RAG-System gefunden und als potenzielle Quelle ausgewählt zu werden.
- Anreicherung (Augmentation): Die relevantesten Informationen aus den abgerufenen Dokumenten werden extrahiert und der ursprünglichen Nutzeranfrage als zusätzlicher Kontext hinzugefügt. Dadurch entsteht ein „angereicherter Prompt“.
- Generierung (Generation): Dieser angereicherte Prompt wird an das LLM weitergeleitet. Das Modell generiert nun seine Antwort, die nicht mehr nur auf seinem veralteten Trainingswissen, sondern auf den aktuellen, abgerufenen Fakten basiert.
Dieser Prozess reduziert das Risiko von „Halluzinationen“ (das Erfinden von Fakten), ermöglicht die Angabe von Quellen und stellt sicher, dass die Antworten aktueller und sachlich genauer sind.
Semantische Suche & Vektor-Embeddings: Die Sprache der KI
Um zu verstehen, wie der „Retrieval“-Schritt in RAG funktioniert, muss man das Konzept der semantischen Suche verstehen.
- Von Keywords zu Bedeutung: Die traditionelle Suche basiert auf dem Abgleich von Schlüsselwörtern. Die semantische Suche hingegen zielt darauf ab, die Absicht (Intent) und den Kontext einer Anfrage zu verstehen. So kann eine Suche nach „warme Winterhandschuhe“ auch Ergebnisse für „Wollfäustlinge“ liefern, weil das System die semantische Beziehung zwischen den Konzepten erkennt.
- Vektor-Embeddings als Kernmechanismus: Die technische Grundlage dafür sind Vektor-Embeddings. Ein spezielles „Embedding-Modell“ wandelt Texteinheiten (Wörter, Sätze, ganze Dokumente) in eine numerische Darstellung um – einen Vektor in einem hochdimensionalen Raum.
- Räumliche Nähe als semantische Ähnlichkeit: In diesem Vektorraum werden semantisch ähnliche Konzepte als nahe beieinander liegende Punkte abgebildet. Der Vektor, der „König“ repräsentiert, hat eine ähnliche Beziehung zum Vektor für „Königin“ wie der Vektor für „Mann“ zum Vektor für „Frau“.
- Anwendung im RAG-Prozess: Die Anfrage eines Nutzers wird ebenfalls in einen Vektor umgewandelt. Das RAG-System durchsucht dann seine Vektordatenbank, um die Dokumenten-Vektoren zu finden, die dem Anfrage-Vektor am nächsten liegen. Auf diese Weise werden die semantisch relevantesten Informationen für die Anreicherung des Prompts abgerufen.
Denkmodelle & Gedankenkette: Die nächste Evolutionsstufe
An der vordersten Front der LLM-Entwicklung stehen sogenannte Denkmodelle, die eine noch fortschrittlichere Form der Informationsverarbeitung versprechen.
- Über einfache Antworten hinaus: Während Standard-LLMs eine Antwort in einem einzigen Durchgang generieren, zerlegen Denkmodelle komplexe Probleme in eine Reihe von logischen Zwischenschritten, eine sogenannte „Gedankenkette“ (Chain-of-Thought).
- Funktionsweise: Diese Modelle werden durch bestärkendes Lernen (Reinforcement Learning) trainiert, wobei erfolgreiche, mehrstufige Lösungswege belohnt werden. Sie „denken“ intern quasi laut nach, formulieren und verwerfen verschiedene Lösungsansätze, bevor sie zu einer endgültigen, oft robusteren und genaueren Antwort gelangen.
- Implikationen für die Optimierung: Obwohl diese Technologie noch in den Anfängen steckt, deutet sie darauf hin, dass zukünftige Suchmaschinen in der Lage sein werden, weitaus komplexere und vielschichtigere Anfragen zu bearbeiten. Inhalte, die klare, logische Schritt-für-Schritt-Anleitungen, detaillierte Prozessbeschreibungen oder gut strukturierte Argumentationsketten bieten, sind ideal positioniert, um von diesen fortschrittlichen Modellen als hochwertige Informationsquelle genutzt zu werden.
Der technologische Aufbau moderner KI-Suchen – eine Kombination aus LLM, RAG und semantischer Suche – schafft eine starke, sich selbst verstärkende Rückkopplungsschleife zwischen dem „alten Web“ der gerankten Seiten und dem „neuen Web“ der KI-generierten Antworten. Hochwertige, autoritative Inhalte, die in der traditionellen SEO gut abschneiden, werden prominent indexiert und gerankt. Dieses hohe Ranking macht sie zu einem erstklassigen Kandidaten für den Abruf durch RAG-Systeme. Wenn eine KI diese Inhalte zitiert, stärkt dies wiederum deren Autorität, was zu mehr Nutzerengagement, mehr Backlinks und letztendlich zu noch stärkeren traditionellen SEO-Signalen führen kann. Dies erzeugt einen „Tugendkreis der Autorität“. Umgekehrt wird minderwertiger Inhalt sowohl von der traditionellen Suche als auch von RAG-Systemen ignoriert und dadurch zunehmend unsichtbar. Die Kluft zwischen den digitalen „Haves“ und „Have-Nots“ wird sich dadurch exponentiell vergrößern. Die strategische Konsequenz ist, dass Investitionen in grundlegendes SEO und den Aufbau von inhaltlicher Autorität nicht mehr nur auf das Ranking abzielen; sie sichern einen dauerhaften Platz am Tisch der KI-gesteuerten Zukunft der Informationssynthese.
🎯🎯🎯 Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | BD, R&D, XR, PR & Digitale Sichtbarkeitsoptimierung

Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | R&D, XR, PR & Digitale Sichtbarkeitsoptimierung - Bild: Xpert.Digital
Xpert.Digital verfügt über tiefgehendes Wissen in verschiedenen Branchen. Dies erlaubt es uns, maßgeschneiderte Strategien zu entwickeln, die exakt auf die Anforderungen und Herausforderungen Ihres spezifischen Marktsegments zugeschnitten sind. Indem wir kontinuierlich Markttrends analysieren und Branchenentwicklungen verfolgen, können wir vorausschauend agieren und innovative Lösungen anbieten. Durch die Kombination aus Erfahrung und Wissen generieren wir einen Mehrwert und verschaffen unseren Kunden einen entscheidenden Wettbewerbsvorteil.
