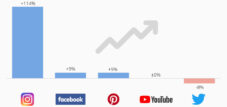
Розбіжність між показниками трафіку в різних інструментах аналізу та їх приховані причини – Зображення: Xpert.Digital
Чи справжні ваші відвідувачі – чи всі вони справжні? Дивовижна правда про помилкове виявлення ботів
### Ви довіряєте Google Analytics? Ця дорога помилка спотворює всю вашу стратегію ### Чому ваші аналітичні інструменти не знають справжньої кількості відвідувачів ### Від ботів до GDPR: невидимі вороги, які саботують вашу веб-аналітику ### Хаос аналітики: приховані причини, чому ваші показники трафіку ніколи не збігаються ###
Більше, ніж просто цифри: що насправді приховує від вас ваша веб-аналітика
Кожен, хто керує веб-сайтом, знає це неприємне відчуття: погляд на Google Analytics показує одне число, журнал сервера – інше, а маркетинговий інструмент – третє. Те, що виглядає як технічна помилка або проста неточність, насправді є верхівкою складного айсберга. Розбіжність між показниками трафіку – це не помилка, а систематична проблема, глибоко вкорінена в архітектурі сучасного Інтернету. Просте запитання «Скільки у мене відвідувачів?» більше не має простої відповіді.
Причини настільки ж різноманітні, наскільки й невидимі. Вони варіюються від агресивних систем виявлення ботів, які помилково фільтрують реальних людей, до суворих законів про захист даних, таких як GDPR, які створюють величезні прогалини в даних через банери cookie, та сучасних браузерів, які активно блокують відстеження з міркувань конфіденційності. До цього додаються технічні пастки, такі як несправне міждоменне відстеження, статистичні складнощі вибірки даних та невидима роль систем кешування, які роблять деяких ваших відвідувачів невидимими для ваших серверів.
Ці неточності — це більше, ніж просто косметичні недоліки у звіті. Вони призводять до неправильних висновків, помилкових маркетингових інвестицій та фундаментально спотвореного уявлення про поведінку користувачів. Якщо ви не розумієте, чому ваші цифри відрізняються, ви приймаєте рішення наосліп. Ця стаття глибоко заглиблюється в приховані причини цих розбіжностей, розкриває складнощі, що стоять за лаштунками, та показує, як приймати обґрунтовані та стратегічно обґрунтовані рішення у світі неповних даних.
Пов'язано з цим:

Чому не весь трафік однаковий
Вимірювання трафіку веб-сайту на перший погляд здається простим. Однак реальність малює складнішу картину, оскільки різні інструменти аналітики можуть надавати різні показники для одного й того ж веб-сайту. Ці розбіжності виникають не через випадковість чи технічні помилки, а через фундаментальні відмінності в тому, як трафік фіксується, обробляється та інтерпретується.
Проблема починається з визначення того, що вважається дійсним трафіком. Хоча один інструмент може враховувати кожен перегляд сторінки як відвідування, інший може фільтрувати автоматизований доступ або враховувати лише відвідувачів із увімкненим JavaScript. Ці різні підходи призводять до цифр, які на перший погляд здаються суперечливими, але всі вони мають своє місце.
Проблема стає ще складнішою, якщо врахувати, що сучасні вебсайти – це вже не просто HTML-сторінки, а складні додатки з різними доменами, піддоменами та інтегрованими сервісами. Користувач може розпочати свою подорож на головному вебсайті, перейти до зовнішнього постачальника платіжних послуг, а потім повернутися на сторінку підтвердження. Кожен із цих кроків можна відстежувати по-різному, залежно від використовуваного інструменту та його налаштування.
Приховані пастки виявлення ботів
Коли люди стають ботами
Автоматичне виявлення бот-трафіку є одним із найскладніших завдань веб-аналітики. Сучасні системи виявлення ботів використовують складні алгоритми, засновані на різних сигналах: рухи миші, поведінка прокручування, час, проведений на сторінках, відбитки браузера та багато інших параметрів. Ці системи призначені для ідентифікації та фільтрації автоматизованого доступу, щоб отримати більш реалістичну картину користувачів-людей.
Проблема, однак, полягає в недосконалості цих систем виявлення. Хибнопозитивні результати, неправильна ідентифікація реальних користувачів як ботів, є поширеною проблемою. Користувача, який дуже швидко переглядає веб-сайт, можливо, з вимкненими файлами cookie або JavaScript, легко можна класифікувати як бота. Особливо страждають користувачі з певними звичками перегляду: люди, які використовують технології доступності, досвідчені користувачі, які віддають перевагу комбінаціям клавіш, або користувачі з регіонів з повільним інтернет-з’єднанням, що призводить до незвичайних моделей завантаження.
Вплив значний. Дослідження показують, що під час використання популярних інструментів виявлення ботів, таких як Botometer, рівень помилок класифікації може коливатися від 15 до 85 відсотків, залежно від використаного порогу та аналізованого набору даних. Це означає, що значна частина відвідувань, відфільтрованих як «бот-трафік», насправді була від реальних людей, чию поведінку система неправильно інтерпретувала.
Розвиток бот-ландшафту
Ландшафт ботів кардинально змінився. Хоча ранніх ботів можна було легко ідентифікувати за допомогою простих параметрів, таких як рядки користувацького агента або IP-адреси, сучасні боти набагато складніші. Вони використовують реальні браузерні движки, імітують моделі поведінки людини та використовують IP-адреси житлових приміщень. Водночас з'явилися агенти на базі штучного інтелекту, які можуть виконувати складні завдання та майже ідеально імітувати поведінку людини.
Цей розвиток подій створює нові виклики для систем виявлення. Традиційні методи, такі як аналіз відбитків браузера або моделей поведінки, стають менш надійними, оскільки боти стають складнішими. Це призводить до того, що системи виявлення або налаштовуються занадто консервативно, пропускаючи багато ботів, або налаштовуються занадто агресивно, неправильно блокуючи легітимних користувачів.
Невидимий світ інтрамереж та закритих мереж
Вимірювання за брандмауерами
Значна частина інтернет-трафіку відбувається в закритих мережах, невидимих для звичайних інструментів аналітики. Корпоративні інтрамережі, приватні мережі та закриті групи генерують значні обсяги трафіку, які не враховуються у стандартній статистиці. Ці мережі часто використовують власні аналітичні рішення або взагалі відмовляються від комплексного відстеження, щоб забезпечити безпеку та конфіденційність даних.
Проблеми вимірювання інтрамережевої мережі різноманітні. Брандмауери можуть блокувати активні спроби дослідження, трансляція мережевих адрес (NAT) приховує фактичну кількість і структуру хостів, а адміністративні політики часто обмежують видимість мережевих компонентів. Багато організацій впроваджують додаткові заходи безпеки, такі як проксі-сервери або інструменти формування трафіку, що ще більше ускладнює аналіз трафіку.
Методи внутрішнього аналізу
Компанії, які хочуть вимірювати свій внутрішній трафік, повинні використовувати спеціалізовані методи. Перехоплення пакетів та аналіз мережевого потоку є поширеними методами, але вони фіксують трафік на іншому рівні, ніж інструменти веб-аналітики. У той час як інструменти на основі JavaScript відстежують окремі сеанси користувачів та перегляди сторінок, інструменти моніторингу мережі аналізують весь трафік даних на рівні пакетів.
Ці різні підходи призводять до принципово різних показників. Наприклад, інструмент моніторингу мережі може показати, що між двома серверами передається великий обсяг даних, але він не може розрізнити, чи надходять ці дані від одного користувача, який переглядає велике відео, чи від сотні користувачів, які одночасно завантажують невеликі файли.
