


Ett försök att förklara AI: Hur fungerar artificiell intelligens och hur tränas den? – Bild: Xpert.Digital
📊 Från datainmatning till modellprediktion: AI-processen
Hur fungerar artificiell intelligens (AI)? 🤖
Artificiell intelligens (AI) kan delas in i flera tydligt definierade steg. Vart och ett av dessa steg är avgörande för det slutliga resultatet som AI:n levererar. Processen börjar med datainmatning och slutar med modellprediktion och eventuell feedback eller vidare träningsomgångar. Dessa faser beskriver den process som nästan alla AI-modeller går igenom, oavsett om det är enkla regeluppsättningar eller mycket komplexa neurala nätverk.
1. Datainmatningen 📊
Grunden för all artificiell intelligens är den data den arbetar med. Denna data kan existera i olika former, såsom bilder, text, ljudfiler eller videor. AI:n använder denna rådata för att känna igen mönster och fatta beslut. Kvaliteten och kvantiteten på data spelar en avgörande roll här, eftersom de avsevärt påverkar hur bra eller dåligt modellen i slutändan kommer att prestera.
Ju mer omfattande och exakt data är, desto bättre kan AI:n lära sig. Till exempel, när man tränar en AI för bildbehandling behöver den en stor mängd bilddata för att korrekt identifiera olika objekt. För språkmodeller är det textdata som hjälper AI:n att förstå och generera mänskligt tal. Datainmatning är det första och ett av de viktigaste stegen, eftersom kvaliteten på förutsägelser bara kan vara så bra som de underliggande data. En känd princip inom datavetenskap beskriver detta med talesättet "garbage in, garbage out" – dålig data leder till dåliga resultat.
2. Dataförbehandling 🧹
När data har matats in måste de förberedas innan de kan matas in i själva modellen. Denna process kallas dataförbehandling. Målet här är att omvandla data till ett format som modellen kan bearbeta optimalt.
Ett vanligt steg i förbehandling är datanormalisering. Detta innebär att data placeras inom ett enhetligt värdeområde så att den behandlas konsekvent av modellen. Ett exempel skulle vara att skala alla pixelvärden i en bild till ett intervall från 0 till 1, istället för 0 till 255.
En annan viktig del av förbehandlingen är funktionsutvinning. Detta innebär att man extraherar specifika funktioner från rådata som är särskilt relevanta för modellen. Vid bildbehandling kan dessa vara kanter eller specifika färgmönster, medan man vid textbehandling extraherar relevanta nyckelord eller meningsstrukturer. Förbehandling är avgörande för att göra AI:ns inlärningsprocess mer effektiv och precis.
3. Modellen 🧩
Modellen är kärnan i all artificiell intelligens. Här analyseras och bearbetas data baserat på algoritmer och matematiska beräkningar. En modell kan existera i olika former. En av de mest kända modellerna är det neurala nätverket, som är baserat på hur den mänskliga hjärnan fungerar.
Neurala nätverk består av flera lager av artificiella neuroner som bearbetar och vidarebefordrar information. Varje lager tar utdata från det föregående lagret och bearbetar dem vidare. Inlärningsprocessen för ett neuralt nätverk innebär att man justerar vikterna på kopplingarna mellan dessa neuroner så att nätverket kan göra alltmer exakta förutsägelser eller klassificeringar. Denna justering uppnås genom träning, där nätverket får tillgång till stora mängder exempeldata och iterativt förbättrar sina interna parametrar (vikter).
Förutom neurala nätverk används många andra algoritmer i AI-modeller. Dessa inkluderar beslutsträd, slumpmässiga skogar, stödvektormaskiner och många fler. Vilken algoritm som används beror på den specifika uppgiften och tillgängliga data.
4. Modellprognosen 🔍
När modellen har tränats med data kan den göra förutsägelser. Detta steg kallas modellprediktion. AI:n tar emot en indata och returnerar, baserat på de mönster den hittills har lärt sig, en utdata, det vill säga en förutsägelse eller ett beslut.
