Подаци су кључна компонента генеративне вештачке интелигенције – О важности података за вештачку интелигенцију – Слика: Xpert.Digital
🌟🔍 Квалитет и разноликост: Зашто су подаци неопходни за генеративну вештачку интелигенцију
🌐📊 Значај података за генеративну вештачку интелигенцију
Подаци су окосница модерне технологије и играју кључну улогу у развоју и раду генеративне вештачке интелигенције. Генеративна вештачка интелигенција, позната и као вештачка интелигенција способна да креира садржај (као што су текст, слике, музика, па чак и видео снимци), тренутно је једно од најинoвативнијих и најдинамичнијих подручја технолошког развоја. Али шта омогућава овај развој? Одговор је једноставан: подаци.
📈💡 Подаци: Срце генеративне вештачке интелигенције
Подаци су у многим аспектима срж генеративне вештачке интелигенције. Без огромних количина висококвалитетних података, алгоритми који покрећу ове системе не би могли да уче или еволуирају. Врста и квалитет података који се користе за обуку ових модела значајно одређују њихову способност да произведу креативне и корисне резултате.
Да бисмо разумели зашто су подаци толико важни, морамо погледати како функционишу генеративни системи вештачке интелигенције. Ови системи се обучавају кроз машинско учење, тачније дубоко учење. Дубоко учење је подскуп машинског учења који се ослања на вештачке неуронске мреже моделиране по узору на то како функционише људски мозак. Ове мреже добијају огромне количине података, из којих могу да идентификују обрасце и односе и уче.
📝📚 Креирање текста помоћу генеративне вештачке интелигенције: Једноставан пример
Једноставан пример је генерисање текста помоћу генеративне вештачке интелигенције. Да би вештачка интелигенција могла да пише убедљиве текстове, прво мора да анализира огромну количину лингвистичких података. Ова анализа података омогућава вештачкој интелигенцији да разуме и реплицира структуру, граматику, семантику и стилске уређаје људског језика. Што су подаци разноврснији и свеобухватнији, то вештачка интелигенција боље може да разуме и репродукује различите језичке стилове и нијансе.
🧹🏗️ Квалитет и припрема података
Али није ствар само у количини података; квалитет је такође кључан. Висококвалитетни подаци су чисти, добро одржавани и репрезентативни за оно што вештачка интелигенција треба да научи. На пример, било би од мале користи тренирати текстуалну вештачку интелигенцију подацима који садрже претежно погрешне или нетачне информације. Подједнако је важно осигурати да подаци нису пристрасни. Пристрасност у подацима за обуку може довести до тога да вештачка интелигенција производи пристрасне или нетачне резултате, што може бити проблематично у многим случајевима употребе, посебно у осетљивим областима као што су здравствена заштита или правосуђе.
Још један важан аспект је разноликост података. Генеративна вештачка интелигенција користи широк спектар извора података. Ово осигурава да су модели општије применљиви и способни да одговоре на различите контексте и случајеве употребе. На пример, приликом обучавања генеративног модела за продукцију текста, подаци треба да потичу из различитих жанрова, стилова и епоха. Ово даје вештачкој интелигенцији могућност да разуме и генерише широк спектар стилова и формата писања.
Поред важности самих података, процес припреме података је такође кључан. Подаци се често морају обрадити пре обуке вештачке интелигенције како би се максимизирала њихова корисност. То укључује задатке као што су чишћење података, уклањање дупликата, исправљање грешака и нормализација података. Пажљиво изведен процес припреме података значајно побољшава перформансе модела вештачке интелигенције.
🖼️🖥️ Генерисање слика помоћу генеративне вештачке интелигенције
Једно важно подручје где генеративна вештачка интелигенција и значај података постају посебно очигледни јесте генерисање слика. Технике попут генеративних адверзарних мрежа (GAN) револуционисале су традиционалне методе генерисања слика. GAN се састоје од две конкурентске неуронске мреже: генератора и дискриминатора. Генератор креира слике, а дискриминатор процењује да ли су те слике стварне (из скупа података за обуку) или генерисане (од стране генератора). Кроз ово такмичење, генератор се континуирано побољшава док не може да произведе варљиво реалистичне слике. И овде су неопходни обимни и разноврсни подаци о сликама како би генератор могао да креира реалистичне и веома детаљне слике.
🎶🎼 Музичка композиција и генеративна вештачка интелигенција
Значај података протеже се и на област музике. Генеративне музичке вештачке интелигенције користе велике базе података музичких дела како би научиле структуре и обрасце карактеристичне за одређене музичке стилове. Са овим подацима, вештачке интелигенције могу да компонују нова музичка дела која стилски подсећају на дела људских композитора. Ово отвара узбудљиве могућности у музичкој индустрији, као што су развој нових композиција или персонализована музичка продукција.
