
Strukturerad data (markup) i AI-åldern med Schema.org: Vad Googles ingenjörer verkligen tycker
Xpert-förhandsversion

Available in 27 languages 📢
Föredra Xpert.Digital på GoogleⓘPublicerad den: 7 maj 2026 / Uppdaterad den: 7 maj 2026 – Författare: Konrad Wolfenstein
Strukturerad data (markup) i AI-åldern med Schema.org: Vad Googles ingenjörer verkligen tycker – Bild: Xpert.Digital
Googles SEO-hemlighet: Varför AI misslyckas utan strukturerad data
Trots ChatGPT & Co.: Varför Googles ingenjörer fortsätter att svärja på Schema.org
SEO-uppdatering: Varför Schema.org nu ersätter Open Graph på Google
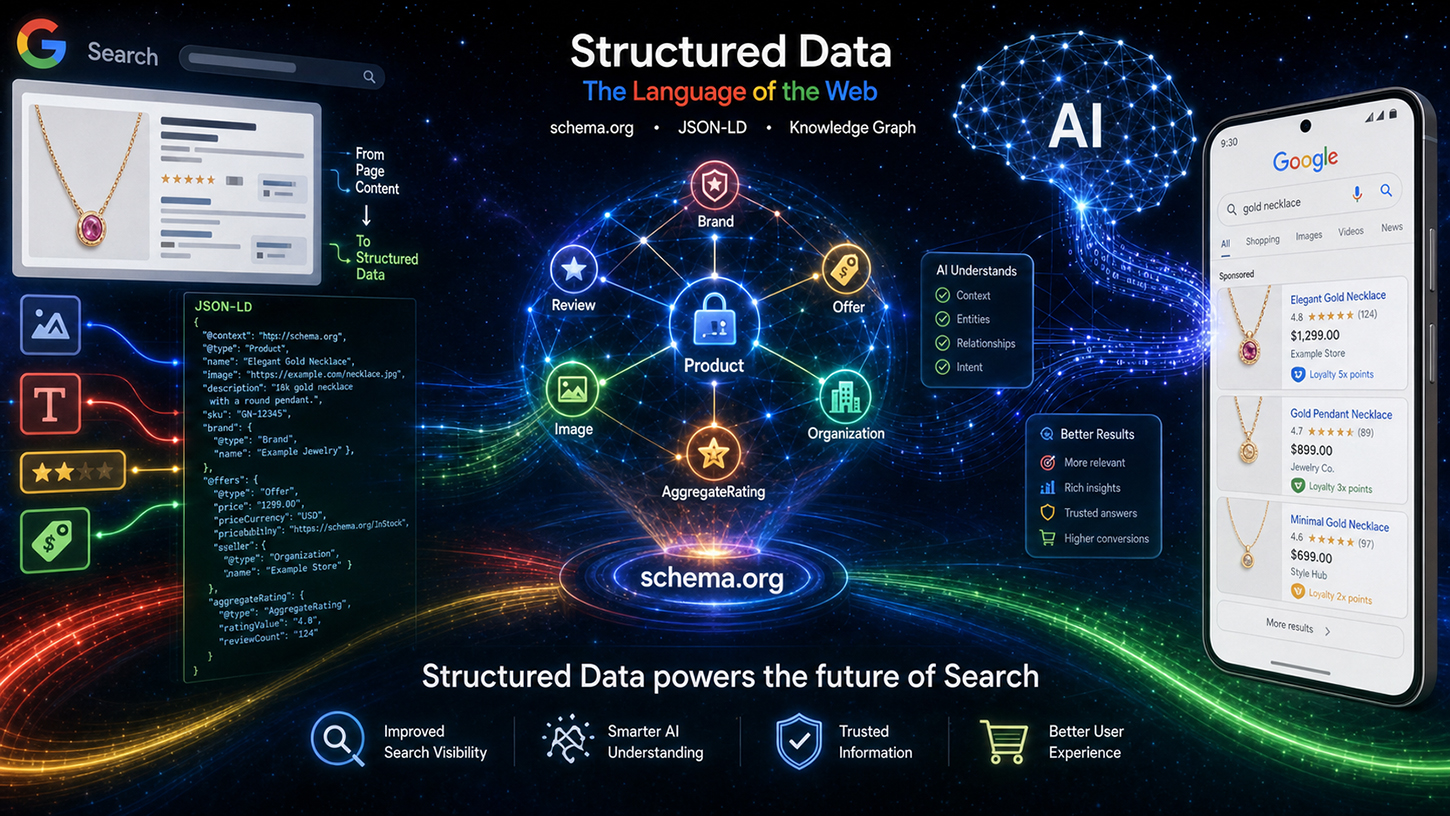
En ihållande myt cirkulerar i SEO-världen: I en tid av briljanta AI-språkmodeller som enkelt förstår även ostrukturerad text har noggrant underhållen strukturerad data som Schema.org helt enkelt blivit föråldrad. Men verkligheten är en helt annan. Vid Google Search Central Live-evenemanget avfärdade Google-ingenjören Ryan Levering denna missuppfattning och klargjorde det otvetydigt: Strukturerad markup är inte en kvarleva från det förflutna, utan snarare den grundläggande ryggraden i den nya AI-drivna sökningen.
