
Yapay zekâ çağında Schema.org ile yapılandırılmış veri (işaretleme): Google mühendisleri gerçekten ne düşünüyor?
Xpert Ön Sürümü

Available in 27 languages 📢
Google'da Xpert.Digital'i tercih edinⓘYayınlanma tarihi: 7 Mayıs 2026 / Güncelleme tarihi: 7 Mayıs 2026 – Yazar: Konrad Wolfenstein
Yapay zekâ çağında Schema.org ile yapılandırılmış veri (işaretleme): Google mühendisleri gerçekten ne düşünüyor? – Resim: Xpert.Digital
Google'ın SEO sırrı: Yapay zeka yapılandırılmış veri olmadan neden başarısız oluyor?
ChatGPT ve benzerlerine rağmen: Google mühendisleri neden Schema.org'a hâlâ güveniyor?
SEO Güncellemesi: Schema.org neden Google'da Open Graph'ın yerini alıyor?
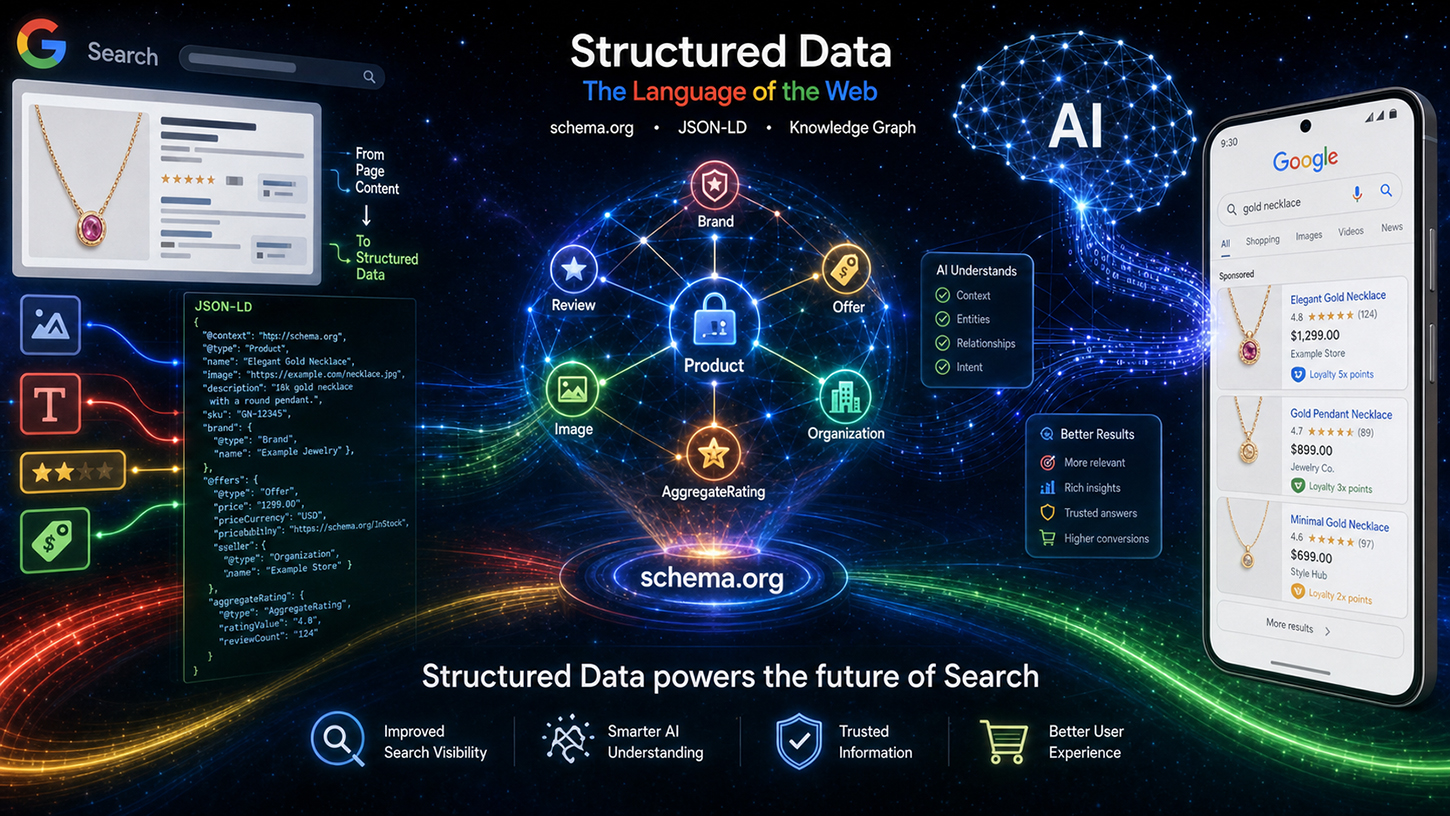
SEO dünyasında sürekli tekrarlanan bir efsane var: Yapılandırılmamış metinleri bile zahmetsizce anlayan parlak yapay zeka dil modelleri çağında, Schema.org gibi özenle oluşturulmuş yapılandırılmış veriler artık geçerliliğini yitirdi. Ancak gerçek oldukça farklı. Google Search Central Live etkinliğinde Google mühendisi Ryan Levering bu yanlış algıyı çürüttü ve şunu açıkça belirtti: Yapılandırılmış işaretleme geçmişin bir kalıntısı değil, yeni yapay zeka destekli aramanın temel omurgasıdır.
Yeni yapay zekâ genel bakışlarından otonom alışveriş ajanlarına kadar, dil modellerinin yanılsamadan kaçınmak ve hesaplama açısından verimli çalışmak için hassas, makine tarafından okunabilir yönergelere ihtiyacı vardır. Modern web'de görünür kalmak isteyenler, makinelerin bağlamı belirsizlik olmadan anlamasına yardımcı olmalıdır. Bu