Felberäkningen på 57 miljarder dollar – NVIDIA varnar av alla företag: AI-industrin har satsat på fel häst – Bild: Xpert.Digital
Glöm AI-jättarna: Varför framtiden är liten, decentraliserad och mycket billigare
### Små språkmodeller: Nyckeln till verklig affärsautonomi ### Från hyperskalare tillbaka till användare: Maktskifte i AI-världen ### Misstaget på 57 miljarder dollar: Varför den verkliga AI-revolutionen inte sker i molnet ### Den tysta AI-revolutionen: Decentraliserat istället för centraliserat ### Teknikjättar på fel spår: Framtiden för AI är lean och lokal ### Från hyperskalare tillbaka till användare: Maktskifte i AI-världen ###
Miljarder dollar i bortkastade investeringar: Varför små AI-modeller går om de stora
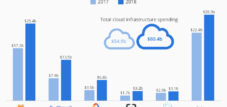
Den artificiella intelligensens värld står inför en jordbävning vars magnitud påminner om korrigeringarna under dotcom-eran. I hjärtat av denna omvälvning ligger en kolossal felberäkning: Medan teknikjättar som Microsoft, Google och Meta investerar hundratals miljarder i centraliserade infrastrukturer för massiva språkmodeller (Large Language Models, LLMs), släpar den faktiska marknaden för deras tillämpningar dramatiskt efter. En banbrytande analys, delvis utförd av branschledaren NVIDIA själv, kvantifierar skillnaden till 57 miljarder dollar i infrastrukturinvesteringar jämfört med en verklig marknad på endast 5,6 miljarder dollar – en tiofaldig skillnad.
Detta strategiska misstag härrör från antagandet att AI:s framtid enbart ligger i allt större, mer beräkningsintensiva och centralt styrda modeller. Men nu håller detta paradigm på att falla sönder. En tyst revolution, driven av decentraliserade, mindre språkmodeller (Small Language Models, SLM), vänder den etablerade ordningen upp och ner. Dessa modeller är inte bara många gånger billigare och effektivare, utan de gör det också möjligt för företag att uppnå nya nivåer av autonomi, datasuveränitet och flexibilitet – långt ifrån kostsamt beroende av ett fåtal hyperskalare. Denna text analyserar anatomin i denna mångmiljardstora felinvestering och visar varför den verkliga AI-revolutionen inte äger rum i gigantiska datacenter, utan decentraliserat och på smidig hårdvara. Det är berättelsen om ett grundläggande maktskifte från infrastrukturleverantörerna tillbaka till användarna av tekniken.
Relaterat till detta:


NVIDIA-forskning om felallokering av AI-kapital
Uppgifterna du beskrev kommer från en forskningsartikel från NVIDIA som publicerades i juni 2025. Den fullständiga källan är:
"Små språkmodeller är framtiden för agentisk AI"
- Författare: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Utgivningsdatum: 2 juni 2025 (version 1), senaste revidering 15 september 2025 (version 2)
- Publiceringsplats: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Officiell NVIDIA Research-sida: https://research.nvidia.com/labs/lpr/slm-agents/
Det viktigaste budskapet gällande kapitalfelallokering
Forskningen dokumenterar en fundamental skillnad mellan infrastrukturinvesteringar och faktisk marknadsvolym: År 2024 investerade branschen 57 miljarder dollar i molninfrastruktur för att stödja API-tjänster för stora språkmodeller (LLM), medan den faktiska marknaden för dessa tjänster endast var 5,6 miljarder dollar. Denna tio-till-ett-skillnad tolkas i studien som en indikation på en strategisk felberäkning, eftersom branschen investerade kraftigt i centraliserad infrastruktur för storskaliga modeller, trots att 40-70 % av nuvarande LLM-arbetsbelastningar skulle kunna ersättas av mindre, specialiserade småspråkmodeller (SLM) till 1/30 av kostnaden.
Forskningskontext och författarskap
Denna studie är en ståndpunktsrapport från Deep Learning Efficiency Research Group på NVIDIA Research. Huvudförfattaren Peter Belcak är en AI-forskare på NVIDIA som fokuserar på tillförlitlighet och effektivitet hos agentbaserade system. Rapporten argumenterar utifrån tre grundpelare:
SLM:er är
- tillräckligt kraftfull
- kirurgiskt lämplig och
- ekonomiskt nödvändig
för många användningsfall i agentiska AI-system.
Forskarna betonar uttryckligen att de åsikter som uttrycks i denna artikel är författarnas egna och inte nödvändigtvis återspeglar NVIDIAs ståndpunkt som företag. NVIDIA inbjuder till kritisk diskussion och åtar sig att publicera all relaterad korrespondens på den bifogade webbplatsen.
Varför decentraliserade små språkmodeller gör den centraliserade infrastruktursatsningen föråldrad
Artificiell intelligens befinner sig vid en vändpunkt, vars konsekvenser påminner om omvälvningarna under dotcom-bubblan. En forskningsartikel från NVIDIA har avslöjat en fundamental felallokering av kapital som skakar grunden för deras nuvarande AI-strategi. Medan teknikindustrin investerade 57 miljarder dollar i centraliserad infrastruktur för storskaliga språkmodeller, växte den faktiska marknaden för deras användning till endast 5,6 miljarder dollar. Denna tio-till-ett-skillnad markerar inte bara en överskattning av efterfrågan utan avslöjar också ett grundläggande strategiskt fel när det gäller framtiden för artificiell intelligens.
