
BERT ile Yapay Zeka ve SEO – Transformatörlerden Çift Yönlü Kodlayıcı Temsilleri – doğal dil işleme (NLP) alanında model

Dil seçimi 📢
Yayınlanan: 4 Ekim 2024 / Güncelleme: 4 Ekim 2024 - Yazar: Konrad Wolfenstein

BERT ile Yapay Zeka ve SEO – Transformatörlerden Çift Yönlü Kodlayıcı Temsilleri – Doğal dil işleme (NLP) alanında model – Resim: Xpert.Digital
🚀💬 Google tarafından geliştirildi: BERT ve NLP için önemi - Çift yönlü metin anlama neden önemlidir?
🔍🗣️ Transformers'tan Çift Yönlü Kodlayıcı Temsilleri'nin kısaltması olan BERT, Google tarafından geliştirilen doğal dil işleme (NLP) alanında önemli bir modeldir. Makinelerin dili anlama biçiminde devrim yarattı. Metni soldan sağa veya soldan sağa sırayla analiz eden önceki modellerden farklı olarak BERT, çift yönlü işlemeyi mümkün kılar. Bu, bir kelimenin bağlamını hem önceki hem de sonraki metin dizisinden yakaladığı anlamına gelir. Bu yetenek, karmaşık dilsel bağlamların anlaşılmasını önemli ölçüde geliştirir.
🔍 BERT'in mimarisi
Son yıllarda, Doğal Dil İşleme (NLP) alanındaki en önemli gelişmelerden biri, PDF 2017 - Dikkat tek ihtiyacınız olan - makalesinde ( Wikipedia ) sunulduğu gibi, Transformer modelinin tanıtılmasıyla meydana geldi. Bu model, makine çevirisi gibi daha önce kullanılan yapıları atarak alanı temelden değiştirdi. Bunun yerine yalnızca dikkat mekanizmalarına dayanır. O zamandan bu yana Transformer'ın tasarımı, dil üretimi, çeviri ve ötesi gibi çeşitli alanlarda en son teknolojiyi temsil eden birçok modelin temelini oluşturdu.
Transformer modelinin ana bileşenlerinin bir örneği - Resim: Google
BERT bu Transformer mimarisini temel alır. Bu mimari, bir cümledeki kelimeler arasındaki ilişkileri analiz etmek için öz-dikkat mekanizmaları olarak adlandırılan mekanizmaları kullanır. Cümlenin tamamı bağlamında her kelimeye dikkat edilerek sözdizimsel ve anlamsal ilişkilerin daha kesin anlaşılması sağlanır.
“Dikkat İhtiyacınız olan her şey” makalesinin yazarları:
- Ashish Vaswani (Google Beyin)
- Noam Shazeer (Google Beyin)
- Niki Parmar (Google Araştırması)
- Jakob Uszkoreit (Google Araştırması)
- Lion Jones (Google Araştırması)
- Aidan N. Gomez (Toronto Üniversitesi, çalışmanın bir kısmı Google Brain'de yapılmıştır)
- Lukasz Kaiser (Google Beyin)
- Illia Polosukhin (Bağımsız, Google Araştırma'daki önceki çalışması)
Bu yazarlar, bu makalede sunulan Transformer modelinin geliştirilmesine önemli ölçüde katkıda bulunmuşlardır.
🔄 Çift yönlü işleme
BERT'in öne çıkan özelliği çift yönlü işleme yeteneğidir. Tekrarlayan sinir ağları (RNN'ler) veya Uzun Kısa Süreli Bellek (LSTM) ağları gibi geleneksel modeller metni yalnızca tek yönde işlerken, BERT bir kelimenin içeriğini her iki yönde de analiz eder. Bu, modelin anlamın ince nüanslarını daha iyi yakalamasına ve dolayısıyla daha doğru tahminler yapmasına olanak tanır.