Наша рекомендація: 🌍 Безмежний охоплення 🔗 Зв'язок 🌐 Багатомовність 💪 Сила продажів: 💡 Автентичність зі стратегією 🚀 Інновації зустрічаються 🧠 Інтуїція


Від локального до глобального: малі та середні підприємства завойовують світовий ринок за допомогою розумної стратегії - Зображення: Xpert.Digital
В епоху, коли цифрова присутність компанії визначає її успіх, завдання полягає у створенні автентичної, персоналізованої та широкомасштабної присутності. Xpert.Digital пропонує інноваційне рішення, яке позиціонує себе як поєднання галузевого центру, блогу та амбасадора бренду. Воно поєднує переваги комунікаційних та збутових каналів на єдиній платформі та дозволяє публікувати матеріали 18 різними мовами. Співпраця з партнерськими порталами та можливість публікації статей у Google News та списку розсилки преси, який налічує приблизно 8000 журналістів та читачів, максимізує охоплення та видимість контенту. Це є вирішальним фактором у зовнішніх продажах та маркетингу (SMarketing).
Більше інформації тут:
Збереження якості даних: стратегії проти GDPR та інструменти конфіденційності
Правила захисту даних як засіб знищення трафіку
Вплив GDPR на збір даних
Впровадження Загального регламенту про захист даних (GDPR) та аналогічних законів докорінно змінило ландшафт веб-аналітики. Веб-сайти тепер повинні отримувати чітку згоду на відстеження користувачів, що призвело до різкого зменшення доступних даних. Дослідження показують, що лише частина відвідувачів погоджується на використання файлів cookie для відстеження, що призводить до значних прогалин в аналітичних даних.
Проблема виходить за рамки простого збору даних. GDPR вимагає, щоб згода була конкретною та усвідомленою, що важко гарантувати за допомогою ітеративного аналізу даних. Компанії більше не можуть просто запитувати дозвіл на «всі майбутні цілі аналізу», а повинні детально описувати, як дані будуть використовуватися. Ця вимога робить практично неможливим проведення комплексного аналізу без перевищення правових меж.
Інструменти блокування файлів cookie та конфіденційності
Сучасні браузери впровадили розширені заходи захисту конфіденційності, які виходять далеко за рамки законодавчих вимог. Safari та Firefox блокують сторонні файли cookie за замовчуванням, Chrome оголосив, що наслідуватиме цей приклад, а браузери, орієнтовані на конфіденційність, такі як Brave, йдуть ще далі у своїх заходах захисту.
Вплив на якість даних є значним. Вебсайти відчувають скорочення обсягу зібраних даних на 30-70 відсотків, залежно від цільової аудиторії та використаних методів відстеження. Особливо проблематичним аспектом є те, що це скорочення не розподіляється рівномірно між усіма групами користувачів. Технічно підковані користувачі частіше використовують інструменти конфіденційності, що призводить до систематичного спотворення даних.
Пов'язано з цим:


Пастки вибірки даних
Коли ціле стає частиною
Вибірка даних – це статистичний метод, який використовується багатьма аналітичними інструментами для обробки великих наборів даних. Замість аналізу всіх доступних даних оцінюється лише репрезентативна частина, а результати екстрапольуються. Наприклад, Google Analytics автоматично починає вибірку зі складних звітів або великих наборів даних, щоб скоротити час обчислення.
Проблема полягає в припущенні, що вибірка є репрезентативною. Однак у веб-аналітиці важко забезпечити рівномірне представлення всіх типів відвідувачів і всіх типів трафіку у вибірці. Наприклад, алгоритм вибірки може фіксувати непропорційно велику кількість відвідувань з певної рекламної кампанії, що призводить до спотворених результатів.
Межі похибки вибірки можуть бути значними. Хоча точність відносно висока для великих вибірок, відхилення до 30 відсотків можуть виникати для менших сегментів або певних періодів часу. Для компаній, які покладаються на точні дані для прийняття бізнес-рішень, ці неточності можуть призвести до дороговартісних помилок.
Межі вибірки
Проблеми з вибіркою стають особливо очевидними, коли одночасно застосовується кілька фільтрів або сегментів. Звіт, сегментований за регіоном, типом пристрою та кампанією, зрештою може базуватися лише на дуже невеликій частині вихідних даних. Ці різко скорочені набори даних схильні до статистичних коливань і можуть свідчити про оманливі тенденції.