Från nya AI-översikter till autonoma shoppingagenter behöver språkmodeller exakta, maskinläsbara riktlinjer för att undvika hallucinationer och för att fungera beräkningsmässigt effektivt. De som vill förbli synliga på den moderna webben måste hjälpa maskiner att förstå sammanhang utan tvetydighet. Den här artikeln undersöker Googles strategiska omställning, presenterar revolutionerande innovationer för e-handel och användargenererat innehåll och visar varför teknisk SEO nu är den avgörande konkurrensfördelen i kampen om maskinsynlighet.
Maskiner kan läsa webben – men bara om du hjälper dem att förstå den
Den 21 april 2026 ägde det första Google Search Central Live-evenemanget på kanadensisk mark rum i Toronto – och det var ingen vanlig branschträff. Ryan Levering, ingenjör på Google Search Engineering, höll vad som förmodligen var dagens mest tekniskt täta och strategiskt betydelsefulla presentation: ”Structured Data, Quality & AI”. Det han presenterade var mer än en teknisk granskning. Det var ett tydligt uttalande om den semantiska webbens framtid i en era där artificiell intelligens i allt högre grad tar på sig rollen som mellanhand mellan användare och information.
Mellan två ytterligheter: Fel antingen-eller
I början av sin presentation kontrasterade Ryan Levering två diametralt motsatta åsikter som cirkulerar inom SEO-communityn. Å ena sidan finns övertygelsen att strukturerad data helt enkelt är överflödig i en tid av kraftfulla språkmodeller: Om AI-modeller enkelt kan tolka ostrukturerad text, varför mödosamt lägga till schema.org-markup i källkoden? Å andra sidan sprider vissa entusiaster idén att strukturerad data är internets framtid – ett universellt semantiskt kommunikationsprotokoll mellan autonoma AI-agenter som till stor del kommer att ersätta den traditionella webben.
Levering förkastade båda ytterligheterna och presenterade istället ett nyanserat, empiriskt grundat perspektiv. Båda ståndpunkterna innehöll en kärna av sanning, drog han slutsatsen, men ingen av dem beskrev verkligheten fullt ut. Denna nyans är karakteristisk för Googles nuvarande syn på ämnet: det handlar inte om dogmer, utan om pragmatisk effektivitet.
Fyra argument som förklarar allt
Leverings centrala argument kan sammanfattas i fyra huvudpunkter, som han utvecklade under titeln "Värdet av strukturerad data". Den första punkten är precision: Strukturerad data ger betydligt högre noggrannhet för komplexa scheman som försäljningspriser eller lojalitetsprogram än LLM-baserad extrahering från fritext. Språkmodeller kan vara vilseledande – de fyller i saknade attribut, kapslar data felaktigt eller får tillgång till information ur sitt sammanhang. När man extraherar produktpriser från en stor e-handelswebbplats med dussintals liknande artiklar är felfrekvensen betydligt högre med AI-inferens än med rent implementerad, strukturerad markup.
Den andra punkten gäller ytterligare innehåll: Strukturerad data innehåller ofta osynliga metadata som helt enkelt inte finns i sidans renderade HTML. Kompletta ISO-datumformat, stabila identifierare för användargenererat innehåll eller interna enhets-ID:n – denna information finns exklusivt i markupen. Ingen språkmodell kan extrahera det som inte finns i texten.