En dålig investering? Miljarder spenderade på AI-infrastruktur – vad ska man göra med överskottskapaciteten?
Siffrorna talar för sig själva. År 2024 uppgick de globala utgifterna för AI-infrastruktur till mellan 80 och 87 miljarder dollar, enligt olika analyser, varav datacenter och acceleratorer stod för den stora majoriteten. Microsoft tillkännagav investeringar på 80 miljarder dollar för räkenskapsåret 2025, Google höjde sin prognos till mellan 91 och 93 miljarder dollar, och Meta planerar att investera upp till 70 miljarder dollar. Enbart dessa tre hyperskalare representerar en investeringsvolym på över 240 miljarder dollar. De totala utgifterna för AI-infrastruktur kan uppgå till mellan 3,7 och 7,9 biljoner dollar år 2030, enligt McKinseys uppskattningar.
Däremot är verkligheten på efterfrågesidan allvarlig. Marknaden för stora språkmodeller för företag uppskattades till endast 4 till 6,7 miljarder dollar för 2024, med prognoser för 2025 som sträcker sig från 4,8 till 8 miljarder dollar. Även de mest generösa uppskattningarna för marknaden för generativ AI som helhet ligger mellan 28 och 44 miljarder dollar för 2024. Den grundläggande skillnaden är tydlig: infrastrukturen byggdes för en marknad som inte existerar i denna form och omfattning.
Denna felinvestering härrör från ett antagande som alltmer visar sig vara falskt: att AI:s framtid ligger i allt större, centraliserade modeller. Hyperskalare följde en strategi för massiv skalning, drivna av övertygelsen att parameterantal och datorkraft var de avgörande konkurrensfaktorerna. GPT-3, med 175 miljarder parametrar, ansågs vara ett genombrott 2020, och GPT-4, med över en biljon parametrar, satte nya standarder. Branschen följde blint denna logik och investerade i en infrastruktur utformad för behoven hos modeller som är överdimensionerade för de flesta användningsfall.
Investeringsstrukturen illustrerar tydligt den felaktiga allokeringen. Under andra kvartalet 2025 gick 98 procent av de 82 miljarder dollar som spenderades på AI-infrastruktur till servrar, varav 91,8 procent gick till GPU- och XPU-accelererade system. Hyperskalare och molnbyggare absorberade 86,7 procent av dessa utgifter, ungefär 71 miljarder dollar under ett enda kvartal. Denna koncentration av kapital i högspecialiserad, extremt energiintensiv hårdvara för träning och härledning av massiva modeller ignorerade en grundläggande ekonomisk verklighet: de flesta företagsapplikationer kräver inte denna kapacitet.
Paradigmet bryts: Från centraliserat till decentraliserat
NVIDIA själva, den största vinnaren av den senaste infrastrukturboomen, tillhandahåller nu den analys som utmanar detta paradigm. Forskning om små språkmodeller som framtiden för agentbaserad AI hävdar att modeller med färre än 10 miljarder parametrar inte bara är tillräckliga utan också operativt överlägsna för den stora majoriteten av AI-applikationer. Studien av tre stora agentsystem med öppen källkod visade att 40 till 70 procent av anropen till stora språkmodeller kunde ersättas av specialiserade små modeller utan någon prestandaförlust.
Dessa resultat skakar om de grundläggande antagandena i den befintliga investeringsstrategin. Om MetaGPT kan ersätta 60 procent av sina LLM-anrop, Open Operator 40 procent och Cradle 70 procent med SLM:er, så har infrastrukturkapacitet byggts upp för behov som inte existerar i denna skala. Ekonomin förändras dramatiskt: En Llama 3.1B Small Language Model kostar tio till trettio gånger mindre att driva än dess större motsvarighet, Llama 3.3 405B. Finjustering kan åstadkommas på några få GPU-timmar istället för veckor. Många SLM:er körs på konsumenthårdvara, vilket helt eliminerar molnberoenden.
Det strategiska skiftet är grundläggande. Kontrollen flyttas från infrastrukturleverantörer till operatörer. Medan den tidigare arkitekturen tvingade företag in i en beroendeställning av ett fåtal hyperskalare, möjliggör decentralisering genom SLM:er ny autonomi. Modeller kan drivas lokalt, data finns kvar inom företaget, API-kostnader elimineras och leverantörsinlåsning bryts. Detta är inte bara en teknologisk transformation, utan en maktpolitisk transformation.
Den tidigare satsningen på centraliserade storskaliga modeller baserades på antagandet om exponentiella skalningseffekter. Emellertid motsäger empiriska data alltmer detta. Microsoft Phi-3, med 7 miljarder parametrar, uppnår kodgenereringsprestanda jämförbar med modeller med 70 miljarder parametrar. NVIDIA Nemotron Nano 2, med 9 miljarder parametrar, överträffar Qwen3-8B i resonemangsbenchmarks med sex gånger högre dataflöde. Effektiviteten per parameter ökar med mindre modeller, medan stora modeller ofta bara aktiverar en bråkdel av sina parametrar för en given ingång – en inneboende ineffektivitet.
Den ekonomiska överlägsenheten hos små språkmodeller
Kostnadsstrukturen visar den ekonomiska verkligheten med brutal tydlighet. Att träna modeller av GPT-4-klass uppskattas till över 100 miljoner dollar, där Gemini Ultra potentiellt kan kosta 191 miljoner dollar. Även finjustering av stora modeller för specifika domäner kan kosta tiotusentals dollar i GPU-tid. Däremot kan SLM:er tränas och finjusteras för bara några tusen dollar, ofta på en enda avancerad GPU.
