
Yapay zekayı açıklama girişimi: Yapay zeka nasıl çalışır ve çalışır, nasıl eğitilir?

Dil seçimi 📢
Yayınlanan: 8 Eylül 2024 / Güncelleme: 9 Eylül 2024 - Yazar: Konrad Wolfenstein

Yapay zekayı açıklama girişimi: Yapay zeka nasıl çalışır ve nasıl eğitilir? – Resim: Xpert.Digital
📊 Veri girişinden model tahminine: Yapay zeka süreci
Yapay zeka (AI) nasıl çalışır? 🤖
Yapay zekanın (AI) nasıl çalıştığı, açıkça tanımlanmış birkaç adıma ayrılabilir. Bu adımların her biri yapay zekanın sunduğu nihai sonuç açısından kritik öneme sahiptir. Süreç, veri girişiyle başlar ve model tahmini, olası geri bildirim veya ileri eğitim turlarıyla sona erer. Bu aşamalar, ister basit kurallar dizisi, ister oldukça karmaşık sinir ağları olsun, hemen hemen tüm yapay zeka modellerinin içinden geçtiği süreci tanımlar.
1. Veri girişi 📊
Tüm yapay zekaların temeli, birlikte çalıştığı verilerdir. Bu veriler, resimler, metinler, ses dosyaları veya videolar gibi çeşitli biçimlerde olabilir. Yapay zeka bu ham verileri kalıpları tanımak ve karar vermek için kullanır. Verilerin kalitesi ve miktarı burada merkezi bir rol oynuyor çünkü modelin daha sonra ne kadar iyi veya kötü çalışacağı üzerinde önemli bir etkiye sahipler.
Veriler ne kadar kapsamlı ve kesin olursa yapay zeka da o kadar iyi öğrenebilir. Örneğin, bir yapay zeka görüntü işleme için eğitildiğinde, farklı nesneleri doğru bir şekilde tanımlamak için büyük miktarda görüntü verisine ihtiyaç duyar. Dil modellerinde yapay zekanın insan dilini anlamasına ve oluşturmasına yardımcı olan metin verileridir. Tahminlerin kalitesi yalnızca temel veriler kadar iyi olabileceğinden, veri girişi ilk ve en önemli adımlardan biridir. Bilgisayar bilimindeki ünlü bir prensip bunu "Çöp girer, çöp çıkar" sözleriyle açıklar; kötü veriler kötü sonuçlara yol açar.
2. Veri ön işleme 🧹
Veriler girildikten sonra gerçek modele aktarılmadan önce hazırlanması gerekir. Bu işleme veri ön işleme denir. Burada amaç verinin model tarafından en iyi şekilde işlenebilecek forma getirilmesidir.
Ön işlemede yaygın bir adım veri normalleştirmedir. Bu, modelin verileri eşit şekilde ele alması için verilerin tek tip bir değer aralığına getirildiği anlamına gelir. Buna bir örnek, bir görüntünün tüm piksel değerlerini 0 ila 255 yerine 0 ila 1 aralığına ölçeklendirmek olabilir.
Ön işlemenin bir diğer önemli kısmı özellik çıkarma olarak adlandırılan kısımdır. Özellikle modelle ilgili olan ham verilerden belirli özellikler çıkarılır. Örneğin görüntü işlemede bu kenarlar veya belirli renk desenleri olabilirken, metinlerde ilgili anahtar kelimeler veya cümle yapıları çıkarılır. Ön işleme, yapay zekanın öğrenme sürecini daha verimli ve hassas hale getirmek için çok önemlidir.
3. Model 🧩
Model her yapay zekanın kalbidir. Burada veriler algoritmalara ve matematiksel hesaplamalara dayalı olarak analiz edilir ve işlenir. Bir model farklı şekillerde mevcut olabilir. En bilinen modellerden biri insan beyninin nasıl çalıştığını temel alan sinir ağlarıdır.