För det tredje, effektivitet: Att analysera strukturerad markup är många gånger billigare än att bearbeta en stor språkmodell för att extrahera komplex data. Google indexerar miljarder sidor dagligen. Beräkningen är enkel: En vanlig parser som bearbetar JSON-LD förbrukar en bråkdel av beräkningsresurserna för ett LLM-inferenssteg. Strukturerad data är därför inte bara semantiskt överlägsen – den är också betydligt effektivare ur ett affärsperspektiv. Denna punkt är av direkt relevans för Googles infrastruktur.
Den fjärde, och kanske mest underskattade, aspekten är fokus: Strukturerad data markerar explicit vilken information som är relevant på en sida, vilket förhindrar AI-system från att plocka upp irrelevant data. På en produktsida med en huvudartikel, flera relaterade produkter och en navigeringsfält full av priser kan en språkmodell utan explicit annotering inte vara säker på vilket pris den ska referera till. Strukturerad markup löser detta problem genom entydig tilldelning.
Hur strukturerad data faktiskt bearbetas
Levering gjorde också det tekniska bearbetningsflödet transparent. Schema.org-data bearbetas först genom specifik rengöring och filtrering innan de kategoriseras som indexerad data – uppdelad i områden som evenemang, shopping och recensioner. Denna förberedda data flödar sedan in i två olika utdatakanaler: å ena sidan den klassiska sökresultatsidan (SRP), och å andra sidan som kontext för Googles AI-baserade system, specifikt de så kallade AI-översikterna (AIO) och AI-läget (AIM). Strukturerad data är således inte längre bara ett verktyg för avancerade resultat, utan direkt input för generativa AI-svar. Detta representerar ett fundamentalt skifte i den strategiska betydelsen av schema.org-markup.
🎯🎯🎯 Datadriven B2B-branschhubb som en kvasi-intern lösning

Den kvasi-interna lösningen: Hur Xpert.Digital stänger operativa luckor inom B2B-marknadsföring och -försäljning – Smart Content-Driven Business - Bild: Xpert.Digital
Xpert.Digital är en datadriven B2B-branschhubb som leds av Konrad Wolfenstein . Företaget fungerar som en extern, nästan intern lösning för industriella partners och täcker operativa luckor inom marknadsföring, innehåll och försäljning – utan att kräva ytterligare resurser från kundsidan.
Mer information här:
Varför strukturerad data håller på att bli infrastrukturen för AI-agenter
Shopping i fokus: Frakt, lojalitet och variationer
En betydande del av presentationen fokuserade på innovationer inom e-handel. Levering förklarade att, enligt data från Baymard Institute, rankas oväntad leveransinformation som nummer två och tre bland de vanligaste orsakerna till att kundvagnar överges. Strukturerad uppmärkning för leveranstjänster kan direkt åtgärda detta problem: Handlare kan nu exakt definiera ursprungs- och destinationsregioner, dimensioner och vikter, tröskelvärden för ordervärden, behandlingstider och lojalitetsprogramsanslutningar direkt i koden.
Leveranstidsmodellen som Google använder är indelad i två faser: hanteringstiden, dvs. tiden från ordermottagande till överlämning till transportören, och den faktiska leveranstiden. Båda faserna kan kommenteras separat och med hög granularitet – ner till orderstopptider och om bearbetning även sker på vardagar. Motsvarande JSON-LD-exempel visar hur typen `ShippingConditions` kan användas för att definiera fri frakt för vissa länder (t.ex. Frankrike och Tyskland) och lägsta ordervärden (t.ex. 50 €).
Integreringen av frakttjänster med lojalitetsprogram är särskilt innovativ. Med hjälp av egenskapen `validForMemberTier` kan en frakttjänst explicit länkas till ett medlemskapsprogram och en specifik nivå. Detta gör det möjligt att deklarera fraktförmåner för premiummedlemmar direkt i uppmärkningen – en funktion som tidigare endast kunde konfigureras via Google Merchant Center. Det associerade lojalitetsprogrammet i sig definieras som ett `MemberProgram`-objekt under entiteten `Organization`, med nivåer som "Guld" eller "Silver" och tillhörande förmåner som lojalitetsbelöningar eller poängbelöningar.