Denna förutsägelse kan ta sig olika uttryck. I en bildklassificeringsmodell kan AI:n till exempel förutsäga vilket objekt som visas i en bild. I en språkmodell kan den förutsäga vilket ord som kommer härnäst i en mening. I finansiella förutsägelser kan AI:n prognostisera hur aktiemarknaden kommer att prestera.
Det är viktigt att betona att prediktionernas noggrannhet i hög grad beror på kvaliteten på träningsdata och modellens arkitektur. En modell som tränas på otillräcklig eller partisk data är mycket sannolikt att göra felaktiga prediktioner.
5. Feedback och utbildning (valfritt) ♻️
En annan viktig aspekt av hur en AI fungerar är feedbackmekanismen. Här kontrolleras modellen regelbundet och optimeras ytterligare. Denna process sker antingen under träning eller efter modellens förutsägelse.
Om modellen gör felaktiga förutsägelser kan den genom feedback lära sig att känna igen dessa fel och justera sina interna parametrar därefter. Detta görs genom att jämföra modellens förutsägelser med de faktiska resultaten (t.ex. med kända data för vilka de korrekta svaren redan finns). En typisk metod i detta sammanhang är så kallad övervakad inlärning, där AI:n lär sig från exempeldata som redan innehåller de korrekta svaren.
En vanlig återkopplingsmetod är backpropagation-algoritmen som används i neurala nätverk. Här propageras de fel som modellen gör bakåt genom nätverket för att justera vikterna på de neurala kopplingarna. På så sätt lär sig modellen av sina misstag och blir alltmer exakt i sina förutsägelser.
Träningens roll 🏋️♂️
Att träna en AI är en iterativ process. Ju mer data modellen ser och ju oftare den tränas på den datan, desto mer exakta blir dess förutsägelser. Det finns dock begränsningar: En övertränad modell kan utveckla så kallade "överanpassningsproblem". Det betyder att den memorerar träningsdata så väl att den ger sämre resultat på ny, okänd data. Därför är det viktigt att träna modellen på ett sådant sätt att den generaliserar, vilket innebär att den också kan göra bra förutsägelser på ny data.
Förutom vanlig träning finns det även metoder som transfer learning. Här används en modell som redan har tränats på en stor datamängd för en ny, liknande uppgift. Detta sparar tid och beräkningskraft, eftersom modellen inte behöver tränas helt från grunden.
Få ut det mesta av dina styrkor 🚀
Artificiell intelligens (AI) fungerar på ett komplext samspel mellan olika steg. Från datainmatning och förbehandling till modellträning, förutsägelser och feedback påverkar många faktorer AI:s noggrannhet och effektivitet. En välutbildad AI kan erbjuda enorma fördelar inom många områden i livet – från att automatisera enkla uppgifter till att lösa komplexa problem. Det är dock lika viktigt att förstå AI:s begränsningar och potentiella fallgropar för att kunna utnyttja dess styrkor på bästa sätt.
🤖📚 Enkelt förklarat: Hur tränas en AI?
