


Покушај објашњења вештачке интелигенције: Како функционише вештачка интелигенција и како се обучава? – Слика: Xpert.Digital
📊 Од уноса података до предвиђања модела: Процес вештачке интелигенције
Како функционише вештачка интелигенција (ВИ)? 🤖
Функционисање вештачке интелигенције (ВИ) може се поделити на неколико јасно дефинисаних корака. Сваки од ових корака је кључан за коначни резултат који ВИ испоручује. Процес почиње уносом података, а завршава се предвиђањем модела и евентуалним повратним информацијама или даљим рундама обуке. Ове фазе описују процес кроз који пролазе скоро сви модели ВИ, без обзира да ли су у питању једноставни скупови правила или веома сложене неуронске мреже.
1. Унос података 📊
Основа сваке вештачке интелигенције су подаци са којима ради. Ови подаци могу постојати у различитим облицима, као што су слике, текст, аудио датотеке или видео снимци. Вештачка интелигенција користи ове сирове податке да би препознала обрасце и доносила одлуке. Квалитет и количина података овде играју кључну улогу, јер значајно утичу на то колико ће модел на крају добро или лоше функционисати.
Што су подаци свеобухватнији и тачнији, то вештачка интелигенција може боље да учи. На пример, приликом обучавања вештачке интелигенције за обраду слика, потребна јој је велика количина података о сликама да би правилно идентификовала различите објекте. За језичке моделе, текстуални подаци помажу вештачкој интелигенцији да разуме и генерише људски говор. Унос података је први и један од најважнијих корака, јер квалитет предвиђања може бити само онолико добар колико и основни подаци. Познати принцип у рачунарству ово описује изреком „смеће унутра, смеће напоље“ – лоши подаци доводе до лоших резултата.
2. Претходна обрада података 🧹
Када се подаци унесу, морају се припремити пре него што се могу унети у стварни модел. Овај процес се назива претходна обрада података. Циљ је трансформисати податке у формат који модел може оптимално да обради.
Уобичајени корак у претходној обради је нормализација података. То значи довођење података у једнообразни опсег вредности тако да их модел третира доследно. Пример би био скалирање свих вредности пиксела слике на опсег од 0 до 1, уместо од 0 до 255.
Још један важан део претходне обраде је екстракција карактеристика. Ово подразумева издвајање специфичних карактеристика из сирових података које су посебно релевантне за модел. У обради слика, то могу бити ивице или одређени обрасци боја, док се у обради текста издвајају релевантне кључне речи или реченичне структуре. Претходна обрада је кључна за ефикаснији и прецизнији процес учења вештачке интелигенције.
3. Модел 🧩
Модел је срж сваке вештачке интелигенције. Овде се подаци анализирају и обрађују на основу алгоритама и математичких прорачуна. Модел може постојати у различитим облицима. Један од најпознатијих модела је неуронска мрежа, која се заснива на раду људског мозга.
Неуронске мреже се састоје од више слојева вештачких неурона који обрађују и преносе информације. Сваки слој узима излазе из претходног слоја и даље их обрађује. Процес учења неуронске мреже подразумева подешавање тежина веза између ових неурона тако да мрежа може да прави све прецизнија предвиђања или класификације. Ово подешавање се постиже обуком, у којој мрежа приступа великим количинама примерних података и итеративно побољшава своје интерне параметре (тежине).
Поред неуронских мрежа, у моделима вештачке интелигенције се користе многи други алгоритми. То укључује стабла одлучивања, случајне шуме, машине вектора подршке и многе друге. Који се алгоритам користи зависи од специфичног задатка и доступних података.
4. Прогноза модела 🔍
Када је модел обучен помоћу података, он је у стању да прави предвиђања. Овај корак се назива предвиђање модела. Вештачка интелигенција прима улаз и, на основу образаца које је до сада научила, враћа излаз, односно предвиђање или одлуку.
