


Den nya digitala synligheten – En avkodning av SEO, LLMO, GEO, AIO och AEO – SEO ensamt räcker inte längre – Bild: Xpert.Digital
En strategisk guide till generativ motoroptimering (GEO) och storspråksmodelloptimering (LLMO) (Lästid: 30 min / Inga annonser / Ingen betalvägg)
Paradigmskiftet: Från sökmotoroptimering till generativ motoroptimering
Omdefiniera digital synlighet i AI-åldern
Det digitala informationslandskapet genomgår för närvarande sin mest djupgående omvandling sedan introduktionen av grafisk webbsökning. Den traditionella mekanismen, där sökmotorer presenterar en lista med potentiella svar i form av blå länkar och låter användaren sålla igenom, jämföra och syntetisera relevant information, ersätts i allt högre grad av ett nytt paradigm. Detta ersätts av en "fråga-och-ta-mot"-modell som drivs av generativa AI-system. Dessa system utför syntesarbetet åt användaren och levererar ett direkt, kurerat och naturligt språkligt svar på en ställd fråga.
Denna grundläggande förändring har långtgående konsekvenser för definitionen av digital synlighet. Framgång innebär inte längre bara att synas på första sökresultatsidan; den definieras i allt högre grad som en integrerad del av det AI-genererade svaret – vare sig det är en direkt citerad källa, ett nämnt varumärke eller grunden för den syntetiserade informationen. Denna utveckling accelererar den befintliga trenden mot "nollklicksökningar", där användare tillgodoser sina informationsbehov direkt på sökresultatsidan utan att behöva besöka en webbplats. Det är därför viktigt för företag och innehållsskapare att förstå de nya spelreglerna och anpassa sina strategier därefter.
Relaterat till detta:


Optimeringens nya vokabulär: En avkodning av SEO, LLMO, GEO, AIO och AEO
Med tillkomsten av dessa nya teknologier har ett komplext och ofta förvirrande ordförråd utvecklats. En tydlig definition av dessa termer är avgörande för en riktad strategi.
SEO (sökmotoroptimering): Detta är den etablerade, grundläggande disciplinen för att optimera webbinnehåll för traditionella sökmotorer som Google och Bing. Huvudmålet är att uppnå höga rankningar i traditionella, länkbaserade sökmotorresultatsidor (SERP). SEO är fortfarande avgörande även i AI:s tidsålder, eftersom det utgör grunden för all ytterligare optimering.
LLMO (Large Language Model Optimization): Denna exakta tekniska term beskriver optimering av innehåll specifikt så att det effektivt kan förstås, bearbetas och citeras av textbaserade stora språkmodeller (LLM) som OpenAI:s ChatGPT eller Googles Gemini. Målet är inte längre rankning, utan snarare inkludering som en trovärdig källa i de AI-genererade svaren.
GEO (Generativ motoroptimering): En något bredare term, ofta använd synonymt med LLMO. GEO fokuserar på att optimera hela det generativa systemet eller "motorn" (t.ex. Perplexity, Google AI Overviews) som genererar ett svar, snarare än bara själva språkmodellen. Det handlar om att säkerställa att ett varumärkes budskap representeras och sprids korrekt över dessa nya kanaler.
AIO (AI-optimering): Detta är ett paraplybegrepp med flera betydelser, vilket kan leda till förvirring. I samband med innehållsoptimering hänvisar AIO till den allmänna strategin för att anpassa innehåll för alla typer av AI-system. Termen kan dock också hänvisa till teknisk optimering av själva AI-modellerna eller till användningen av AI för att automatisera affärsprocesser. Denna tvetydighet gör det mindre precist för en specifik innehållsstrategi.
AEO (Answer Engine Optimization): Ett specialiserat delområde inom GEO/LLMO som fokuserar på att optimera för direkta svarsfunktioner inom söksystem, såsom de som finns i Googles AI-översikter.
I denna rapport används GEO och LLMO som de primära termerna för de nya strategierna för innehållsoptimering, eftersom de bäst beskriver fenomenet och i allt högre grad blir branschstandard.
Varför traditionell SEO är grundläggande, men inte längre tillräckligt
En vanlig missuppfattning är att de nya optimeringsdisciplinerna kommer att ersätta SEO. Faktum är att LLMO och GEO kompletterar och utökar traditionell sökmotoroptimering. Relationen är symbiotisk: utan en solid SEO-grund är effektiv optimering för generativ AI knappast möjlig.
SEO som grund: Kärnaspekter av teknisk SEO – som snabba laddningstider, tydlig webbplatsarkitektur och säkerställande av genomsökningsbarhet – är absolut nödvändiga för att AI-system ens ska kunna hitta, läsa och bearbeta en webbplats. Likaså är etablerade kvalitetssignaler som högkvalitativt innehåll och tematiskt relevanta bakåtlänkar avgörande för att betraktas som en pålitlig källa.
RAG-kopplingen: Många generativa sökmotorer använder en teknik som kallas Retrieval-Augmented Generation (RAG) för att berika sina svar med aktuell information från webben. De använder ofta de översta resultaten från traditionella sökmotorer. En hög ranking i traditionell sökning ökar därmed direkt sannolikheten för att en AI ska använda den som källa för ett genererat svar.
SEO-gapet: Trots sin grundläggande betydelse är SEO inte längre tillräckligt. En topplacering är inte längre en garanti för synlighet eller trafik, eftersom det AI-genererade svaret ofta överskuggar traditionella resultat och direkt besvarar användarfrågan. Det nya målet är att adressera och syntetisera relevant information i detta AI-genererade svar. Detta kräver ett ytterligare optimeringslager med fokus på maskinläsbarhet, kontextuellt djup och påvisbar auktoritet – aspekter som går utöver traditionell sökordsoptimering.
Fragmenteringen av terminologi är mer än en semantisk debatt; det är ett symptom på ett paradigmskifte i dess tidiga skeden. De olika akronymerna återspeglar olika perspektiv som kämpar för att definiera det nya området – från ett tekniskt perspektiv (AIO, LLMO) till ett marknadsföringsdrivet (GEO, AEO). Denna tvetydighet och avsaknaden av en etablerad standard skapar ett strategiskt fönster av möjligheter. Medan större, mer isolerade organisationer fortfarande debatterar terminologi och strategi, kan mer flexibla företag anta kärnprinciperna för maskinläsbart, auktoritativt innehåll och säkra en betydande fördel som först. Den nuvarande osäkerheten är inte ett hinder, utan en möjlighet.