🕵️♂️ Maskeli dil modelleme
BERT'in bir diğer yenilikçi yönü ise Maskeli Dil Modeli (MLM) tekniğidir. Bir cümlede rastgele seçilen kelimelerin maskelenmesini ve modelin, bu kelimeleri çevredeki bağlama göre tahmin edecek şekilde eğitilmesini içerir. Bu yöntem BERT'i cümledeki her kelimenin bağlamı ve anlamı hakkında derinlemesine bir anlayış geliştirmeye zorlar.
🚀 BERT'in eğitimi ve özelleştirilmesi
BERT iki aşamalı bir eğitim sürecinden geçer: ön eğitim ve ince ayar.
📚Ön eğitim
Ön eğitimde BERT, genel dil kalıplarını öğrenmek için büyük miktarda metinle eğitilir. Buna Vikipedi metinleri ve diğer kapsamlı metin külliyatları da dahildir. Bu aşamada model, temel dilsel yapıları ve bağlamları öğrenir.
🔧 İnce ayar
Ön eğitimden sonra BERT, metin sınıflandırması veya duygu analizi gibi belirli NLP görevleri için özelleştirilir. Model, performansını belirli uygulamalara göre optimize etmek için daha küçük, görevle ilgili veri kümeleriyle eğitilir.
🌍 BERT'in uygulama alanları
BERT'in doğal dil işlemenin birçok alanında son derece yararlı olduğu kanıtlanmıştır:
Arama Motoru Optimizasyonu
Google, arama sorgularını daha iyi anlamak ve daha alakalı sonuçlar göstermek için BERT'i kullanıyor. Bu, kullanıcı deneyimini büyük ölçüde geliştirir.
Metin sınıflandırması
BERT, belgeleri konuya göre kategorilere ayırabilir veya metinlerdeki ruh halini analiz edebilir.
Adlandırılmış Varlık Tanıma (NER)
Model, metinlerdeki kişi, yer veya kuruluş adları gibi adlandırılmış varlıkları tanımlar ve sınıflandırır.
Soru-cevap sistemleri
BERT sorulan sorulara kesin cevaplar vermek için kullanılır.
🧠 Yapay zekanın geleceği için BERT'in önemi
BERT, NLP modelleri için yeni standartlar belirledi ve daha fazla yeniliklerin önünü açtı. Çift yönlü işleme kapasitesi ve dil bağlamına ilişkin derin anlayış sayesinde, yapay zeka uygulamalarının verimliliğini ve doğruluğunu önemli ölçüde artırdı.
🔜 Gelecekteki gelişmeler
BERT ve benzer modellerin daha da geliştirilmesi muhtemelen daha güçlü sistemler yaratmayı hedefleyecektir. Bunlar daha karmaşık dil görevlerini yerine getirebilir ve çeşitli yeni uygulama alanlarında kullanılabilir. Bu tür modelleri günlük teknolojilere entegre etmek, bilgisayarlarla etkileşim şeklimizi temelden değiştirebilir.
🌟Yapay zekanın gelişiminde kilometre taşı
BERT, yapay zekanın gelişiminde bir dönüm noktasıdır ve makinelerin doğal dili işleme biçiminde devrim yaratmıştır. Çift yönlü mimarisi, dilsel ilişkilerin daha derin anlaşılmasını sağlar ve bu da onu çeşitli uygulamalar için vazgeçilmez kılar. Araştırma ilerledikçe BERT gibi modeller yapay zeka sistemlerinin iyileştirilmesinde ve bunların kullanımı için yeni olanakların açılmasında merkezi bir rol oynamaya devam edecek.
