
KI och SEO med BERT - Bidirectional Encoder Representations from Transformers - Model in the Field of Natural Language Processing (NLP)

Röstval 📢
Publicerad: 4 oktober 2024 / UPDATE Från: 4 oktober 2024 - Författare: Konrad Wolfenstein

KI och SEO med BERT - Bidirectional Encoder Representations from Transformers - Model in the Field of Natural Language Processing (NLP) - Bild: Xpert.digital
🚀💬 Utvecklad av Google: Bert och dess betydelse för NLP - Varför dubbelriktad förståelse av text är avgörande
🔍🗣 Bert, kort för dubbelriktade kodare -representationer från transformatorer, är en viktig modell inom området Natural Language Processing (NLP), som utvecklades av Google. Det har revolutionerat hur maskiner förstår språk. Till skillnad från tidigare modeller som analyserade texter i följd från vänster till höger eller vice versa möjliggör Bert dubbelriktad bearbetning. Detta innebär att det fångar sammanhanget för ett ord från både föregående och följande textsekvens. Denna förmåga förbättrar förståelsen för komplexa språkliga relationer avsevärt.
🔍 Berts arkitektur
Under de föregående åren fanns det en av de viktigaste utvecklingen inom området för bearbetning av naturligt språk (Natural Language Processing, NLP) genom att introducera transformormodellen, eftersom det var i PDF 2017-uppmärksamhet är allt du behöver papper ( Wikipedia ). Denna modell har i grunden förändrat fältet genom att avvisa de strukturer som tidigare använts, till exempel maskinöversättningen. Istället förlitar det sig bara på uppmärksamhetsmekanismer. Sedan dess har utformningen av transformatorn varit grunden för många modeller som representerar toppmodern inom olika områden som språkgenerering, översättning och därefter.
En kartläggning av huvudkomponenterna i transformatorns modell-bild: Google
Bert är baserad på denna transformatorarkitektur. Denna arkitektur använder så kallade självförlevnadsmekanismer (självstation) för att analysera förhållanden mellan orden i en mening. Varje ord i samband med hela meningen ägnas åt uppmärksamhet, vilket leder till en mer exakt förståelse av syntaktiska och semantiska relationer.
Författarna till uppsatsen "uppmärksamhet är allt du behöver" är:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob USzKoreit (Google Research)
- Llion Jones (Google Research)
- Aidan N. Gomez (University of Toronto, delvis genomförd på Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (oberoende, tidigare arbete med Google Research)
Dessa författare har bidragit väsentligt till utvecklingen av transformatormodellen, som presenterades i detta dokument.
🔄 Bidirectional bearbetning
Ett enastående kännetecken för Bert är hans förmåga att arbeta med dubbelriktning. Medan traditionella modeller som återkommande neuronala nätverk (RNN) eller långt korttidsminne (LSTM) nätverk av nätverk bara bearbetar texter i en riktning, analyserar Bert sammanhanget för ett ord i båda riktningarna. Detta gör det möjligt för modellen att bättre fånga subtila nyanser och därmed göra mer exakta förutsägelser.
🕵️ maskerad röstmodellering
En annan innovativ aspekt av Bert är tekniken för den maskerade språkmodellen (MLM). Slumpmässigt utvalda ord maskeras i en mening och modellen tränas för att förutsäga dessa ord baserat på det omgivande sammanhanget. Denna metod tvingar Bert att utveckla en djup förståelse av sammanhanget och betydelsen av varje ord i meningen.
🚀 Utbildning och anpassning av Bert
Bert genomgår en tvåstegs träningsprocess: förträning och finjustering.
📚 Förutbildning
Vid förutbildning tränas Bert med stora mängder text för att lära sig allmänna språkmönster. Detta inkluderar Wikipedia -texter och andra omfattande textföretag. I denna fas lär modellen känna grundläggande språkliga strukturer och sammanhang.
🔧 Finjustering
Efter förutbildning är BERT anpassad för specifika NLP-uppgifter, såsom textklassificering eller sentimentanalys. Modellen är utbildad med mindre, uppgiftsrelaterade dataposter för att optimera dess prestanda för vissa applikationer.
🌍 Tillämpningsområden
Bert har visat sig vara extremt användbar inom många områden med naturligt språkbearbetning:
Sökmotoroptimering
Google använder BERT för att bättre förstå sökfrågor och visa mer relevanta resultat. Detta förbättrar användarupplevelsen avsevärt.