Jämförelse av optimeringsdiscipliner
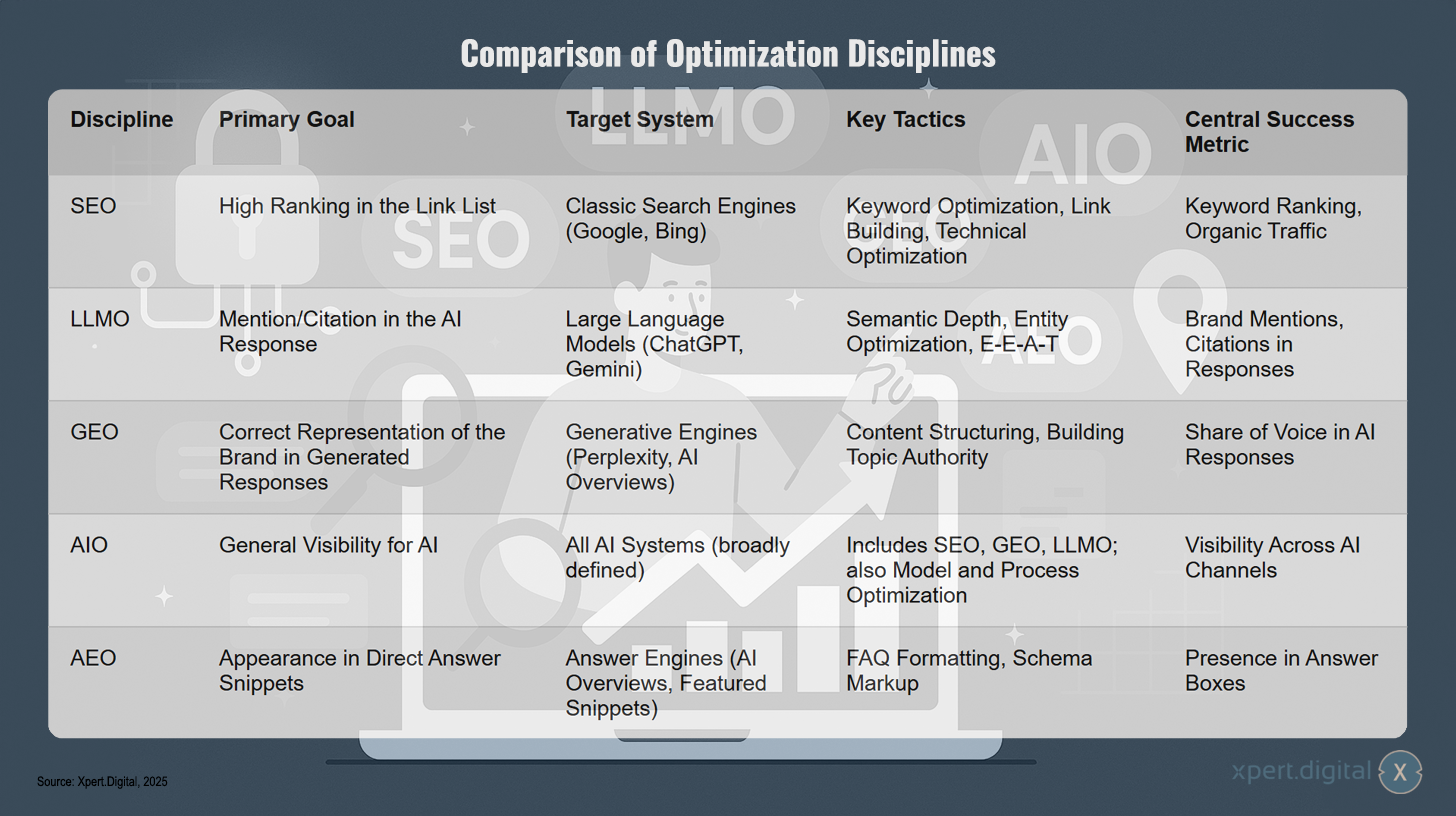
Jämförelse av optimeringsdiscipliner – Bild: Xpert.Digital
De olika optimeringsdisciplinerna strävar efter olika mål och strategier. SEO fokuserar på att uppnå höga rankningar i traditionella sökmotorer som Google och Bing genom sökordsoptimering, länkbyggande och tekniska förbättringar, med framgång mätt i sökordsrankningar och organisk trafik. LLMO, å andra sidan, syftar till att bli omnämnd eller citerad i AI-svar från stora språkmodeller som ChatGPT eller Gemini genom att använda semantiskt djup, entitetsoptimering och EEAT-faktorer – framgång återspeglas i varumärkesomnämnanden och citat. GEO strävar efter korrekt representation av varumärket i svar som genereras av motorer som Perplexity eller AI Overviews, och prioriterar innehållsstrukturering och byggande av ämnesauktoritet, där röstdelning i AI-svar fungerar som ett mått på framgång. AIO strävar efter det mest omfattande målet: generell synlighet över alla AI-system. Det kombinerar SEO, GEO och LLMO med ytterligare modell- och processoptimering, mätt i synlighet över olika AI-kanaler. AEO fokuserar slutligen på att synas i direkta svarsutdrag från svarsmotorer genom FAQ-formatering och schemamarkering, där närvaro i svarsrutor definierar framgång.
Maskinrummet: Insikter i tekniken bakom AI-sökning
För att effektivt optimera innehåll för AI-system är en grundläggande förståelse för de underliggande teknologierna avgörande. Dessa system är inte magiska svarta lådor, utan är baserade på specifika tekniska principer som avgör deras funktionalitet och därmed kraven för det innehåll som ska bearbetas.
Stora språkmodeller (LLM): Kärnmekaniken
Generativ AI fokuserar på stora språkmodeller (LLM).
- Förträning med massiva datamängder: Jurister tränas på enorma textdatamängder från källor som Wikipedia, hela det offentligt tillgängliga internet (t.ex. via Common Crawl-datasetet) och digitala boksamlingar. Genom att analysera biljoner ord lär sig dessa modeller statistiska mönster, grammatiska strukturer, faktakunskap och semantiska relationer inom mänskligt språk.
- Problemet med kunskapsgränsen: En avgörande begränsning för juridiklärare är att deras kunskap är fryst på nivån av träningsdata. De har ett så kallat "kunskapsgränsdatum" och kan inte komma åt information som skapats efter det datumet. En juridiklärare som utbildats fram till 2023 vet inte vad som hände igår. Detta är det grundläggande problemet som behöver lösas för sökapplikationer.
- Tokenisering och probabilistisk generering: LLM:er bearbetar inte text ord för ord, utan bryter ner den i mindre enheter som kallas "tokens". Deras kärnfunktion är att förutsäga den mest sannolika nästa token baserat på det befintliga sammanhanget, och därmed sekventiellt generera en sammanhängande text. De är mycket sofistikerade statistiska mönsterigenkännare och har inte mänsklig medvetenhet eller förståelse.
Retrieval-Augmented Generation (RAG): Bryggan till den levande webben
Retrieval-Augmented Generation (RAG) är den viktigaste tekniken som gör det möjligt för juridiska lärare att fungera som moderna sökmotorer. Den överbryggar klyftan mellan den statiska, förtränade kunskapen om modellen och den dynamiska informationen på internet.
RAG-processen kan delas in i fyra steg:
- Fråga: En användare ställer en fråga till systemet.
- Hämtning: Istället för att svara omedelbart aktiverar systemet en "hämtningskomponent". Denna komponent, ofta en semantisk sökmotor, söker i en extern kunskapsbas – vanligtvis indexet för en större sökmotor som Google eller Bing – efter dokument som är relevanta för frågan. Det är här vikten av höga traditionella SEO-rankningar blir uppenbar: Innehåll som rankas bra i klassiska sökresultat har större sannolikhet att hittas av RAG-systemet och väljas ut som en potentiell källa.