Хоча сучасні аналітичні інструменти пропонують способи зменшення або уникнення вибірки, вони часто коштують дорожче або потребують більше часу на обробку. Багато компаній не знають, що їхні звіти базуються на вибіркових даних, оскільки відповідні показники часто ігноруються або не відображаються достатньо помітно.
Міждоменне відстеження та фрагментація користувацького досвіду
Проблема міждоменного відстеження
Сучасні вебсайти рідко складаються з одного домену. Сайти електронної комерції використовують окремі домени для каталогів товарів та обробки платежів, компанії мають різні піддомени для різних сфер бізнесу, а багато послуг передаються на аутсорсинг мережам доставки контенту або хмарним платформам. Будь-яке перемикання між цими доменами може призвести до перерви у відстеженні користувачів.
Проблема полягає в політиках безпеки браузера. За замовчуванням файли cookie та інші механізми відстеження обмежені доменом, на якому вони були встановлені. Якщо користувач переходить з shop.example.com на payment.example.com, інструменти аналітики розглядають це як два окремі відвідування, навіть якщо це один і той самий сеанс користувача.
Впровадження міждоменного відстеження є технічно складним та схильним до помилок. До поширених проблем належать неправильно налаштовані списки виключення реферерів, неповні конфігурації доменів або проблеми з передачею ідентифікаторів клієнтів між доменами. Ці технічні перешкоди призводять до того, що багато веб-сайтів збирають неповні або спотворені дані про шляхи користувачів.
Вплив на якість даних
Якщо міждоменне відстеження працює неправильно, в аналітичних даних виникають систематичні упередження. Прямий трафік зазвичай представлений надмірно, оскільки користувачі, які переходять з одного домену на інший, враховуються як нові прямі відвідувачі. Водночас інші джерела трафіку представлені недостатньо, оскільки втрачається інформація про вихідний реферер.
Ці упередження можуть призвести до неправильних висновків щодо ефективності маркетингових кампаній. Рекламна кампанія, яка спочатку спрямовує користувачів на цільову сторінку, а потім до системи оформлення замовлення на іншому домені, може мати гірші аналітичні показники, ніж насправді, оскільки конверсія пов'язана з прямим трафіком.
Журнали сервера проти аналітики на стороні клієнта
Два світи збору даних
Метод збору даних принципово впливає на те, який трафік реєструється. Аналіз журналів сервера та системи відстеження на основі JavaScript вимірюють принципово різні аспекти використання веб-сайту. Журнали сервера реєструють кожен HTTP-запит, який надходить на сервер, незалежно від того, чи походить він від людини, чи від бота. З іншого боку, інструменти на основі JavaScript вимірюють лише ті взаємодії, під час яких виконується код браузера.
Ці відмінності призводять до різних сліпих зон у відповідних системах. Журнали сервера також фіксують доступ від користувачів, у яких вимкнено JavaScript, які використовують блокувальники реклами або дуже швидко переміщуються по сторінці. З іншого боку, інструменти на основі JavaScript можуть збирати детальнішу інформацію про взаємодію користувачів, таку як глибина прокручування, кліки на певних елементах або час, витрачений на перегляд певного контенту.
Проблема ботів у різних системах
Обробка трафіку ботів суттєво відрізняється між інструментами аналізу журналів на стороні сервера та клієнта. Журнали сервера, природно, містять набагато більше трафіку ботів, оскільки кожен автоматизований запит фіксується. Фільтрація ботів із журналів сервера – це складне та трудомістке завдання, що вимагає спеціалізованих знань.
Інструменти аналітики на стороні клієнта мають перевагу в тому, що багато простих ботів автоматично фільтруються, оскільки вони не виконують JavaScript. Однак це також виключає легітимних користувачів, чиї браузери не підтримують JavaScript або вимкнено. Сучасні, складні боти, які використовують повноцінні браузерні механізми, навпаки, розпізнаються обома системами як звичайні користувачі.
Роль мереж доставки контенту та кешування
Невидима інфраструктура
Мережі доставки контенту та системи кешування стали невід'ємною частиною сучасного інтернету, але вони ускладнюють вимірювання трафіку. Коли контент доставляється з кешу, відповідні запити можуть ніколи не досягти початкового сервера, на якому встановлено систему відстеження.
Кешування на периферії та сервіси CDN можуть призвести до того, що значна частина фактичних переглядів сторінок не відображатиметься в журналах сервера. Водночас коди відстеження на основі JavaScript, що працюють на кешованих сторінках, можуть фіксувати ці відвідування, що призводить до розбіжностей між різними методами вимірювання.
Проблеми географічного розподілу та вимірювання
CDN розподіляють контент географічно, щоб оптимізувати час завантаження. Однак такий розподіл може призвести до того, що моделі трафіку реєструватимуться по-різному залежно від регіону. Користувач у Європі може отримати доступ до сервера CDN у Німеччині, тоді як його візит може навіть не відображатися в журналах оригінального сервера в США.
Така географічна фрагментація ускладнює точне вимірювання фактичного охоплення та впливу веб-сайту. Аналітичні інструменти, які покладаються виключно на журнали сервера, можуть систематично недооцінювати трафік з певних регіонів, тоді як інструменти з глобальною інфраструктурою можуть надати повнішу картину.
Новий вимір цифрової трансформації з «керованим ШІ» (штучним інтелектом) – платформа та рішення B2B | Xpert Consulting

Новий вимір цифрової трансформації з «керованим ШІ» (штучним інтелектом) – платформа та рішення B2B | Xpert Consulting - Зображення: Xpert.Digital
Тут ви дізнаєтеся, як ваша компанія може швидко, безпечно та без високих бар'єрів входу впроваджувати індивідуальні рішення на основі штучного інтелекту.
Керована платформа штучного інтелекту — це ваше комплексне та безтурботне рішення для штучного інтелекту. Замість того, щоб мати справу зі складними технологіями, дорогою інфраструктурою та тривалими процесами розробки, ви отримуєте готове рішення, адаптоване до ваших потреб, від спеціалізованого партнера — часто всього за кілька днів.
Основні переваги з першого погляду:
⚡ Швидке впровадження: від ідеї до готового до використання застосунку за лічені дні, а не місяці. Ми пропонуємо практичні рішення, які створюють негайну додану цінність.
🔒 Максимальна безпека даних: Ваші конфіденційні дані залишаються з вами. Ми гарантуємо безпечну та відповідність вимогам обробку без передачі даних третім особам.
💸 Без фінансових ризиків: Ви платите лише за результат. Повністю виключаються значні початкові інвестиції в обладнання, програмне забезпечення чи персонал.
🎯 Зосередьтеся на своєму основному бізнесі: Зосередьтеся на тому, що ви робите найкраще. Ми подбаємо про повне технічне впровадження, експлуатацію та обслуговування вашого рішення на базі штучного інтелекту.
📈 Орієнтований на майбутнє та масштабований: Ваш ШІ зростає разом з вами. Ми забезпечуємо постійну оптимізацію та масштабованість, а також гнучко адаптуємо моделі до нових вимог.
Більше інформації тут:
Відстеження на стороні сервера: рішення чи нова складність?
Відстеження, що зосереджене на конфіденційності, та його обмеження: відстеження на стороні сервера – рішення чи нова складність?
Перехід до даних власних джерел
У відповідь на зміни в правилах конфіденційності та браузерах, багато компаній намагаються перейти на збір даних безпосередньо. Цей підхід передбачає збір даних лише безпосередньо з їхнього власного веб-сайту, без залежності від сторонніх сервісів. Хоча цей підхід більше відповідає вимогам конфіденційності, він також створює нові виклики.
