
Publicerad den: 15 april 2025 / Uppdaterad den: 15 april 2025 – Författare: Konrad Wolfenstein

AI-sökningsrankning: Perplexity Sonars AI-modeller är ledande inom AI-sökningslandskapet – Bild: Xpert.Digital
Sonar Reasoning Pro-High: Perplexitys språng till toppen av AI-sökning
AI-söksystem i övergång: Perplexitys milstolpe i utvecklingen
Perplexitys Sonar-modeller har uppnått imponerande resultat i den senaste LM Search Arena-utvärderingen, med Sonar-Reasoning-Pro-High ranking tillsammans med Googles Gemini-2.5-Pro-Grounding. Denna ranking representerar en betydande milstolpe i utvecklingen av AI-söksystem och understryker Perplexitys ledande position inom detta mycket konkurrensutsatta område.
Lämplig för detta:

Utvärderingen av LM Search Arena
LM Search Arena är en ny utvärderingsplattform utvecklad av LM Arena för att bedöma sökförbättrade AI-system baserat på mänskliga preferenser. Till skillnad från tidigare riktmärken som SimpleQA, som fokuserade på snäv faktabaserad noggrannhet, utvärderar Search Arena hur modeller presterar på verkliga användarfrågor inom områden som programmering, skrivande, forskning och rekommendationer.
Utvärderingen ägde rum mellan 18 mars och 13 april 2025 och samlade in över 10 000 röster från människors preferenser för 11 modeller. Användare ombads att skicka in frågor och sedan betygsätta vilket modellsvar som bäst uppfyllde deras informationsbehov.
Enastående prestanda hos sonarmodellerna
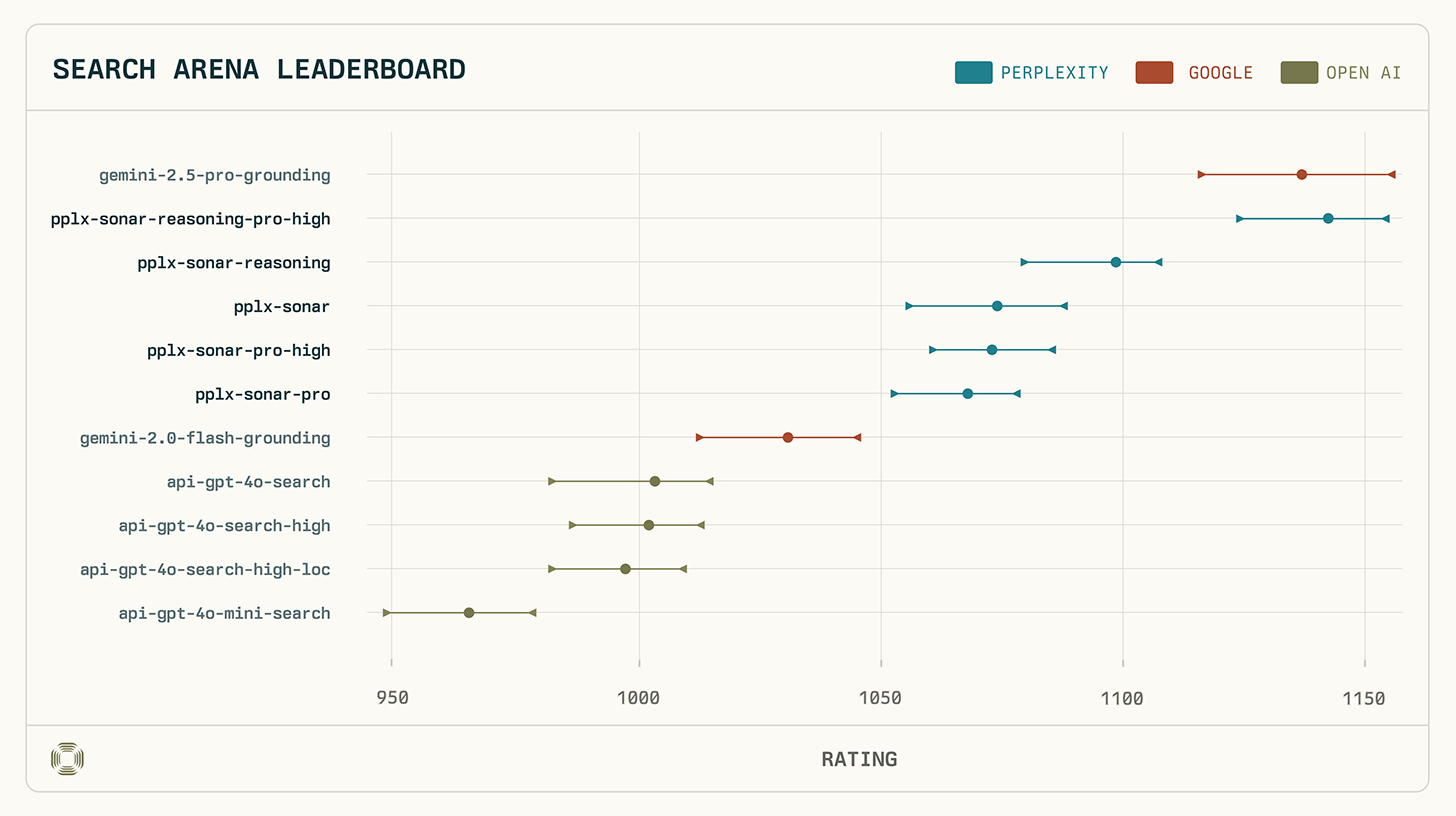
AI-sökningsrankning: Enastående prestanda hos sonarmodeller – Bild: Förvirring
Perplexitys Sonar-Reasoning-Pro-High uppnådde ett Arena-resultat på 1136 (±21/−19), vilket statistiskt sett motsvarar Googles Gemini-2.5-Pro-Grounding (1142 +14/-17), och säkrade därmed en delad topposition. Särskilt anmärkningsvärt är att Sonar-Reasoning-Pro-High i direkta jämförelser överträffade Gemini-2.5-Pro-Grounding i 53 % av fallen.