- Utökning: Den mest relevanta informationen från de hämtade dokumenten extraheras och läggs till i den ursprungliga användarförfrågan som ytterligare kontext. Detta skapar en "berikad prompt".
- Generering: Denna berikade prompt vidarebefordras till LLM. Modellen genererar nu sitt svar, som inte längre enbart baseras på dess föråldrade utbildningskunskap, utan på aktuella, hämtade fakta.
Denna process minskar risken för ”hallucinationer” (att hitta på fakta), möjliggör källhänvisning och säkerställer att svaren är mer aktuella och faktamässigt korrekta.
Semantisk sökning och vektorinbäddningar: AI:s språk
För att förstå hur "Retrieval"-steget fungerar i RAG måste man förstå konceptet semantisk sökning.
- Från nyckelord till betydelse: Traditionell sökning baseras på matchande nyckelord. Semantisk sökning, å andra sidan, syftar till att förstå avsikten och sammanhanget för en sökfråga. Till exempel kan en sökning efter "varma vinterhandskar" också returnera resultat för "ullvantar" eftersom systemet känner igen det semantiska förhållandet mellan begreppen.
- Vektorinbäddningar som kärnmekanism: Den tekniska grunden för detta är vektorinbäddningar. En speciell "inbäddningsmodell" omvandlar textenheter (ord, meningar, hela dokument) till en numerisk representation – en vektor i ett högdimensionellt rum.
- Spatial närhet som semantisk likhet: I detta vektorrum representeras semantiskt liknande begrepp som punkter belägna nära varandra. Vektorn som representerar "kung" har ett liknande förhållande till vektorn för "drottning" som vektorn för "man" har till vektorn för "kvinna".
- Tillämpning i RAG-processen: En användares förfrågan konverteras också till en vektor. RAG-systemet söker sedan i sin vektordatabas för att hitta de dokumentvektorer som är närmast förfrågningsvektorn. På så sätt hämtas den mest semantiskt relevanta informationen för att berika prompten.
Tankemodeller och tankeprocesser: Nästa steg i evolutionen
I framkant av LLM-utvecklingen finns så kallade kognitiva modeller som lovar en ännu mer avancerad form av informationsbehandling.
- Utöver enkla svar: Medan vanliga LLM-modeller genererar ett svar i ett enda steg, bryter tankemodeller ner komplexa problem i en serie logiska mellansteg, en så kallad "tankekedja".
- Så här fungerar det: Dessa modeller tränas genom förstärkningsinlärning, där framgångsrika lösningar i flera steg belönas. De "tänker i huvudsak högt" internt, formulerar och förkastar olika tillvägagångssätt innan de kommer fram till ett slutgiltigt, ofta mer robust och korrekt svar.
- Implikationer för optimering: Även om denna teknik fortfarande är i sin linda, tyder den på att framtida sökmotorer kommer att kunna hantera betydligt mer komplexa och mångfacetterade sökfrågor. Innehåll som erbjuder tydliga, logiska steg-för-steg-instruktioner, detaljerade processbeskrivningar eller välstrukturerade resonemang är idealiskt positionerat för att användas av dessa avancerade modeller som en högkvalitativ informationskälla.
Den tekniska arkitekturen för moderna AI-sökningar – en kombination av LLM, RAG och semantisk sökning – skapar en kraftfull, självförstärkande återkopplingsslinga mellan den "gamla webben" av rankade sidor och den "nya webben" av AI-genererade svar. Högkvalitativt, auktoritativt innehåll som presterar bra i traditionell SEO indexeras och rankas tydligt. Denna höga ranking gör det till en utmärkt kandidat för hämtning av RAG-system. När en AI citerar detta innehåll stärker det ytterligare dess auktoritet, vilket kan leda till ökat användarengagemang, fler bakåtlänkar och i slutändan ännu starkare traditionella SEO-signaler. Detta skapar en "god cirkel av auktoritet". Omvänt ignoreras innehåll av låg kvalitet av både traditionella sök- och RAG-system och blir alltmer osynligt. Klyftan mellan digitala "haves" och "have-not" kommer därmed att vidgas exponentiellt. Den strategiska implikationen är att investeringar i grundläggande SEO och att bygga innehållsauktoritet inte längre enbart fokuserar på ranking; de säkrar en permanent plats vid bordet för den AI-drivna framtiden för informationssyntes.
🎯🎯🎯 Dra nytta av Xpert.Digitals omfattande, femfaldiga expertis i ett heltäckande tjänstepaket | BD, R&D, XR, PR och optimering av digital synlighet

Dra nytta av Xpert.Digitals omfattande, femfaldiga expertis i ett heltäckande tjänstepaket | FoU, XR, PR och optimering av digital synlighet - Bild: Xpert.Digital
Xpert.Digital besitter djupgående kunskap inom olika branscher. Detta gör det möjligt för oss att utveckla skräddarsydda strategier som är exakt anpassade till kraven och utmaningarna inom just ditt marknadssegment. Genom att kontinuerligt analysera marknadstrender och övervaka branschutvecklingen kan vi agera proaktivt och erbjuda innovativa lösningar. Kombinationen av erfarenhet och expertis genererar mervärde och ger våra kunder en avgörande konkurrensfördel.
Mer information här:
Bygga digital auktoritet: Varför traditionell SEO inte längre är tillräckligt för AI-drivna sökmotorer
De tre pelarna inom generativ motoroptimering
Den tekniska förståelsen från del I utgör grunden för ett konkret och handlingsbart strategiskt ramverk. För att lyckas i den nya eran av AI-sökning måste optimeringsinsatser vila på tre centrala pelare: strategiskt innehåll för maskinförståelse, avancerad teknisk optimering för AI-crawlers och proaktiv hantering av digital auktoritet.
Relaterat till detta:


Pelare 1: Strategiskt innehåll för maskinförståelse
Sättet som innehåll skapas och struktureras på behöver förändras fundamentalt. Målet är inte längre bara att övertyga en mänsklig läsare, utan också att förse en maskin med bästa möjliga grund för att extrahera och syntetisera information.
Ämnesauktoritet som en ny gräns
Fokus för innehållsstrategin flyttas från att optimera enskilda sökord till att bygga omfattande ämnesauktoritet.
- Bygga kunskapscentra: Istället för att skapa isolerade artiklar för enskilda nyckelord är målet att skapa holistiska "ämneskluster". Dessa består av en central, omfattande "pelarinnehållsartikel" som täcker ett brett ämne och ett flertal länkade underartiklar som tar upp specifika nischaspekter och detaljerade frågor. En sådan struktur signalerar till AI-system att en webbplats är en auktoritativ och uttömmande källa för ett visst ämnesområde.
- Omfattande täckning: Jurister bearbetar information inom semantiska sammanhang. En webbplats som täcker ett ämne på ett heltäckande sätt – inklusive alla relevanta aspekter, användarfrågor och relaterade koncept – ökar sannolikheten för att den används av en AI som primärkälla. Systemet hittar all nödvändig information på ett ställe och behöver inte pussla ihop den från flera, mindre omfattande källor.
- Praktisk tillämpning: Nyckelordsanalys används inte längre för att hitta enskilda söktermer, utan för att kartlägga hela universumet av frågor, delaspekter och relaterade ämnen som tillhör ett kärnkompetensområde.