📣 Benzer konular
- 📚 BERT ile Tanışın: Çığır Açan NLP Modeli
- 🔍 BERT ve NLP'de çift yönlülüğün rolü
- 🧠 Transformer modeli: BERT'in temel taşı
- 🚀 Maskeli Dil Modellemesi: BERT'in Başarısının Anahtarı
- 📈 BERT'in özelleştirilmesi: Ön eğitimden ince ayara kadar
- 🌐 BERT'in modern teknolojideki uygulama alanları
- 🤖 BERT'in yapay zekanın geleceği üzerindeki etkisi
- 💡 Gelecekteki beklentiler: BERT'in daha da geliştirilmesi
- 🏆 Yapay zeka gelişiminde bir dönüm noktası olarak BERT
- 📰 “İhtiyacınız Olan Tek Şey Dikkat” adlı Transformer makalesinin yazarları: BERT'in arkasındaki beyinler
#️⃣ Hashtag'ler: #NLP #Yapay Zeka #Dil Modelleme #Transformer #Makine Öğrenimi
🎯🎯🎯 Kapsamlı bir hizmet paketinde Xpert.Digital'in kapsamlı, beş katlı uzmanlığından yararlanın | Ar-Ge, XR, Halkla İlişkiler ve SEM

Yapay Zeka ve XR 3D İşleme Makinesi: Xpert.Digital'in kapsamlı bir hizmet paketi, AR-GE XR, PR ve SEM ile beş kat uzmanlığı - Resim: Xpert.Digital
Xpert.Digital, çeşitli endüstriler hakkında derinlemesine bilgiye sahiptir. Bu, spesifik pazar segmentinizin gereksinimlerine ve zorluklarına tam olarak uyarlanmış, kişiye özel stratejiler geliştirmemize olanak tanır. Pazar trendlerini sürekli analiz ederek ve sektördeki gelişmeleri takip ederek öngörüyle hareket edebilir ve yenilikçi çözümler sunabiliriz. Deneyim ve bilginin birleşimi sayesinde katma değer üretiyor ve müşterilerimize belirleyici bir rekabet avantajı sağlıyoruz.
Bununla ilgili daha fazla bilgiyi burada bulabilirsiniz:
BERT: Devrim niteliğinde 🌟 NLP teknolojisi
🚀 Transformers'tan Çift Yönlü Kodlayıcı Temsilleri'nin kısaltması olan BERT, Google tarafından geliştirilen ve 2018'deki lansmanından bu yana Doğal Dil İşleme (NLP) alanında önemli bir atılım haline gelen gelişmiş bir dil modelidir. Makinelerin metni anlama ve işleme biçiminde devrim yaratan Transformer mimarisine dayanmaktadır. Peki BERT'i bu kadar özel kılan şey tam olarak nedir ve tam olarak ne için kullanılıyor? Bu soruyu cevaplamak için BERT'in teknik prensiplerini, işlevselliğini ve uygulama alanlarını daha derinlemesine incelememiz gerekiyor.
📚 1. Doğal dil işlemenin temelleri
BERT'in anlamını tam olarak kavramak için doğal dil işlemenin (NLP) temellerini kısaca gözden geçirmek faydalı olacaktır. NLP, bilgisayarlar ve insan dili arasındaki etkileşimle ilgilenir. Amaç, makinelere metin verilerini analiz etmeyi, anlamayı ve yanıt vermeyi öğretmektir. BERT gibi modellerin tanıtılmasından önce, dilin makineyle işlenmesi, özellikle insan dilinin belirsizliği, bağlam bağımlılığı ve karmaşık yapısı nedeniyle sıklıkla önemli zorluklarla karşılaşıyordu.
📈 2. NLP modellerinin geliştirilmesi
BERT sahneye çıkmadan önce çoğu NLP modeli tek yönlü mimarilere dayanıyordu. Bu, bu modellerin metni yalnızca soldan sağa veya sağdan sola okuduğu anlamına geliyor; bu da, bir cümledeki bir kelimeyi işlerken yalnızca sınırlı miktarda bağlamı hesaba katabilecekleri anlamına geliyor. Bu sınırlama genellikle modellerin bir cümlenin tam anlamsal bağlamını tam olarak yakalayamamasına neden oldu. Bu, belirsiz veya bağlama duyarlı sözcüklerin doğru şekilde yorumlanmasını zorlaştırdı.