Mehr dazu hier:
Digitale Autorität aufbauen: Warum traditionelle SEO für KI-gesteuerte Suchmaschinen nicht mehr ausreicht
Die drei Säulen der Generative Engine Optimization
Das technische Verständnis aus Teil I bildet die Grundlage für ein konkretes, umsetzbares strategisches Rahmenwerk. Um in der neuen Ära der KI-Suche erfolgreich zu sein, müssen Optimierungsbemühungen auf drei zentralen Säulen ruhen: strategische Inhalte für maschinelles Verständnis, fortschrittliche technische Optimierung für KI-Crawler und ein proaktives Management der digitalen Autorität.
Passend dazu:


Säule 1: Strategische Inhalte für maschinelles Verständnis
Die Art und Weise, wie Inhalte erstellt und strukturiert werden, muss sich grundlegend ändern. Das Ziel ist nicht mehr nur, einen menschlichen Leser zu überzeugen, sondern auch, einer Maschine die bestmögliche Grundlage für die Extraktion und Synthese von Informationen zu bieten.
Themenautorität als neue Grenze
Der Fokus der Content-Strategie verschiebt sich von der Optimierung einzelner Keywords hin zum Aufbau umfassender Themenautorität (Topical Authority).
- Aufbau von Wissenszentren: Anstatt isolierte Artikel für einzelne Keywords zu erstellen, besteht das Ziel darin, ganzheitliche „Themencluster“ zu schaffen. Diese bestehen aus einem zentralen, umfassenden „Pillar Content“ (Säuleninhalt), der ein breites Thema abdeckt, und zahlreichen verlinkten Unterartikeln, die spezifische Nischenaspekte und Detailfragen behandeln. Eine solche Struktur signalisiert den KI-Systemen, dass eine Website eine maßgebliche und erschöpfende Quelle für ein bestimmtes Fachgebiet ist.
- Ganzheitliche Abdeckung: LLMs verarbeiten Informationen in semantischen Zusammenhängen. Eine Website, die ein Thema umfassend abdeckt – einschließlich aller relevanten Facetten, Nutzerfragen und verwandten Konzepte – erhöht die Wahrscheinlichkeit, von einer KI als primäre Quelle genutzt zu werden. Das System findet alle benötigten Informationen an einem Ort und muss sie nicht aus mehreren, weniger umfassenden Quellen zusammensetzen.
- Praktische Anwendung: Keyword-Recherchen dienen nicht mehr dazu, einzelne Suchbegriffe zu finden, sondern das gesamte Universum an Fragen, Teilaspekten und verwandten Themen zu kartieren, das zu einem Kernkompetenzbereich gehört.
E-E-A-T als algorithmisches Signal
Das E-E-A-T-Konzept von Google (Experience, Expertise, Authoritativeness, Trustworthiness – Erfahrung, Fachwissen, Autorität, Vertrauenswürdigkeit) entwickelt sich von einer reinen Richtlinie für menschliche Qualitätsprüfer zu einem Satz maschinenlesbarer Signale, die zur Bewertung von Inhaltsquellen herangezogen werden.
Vertrauen gezielt aufbauen: Unternehmen müssen diese Signale aktiv auf ihren Websites implementieren und sichtbar machen:
- Erfahrung & Fachwissen (Experience & Expertise): Autoren müssen klar ausgewiesen werden, idealerweise mit detaillierten Biografien, die ihre Qualifikationen und ihre praktische Erfahrung belegen. Inhalte sollten einzigartige Einblicke aus der Praxis enthalten, die über reines Faktenwissen hinausgehen.
- Autorität (Authoritativeness): Der Aufbau von kontextuell relevanten Backlinks von anderen angesehenen Websites bleibt wichtig. Zunehmend an Bedeutung gewinnen jedoch auch nicht verlinkte Markennennungen (Mentions) in autoritativen Quellen.
- Vertrauenswürdigkeit (Trustworthiness): Klare und leicht auffindbare Kontaktinformationen, das Zitieren glaubwürdiger Quellen, die Veröffentlichung eigener, originärer Daten oder Studien und die regelmäßige Aktualisierung und Korrektur von Inhalten sind entscheidende Vertrauenssignale.
Entitätenbasierte Content-Strategie: Optimierung für Dinge, nicht für Zeichenketten
Moderne Suchmaschinen bauen ihr Verständnis der Welt auf einem „Knowledge Graph“ auf. Dieser Graph besteht nicht aus Wörtern, sondern aus realen Entitäten (Personen, Orte, Marken, Konzepte) und den Beziehungen zwischen ihnen.
- Die eigene Marke zur Entität machen: Das strategische Ziel ist es, die eigene Marke als eine klar definierte und anerkannte Entität innerhalb dieses Graphen zu etablieren, die eindeutig mit einem bestimmten Fachgebiet assoziiert wird. Dies wird durch eine konsistente Namensgebung, die Nutzung strukturierter Daten (siehe Abschnitt 4) und die häufige gemeinsame Nennung (Co-Occurrence) mit anderen relevanten Entitäten erreicht.
- Praktische Anwendung: Inhalte sollten um klar definierte Entitäten herum strukturiert werden. Wichtige Fachbegriffe können in Glossaren oder Definitionsboxen erklärt werden. Die Verlinkung auf anerkannte Entitäten-Quellen wie Wikipedia oder Wikidata kann Google dabei helfen, die richtigen Verbindungen herzustellen und die thematische Einordnung zu festigen.
Die Kunst des Snippets: Inhalte für die direkte Extraktion strukturieren
Die Formatierung von Inhalten muss so erfolgen, dass Maschinen sie leicht zerlegen und wiederverwenden können.
- Optimierung auf Passage-Ebene: KI-Systeme extrahieren oft nicht ganze Artikel, sondern einzelne, perfekt formulierte „Chunks“ oder Abschnitte – einen Absatz, einen Listenpunkt, eine Tabellenzeile –, um einen spezifischen Teil einer Anfrage zu beantworten. Eine Webseite sollte daher als eine Sammlung solcher hochgradig extrahierbarer Informations-Snippets konzipiert sein.
- Strukturelle Best Practices:
- Antwort-voran-Schreibweise (Answer-First Writing): Absätze sollten mit einer prägnanten, direkten Antwort auf eine implizite Frage beginnen, gefolgt von erläuternden Details.
- Einsatz von Listen und Tabellen: Komplexe Informationen sollten in Aufzählungen, nummerierten Listen und Tabellen aufbereitet werden, da diese Formate für KI-Systeme besonders einfach zu parsen sind.
- Strategischer Einsatz von Überschriften: Klare, beschreibende H2- und H3-Überschriften, oft als Fragen formuliert, sollten Inhalte logisch gliedern. Jeder Abschnitt sollte sich auf eine einzige, fokussierte Idee konzentrieren.