EEAT som en algoritmisk signal
Googles EEAT-koncept (Experience, Expertise, Authoritativeness, Trustworthiness) utvecklas från en ren riktlinje för mänskliga kvalitetsbedömare till en uppsättning maskinläsbara signaler som används för att utvärdera innehållskällor.
Bygga förtroende strategiskt: Företag måste aktivt implementera och synliggöra dessa signaler på sina webbplatser:
- Erfarenhet och expertis: Författare måste vara tydligt identifierade, helst med detaljerade biografier som visar deras kvalifikationer och praktiska erfarenhet. Innehållet bör erbjuda unika insikter från verkligheten som går utöver ren faktakunskap.
- Auktoritet (Auktoritativitet): Att bygga kontextuellt relevanta bakåtlänkar från andra välrenommerade webbplatser är fortfarande viktigt. Men omnämnanden av olänkade varumärken i auktoritativa källor blir också allt viktigare.
- Trovärdighet: Tydlig och lättillgänglig kontaktinformation, hänvisning till trovärdiga källor, publicering av originaldata eller studier samt regelbunden uppdatering och korrigering av innehåll är viktiga förtroendesignaler.
Entitetsbaserad innehållsstrategi: Optimera för saker, inte strängar
Moderna sökmotorer baserar sin förståelse av världen på en "kunskapsgraf". Denna graf består inte av ord, utan av verkliga enheter (personer, platser, varumärken, koncept) och relationerna mellan dem.
- Att lyfta ditt varumärke till en enhet: Det strategiska målet är att etablera ditt varumärke som en tydligt definierad och igenkänd enhet inom detta diagram, en som otvetydigt är associerad med ett specifikt område. Detta uppnås genom konsekvent namngivning, användning av strukturerad data (se avsnitt 4) och frekvent samtidig förekomst med andra relevanta enheter.
- Praktisk tillämpning: Innehållet bör struktureras kring tydligt definierade entiteter. Viktiga tekniska termer kan förklaras i ordlistor eller definitionsrutor. Att länka till erkända entitetskällor som Wikipedia eller Wikidata kan hjälpa Google att skapa korrekta kopplingar och befästa den tematiska klassificeringen.
Konsten att skapa ett snippet: strukturera innehåll för direkt extraktion
Innehåll måste formateras på ett sådant sätt att maskiner enkelt kan demontera och återanvända det.
- Optimering på avsnittsnivå: AI-system extraherar ofta inte hela artiklar, utan snarare individuella, perfekt formulerade "bitar" eller avsnitt – ett stycke, ett listobjekt, en tabellrad – för att besvara en specifik del av en fråga. En webbplats bör därför utformas som en samling av sådana mycket extraherbara informationsutdrag.
- Strukturella bästa praxis:
- Svar först: Stycken bör inledas med ett koncist, direkt svar på en implicit fråga, följt av förklarande detaljer.
- Användning av listor och tabeller: Komplex information bör presenteras i uppräkningar, numrerade listor och tabeller, eftersom dessa format är särskilt enkla för AI-system att analysera.
- Strategisk användning av rubriker: Tydliga, beskrivande H2- och H3-rubriker, ofta formulerade som frågor, bör logiskt strukturera innehållet. Varje avsnitt bör fokusera på en enda, fokuserad idé.
- FAQ-sektioner: Vanliga frågor (FAQ) är idealiska eftersom de direkt återspeglar det konversationsformat med frågor och svar som används i AI-chattar.
Multimodalitet och naturligt språk
- Konversationston: Innehållet bör skrivas i en naturlig, mänsklig stil. AI-modeller tränas på autentiskt, mänskligt språk och föredrar texter som läses som en riktig konversation.
- Optimering av visuellt innehåll: Modern AI kan även bearbeta visuell information. Bilder behöver därför meningsfull alt-text och bildtexter. Videor bör åtföljas av transkriptioner. Detta gör multimedieinnehåll indexerbart och citerbart för AI.
Konvergensen av dessa innehållsstrategier – ämnesauktoritet, EEAT, entitetsoptimering och strukturering av snippets – leder till en djupgående insikt: det mest effektiva innehållet för AI är samtidigt det mest hjälpsamma, tydligaste och mest pålitliga innehållet för människor. Eran av att "skriva för algoritmen", som ofta resulterade i onaturligt klingande texter, närmar sig sitt slut. Den nya algoritmen kräver människocentrerade bästa praxis. Den strategiska implikationen är att investeringar i genuin expertis, högkvalitativt skrivande, tydlig informationsdesign och transparenta källhänvisningar inte längre bara är "god praxis" – det är den mest direkta och hållbara formen av teknisk optimering för den generativa tidsåldern.
Pelare 2: Avancerad teknisk optimering för AI-crawlers
Medan strategiskt innehåll definierar "vad" i optimering, säkerställer teknisk optimering "hur" – det garanterar att AI-system kan komma åt, tolka och bearbeta detta innehåll korrekt. Utan en solid teknisk grund förblir även det bästa innehållet osynligt.
Teknisk SEO omprövad: Den fortsatta betydelsen av Core Vitals
Grunderna i teknisk sökmotoroptimering är inte bara relevanta för GEO, utan blir ännu viktigare.
- Genomsökningsbarhet och indexerbarhet: Detta är helt grundläggande. Om en AI-crawler – vare sig det är den välkända Googlebot eller specialiserade bottar som ClaudeBot och GPTBot – inte kan komma åt eller rendera en sida, existerar den inte för AI-systemet. Det måste säkerställas att relevanta sidor returnerar HTTP-statuskoden 200 och inte (oavsiktligt) blockeras av robots.txt-filen.
- Sidhastighet och renderingstidsgränser: AI-crawlers arbetar ofta med mycket korta renderingsfönster för en sida, ibland bara 1–5 sekunder. Långsamt laddande sidor, särskilt de med högt JavaScript-innehåll, riskerar att hoppas över eller bara delvis bearbetas. Att optimera Core Web Vitals och den totala sidhastigheten är därför avgörande.
- JavaScript-rendering: Medan Googles sökrobot nu är mycket bra på att rendera JavaScript-intensiva sidor, är detta inte fallet för många andra AI-sökrobotar. För att säkerställa universell tillgänglighet bör kritiskt innehåll redan inkluderas i sidans ursprungliga HTML-kod och inte laddas på klientsidan.
Schema.orgs strategiska imperativ: Skapa ett nätverksbaserat kunskapsdiagram
Schema.org är ett standardiserat ordförråd för strukturerad data. Det gör det möjligt för webbplatsoperatörer att explicit berätta för sökmotorer vad deras innehåll handlar om och hur olika informationsdelar är relaterade. En webbplats som är markerad med Schema blir i huvudsak en maskinläsbar databas.
- Varför scheman är avgörande för AI: Strukturerad data eliminerar tvetydighet. Det gör det möjligt för AI-system att extrahera fakta som priser, datum, platser, betyg eller stegen i en guide med hög grad av säkerhet. Detta gör innehållet till en mycket mer pålitlig källa för att generera svar än ostrukturerad text.
- Viktiga schematyper för GEO:
- Organisation och person: Att tydligt definiera sitt eget varumärke och författarna som enheter.