Ово предвиђање може имати различите облике. У моделу класификације слика, на пример, вештачка интелигенција може предвидети који је објекат приказан на слици. У језичком моделу, може предвидети која ће реч бити следећа у реченици. У финансијским предвиђањима, вештачка интелигенција може предвидети како ће се берза понашати.
Важно је нагласити да тачност предвиђања у великој мери зависи од квалитета података за обуку и архитектуре модела. Модел обучен на недовољним или пристрасним подацима ће вероватно давати погрешна предвиђања.
5. Повратне информације и обука (опционо) ♻️
Још један важан аспект начина рада вештачке интелигенције је механизам повратних информација. Овде се модел редовно проверава и додатно оптимизује. Овај процес се одвија или током обуке или након предвиђања модела.
Ако модел прави погрешна предвиђања, може да научи путем повратних информација да препозна те грешке и да у складу са тим прилагоди своје интерне параметре. То се ради упоређивањем предвиђања модела са стварним резултатима (нпр. са познатим подацима за које већ постоје тачни одговори). Типична метода у овом контексту је такозвано надгледано учење, у којем вештачка интелигенција учи из примера података који већ садрже тачне одговоре.
Уобичајена метода повратне спреге је алгоритам повратног ширења који се користи у неуронским мрежама. Овде се грешке које направи модел шире уназад кроз мрежу како би се подесиле тежине неуронских веза. На овај начин, модел учи из својих грешака и постаје све прецизнији у својим предвиђањима.
Улога тренинга 🏋️♂️
Обука вештачке интелигенције је итеративни процес. Што више података модел види и што се чешће обучава на тим подацима, то су његова предвиђања тачнија. Међутим, постоје ограничења: Преобучен модел може развити такозване проблеме „преоптерећења“. То значи да тако добро памти податке за обуку да даје лошије резултате на новим, непознатим подацима. Стога је важно тренирати модел на такав начин да се генерализује, што значи да може да прави добра предвиђања и на новим подацима.
Поред редовне обуке, постоје и методе попут трансфер учења. Овде се модел који је већ обучен на великом скупу података користи за нови, сличан задатак. Ово штеди време и рачунарску снагу, јер модел не мора бити потпуно обучен од нуле.
Искористите своје снаге максимално 🚀
Рад вештачке интелигенције (ВИ) заснива се на сложеној интеракцији различитих корака. Од уноса података и претходне обраде до обуке модела, предвиђања и повратних информација, многи фактори утичу на тачност и ефикасност ВИ. Добро обучена ВИ може понудити огромне предности у многим областима живота - од аутоматизације једноставних задатака до решавања сложених проблема. Међутим, подједнако је важно разумети ограничења и потенцијалне замке ВИ како би се најбоље искористиле њене снаге.
🤖📚 Једноставно објашњено: Како се вештачка интелигенција обучава?
🤖📊 Процес учења вештачке интелигенције: Снимање, повезивање и складиштење
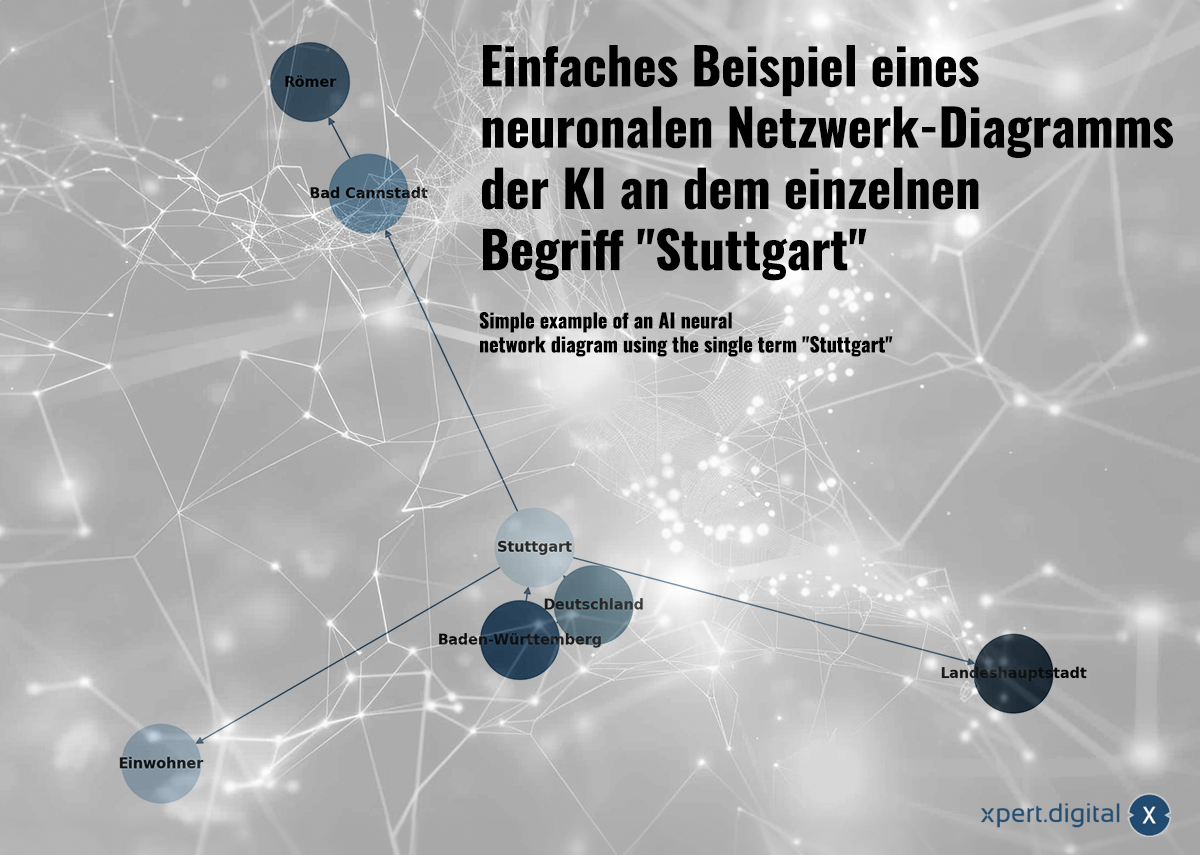
Једноставан пример дијаграма вештачке интелигенције неуронске мреже користећи један термин „Штутгарт“ – Слика: Xpert.Digital
🌟 Прикупите и припремите податке
Први корак у процесу учења вештачке интелигенције је прикупљање и припрема података. Ови подаци могу доћи из различитих извора, као што су базе података, сензори, текстови или слике.
🌟 Подаци о односима (неуронска мрежа)
Прикупљени подаци су повезани у неуронску мрежу. Сваки пакет података је представљен везама у мрежи „неурона“ (чворова). Једноставан пример користећи град Штутгарт могао би изгледати овако:
а) Штутгарт је град у Баден-Виртембергу
б) Баден-Виртемберг је савезна држава у Немачкој
ц) Штутгарт је град у Немачкој
д) Штутгарт је 2023. године имао 633.484 становника
е) Бад Канштат је округ Штутгарта
ф) Бад Канштат су основали Римљани
г) Штутгарт је главни град покрајине Баден-Виртемберг
У зависности од величине обима података, параметри за потенцијалне излазе се генеришу помоћу вештачке интелигенције (AI) модела. На пример, GPT-3 има приближно 175 милијарди параметара!
🌟 Чување и прилагођавање (учење)
Подаци се уносе у неуронску мрежу. Пролазе кроз вештачку интелигенцију и обрађују се путем веза (слично синапсама). Тежине (параметри) између неурона се подешавају како би се тренирао модел или извршио задатак.
За разлику од конвенционалних метода складиштења као што су директан приступ, индексирани приступ, секвенцијално или пакетно складиштење, неуронске мреже складиште податке на неконвенционалан начин. „Подаци“ се складиште у тежинама и пристрасностима веза између неурона.
Стварно „складиштење“ информација у неуронској мрежи се одвија кроз подешавање тежина веза између неурона. Модел вештачке интелигенције „учи“ континуираним подешавањем ових тежина и пристрасности на основу улазних података и дефинисаног алгоритма учења. Ово је континуирани процес у којем модел може да прави прецизнија предвиђања кроз поновљена подешавања.
Модел вештачке интелигенције може се посматрати као врста програмирања, јер се креира путем дефинисаних алгоритама и математичких прорачуна, а подешавање његових параметара (тежина) се континуирано побољшава како би се направила тачна предвиђања. Ово је континуирани процес.
Пристрасности су додатни параметри у неуронским мрежама који се додају пондерисаним улазним вредностима неурона. Оне омогућавају да се параметри пондеришу (важно, мање важно итд.), чинећи вештачку интелигенцију флексибилнијом и прецизнијом.
Неуронске мреже не само да могу да чувају појединачне чињенице, већ и да препознају везе између података путем препознавања образаца. Пример са Штутгартом илуструје како се знање може унети у неуронску мрежу, али неуронске мреже не уче кроз експлицитно знање (као у овом једноставном примеру), већ кроз анализу образаца података. Стога, неуронске мреже не могу само да чувају појединачне чињенице, већ и да уче тежине и везе између улазних података.
Овај процес пружа разумљив увод у то како вештачка интелигенција, а посебно неуронске мреже, функционишу, без превише дубоког улажења у техничке детаље. Он показује да се информације не чувају у неуронским мрежама као у конвенционалним базама података, већ подешавањем веза (тежина) унутар мреже.
🤖📚 Детаљније: Како се вештачка интелигенција обучава?
🏋️♂️ Обука вештачке интелигенције, посебно модела машинског учења, подразумева неколико корака. Обука вештачке интелигенције заснива се на континуираној оптимизацији параметара модела путем повратних информација и подешавања док модел не постигне најбоље резултате на основу датих података. Ево детаљног објашњења како овај процес функционише:
1. 📊 Прикупите и припремите податке
Подаци су основа обуке вештачке интелигенције. Обично се састоје од хиљада или милиона примера које систем треба да анализира. Примери укључују слике, текст или временске серије података.
Подаци морају бити очишћени и нормализовани како би се избегли непотребни извори грешака. Често се подаци трансформишу у карактеристике које садрже релевантне информације.
2. 🔍 Дефинишите модел
Модел је математичка функција која описује односе у подацима. У неуронским мрежама, које се често користе за вештачку интелигенцију, модел се састоји од више слојева неурона који су међусобно повезани.
Сваки неурон извршава математичку операцију за обраду улазних података, а затим прослеђује сигнал следећем неурону.
3. 🔄 Иницијализујте тежине
Везе између неурона имају тежинске коефицијенте који су у почетку насумично подешени. Ови тежински коефицијенти одређују колико снажно неурон реагује на сигнал.
Циљ обуке је да се ове тежине прилагоде тако да модел прави боље предвиђања.
4. ➡️ Ширење унапред
Током проласка унапред, модел обрађује улазне податке како би се добило предвиђање.
Сваки слој обрађује податке и прослеђује их следећем слоју док последњи слој не испоручи резултат.
5. ⚖️ Израчунајте функцију губитака
Функција губитка мери колико се добро предвиђања модела поклапају са стварним вредностима (ознакама). Уобичајена мера је грешка између предвиђеног и стварног одговора.
Што је већи губитак, то је лошија прогноза модела.
6. 🔙 Повратно ширење
У обрнутој итерацији, грешка се прати од излаза модела до претходних слојева.
Грешка се прерасподељује на тежине веза, а модел подешава тежине тако да грешке постану мање.
Ово се ради коришћењем градијентног спуста: Израчунава се вектор градијента, који показује како треба променити тежине да би се грешка свела на минимум.
7. 🔧 Ажурирајте тежине
Након што је грешка израчуната, тежине веза се ажурирају уз мало подешавање на основу брзине учења.
Брзина учења одређује колико се тежине мењају у сваком кораку. Превелике промене могу учинити модел нестабилним, док премале промене доводе до спорог процеса учења.
8. 🔁 Понављање (Епохе)
Овај процес проласка унапред, израчунавања грешке и ажурирања тежине се понавља, често током неколико епоха (пролази кроз цео скуп података), док модел не постигне прихватљиву тачност.
Са сваком ером, модел учи мало више и додатно прилагођава своје тежине.
9. 📉 Валидација и тестирање
Након што је модел обучен, тестира се на валидираном скупу података како би се проверило колико добро генерализује. Ово осигурава да је не само „запамтио“ податке за обуку, већ и да даје добра предвиђања на основу непознатих података.
Подаци из тестова помажу у мерењу коначних перформанси модела пре него што се користи у пракси.
10. 🚀 Оптимизација
Даљи кораци за побољшање модела укључују подешавање хиперпараметара (нпр. подешавање брзине учења или структуре мреже), регуларизацију (како би се избегло прекомерно прилагођавање) или повећање количине података.
📊🔙 Вештачка интелигенција: Чињење црне кутије вештачке интелигенције разумљивом, схватљивом и објашњивом помоћу објашњиве вештачке интелигенције (XAI), топлотних мапа, сурогат модела или других решења


Вештачка интелигенција: Чињење црне кутије вештачке интелигенције разумљивом, схватљивом и објашњивом помоћу објашњиве вештачке интелигенције (XAI), топлотних мапа, сурогат модела или других решења – Слика: Xpert.Digital
Такозвана „црна кутија“ вештачке интелигенције (ВИ) представља значајан и хитан проблем. Чак се и стручњаци често суочавају са изазовом да не могу у потпуности да разумеју како системи ВИ доносе своје одлуке. Овај недостатак транспарентности може изазвати значајне проблеме, посебно у критичним областима као што су економија, политика и медицина. Лекар или лекар који се ослања на систем ВИ за дијагнозу и препоруке за лечење мора имати поверење у донете одлуке. Међутим, ако процес доношења одлука ВИ није довољно транспарентан, јавља се неизвесност, што потенцијално доводи до недостатка поверења – и то у ситуацијама где би људски животи могли бити угрожени.
Више информација овде:
Ту смо за вас - Консалтинг - Планирање - Имплементација - Управљање пројектима
☑️ Подршка малим и средњим предузећима у стратегији, консултацијама, планирању и имплементацији
☑️ Креирање или реорганизација дигиталне стратегије и дигитализације
☑️ Проширење и оптимизација међународних продајних процеса
☑️ Глобалне и дигиталне B2B платформе за трговање
☑️ Пионирски развој пословања

Konrad Wolfenstein
Било би ми драго да вам будем лични саветник.
Можете ме контактирати попуњавањем контакт форме испод или ме једноставно позовите на +49 7348 4088 965 .
Радујем се нашем заједничком пројекту.
Пиши ми




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital је центар за индустрију фокусиран на дигитализацију, машинство, логистику/интралогистику и фотонапонске системе.
Са нашим решењем за развој пословања од 360°, пружамо подршку реномираним компанијама, од нових пословања до постпродајних услуга.
Тржишна интелигенција, маркетиншки маркетинг, маркетиншка аутоматизација, развој садржаја, односи с јавношћу, мејлинг кампање, персонализоване друштвене мреже и неговање потенцијалних клијената су део наших дигиталних алата.
Више информација можете пронаћи на: www.xpert.digital - www.xpert.solar - www.xpert.plus
Останите у контакту