Відстеження власними силами зазвичай менш комплексне, ніж рішення сторонніх розробників. Воно не може відстежувати користувачів на різних веб-сайтах, що обмежує можливості атрибуції та аналізу аудиторії. Крім того, воно вимагає значних технічних знань та інвестицій в інфраструктуру, які не всі компанії можуть собі дозволити.
Відстеження на стороні сервера як альтернатива
Відстеження на стороні сервера все частіше просувається як рішення проблем конфіденційності та блокування. За такого підходу дані збираються та обробляються на стороні сервера, що робить їх менш вразливими до механізмів блокування на основі браузера. Однак цей підхід також створює власні складнощі.
Впровадження відстеження на стороні сервера вимагає значних технічних ресурсів та досвіду. Компанії повинні створювати власну інфраструктуру для збору та обробки даних, що передбачає витрати та обслуговування. Крім того, серверні системи не можуть фіксувати певні взаємодії на стороні клієнта, які є критично важливими для комплексного аналізу.
Пов'язано з цим:
Технічна інфраструктура та її вплив
Одиночні точки відмови
Багато вебсайтів покладаються на зовнішні сервіси для своєї аналітики. Якщо ці сервіси дають збій або блокуються, виникають прогалини в даних, які часто помічаються лише пізніше. Збій може мати різні причини: технічні проблеми у постачальника, проблеми з мережею або блокування брандмауерами чи інструментами конфіденційності.
Ці залежності створюють ризики для цілісності даних. Короткочасний збій у роботі Google Analytics під час критичної маркетингової кампанії може призвести до систематичного недооцінювання ефективності кампанії. Компанії, які покладаються виключно на один інструмент аналітики, особливо вразливі до таких втрат даних.
Помилки впровадження та їх наслідки
Помилки у впровадженні кодів відстеження є поширеними та можуть призвести до значної втрати даних. До поширених проблем належать відсутність кодів відстеження на певних сторінках, дублювання впровадження або неправильні конфігурації. Ці помилки можуть залишатися непоміченими протягом тривалого часу, оскільки наслідки часто не одразу помітні.
Забезпечення якості впровадження аналітики часто є недооцінюваним завданням. Багато компаній впроваджують коди відстеження без достатнього тестування та валідації. Зміни в структурі веб-сайту, нові сторінки або оновлення систем управління контентом можуть порушити роботу існуючих реалізацій відстеження, і це не буде одразу помічено.
Майбутнє вимірювання трафіку
Нові технології та підходи
Вимірювання трафіку постійно розвивається, щоб відповідати новим викликам. Машинне навчання та штучний інтелект все частіше використовуються для виявлення бот-трафіку та заповнення прогалин у даних. Ці технології можуть виявляти закономірності у великих наборах даних, які людям важко ідентифікувати.
Водночас з'являються нові технології вимірювання, що відповідають вимогам конфіденційності. Диференціальна конфіденційність, федеративне навчання та інші підходи намагаються надати корисну аналітику без ідентифікації окремих користувачів. Ці технології все ще перебувають у стадії розробки, але можуть сформувати майбутнє веб-аналітики.
Нормативні зміни
Нормативно-правовий ландшафт захисту даних постійно змінюється. Нові закони в різних країнах і регіонах створюють додаткові вимоги до збору та обробки даних. Компанії повинні постійно адаптувати свої аналітичні стратегії, щоб залишатися в рамках вимог.
Ці регуляторні зміни, ймовірно, призведуть до подальшої фрагментації доступних даних. Часи, коли були легкодоступні вичерпні та детальні дані про трафік, можливо, минули. Компаніям потрібно буде навчитися працювати з частковими та неповними даними та відповідно адаптувати свої процеси прийняття рішень.
Практичні наслідки для бізнесу
Стратегії подолання невизначеності даних
З огляду на різні джерела розбіжностей у даних, компаніям необхідно розробити нові підходи до інтерпретації своїх аналітичних даних. Часи вилучення однієї «істини» з аналітичного інструменту минули. Натомість необхідно співвідносити та інтерпретувати кілька джерел даних.
Надійний підхід передбачає використання кількох аналітичних інструментів та регулярну перевірку даних за іншими показниками, такими як журнали сервера, дані про продажі або відгуки клієнтів. Компанії також повинні розуміти обмеження своїх інструментів та те, як вони впливають на інтерпретацію даних.
Важливість якості даних
Якість аналітичних даних стає дедалі важливішою, навіть більшою, ніж їхня кількість. Компанії повинні інвестувати в інфраструктуру та процеси, які забезпечують правильний збір та інтерпретацію їхніх даних. Це включає регулярні перевірки впровадження відстеження, навчання команд, які працюють з даними, та розробку процесів забезпечення якості.
Інвестування в якість даних окупається в довгостроковій перспективі, оскільки кращі дані призводять до кращих рішень. Компанії, які розуміють обмеження своїх аналітичних даних і діють відповідно, мають конкурентну перевагу над тими, хто покладається на поверхневі або неточні показники.
Чому трафік веб-сайту ніколи не має єдиної правди
Здавалося б, просте питання кількості відвідувачів веб-сайту виявляється складною та багатогранною темою. Трафік – це не просто трафік, і цифри в різних інструментах аналітики можуть відрізнятися не без підстав. Проблеми варіюються від технічних аспектів, таких як виявлення ботів та міждоменне відстеження, до правових вимог, що встановлюються законами про захист даних.
Для компаній це означає, що їм потрібно переосмислити та диверсифікувати свої аналітичні стратегії. Покладання на один інструмент чи джерело даних є ризикованим і може призвести до неправильних бізнес-рішень. Натомість їм слід використовувати кілька джерел даних та розуміти обмеження кожного з них.
Майбутнє веб-аналітики, ймовірно, характеризуватиметься ще більшою складністю. Правила конфіденційності стають суворішими, браузери впроваджують більше заходів безпеки, а користувачі стають більш усвідомленими щодо своєї цифрової конфіденційності. Водночас з'являються нові технології та методи, які пропонують нові можливості для збору та аналізу даних.
Компанії, які розуміють ці зміни та готуються до них, матимуть кращі можливості для успіху у світі фрагментованих та обмежених аналітичних даних. Головне не очікувати ідеальних даних, а правильно інтерпретувати доступні дані та робити правильні висновки.
Розбіжність між різними показниками трафіку — це не помилка, а особливість сучасного інтернету. Вона відображає складність та різноманітність цифрового ландшафту. Компанії, які розуміють цю складність як можливість та розробляють відповідні стратегії, будуть успішнішими в довгостроковій перспективі, ніж ті, які шукають простих відповідей на складні питання.
Ми тут для вас - Консалтинг - Планування - Впровадження - Управління проектами
☑️ Підтримка МСП у стратегії, консалтингу, плануванні та впровадженні
☑️ Створення або переорієнтація цифрової стратегії та діджиталізації
☑️ Розширення та оптимізація процесів міжнародних продажів
☑️ Глобальні та цифрові торгові платформи B2B
☑️ Розвиток бізнесу Pioneer

Konrad Wolfenstein
Я буду радий служити вашим особистим консультантом.
Ви можете зв'язатися зі мною, заповнивши контактну форму нижче, або просто зателефонувавши мені за номером +49 7348 4088 965 .
Я з нетерпінням чекаю нашого спільного проєкту.
Напиши мені




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital – це галузевий центр, що спеціалізується на цифровізації, машинобудуванні, логістиці/інтралогістиці та фотоелектричній енергетиці.
Завдяки нашому комплексному рішенню для розвитку бізнесу на 360° ми підтримуємо відомі компанії, починаючи від нового бізнесу і закінчуючи післяпродажним обслуговуванням.
Ринкова аналітика, маркетинг, автоматизація маркетингу, розробка контенту, PR, поштові кампанії, персоналізовані соціальні мережі та підтримка лідів – це частина наших цифрових інструментів.
Більше інформації можна знайти за адресами: www.xpert.digital - www.xpert.solar - www.xpert.plus
Залишайтеся на зв'язку