- FAQ-sida och instruktioner: För att strukturera innehåll för direkta svar och steg-för-steg-instruktioner som föredras av AI-system.
- Artikel: För att överföra viktiga metadata såsom författare och publiceringsdatum, och därigenom stärka EEAT-signaler.
- Produkt: Viktigt för e-handel för att göra pris-, tillgänglighets- och betygsdata maskinläsbara.
- Bästa praxis – Sammankopplade enheter: Optimering bör gå utöver att bara lägga till isolerade schemablock. Genom att använda @id-attributet kan olika enheter på en sida och över hela webbplatsen länkas samman (t.ex. länka en artikel till dess författare och utgivare). Detta skapar en sammanhängande, intern kunskapsgraf som gör de semantiska relationerna explicita för maskiner.
Den framväxande llms.txt-standarden: En direkt kommunikationslinje till AI-modeller
llms.txt är en föreslagen ny standard som syftar till att möjliggöra direkt och effektiv kommunikation med AI-modeller.
- Syfte och funktion: Det är en enkel textfil skriven i Markdown-format, placerad i rotkatalogen på en webbplats. Den tillhandahåller en kurerad "karta" över webbplatsens viktigaste innehåll, renad från störande HTML, JavaScript och reklambanners. Detta gör det extremt effektivt för AI-modeller att hitta och bearbeta den mest relevanta informationen.
- Skillnaden mellan robots.txt och sitemap.xml: Medan robots.txt talar om för sökrobotar vilka områden de inte bör besöka, och sitemap.xml tillhandahåller en okommenterad lista över alla URL:er, erbjuder llms.txt en strukturerad och kontextualiserad guide till de mest värdefulla innehållsresurserna på en webbplats.
- Specifikation och format: Filen använder enkel Markdown-syntax. Den börjar vanligtvis med en H1-rubrik (sidtitel), följt av en kort sammanfattning i ett citatblock. H2-rubriker grupperar sedan listor med länkar till viktiga resurser som dokumentation eller riktlinjer. Varianter som llms-full.txt finns också, som kombinerar allt textinnehåll på en webbplats till en enda fil.
- Implementering och verktyg: Skapandet kan göras manuellt eller stödjas av ett växande antal genereringsverktyg som FireCrawl, Markdowner eller specialiserade plugins för innehållshanteringssystem som WordPress och Shopify.
- Debatten kring dess acceptans: Att förstå den nuvarande kontroversen kring denna standard är avgörande. Googles officiella dokumentation anger att sådana filer inte är nödvändiga för synlighet i AI-översikter. Ledande Google-experter som John Mueller har uttryckt skepsis och jämfört dess användbarhet med den föråldrade metataggen för sökord. Andra stora AI-företag som Anthropic använder dock redan aktivt standarden på sina egna webbplatser, och dess acceptans inom utvecklargemenskapen växer.
Debatten kring llms.txt och avancerade schemaimplementeringar avslöjar en kritisk strategisk spänning: den mellan att optimera för en enda, dominerande plattform (Google) och att optimera för det bredare, heterogena AI-ekosystemet. Att enbart förlita sig på Googles riktlinjer ("Du behöver det inte") är en riskabel strategi som förlorar kontroll och potentiell synlighet på andra snabbt växande plattformar som ChatGPT, Perplexity och Claude. En framåtblickande, "polygam" optimeringsstrategi som följer Googles kärnprinciper samtidigt som den implementerar ekosystemövergripande standarder som llms.txt och omfattande scheman är den mest motståndskraftiga metoden. Den behandlar Google som den primära, men inte den enda, maskinkonsumenten av ett företags innehåll. Detta är en form av strategisk diversifiering och riskreducering för ett företags digitala tillgångar.
Pelare 3: Digital auktoritetshantering
Framväxten av en ny disciplin
Den tredje, och kanske mest strategiska, pelaren inom Generativ Motoroptimering går utöver enbart innehålls- och teknisk optimering. Den fokuserar på att bygga och hantera ett varumärkes övergripande digitala auktoritet. I en värld där AI-system försöker bedöma källors tillförlitlighet blir algoritmiskt mätbar auktoritet en avgörande rankningsfaktor.
Konceptet "Digital Authority Management" formades i hög grad av branschexperten Olaf Kopp och beskriver en ny, nödvändig disciplin inom digital marknadsföring.
Bron mellan silorna
I EEAT:s och AI:s tidsålder genereras de signaler som bygger algoritmiskt förtroende – såsom varumärkesrykte, medieomnämnanden och författares trovärdighet – av aktiviteter som traditionellt sett har placerats i separata avdelningar som PR, varumärkesmarknadsföring och sociala medier. SEO ensamt har ofta begränsad inverkan på dessa områden. Digital auktoritetshantering överbryggar detta gap genom att förena dessa insatser med SEO under ett enda strategiskt paraply.
Det övergripande målet är en medveten och proaktiv utveckling av ett digitalt igenkännbart och auktoritativt varumärke som lätt kan identifieras av algoritmer och klassificeras som pålitligt.
Bortom bakåtlänkar: Valutan för omnämnanden och samtidig förekomst
- Omnämnanden som signal: Olänkade varumärkesomnämnanden i auktoritativa sammanhang blir allt viktigare. AI-system aggregerar dessa omnämnanden från hela webben för att bedöma ett varumärkes kännedom och rykte.
- Samförekomst och kontext: AI-system analyserar vilka enheter (varumärken, personer, ämnen) som ofta nämns tillsammans. Det strategiska målet måste vara att skapa en stark och konsekvent koppling mellan varumärket och dess kärnkompetensämnen över hela det digitala utrymmet.
Bygga ett digitalt igenkännbart varumärke
- Konsekvens är nyckeln: Absolut konsekvens i stavningen av varumärkesnamn, författarnamn och företagsbeskrivningar över alla digitala kontaktpunkter är avgörande – från din egen webbplats och profiler på sociala medier till branschkataloger. Inkonsekvenser skapar tvetydighet för algoritmerna och försvagar helheten.
- Plattformsoberoende auktoritet: Generativa sökmotorer bedömer ett varumärkes närvaro holistiskt. En enhetlig röst och konsekventa budskap över alla kanaler (webbplats, LinkedIn, gästinlägg, forum) stärker upplevd auktoritet. Återanvändning och anpassning av framgångsrikt innehåll för olika format och plattformar är en viktig taktik här.
Rollen för digital PR och rykteshantering
- Strategisk PR: Digitala PR-insatser måste fokusera på att uppnå omnämnanden i publikationer som inte bara är relevanta för målgruppen utan också klassificeras som auktoritativa källor av AI-modeller.
- Rykteshantering: Det är avgörande att aktivt marknadsföra och övervaka positiva recensioner på välrenommerade plattformar. Lika viktigt är aktivt deltagande i relevanta diskussioner på communityplattformar som Reddit och Quora, eftersom dessa ofta används av AI-system som källor till autentiska åsikter och erfarenheter.
SEO:s nya roll
- Digital auktoritetshantering förändrar fundamentalt SEO:s roll inom en organisation. Den lyfter SEO från en taktisk funktion fokuserad på att optimera en enda kanal (webbplatsen) till en strategisk funktion som ansvarar för att orkestrera ett företags hela digitala fotavtryck för algoritmisk tolkning.
