Люди та процеси, що стоять за штучним інтелектом – @shutterstock | Zapp2Photo
Штучний інтелект має погану репутацію вбивці робочих місць та заміни людської праці. У деяких сферах це правда, але в інших, особливо щодо очищення та обробки даних, ШІ є лідером у створенні нових робочих місць.
«Маркування та анотування даних » – це бурхливо розвиваюча галузь, що виникла завдяки штучному інтелекту. Неструктуровані набори даних з таких джерел, як камери та соціальні мережі, або структуровані джерела, такі як бази даних, маркуються, позначаються тегами, кольором або виділяються, щоб виявити відмінності та подібності між людьми. Щоб навчити машину розпізнавати знак «стоп», людина має зайти на запис вуличної камери та позначити всі знаки «стоп» на фотографії. Потім машині будуть передані дані, що ідентифікують тисячі цих зображень. З часом, обробляючи позначені дані, система може стати точнішою у розпізнаванні знака «стоп». Цей тип машинного навчання, де система підвищує точність, отримуючи більше даних, називається глибоким навчанням.
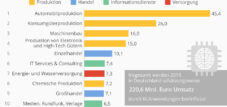
Оскільки цей процес є важливим для точного виконання алгоритмами основних функцій, галузь маркування даних набуде значного значення протягом наступних п'яти років. У 2018 році ринок підготовки даних за допомогою штучного інтелекту та машинного навчання, процесу, який сильно залежить від ручного маркування даних людьми, оцінювався в 500 мільйонів доларів. За даними Cognilytica , очікується, що до 2023 року цей показник зросте більш ніж удвічі, досягнувши 1,2 мільярда доларів. Сторонні постачальники очікують значного збільшення цього зростання з 150 мільйонів доларів до 1 мільярда доларів за той самий період. Маркування даних особливо важливе для застосувань штучного інтелекту, таких як розпізнавання об'єктів та зображень, автономні транспортні засоби, а також анотації тексту та зображень.
Штучний інтелект має погану репутацію як вбивця робочих місць та замінник людської праці. У деяких сферах це правда, але в інших, особливо щодо того, як очищуються та обробляються дані, ШІ очолює створення нових робочих місць.
Маркування та анотування даних – це бурхливо розвиваюча галузь, що народилася завдяки штучному інтелекту. Неструктуровані набори даних з таких джерел, як камери та дані соціальних мереж, або структурованих джерел, таких як бази даних, маркуються, позначаються, забарвлюються або виділяються, щоб показати відмінності та подібності між людьми. Щоб навчити машину розпізнавати знак «стоп», людина повинна переглянути запис вулиці з камери та позначити всі знаки «стоп». Потім машині передаються дані, що ідентифікують тисячі цих зображень. З часом система може точніше визначити, що таке знак «стоп», обробляючи позначені дані. Цей тип машинного навчання, де система стає точнішою, отримуючи більше даних, називається глибоким навчанням.
Оскільки цей процес є важливим для точного виконання алгоритмами основних частин своєї функції, індустрія маркування даних має намір злетіти протягом наступних п'яти років. У 2018 році ринок підготовки даних за допомогою штучного інтелекту та машинного навчання, процесу, який значною мірою залежить від людей для ручного маркування даних, становив 500 мільйонів доларів. За даними Cognilytica, очікується, що цей показник зросте більш ніж удвічі, досягнувши 1,2 мільярда доларів до 2023 року. Сторонні постачальники очікують значного зростання цього ринку зі 150 мільйонів доларів до 1 мільярда доларів за той самий період часу. Маркування даних особливо важливе для штучного інтелекту, який займається розпізнаванням об'єктів та зображень, автономними транспортними засобами, а також анотаціями тексту та зображень.


Залишайтеся на зв'язку