Inferenskostnaderna avslöjar ännu mer drastiska skillnader. GPT-4 kostar cirka 0,03 dollar per 1 000 indatatokens och 0,06 dollar per 1 000 utdatatokens, totalt 0,09 dollar per genomsnittlig fråga. Mistral 7B, som ett SLM-exempel, kostar 0,0001 dollar per 1 000 indatatokens och 0,0003 dollar per 1 000 utdatatokens, eller 0,0004 dollar per fråga. Detta representerar en kostnadsminskning med en faktor 225. Med miljontals frågor summeras denna skillnad till betydande belopp som direkt påverkar lönsamheten.
Den totala ägandekostnaden avslöjar ytterligare dimensioner. Att självhosta en modell med 7 miljarder parametrar på bare-metal-servrar med L40S GPU:er kostar cirka 953 dollar per månad. Molnbaserad finjustering med AWS SageMaker på g5.2xlarge-instanser kostar 1,32 dollar per timme, med potentiella utbildningskostnader från 13 dollar för mindre modeller. 24/7-inferensdistribution skulle kosta cirka 950 dollar per månad. Jämfört med API-kostnader för kontinuerlig användning av stora modeller, som lätt kan nå tiotusentals dollar per månad, blir den ekonomiska fördelen tydlig.
Implementeringshastigheten är en ofta underskattad ekonomisk faktor. Medan finjustering av en stor språkmodell kan ta veckor, är SLM:er redo att användas på timmar eller några dagar. Smidigheten att snabbt reagera på nya krav, lägga till nya funktioner eller anpassa beteenden blir en konkurrensfördel. På snabbväxande marknader kan denna tidsskillnad vara skillnaden mellan framgång och misslyckande.
Skalfördelarna håller på att vända. Traditionellt sett sågs skalfördelar som fördelen med hyperskalare, som upprätthåller enorma kapaciteter och distribuerar dem över många kunder. Men med SLM:er kan även mindre organisationer skala effektivt eftersom hårdvarukraven är drastiskt lägre. En startup kan bygga en specialiserad SLM med en begränsad budget som överträffar en stor, generalistisk modell för sin specifika uppgift. Demokratiseringen av AI-utveckling håller på att bli en ekonomisk verklighet.
Tekniska grunder för disruption
De tekniska innovationer som möjliggör SLM:er är lika betydande som deras ekonomiska konsekvenser. Kunskapsdestillation, en teknik där en mindre elevmodell absorberar kunskapen från en större lärarmodell, har visat sig vara mycket effektiv. DistilBERT komprimerade framgångsrikt BERT, och TinyBERT följde liknande principer. Moderna metoder destillerar kapaciteten hos stora generativa modeller som GPT-3 till betydligt mindre versioner som uppvisar jämförbar eller bättre prestanda i specifika uppgifter.
Processen använder både de mjuka etiketterna (sannolikhetsfördelningarna) från lärarmodellen och de hårda etiketterna från originaldata. Denna kombination gör det möjligt för den mindre modellen att fånga nyanserade mönster som skulle gå förlorade i enkla input-output-par. Avancerade destillationstekniker, såsom stegvis destillation, har visat att små modeller kan uppnå bättre resultat än LLM:er även med mindre träningsdata. Detta förändrar fundamentalt ekonomin: istället för dyra, långa träningskörningar på tusentals GPU:er räcker det med riktade destillationsprocesser.
Kvantisering minskar precisionen i den numeriska representationen av modellvikter. Istället för 32-bitars eller 16-bitars flyttal använder kvantiserade modeller 8-bitars eller till och med 4-bitars heltalsrepresentationer. Minneskraven minskar proportionellt, inferenshastigheten ökar och strömförbrukningen minskar. Moderna kvantiseringstekniker minimerar förlusten av noggrannhet, vilket ofta lämnar prestandan praktiskt taget oförändrad. Detta möjliggör implementering på edge-enheter, smartphones och inbyggda system som skulle vara omöjlig med helt exakta stora modeller.
Beskärning tar bort redundanta kopplingar och parametrar från neurala nätverk. I likhet med att redigera en alltför lång text identifieras och elimineras icke-väsentliga element. Strukturerad beskärning tar bort hela neuroner eller lager, medan ostrukturerad beskärning tar bort individuella vikter. Den resulterande nätverksstrukturen är effektivare och kräver mindre minne och processorkraft, men behåller sina kärnfunktioner. I kombination med andra komprimeringstekniker uppnår beskurna modeller imponerande effektivitetsvinster.
Lågrangsfaktorisering sönderdelar matriser med stora vikter till produkter av mindre matriser. Istället för en enda matris med miljontals element lagrar och bearbetar systemet två betydligt mindre matriser. Den matematiska operationen förblir ungefär densamma, men beräkningsansträngningen minskas dramatiskt. Denna teknik är särskilt effektiv i transformatorarkitekturer, där uppmärksamhetsmekanismer dominerar stora matrismultiplikationer. Minnesbesparingarna möjliggör större kontextfönster eller batchstorlekar med samma hårdvarubudget.