- Detta innebär en betydande förändring av organisationsstrukturen och de kompetenser som krävs. "Digital Authority Manager" är en ny hybridroll som kombinerar SEO:s analytiska noggrannhet med de narrativa och relationsbyggande färdigheterna hos en varumärkesstrateg och PR-proffs. Företag som misslyckas med att skapa denna integrerade funktion kommer att upptäcka att deras fragmenterade digitala signaler inte kan konkurrera med konkurrenter som presenterar en enhetlig, auktoritativ identitet för AI-system.
B2B-upphandling: Leverantörskedjor, handel, marknadsplatser och AI-driven sourcing

B2B-upphandling: Leverantörskedjor, handel, marknadsplatser och AI-driven sourcing med ACCIO.com - Bild: Xpert.Digital
Mer information här:
Från SEO till GEO: Nya mätvärden för att mäta framgång i AI-eran
Konkurrenslandskapet och prestationsmätning
När de strategiska pelarna för optimering har definierats, flyttas fokus till praktisk tillämpning i det rådande konkurrenslandskapet. Detta kräver en datadriven analys av de viktigaste AI-sökplattformarna, samt införandet av nya metoder och verktyg för prestationsmätning.
Relaterat till detta:

Dekonstruktion av källval: En jämförande analys
De olika AI-sökplattformarna fungerar inte identiskt. De använder olika datakällor och algoritmer för att generera sina resultat. Att förstå dessa skillnader är avgörande för att prioritera optimeringsåtgärder. Följande analys baseras på en syntes av ledande branschstudier, särskilt den omfattande studien från SE Ranking, kompletterad med kvalitativa analyser och plattformsspecifik dokumentation.
Översikter över Google AI: Fördelen med det etablerade systemet
- Källprofil: Google har en ganska konservativ strategi. AI-översikterna förlitar sig i hög grad på den befintliga kunskapsgrafen, etablerade EEAT-signaler och topprankade organiska resultat. Studier visar en signifikant, men inte fullständig, korrelation med de 10 bästa positionerna i traditionell sökning.
- Datapunkter: Google citerar i genomsnitt 9,26 länkar per svar och uppvisar hög diversitet med 2 909 unika domäner i den analyserade studien. Det finns en tydlig preferens för äldre, etablerade domäner (49 % av de citerade domänerna är över 15 år gamla), medan mycket unga domäner beaktas mer sällan.
- Strategisk implikation: Framgång i Google AI Overviews är oupplösligt kopplad till stark, traditionell SEO-auktoritet. Det är ett ekosystem där framgång föder ytterligare framgång.
ChatGPT Search: Utmanaren med fokus på användargenererat innehåll och Bing
- Källprofil: ChatGPT använder Microsoft Bings index för sin webbsökning, men tillämpar sin egen logik för filtrering och ordning av resultat. Plattformen visar en tydlig preferens för användargenererat innehåll (UGC), särskilt från YouTube, som är en av de mest citerade källorna, samt för communityplattformar som Reddit.
- Datapunkter: ChatGPT citerar flest länkar (i genomsnitt 10,42) och refererar till det största antalet unika domäner (4 034). Samtidigt uppvisar plattformen den högsta andelen flera omnämnanden av samma domän inom ett enda svar (71 %), vilket tyder på en strategi med djupgående analys med hjälp av en enda, betrodd källa.
- Strategisk implikation: Synlighet i ChatGPT kräver en strategi för flera plattformar som inte bara inkluderar optimering för Bing-indexet utan också aktiv närvaro på viktiga plattformar för användargenererat innehåll.
Perplexity.ai: Den transparenta realtidsforskaren
- Källprofil: Perplexity är utformad för att utföra en webbsökning i realtid för varje fråga, vilket säkerställer att informationen är aktuell. Plattformen är mycket transparent och ger tydliga inbäddade hänvisningar i sina svar. En unik funktion är funktionen "Fokus", som låter användare begränsa sin sökning till ett fördefinierat urval av källor (t.ex. endast akademiska artiklar, Reddit eller specifika webbplatser).
- Datapunkter: Källvalet är mycket konsekvent; nästan alla svar innehåller exakt 5 länkar. Perplexitys svar visar den högsta semantiska likheten med ChatGPT:s (0,82), vilket tyder på liknande preferenser för innehållsval.
- Strategisk implikation: Nyckeln till framgång på Perplexity ligger i att bli en "målkälla" – en webbplats som är så auktoritativ att användarna medvetet inkluderar den i sina fokuserade sökningar. Plattformens realtidskaraktär belönar också särskilt aktuellt och sakligt korrekt innehåll.
De olika sourcingstrategierna hos de stora AI-plattformarna skapar en ny form av "algoritmisk arbitrage". Ett varumärke som kämpar för att få fotfäste i Google AI Overviews mycket konkurrensutsatta, auktoritetsdrivna ekosystem kan hitta en enklare väg till synlighet via ChatGPT genom att fokusera på Bing SEO och en stark närvaro på YouTube och Reddit. På liknande sätt kan en nischexpert kringgå mainstreamkonkurrens genom att bli en viktig källa för fokuserade sökningar på Perplexity. Den strategiska slutsatsen är inte att utkämpa varje strid på varje front, utan snarare att analysera de olika "inträdesbarriärerna" för varje AI-plattform och anpassa innehållsskapande och auktoritetsbyggande insatser till den plattform som bäst överensstämmer med varumärkets styrkor.
Jämförande analys av AI-sökplattformar

Jämförande analys av AI-sökplattformar – Bild: Xpert.Digital
En jämförande analys av AI-sökplattformar avslöjar betydande skillnader mellan Google AI Overviews, ChatGPT Search och Perplexity.ai. Google AI Overviews använder Google Index och Knowledge Graph som sin primära datakälla, levererar i genomsnitt 9,26 citeringar och uppvisar låg källöverlappning med Bing och måttlig överlappning med ChatGPT. Plattformen visar en måttlig preferens för användargenererat innehåll som Reddit och Quora, men gynnar väletablerade, äldre domäner. Dess unika försäljningsargument ligger i dess integration med den dominerande sökmotorn och dess starka betoning på EEAT-rankningar (Ever After Appearance), med ett strategiskt fokus på att bygga EEAT och stark traditionell SEO-auktoritet.
ChatGPT Search använder Bing Index som sin primära datakälla och genererar flest citeringar, med ett genomsnitt på 10,42. Plattformen visar en hög grad av överlappning med Perplexity och måttlig överlappning med Google. Särskilt anmärkningsvärt är dess starka preferens för användargenererat innehåll, särskilt från YouTube och Reddit. Dess åldersbedömning av domänen visar blandade resultat, med en tydlig preferens för yngre domäner. Dess unika försäljningsargument ligger i det höga antalet citeringar och den starka UGC-integrationen, medan dess strategiska fokus ligger på Bing SEO och en närvaro på UGC-plattformar.
Perplexity.ai utmärker sig genom att använda webbsökning i realtid som sin primära datakälla och levererar minst antal citat, med ett genomsnitt på 5,01. Källöverlappningen är hög med ChatGPT men låg med Google och Bing. Plattformen visar en måttlig preferens för användargenererat innehåll och gynnar Reddit och YouTube i fokusläge. Domänålder spelar en mindre roll på grund av fokus på relevans i realtid. Perplexity.ais unika försäljningsargument inkluderar transparens genom inline-citat och anpassningsbart källval via fokusfunktionen. Dess strategiska fokus ligger på att bygga nischauktoritet och säkerställa att innehållet är uppdaterat.
Den nya analysen: Mätning och övervakning av LLM-synlighet
Paradigmskiftet från sökmotorer till responsmarknadsföring kräver en fundamental anpassning av hur framgång mäts. Traditionella SEO-mått förlorar sin relevans när klick på webbplatsen inte längre är det primära målet. Nya mätvärden och verktyg krävs för att kvantifiera ett varumärkes inflytande och närvaro i det generativa AI-landskapet.
Paradigmskiftet inom mätning: Från klick till inflytande
- Gamla mätvärden: Framgången för traditionell SEO utvärderas främst genom direkt mätbara mätvärden som sökordsrankningar, organisk trafik och klickfrekvenser (CTR).
- Nya mätvärden: GEO/LLMO:s framgång kommer att mätas med mätvärden för inflytande och närvaro, vilka ofta är indirekta till sin natur:
- LLM-synlighet / Varumärkesomnämnanden: Mäter hur ofta ett varumärke nämns i relevanta AI-svar. Detta är det mest grundläggande nya mätvärdet.
- Andel av rösten / Andel av modellen: Kvantifierar andelen omnämnanden av det egna varumärket jämfört med konkurrenterna för en definierad grupp av sökfrågor (prompts).
- Citat: Spårar hur ofta din egen webbplats länkas som källa.
- Känslor och kvalitet i omnämnanden: Analyserar tonen (positiv, neutral, negativ) och den faktiska noggrannheten i omnämnandena.
Den framväxande verktygslådan: Plattformar för att spåra AI-omnämnanden
- Så här fungerar det: Dessa verktyg frågar automatiskt och i stor skala olika AI-modeller med fördefinierade frågor. De loggar vilka varumärken och källor som förekommer i svaren, analyserar sentimentet och spårar utvecklingen över tid.
- Ledande verktyg: Marknaden är ung och fragmenterad, men flera specialiserade plattformar har redan etablerat sig. Dessa inkluderar verktyg som Profound, Peec.ai, RankScale och Otterly.ai, vilka skiljer sig åt i sitt utbud av funktioner och målgrupp (från små och medelstora företag till stora företag).
- Anpassning av traditionella verktyg: Etablerade leverantörer av programvara för varumärkesövervakning (t.ex. Sprout Social, Mention) och omfattande SEO-paket (t.ex. Semrush, Ahrefs) börjar också integrera funktioner för AI-synlighetsanalys i sina produkter.
Att minska attributionsgapet: Integrera LLM-analys i rapportering
En av de största utmaningarna är att tillskriva affärsresultat till ett omnämnande i ett AI-svar, eftersom detta ofta inte leder till ett direkt klick. En flerstegsanalysmetod krävs:
- Spåra hänvisningstrafik: Det första och enklaste steget är att analysera direkt hänvisningstrafik från AI-plattformar med hjälp av webbanalysverktyg som Google Analytics 4. Genom att skapa anpassade kanalgrupper baserade på hänvisningskällor (t.ex. perplexity.ai, bing.com för ChatGPT-sökningar) kan denna trafik isoleras och utvärderas.
- Övervakning av indirekta signaler: Den mer avancerade metoden involverar korrelationsanalys. Analytiker behöver övervaka trender i indirekta indikatorer, såsom en ökning av direkt webbplatstrafik och en ökning av varumärkessökfrågor i Google Search Console. Dessa trender måste sedan korreleras med utvecklingen av LLM-synlighet, mätt med nya övervakningsverktyg.
- Analys av botloggar: För tekniskt skickliga team ger analys av serverloggfiler värdefulla insikter. Genom att identifiera och övervaka aktiviteterna hos AI-crawlers (t.ex. GPTBot, ClaudeBot) är det möjligt att avgöra vilka sidor som används av AI-system för att samla in information.
Utvecklingen av nyckeltal

Utveckling av nyckeltal – Bild: Xpert.Digital
Utvecklingen av nyckeltal (KPI:er) visar ett tydligt skifte från traditionella SEO-mått till AI-drivna mätvärden. Synlighet rör sig bort från klassisk sökordsrankning mot Share of Voice och Share of Model, mätt med specialiserade LLM-övervakningsverktyg som Peec.ai eller Profound. När det gäller trafik kompletterar hänvisningstrafik från AI-plattformar organisk trafik och klickfrekvens, med webbanalysverktyg som Google Analytics 4 (GA4) som använder anpassade kanalgrupper. Webbplatsauktoritet bestäms inte längre enbart av domänauktoritet och bakåtlänkar, utan också av citeringar och kvaliteten på omnämnanden i AI-system, mätbara genom LLM-övervakningsverktyg och bakåtlänksanalys av citerade källor. Varumärkesuppfattningen utvidgas från varumärkesrelaterade sökfrågor till att inkludera sentimentet i AI-omnämnanden, fångat upp av LLM-övervakning och verktyg för sociala lyssningar. På en teknisk nivå, utöver den traditionella indexeringsfrekvensen, finns hämtningsfrekvensen av AI-botar, vilken bestäms med hjälp av serverloggfilsanalys.
Ledande verktyg för övervakning och analys av GEO/LLMO

Ledande verktyg för övervakning och analys av GEO/LLMO – Bild: Xpert.Digital
Landskapet av ledande GEO/LLMO-övervaknings- och analysverktyg erbjuder olika specialiserade lösningar för olika målgrupper. Profound representerar en omfattande företagslösning som tillhandahåller övervakning, röstdelning, sentimentanalys och källanalys för ChatGPT, Copilot, Perplexity och Google AIO. Peec.ai riktar sig även till marknadsföringsteam och företagskunder och erbjuder en dashboard för varumärkesnärvaro, konkurrentbenchmarking och innehållsgapsanalys för ChatGPT, Perplexity och Google AIO.
För små och medelstora företag (SMF) och SEO-proffs erbjuder RankScale realtidsrankningsanalys i AI-genererade svar, sentimentanalys och citeringsanalys på ChatGPT, Perplexity och Bing Chat. Otterly.ai fokuserar på omnämnanden och bakåtlänkar med aviseringar om förändringar och betjänar SMF och byråer via ChatGPT, Claude och Gemini. Goodie AI positionerar sig som en allt-i-ett-plattform för övervakning, optimering och innehållsskapande på samma plattformar och riktar sig till SMF och byråer.
Hall erbjuder en specialiserad lösning för företags- och produktteam med konversationsintelligens, trafikmätning baserad på AI-rekommendationer och agentspårning för olika chatbotar. Gratisverktyg finns tillgängliga för nybörjare: HubSpot AI Grader erbjuder en gratis kontroll av röstdelning och sentiment på GPT-4 och Perplexity, medan Mangools AI Grader erbjuder en gratis kontroll av AI-synlighet och konkurrentjämförelse på ChatGPT, Google AIO och Perplexity för nybörjare och SEO-experter.
Det kompletta GEO-åtgärdsramverket: 5 faser till optimal AI-synlighet
Bygga auktoritet för AI-framtiden: Varför EEAT är nyckeln till framgång
Efter en detaljerad analys av de tekniska grunderna, strategiska pelarna och konkurrenslandskapet sammanfattar denna sista del resultaten i ett praktiskt handlingsramverk och tittar på den framtida utvecklingen av sökmotorer.
Ett fungerande ramverk för handling
Komplexiteten i Generativ Motoroptimering kräver en strukturerad och iterativ metod. Följande checklista sammanfattar rekommendationerna från föregående avsnitt i ett praktiskt arbetsflöde som kan fungera som en vägledning för implementering.
Fas 1: Revision och baslinjebedömning
- Genomför en teknisk SEO-granskning: Granska grundläggande tekniska krav såsom crawlbarhet, indexerbarhet, sidhastighet (Core Web Vitals) och mobiloptimering. Identifiera problem som kan blockera AI-crawlers (t.ex. långsamma laddningstider, JavaScript-beroenden).
- Kontrollera Schema.org-kod: Granska den befintliga strukturerade datakodningen för fullständighet, korrekthet och användning av nätverksanslutna enheter (@id).
- Genomför en innehållsgranskning: Utvärdera befintligt innehåll med avseende på EEAT-signaler (identifieras författarna, citeras källorna?), semantiskt djup och ämnesauktoritet. Identifiera luckor i ämnesklustren.
- Fastställ baslinjen för LLM-synlighet: Använd specialiserade övervakningsverktyg eller manuella frågor på relevanta AI-plattformar (Google AIO, ChatGPT, Perplexity) för att fånga status quo för din egen varumärkessynlighet och dina huvudkonkurrenters.
Fas 2: Innehållsstrategi och optimering
- Utveckla en ämnesklusterkarta: Baserat på sökords- och ämnesforskning, skapa en strategisk karta över de ämnen och delämnen som ska behandlas, utifrån din egen expertis.
- Skapa och optimera innehåll: Skapa nytt innehåll och revidera befintligt innehåll, med ett tydligt fokus på optimering för extrahering (kodavsnittsstruktur, listor, tabeller, vanliga frågor) och entitetstäckning.
- Stärka EEAT-signaler: Implementera eller förbättra författarsidor, lägga till referenser och citat, införliva unika vittnesmål och originaldata.
Fas 3: Teknisk implementering
- Lansera/uppdatera Schema.org-kod: Implementering av relevant och sammankopplad Schema-kod på alla viktiga sidor, särskilt för produkter, vanliga frågor, guider och artiklar.
- Skapa och tillhandahålla en llms.txt-fil: Skapa en llms.txt-fil som refererar till det viktigaste och mest relevanta innehållet för AI-system och placera den i webbplatsens rotkatalog.
- Lös prestandaproblem: Eliminera de problem som identifierades i den tekniska granskningen gällande laddningstid och rendering.
Fas 4: Bygga auktoritet och främja
- Genomför digital PR och uppsökande verksamhet: Riktade kampanjer för att generera högkvalitativa bakåtlänkar och, ännu viktigare, omnämnanden av olänkade varumärken i auktoritativa, ämnesrelevanta publikationer.
- Engagera dig på communityplattformar: Delta aktivt och hjälpsamt i diskussioner på plattformar som Reddit och Quora för att positionera varumärket som en hjälpsam och kompetent källa.
Fas 5: Mätning och iterering
- Konfigurera analyser: Konfigurera webbanalysverktyg för att spåra hänvisningstrafik från AI-källor och för att övervaka indirekta signaler som direkt trafik och varumärkesbaserad sökning.
- Kontinuerligt övervaka LLM-synligheten: Använd regelbundet övervakningsverktyg för att följa utvecklingen av din egen och dina konkurrenters synlighet.
- Anpassa strategi: Använd den erhållna datan för att kontinuerligt förfina innehålls- och auktoritetsstrategin och för att reagera på förändringar i AI-landskapet.
Sökningens framtid: Från informationsinsamling till kunskapsinteraktion
Integreringen av generativ AI är inte en övergående trend, utan början på en ny era av människa-datorinteraktion. Denna utveckling kommer att sträcka sig bortom dagens system och i grunden förändra hur vi får tillgång till information.
Utvecklingen av AI inom sök
- Hyperpersonalisering: Framtida AI-system kommer att skräddarsy svar inte bara efter den explicita begäran, utan även efter användarens implicita kontext – deras sökhistorik, plats, preferenser och till och med deras tidigare interaktioner med systemet.
- Agentliknande arbetsflöden: AI kommer att utvecklas från en ren svarsleverantör till en proaktiv assistent som kan utföra uppgifter i flera steg för användarens räkning – från research och sammanfattning till bokning eller köp.
- Slutet på "sökandet" som metafor: Begreppet aktivt "sökande" ersätts alltmer av kontinuerlig, dialogorienterad interaktion med en allestädes närvarande, intelligent assistent. Sökandet blir en konversation.
Förberedelser inför framtiden: Bygga en motståndskraftig och framtidssäker strategi
Det slutgiltiga budskapet är att principerna som beskrivs i denna rapport – att bygga genuin auktoritet, skapa högkvalitativt, strukturerat innehåll och hantera en enhetlig digital närvaro – inte är kortsiktiga taktiker för den nuvarande generationen av AI. De är de grundläggande principerna för att bygga ett varumärke som kan blomstra i alla framtida landskap där information levereras genom intelligenta system.
Fokus måste ligga på att bli en källa till sanning som både människor och deras AI-assistenter vill lära sig av. Företag som investerar i kunskap, empati och tydlighet kommer inte bara att synas i dagens sökresultat utan kommer också att avsevärt forma berättelserna om sin bransch i morgondagens AI-drivna värld.
Vi finns här för dig - Konsulttjänster - Planering - Implementering - Projektledning
☑️ Stöd till små och medelstora företag inom strategi, konsultation, planering och implementering
☑️ Skapande eller omstrukturering av den digitala strategin och digitaliseringen
☑️ Utökning och optimering av internationella säljprocesser
☑️ Globala och digitala B2B-handelsplattformar
☑️ Pionjär inom affärsutveckling

Konrad Wolfenstein
Jag skulle gärna fungera som din personliga rådgivare.
Du kan kontakta mig genom att fylla i kontaktformuläret nedan eller helt enkelt ringa mig på +49 7348 4088 965 .
Jag ser fram emot vårt gemensamma projekt.
Skriv till mig




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital är ett nav för industrin med fokus på digitalisering, maskinteknik, logistik/intralogistik och solceller.
Med vår 360° affärsutvecklingslösning stödjer vi välrenommerade företag från nya affärer till eftermarknadsförsäljning.
Marknadsinformation, smarketing, marknadsautomation, innehållsutveckling, PR, utskick, personliga sociala medier och lead nurturing är en del av våra digitala verktyg.
Du hittar mer information på: www.xpert.digital - www.xpert.solar - www.xpert.plus
Håll kontakten