Lojalitetsprogram som semantiska enheter
Införandet av lojalitetsprogramspåslag är ekonomiskt betydelsefullt. Organisationer kan definiera flera oberoende medlemsprogram, vart och ett med flera nivåer och differentierade förmåner – poäng, medlemspriser, returpolicyer, fraktbonusar. Denna information visas sedan direkt i Googles sökresultat, vilket Levering demonstrerade med verkliga exempel, inklusive ett Sephora-erbjudande som visade 30 procents medlemsrabatt direkt i shoppingkodavsnittet. Cross-page ID-länkning, möjligheten att länka till lojalitetsprogramdefinitioner från andra sidor, är, enligt Levering, nästa planerade steg, för närvarande med titeln "Blazing the path for cross-page @id linkage". Målet: starkare organisatoriska referenser mellan produktsidor och företagspolicyer.
Användargenererat innehåll: Problemet med AI-märkning
Ett annat viktigt ämne var vidareutvecklingen av schematyper för användargenererat innehåll (UGC). Två nya funktioner är särskilt relevanta här. För det första stöds inbäddade inlägg och reposts i forum- och Q&A-markup, vilket möjliggör en mer exakt semantisk representation av diskussionsstrukturer. För det andra – och detta är av ännu större strategisk betydelse – introduceras egenskapen `so#digitalSourceType` för att explicit identifiera maskingenererat innehåll.
Denna utveckling är ett direkt svar på floden av AI-genererat innehåll på plattformar som forum och frågestunder. Webbansvariga kan nu deklarera om ett inlägg genererades algoritmiskt eller av en språkmodell. De som inte specificerar detta antas implicit av Google vara mänskliga författare – en regel som stimulerar transparent märkning. Egenskapen `digitalSourceType` är baserad på IPTC-koder för digitala källor och skiljer bland annat mellan algoritmiskt genererat och modellgenererat innehåll.
Bildval: Schema slår Open Graph
En mindre uppmärksammad men praktiskt effektiv uppdatering gäller Googles logik för bildval. Systemet konsolideras internt med en tydlig prioriteringshierarki: Schema.org-kod, specifikt egenskaperna `primaryImageOfPage` och `mainEntity → image`, prioriteras. Först därefter följer metataggen `og:image` från Open Graph. Denna förändring innebär att för webbplatsoperatörer påverkar en ren schema.org-implementering av huvudbilden direkt dess visning i Googles sökresultat och AI-översikter – en konkret, mätbar fördel.
Schema.org får själva investeringar
Det är också anmärkningsvärt att Google aviserar om återinvestering i schema.org som en öppen specifikation. Tre konkreta åtgärder nämndes: publicering av statistik om användningsfrekvensen för enskilda schematermer (prevalensdata, som en bildvisning visar, finns redan tillgänglig för enskilda termer som "digitalSourceType" med information om cirka 10 000 domäner), publicering av Googles egna valideringsregler i maskinläsbara standardformat som SHACL eller ShEx, och förbättrat stöd för ordningsregler. Detta är viktigt eftersom det skulle göra det möjligt för externa utvecklare att bygga sina egna valideringsverktyg baserade på Googles standarder – oberoende av de officiella testverktygen, som ibland kraschar under belastning.
Validering: Två verktyg, ett mål
Levering presenterade två valideringsverktyg som kompletterar varandra men tillämpar olika testkriterier. Rich Result Test Tool på `search.google.com/test/rich-results` accepterar URL:er eller ren JSON och kontrollerar om markupen är lämplig för Googles sökresultat – den är därför baserad på Googles specifika krav, inte på själva schema.org-standarden. `Validator.schema.org`, å andra sidan, kontrollerar om markupen är schema.org-kompatibel, d.v.s. följer den öppna vokabulären, oavsett om Google genererar rich results från den. Detta leder till en tydlig rekommendation för webbutvecklare: båda verktygen bör användas, eftersom markup kan vara schemakompatibel men inte rich-result-kapabel – och vice versa.
Den större bilden: Strukturerad data som AI-infrastruktur
Om man tittar på Toronto-evenemanget som helhet är ett skifte uppenbart som sträcker sig långt bortom traditionell SEO-optimering. Strukturerad data utvecklas från ett verktyg för att uppnå rich snippets till en grundläggande datalagerstandard för AI-system. Googles AI Overviews och AI Mode använder aktivt schema.org-markup som kontext för svarsgenerering och entitetsverifiering. De som implementerar korrekt, fullständig och precis strukturerad data förbättrar inte bara sina chanser att uppnå visuella höjdpunkter i sökresultaten – de positionerar sitt innehåll som en pålitlig primärkälla för AI-svar.