- FAQ-Bereiche: Abschnitte mit häufig gestellten Fragen (Frequently Asked Questions) sind ideal, da sie das konversationelle Frage-Antwort-Format von KI-Chats direkt widerspiegeln.
Multimodalität und natürliche Sprache
- Konversationeller Ton: Inhalte sollten in einem natürlichen, menschlichen Stil verfasst sein. KI-Modelle werden mit authentischer, menschlicher Sprache trainiert und bevorzugen Texte, die sich wie ein echtes Gespräch lesen.
- Optimierung visueller Inhalte: Moderne KI kann auch visuelle Informationen verarbeiten. Bilder benötigen daher aussagekräftige Alt-Texte und Bildunterschriften. Videos sollten mit Transkripten versehen werden. Dies macht multimediale Inhalte für die KI indexierbar und zitierfähig.
Die Konvergenz dieser Content-Strategien – Themenautorität, E-E-A-T, Entitätenoptimierung und Snippet-Strukturierung – führt zu einer tiefgreifenden Erkenntnis: Die effektivsten Inhalte für KI sind gleichzeitig die hilfreichsten, klarsten und vertrauenswürdigsten Inhalte für Menschen. Die Ära des „Schreibens für den Algorithmus“, die oft zu unnatürlich wirkenden Texten führte, geht zu Ende. Der neue Algorithmus erfordert menschzentrierte Best Practices. Die strategische Implikation ist, dass Investitionen in echtes Fachwissen, hochwertiges Schreiben, klares Informationsdesign und transparente Quellenangaben nicht länger nur „gute Praxis“ sind – sie sind die direkteste und nachhaltigste Form der technischen Optimierung für das generative Zeitalter.
Säule 2: Fortschrittliche technische Optimierung für KI-Crawler
Während strategische Inhalte das „Was“ der Optimierung definieren, stellt die technische Optimierung das „Wie“ sicher – sie gewährleistet, dass KI-Systeme auf diese Inhalte zugreifen, sie interpretieren und korrekt verarbeiten können. Ohne ein solides technisches Fundament bleiben selbst die besten Inhalte unsichtbar.
Technische SEO neu betrachtet: Die anhaltende Bedeutung der Core Vitals
Die Grundlagen der technischen Suchmaschinenoptimierung sind für GEO nicht nur relevant, sondern werden noch kritischer.
- Crawlbarkeit und Indexierbarkeit: Dies ist die absolute Basis. Wenn ein KI-Crawler – sei es der bekannte Googlebot oder spezialisierte Bots wie ClaudeBot und GPTBot – eine Seite nicht aufrufen oder rendern kann, existiert sie für das KI-System nicht. Es muss sichergestellt werden, dass relevante Seiten den HTTP-Statuscode 200 zurückgeben und nicht (unbeabsichtigt) durch die robots.txt-Datei blockiert werden.
- Seitengeschwindigkeit und Render-Timeouts: KI-Crawler arbeiten oft mit sehr kurzen Zeitfenstern für das Rendern einer Seite, teilweise nur 1-5 Sekunden. Langsam ladende Seiten, insbesondere solche mit hohem JavaScript-Anteil, laufen Gefahr, übersprungen oder nur unvollständig verarbeitet zu werden. Die Optimierung der Core Web Vitals und der allgemeinen Ladegeschwindigkeit (PageSpeed) ist daher von entscheidender Bedeutung.
- JavaScript-Rendering: Während der Google-Crawler mittlerweile sehr gut darin ist, JavaScript-intensive Seiten zu rendern, gilt dies nicht für viele andere KI-Crawler. Um eine universelle Zugänglichkeit zu gewährleisten, sollten kritische Inhalte bereits im initialen HTML-Code der Seite enthalten sein und nicht erst clientseitig nachgeladen werden.
Der strategische Imperativ von Schema.org: Ein vernetztes Wissensdiagramm erstellen
Schema.org ist ein standardisiertes Vokabular für strukturierte Daten. Es ermöglicht Website-Betreibern, Suchmaschinen explizit mitzuteilen, worum es in ihren Inhalten geht und wie verschiedene Informationselemente zusammenhängen. Eine mit Schema ausgezeichnete Website wird quasi zu einer maschinenlesbaren Datenbank.
- Warum Schema für KI entscheidend ist: Strukturierte Daten beseitigen Mehrdeutigkeit. Sie ermöglichen es KI-Systemen, Fakten wie Preise, Daten, Orte, Bewertungen oder die Schritte in einer Anleitung mit hoher Sicherheit zu extrahieren. Dies macht den Inhalt zu einer weitaus zuverlässigeren Quelle für die Generierung von Antworten als unstrukturierten Fließtext.
- Schlüssel-Schema-Typen für GEO:
- Organization und Person: Zur eindeutigen Definition der eigenen Marke und der Autoren als Entitäten.
- FAQPage und HowTo: Zur Strukturierung von Inhalten für direkte Antworten und Schritt-für-Schritt-Anleitungen, die von KI-Systemen bevorzugt werden.
- Article: Um wichtige Metadaten wie Autor und Veröffentlichungsdatum zu übermitteln und damit E-E-A-T-Signale zu stärken.
- Product: Unverzichtbar für den E-Commerce, um Preis-, Verfügbarkeits- und Bewertungsdaten maschinenlesbar zu machen.
- Best Practice – Vernetzte Entitäten: Die Optimierung sollte über das Hinzufügen isolierter Schema-Blöcke hinausgehen. Durch die Verwendung des @id-Attributs können verschiedene Entitäten auf einer Seite und über die gesamte Website hinweg miteinander verknüpft werden (z. B. die Verknüpfung eines Article mit seinem Author und seinem Publisher). Auf diese Weise entsteht ein kohärenter, interner Wissensgraph, der die semantischen Beziehungen für Maschinen explizit macht.
Der aufkommende llms.txt-Standard: Eine direkte Kommunikationslinie zu KI-Modellen
llms.txt ist ein vorgeschlagener neuer Standard, der eine direkte und effiziente Kommunikation mit KI-Modellen ermöglichen soll.
- Zweck und Funktion: Es handelt sich um eine einfache, im Markdown-Format verfasste Textdatei, die im Stammverzeichnis einer Website platziert wird. Sie bietet eine kuratierte „Landkarte“ der wichtigsten Inhalte einer Website, bereinigt von störendem HTML, JavaScript und Werbebannern. Dies macht es für KI-Modelle extrem effizient, die relevantesten Informationen zu finden und zu verarbeiten.