Kombinationen av dessa tekniker i moderna SLM-maskiner som Microsoft Phi-serien, Google Gemma eller NVIDIA Nemotron visar potentialen. Phi-2, med endast 2,7 miljarder parametrar, överträffar Mistral- och Llama-2-modellerna med 7 respektive 13 miljarder parametrar i aggregerade riktmärken och uppnår bättre prestanda än den 25 gånger större Llama-2-70B i flerstegsuppgifter. Detta uppnåddes genom strategiskt dataval, högkvalitativ syntetisk datagenerering och innovativa skalningstekniker. Budskapet är tydligt: storlek är inte längre ett mått på kapacitet.
Marknadsdynamik och substitutionspotential
Empiriska resultat från verkliga tillämpningar stöder de teoretiska övervägandena. NVIDIAs analys av MetaGPT, ett ramverk för mjukvaruutveckling med flera agenter, identifierade att cirka 60 procent av LLM-förfrågningar är utbytbara. Dessa uppgifter inkluderar generering av standardkod, dokumentationsskapande och strukturerad utdata – alla områden där specialiserade SLM:er fungerar snabbare och mer kostnadseffektivt än generella, storskaliga modeller.
Open Operator, ett system för automatisering av arbetsflöden, visar med sin 40-procentiga substitutionspotential att även i komplexa orkestreringsscenarier kräver många deluppgifter inte LLM:ernas fulla kapacitet. Intentparsing, mallbaserad utdata och routingbeslut kan hanteras mer effektivt med finjusterade, små modeller. De återstående 60 procenten, som faktiskt kräver djupt resonemang eller bred omvärldskunskap, motiverar användningen av stora modeller.
Cradle, ett GUI-automationssystem, uppvisar den högsta substitutionspotentialen på 70 procent. Repetitiva UI-interaktioner, klicksekvenser och formulärinmatningar är idealiska för SLM:er. Uppgifterna är snävt definierade, variabiliteten är begränsad och kraven på kontextuell förståelse är låga. En specialiserad modell som tränas på GUI-interaktioner överträffar en generalist LLM i hastighet, tillförlitlighet och kostnad.
Dessa mönster upprepar sig inom olika applikationsområden. Kundtjänstens chattrobotar för vanliga frågor, dokumentklassificering, sentimentanalys, namngiven entitetsidentifiering, enkla översättningar, databasfrågor på naturligt språk – alla dessa uppgifter gynnas av SLM:er. En studie uppskattar att i typiska AI-implementeringar för företag faller 60 till 80 procent av frågorna inom kategorier där SLM:er är tillräckliga. Implikationerna för infrastrukturbehovet är betydande.
Konceptet med modellrouting blir allt viktigare. Intelligenta system analyserar inkommande frågor och dirigerar dem till rätt modell. Enkla frågor går till kostnadseffektiva SLM:er, medan komplexa uppgifter hanteras av högpresterande LLM:er. Denna hybridmetod optimerar balansen mellan kvalitet och kostnad. Tidiga implementeringar rapporterar kostnadsbesparingar på upp till 75 procent med samma eller till och med bättre totalprestanda. Själva routningslogiken kan vara en liten maskininlärningsmodell som tar hänsyn till frågornas komplexitet, kontext och användarpreferenser.
Spridningen av finjusteringsplattformar som en tjänst accelererar implementeringen. Företag utan djupgående expertis inom maskininlärning kan bygga specialiserade SLM:er som integrerar deras proprietära data och domänspecifikationer. Tidsinvesteringen minskar från månader till dagar och kostnaden från hundratusentals dollar till tusentals. Denna tillgänglighet demokratiserar i grunden AI-innovation och flyttar värdeskapandet från infrastrukturleverantörer till applikationsutvecklare.
En ny dimension av digital transformation med 'Managed AI' (Artificial Intelligence) - Plattform & B2B-lösning | Xpert Consulting

En ny dimension av digital transformation med 'Managed AI' (Artificial Intelligence) – Plattform & B2B-lösning | Xpert Consulting - Bild: Xpert.Digital
Här får du lära dig hur ditt företag kan implementera skräddarsydda AI-lösningar snabbt, säkert och utan höga inträdesbarriärer.
En hanterad AI-plattform är din heltäckande och bekymmersfria lösning för artificiell intelligens. Istället för att behöva hantera komplex teknik, dyr infrastruktur och långa utvecklingsprocesser får du en färdig lösning skräddarsydd efter dina behov från en specialiserad partner – ofta inom bara några dagar.
De viktigaste fördelarna i korthet:
⚡ Snabb implementering: Från idé till färdig applikation på dagar, inte månader. Vi levererar praktiska lösningar som skapar omedelbart mervärde.
🔒 Maximal datasäkerhet: Dina känsliga uppgifter stannar hos dig. Vi garanterar säker och korrekt behandling utan att dela data med tredje part.
💸 Ingen ekonomisk risk: Du betalar bara för resultat. Höga initiala investeringar i hårdvara, mjukvara eller personal elimineras helt.
🎯 Fokusera på din kärnverksamhet: Koncentrera dig på det du gör bäst. Vi tar hand om hela den tekniska implementeringen, driften och underhållet av din AI-lösning.
📈 Framtidssäkert och skalbart: Din AI växer med dig. Vi säkerställer kontinuerlig optimering och skalbarhet, och anpassar modellerna flexibelt till nya krav.