🤖📊 AI-inlärningsprocess: Registrera, länka och lagra
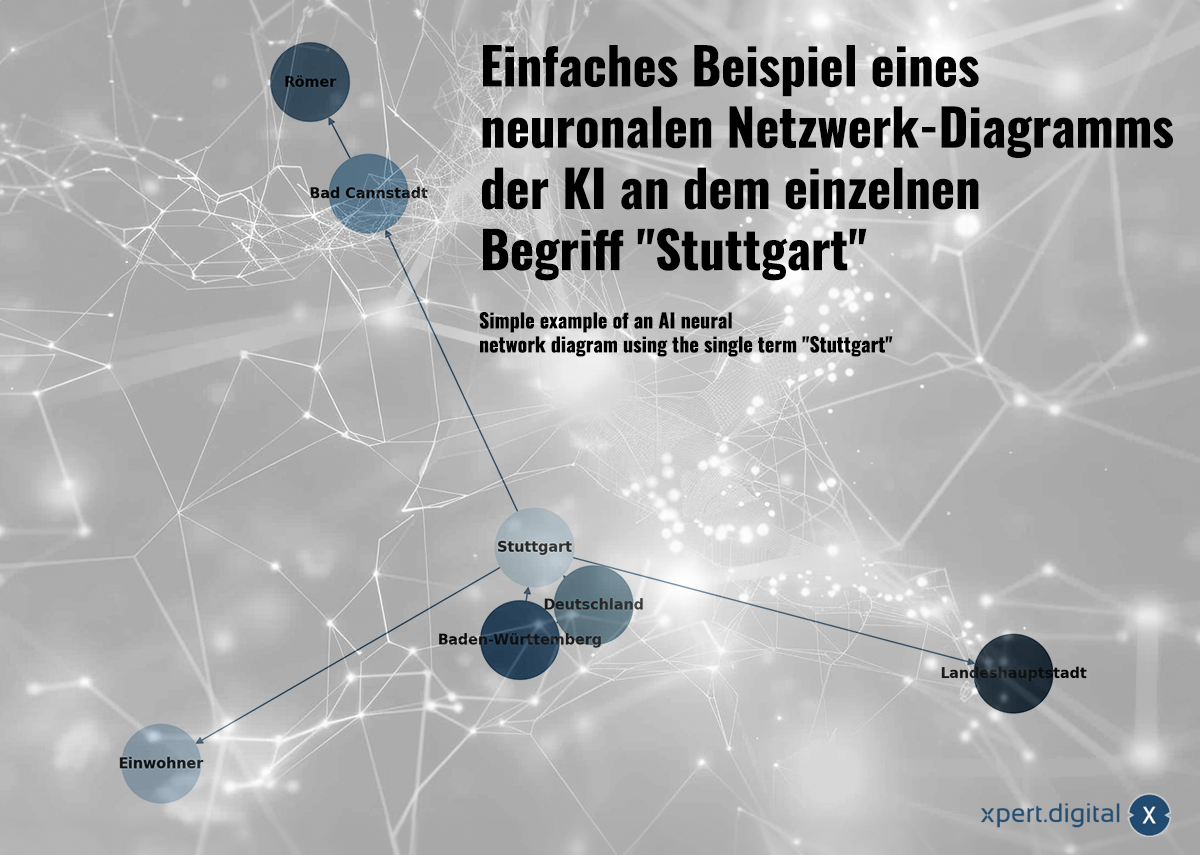
Enkelt exempel på ett AI-neuralt nätverksdiagram med termen "Stuttgart" – Bild: Xpert.Digital
🌟 Samla in och förbered data
Det första steget i AI-inlärningsprocessen är att samla in och förbereda data. Dessa data kan komma från olika källor, såsom databaser, sensorer, texter eller bilder.
🌟 Relationsdata (neurala nätverk)
Den insamlade datan länkas samman i ett neuralt nätverk. Varje datapaket representeras av kopplingar i ett nätverk av "neuroner" (noder). Ett enkelt exempel med staden Stuttgart kan se ut så här:
a) Stuttgart är en stad i Baden-Württemberg
b) Baden-Württemberg är en delstat i Tyskland
c) Stuttgart är en stad i Tyskland
d) Stuttgart hade en befolkning på 633 484 år 2023
e) Bad Cannstatt är en stadsdel i Stuttgart
f) Bad Cannstatt grundades av romarna
g) Stuttgart är delstatshuvudstad i Baden-Württemberg
Beroende på datamängdens storlek genereras parametrarna för potentiella utdata med hjälp av AI-modellen. Till exempel har GPT-3 cirka 175 miljarder parametrar!
🌟 Spara och anpassa (inlärning)
Data matas in i det neurala nätverket. Den passerar genom AI-modellen och bearbetas via kopplingar (liknande synapser). Vikterna (parametrarna) mellan neuronerna justeras för att träna modellen eller för att utföra en uppgift.
Till skillnad från konventionella lagringsmetoder som direktåtkomst, indexerad åtkomst, sekventiell eller batchlagring, lagrar neurala nätverk data på ett okonventionellt sätt. ”Datan” lagras i vikterna och förspänningarna hos kopplingarna mellan neuronerna.
Själva "lagringen" av information i ett neuralt nätverk sker genom justering av kopplingsvikterna mellan neuronerna. AI-modellen "lär sig" genom att kontinuerligt justera dessa vikter och biaser baserat på indata och en definierad inlärningsalgoritm. Detta är en kontinuerlig process där modellen kan göra mer exakta förutsägelser genom upprepade justeringar.
AI-modellen kan ses som ett slags programmering, eftersom den skapas genom definierade algoritmer och matematiska beräkningar, och justeringen av dess parametrar (vikter) förbättras kontinuerligt för att göra korrekta förutsägelser. Detta är en pågående process.
Biaser är ytterligare parametrar i neurala nätverk som läggs till de viktade ingångsvärdena för en neuron. De gör det möjligt att vikta parametrarna (viktiga, mindre viktiga, etc.), vilket gör AI:n mer flexibel och exakt.
Neurala nätverk kan inte bara lagra individuella fakta, utan även känna igen samband mellan data genom mönsterigenkänning. Exemplet med Stuttgart illustrerar hur kunskap kan matas in i ett neuralt nätverk, men neurala nätverk lär sig inte genom explicit kunskap (som i detta enkla exempel), utan snarare genom analys av datamönster. Därför kan neurala nätverk inte bara lagra individuella fakta, utan också lära sig vikter och samband mellan indata.
Denna process ger en begriplig introduktion till hur AI, och neurala nätverk i synnerhet, fungerar, utan att fördjupa sig i tekniska detaljer. Den visar att information inte lagras i neurala nätverk som i konventionella databaser, utan snarare genom att justera kopplingarna (vikterna) inom nätverket.
🤖📚 Mer detaljerat: Hur tränas en AI?
🏋️♂️ Att träna en AI, särskilt en maskininlärningsmodell, innebär flera steg. AI-träning baseras på kontinuerlig optimering av modellparametrar genom feedback och justeringar tills modellen presterar bäst på den tillhandahållna datan. Här är en detaljerad förklaring av hur denna process fungerar:
1. 📊 Samla in och förbered data
Data är grunden för AI-träning. Det består vanligtvis av tusentals eller miljontals exempel som systemet är avsett att analysera. Exempel inkluderar bilder, text eller tidsseriedata.
Data måste rensas och normaliseras för att undvika onödiga felkällor. Ofta omvandlas data till funktioner som innehåller relevant information.
2. 🔍 Definiera modell
En modell är en matematisk funktion som beskriver sambanden i data. I neurala nätverk, som ofta används för AI, består modellen av flera lager av neuroner som är sammankopplade.
Varje neuron utför en matematisk operation för att bearbeta indata och skickar sedan en signal till nästa neuron.
3. 🔄 Initiera vikter
Förbindelserna mellan neuroner har vikter som initialt sätts slumpmässigt. Dessa vikter avgör hur starkt en neuron reagerar på en signal.
Målet med träningen är att justera dessa vikter så att modellen gör bättre förutsägelser.
4. ➡️ Framåtriktad spridning
Under framåtpasseringen bearbetas indata av modellen för att få en förutsägelse.
Varje lager bearbetar data och skickar den vidare till nästa lager tills det sista lagret levererar resultatet.
5. ⚖️ Beräkna förlustfunktionen
Förlustfunktionen mäter hur väl modellens förutsägelser står sig i jämförelse med de faktiska värdena (etiketterna). Ett vanligt mått är felet mellan det förutspådda och det faktiska svaret.
Ju högre förlusten är, desto sämre blir modellens förutsägelse.
6. 🔙 Bakåtpropagering
Vid omvänd iteration spåras felet tillbaka från modellens utdata till de föregående lagren.