makale, Google'ın stratejik yeniden yapılanmasını inceliyor, e-ticaret ve kullanıcı tarafından oluşturulan içerik için devrim niteliğindeki yenilikleri sunuyor ve teknik SEO'nun makine görünürlüğü mücadelesinde neden belirleyici rekabet avantajı olduğunu gösteriyor.
Makineler interneti okuyabilir, ancak bunu ancak siz onlara interneti anlamaları için yardımcı olursanız başarabilirler
21 Nisan 2026'da, Kanada topraklarındaki ilk Google Search Central Live etkinliği Toronto'da gerçekleşti ve bu sıradan bir sektör toplantısı değildi. Google Arama Mühendisliği'nde mühendis olarak çalışan Ryan Levering, günün belki de en teknik açıdan yoğun ve stratejik açıdan önemli sunumunu yaptı: "Yapılandırılmış Veri, Kalite ve Yapay Zeka". Sunduğu şey, teknik bir incelemeden çok daha fazlasıydı. Yapay zekanın kullanıcılar ve bilgi arasında giderek daha fazla aracı rolü üstlendiği bir çağda, anlamsal web'in geleceği hakkında net bir açıklamaydı.
İki uç nokta arasında: Yanlış ya da ikilem
Ryan Levering sunumunun başında, SEO camiasında dolaşan birbirine tamamen zıt iki görüşü karşılaştırdı. Bir yandan, güçlü dil modelleri çağında yapılandırılmış verinin gereksiz olduğu inancı var: Yapay zeka modelleri yapılandırılmamış metni kolayca yorumlayabiliyorsa, kaynak koduna schema.org işaretlemesi eklemek için neden zahmet edelim ki? Öte yandan, bazı meraklılar yapılandırılmış verinin internetin geleceği olduğu fikrini savunuyor – geleneksel web'in yerini büyük ölçüde alacak, otonom yapay zeka ajanları arasında evrensel bir anlamsal iletişim protokolü.