Mer information här:
Hur decentraliserad AI sparar företag miljarder i kostnader
De dolda kostnaderna för centraliserade arkitekturer
Att enbart fokusera på direkta beräkningskostnader underskattar den totala kostnaden för centraliserade LLM-arkitekturer. API-beroenden skapar strukturella nackdelar. Varje förfrågan genererar kostnader som skalar med användningen. För framgångsrika applikationer med miljontals användare blir API-avgifter den dominerande kostnadsfaktorn, vilket urholkar marginalerna. Företag är fångade i en kostnadsstruktur som växer proportionellt mot framgången, utan motsvarande stordriftsfördelar.
API-leverantörers prisvolatilitet utgör en affärsrisk. Prisökningar, kvotbegränsningar eller ändringar i användarvillkoren kan förstöra en applikations lönsamhet över en natt. De nyligen aviserade kapacitetsbegränsningarna från stora leverantörer, som tvingar användare att ransonera sina resurser, illustrerar sårbarheten i detta beroende. Dedikerade SLM:er eliminerar denna risk helt.
Datasuveränitet och efterlevnad blir allt viktigare. GDPR i Europa, jämförbara regleringar världen över och ökande krav på datalokalisering skapar komplexa rättsliga ramverk. Att skicka känslig företagsdata till externa API:er som kan verka i utländska jurisdiktioner medför regulatoriska och juridiska risker. Hälso- och sjukvård, finans och offentlig sektor har ofta strikta krav som utesluter eller kraftigt begränsar användningen av externa API:er. Lokala SLM:er löser i grunden dessa problem.
Problem med immateriella rättigheter är verkliga. Varje förfrågan som skickas till en API-leverantör exponerar potentiellt proprietär information. Affärslogik, produktutveckling, kundinformation – allt detta skulle teoretiskt sett kunna extraheras och användas av leverantören. Kontraktsklausuler erbjuder begränsat skydd mot oavsiktliga läckor eller illvilliga aktörer. Den enda verkligt säkra lösningen är att aldrig externalisera data.
Latens och tillförlitlighet blir lidande på grund av nätverksberoenden. Varje moln-API-förfrågan korsar internetinfrastrukturen, med förbehåll för nätverksjitter, paketförlust och varierande returtider. För realtidsapplikationer som konversationsbaserad AI eller styrsystem är dessa fördröjningar oacceptabla. Lokala SLM:er svarar på millisekunder istället för sekunder, oavsett nätverksförhållanden. Användarupplevelsen förbättras avsevärt.
Strategisk beroende av ett fåtal hyperskalare koncentrerar makt och skapar systemrisker. AWS, Microsoft Azure, Google Cloud och några andra dominerar marknaden. Avbrott i dessa tjänster har kaskadeffekter över tusentals beroende applikationer. Illusionen av redundans försvinner när man betänker att de flesta alternativa tjänster i slutändan är beroende av samma begränsade uppsättning modellleverantörer. Sann motståndskraft kräver diversifiering, helst inklusive intern kapacitet.
Relaterat till detta:

Edge computing som en strategisk vändpunkt
Konvergensen mellan SLM och edge computing skapar en transformativ dynamik. Edge-distribution tar beräkningar till där data kommer från – IoT-sensorer, mobila enheter, industriella styrenheter och fordon. Minskningen av latens är dramatisk: från sekunder till millisekunder, från molnbaserad tur och retur till lokal bearbetning. För autonoma system, förstärkt verklighet, industriell automation och medicintekniska produkter är detta inte bara önskvärt utan också avgörande.
Bandbreddsbesparingarna är betydande. Istället för kontinuerliga dataströmmar till molnet, där de bearbetas och resultaten skickas tillbaka, sker bearbetningen lokalt. Endast relevant, aggregerad information överförs. I scenarier med tusentals edge-enheter minskar detta nätverkstrafiken med flera storleksordningar. Infrastrukturkostnaderna minskar, nätverksöverbelastning undviks och tillförlitligheten ökar.
Integriteten är i grunden skyddad. Data lämnar inte längre enheten. Kameraflöden, ljudinspelningar, biometrisk information, platsdata – allt detta kan bearbetas lokalt utan att nå centrala servrar. Detta löser grundläggande integritetsproblem som uppstår med molnbaserade AI-lösningar. För konsumentapplikationer blir detta en differentierande faktor; för reglerade branscher blir det ett krav.
Energieffektiviteten förbättras på flera nivåer. Specialiserade AI-chips för kantstyrning, optimerade för att analysera små modeller, förbrukar en bråkdel av energin hos datacenters GPU:er. Att eliminera dataöverföring sparar energi i nätverksinfrastrukturen. För batteridrivna enheter håller detta på att bli en kärnfunktion. Smartphones, wearables, drönare och IoT-sensorer kan utföra AI-funktioner utan att batteritiden dramatiskt påverkas.
Offline-kapacitet skapar robusthet. Edge AI fungerar även utan internetanslutning. Funktionaliteten bibehålls i avlägsna regioner, kritisk infrastruktur eller katastrofscenarier. Detta oberoende från nätverkstillgänglighet är avgörande för många tillämpningar. Ett autonomt fordon kan inte förlita sig på molnanslutning, och en medicinteknisk apparat får inte sluta fungera på grund av instabilt Wi-Fi.
Kostnadsmodeller skiftar från operativa till kapitalutgifter. Istället för kontinuerliga molnkostnader sker en engångsinvestering i hårdvara i edge-miljö. Detta blir ekonomiskt attraktivt för långlivade applikationer med hög volym. Förutsägbara kostnader förbättrar budgetplaneringen och minskar finansiella risker. Företag återfår kontrollen över sina AI-infrastrukturutgifter.