BERT'den önce NLP araştırmalarındaki bir diğer önemli gelişme, bilgisayarların kelimeleri anlamsal benzerlikleri yansıtan vektörlere çevirmesine olanak tanıyan word2vec modeliydi. Ancak burada da bağlam bir kelimenin yakın çevresiyle sınırlıydı. Daha sonra, Tekrarlayan Sinir Ağları (RNN'ler) ve özellikle Uzun Kısa Süreli Bellek (LSTM) modelleri geliştirildi; bu modeller, birden fazla sözcükte bilgi depolayarak metin dizilerinin daha iyi anlaşılmasını mümkün kıldı. Ancak bu modellerin, özellikle uzun metinlerle uğraşırken ve bağlamı aynı anda her iki yönde de anlarken, kendi sınırlamaları da vardı.
🔄 3. Transformer mimarisiyle devrim
Bu atılım, 2017 yılında BERT'in temelini oluşturan Transformer mimarisinin piyasaya sürülmesiyle gerçekleşti. Transformatör modelleri, hem önceki hem de sonraki metindeki bir kelimenin bağlamını dikkate alarak metnin paralel işlenmesini sağlayacak şekilde tasarlanmıştır. Bu, cümledeki her bir kelimeye, cümledeki diğer kelimelere göre ne kadar önemli olduğuna bağlı olarak bir ağırlık değeri atayan, öz-dikkat mekanizmaları adı verilen mekanizmalar aracılığıyla gerçekleştirilir.
Transformer modelleri önceki yaklaşımlardan farklı olarak tek yönlü değil çift yönlüdür. Bu, bir kelimenin hem sol hem de sağ bağlamından bilgi alabilecekleri ve kelimenin ve anlamının daha eksiksiz ve doğru bir temsilini üretebilecekleri anlamına gelir.
🧠 4. BERT: Çift yönlü bir model
BERT, Transformer mimarisinin performansını yeni bir seviyeye taşıyor. Model, bir kelimenin bağlamını yalnızca soldan sağa veya sağdan sola değil aynı anda her iki yönde de yakalayacak şekilde tasarlanmıştır. Bu, BERT'in bir cümle içindeki bir kelimenin tam bağlamını dikkate almasına olanak tanır ve bu da dil işleme görevlerinde önemli ölçüde geliştirilmiş doğruluk sağlar.
BERT'in temel bir özelliği, Maskeli Dil Modeli (MLM) olarak adlandırılan yöntemin kullanılmasıdır. BERT eğitiminde, bir cümlede rastgele seçilen kelimeler bir maske ile değiştirilir ve model, bağlama dayalı olarak bu maskelenmiş kelimeleri tahmin edecek şekilde eğitilir. Bu teknik BERT'in bir cümledeki kelimeler arasındaki ilişkileri daha derin ve daha kesin öğrenmesini sağlar.
Ek olarak BERT, modelin bir cümlenin diğerini takip edip etmediğini tahmin etmeyi öğrendiği Sonraki Cümle Tahmini (NSP) adı verilen bir yöntem kullanır. Bu, BERT'in daha uzun metinleri anlama ve cümleler arasındaki daha karmaşık ilişkileri tanıma yeteneğini geliştirir.
🌐 5. BERT'in pratikte uygulanması
BERT'in çeşitli NLP görevleri için son derece yararlı olduğu kanıtlanmıştır. Başlıca uygulama alanlarından bazıları şunlardır:
📊 a) Metin sınıflandırması
BERT'in en yaygın kullanımlarından biri, metinlerin önceden tanımlanmış kategorilere ayrıldığı metin sınıflandırmasıdır. Bunun örnekleri arasında duygu analizi (örneğin bir metnin olumlu mu yoksa olumsuz mu olduğunun tanınması) veya müşteri geri bildiriminin sınıflandırılması yer alır. BERT, kelimelerin bağlamını derinlemesine anlaması sayesinde önceki modellere göre daha kesin sonuçlar verebilmektedir.