- Abgrenzung zu robots.txt und sitemap.xml: Während robots.txt Crawlern mitteilt, welche Bereiche sie nicht besuchen sollen, und sitemap.xml eine unkommentierte Liste aller URLs bereitstellt, bietet llms.txt einen strukturierten und kontextualisierten Leitfaden zu den inhaltlich wertvollsten Ressourcen einer Website.
- Spezifikation und Format: Die Datei verwendet die einfache Markdown-Syntax. Sie beginnt typischerweise mit einer H1-Überschrift (Seitentitel), gefolgt von einer kurzen Zusammenfassung in einem Zitatblock. H2-Überschriften gruppieren dann Listen von Links zu wichtigen Ressourcen wie Dokumentationen oder Richtlinien. Es existieren auch Varianten wie llms-full.txt, die den gesamten Textinhalt einer Website in einer einzigen Datei zusammenfassen.
- Implementierung und Werkzeuge: Die Erstellung kann manuell erfolgen oder durch eine wachsende Zahl von Generator-Tools wie FireCrawl, Markdowner oder spezialisierten Plugins für Content-Management-Systeme wie WordPress und Shopify unterstützt werden.
- Die Debatte um die Akzeptanz: Es ist von entscheidender Bedeutung, die aktuelle Kontroverse um diesen Standard zu verstehen. Googles offizielle Dokumentation besagt, dass solche Dateien für die Sichtbarkeit in den AI Overviews nicht notwendig sind. Führende Google-Experten wie John Mueller äußerten sich skeptisch und verglichen die Nützlichkeit mit dem veralteten Keywords-Meta-Tag. Gleichzeitig nutzen jedoch andere wichtige KI-Unternehmen wie Anthropic den Standard bereits aktiv für ihre eigenen Websites, und die Akzeptanz in der Entwickler-Community wächst.
Die Debatte um llms.txt und fortgeschrittene Schema-Implementierungen offenbart eine kritische strategische Spannung: die zwischen der Optimierung für eine einzige, dominante Plattform (Google) und der Optimierung für das breitere, heterogene KI-Ökosystem. Sich ausschließlich auf die Leitlinien von Google zu verlassen („Sie brauchen es nicht“), ist eine risikoreiche Strategie, die die Kontrolle und potenzielle Sichtbarkeit auf anderen schnell wachsenden Plattformen wie ChatGPT, Perplexity und Claude aufgibt. Eine vorausschauende, „polygamische“ Optimierungsstrategie, die sowohl die Kernprinzipien von Google befolgt als auch ökosystemweite Standards wie llms.txt und umfassendes Schema implementiert, ist der widerstandsfähigste Ansatz. Sie behandelt Google als den wichtigsten, aber nicht den einzigen maschinellen Konsumenten der eigenen Inhalte. Dies ist eine Form der strategischen Diversifizierung und Risikominderung für die digitalen Vermögenswerte eines Unternehmens.
Säule 3: Digitales Autoritätsmanagement
Die Entstehung einer neuen Disziplin
Die dritte und vielleicht strategischste Säule der Generative Engine Optimization geht über die reine Inhalts- und Technikoptimierung hinaus. Sie befasst sich mit dem Aufbau und der Verwaltung der digitalen Autorität einer Marke als Ganzes. In einer Welt, in der KI-Systeme versuchen, die Vertrauenswürdigkeit von Quellen zu bewerten, wird die algorithmisch messbare Autorität zu einem entscheidenden Rankingfaktor.
Das Konzept des „Digitalen Autoritätsmanagements“ wurde maßgeblich vom Branchenexperten Olaf Kopp geprägt und beschreibt eine neue, notwendige Disziplin im digitalen Marketing.
Die Brücke zwischen den Silos
Im Zeitalter von E-E-A-T und KI werden die Signale, die algorithmisches Vertrauen aufbauen – wie Markenreputation, Erwähnungen in den Medien und die Glaubwürdigkeit von Autoren – durch Aktivitäten erzeugt, die traditionell in getrennten Abteilungen wie PR, Markenmarketing und Social Media angesiedelt sind. SEO allein hat auf diese Bereiche oft nur begrenzten Einfluss. Digitales Autoritätsmanagement schließt diese Lücke, indem es diese Bemühungen mit der SEO unter einem einheitlichen strategischen Dach vereint.
Das übergeordnete Ziel ist der bewusste und proaktive Aufbau einer digital wiedererkennbaren und autoritativen Marken-Entität, die von Algorithmen leicht identifiziert und als vertrauenswürdig eingestuft werden kann.
Jenseits von Backlinks: Die Währung von Erwähnungen und Co-Occurrence
- Erwähnungen als Signal: Nicht verlinkte Markennennungen in autoritativen Kontexten gewinnen massiv an Bedeutung. KI-Systeme aggregieren diese Erwähnungen aus dem gesamten Web, um die Bekanntheit und den Ruf einer Marke zu bewerten.
- Co-Occurrence und Kontext: KI-Systeme analysieren, welche Entitäten (Marken, Personen, Themen) häufig gemeinsam genannt werden. Das strategische Ziel muss es sein, eine starke und konsistente Assoziation zwischen der eigenen Marke und den Kernkompetenzthemen im gesamten digitalen Raum zu schaffen.
Aufbau einer digital wiedererkennbaren Marken-Entität
- Konsistenz ist der Schlüssel: Eine absolute Konsistenz bei der Schreibweise des Markennamens, der Autorennamen und der Unternehmensbeschreibungen über alle digitalen Berührungspunkte hinweg ist unerlässlich – von der eigenen Website über soziale Profile bis hin zu Branchenverzeichnissen. Inkonsistenzen erzeugen Mehrdeutigkeit für die Algorithmen und schwächen die Entität.
- Plattformübergreifende Autorität: Generative Engines bewerten die Präsenz einer Marke ganzheitlich. Eine einheitliche Stimme und konsistente Botschaften über alle Kanäle (Website, LinkedIn, Gastbeiträge, Foren) stärken die wahrgenommene Autorität. Die Wiederverwendung und Anpassung von erfolgreichen Inhalten für verschiedene Formate und Plattformen ist hierbei eine zentrale Taktik.
Die Rolle von Digital PR und Reputationsmanagement
- Strategische Öffentlichkeitsarbeit: Die Bemühungen der Digital PR müssen sich darauf konzentrieren, Erwähnungen in Publikationen zu erzielen, die nicht nur für die Zielgruppe relevant sind, sondern auch von KI-Modellen als autoritative Quellen eingestuft werden.
- Management der Reputation: Es ist entscheidend, aktiv positive Bewertungen auf angesehenen Plattformen zu fördern und zu überwachen. Ebenso wichtig ist die aktive Teilnahme an relevanten Diskussionen auf Community-Plattformen wie Reddit und Quora, da diese von KI-Systemen häufig als Quellen für authentische Meinungen und Erfahrungen herangezogen werden.
Die neue Rolle der SEO
- Digitales Autoritätsmanagement verändert die Rolle der SEO innerhalb einer Organisation grundlegend. Es erhebt SEO von einer taktischen Funktion, die sich auf die Optimierung eines einzelnen Kanals (der Website) konzentriert, zu einer strategischen Funktion, die für die Orchestrierung des gesamten digitalen Fußabdrucks eines Unternehmens für die algorithmische Interpretation verantwortlich ist.
- Dies impliziert eine signifikante Veränderung der Organisationsstruktur und der erforderlichen Fähigkeiten. Der „Digital Authority Manager“ ist eine neue hybride Rolle, die die analytische Strenge der SEO mit den narrativen und beziehungsaufbauenden Fähigkeiten eines Markenstrategen und PR-Profis verbindet. Unternehmen, die es versäumen, diese integrierte Funktion zu schaffen, werden feststellen, dass ihre fragmentierten digitalen Signale im Wettbewerb mit Konkurrenten, die den KI-Systemen eine einheitliche, autoritative Identität präsentieren, nicht bestehen können.
B2B-Beschaffung: Lieferketten, Handel, Marktplätze & KI-gestütztes Sourcing

B2B-Beschaffung: Lieferketten, Handel, Marktplätze & KI-gestütztes Sourcing mit ACCIO.com - Bild: Xpert.Digital
Mehr dazu hier:
Von SEO zu GEO: Neue Metriken für die Erfolgsmessung in der KI-Ära
Die Wettbewerbslandschaft & Erfolgsmessung
Nachdem die strategischen Säulen der Optimierung definiert sind, richtet sich der Blick auf die praktische Anwendung im aktuellen Wettbewerbsumfeld. Dies erfordert eine datengestützte Analyse der wichtigsten KI-Suchplattformen sowie die Einführung neuer Methoden und Werkzeuge zur Leistungsmessung.
Passend dazu:

Dekonstruktion der Quellenauswahl: Eine vergleichende Analyse
Die verschiedenen KI-Suchplattformen arbeiten nicht identisch. Sie nutzen unterschiedliche Datenquellen und Algorithmen, um ihre Antworten zu generieren. Ein Verständnis dieser Unterschiede ist entscheidend für die Priorisierung von Optimierungsmaßnahmen. Die folgende Analyse basiert auf einer Synthese führender Branchenstudien, insbesondere der umfassenden Untersuchung von SE Ranking, ergänzt durch qualitative Analysen und plattformeigene Dokumentationen.
Google AI Overviews: Der Vorteil des etablierten Systems
- Quellenprofil: Google verfolgt einen eher konservativen Ansatz. Die AI Overviews stützen sich stark auf den bestehenden Knowledge Graph, etablierte E-E-A-T-Signale und die organischen Top-Ranking-Ergebnisse. Studien zeigen eine signifikante, wenn auch nicht vollständige, Korrelation mit den Top-10-Positionen der klassischen Suche.
- Datenpunkte: Google zitiert im Durchschnitt 9,26 Links pro Antwort und weist dabei eine hohe Diversität mit 2.909 einzigartigen Domains in der analysierten Studie auf. Es besteht eine klare Präferenz für ältere, etablierte Domains (49 % der zitierten Domains sind über 15 Jahre alt), während sehr junge Domains seltener berücksichtigt werden.
- Strategische Implikation: Der Erfolg in den Google AI Overviews ist untrennbar mit einer starken, traditionellen SEO-Autorität verbunden. Es handelt sich um ein Ökosystem, in dem Erfolg zu weiterem Erfolg führt.
ChatGPT Search: Der Herausforderer mit Fokus auf Nutzergenerierte Inhalte und Bing
- Quellenprofil: ChatGPT nutzt für seine Websuche den Index von Microsoft Bing, wendet jedoch eine eigene Logik für die Filterung und Anordnung der Ergebnisse an. Die Plattform zeigt eine deutliche Vorliebe für nutzergenerierte Inhalte (User-Generated Content, UGC), insbesondere von YouTube, das eine der am häufigsten zitierten Quellen ist, sowie für Community-Plattformen wie Reddit.
- Datenpunkte: ChatGPT zitiert mit durchschnittlich 10,42 die meisten Links und verweist auf die größte Anzahl einzigartiger Domains (4.034). Gleichzeitig weist die Plattform die höchste Rate an Mehrfachnennungen derselben Domain innerhalb einer Antwort auf (71 %), was auf eine Strategie der Vertiefung durch eine einzelne, als vertrauenswürdig erachtete Quelle hindeutet.
- Strategische Implikation: Sichtbarkeit in ChatGPT erfordert eine Multi-Plattform-Strategie, die neben der Optimierung für den Bing-Index auch den aktiven Aufbau einer Präsenz auf wichtigen nutzergenerierten Inhalten-Plattformen umfasst.
Perplexity.ai: Der transparente Echtzeit-Rechercheur
- Quellenprofil: Perplexity ist darauf ausgelegt, für jede Anfrage eine Echtzeit-Websuche durchzuführen, was die Aktualität der Informationen sicherstellt. Die Plattform ist äußerst transparent und versieht ihre Antworten mit klaren Inline-Zitaten. Ein Alleinstellungsmerkmal ist die „Focus“-Funktion, die es Nutzern ermöglicht, die Suche auf eine vordefinierte Auswahl von Quellen (z. B. nur wissenschaftliche Paper, Reddit oder bestimmte Websites) zu beschränken.
- Datenpunkte: Die Quellenauswahl ist sehr konsistent; fast alle Antworten enthalten genau 5 Links. Die Antworten von Perplexity weisen die höchste semantische Ähnlichkeit mit denen von ChatGPT auf (0,82), was auf ähnliche Präferenzen bei der Inhaltsauswahl hindeutet.
- Strategische Implikation: Der Schlüssel zum Erfolg auf Perplexity liegt darin, zu einer „Zielquelle“ zu werden – einer Website, die so autoritativ ist, dass Nutzer sie bewusst in ihre fokussierten Suchen einbeziehen. Die Echtzeit-Natur der Plattform belohnt zudem besonders aktuelle und faktisch präzise Inhalte.