Sinir ağları, bilgiyi işleyen ve aktaran birkaç yapay nöron katmanından oluşur. Her katman bir önceki katmanın çıktılarını alır ve bunları daha da işler. Bir sinir ağının öğrenme süreci, ağın giderek daha doğru tahminler veya sınıflandırmalar yapabilmesi için bu nöronlar arasındaki bağlantıların ağırlıklarının ayarlanmasından oluşur. Bu adaptasyon, ağın büyük miktarlarda örnek veriye eriştiği ve dahili parametrelerini (ağırlıklarını) yinelemeli olarak iyileştirdiği eğitim yoluyla gerçekleşir.
Yapay zeka modellerinde sinir ağlarının yanı sıra başka birçok algoritma da kullanılıyor. Bunlar karar ağaçlarını, rastgele ormanları, destek vektör makinelerini ve daha birçoklarını içerir. Hangi algoritmanın kullanılacağı spesifik göreve ve mevcut verilere bağlıdır.
4. Model tahmini 🔍
Model verilerle eğitildikten sonra tahminlerde bulunabilmektedir. Bu adıma model tahmini denir. Yapay zeka bir girdi alır ve şu ana kadar öğrendiği kalıplara dayanarak bir çıktı, yani bir tahmin veya karar döndürür.
Bu tahmin farklı şekillerde olabilir. Örneğin, bir görüntü sınıflandırma modelinde yapay zeka, bir görüntüde hangi nesnenin görünür olduğunu tahmin edebilir. Bir dil modelinde, cümlede hangi kelimenin sonra geleceğine dair bir tahmin yapılabilir. Finansal tahminlerde yapay zeka, borsanın nasıl performans göstereceğini tahmin edebiliyor.
Tahminlerin doğruluğunun büyük ölçüde eğitim verilerinin kalitesine ve model mimarisine bağlı olduğunu vurgulamak önemlidir. Yetersiz veya önyargılı verilerle eğitilmiş bir modelin yanlış tahminlerde bulunması muhtemeldir.
5. Geri bildirim ve eğitim (isteğe bağlı) ♻️
Yapay zekanın çalışmasının bir diğer önemli kısmı geri bildirim mekanizmasıdır. Model düzenli olarak kontrol edilir ve daha da optimize edilir. Bu süreç ya eğitim sırasında ya da model tahmininden sonra gerçekleşir.
Model yanlış tahminlerde bulunursa geri bildirim yoluyla bu hataları tespit etmeyi öğrenebilir ve dahili parametrelerini buna göre ayarlayabilir. Bu, model tahminlerini gerçek sonuçlarla (örneğin, doğru cevapların zaten mevcut olduğu bilinen verilerle) karşılaştırarak yapılır. Bu bağlamdaki tipik bir prosedür, yapay zekanın halihazırda doğru yanıtlarla sağlanan örnek verilerden öğrendiği denetimli öğrenme olarak adlandırılır.
Yaygın bir geri bildirim yöntemi, sinir ağlarında kullanılan geri yayılım algoritmasıdır. Modelin yaptığı hatalar, nöron bağlantılarının ağırlıklarını ayarlamak için ağ üzerinden geriye doğru yayılır. Model hatalarından ders alıyor ve tahminlerinde giderek daha kesin hale geliyor.
Antrenmanın rolü 🏋️♂️
Bir yapay zekayı eğitmek yinelenen bir süreçtir. Model ne kadar çok veri görürse ve bu verilere dayalı olarak ne kadar sıklıkla eğitilirse tahminleri de o kadar doğru olur. Ancak sınırlamalar da vardır: Aşırı eğitilmiş bir model, "aşırı uyum" olarak adlandırılan sorunlara sahip olabilir. Bu, eğitim verilerini o kadar iyi ezberlediği ve yeni, bilinmeyen verilerde daha kötü sonuçlar ürettiği anlamına gelir. Bu nedenle modeli genelleştirecek ve yeni veriler üzerinde bile iyi tahminler yapacak şekilde eğitmek önemlidir.
Düzenli eğitimlerin yanı sıra transfer öğrenme gibi prosedürler de bulunmaktadır. Burada, halihazırda büyük miktarda veri üzerinde eğitilmiş bir model, yeni ve benzer bir görev için kullanılıyor. Bu, modelin sıfırdan eğitilmesine gerek olmadığından zamandan ve bilgi işlem gücünden tasarruf sağlar.
Güçlü yönlerinizden en iyi şekilde yararlanın 🚀
Yapay zekanın çalışması, çeşitli adımların karmaşık etkileşimine dayanmaktadır. Veri girişi, ön işleme, model eğitimi, tahmin ve geri bildirimden yapay zekanın doğruluğunu ve verimliliğini etkileyen birçok faktör vardır. İyi eğitilmiş bir yapay zeka, basit görevlerin otomatikleştirilmesinden karmaşık sorunların çözülmesine kadar yaşamın birçok alanında muazzam faydalar sağlayabilir. Ancak yapay zekanın güçlü yönlerinden en iyi şekilde yararlanmak için sınırlamalarını ve potansiyel tuzaklarını anlamak da aynı derecede önemlidir.
🤖📚 Basitçe açıkladım: Yapay zeka nasıl eğitilir?
🤖📊 Yapay zeka öğrenme süreci: yakalayın, bağlayın ve kaydedin
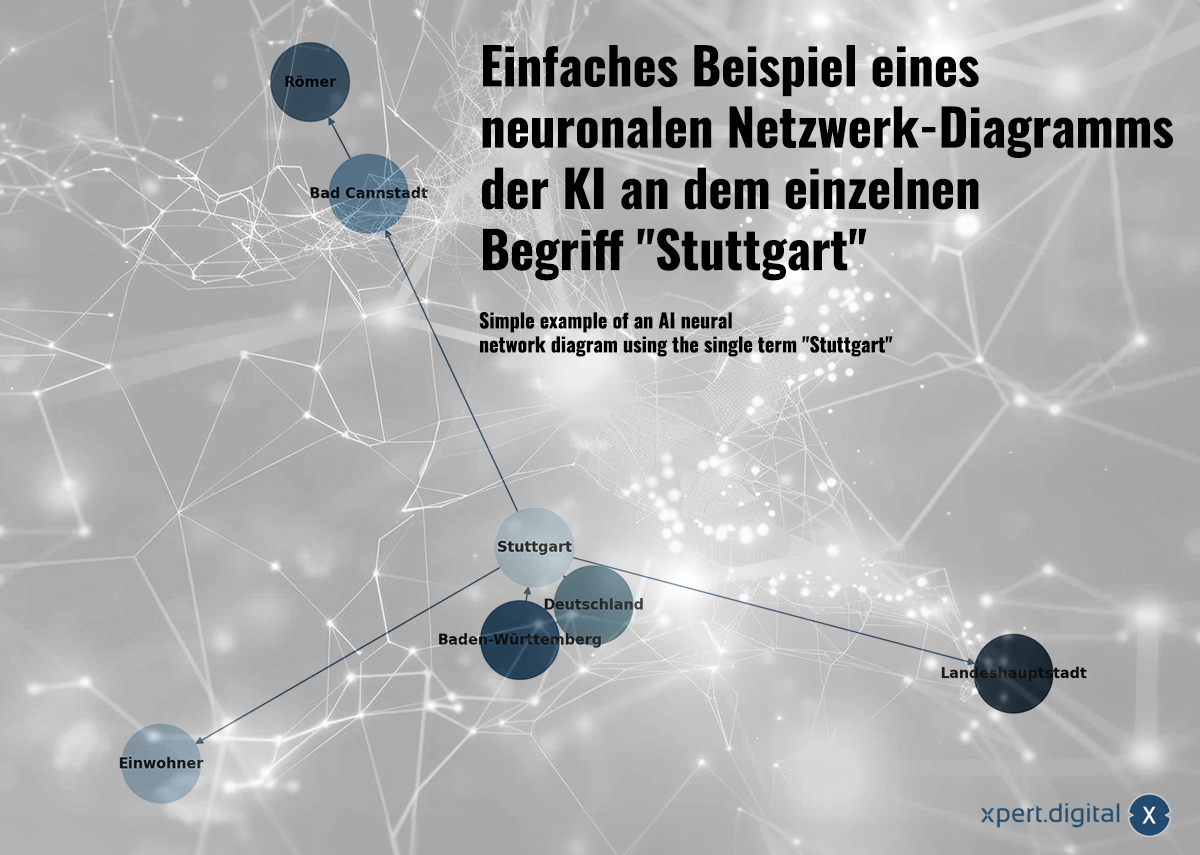
Bireysel “Stuttgart” teriminde AI'nın nöronal ağ diyagramının basit bir örneği -Image: Xpert.digital
🌟 Veri toplayın ve hazırlayın
Yapay zeka öğrenme sürecinin ilk adımı verilerin toplanması ve hazırlanmasıdır. Bu veriler veritabanları, sensörler, metinler veya resimler gibi çeşitli kaynaklardan gelebilir.
🌟 Verileri ilişkilendirme (Sinir Ağı)
Toplanan veriler bir sinir ağında birbirleriyle ilişkilidir. Her veri paketi, “nöronlar” (düğüm) ağındaki bağlantılarla gösterilir. Stuttgart şehri ile basit bir örnek şöyle görünebilir:
a) Stuttgart, Baden-Württemberg'in bir şehridir
b) Baden-Württemberg, Almanya'nın federal bir eyaletidir
c) Stuttgart, Almanya'nın bir şehridir
d) Stuttgart'ın 2023 yılı nüfusu 633.484'tür
e) Bad Cannstatt, Stuttgart'ın bir ilçesidir
f) Bad Cannstatt Romalılar tarafından kurulmuştur
g) Stuttgart, Baden-Württemberg eyaletinin başkentidir
Veri hacminin boyutuna bağlı olarak, kullanılan yapay zeka modeli kullanılarak potansiyel harcamalara ilişkin parametreler oluşturulur. Örnek olarak: GPT-3'ün yaklaşık 175 milyar parametresi var!
🌟 Depolama ve özelleştirme (öğrenme)
Veriler sinir ağına beslenir. Yapay zeka modelinden geçerler ve bağlantılar (sinapslara benzer şekilde) aracılığıyla işlenirler. Nöronlar arasındaki ağırlıklar (parametreler), modeli eğitmek veya bir görevi gerçekleştirmek için ayarlanır.
Doğrudan erişim, belirtilen erişim, sıralı veya yığın depolama gibi geleneksel bellek formlarının aksine, sinir ağları verileri alışılmadık bir şekilde depolar. “Veriler”, nöronlar arasındaki bağlantıların ağırlıkları ve önyargılarında saklanır.
Nöronal bir ağdaki bilgilerin gerçek "depolanması" nöronlar arasındaki bağlantı ağırlıklarını uyarlayarak gerçekleşir. AI modeli, bu ağırlık ve önyargıları giriş verilerine ve tanımlanmış bir öğrenme algoritmasına göre sürekli olarak uyarlayarak “öğrenir”. Bu, modelin yinelenen ayarlamalar nedeniyle kesin tahminler yapabileceği sürekli bir süreçtir.
Yapay zeka modeli, tanımlanmış algoritmalar ve matematiksel hesaplamalar yoluyla oluşturulduğu ve doğru tahminler yapabilmek için parametrelerinin (ağırlıklarının) ayarlanmasını sürekli olarak geliştirdiği için bir tür programlama olarak kabul edilebilir. Bu devam eden bir süreçtir.
Önyargılar, sinir ağlarında bir nöronun ağırlıklı giriş değerlerine eklenen ek parametrelerdir. Parametrelerin ağırlıklandırılmasına (önemli, daha az önemli, önemli vb.) izin vererek yapay zekayı daha esnek ve doğru hale getirirler.
Sinir ağları yalnızca bireysel gerçekleri depolamakla kalmaz, aynı zamanda örüntü tanıma yoluyla veriler arasındaki bağlantıları da tanıyabilir. Stuttgart örneği, bilginin bir sinir ağına nasıl dahil edilebileceğini göstermektedir, ancak sinir ağları açık bilgi yoluyla (bu basit örnekte olduğu gibi) değil, veri modellerinin analizi yoluyla öğrenir. Sinir ağları yalnızca bireysel gerçekleri depolamakla kalmaz, aynı zamanda girdi verileri arasındaki ağırlıkları ve ilişkileri de öğrenebilir.
Bu akış, teknik ayrıntılara çok fazla dalmadan, özellikle yapay zeka ve sinir ağlarının nasıl çalıştığına dair anlaşılır bir giriş sağlıyor. Sinir ağlarında bilginin depolanmasının geleneksel veritabanlarında olduğu gibi değil, ağ içindeki bağlantıların (ağırlıkların) ayarlanmasıyla yapıldığını göstermektedir.
🤖📚 Daha detaylı: Yapay zeka nasıl eğitilir?
🏋️♂️ Bir yapay zekanın, özellikle de bir makine öğrenme modelinin eğitimi birkaç adımda gerçekleşir. Bir yapay zekanın eğitimi, model sağlanan veriler üzerinde en iyi performansı gösterene kadar geri bildirim ve ayarlama yoluyla model parametrelerinin sürekli olarak optimize edilmesine dayanır. Bu sürecin nasıl işlediğine dair ayrıntılı bir açıklamayı burada bulabilirsiniz:
1. 📊Verileri toplayın ve hazırlayın
Veriler yapay zeka eğitiminin temelidir. Genellikle sistemin analiz etmesi için binlerce veya milyonlarca örnekten oluşurlar. Örnekler; resimler, metinler veya zaman serisi verileridir.
Gereksiz hata kaynaklarından kaçınmak için veriler temizlenmeli ve normalleştirilmelidir. Çoğu zaman veriler, ilgili bilgileri içeren özelliklere dönüştürülür.
2. 🔍 Modeli tanımlayın
Model, verilerdeki ilişkileri açıklayan matematiksel bir fonksiyondur. Yapay zeka için sıklıkla kullanılan sinir ağlarında model, birbirine bağlı birden fazla nöron katmanından oluşur.
Her nöron, giriş verilerini işlemek için matematiksel bir işlem gerçekleştirir ve ardından bir sonraki nörona bir sinyal iletir.
3. 🔄 Ağırlıkları başlat
Nöronlar arasındaki bağlantıların başlangıçta rastgele belirlenen ağırlıkları vardır. Bu ağırlıklar, bir nöronun bir sinyale ne kadar güçlü tepki vereceğini belirler.
Eğitimin amacı, modelin daha iyi tahminler yapabilmesi için bu ağırlıkları ayarlamaktır.
4. ➡️ İleri Yayılma
İleri geçiş, bir tahmin üretmek için giriş verilerini modelden geçirir.
Her katman verileri işler ve son katman sonucu verene kadar onu bir sonraki katmana aktarır.
5. ⚖️ Kayıp fonksiyonunu hesaplayın
Kayıp fonksiyonu, modelin tahminlerinin gerçek değerlerle (etiketler) karşılaştırıldığında ne kadar iyi olduğunu ölçer. Yaygın bir ölçü, tahmin edilen ve gerçek tepki arasındaki hatadır.
Kayıp ne kadar yüksekse modelin tahmini de o kadar kötüydü.
6. 🔙 Geri yayılım
Geriye doğru geçişte hata, modelin çıktısından önceki katmanlara geri beslenir.
Hata, bağlantıların ağırlıklarına yeniden dağıtılır ve model, hataların küçülmesi için ağırlıkları ayarlar.
Bu, gradyan iniş kullanılarak yapılır: gradyan vektörü hesaplanır; bu, hatayı en aza indirmek için ağırlıkların nasıl değiştirilmesi gerektiğini gösterir.
7. 🔧 Ağırlıkları güncelleyin
Hata hesaplandıktan sonra bağlantıların ağırlıkları öğrenme oranına göre küçük bir ayarlama ile güncellenir.
Öğrenme oranı, her adımda ağırlıkların ne kadar değişeceğini belirler. Çok büyük değişiklikler modeli kararsız hale getirebilir, çok küçük değişiklikler ise öğrenme sürecinin yavaşlamasına yol açabilir.
8. 🔁 Tekrarla (Dönem)
Bu ileri geçiş, hata hesaplama ve ağırlık güncelleme süreci, model kabul edilebilir doğruluğa ulaşana kadar sıklıkla birden fazla dönem boyunca (tüm veri setinden geçer) tekrarlanır.
Model her dönemde biraz daha fazla şey öğrenir ve ağırlıklarını daha da ayarlar.
9. 📉 Doğrulama ve test etme
Model eğitildikten sonra, ne kadar iyi genelleştirilebildiğini kontrol etmek için doğrulanmış bir veri seti üzerinde test edilir. Bu, yalnızca eğitim verilerini "ezberlemesini" sağlamakla kalmaz, aynı zamanda bilinmeyen veriler üzerinde iyi tahminler yapmasını da sağlar.
Test verileri, modelin pratikte kullanılmadan önceki nihai performansının ölçülmesine yardımcı olur.
10. 🚀 Optimizasyon
Modeli geliştirmeye yönelik ek adımlar arasında hiperparametre ayarı (örneğin, öğrenme hızının veya ağ yapısının ayarlanması), düzenlileştirme (fazla uyumu önlemek için) veya veri miktarının arttırılması yer alır.
📊🔙 Yapay zeka: Açıklanabilir Yapay Zeka (XAI), ısı haritaları, vekil modeller veya diğer çözümlerle yapay zekanın kara kutusunu anlaşılabilir, anlaşılır ve açıklanabilir hale getirin

Yapay zeka: Açıklanabilir Yapay Zeka (XAI), ısı haritaları, vekil modeller veya diğer çözümlerle yapay zekanın kara kutusunu anlaşılır, anlaşılır ve açıklanabilir hale getirmek - Resim: Xpert.Digital
Yapay zekanın (AI) "kara kutusu" olarak adlandırılan durum, önemli ve güncel bir sorunu temsil ediyor. Uzmanlar bile çoğu zaman yapay zeka sistemlerinin kararlarını nasıl aldıklarını tam olarak anlayamama sorunuyla karşı karşıya kalıyor. Bu şeffaflık eksikliği özellikle ekonomi, politika veya tıp gibi kritik alanlarda önemli sorunlara neden olabiliyor. Teşhis koymak ve tedavi önermek için yapay zeka sistemine güvenen bir doktor veya tıp uzmanının, alınan kararlara güven duyması gerekir. Ancak yapay zekanın karar alma mekanizması yeterince şeffaf değilse, insan hayatının tehlikede olabileceği durumlarda belirsizlik ve potansiyel olarak güven eksikliği ortaya çıkabilir.
Bununla ilgili daha fazla bilgiyi burada bulabilirsiniz:
Sizin için oradayız - tavsiye - planlama - uygulama - proje yönetimi
☑️ Strateji, danışmanlık, planlama ve uygulama konularında KOBİ desteği
☑️ Dijital stratejinin ve dijitalleşmenin oluşturulması veya yeniden düzenlenmesi
☑️ Uluslararası satış süreçlerinin genişletilmesi ve optimizasyonu
☑️ Küresel ve Dijital B2B ticaret platformları
☑️ Öncü İş Geliştirme

Konrad Wolfenstein
Kişisel danışmanınız olarak hizmet etmekten mutluluk duyarım.
Aşağıdaki iletişim formunu doldurarak benimle iletişime geçebilir veya +49 89 89 674 804 (Münih) .
Ortak projemizi sabırsızlıkla bekliyorum.
Bana yaz

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital, dijitalleşme, makine mühendisliği, lojistik/intralojistik ve fotovoltaik konularına odaklanan bir endüstri merkezidir.
360° iş geliştirme çözümümüzle, tanınmış firmalara yeni işlerden satış sonrasına kadar destek veriyoruz.
Pazar istihbaratı, pazarlama, pazarlama otomasyonu, içerik geliştirme, halkla ilişkiler, posta kampanyaları, kişiselleştirilmiş sosyal medya ve öncü yetiştirme dijital araçlarımızın bir parçasıdır.
Daha fazla bilgiyi şu adreste bulabilirsiniz: www.xpert.digital - www.xpert.solar - www.xpert.plus
İletişimi koparmamak


