❓ b) Soru-cevap sistemleri
BERT aynı zamanda modelin bir metinden sorulan soruların yanıtlarını çıkardığı soru-cevap sistemlerinde de kullanılır. Bu yetenek özellikle arama motorları, sohbet robotları veya sanal asistanlar gibi uygulamalarda önemlidir. Çift yönlü mimarisi sayesinde BERT, soru dolaylı olarak formüle edilmiş olsa bile bir metinden ilgili bilgileri çıkarabilir.
🌍 c) Metin çevirisi
BERT'in kendisi doğrudan bir çeviri modeli olarak tasarlanmasa da, makine çevirisini geliştirmek için diğer teknolojilerle birlikte kullanılabilir. BERT, bir cümledeki anlamsal ilişkileri daha iyi anlayarak, özellikle belirsiz veya karmaşık ifadeler için daha doğru çeviriler oluşturulmasına yardımcı olabilir.
🏷️ d) Adlandırılmış Varlık Tanıma (NER)
Diğer bir uygulama alanı ise bir metindeki isimler, yerler veya kuruluşlar gibi belirli varlıkların tanımlanmasını içeren Adlandırılmış Varlık Tanıma'dır (NER). BERT'in bu görevde özellikle etkili olduğu kanıtlandı çünkü bir cümlenin bağlamını tamamen dikkate alıyor ve farklı bağlamlarda farklı anlamlara sahip olsalar bile varlıkları tanımayı daha iyi hale getiriyor.
✂️ e) Metin özeti
BERT'in bir metnin tüm içeriğini anlama yeteneği aynı zamanda onu otomatik metin özetleme için de güçlü bir araç haline getirir. Uzun bir metinden en önemli bilgileri çıkarmak ve kısa bir özet oluşturmak için kullanılabilir.
🌟 6. BERT'in araştırma ve endüstri açısından önemi
BERT'in tanıtılması, NLP araştırmalarında yeni bir çağ başlattı. Çift yönlü Transformatör mimarisinin gücünden tam olarak yararlanan ilk modellerden biriydi ve sonraki birçok model için çıtayı belirledi. Birçok şirket ve araştırma enstitüsü, uygulamalarının performansını artırmak için BERT'i NLP hatlarına entegre etti.
Ayrıca BERT, dil modelleri alanında daha fazla yeniliklerin yolunu açmıştır. Örneğin, benzer ilkelere dayanan ancak farklı kullanım durumları için özel iyileştirmeler sunan GPT (Generative Pretrained Transformer) ve T5 (Metinden Metne Aktarım Transformatörü) gibi modeller daha sonra geliştirildi.
🚧 7. BERT'in zorlukları ve sınırlamaları
Pek çok avantajına rağmen BERT'in bazı zorlukları ve sınırlamaları da vardır. En büyük engellerden biri modeli eğitmek ve uygulamak için gereken yüksek hesaplama çabasıdır. BERT milyonlarca parametreye sahip çok büyük bir model olduğundan, özellikle büyük miktarlarda veri işlerken güçlü donanım ve önemli bilgi işlem kaynakları gerektirir.
Diğer bir konu da eğitim verilerinde bulunabilecek potansiyel önyargıdır. BERT büyük miktarda metin verisi üzerinde eğitildiğinden bazen bu verilerde mevcut olan önyargıları ve stereotipleri yansıtır. Ancak araştırmacılar bu sorunları belirlemek ve çözmek için sürekli çalışıyorlar.
🔍Modern dil işleme uygulamaları için temel araç
BERT, makinelerin insan dilini anlama şeklini önemli ölçüde geliştirdi. Çift yönlü mimarisi ve yenilikçi eğitim yöntemleriyle, bir cümledeki kelimelerin bağlamını derinlemesine ve doğru bir şekilde yakalayarak birçok NLP görevinde daha yüksek doğruluk elde edilmesini sağlar. Metin sınıflandırmasında, soru-cevap sistemlerinde veya varlık tanımada BERT kendisini modern dil işleme uygulamaları için vazgeçilmez bir araç olarak kabul ettirmiştir.