Att förvirring dominerar i utvärderingen illustreras av följande rangordning:
- Gemini 2.5 Pro Jordning (1142 poäng)
- Sonar Reasoning Pro-High (1136 poäng)
- Sonarresonemang (1097 poäng)
- Ekolod (1072 poäng)
- Sonar-Pro-High (1071 poäng)
- Sonar-Pro (1066 poäng)
Alla Perplexity-modeller hamnade i topprankningen och presterade betydligt bättre än andra utvärderade modeller från Google (Gemini-2.0-Flash-Grounding) och OpenAI (GPT-4o Search).
Viktiga faktorer för framgång
Search Arena identifierade tre faktorer som korrelerade starkt med mänskliga preferenser:
Mer omfattande svar
Längre svar föredrogs av användarna (koefficient 0,255, p < 0,05). Sonar-modellerna ger omfattande och detaljerad information om ett brett spektrum av ämnen, vilket leder till högre användarnöjdhet.
Överlägsenhet i källhänvisningar
Ett högre antal citat korrelerade starkt med användarnas preferenser (koefficient 0,234, p < 0,05). Sonar-modellerna utför en djupare sökning och citerar i genomsnitt 2–3 gånger fler källor än jämförbara Gemini-modeller. Denna omfattande användning av källor säkerställer att informationen som tillhandahålls är väl dokumenterad och trovärdig.
Använda olika källor
Utvärderingen visade att citat från community-webbkällor var särskilt värdefulla. Sonar-modellerna kännetecknas av effektiv användning av olika källor, inklusive YouTube, community-plattformar och auktoritativa källor.
Kontrollexperiment bekräftade dessa resultat och visade att sökdjupet är en signifikant prestandaskillnad mellan modellerna. När man kontrollerade för citeringar konvergerade modellens ranking, vilket tyder på att sökdjupet är en avgörande differentierande faktor.