Die unterschiedlichen Sourcing-Strategien der großen KI-Plattformen schaffen eine neue Form der „algorithmischen Arbitrage“. Eine Marke, die Schwierigkeiten hat, im hart umkämpften, autoritätsgetriebenen Ökosystem der Google AI Overviews Fuß zu fassen, könnte einen leichteren Weg zur Sichtbarkeit über ChatGPT finden, indem sie sich auf Bing-SEO und eine starke Präsenz auf YouTube und Reddit konzentriert. In ähnlicher Weise kann ein Nischenexperte den Mainstream-Wettbewerb umgehen, indem er zu einer unverzichtbaren Quelle für fokussierte Suchen auf Perplexity wird. Die strategische Erkenntnis ist, nicht jeden Kampf an jeder Front zu führen, sondern die unterschiedlichen „Markteintrittsbarrieren“ jeder KI-Plattform zu analysieren und die eigenen Content- und Autoritätsaufbaumaßnahmen auf die Plattform auszurichten, die am besten zu den Stärken der eigenen Marke passt.
Vergleichende Analyse von KI-Suchplattformen

Vergleichende Analyse von KI-Suchplattformen – Bild: Xpert.Digital
Die vergleichende Analyse von KI-Suchplattformen zeigt deutliche Unterschiede zwischen Google AI Overviews, ChatGPT Search und Perplexity.ai. Google AI Overviews nutzt als primäre Datenquelle den Google Index und Knowledge Graph, liefert durchschnittlich 9,26 Zitate und weist eine geringe Quellenüberschneidung mit Bing sowie eine moderate mit ChatGPT auf. Die Plattform zeigt eine moderate Präferenz für nutzergenerierten Content wie Reddit und Quora, bevorzugt jedoch stark etablierte Domains mit hohem Alter. Das Alleinstellungsmerkmal liegt in der Integration in die dominante Suchmaschine und der starken E-E-A-T-Gewichtung, wobei der strategische Fokus auf dem Aufbau von E-E-A-T und starker traditioneller SEO-Autorität liegt.
ChatGPT Search basiert auf dem Bing Index als primäre Datenquelle und generiert mit durchschnittlich 10,42 Zitaten die meisten Quellenangaben. Die Plattform zeigt eine hohe Quellenüberschneidung mit Perplexity und eine moderate mit Google. Besonders auffällig ist die hohe Präferenz für nutzergenerierten Content, insbesondere YouTube und Reddit. Bei der Bewertung des Domain-Alters zeigt sich ein gemischtes Verhalten mit Offenheit für jüngere Domains. Das Alleinstellungsmerkmal besteht in der hohen Quellenanzahl und starken UGC-Integration, während der strategische Fokus auf Bing-SEO und Präsenz auf UGC-Plattformen liegt.
Perplexity.ai unterscheidet sich durch die Nutzung einer Echtzeit-Websuche als primäre Datenquelle und liefert mit durchschnittlich 5,01 die wenigsten Zitate. Die Quellenüberschneidung ist hoch mit ChatGPT, aber gering mit Google und Bing. Die Plattform zeigt eine moderate Präferenz für nutzergenerierten Content, wobei Reddit und YouTube im Fokus-Modus bevorzugt werden. Das Domain-Alter spielt eine geringe Rolle, da der Fokus auf Echtzeit-Relevanz liegt. Als Alleinstellungsmerkmal bietet Perplexity.ai Transparenz durch Inline-Zitate und anpassbare Quellenauswahl durch die Focus-Funktion. Der strategische Fokus liegt auf dem Aufbau von Nischenautorität und Content-Aktualität.
Die neue Analytik: Messung und Überwachung der LLM-Sichtbarkeit
Die Verschiebung des Paradigmas von der Suche zur Antwort erfordert eine ebenso grundlegende Anpassung der Erfolgsmessung. Traditionelle SEO-Kennzahlen verlieren an Aussagekraft, wenn der Klick auf die Website nicht mehr das primäre Ziel ist. Neue Metriken und Werkzeuge sind erforderlich, um den Einfluss und die Präsenz einer Marke in der generativen KI-Landschaft zu quantifizieren.
Der Paradigmenwechsel in der Messung: Von Klicks zu Einfluss
- Alte Metriken: Der Erfolg von traditionellem SEO wird primär durch direkt messbare Kennzahlen wie Keyword-Rankings, organischer Traffic und Klickraten (CTR) bewertet.
- Neue Metriken: Der Erfolg von GEO/LLMO wird durch Metriken des Einflusses und der Präsenz gemessen, die oft indirekter Natur sind:
- LLM-Sichtbarkeit / Markennennungen (Brand Mentions): Misst, wie oft eine Marke in relevanten KI-Antworten erwähnt wird. Dies ist die grundlegendste neue Kennzahl.
- Share of Voice / Share of Model: Quantifiziert den prozentualen Anteil der eigenen Markennennungen im Vergleich zu Wettbewerbern für eine definierte Gruppe von Suchanfragen (Prompts).
- Zitierungen (Citations): Erfasst, wie oft die eigene Website als Quelle verlinkt wird.
- Sentiment und Qualität der Nennungen: Analysiert den Ton (positiv, neutral, negativ) und die sachliche Korrektheit der Erwähnungen.
Das aufkommende Toolkit: Plattformen zur Verfolgung von KI-Nennungen
- Funktionsweise: Diese Tools fragen automatisiert und in großem Umfang verschiedene KI-Modelle mit vordefinierten Prompts ab. Sie protokollieren, welche Marken und Quellen in den Antworten erscheinen, analysieren das Sentiment und verfolgen die Entwicklung im Zeitverlauf.
- Führende Werkzeuge: Der Markt ist jung und fragmentiert, aber es haben sich bereits einige spezialisierte Plattformen etabliert. Dazu gehören Tools wie Profound, Peec.ai, RankScale und Otterly.ai, die sich in Funktionsumfang und Zielgruppe (von KMU bis zu Großunternehmen) unterscheiden.
- Adaption traditioneller Tools: Etablierte Anbieter von Brand-Monitoring-Software (z. B. Sprout Social, Mention) und umfassenden SEO-Suiten (z. B. Semrush, Ahrefs) beginnen ebenfalls, Funktionen zur Analyse der KI-Sichtbarkeit in ihre Produkte zu integrieren.
Die Attributionslücke schließen: Integration von LLM-Analysen ins Reporting
Eine der größten Herausforderungen ist die Zuordnung (Attribution) von Geschäftsergebnissen zu einer Nennung in einer KI-Antwort, da diese oft nicht zu einem direkten Klick führt. Eine mehrstufige Analysemethode ist erforderlich:
- Verfolgung des Referral-Traffics: Der erste und einfachste Schritt ist die Analyse des direkten Verweisverkehrs (Referral Traffic) von KI-Plattformen in Webanalyse-Tools wie Google Analytics 4. Durch die Erstellung benutzerdefinierter Kanalgruppen auf Basis der Verweisquellen (z. B. perplexity.ai, bing.com für ChatGPT-Suchen) kann dieser Traffic isoliert und bewertet werden.