Doğal dil işleme konusundaki araştırmalar şüphesiz ilerlemeye devam edecek ve BERT gelecekteki birçok yeniliğin temelini attı. Mevcut zorluklara ve sınırlamalara rağmen BERT, teknolojinin kısa sürede ne kadar ilerlediğini ve gelecekte ne gibi heyecan verici fırsatların açılacağını etkileyici bir şekilde gösteriyor.
🌀 Transformer: Doğal Dil İşlemede Bir Devrim
🌟 Son yıllarda Doğal Dil İşleme (NLP) alanındaki en önemli gelişmelerden biri, 2017 tarihli “Tek İhtiyacınız Olan Dikkat” makalesinde anlatıldığı gibi Transformer modelinin tanıtılması olmuştur. Bu model, makine çevirisi gibi dizi transdüksiyon görevleri için daha önce kullanılan yinelenen veya evrişimli yapıları atarak alanı temelden değiştirdi. Bunun yerine yalnızca dikkat mekanizmalarına dayanır. O zamandan bu yana Transformer'ın tasarımı, dil üretimi, çeviri ve ötesi gibi çeşitli alanlarda en son teknolojiyi temsil eden birçok modelin temelini oluşturdu.
🔄 Transformer: Bir paradigma değişimi
Transformer'ın piyasaya sürülmesinden önce, görevlerin sıralanmasına yönelik çoğu model, doğası gereği sıralı olan tekrarlayan sinir ağlarına (RNN'ler) veya uzun kısa süreli bellek ağlarına (LSTM'ler) dayanıyordu. Bu modeller giriş verilerini adım adım işleyerek dizi boyunca yayılan gizli durumlar yaratır. Bu yöntem etkili olmasına rağmen hesaplama açısından pahalıdır ve özellikle uzun diziler için paralelleştirilmesi zordur. Ek olarak, RNN'ler "kaybolan gradyan" sorunu nedeniyle uzun vadeli bağımlılıkları öğrenmekte zorluk çekiyor.
Transformer'ın temel yeniliği, modelin konumlarına bakılmaksızın bir cümledeki farklı kelimelerin önemini birbirine göre ağırlıklandırmasına olanak tanıyan öz-dikkat mekanizmalarının kullanılmasında yatmaktadır. Bu, modelin geniş aralıklı kelimeler arasındaki ilişkileri RNN'ler veya LSTM'lerden daha etkili bir şekilde yakalamasına ve bunu sıralı yerine paralel bir şekilde yapmasına olanak tanır. Bu yalnızca eğitim verimliliğini artırmakla kalmaz, aynı zamanda makine çevirisi gibi görevlerdeki performansı da artırır.
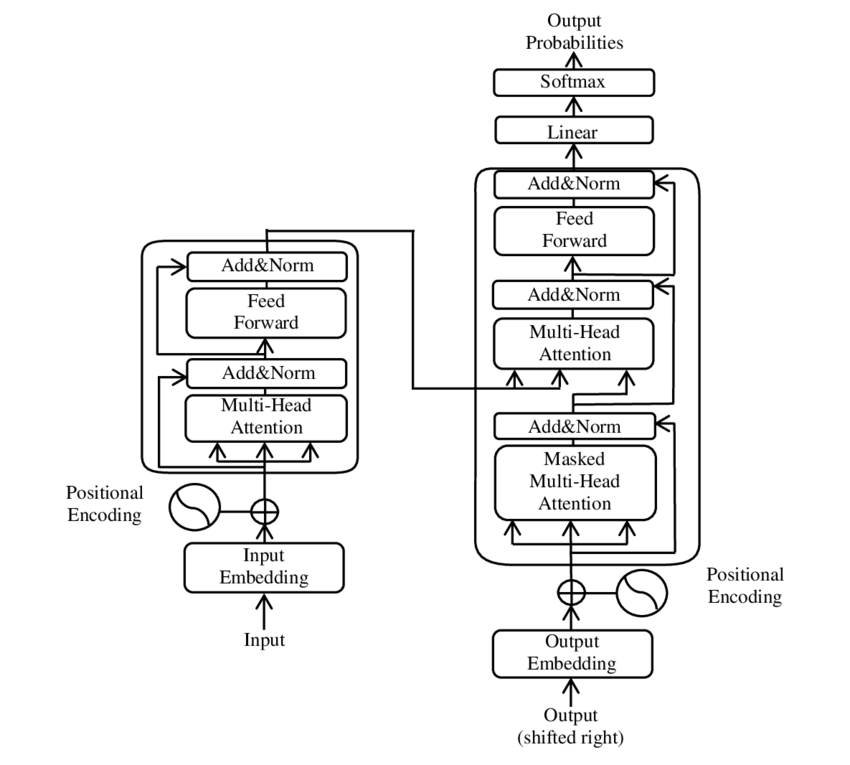
🧩 Model mimarisi
Transformer iki ana bileşenden oluşur: her ikisi de birden fazla katmandan oluşan ve büyük ölçüde çok kafalı dikkat mekanizmalarına dayanan bir kodlayıcı ve bir kod çözücü.