Lämplig för detta:

Tekniken bakom sonar
Perplexitys sonarmodell är baserad på Llama 3.3 70B och har specifikt förbättrats för att optimera svarskvaliteten och användarupplevelsen. Den har tränats för att förbättra den faktiska noggrannheten och läsbarheten hos svaren.
Hastighet och prestanda
Sonar drivs av Cerebras inferensinfrastruktur och levererar svar med en imponerande hastighet – 1200 tokens per sekund, vilket möjliggör nästan omedelbar svarsgenerering. Denna hastighet är nästan 10 gånger snabbare än jämförbara modeller som Gemini 2.0 Flash.
Användarpreferenser och prestandajämförelse
Omfattande A/B-tester visade att Sonar avsevärt överträffar modeller som GPT-4o mini och Claude 3.5 Haiku, och till och med matchar eller överträffar prestandan hos toppmodeller som GPT-4o och Claude 3.5 Sonnet när det gäller användarnöjdhet.
Sonar API: Tillgänglighet för utvecklare
Perplexity erbjuder även sin sonarteknik via API:er, vilket gör det möjligt för utvecklare att integrera AI-drivna sökfunktioner i sina applikationer. Det finns två huvudversioner av API:et:
Sonar API
Standard-API:et för Sonar är lätt, kostnadseffektivt, snabbt och enkelt att använda. Det utformades för företag som behöver enkla frågor och svar och är optimerade för hastighet.
Sonar Pro API
För företag som kräver mer avancerade funktioner erbjuder Sonar Pro API möjligheten att hantera mer komplexa frågor i flera steg. Det genererar i genomsnitt dubbelt så många källhänvisningar per sökning som standardversionen och har ett större kontextfönster för längre och mer nyanserade frågor.
Prisstrukturen återspeglar dessa skillnader: Standard Sonar kostar 5 dollar per 1 000 sökningar plus 1 dollar per 750 000 ord (kombinerad inmatning och utmatning). Sonar Pro behåller samma 5 dollar per 1 000 sökningar men debiterar 3 dollar per 750 000 inmatade ord och 15 dollar per 750 000 genererade ord.
Från noggrannhetsfaktorer till användarvänlighet: Perplexitys ekolod imponerar
De enastående resultaten i LM Search Arena-utvärderingen bekräftar att Perplexitys Sonar-modeller är bland de ledande AI-söksystemen. Genom att kombinera faktamässig noggrannhet, omfattande källhänvisningar och djupgående sökfunktioner erbjuder de en överlägsen användarupplevelse.
Dessa framgångar understryker Perplexitys position som en innovatör inom AI-driven sökning och informationsleverans. Den kontinuerliga förbättringen av deras modeller baserat på användarfeedback indikerar ytterligare potential för framtida utvecklingar.
För Perplexity-användare innebär dessa resultat att de har tillgång till högsta noggrannhet, omfattande källhänvisning och högkvalitativa svar inom en mängd olika ämnen. Pro-användare kan ytterligare dra nytta av dessa kraftfulla modeller genom att ställa in Sonar som standardmodell i inställningarna.
Sonars starka resultat i Search Arena Evaluation understryker inte bara Perplexitys tekniska expertis, utan pekar också ut vägen för framtiden för AI-sökning: mer exakt, mer omfattande och med en djupare förståelse för användarnas informationsbehov.
Lämplig för detta:
Din AI -omvandling, AI -integration och AI -plattformsindustrin Expert
☑ Vårt affärsspråk är engelska eller tyska
☑ Nytt: korrespondens på ditt nationella språk!

Konrad Wolfenstein
Jag är glad att vara tillgänglig för dig och mitt team som personlig konsult.
Du kan kontakta mig genom att fylla i kontaktformuläret eller helt enkelt ringa mig på +49 89 674 804 (München) . Min e -postadress är: Wolfenstein ∂ xpert.digital
Jag ser fram emot vårt gemensamma projekt.