- Überwachung indirekter Signale: Der fortgeschrittenere Ansatz besteht in der Korrelationsanalyse. Analysten müssen Trends bei indirekten Indikatoren wie einem Anstieg des direkten Website-Traffics (Direct Traffic) und einer Zunahme von markenbezogenen Suchanfragen (Branded Search) in der Google Search Console beobachten. Diese Trends müssen dann mit der Entwicklung der LLM-Sichtbarkeit, wie sie von den neuen Monitoring-Tools gemessen wird, in Beziehung gesetzt werden.
- Analyse der Bot-Protokolle: Für technisch versierte Teams bietet die Analyse der Server-Logfiles wertvolle Einblicke. Durch die Identifizierung und Überwachung der Aktivitäten von KI-Crawlern (z. B. GPTBot, ClaudeBot) kann festgestellt werden, welche Seiten von den KI-Systemen zur Informationsgewinnung herangezogen werden.
Die Entwicklung der Leistungskennzahlen

Die Entwicklung der Leistungskennzahlen – Bild: Xpert.Digital
Die Entwicklung der Leistungskennzahlen zeigt einen deutlichen Wandel von traditionellen SEO-Metriken hin zu KI-orientierten Kennzahlen. Bei der Sichtbarkeit verschiebt sich der Fokus vom klassischen Keyword-Ranking hin zum Share of Voice und Share of Model, welche durch spezialisierte LLM-Monitoring-Tools wie Peec.ai oder Profound gemessen werden. Im Bereich Traffic ergänzt der Referral-Traffic von KI-Plattformen den organischen Traffic und die Click-Through-Rate, wobei Web-Analyse-Tools wie GA4 mit benutzerdefinierten Kanalgruppen zum Einsatz kommen. Die Autorität einer Website wird nicht mehr nur durch Domain Authority und Backlinks bestimmt, sondern auch durch Zitierungen und die Qualität der Nennungen in KI-Systemen, messbar durch LLM-Monitoring-Tools und Backlink-Analyse zitierter Quellen. Die Markenwahrnehmung erweitert sich von markenbezogenen Suchanfragen um das Sentiment der KI-Nennungen, erfasst durch LLM-Monitoring- und Social-Listening-Tools. Auf technischer Ebene tritt neben die traditionelle Indexierungsrate die Abrufrate durch KI-Bots, die mittels Server-Logfile-Analyse ermittelt wird.
Führende GEO/LLMO Monitoring- & Analyse-Tools

Führende GEO/LLMO Monitoring- & Analyse-Tools – Bild: Xpert.Digital
Die Landschaft der führenden GEO/LLMO Monitoring- und Analyse-Tools bietet verschiedene spezialisierte Lösungen für unterschiedliche Zielgruppen. Profound stellt eine umfassende Enterprise-Lösung dar, die Monitoring, Share of Voice, Sentiment-Analyse und Quellen-Analyse für ChatGPT, Copilot, Perplexity und Google AIO anbietet. Peec.ai richtet sich ebenfalls an Marketing-Teams und Enterprise-Kunden und bietet ein Markenpräsenz-Dashboard, Wettbewerbs-Benchmarking sowie Content-Gap-Analyse für ChatGPT, Perplexity und Google AIO.
Für kleinere und mittlere Unternehmen sowie SEO-Profis bietet RankScale Echtzeit-Ranking-Analysen in KI-Antworten, Sentiment-Analyse und Citation-Analyse auf ChatGPT, Perplexity und Bing Chat. Otterly.ai konzentriert sich auf Nennungen und Backlinks mit Alerts bei Veränderungen und bedient KMU sowie Agenturen über ChatGPT, Claude und Gemini. Goodie AI positioniert sich als All-in-One-Plattform für Monitoring, Optimierung und Content-Erstellung auf denselben Plattformen und richtet sich an den Mittelstand und Agenturen.
Hall bietet eine spezialisierte Lösung für Enterprise und Produkt-Teams mit Conversation Intelligence, Traffic-Messung aus KI-Empfehlungen und Agent-Tracking für diverse Chatbots. Für Einsteiger stehen kostenlose Tools zur Verfügung: Der HubSpot AI Grader bietet einen kostenlosen Check für Share of Voice und Sentiment auf GPT-4 und Perplexity, während der Mangools AI Grader einen kostenlosen Check der KI-Sichtbarkeit und Wettbewerbsvergleich auf ChatGPT, Google AIO und Perplexity für Einsteiger und SEOs bereitstellt.
Der komplette GEO-Handlungsrahmen: In 5 Phasen zur optimalen KI-Sichtbarkeit
Autorität aufbauen für die KI-Zukunft: Warum E-E-A-T der Schlüssel zum Erfolg ist
Nach der detaillierten Analyse der technologischen Grundlagen, strategischen Säulen und der Wettbewerbslandschaft fasst dieser letzte Teil die Erkenntnisse in einem praktischen Handlungsrahmen zusammen und wirft einen Blick auf die zukünftige Entwicklung der Suche.
Ein umsetzbarer Handlungsrahmen
Die Komplexität der Generative Engine Optimization erfordert einen strukturierten und iterativen Ansatz. Die folgende Checkliste fasst die Empfehlungen aus den vorangegangenen Abschnitten zu einem praktischen Workflow zusammen, der als Leitfaden für die Implementierung dienen kann.
Phase 1: Audit & Baseline-Erfassung
- Technisches SEO-Audit durchführen: Überprüfung der grundlegenden technischen Voraussetzungen wie Crawlbarkeit, Indexierbarkeit, Seitengeschwindigkeit (Core Web Vitals) und mobile Optimierung. Identifizierung von Problemen, die KI-Crawler blockieren könnten (z. B. langsame Ladezeiten, JavaScript-Abhängigkeiten).
- Schema.org-Markup überprüfen: Audit des vorhandenen strukturierten Daten-Markups auf Vollständigkeit, Korrektheit und die Nutzung vernetzter Entitäten (@id).
- Content-Audit durchführen: Bewertung der bestehenden Inhalte hinsichtlich E-E-A-T-Signalen (sind Autoren ausgewiesen, werden Quellen zitiert?), semantischer Tiefe und Themenautorität. Identifizierung von Lücken in den Themenclustern.