Levering her iki uç noktayı da reddetti ve bunun yerine incelikli, ampirik temelli bir bakış açısı sundu. Her iki pozisyonun da bir doğruluk payı içerdiğini, ancak hiçbirinin gerçeği tam olarak yansıtmadığını belirtti. Bu incelik, Google'ın konuya mevcut yaklaşımının da bir özelliğidir: mesele dogma değil, pragmatik verimliliktir.
Her şeyi açıklayan dört argüman
Levering'in temel argümanı, "Yapılandırılmış Verinin Değeri" başlığı altında detaylandırdığı dört önemli noktada özetlenebilir. İlk nokta hassasiyettir: Yapılandırılmış veri, satış fiyatları veya sadakat programları gibi karmaşık şemalar için serbest metinden LLM tabanlı çıkarıma göre önemli ölçüde daha yüksek doğruluk sağlar. Dil modelleri yanıltıcı olabilir; eksik öznitelikleri doldurabilir, verileri yanlış şekilde iç içe yerleştirebilir veya bağlam dışı bilgilere erişebilir. Benzer onlarca ürüne sahip büyük bir e-ticaret sitesinden ürün fiyatlarını çıkarırken, hata oranı, temiz bir şekilde uygulanan yapılandırılmış işaretlemeye kıyasla yapay zeka çıkarımıyla önemli ölçüde daha yüksektir.
İkinci nokta ek içerikle ilgilidir: Yapılandırılmış veriler genellikle, bir sayfanın oluşturulmuş HTML'sinde bulunmayan görünmez meta veriler içerir. Tam ISO tarih formatları, kullanıcı tarafından oluşturulan içerik için kararlı tanımlayıcılar veya dahili varlık kimlikleri—bu bilgiler yalnızca işaretlemede bulunur. Hiçbir dil modeli metinde olmayan şeyi çıkaramaz.
Üçüncüsü, verimlilik: Yapılandırılmış işaretlemeyi ayrıştırmak, karmaşık verileri çıkarmak için büyük bir dil modelini işlemekten çok daha ucuzdur. Google her gün milyarlarca sayfayı indeksliyor. Hesaplama basit: JSON-LD'yi işleyen normal bir ayrıştırıcı, bir LLM çıkarım adımının hesaplama kaynaklarının çok küçük bir bölümünü tüketir. Bu nedenle yapılandırılmış veri yalnızca anlamsal olarak üstün değil, aynı zamanda iş açısından da önemli ölçüde daha verimlidir. Bu nokta, Google'ın altyapısı için doğrudan önem taşımaktadır.
Dördüncü ve belki de en az önemsenen yön ise odaklanmadır: Yapılandırılmış veri, bir sayfadaki hangi bilgilerin alakalı olduğunu açıkça vurgulayarak yapay zeka sistemlerinin alakasız verileri almasını engeller. Ana makale, birkaç ilgili ürün ve fiyatlarla dolu bir gezinme çubuğu içeren bir ürün sayfasında, açık bir açıklama içermeyen bir dil modeli hangi fiyata atıfta bulunacağından emin olamaz. Yapılandırılmış işaretleme, bu sorunu belirsiz olmayan atama yoluyla çözer.
Yapılandırılmış verilerin gerçekte nasıl işlendiği
Kaldıraç kullanımı, teknik işleme akışını da şeffaf hale getirdi. Schema.org verileri, önce belirli temizleme ve filtreleme işlemlerinden geçirilerek indekslenmiş veri olarak sınıflandırılır; etkinlikler, alışveriş ve yorumlar gibi alanlara ayrılır. Bu hazırlanmış veriler daha sonra iki farklı çıktı kanalına akar: bir yandan klasik arama sonuçları sayfası (SRP), diğer yandan ise Google'ın yapay zeka tabanlı sistemleri, özellikle de Yapay Zeka Genel Bakışları (AIO) ve Yapay Zeka Modu (AIM) için bağlam olarak. Yapılandırılmış veri böylece artık sadece zengin sonuçlar sağlayan bir araç değil, aynı zamanda üretken yapay zeka yanıtları için doğrudan girdi haline geliyor. Bu, schema.org işaretlemesinin stratejik öneminde temel bir değişimi temsil ediyor.