Felet omfördelas till kopplingarnas vikter, och modellen justerar vikterna så att felen blir mindre.
Detta görs med hjälp av gradientnedgång: Gradientvektorn beräknas, vilken indikerar hur vikterna ska ändras för att minimera felet.
7. 🔧 Uppdatera vikter
Efter att felet har beräknats uppdateras vikterna för kopplingarna med en liten justering baserad på inlärningshastigheten.
Inlärningshastigheten avgör hur mycket vikterna ändras i varje steg. För stora förändringar kan göra modellen instabil, medan för små förändringar leder till en långsam inlärningsprocess.
8. 🔁 Upprepa (epoker)
Denna process med framåtriktad passning, felberäkning och viktuppdatering upprepas, ofta över flera epoker (passerar genom hela datamängden), tills modellen uppnår acceptabel noggrannhet.
Med varje era lär sig modellen lite mer och justerar sina vikter ytterligare.
9. 📉 Validering och testning
Efter att modellen har tränats testas den på en validerad datamängd för att kontrollera hur väl den generaliserar. Detta säkerställer att den inte bara har "memorerat" träningsdata, utan också gör bra förutsägelser på okända data.
Testdata hjälper till att mäta modellens slutliga prestanda innan den används i praktiken.
10. 🚀 Optimering
Ytterligare steg för att förbättra modellen inkluderar hyperparameterjustering (t.ex. justering av inlärningshastigheten eller nätverksstrukturen), regularisering (för att undvika överanpassning) eller ökning av datamängden.
📊🔙 Artificiell intelligens: Göra AI:s svarta låda begriplig, lättförståelig och förklarbar med Explainable AI (XAI), värmekartor, surrogatmodeller eller andra lösningar


Artificiell intelligens: Att göra AI:s svarta låda begriplig, begriplig och förklarbar med Explainable AI (XAI), värmekartor, surrogatmodeller eller andra lösningar – Bild: Xpert.Digital
Den så kallade "svarta lådan" inom artificiell intelligens (AI) representerar ett betydande och akut problem. Även experter står ofta inför utmaningen att inte helt förstå hur AI-system fattar sina beslut. Denna brist på transparens kan orsaka betydande problem, särskilt inom kritiska områden som ekonomi, politik och medicin. En läkare som förlitar sig på ett AI-system för diagnos och behandlingsrekommendationer måste ha förtroende för de beslut som fattas. Men om en AI:s beslutsprocess inte är tillräckligt transparent uppstår osäkerhet, vilket potentiellt kan leda till bristande förtroende – och detta i situationer där människoliv kan stå på spel.
Mer information här:
Vi finns här för dig - Konsulttjänster - Planering - Implementering - Projektledning
☑️ Stöd till små och medelstora företag inom strategi, konsultation, planering och implementering
☑️ Skapande eller omstrukturering av den digitala strategin och digitaliseringen
☑️ Utökning och optimering av internationella säljprocesser
☑️ Globala och digitala B2B-handelsplattformar
☑️ Pionjär inom affärsutveckling

Konrad Wolfenstein
Jag skulle gärna fungera som din personliga rådgivare.
Du kan kontakta mig genom att fylla i kontaktformuläret nedan eller helt enkelt ringa mig på +49 7348 4088 965 .
Jag ser fram emot vårt gemensamma projekt.
Skriv till mig




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital är ett nav för industrin med fokus på digitalisering, maskinteknik, logistik/intralogistik och solceller.
Med vår 360° affärsutvecklingslösning stödjer vi välrenommerade företag från nya affärer till eftermarknadsförsäljning.
Marknadsinformation, smarketing, marknadsautomation, innehållsutveckling, PR, utskick, personliga sociala medier och lead nurturing är en del av våra digitala verktyg.
Du hittar mer information på: www.xpert.digital - www.xpert.solar - www.xpert.plus
Håll kontakten