⚙️ Kodlayıcı
Kodlayıcı, her biri iki alt katmana sahip altı özdeş katmandan oluşur:
1. Çok Kafalı Kişisel Dikkat
Bu mekanizma, modelin her bir kelimeyi işlerken giriş cümlesinin farklı bölümlerine odaklanmasını sağlar. Dikkati tek bir alanda hesaplamak yerine, çok kafalı dikkat, girdiyi birkaç farklı alana yansıtır ve kelimeler arasındaki farklı türdeki ilişkilerin yakalanmasına olanak tanır.
2. Konum bazında tamamen bağlı ileri beslemeli ağlar
Dikkat katmanından sonra her konuma bağımsız olarak tam bağlantılı bir ileri beslemeli ağ uygulanır. Bu, modelin her kelimeyi bağlam içinde işlemesine ve dikkat mekanizmasından gelen bilgileri kullanmasına yardımcı olur.
Giriş dizisinin yapısını korumak için model aynı zamanda konumsal girişler (konumsal kodlamalar) içerir. Transformer kelimeleri sıralı olarak işlemediği için bu kodlamalar, kelimelerin cümle içindeki sırasına ilişkin model bilgisinin verilmesi açısından önemlidir. Modelin dizideki farklı konumları ayırt edebilmesi için konum girişleri sözcük yerleştirmelerine eklenir.
🔍 Kod çözücüler
Kodlayıcı gibi kod çözücü de altı katmandan oluşur; her katman, modelin çıktıyı üretirken girdi dizisinin ilgili kısımlarına odaklanmasını sağlayan ek bir dikkat mekanizmasına sahiptir. Kod çözücü ayrıca, dizi oluşturmanın otoregresif doğasını koruyarak gelecekteki konumları dikkate almasını önlemek için bir maskeleme tekniği kullanır.
🧠 Çok kafalı dikkat ve nokta ürün dikkati
Transformatörün kalbi, daha basit nokta çarpım dikkatinin bir uzantısı olan Çok Kafalı Dikkat mekanizmasıdır. Dikkat işlevi, bir sorgu ile bir dizi anahtar-değer çifti (anahtarlar ve değerler) arasında bir eşleme olarak görülebilir; burada her anahtar dizideki bir kelimeyi temsil eder ve değer, ilgili bağlamsal bilgiyi temsil eder.
Çok kafalı dikkat mekanizması, modelin aynı anda dizinin farklı bölümlerine odaklanmasını sağlar. Model, girdiyi birden fazla alt uzaya yansıtarak sözcükler arasında daha zengin bir ilişkiler kümesi yakalayabilir. Bu, özellikle bir kelimenin bağlamını anlamanın sözdizimsel yapı ve anlamsal anlam gibi birçok farklı faktör gerektirdiği makine çevirisi gibi görevlerde faydalıdır.
Nokta çarpım dikkatinin formülü şöyledir:

Burada (Q) sorgu matrisi, (K) anahtar matrisi ve (V) değer matrisidir. (sqrt{d_k}) terimi, nokta çarpımlarının çok büyük olmasını önleyen bir ölçeklendirme faktörüdür, bu da çok küçük degradelere ve daha yavaş öğrenmeye yol açar. Dikkat ağırlıklarının toplamının bire eşit olmasını sağlamak için softmax fonksiyonu uygulanır.