Exempel visar potentialen. NVIDIA ChatRTX möjliggör lokal LLM-inferens på konsument-GPU:er. Apple integrerar AI på enheter i iPhones och iPads, med mindre modeller som körs direkt på enheten. Qualcomm utvecklar NPU:er för smartphones specifikt för edge AI. Google Coral och liknande plattformar riktar sig mot IoT och industriella applikationer. Marknadsdynamiken visar en tydlig trend mot decentralisering.
Heterogena AI-arkitekturer som en framtidsmodell
Framtiden ligger inte i absolut decentralisering, utan i intelligenta hybridarkitekturer. Heterogena system kombinerar SLM:er i edge-miljö för rutinmässiga, latenskänsliga uppgifter med LLM:er i molnet för komplexa resonemangskrav. Denna komplementaritet maximerar effektiviteten samtidigt som flexibilitet och kapacitet bibehålls.
Systemarkitekturen består av flera lager. I kantlagret ger högoptimerade SLM:er omedelbara svar. Dessa förväntas hantera 60 till 80 procent av förfrågningarna autonomt. För tvetydiga eller komplexa frågor som inte uppfyller lokala konfidensgränser sker eskalering till dimberäkningslagret – regionala servrar med mellanstora modeller. Endast verkligt svåra fall når den centrala molninfrastrukturen med stora, generella modeller.
Modellrouting blir alltmer en kritisk komponent. Maskininlärningsbaserade routrar analyserar förfrågningsegenskaper: textlängd, komplexitetsindikatorer, domänsignaler och användarhistorik. Baserat på dessa funktioner tilldelas förfrågan till lämplig modell. Moderna routrar uppnår över 95 % noggrannhet i komplexitetsuppskattning. De optimerar kontinuerligt baserat på faktisk prestanda och avvägningar mellan kostnad och kvalitet.
Korsuppmärksamhetmekanismer i avancerade routingsystem modellerar explicit interaktioner mellan frågor. Detta möjliggör nyanserade beslut: Är Mistral-7B tillräckligt, eller krävs GPT-4? Kan Phi-3 hantera detta, eller behövs Claude? Den finkorniga karaktären hos dessa beslut, multiplicerad över miljontals frågor, genererar betydande kostnadsbesparingar samtidigt som användarnöjdheten bibehålls eller förbättras.
Karakterisering av arbetsbelastning är grundläggande. Agentiska AI-system består av orkestrering, resonemang, verktygsanrop, minnesoperationer och generering av utdata. Alla komponenter kräver inte samma beräkningskapacitet. Orkestrering och verktygsanrop är ofta regelbaserade eller kräver minimal intelligens – idealiskt för SLM:er. Resonemang kan vara hybrid: enkel inferens på SLM:er, komplext flerstegsresonemang på LLM:er. Generering av utdata för mallar använder SLM:er, generering av kreativ text använder LLM:er.
Optimering av total ägandekostnad (TCO) tar hänsyn till hårdvaruheterogenitet. Avancerade H100-GPU:er används för kritiska LLM-arbetsbelastningar, mellanstora A100 eller L40S för mellansegmentmodeller och kostnadseffektiva T4- eller inferensoptimerade chip för SLM:er. Denna granularitet möjliggör exakt matchning av arbetsbelastningskrav och hårdvarukapacitet. Initiala studier visar en minskning av TCO på 40 till 60 procent jämfört med homogena avancerade implementeringar.
Orkestrering kräver sofistikerade programvarusystem. Kubernetes-baserade klusterhanteringssystem, kompletterade av AI-specifika schemaläggare som förstår modellens egenskaper, är avgörande. Lastbalansering tar inte bara hänsyn till förfrågningar per sekund utan även tokenlängder, modellens minnesavtryck och latensmål. Autoskalning svarar på efterfrågemönster, tillhandahåller ytterligare kapacitet eller skalar ner under perioder med låg användning.
Hållbarhet och energieffektivitet
Miljöpåverkan från AI-infrastruktur blir en central fråga. Att träna en enda stor språkmodell kan förbruka lika mycket energi som en liten stad på ett år. Datacenter som kör AI-arbetsbelastningar kan stå för 20 till 27 procent av den globala energibehovet för datacenter år 2028. Prognoser uppskattar att AI-datacenter år 2030 kan behöva 8 gigawatt för enskilda träningskörningar. Koldioxidavtrycket kommer att vara jämförbart med flygindustrins.
Energiintensiteten hos stora modeller ökar oproportionerligt. GPU:ns strömförbrukning har fördubblats från 400 till över 1000 watt på tre år. NVIDIA GB300 NVL72-system kräver enorma mängder energi, trots innovativ strömutjämningsteknik som minskar toppbelastningen med 30 procent. Kylinfrastruktur ökar energibehovet med ytterligare 30 till 40 procent. De totala koldioxidutsläppen från AI-infrastruktur kan öka med 220 miljoner ton till 2030, även med optimistiska antaganden om minskad koldioxidutsläpp i elnätet.