Att Universal Commerce Protocol (UCP) och WebMCP nämns i detta sammanhang är ingen slump. Båda agentbaserade kommunikationsstandarderna, som Google släppte i tidiga versioner 2026, kräver att webbplatser beskrivs semantiskt. Schema.org utgör grunden för detta. I en värld där AI-agenter agerar autonomt på webben, söker, jämför och initierar transaktioner, är maskinläsbarhet av innehåll inte längre valfritt, utan en förutsättning för ekonomisk relevans. Ryan Leverings presentation i Toronto var därför inte bara en teknisk uppdateringsrapport – det var en glimt av infrastrukturen för nästa webb.
Du kan ta reda på det själv på 10 sekunder
Om du vill veta hur väl och omfattande din eller en annan webbplats använder strukturerad data kan du använda just de två verktyg som Ryan Levering från Google (från vår text ovan) rekommenderade:
Google Rich Results Test (fokus på synlighet på Google):
Gå till search.google.com/test/rich-results, kopiera URL:en till valfri xpert.digital-artikel och klicka på "Testa URL". Verktyget visar exakt vilka markeringar Google känner igen på den sidan och om de är felfria.
Schemavalidator (fokus på ren standardefterlevnad):
Gå till validator.schema.orgoch klistra in samma URL. Här kan du se direkt i källkoden, markerat med färg, vilka JSON-LD-skript (strukturerad data) som xpert.digital har införlivat.
Din globala partner för marknadsföring och affärsutveckling
☑️ Vårt affärsspråk är engelska eller tyska
☑️ NYTT: Korrespondens på ditt modersmål!

Konrad Wolfenstein
Jag och mitt team står gärna till er förfogande som er personliga rådgivare.
Du kan kontakta mig genom att fylla i kontaktformuläret här helt enkelt ringa mig på +49 7348 4088 965. Min e-postadress är [email protected]:eller
Jag ser fram emot vårt gemensamma projekt.
☑️ Stöd till små och medelstora företag inom strategi, konsultation, planering och implementering
☑️ Skapande eller omstrukturering av den digitala strategin och digitaliseringen
☑️ Utökning och optimering av internationella säljprocesser
☑️ Globala och digitala B2B-handelsplattformar
☑️ Pionjär inom affärsutveckling / marknadsföring / PR / mässor
B2B-support och SaaS för SEO och GEO (AI-sökning) kombinerat: Allt-i-ett-lösningen för B2B-företag

B2B-support och SaaS för SEO och GEO (AI-sökning) kombinerat: Allt-i-ett-lösningen för B2B-företag - Bild: Xpert.Digital
AI-sökning förändrar allt: Hur denna SaaS-lösning kommer att revolutionera din B2B-ranking för alltid.
Det digitala landskapet för B2B-företag genomgår snabba förändringar. Drivet av artificiell intelligens skrivs reglerna för synlighet online om. För företag har det alltid varit en utmaning att inte bara synas i den digitala massan, utan också att vara relevant för rätt beslutsfattare. Traditionella SEO-strategier och hantering av lokal närvaro (geo-marketing) är komplexa, tidskrävande och ofta en kamp mot ständigt föränderliga algoritmer och intensiv konkurrens.
Men tänk om det fanns en lösning som inte bara förenklade den här processen utan också gjorde den smartare, mer prediktiv och betydligt mer effektiv? Det är här kombinationen av specialiserad B2B-support med en kraftfull SaaS-plattform (Software as a Service) kommer in i bilden, specifikt utformad för SEO och GEO:s krav i AI-sökningens tidsålder.
Denna nya generation verktyg förlitar sig inte längre enbart på manuell sökordsanalys och backlänkstrategier. Istället utnyttjar den artificiell intelligens för att mer exakt förstå sökintentioner, automatiskt optimera lokala rankningsfaktorer och genomföra konkurrensanalyser i realtid. Resultatet är en proaktiv, datadriven strategi som ger B2B-företag en avgörande fördel: de blir inte bara hittade, utan uppfattade som den ledande auktoriteten inom sin nisch och plats.
Här är symbiosen mellan B2B-support och AI-driven SaaS-teknik som transformerar SEO- och GEO-marknadsföring, och hur ditt företag kan dra nytta av den för att växa hållbart i den digitala världen.
Mer information här:
