📽️🎬 Видео продукција и генеративна вештачка интелигенција
Подаци су такође непроцењиви у видео продукцији. Генеративни модели су способни да креирају видео записе који делују реалистично и иновативно. Ове вештачке интелигенције могу се користити за генерисање специјалних ефеката за филмове или за креирање нових сцена за видео игре. Основни подаци могу се састојати од милиона видео клипова који садрже различите сцене, перспективе и обрасце кретања.
🎨🖌️ Уметност и генеративна вештачка интелигенција
Још једна област која има користи од генеративне вештачке интелигенције и важности података је уметност. Уметнички модели вештачке интелигенције стварају импресивна уметничка дела, инспирисана мајсторима прошлости или уводећи потпуно нове уметничке стилове. Ови системи су обучени на скуповима података који садрже дела различитих уметника и епоха како би обухватили широк спектар уметничких стилова и техника.
🔒🌍 Етика и заштита података
Етика такође игра кључну улогу када су у питању подаци и генеративна вештачка интелигенција. Пошто ови модели често користе велике количине личних или осетљивих података, морају се решити питања заштите података. Неопходно је да се подаци користе праведно и транспарентно и да се заштити приватност појединаца. Компаније и истраживачке институције морају да обезбеде да одговорно рукују подацима и да се системи вештачке интелигенције које развијају придржавају етичких стандарда.
Закључно, подаци су кључна компонента за развој и успех генеративне вештачке интелигенције. Они нису само сировина из које ови системи црпе своје знање, већ и кључ за остваривање њиховог пуног потенцијала у широком спектру примена. Пажљиво прикупљање, обрада и коришћење података осигуравају да системи генеративне вештачке интелигенције буду не само моћнији и флексибилнији, већ и етички исправнији и безбеднији. Путовање генеративне вештачке интелигенције је још увек у раним фазама, а улога података ће и даље бити од централног значаја.
📣 Сличне теме
- 📊 Суштина података за генеративну вештачку интелигенцију
- 📈 Квалитет и разноликост података: Кључ успеха вештачке интелигенције
- 🎨 Вештачка креативност: Генеративна вештачка интелигенција у уметности и дизајну
- 📝 Креирање текста вођено подацима путем генеративне вештачке интелигенције
- 🎬 Револуција у видео продукцији захваљујући генеративној вештачкој интелигенцији
- 🎶 Генеративна вештачка интелигенција компонује: Будућност музике
- 🧐 Етичка разматрања у коришћењу података за вештачку интелигенцију
- 👾 Генеративне адверзарне мреже: од кода до уметности
- 🧠 Дубоко учење и важност висококвалитетних података
- 🔍 Процес припреме података за генеративну вештачку интелигенцију
#️⃣ Хештегови: #Подаци #ГенеративнаАИ #Етика #КреирањеТекста #Креативност
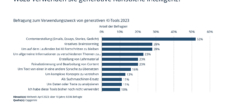
💡🤖 Интервју са проф. Рајнхардом Хекелом о важности података за вештачку интелигенцију

Реинхард Хецкел, професор машинског учења – Слика: Астрид Ецкерт / ТУМ
📊💻 Подаци чине основу вештачке интелигенције. За обуку се користе слободно доступни подаци са интернета, који су строго филтрирани.
- Тешко је избећи пристрасности током обуке. Стога, модели покушавају да пруже уравнотежене одговоре и избегну проблематичне термине.
- Тачност вештачке интелигенције варира у зависности од области примене, при чему је сваки детаљ релевантан у дијагнози болести, између осталог.
- Заштита података и преносивост података су изазови у медицинском контексту.
Наши подаци се сада прикупљају свуда на интернету и користе се и за обучавање великих језичких модела попут ChatGPT-а. Али како се вештачка интелигенција (ВИ) обучава, како се осигурава да у моделима не дође до изобличења, такозваних пристрасности, и како се поштује заштита података? Рајнхард Хекел, професор машинског учења на Техничком универзитету у Минхену (ТУМ), даје одговоре на ова питања. Његово истраживање се фокусира на велике језичке моделе и технике медицинског снимања.
🔍🤖 Какву улогу играју подаци у обуци система вештачке интелигенције?
Системи вештачке интелигенције користе податке као примере за обуку. Велики језички модели попут ChatGPT-а могу да одговоре само на питања о темама за које су обучени.
Већина информација које се користе за обуку општих језичких модела је слободно доступна на мрежи. Што је више података за обуку доступно за дато питање, то су резултати бољи. На пример, ако постоји много висококвалитетних текстова који описују математичке концепте за вештачку интелигенцију дизајнирану да помогне у математичким проблемима, подаци за обуку ће бити сходно томе добри. Међутим, тренутна селекција података подразумева веома ригорозно филтрирање. Из огромне количине доступних података, само висококвалитетни подаци се прикупљају и користе за обуку.
📉🧠 Како се осигурава да вештачка интелигенција не производи, на пример, расистичке или сексистичке стереотипе, такозване предрасуде, приликом одабира података?