Textklassificering
Bert kan kategorisera dokument enligt ämnen eller analysera stämningen i texter.
Namngiven enhetsigenkänning (NER)
Modellen identifierar och klassificerar namngivna enheter i texter som personliga, plats- eller organisatoriska namn.
Frågesystem
Bert används för att ge exakta svar på frågor som ställs.
🧠 Betydelsen av Bert för AI: s framtid
Bert har fastställt nya standarder för NLP -modeller och banat vägen för ytterligare innovationer. På grund av dess förmåga att bearbeta dubbelriktning och dess djupa förståelse för språkförhållanden har den ökat effektiviteten och noggrannheten hos AI -applikationer.
🔜 Framtida utveckling
Den vidare utvecklingen av Bert och liknande modeller förväntas syftar till att skapa ännu kraftfullare system. Dessa kan hantera mer komplexa röstuppgifter och används inom en mängd nya tillämpningsområden. Integrationen av sådana modeller i vardagsteknologier kan i grunden ändra vår interaktion med datorer.
🌟 Milstolpe i utvecklingen av konstgjord intelligens
Bert är en milstolpe i utvecklingen av konstgjord intelligens och har revolutionerat sättet för hur maskiner bearbetar naturligt språk. Dess dubbelriktade arkitektur möjliggör en djupare förståelse av språkliga relationer, vilket gör det nödvändigt för en mängd olika applikationer. Med progressiv forskning kommer modeller som BERT att fortsätta spela en central roll för att förbättra AI -system och öppna nya möjligheter för deras användning.
📣 Liknande ämnen
- 📚 Introduktion till Bert: Den banbrytande NLP -modellen
- 🔍 BERT och BID -riktningens roll i NLP
- 🧠 Transformermodellen: fallsten av Bert
- 🚀 Maskerad röstmodellering: Bert's nyckel till framgång
- 📈 Anpassning av Bert: Från för-utbildning till finjustering
- 🌐 BERT: s tillämpningsområden inom modern teknik
- 🤖 BERT: s inflytande på framtiden för konstgjord intelligens
- 💡 Framtidsutsikter: Ytterligare utveckling av Bert
- 🏆 Bert som en milstolpe i AI -utvecklingen
- 📰 Författare av transformatorpapperet "Uppmärksamhet är allt du behöver": huvuden bakom Bert
#⃣ Hashtags: #NLP #Artificial EditionStz #Language Modeling #TransFormer #MaschinelesLernen
🎯🎯🎯 Dra nytta av den omfattande, femtidskompetens från Xpert.Digital i ett omfattande servicepaket | FoU, XR, PR & SEM

AI & XR-3D-Rendering Machine: Fem gånger expertis från Xpert.Digital i ett omfattande servicepaket, FoU XR, PR & SEM-IMAGE: Xpert.Digital
Xpert.Digital har djup kunskap i olika branscher. Detta gör att vi kan utveckla skräddarsydda strategier som är anpassade efter kraven och utmaningarna för ditt specifika marknadssegment. Genom att kontinuerligt analysera marknadstrender och bedriva branschutveckling kan vi agera med framsyn och erbjuda innovativa lösningar. Med kombinationen av erfarenhet och kunskap genererar vi mervärde och ger våra kunder en avgörande konkurrensfördel.
Mer om detta här:
Bert: Revolutionär 🌟 NLP -teknik
🚀 Bert, kort för dubbelriktade kodare -representationer från transformatorer, är en avancerad röstmodell som har utvecklats av Google och har utvecklats till ett betydande genombrott inom området naturligt språkbearbetning (naturlig språkbearbetning, NLP) sedan dess introduktion 2018. Den är baserad på transformatorarkitekturen som revolutionerade hur maskiner förstår och bearbetar text. Men vad gör Bert så speciellt och vad används det för? För att besvara denna fråga måste vi ta itu med de tekniska grunderna, funktionerna och tillämpningsområdena från Bert.
📚 1. Grunderna för naturligt språkbehandling
För att fullt ut förstå betydelsen av BERT är det bra att kort svara på grunderna för Natural Language Processing (NLP). NLP handlar om interaktionen mellan datorer och mänskligt språk. Målet är att undervisa maskiner, analysera textdata, förstå och reagera på det. Innan introduktionen av modeller som BERT var den mekaniska bearbetningen av språk ofta förknippad med betydande utmaningar, särskilt på grund av tvetydighet, kontextberoende och den komplexa strukturen i mänskligt språk.