🚀 Transformatörün Avantajları
Transformer, RNN'ler ve LSTM'ler gibi geleneksel modellere göre birçok önemli avantaj sunar:
1. Paralelleştirme
Transformer, tüm belirteçleri aynı anda bir sırayla işlediğinden, oldukça paralel hale getirilebilir ve bu nedenle, özellikle büyük veri kümelerinde eğitilmesi RNN'lerden veya LSTM'lerden çok daha hızlıdır.
2. Uzun vadeli bağımlılıklar
Öz-dikkat mekanizması, modelin, hesaplamalarının sıralı doğası nedeniyle sınırlı olan uzak kelimeler arasındaki ilişkileri RNN'lerden daha etkili bir şekilde yakalamasına olanak tanır.
3. Ölçeklenebilirlik
Transformer, RNN'lerle ilişkili performans darboğazlarından etkilenmeden çok büyük veri kümelerine ve daha uzun dizilere kolayca ölçeklenebilir.
🌍 Uygulamalar ve efektler
Transformer, piyasaya sürülmesinden bu yana çok çeşitli NLP modellerinin temeli haline geldi. En dikkate değer örneklerden biri, soru yanıtlama ve metin sınıflandırma da dahil olmak üzere birçok NLP görevinde en son teknolojiyi elde etmek için değiştirilmiş bir Transformer mimarisini kullanan BERT'tir (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri).
Bir diğer önemli gelişme, metin oluşturmak için Transformer'ın kod çözücüyle sınırlı bir versiyonunu kullanan GPT'dir (Generative Pretrained Transformer). GPT-3 de dahil olmak üzere GPT modelleri artık içerik oluşturmadan kod tamamlamaya kadar çeşitli uygulamalar için kullanılıyor.
🔍 Güçlü ve esnek bir model
Transformer, NLP görevlerine yaklaşma şeklimizi temelden değiştirdi. Çeşitli problemlere uygulanabilecek güçlü ve esnek bir model sağlar. Uzun vadeli bağımlılıklarla başa çıkma yeteneği ve eğitim verimliliği, onu en modern modellerin çoğu için tercih edilen mimari yaklaşım haline getirmiştir. Araştırma ilerledikçe Transformer'da, özellikle de dikkat mekanizmalarının ümit verici sonuçlar verdiği görüntü ve dil işleme gibi alanlarda muhtemelen daha fazla iyileştirme ve ayarlamalar göreceğiz.
Sizin için oradayız - tavsiye - planlama - uygulama - proje yönetimi
☑️ Sektör uzmanı, 2.500'den fazla uzman makalenin yer aldığı kendi Xpert.Digital endüstri merkeziyle burada

Konrad Wolfenstein
Kişisel danışmanınız olarak hizmet etmekten mutluluk duyarım.
Aşağıdaki iletişim formunu doldurarak benimle iletişime geçebilir veya +49 89 89 674 804 (Münih) .
Ortak projemizi sabırsızlıkla bekliyorum.
Bana yaz

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital, dijitalleşme, makine mühendisliği, lojistik/intralojistik ve fotovoltaik konularına odaklanan bir endüstri merkezidir.
360° iş geliştirme çözümümüzle, tanınmış firmalara yeni işlerden satış sonrasına kadar destek veriyoruz.
Pazar istihbaratı, pazarlama, pazarlama otomasyonu, içerik geliştirme, halkla ilişkiler, posta kampanyaları, kişiselleştirilmiş sosyal medya ve öncü yetiştirme dijital araçlarımızın bir parçasıdır.
Daha fazla bilgiyi şu adreste bulabilirsiniz: www.xpert.digital - www.xpert.solar - www.xpert.plus
İletişimi koparmamak




