- Baseline der LLM-Sichtbarkeit ermitteln: Nutzung von spezialisierten Monitoring-Tools oder manuellen Abfragen bei den relevanten KI-Plattformen (Google AIO, ChatGPT, Perplexity), um den Status quo der eigenen Markensichtbarkeit und die der wichtigsten Wettbewerber zu erfassen.
Phase 2: Content-Strategie & Optimierung
- Themencluster-Karte entwickeln: Basierend auf der Keyword- und Themenrecherche eine strategische Karte der zu behandelnden Themen und Unterthemen erstellen, die die eigene Expertise widerspiegelt.
- Inhalte erstellen und optimieren: Neue Inhalte erstellen und bestehende überarbeiten, mit einem klaren Fokus auf die Optimierung für die Extraktion (Snippet-Struktur, Listen, Tabellen, FAQs) und die Abdeckung von Entitäten.
- E-E-A-T-Signale stärken: Implementierung oder Verbesserung von Autorenseiten, Hinzufügen von Referenzen und Zitaten, Einbau von einzigartigen Erfahrungsberichten und originären Daten.
Phase 3: Technische Implementierung
- Schema.org-Markup ausrollen/aktualisieren: Implementierung von relevantem und vernetztem Schema-Markup auf allen wichtigen Seiten, insbesondere für Produkte, FAQs, Anleitungen und Artikel.
- llms.txt-Datei erstellen und bereitstellen: Erstellung einer llms.txt-Datei, die auf die wichtigsten und für KI-Systeme relevantesten Inhalte verweist, und Platzierung im Stammverzeichnis der Website.
- Performance-Probleme beheben: Beseitigung der im technischen Audit identifizierten Probleme bezüglich Ladezeit und Rendering.
Phase 4: Autoritätsaufbau & Promotion
- Digitale PR und Outreach durchführen: Gezielte Kampagnen zur Generierung von hochwertigen Backlinks und, noch wichtiger, nicht verlinkten Markennennungen in autoritativen, themenrelevanten Publikationen.
- Auf Community-Plattformen engagieren: Aktive und hilfreiche Teilnahme an Diskussionen auf Plattformen wie Reddit und Quora, um die Marke als hilfreiche und kompetente Quelle zu positionieren.
Phase 5: Messen & Iterieren
- Analytics einrichten: Konfiguration von Webanalyse-Tools zur Verfolgung von Referral-Traffic aus KI-Quellen und zur Überwachung indirekter Signale wie Direct Traffic und Branded Search.
- LLM-Sichtbarkeit kontinuierlich überwachen: Regelmäßige Nutzung der Monitoring-Tools, um die Entwicklung der eigenen Sichtbarkeit und der der Wettbewerber zu verfolgen.
- Strategie anpassen: Die gewonnenen Daten nutzen, um die Content- und Autoritätsstrategie kontinuierlich zu verfeinern und auf Veränderungen in der KI-Landschaft zu reagieren.
Die Zukunft der Suche: Von der Informationsbeschaffung zur Wissensinteraktion
Die Integration von generativer KI ist kein vorübergehender Trend, sondern der Beginn einer neuen Ära der Mensch-Computer-Interaktion. Die Entwicklung wird über die heutigen Systeme hinausgehen und die Art, wie wir auf Informationen zugreifen, weiter fundamental verändern.
Die Entwicklung der KI in der Suche
- Hyper-Personalisierung: Zukünftige KI-Systeme werden Antworten nicht nur auf die explizite Anfrage, sondern auch auf den impliziten Kontext des Nutzers zuschneiden – seine Suchhistorie, seinen Standort, seine Vorlieben und sogar seine bisherigen Interaktionen mit dem System.
- Agentenhafte Workflows: Die KI wird sich von einem reinen Antwortgeber zu einem proaktiven Assistenten entwickeln, der in der Lage ist, mehrstufige Aufgaben im Auftrag des Nutzers auszuführen – von der Recherche und Zusammenfassung bis hin zur Buchung oder zum Kauf.
- Das Ende der „Suche“ als Metapher: Das Konzept des aktiven „Suchens“ wird zunehmend durch eine kontinuierliche, dialogorientierte Interaktion mit einem allgegenwärtigen, intelligenten Assistenten ersetzt. Die Suche wird zu einem Gespräch.
Vorbereitung auf die Zukunft: Aufbau einer widerstandsfähigen, zukunftssicheren Strategie
Die abschließende Botschaft ist, dass die in diesem Bericht dargelegten Prinzipien – der Aufbau echter Autorität, die Erstellung hochwertiger, strukturierter Inhalte und die Verwaltung einer einheitlichen digitalen Präsenz – keine kurzfristigen Taktiken für die aktuelle Generation von KI sind. Sie sind die fundamentalen Prinzipien für den Aufbau einer Marke, die in jeder zukünftigen Landschaft, in der Informationen durch intelligente Systeme vermittelt werden, erfolgreich sein kann.
Der Fokus muss darauf liegen, zur Quelle der Wahrheit zu werden, von der sowohl Menschen als auch ihre KI-Assistenten lernen wollen. Unternehmen, die in Wissen, Empathie und Klarheit investieren, werden nicht nur in den Suchergebnissen von heute sichtbar sein, sondern auch die Narrative ihrer Branche in der KI-gesteuerten Welt von morgen maßgeblich mitgestalten.
Wir sind für Sie da - Beratung - Planung - Umsetzung - Projektmanagement
☑️ KMU Support in der Strategie, Beratung, Planung und Umsetzung
☑️ Erstellung oder Neuausrichtung der Digitalstrategie und Digitalisierung
☑️ Ausbau und Optimierung der internationalen Vertriebsprozesse
☑️ Globale & Digitale B2B-Handelsplattformen
☑️ Pioneer Business Development

Konrad Wolfenstein
Gerne stehe ich Ihnen als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie unten das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 7348 4088 965 an.
Ich freue mich auf unser gemeinsames Projekt.
Schreiben Sie mir




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital ist ein Hub für die Industrie mit den Schwerpunkten, Digitalisierung, Maschinenbau, Logistik/Intralogistik und Photovoltaik.
Mit unserer 360° Business Development Lösung unterstützen wir namhafte Unternehmen vom New Business bis After Sales.
Market Intelligence, Smarketing, Marketing Automation, Content Development, PR, Mail Campaigns, Personalized Social Media und Lead Nurturing sind ein Teil unserer digitalen Werkzeuge.
Mehr finden Sie unter: www.xpert.digital - www.xpert.solar - www.xpert.plus
In Kontakt bleiben