Små språkmodeller (SLM) erbjuder grundläggande effektivitetsvinster. Utbildning kräver 30 till 40 procent av datorkraften hos jämförbara LLM. BERT-utbildning kostar cirka 10 000 euro, jämfört med hundratals miljoner för GPT-4-klassmodeller. Inferensenergin är proportionellt lägre. En SLM-fråga kan förbruka 100 till 1 000 gånger mindre energi än en LLM-fråga. Över miljontals frågor blir detta enorma besparingar.
Edge computing förstärker dessa fördelar. Lokal bearbetning eliminerar den energi som krävs för dataöverföring över nätverk och stamnätsinfrastruktur. Specialiserade edge AI-chips uppnår energieffektivitetsfaktorer som är flera storleksordningar bättre än GPU:er för datacenter. Smartphones och IoT-enheter med milliwatt-NPU:er istället för hundratals watt servrar illustrerar skillnaden i skala.
Användningen av förnybar energi blir alltmer prioriterad. Google har åtagit sig att ha 100 procent koldioxidfri energi år 2030, och Microsoft att minska koldioxidutsläppen. Den stora omfattningen av energibehovet innebär dock utmaningar. Även med förnybara källor kvarstår frågan om nätkapacitet, lagring och intermittensitet. SLM minskar den absoluta efterfrågan, vilket gör övergången till grön AI mer genomförbar.
Koldioxidmedveten databehandling optimerar arbetsbelastningsplanering baserat på nätets koldioxidintensitet. Träningskörningar startas när andelen förnybar energi i nätet är som högst. Inferensförfrågningar dirigeras till regioner med renare energi. Denna tidsmässiga och geografiska flexibilitet, i kombination med effektiviteten hos SLM:er, skulle kunna minska koldioxidutsläppen med 50 till 70 procent.
Regelverket blir allt strängare. EU:s AI-lag inkluderar obligatoriska miljökonsekvensbedömningar för vissa AI-system. Koldioxidrapportering blir standard. Företag med ineffektiva, energiintensiva infrastrukturer riskerar efterlevnadsproblem och anseendeskador. Införandet av SLM och edge computing utvecklas från att vara en bra idé till en nödvändighet.
Demokratisering kontra koncentration
Tidigare utvecklingar har koncentrerat AI-makt i händerna på ett fåtal nyckelaktörer. The Magnificent Seven – Microsoft, Google, Meta, Amazon, Apple, NVIDIA och Tesla – dominerar. Dessa hyperskalare kontrollerar infrastruktur, modeller och i allt högre grad hela värdekedjan. Deras sammanlagda börsvärde överstiger 15 biljoner dollar. De representerar nästan 35 procent av S&P 500-börsvärdet, en koncentrationsrisk av exempellös historisk betydelse.
Denna koncentration har systemiska konsekvenser. Ett fåtal företag sätter standarder, definierar API:er och kontrollerar åtkomst. Mindre aktörer och utvecklingsländer blir beroende. Nationernas digitala suveränitet utmanas. Europa, Asien och Latinamerika svarar med nationella AI-strategier, men dominansen av USA-baserade hyperskalare är fortfarande överväldigande.
Små språkmodeller (SLM) och decentralisering förändrar denna dynamik. SLM med öppen källkod som Phi-3, Gemma, Mistral och Llama demokratiserar tillgången till toppmodern teknik. Universitet, startups och medelstora företag kan utveckla konkurrenskraftiga applikationer utan hyperskaleringsresurser. Innovationsbarriären sänks dramatiskt. Ett litet team kan skapa en specialiserad SLM som överträffar Google eller Microsoft i sin nisch.
Den ekonomiska lönsamheten förändras till förmån för mindre aktörer. Medan utveckling av juridikteknik kräver budgetar på hundratals miljoner, är SLM genomförbara med fem- till sexsiffriga belopp. Molndemokratisering möjliggör tillgång till utbildningsinfrastruktur på begäran. Finjustering av tjänster abstraherar komplexitet. Inträdesbarriären för AI-innovation minskar från oöverkomligt hög till hanterbar.
Datasuveränitet blir verklighet. Företag och myndigheter kan vara värd för modeller som aldrig når externa servrar. Känslig data förblir under deras egen kontroll. GDPR-efterlevnad förenklas. EU:s AI-lag, som ställer strikta krav på transparens och ansvarsskyldighet, blir mer hanterbar med proprietära modeller istället för svarta box-API:er.
Innovationsdiversiteten ökar. Istället för en monokultur av GPT-liknande modeller framträder tusentals specialiserade SLM:er för specifika domäner, språk och uppgifter. Denna mångfald är robust mot systematiska fel, ökar konkurrensen och accelererar framsteg. Innovationslandskapet blir polycentriskt snarare än hierarkiskt.
Riskerna för koncentration blir tydliga. Beroende av ett fåtal leverantörer skapar enskilda felpunkter (single points of failure). Avbrott hos AWS eller Azure lamslår globala tjänster. Politiska beslut av en hyperskalare, såsom användningsbegränsningar eller regionala lockouts, har kaskadeffekter. Decentralisering genom SLM minskar i grunden dessa systemrisker.
Den strategiska omställningen
För företag innebär denna analys grundläggande strategiska justeringar. Investeringsprioriteringar skiftar från centraliserad molninfrastruktur till heterogena, distribuerade arkitekturer. Istället för maximalt beroende av hyperskalerande API:er är målet autonomi genom interna SLM:er. Kompetensutveckling fokuserar på finjustering av modeller, edge-distribution och hybridorkestrering.