📈 2. Utvecklingen av NLP -modeller
Innan Bert dök upp på scenen baserades de flesta NLP-modeller på så kallade enkelriktade arkitekturer. Detta innebär att dessa modeller antingen läser texten från vänster till höger eller från höger till vänster, vilket innebar att de bara kunde ta hänsyn till en begränsad mängd sammanhang när man bearbetar ett ord i en mening. Denna begränsning ledde ofta till de modeller som den fulla semantiska sammanhanget för en mening inte helt registrerade. Detta gjorde den exakta tolkningen av tvetydiga eller sammanhangskänsliga ord.
En annan viktig utveckling i NLP -forskning framför BERT var Word2VEC -modellen, vilket gjorde det möjligt att översätta datorer i vektorer som återspeglade semantiska likheter. Men också här var sammanhanget begränsat till den omedelbara miljön i ett ord. Senare återkommande neurala nätverk (RNNS) och i synnerhet långa korttidsminnesmodeller (LSTM) utvecklades som gjorde det möjligt att bättre förstå textsekvenser genom att lagra information över flera ord. Dessa modeller hade emellertid också sina gränser, särskilt när de hanterade långa texter och samtidig förståelse av sammanhang i båda riktningarna.
🔄 3. Revolutionen av transformatorarkitekturen
Genombrottet kom med introduktionen av transformatorarkitekturen 2017, som ligger till grund för Bert. Transformatormodeller är utformade för att möjliggöra parallellbehandling av text och ta hänsyn till sammanhanget för ett ord från både föregående och från följande text. Detta händer genom så kallade självförlevnadsmekanismer (självposteringsmekanism), som tilldelar ett viktningsvärde till varje ord i en mening, baserat på hur viktigt det är i förhållande till de andra orden i meningen.
Till skillnad från tidigare tillvägagångssätt är transformatormodeller inte enkelriktade, men dubbelriktade. Detta innebär att du kan rita information från vänster och det högra sammanhanget för ett ord för att skapa en mer fullständig och mer exakt representation av ordet och dess betydelse.
🧠 4. Bert: En dubbelriktad modell
Bert höjer prestandararkitekturens prestanda till en ny nivå. Modellen är utformad för att spela in sammanhanget för ett ord inte bara från vänster till höger eller från höger till vänster, utan i båda riktningarna samtidigt. Detta gör det möjligt för BERT att ta hänsyn till hela sammanhanget för ett ord inom en mening, vilket leder till avsevärt förbättrad noggrannhet när det gäller språkbehandling.
Ett centralt inslag i Bert är användningen av den så kallade maskerade röstmodellen (maskerad språkmodell, MLM). I utbildningen av Bert ersätts slumpmässigt utvalda ord av en mask i en mening, och modellen tränas för att gissa dessa maskerade ord baserade på sammanhanget. Denna teknik gör det möjligt för Bert att lära sig djupare och mer exakta förhållanden mellan orden i en mening.
Dessutom använder Bert en metod som heter Next Sentence Prediction (NSP) där modellen lär sig att förutsäga om en mening följer en annan eller inte. Detta förbättrar Berts förmåga att förstå längre texter och känna igen mer komplexa relationer mellan meningar.
🌐 5. Användning av Bert i praktiken
Bert har visat sig vara extremt användbar för en mängd NLP -uppgifter. Här är några av de viktigaste tillämpningsområdena:
📊 a) Textklassificering
Ett av de vanligaste syftena med BERT är textklassificeringen, där texter är indelade i fördefinierade kategorier. Exempel på detta är den sentimentala analysen (t.ex. erkänna om en text är positiv eller negativ) eller kategorisering av kundåterkoppling. Genom sin djupa förståelse av ordens sammanhang kan Bert ge exakt fler resultat än tidigare modeller.
❓ B) Frågesvarssystem
Bert används också i frågeställningar där modellen extraherar svar på frågor från en text. Denna förmåga är särskilt viktig i applikationer som sökmotorer, chatbots eller virtuella assistenter. Tack vare sin dubbelriktade arkitektur kan Bert extrahera relevant information från en text, även om frågan indirekt är formulerad.
🌍 c) Textöversättning
Medan Bert själv inte är direkt utformad som en översättningsmodell, kan den användas i kombination med annan teknik för att förbättra maskinöversättningen. Genom bättre förståelse för semantiska relationer i en mening kan Bert hjälpa till att generera exakta översättningar, särskilt med tvetydiga eller komplexa formuleringar.
🏷 D) Namngiven enhetsigenkänning (NER)
Ett annat ansökningsområde är det namngivna enhetens erkännande (NER), som handlar om att identifiera vissa enheter som namn, platser eller organisationer i en text. Bert har visat sig vara särskilt effektiv i denna uppgift, eftersom den helt tar hänsyn till sammanhanget för en mening och därmed kan bättre känna igen enheter, även om de har olika betydelser i olika sammanhang.
✂ E) text
BERT: s förmåga att förstå hela sammanhanget för en text gör det också till ett kraftfullt verktyg för textens automatiska text. Det kan användas för att extrahera den viktigaste informationen från en lång text och skapa en kortfattad sammanfattning.
🌟 6. Betydelsen av Bert för forskning och industri
Införandet av Bert har meddelat en ny era i NLP -forskning. Det var en av de första modellerna som fullt ut använde prestanda för den dubbelriktade transformatorarkitekturen och därmed placerade måttstocken för många efterföljande modeller. Många företag och forskningsinstitut har integrerat BERT i sina NLP -rörledningar för att förbättra prestandan för sina applikationer.
Bert banade också vägen för ytterligare innovationer inom området för språkmodeller. Till exempel utvecklades modeller som GPT (Generative Pretained Transformer) och T5 (Text-Text Transfer Transformer) som är baserade på liknande principer, men erbjuder specifika förbättringar för olika applikationer.
🚧 7. Utmaningar och gränser för Bert
Trots sina många fördelar har Bert också några utmaningar och begränsningar. Ett av de största häckarna är den höga datoransträngningen som krävs för träning och användning av modellen. Eftersom Bert är en mycket stor modell med miljoner parametrar kräver den kraftfull hårdvara och betydande aritmetiska resurser, särskilt när man bearbetar stora mängder data.
Ett annat problem är den potentiella förspänningen (förspänning), som kan finnas i utbildningsdata. Eftersom Bert är utbildad på stora mängder textdata återspeglar det ibland fördomarna och stereotyper som finns tillgängliga i denna information. Men forskare arbetar kontinuerligt med att identifiera och ta bort dessa problem.
🔍 Osiktigt verktyg för moderna språkbehandlingsapplikationer
Bert har förbättrat hur maskiner förstår mänskligt språk avsevärt. Med sin dubbelriktade arkitektur och de innovativa träningsmetoderna kan den förstå sammanhanget för ord i en mening djupt och exakt, vilket leder till en högre noggrannhet i många NLP -uppgifter. Huruvida klassificering av text, i fråga-svarssystem eller vid upptäckt av enheter-har det etablerat sig som ett oundgängligt verktyg för moderna språkbehandlingsapplikationer.
Forskning inom området naturligt språkbearbetning är utan tvekan fortskrider, och Bert har lagt grunden för många framtida innovationer. Trots de befintliga utmaningarna och gränserna visar Bert imponerande hur långt tekniken har kommit på kort tid och vilka spännande möjligheter kommer att öppna sig i framtiden.
🌀 Transformatorn: En revolution inom bearbetning av naturligt språk
🌟 Under de senaste åren har en av de viktigaste utvecklingen inom området för bearbetning av naturligt språk (naturligt språkbearbetning, NLP) varit introduktionen av transformatormodellen, som beskrivs i 2017 -papperet "uppmärksamhet är allt du behöver". Denna modell har i grunden ändrat fältet genom att avvisa de tidigare använda återkommande eller upplösningsstrukturerna för uppgifter för sekvenstransduktion, såsom maskinöversättningen. Istället förlitar det sig bara på uppmärksamhetsmekanismer. Sedan dess har utformningen av transformatorn varit grunden för många modeller som representerar toppmodern inom olika områden som språkgenerering, översättning och därefter.
🔄 Transformatorn: ett paradigmskift
Innan transformatorn introducerades baserades de flesta modeller för sekvensuppgifter på återkommande neuronala nätverk (RNN) eller "Long Kort-Term Memory" -nätverk (LSTMS), som naturligt fungerar i sekvens. Dessa modeller bearbetar inmatningsdata steg för steg och skapar dolda förhållanden som överförs längs sekvensen. Även om denna metod är effektiv är den matematiskt komplex och svår att parallellisera, särskilt med långa sekvenser. Dessutom uppstår RNN: s svårigheter att lära sig långsiktiga beroenden, eftersom det så kallade "försvinnande gradient" -problemet uppstår.
Transformatorns centrala innovation ligger i användningen av självändmekanismer, som gör det möjligt för modellen att väga vikten av olika ord i en mening, oavsett deras position. Detta gör det möjligt för modellen att förstå förhållandena mellan allmänt isär ord mer effektivt än RNN eller LSTMS, och detta parallellt istället för sekventiellt. Detta förbättrar inte bara träningseffektiviteten, utan också prestanda för uppgifter som maskinöversättning.
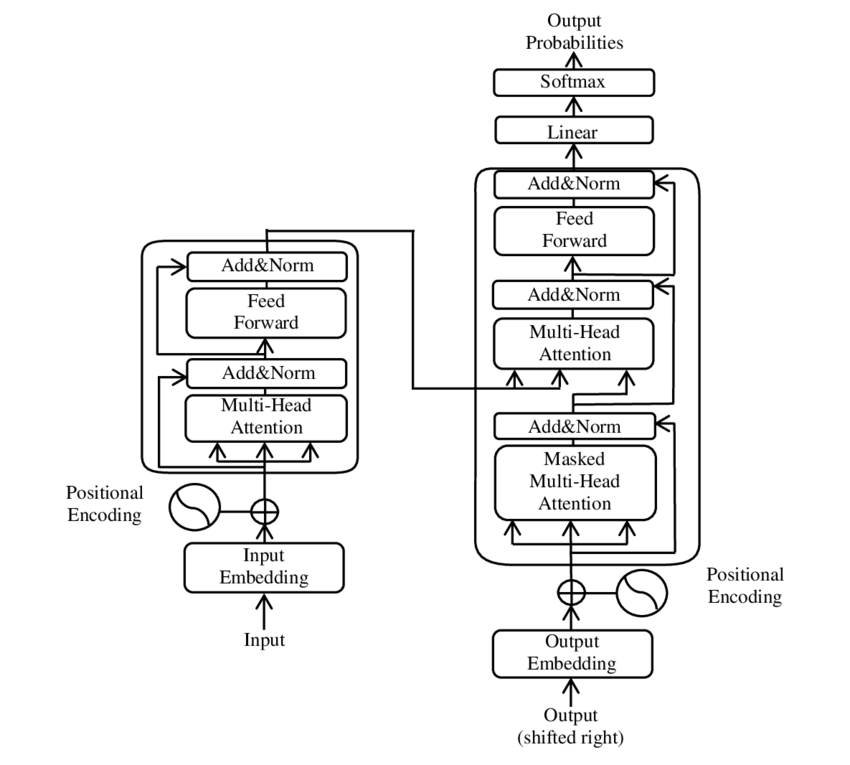
🧩 Modellarkitektur
Transformatorn består av två huvudkomponenter: en kodare och en avkodare, som båda består av flera lager och är starkt beroende av flerhuvudstationsmekanismer.
⚙ kodare
Kodaren består av sex identiska lager, var och en har två lägre klasser:
1. Självhuvudet på flera huvuden
Denna mekanism gör det möjligt för modellen att koncentrera sig på olika delar av ingångshastigheten vid bearbetning av varje ord. Istället för att beräkna uppmärksamheten i ett enkelrum projicerar flerhuvudstationen ingången i flera olika rum, vilket innebär att olika typer av förhållanden mellan ord kan spelas in.
2. Helt anslutna FashionForward Networks
Enligt attackskiktet tillämpas ett helt anslutet feedforward -nätverk oberoende vid valfri position. Detta hjälper modellen att bearbeta varje ord i sammanhang och använda informationen från uppmärksamhetsmekanismen.
För att bevara strukturen för ingångssekvensen innehåller modellen också positionsinmatning (positionskodningar). Eftersom transformatorn inte behandlar orden i följd är dessa kodningar avgörande för att ge modellinformationen om ordens ordning i en mening. Positionens ingångar läggs till i sängens ord så att modellen kan skilja mellan de olika positionerna i sekvensen.
🔍 Avkodare
Liksom kodaren består avkodaren också av sex lager, med varje lager har en ytterligare uppmärksamhetsmekanism som gör det möjligt för modellen att koncentrera sig på relevanta delar av ingångssekvensen medan den genererar utgången. Avkodaren använder också en maskeringsteknik för att förhindra att framtida positioner tar hänsyn till vad den författande -komprimerande karaktären av sekvensgenerering upprätthåller.
🧠 Flerhuvudstation och skalarproduktstation
Transformatorns hjärta är den flerhuvudiga postmekanismen, som är en utvidgning av den enklare skalära produktstationen. Attackfunktionen kan betraktas som en illustration mellan en fråga (fråga) och en mening med nyckelvärdepar (nycklar och värden), varje nyckel representerar ett ord i sekvensen och värdet representerar den tillhörande kontextuella informationen.
Stationsmekanismen för flera huvuden gör det möjligt för modellen att koncentrera sig på olika delar av sekvensen samtidigt. Genom projektion av ingången i flera underrum kan modellen fånga en mer rik mängd relationer mellan ord. Detta är särskilt användbart för uppgifter som maskinöversättning, där förståelsen av sammanhanget för ett ord kräver många olika faktorer, till exempel den syntaktiska strukturen och den semantiska betydelsen.
Formeln för den skalära produktstationen är:

Här (q) fragematrix, (k) nyckelmatrisen och (v) värdematrisen. Termen (sqrt {d_k}) är en skalningsfaktor som förhindrar att skalprodukterna blir för stora, vilket skulle leda till mycket små lutningar och långsammare inlärning. Softmax -funktionen används för att säkerställa att uppmärksamhetsvikterna resulterar i en summa av en.
🚀 Fördelarna med transformatorn
Transformatorn erbjuder flera avgörande fördelar jämfört med traditionella modeller som RNN och LSTMS:
1. Parallellisering
Eftersom transformatorn bearbetar hela sekvensen samtidigt kan den parallelliseras starkt och är därför mycket snabbare att träna än RNNS eller LSTMS, särskilt med stora datamängder.
2. Långsiktiga beroenden
Självställningsmekanismen gör det möjligt för modellen att fånga förhållanden mellan avlägsna ord mer effektivt än RNN, som är begränsade av den sekventiella karaktären av deras beräkningar.
3. Skalbarhet
Transformatorn kan enkelt skalas på mycket stora dataposter och längre sekvenser utan att drabbas av prestandaflaskhalsarna associerade med RN: er.
🌍 Applikationer och effekter
Sedan introduktionen har transformatorn blivit grunden för ett brett spektrum av NLP -modeller. Ett av de mest anmärkningsvärda exemplen är BERT (Bidirectional Encoder Representation från Transformers), som använder en modifierad transformatorarkitektur för att uppnå toppmodern i många NLP -uppgifter, inklusive förhör och textklassificering.
En annan betydande utveckling är GPT (Generative Pretrained Transformer), som använder en version av transformatorn för att generera text. GPT-modeller, inklusive GPT-3, används nu för många applikationer, från innehållsskapande till slutförandet av koden.
🔍 En kraftfull och flexibel modell
Transformatorn har i grunden förändrat hur vi hanterar NLP -uppgifter. Det erbjuder en kraftfull och flexibel modell som kan tillämpas på olika problem. Hans förmåga att behandla långsiktiga beroenden och hans effektivitet i träning har gjort honom till den föredragna arkitektoniska metoden för många av de mest moderna modellerna. Med progressiv forskning kommer vi förmodligen att se ytterligare förbättringar och justeringar av transformatorn, särskilt inom områden som bild- och språkbehandling, där uppmärksamhetsmekanismer visar lovande resultat.
Vi är där för dig - Råd - Planering - Implementering - Projektledning
☑ Branschekspert, här med sitt eget Xpert.Digital Industrial Hub på över 2500 specialbidrag

Konrad Wolfenstein
Jag hjälper dig gärna som personlig konsult.
Du kan kontakta mig genom att fylla i kontaktformuläret nedan eller helt enkelt ringa mig på +49 89 674 804 (München) .
Jag ser fram emot vårt gemensamma projekt.
Skriv mig

Xpert.digital - Konrad Wolfenstein
Xpert.Digital är ett nav för bransch med fokus, digitalisering, maskinteknik, logistik/intralogistik och fotovoltaik.
Med vår 360 ° affärsutvecklingslösning stöder vi välkända företag från ny verksamhet till efter försäljning.
Marknadsintelligens, smarketing, marknadsföringsautomation, innehållsutveckling, PR, postkampanjer, personliga sociala medier och blyomsorg är en del av våra digitala verktyg.
Du kan hitta mer på: www.xpert.digital - www.xpert.solar - www.xpert.plus
Hålla kontakten med



















