
Спроба пояснити ШІ: Як працює штучний інтелект та робота - як він навчається?

Вибір голосу 📢
Опубліковано: 8 вересня 2024 р. / Оновлення з: 9 вересня 2024 р. - Автор: Конрад Вольфенштейн

Спроба пояснити ШІ: Як працює штучний інтелект і як він навчається? - Зображення: xpert.digital
📊 Від введення даних до прогнозу моделі: процес AI
Як працює штучний інтелект (AI)? 🤖
Функціональність штучного інтелекту (AI) можна розділити на кілька чітко визначених кроків. Кожен з цих етапів має вирішальне значення для кінцевого результату, який AI забезпечує. Процес починається при введенні даних і закінчується прогнозом моделі та будь -яким зворотним зв'язком чи іншими навчальними раундами. Ці фази описують процес, який проходять майже всі моделі AI, незалежно від того, чи це прості норми чи дуже складні нейронні мережі.
1. Введення даних 📊
Основою кожного штучного інтелекту є дані, з якими він працює. Ці дані можуть бути доступні в різних формах, наприклад, як зображення, тексти, аудіофайли чи відео. AI використовує ці необроблені дані для розпізнавання моделей та прийняття рішень. Якість та кількість даних відіграють тут центральну роль, оскільки вони суттєво впливають на те, наскільки добре чи погано працює модель пізніше.
Чим більш обширні і точніше дані, тим краще AI може навчитися. Наприклад, якщо AI навчається для обробки зображень, він потребує великої кількості даних про зображення, щоб правильно визначити різні об'єкти. За допомогою голосових моделей саме текстові дані допомагають AI зрозуміти та генерувати людську мову. Введення даних - це перший і один з найважливіших кроків, оскільки якість прогнозів може бути такою ж хорошою, як і основні дані. Відомий принцип інформатики описує це з приказкою "сміття, сміття" - погані дані призводять до поганих результатів.
2. Попередня обробка даних 🧹
Як тільки дані були введені, вони повинні бути підготовлені, перш ніж їх зможуть подати в фактичну модель. Цей процес називається попередньою обробкою даних. Йдеться про те, щоб поставити дані у форму, яка може бути оптимально оброблена моделлю.
Поширеним кроком у попередній обробці є нормалізація даних. Це означає, що дані вводяться в рівномірну область цінності, щоб вони ставилися рівномірно за моделлю. Одним із прикладів було б масштабувати всі значення пікселів зображення в область від 0 до 1 замість 0 до 255.
Ще однією важливою частиною попередньої обробки є так зване вилучення функцій. Деякі функції (особливості) розроблені з необроблених даних, особливо актуальних для моделі. У випадку обробки зображень це може бути, наприклад, краї або певні кольорові шаблони, тоді як витягуються тексти відповідних ключових слів або структур речення. Попередня обробка має вирішальне значення для того, щоб зробити процес навчання ШІ більш ефективним та точним.
3. Модель 🧩
Модель - це серце кожного штучного інтелекту. Тут дані аналізуються та обробляються на основі алгоритмів та математичних розрахунків. Модель може існувати в різних формах. Однією з найвідоміших моделей є нейронна мережа, яка базується на функціонуванні мозку людини.
Нейрональні мережі складаються з декількох шарів штучних нейронів, які обробляють та передають інформацію. Кожен шар приймає витрати попереднього шару і переробляє його далі. Процес навчання нейронної мережі полягає в тому, щоб адаптувати ваги з'єднань між цими нейронами таким чином, щоб мережа могла робити все більш точні прогнози або робити класифікації. Ця адаптація проводиться шляхом навчання, в якій мережа отримує доступ до великих кількостей вибіркових даних, а її внутрішні параметри (ваги) покращуються ітераційно.
Окрім нейронних мереж, також існує багато інших алгоритмів, що використовуються в моделях AI. Сюди входять дерева рішення, випадкові ліси, підтримуючі векторні машини та багато іншого. Який алгоритм використовується залежить від конкретного завдання та наявних даних.