Веома је тешко развити метод који се не ослања на класичне стереотипе и функционише непристрасно и праведно. На пример, спречавање изобличења резултата због боје коже је релативно лако. Међутим, када је укључен и пол, могу настати ситуације у којима више није могуће да модел функционише потпуно непристрасно у погледу и боје коже и пола истовремено.
Већина језичких модела стога покушава да пружи уравнотежене одговоре на политичка питања, на пример, и да осветли вишеструке перспективе. Приликом обуке засноване на медијском садржају, предност се даје медијским кућама које испуњавају критеријуме новинарског квалитета. Штавише, приликом филтрирања података, води се рачуна да се одређене речи, попут расистичких или сексистичких, не појављују.
🌐📚 Неки језици имају пуно садржаја на мрежи, док други имају знатно мање. Како то утиче на квалитет резултата?
Већи део интернета је на енглеском језику. Зато модели великих језика најбоље функционишу на енглеском језику. Међутим, постоји и велика количина садржаја доступна на немачком. За језике који су мање уобичајени и за које постоји мање текстова, постоји мање података за обуку, па модели стога лошије функционишу.
Колико добро се језички модели могу користити у одређеним језицима лако се може посматрати, јер они прате такозване законе скалирања. Ово подразумева тестирање да ли је језички модел у стању да предвиди следећу реч. Што је више података за обуку доступно, модел постаје бољи. Али он се не само континуирано побољшава; његово побољшање је такође предвидљиво. Ово се може ефикасно представити математичком једначином.
💉👨⚕️ Колико тачна треба да буде вештачка интелигенција у пракси?
Много зависи од специфичне примене. На пример, код фотографија које се накнадно обрађују помоћу вештачке интелигенције, није битно да ли је свака длака на правом месту. Често је довољно да коначна слика изгледа добро. Слично томе, код великих језичких модела, важно је да се на питања тачно одговори; није увек кључно да ли детаљи недостају или су нетачни. Поред језичких модела, спроводим и истраживања у области медицинске обраде слика. Овде је битно да сваки детаљ генерисане слике буде тачан. Ако користим вештачку интелигенцију за дијагнозе, она мора бити апсолутно тачна.
🛡️📋 Недостатак заштите података се често помиње у вези са вештачком интелигенцијом. Како се може осигурати да су лични подаци заштићени, посебно у медицинском контексту?
Већина медицинских апликација користи анонимизоване податке о пацијентима. Права опасност лежи у чињеници да постоје ситуације у којима се закључци и даље могу извући из ових података. На пример, старост или пол се често могу утврдити из МРИ или ЦТ скенирања. Дакле, неке наизглед анонимизоване информације су садржане у подацима. Стога је кључно адекватно информисати пацијенте о томе.
⚠️📊 Које друге потешкоће постоје приликом обучавања вештачке интелигенције у медицинском контексту?
Главни изазов лежи у прикупљању података који одражавају широк спектар ситуација и сценарија. Вештачка интелигенција најбоље функционише када су подаци на које се примењује слични подацима за обуку. Међутим, подаци се разликују од болнице до болнице, на пример, у погледу састава пацијента или опреме која се користи за генерисање података. Да бисмо решили овај проблем, постоје две опције: или ћемо успети да побољшамо алгоритме, или морамо оптимизовати наше податке како би се могли ефикасније применити на друге ситуације.
👨🏫🔬 О мени:
Професор Рајнхард Хекел спроводи истраживања у области машинског учења. Ради на развоју алгоритама и теоријских основа за дубоко учење. Један од фокуса његовог рада је обрада медицинских слика. Такође развија решења за складиштење ДНК података и истражује употребу ДНК као дигиталне информационе технологије.
Такође је члан Минхенског института за науку о подацима и Минхенског центра за машинско учење.
Ту смо за вас - Консалтинг - Планирање - Имплементација - Управљање пројектима
☑️ Стручњак из индустрије, овде са својим Xpert.Digital индустријским центром са преко 2.500 стручних чланака

Konrad Wolfenstein
Било би ми драго да вам будем лични саветник.
Можете ме контактирати попуњавањем контакт форме испод или ме једноставно позовите на +49 7348 4088 965 .
Радујем се нашем заједничком пројекту.
Пиши ми




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital је центар за индустрију фокусиран на дигитализацију, машинство, логистику/интралогистику и фотонапонске системе.
Са нашим решењем за развој пословања од 360°, пружамо подршку реномираним компанијама, од нових пословања до постпродајних услуга.
Тржишна интелигенција, маркетиншки маркетинг, маркетиншка аутоматизација, развој садржаја, односи с јавношћу, мејлинг кампање, персонализоване друштвене мреже и неговање потенцијалних клијената су део наших дигиталних алата.
Више информација можете пронаћи на: www.xpert.digital - www.xpert.solar - www.xpert.plus
Останите у контакту