🎯🎯🎯 Veriye dayalı B2B sektörel merkez, neredeyse kurum içi bir çözüm olarak

Şirket içi çözüme benzer bir yaklaşım: Xpert.Digital, B2B pazarlama ve satışta operasyonel boşlukları nasıl kapatıyor? – Akıllı İçerik Odaklı İşletme - Görsel: Xpert.Digital
Xpert.Digital, Konrad Wolfenstein liderliğinde veri odaklı bir B2B endüstri merkezidir. Şirket, endüstriyel ortaklar için harici, yarı şirket içi bir çözüm görevi görerek, müşterinin tarafında ek kaynaklara ihtiyaç duymadan pazarlama, içerik ve satış alanlarındaki operasyonel boşlukları kapatmaktadır.
Daha fazla bilgi burada:
Yapılandırılmış verilerin yapay zeka ajanları için altyapı haline gelmesinin nedenleri
Alışverişe odaklanıyoruz: Kargo, sadakat programı ve ürün çeşitleri
Sunumun önemli bir bölümü e-ticaretteki yeniliklere odaklandı. Levering, Baymard Enstitüsü'nden alınan verilere göre, beklenmedik kargo bilgilerinin alışveriş sepetini terk etmenin en yaygın nedenleri arasında ikinci ve üçüncü sırada yer aldığını açıkladı. Kargo hizmetleri için yapılandırılmış işaretleme bu sorunu doğrudan çözebilir: Satıcılar artık menşe ve hedef bölgeleri, boyutları ve ağırlıkları, sipariş değeri eşiklerini, işlem sürelerini ve sadakat programı üyeliklerini doğrudan kodda hassas bir şekilde tanımlayabilirler.
Google'ın kullandığı gönderim süresi modeli iki aşamaya ayrılmıştır: işlem süresi, yani siparişin alınmasından kargo şirketine teslimine kadar geçen süre ve gerçek teslimat süresi. Her iki aşama da ayrı ayrı ve yüksek hassasiyetle – sipariş son teslim saatlerine ve işlemenin hafta içi günlerde de gerçekleşip gerçekleşmediğine kadar – etiketlenebilir. İlgili JSON-LD örnekleri, `ShippingConditions` türünün belirli ülkeler (örneğin Fransa ve Almanya) için ücretsiz gönderimi ve minimum sipariş değerlerini (örneğin 50 €) tanımlamak için nasıl kullanılabileceğini göstermektedir.
Kargo hizmetlerinin sadakat programlarıyla entegrasyonu özellikle yenilikçi. `validForMemberTier` özelliği kullanılarak, bir kargo hizmeti açıkça bir üyelik programına ve belirli bir kademeye bağlanabilir. Bu, premium üyeler için kargo avantajlarını doğrudan işaretlemede belirtmeyi mümkün kılar; bu özellik daha önce yalnızca Google Merchant Center üzerinden yapılandırılabiliyordu. İlgili sadakat programının kendisi, `Organization` varlığı altında `MemberProgram` nesnesi olarak tanımlanır ve "Altın" veya "Gümüş" gibi kademeler ve sadakat ödülleri veya puan ödülleri gibi ilgili avantajlar içerir.
Sadakat programları anlamsal varlıklar olarak
Sadakat programı fiyatlandırmasının getirilmesi ekonomik açıdan önemli. Kuruluşlar, her biri çeşitli kademelere ve farklı avantajlara (puanlar, üye fiyatları, iade politikaları, kargo bonusları) sahip birden fazla bağımsız üyelik programı tanımlayabilir. Bu bilgiler daha sonra doğrudan Google arama sonuçlarında görünür; Levering bunu, Sephora'nın alışveriş özetinde doğrudan %30 üye indirimi gösteren bir teklifi de dahil olmak üzere gerçek dünya örnekleriyle gösterdi. Levering'e göre, diğer sayfalardan sadakat programı tanımlarına bağlantı verme yeteneği olan sayfalar arası kimlik bağlantısı, şu anda "Sayfalar arası @id bağlantısı için yol açmak" olarak adlandırılan bir sonraki planlanan adımdır. Amaç: ürün sayfaları ve şirket politikaları arasında daha güçlü kurumsal referanslar oluşturmak.
Kullanıcı Tarafından Oluşturulan İçerik: Yapay Zeka Etiketleme Sorunu
Bir diğer önemli konu ise kullanıcı tarafından oluşturulan içerik (UGC) için şema türlerinin daha da geliştirilmesiydi. Burada özellikle iki yeni özellik önem taşıyor. Birincisi, forum ve soru-cevap işaretlemelerinde gömülü gönderiler ve yeniden gönderiler desteklenerek tartışma yapılarının daha doğru bir anlamsal temsili sağlanıyor. İkincisi -ve bu daha da büyük stratejik öneme sahip- makine tarafından oluşturulan içeriği açıkça tanımlamak için `so#digitalSourceType` özelliği tanıtılıyor.
Bu gelişme, forumlar ve soru-cevap siteleri gibi platformlardaki yapay zeka tarafından üretilen içerik seline doğrudan bir yanıt niteliğindedir. Web yöneticileri artık bir gönderinin algoritmik olarak mı yoksa bir dil modeli tarafından mı oluşturulduğunu belirtebilirler. Bunu belirtmeyenler, Google tarafından örtük olarak insan yazarlar olarak kabul edilir; bu kural, şeffaf etiketlemeyi teşvik eder. `digitalSourceType` özelliği, dijital kaynaklar için IPTC kodlarına dayanmaktadır ve diğer şeylerin yanı sıra, algoritmik olarak oluşturulan ve model tarafından oluşturulan içerik arasında ayrım yapar.
Görüntü seçimi: Schema, Open Graph'ı geride bırakıyor
Daha az dikkat çeken ancak pratikte etkili bir güncelleme, Google'ın görsel seçim mantığıyla ilgili. Sistem, net bir öncelik hiyerarşisiyle dahili olarak birleştiriliyor: Schema.org işaretlemesi, özellikle `primaryImageOfPage` ve `mainEntity → image` özellikleri öncelikli. Ancak ondan sonra Open Graph'tan gelen `og:image` meta etiketi geliyor. Bu değişiklik, web sitesi operatörleri için ana görselin temiz bir Schema.org uygulamasının, Google arama sonuçlarında ve yapay zeka genel bakışlarında görüntülenmesini doğrudan etkilediği anlamına geliyor; bu da somut ve ölçülebilir bir avantaj sağlıyor.
Schema.org'un kendisi de yatırım alıyor
Ayrıca Google'ın schema.org'a açık bir spesifikasyon olarak yeniden yatırım yapacağını duyurması da dikkat çekici. Üç somut önlemden bahsedildi: bireysel şema terimlerinin kullanım sıklığına ilişkin istatistiklerin yayınlanması (slayt gösterildiği gibi, `digitalSourceType` gibi bireysel terimler için yaklaşık 10.000 alan adı hakkında bilgi içeren yaygınlık verileri zaten mevcut), Google'ın kendi doğrulama kurallarının SHACL veya ShEx gibi makine tarafından okunabilir standart formatlarda yayınlanması ve sıralama kuralları için geliştirilmiş destek. Bu önemli çünkü harici geliştiricilerin, yük altında zaman zaman çöken resmi test araçlarından bağımsız olarak, Google standartlarına dayalı kendi doğrulama araçlarını oluşturmalarına olanak tanıyacak.
Doğrulama: İki araç, tek hedef
Levering, birbirini tamamlayan ancak farklı test kriterleri uygulayan iki doğrulama aracı sundu. `search.google.com/test/rich-results` adresindeki Zengin Sonuç Test Aracı, URL'leri veya saf JSON'u kabul eder ve işaretlemenin Google Arama Zengin Sonuçları için uygun olup olmadığını kontrol eder; bu nedenle, schema.org standardının kendisinden ziyade Google'ın özel gereksinimlerine dayanmaktadır. Öte yandan, `validator.schema.org`, işaretlemenin schema.org uyumlu olup olmadığını, yani açık sözlüğe uyup uymadığını kontrol eder; Google'ın bundan zengin sonuçlar üretip üretmediğine bakılmaksızın. Bu, web geliştiricileri için net bir öneriye yol açar: Her iki araç da kullanılmalıdır, çünkü işaretleme schema uyumlu olabilir ancak zengin sonuç üretme özelliğine sahip olmayabilir ve bunun tersi de geçerlidir.
Daha geniş perspektif: Yapay zeka altyapısı olarak yapılandırılmış veri
Toronto etkinliğine genel olarak bakıldığında, geleneksel SEO optimizasyonunun çok ötesine uzanan bir değişim göze çarpıyor. Yapılandırılmış veri, zengin snippet'ler elde etme aracından, yapay zeka sistemleri için temel bir veri katmanı standardına dönüşüyor. Google'ın Yapay Zeka Genel Bakışları ve Yapay Zeka Modu, yanıt oluşturma ve varlık doğrulama için bağlam olarak schema.org işaretlemesini aktif olarak kullanıyor. Doğru, eksiksiz ve hassas yapılandırılmış veriyi uygulayanlar, arama sonuçlarında görsel olarak öne çıkma şanslarını artırmakla kalmıyor, aynı zamanda içeriklerini yapay zeka yanıtları için güvenilir birincil kaynak olarak konumlandırıyorlar.
Bu bağlamda Evrensel Ticaret Protokolü (UCP) ve WebMCP'nin anılması tesadüf değildir. Google'ın 2026 yılında erken sürümlerini yayınladığı her iki ajan tabanlı iletişim standardı da web sitelerinin anlamsal olarak tanımlanmasını gerektirir. Schema.org bunun temelini oluşturur. Yapay zekâ ajanlarının web üzerinde otonom olarak hareket ettiği, arama yaptığı, karşılaştırma yaptığı ve işlemleri başlattığı bir dünyada, içeriğin makine tarafından okunabilirliği artık isteğe bağlı değil, ekonomik önem için bir ön koşuldur. Bu nedenle Ryan Levering'in Toronto'daki sunumu sadece teknik bir güncelleme raporu değil, geleceğin web altyapısına bir bakıştı.
Bunu 10 saniyede kendiniz de öğrenebilirsiniz
Eğer kendi web sitenizin veya başka bir web sitesinin yapılandırılmış verileri ne kadar iyi ve kapsamlı bir şekilde kullandığını öğrenmek istiyorsanız, Google'dan Ryan Levering'in (yukarıdaki metnimizde bahsettiğimiz) önerdiği iki aracı kullanabilirsiniz:
Google Zengin Arama Sonuçları Testi (Google görünürlüğüne odaklanarak):
adresine gidin search.google.com/test/rich-results, herhangi bir xpert.digital makalesinin URL'sini kopyalayın ve "URL'yi Test Et"e tıklayın. Araç, Google'ın o sayfada hangi işaretlemeleri tanıdığını ve bunların hatasız olup olmadığını size tam olarak gösterecektir.
Şema Doğrulayıcı (sadece standartlara uyumluluğa odaklanmıştır):
adresine gidin validator.schema.orgve aynı URL'yi yapıştırın. Burada, kaynak kodda, renkli olarak vurgulanmış şekilde, xpert.digital'in hangi JSON-LD komut dosyalarını (yapılandırılmış veri) dahil ettiğini doğrudan görebilirsiniz.
Küresel pazarlama ve iş geliştirme ortağınız
☑️ İş dilimiz İngilizce veya Almancadır
☑️ YENİ: Anadilinizde yazışma imkanı!

Konrad Wolfenstein
Ben ve ekibim, kişisel danışmanınız olarak size hizmet vermekten mutluluk duyarız.
Benimle iletişime geçmek için buradaki iletişim formunu doldurabilir telefondan beni arayabilirsiniz. +49 7348 4088 965 E-posta adresim [email protected]:veya
Ortak projemizi sabırsızlıkla bekliyorum.
☑️ KOBİ'lere strateji, danışmanlık, planlama ve uygulama konularında destek
☑️ Dijital stratejinin oluşturulması veya yeniden düzenlenmesi ve dijitalleşme
☑️ Uluslararası satış süreçlerinin genişletilmesi ve optimize edilmesi
☑️ Küresel ve Dijital B2B ticaret platformları
☑️ Öncü İş Geliştirme / Pazarlama / Halkla İlişkiler / Ticaret Fuarları
B2B desteği ve SEO ile GEO (Yapay Zeka Arama) için SaaS çözümü bir arada: B2B şirketleri için hepsi bir arada çözüm

B2B desteği ve SEO ile GEO (Yapay Zeka Arama) için SaaS çözümü bir arada: B2B şirketleri için hepsi bir arada çözüm - Resim: Xpert.Digital
Yapay zeka araması her şeyi değiştiriyor: Bu SaaS çözümü, B2B sıralamanızı sonsuza dek nasıl devrimleştirecek?.
B2B şirketleri için dijital ortam hızla değişiyor. Yapay zekânın öncülüğünde, çevrimiçi görünürlüğün kuralları yeniden yazılıyor. Şirketler için, yalnızca dijital kitlede görünür olmak değil, aynı zamanda doğru karar vericiler için de alakalı olmak her zaman bir zorluk olmuştur. Geleneksel SEO stratejileri ve yerel varlığın yönetimi (coğrafi pazarlama) karmaşık, zaman alıcı ve genellikle sürekli değişen algoritmalar ve yoğun rekabetle mücadele gerektiren süreçlerdir.
Peki ya bu süreci sadece basitleştirmekle kalmayıp aynı zamanda daha akıllı, daha tahmin edilebilir ve çok daha etkili hale getiren bir çözüm olsaydı? İşte burada, yapay zeka arama çağında SEO ve GEO'nun talepleri için özel olarak tasarlanmış güçlü bir SaaS (Hizmet Olarak Yazılım) platformu ile uzmanlaşmış B2B desteğinin birleşimi devreye giriyor.
Bu yeni nesil araçlar artık yalnızca manuel anahtar kelime analizi ve geri bağlantı stratejilerine dayanmıyor. Bunun yerine, arama amacını daha doğru bir şekilde anlamak, yerel sıralama faktörlerini otomatik olarak optimize etmek ve gerçek zamanlı rekabet analizi yapmak için yapay zekadan yararlanıyor. Sonuç olarak, B2B şirketlerine belirleyici bir avantaj sağlayan proaktif, veri odaklı bir strateji ortaya çıkıyor: Sadece bulunmakla kalmıyor, aynı zamanda kendi nişlerinde ve konumlarında önde gelen otorite olarak algılanıyorlar.
İşte B2B desteği ve yapay zeka destekli SaaS teknolojisinin SEO ve GEO pazarlamasını dönüştüren simbiyozu ve şirketinizin dijital alanda sürdürülebilir bir şekilde büyümek için bundan nasıl faydalanabileceği.
Daha fazla bilgi burada:

