4. Прогноз моделі 🔍
Після того, як модель пройшла навчання з даними, вона здатна робити прогнози. Цей крок називається прогнозом моделі. AI отримує вклад і повертає проблему на основі моделей, які ви дізналися до цього часу, тобто прогнозування чи рішення.
Цей прогноз може приймати різні форми. Наприклад, у моделі класифікації зображень AI може передбачити, який об'єкт можна побачити на малюнку. У мовній моделі вона могла б прогнозувати, яке слово виходить далі в одному реченні. У разі фінансових прогнозів ШІ може передбачити, як розвиватиметься фондовий ринок.
Важливо підкреслити, що точність прогнозів сильно залежить від якості даних про навчання та архітектури моделі. Модель, яка пройшла навчання за неадекватними або спотвореними даними, швидше за все, зробить неправильні прогнози.
5. Перенесення та навчання (необов’язково) ♻
Ще однією важливою частиною роботи ШІ є механізм зворотного зв'язку. Модель регулярно перевіряється та подальше оптимізується. Цей процес відбувається або під час навчання, або відповідно до модельного прогнозу.
Якщо модель робить неправильні прогнози, вона може навчитися розпізнавати ці помилки шляхом зворотного зв'язку та відповідно адаптувати його внутрішні параметри. Це робиться шляхом порівняння прогнозів моделі з фактичними результатами (наприклад, для відомих даних, для яких вже доступні правильні відповіді). Типовим процесом у цьому контексті є так зване моніторинг навчання, в якому AI дізнається із зразкових даних, які вже надаються правильними відповідями.
Поширеним методом зворотного зв'язку є алгоритм розповсюдження задньої частини, який використовується в нейронних мережах. Помилки, які робить модель, поширюються назад через мережу, щоб адаптувати ваги сполук нейронів. Таким чином, модель вчиться на своїх помилках і стає все більш точною у своїх прогнозах.
Роль навчання 🏋
Навчання ШІ - це ітеративний процес. Чим більше даних бачить модель, і тим частіше вона навчається на основі цих даних, тим точніше її прогнози. Однак є також обмеження: надмірно навчена модель може отримати так звані проблеми "надмірного". Це означає, що він вивчає дані навчання настільки добре, що дають гірші результати нових, невідомих даних. Тому важливо навчити модель таким чином, що вона узагальнює, тобто також робить хороші прогнози на нові дані.
Окрім регулярної підготовки, є також такі процедури, як передача навчання. Тут модель, яка вже пройшла навчання на великій кількості даних, використовується для нового, подібного завдання. Це економить час і обчислювальну потужність, оскільки модель не повинна повністю навчатись з нуля.
Використовуйте сильні сторони оптимально 🚀
Робота штучного інтелекту заснована на складній взаємодії різних кроків. Від введення даних до попередньої обробки та модельної підготовки до прогнозування та зворотного зв'язку, існує багато факторів, які впливають на точність та ефективність ШІ. Добре тренований AI може запропонувати величезні переваги у багатьох сферах життя - від автоматизації простих завдань до вирішення складних проблем. Але так само важливо зрозуміти межі та потенційні підводні камені ШІ, щоб мати можливість оптимально використовувати свої сильні сторони.
🤖📚 Просто пояснив: Як навчається AI?
🤖📊 Процес навчання AI: Захоплення, посилання та збереження
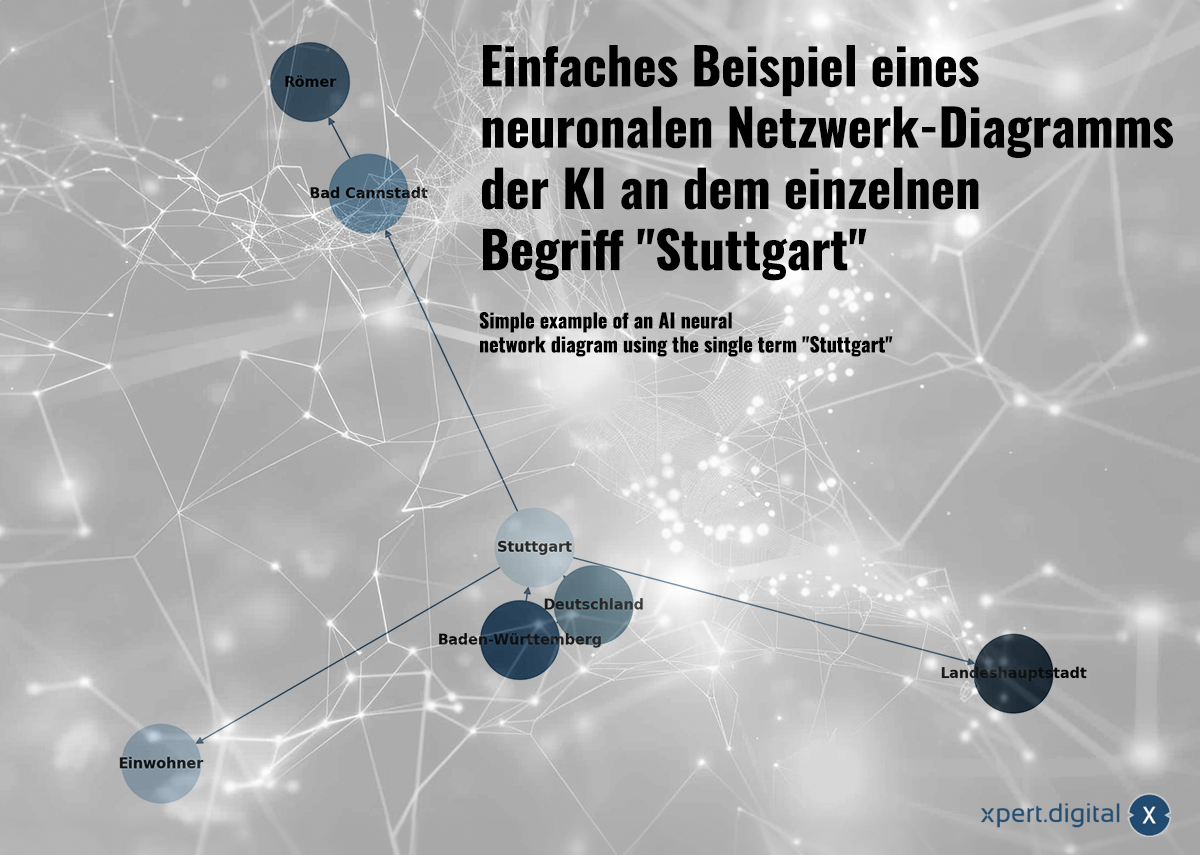
Простий приклад нейрональної мережевої діаграми AI на індивідуальному терміні "Штутгарт" -IMage: xpert.digital
🌟 Зберіть та підготуйте дані
Перший крок у процесі навчання AI - це збору та підготовки даних. Ці дані можуть надходити з різних джерел, наприклад з баз даних, датчиків, текстів чи зображень.
🌟 Відносити дані (нейронна мережа)
Зібрані дані пов'язані між собою в нейронній мережі. Кожен пакет даних відображається підключеннями в мережі "нейронів" (вузол). Простий приклад із містом Штутгарт міг би виглядати так:
a) Штутгарт-місто в Баден-Вюртемберзі
б) Баден-Вюртемберг-федеральна держава в Німеччині
c) Штутгарт-місто в Німеччині
d) Штутгарт, населення 633 484
e) Bad Cannstatt-це округ Штутгарта
Ф) Баден-Баден, заснований Romans
g) Stuttgart, який був заснований Romans gumans stuttgat
Залежно від розміру обсягу даних, параметри для потенційних видань створюються з цього за допомогою використовуваної моделі AI. Як приклад: GPT-3 має близько 175 мільярдів параметрів!
🌟 Зберігання та адаптація (навчання)
Дані надаються до нейронної мережі. Вони проходять через модель AI і обробляються за допомогою з'єднань (подібно до синапсів). Зважування (параметри) адаптуються між нейронами для підготовки моделі або виконання завдання.
На відміну від звичайних форм пам’яті, таких як прямий доступ, вказаний доступ, послідовний або стек зберігання, нейронні мережі зберігають дані нетрадиційно. "Дані" зберігаються у вагах та упередженні з'єднань між нейронами.
Фактичне "зберігання" інформації в нейронній мережі відбувається, адаптуючи ваги з'єднання між нейронами. Модель AI "навчається", постійно адаптуючи ці ваги та упередження на основі вхідних даних та визначеного алгоритму навчання. Це безперервний процес, в якому модель може робити точні прогнози через повторювані коригування.
Модель AI може розглядатися як своєрідне програмування, оскільки вона виникає з визначених алгоритмів та математичних розрахунків, а адаптація його параметрів (ваги) постійно вдосконалюється для того, щоб зробити точні прогнози. Це тривалий процес.
Ухили - це додаткові параметри в нейронних мережах, які додаються до зважених вхідних значень нейрона. Вони дозволяють параметрам вагу (важливий, менш важливий, серед іншого), що робить AI більш гнучким і точнішим.
Нейрональні мережі можуть не лише зберегти окремі факти, але й розпізнавати з'єднання між даними за розпізнаванням шаблону. Приклад із Stuttgart ілюструє, як знання можуть бути введені в нейронну мережу, але нейронні мережі не навчаються через явні знання (як у цьому простому прикладі), а аналізуючи моделі даних. Таким чином, нейронні мережі можуть не тільки зберігати окремі факти, але й вивчати ваги та взаємозв'язки між вхідними даними.
Цей процес дає зрозуміле вступ до того, як працюють AI та особливо нейронні мережі, не занурюючи їх занадто глибоко в технічні деталі. Це показує, що зберігання інформації в нейронних мережах відбувається не як у звичайних базах даних, а шляхом адаптації сполук (ваги) в мережі.
🤖📚 Детальніше: як навчається AI?
🏋 Навчання ШІ, особливо механічної моделі навчання, відбувається в декількох кроках. Навчання AI засноване на безперервній оптимізації параметрів моделі за допомогою зворотного зв'язку та адаптації, поки модель не показує найкращі показники наданих даних. Ось детальне пояснення того, як працює цей процес:
1. 📊 Зберіть та підготуйте дані
Дані є основою навчання ШІ. Зазвичай вони складаються з тисяч або мільйонів прикладів для аналізу системи. Прикладами є зображення, тексти або дані часових рядів.
Дані повинні бути скориговані та нормалізовані, щоб уникнути зайвих джерел помилки. Дані часто перетворюються на функції (функції), які містять відповідну інформацію.
2. 🔍 Визначте модель
Модель - це математична функція, яка описує взаємозв'язки в даних. У нейронних мережах, які часто використовуються для ШІ, модель складається з декількох шарів нейронів, які з'єднані один з одним.
Кожен нейрон здійснює математичну операцію для обробки вхідних даних, а потім передає сигнал наступному нейрону.
3. 🔄 Ініціалізуйте ваги
Зв'язки між нейронами мають ваги, які спочатку встановлюються випадковим чином. Ці ваги визначають, наскільки сильно нейрон реагує на сигнал.
Метою тренувань є коригування цих ваг таким чином, щоб модель робить кращі прогнози.
4. ➡ Пробіг вперед (поширення вперед)
У випадку запуску вперед, вхідні дані керуються моделлю для отримання прогнозування.
Кожен шар обробляє дані і передає їх до наступного шару, поки останній шар не забезпечить результат.
5. ⚖ Обчисліть функцію втрат
Функція втрат вимірює, наскільки хороші прогнози моделі порівнюються з фактичними значеннями (мітками). Поширеною мірою є помилка між передбачуваною та фактичною відповіддю.
Чим вище втрата, тим гірше прогнозування моделі.
6.
У зворотному запуску помилка приписується від виходу моделі до попередніх шарів.
Помилка розподіляється на ваги з'єднань, а модель регулює ваги, щоб помилки стали меншими.
Це відбувається за допомогою градієнтного спуску: обчислюється вектор градієнта, що вказує на те, як слід змінити ваги, щоб мінімізувати помилку.
7. 🔧 Оновіть ваги
Після обчислення помилки ваги з'єднань оновлюються невеликим коригуванням на основі швидкості навчання.
Коефіцієнт навчання визначає, наскільки ваги змінюються на кожному кроці. Зміни, які є занадто великими, можуть зробити модель нестабільною і занадто мала зміна призводить до повільного процесу навчання.
8. 🔁 Повторіть (епохи)
Цей процес запуску вперед, розрахунок помилок та оновлення ваги повторюються, часто в декількох епохах (запускаються через весь набір даних), поки модель не досягне прийнятної точності.
З кожною епохою модель дізнається трохи більше і ще більше адаптує свої ваги.
9. 📉 Валідація та тестування
Після того, як модель пройшла навчання, вона тестується на перевіреному записі даних, щоб перевірити, наскільки вона добре узагальнює. Це гарантує, що він не тільки "запам'ятовує" дані про навчання, але й робить хороші прогнози на невідомі дані.
Дані тесту допомагають виміряти остаточну продуктивність моделі до її використання на практиці.
10. 🚀 Оптимізація
Подальші кроки для поліпшення моделі включають настройку гіперпараметра (наприклад, коригування швидкості навчання або структури мережі), регуляризацію (для уникнення надмірного пристосування) або ** збільшення кількості даних.
📊🔙 Штучний інтелект: Чорна коробка ШІ з поясненим AI (XAI), тепловими картими, сурогатними моделями або іншими рішеннями робить його зрозумілим, зрозумілим та поясненим

Штучний інтелект: Чорна коробка AI з поясненим AI (XAI), тепловими картими, сурогатними моделями або іншими рішеннями, зрозумілими, зрозумілими та пояснювальними: xpert.digital
Так звана "чорна коробка" штучного інтелекту (AI)-важлива і сучасна проблема. Навіть експерти часто стикаються з викликом не в змозі повністю зрозуміти, як системи AI можуть приймати свої рішення. Ця непарність може спричинити значні проблеми, особливо в критичних сферах, таких як бізнес, політика чи медицина. Лікар або лікар, який покладається на систему ШІ під час діагностики та рекомендації щодо терапії, повинен мати впевненість у прийнятті рішень. Однак, якщо прийняття рішення AI не є достатньо прозорим, невизначеність і, можливо, відсутність довіри - і в ситуаціях, коли людське життя може бути під загрозою.
Детальніше про це тут:
Ми там для вас - поради - планування - впровадження - управління проектами
☑ Підтримка МСП у стратегії, порадах, плануванні та впровадженні
☑ Створення або перестановка цифрової стратегії та оцифрування
☑ Розширення та оптимізація міжнародних процесів продажів
☑ Глобальні та цифрові торгові платформи B2B
☑ Піонерський розвиток бізнесу

Конрад Вольфенштейн
Я радий допомогти вам як особистого консультанта.
Ви можете зв’язатися зі мною, заповнивши контактну форму нижче або просто зателефонуйте мені за номером +49 89 674 804 (Мюнхен) .
Я з нетерпінням чекаю нашого спільного проекту.
Напишіть мені

Xpert.digital - Konrad Wolfenstein
Xpert.digital - це центр для промисловості з фокусом, оцифруванням, машинобудуванням, логістикою/внутрішньологічною та фотоелектричною.
За допомогою нашого рішення щодо розвитку бізнесу на 360 ° ми підтримуємо відомі компанії від нового бізнесу до після продажу.
Ринкова розвідка, маха, автоматизація маркетингу, розвиток контенту, PR, поштові кампанії, персоналізовані соціальні медіа та виховання свинцю є частиною наших цифрових інструментів.
Ви можете знайти більше на: www.xpert.digital - www.xpert.solar - www.xpert.plus
Підтримувати зв’язок

