Beslutet att bygga kontra köpa håller på att förändras. Medan det tidigare ansågs rationellt att köpa API-åtkomst, blir det alltmer attraktivt att utveckla interna, specialiserade SLM:er. Den totala ägandekostnaden över tre till fem år gynnar tydligt interna modeller. Strategisk kontroll, datasäkerhet och anpassningsförmåga ger ytterligare kvalitativa fördelar.
För investerare signalerar denna felallokering försiktighet gällande rena infrastruktursatsningar. Datacenter-REIT:er, GPU-tillverkare och hyperskalare kan uppleva överkapacitet och minskande utnyttjandegrad om efterfrågan inte blir som prognostiserat. Värdemigration sker mot leverantörer av SLM-teknik, edge AI-chip, orkestreringsprogramvara och specialiserade AI-applikationer.
Den geopolitiska dimensionen är betydande. Länder som prioriterar nationell AI-suveränitet gynnas av SLM-skiftet. Kina investerar 138 miljarder dollar i inhemsk teknologi, och Europa investerar 200 miljarder dollar i InvestAI. Dessa investeringar kommer att bli mer effektiva när absolut skala inte längre är den avgörande faktorn, utan snarare smarta, effektiva och specialiserade lösningar. Den multipolära AI-världen håller på att bli verklighet.
Regelverket utvecklas parallellt. Dataskydd, algoritmisk ansvarsskyldighet, miljöstandarder – allt detta gynnar decentraliserade, transparenta och effektiva system. Företag som tidigt anammar SLM och edge computing positionerar sig gynnsamt för att följa framtida regler.
Talanglandskapet förändras. Medan tidigare bara elituniversitet och ledande teknikföretag hade resurser för LLM-forskning, kan nu praktiskt taget vilken organisation som helst utveckla SLM:er. Kompetensbristen som hindrar 87 procent av organisationerna från att anlita AI mildras av lägre komplexitet och bättre verktyg. Produktivitetsvinster från AI-stödd utveckling förstärker denna effekt.
Sättet vi mäter avkastningen på AI-investeringar håller på att förändras. Istället för att fokusera på rå beräkningskapacitet blir effektivitet per uppgift det viktigaste måttet. Företag rapporterar en genomsnittlig avkastning på investeringar på 5,9 procent på AI-initiativ, vilket är betydligt lägre än förväntningarna. Anledningen ligger ofta i att man använder överdimensionerade, dyra lösningar för enkla problem. Övergången till uppgiftsoptimerade SLM:er kan dramatiskt förbättra denna avkastning.
Analysen avslöjar en bransch vid en vändpunkt. Felinvesteringen på 57 miljarder dollar är mer än bara en överskattning av efterfrågan. Den representerar en grundläggande strategisk felberäkning av arkitekturen för artificiell intelligens. Framtiden tillhör inte centraliserade jättar, utan decentraliserade, specialiserade och effektiva system. Små språkmodeller är inte sämre än stora språkmodeller – de är överlägsna för den stora majoriteten av verkliga tillämpningar. De ekonomiska, tekniska, miljömässiga och strategiska argumenten sammanfaller till en tydlig slutsats: AI-revolutionen kommer att vara decentraliserad.
Maktförskjutningen från leverantörer till operatörer, från hyperskalare till applikationsutvecklare, från centralisering till distribution markerar en ny fas i AI-utvecklingen. De som inser och omfamnar denna övergång tidigt kommer att bli vinnarna. De som håller fast vid den gamla logiken riskerar att deras dyra infrastrukturer blir strandade tillgångar, omkörda av mer flexibla och effektiva alternativ. De 57 miljarderna dollarna är inte bara bortkastade – de markerar början på slutet för ett paradigm som redan är föråldrat.
Din globala partner för marknadsföring och affärsutveckling
☑️ Vårt affärsspråk är engelska eller tyska
☑️ NYTT: Korrespondens på ditt modersmål!

Konrad Wolfenstein
Jag och mitt team står gärna till er förfogande som er personliga rådgivare.
Du kan kontakta mig genom att fylla i kontaktformuläret här wolfenstein@xpert.digital:eller helt enkelt ringa mig på +49 7348 4088 965. Min e-postadress är
Jag ser fram emot vårt gemensamma projekt.
☑️ Stöd till små och medelstora företag inom strategi, konsultation, planering och implementering
☑️ Skapande eller omstrukturering av den digitala strategin och digitaliseringen
☑️ Utökning och optimering av internationella säljprocesser
☑️ Globala och digitala B2B-handelsplattformar
☑️ Pionjär inom affärsutveckling / marknadsföring / PR / mässor
🎯🎯🎯 Dra nytta av Xpert.Digitals omfattande, femfaldiga expertis i ett heltäckande tjänstepaket | BD, R&D, XR, PR och optimering av digital synlighet

Dra nytta av Xpert.Digitals omfattande, femfaldiga expertis i ett heltäckande tjänstepaket | FoU, XR, PR och optimering av digital synlighet - Bild: Xpert.Digital
Xpert.Digital besitter djupgående kunskap inom olika branscher. Detta gör det möjligt för oss att utveckla skräddarsydda strategier som är exakt anpassade till kraven och utmaningarna inom just ditt marknadssegment. Genom att kontinuerligt analysera marknadstrender och övervaka branschutvecklingen kan vi agera proaktivt och erbjuda innovativa lösningar. Kombinationen av erfarenhet och expertis genererar mervärde och ger våra kunder en avgörande konkurrensfördel.
Mer information här: