
Veröffentlicht am: 21. Juli 2025 / Update vom: 21. Juli 2025 – Verfasser: Konrad Wolfenstein

Ein neuer “Sputnik-Moment”? KI-Modelle: Kommt bald Kimi K3? Warum elektrisiert Kimi K2 die KI-Branche? – Bild: Xpert.Digital
Der Kimi-Knall: Dieses KI-Modell aus China ist 10x günstiger als GPT-4 und genauso schlau.
Chinas Durchbruch | KI zum Kampfpreis: Wenn Technologie demokratischer wird
Die KI-Welt steht unter Strom, und der Auslöser hat einen Namen: Kimi K2. Entwickelt vom Pekinger Startup Moonshot AI, sorgt dieses neue Sprachmodell für einen wahren “Kimi-Knall” in der Branche und wird bereits als der “zweite DeepSeek-Moment” gehandelt – ein Ereignis, das die Machtverhältnisse im globalen KI-Wettbewerb neu ordnet. Doch was macht Kimi K2 so besonders? Es ist die explosive Kombination aus drei disruptiven Eigenschaften: radikale Offenheit durch eine modifizierte MIT-Lizenz, eine beeindruckende Leistung, die in Benchmarks mit Giganten wie GPT-4 mithält, und ein Preismodell, das die westliche Konkurrenz um Grössenordnungen unterbietet.
Die Metapher vom „Sputnik-Moment“ beschreibt den Schock, den die USA 1957 erlebten, als die Sowjetunion unerwartet den ersten Satelliten – Sputnik 1 – ins All schoss. Dieses Ereignis machte dem Westen schlagartig bewusst, dass er in einem entscheidenden Technologiefeld von einem Konkurrenten überholt worden war. Die Folge war ein nationaler Weckruf, der zu massiven Investitionen in Wissenschaft und Bildung führte und den „Wettlauf ins All“ auslöste.
Übertragen auf die KI bedeutet der „Kimi-Knall“ einen ähnlichen Weckruf für die westliche Tech-Welt: Ein chinesisches Unternehmen hat nicht nur ein Modell entwickelt, das in der Leistung mit dem führenden GPT-4 mithalten kann, sondern es gleichzeitig als Open-Source-Modell und zu einem Bruchteil der Kosten veröffentlicht. Dieser technologische und ökonomische Durchbruch stellt die bisherige Dominanz von US-Firmen wie OpenAI infrage und signalisiert den Beginn einer neuen, verschärften Wettbewerbsphase um die globale KI-Führung.
Dieser Vorstoß beweist eindrucksvoll, dass offene, frei verfügbare KI-Modelle nicht nur technologisch aufschließen, sondern in puncto Kosteneffizienz und Zugänglichkeit eine neue Ära einläuten. Für Start-ups, Forscher und Unternehmen weltweit bedeutet dies eine Revolution der Möglichkeiten, während etablierte Player wie OpenAI und Anthropic unter massiven Zugzwang geraten. Wir tauchen tief in die Architektur, die Benchmarks und die weitreichenden Implikationen von Kimi K2 ein und analysieren, ob dieser “KI-Sputnik-Moment” aus China die Zukunft der künstlichen Intelligenz nachhaltig verändern wird.
Kimi K2 vereint drei disruptive Eigenschaften:
- Offenheit – Moonshot AI veröffentlicht Modelldateien unter modifizierter MIT-Lizenz.
- Leistung – In Benchmarks wie MMLU-Pro übertrifft Kimi K2 öffentliche Konkurrenzmodelle und erreicht Ergebnisse auf GPT-4-Niveau.
- Kosten – Die API verlangt nur $0.15 je 1 Mio Input-Tokens und $2.50 je 1 Mio Output-Tokens, womit sie um Größeneinheiten günstiger ist als westliche Top-Modelle.
Passend dazu:

Wer entwickelt Kimi K2 und was bedeutet der Begriff „Kimi-Knall“?
Moonshot AI, 2023 in Peking gegründet, fokussiert sich auf extrem große Sprachmodelle und bezeichnet jede große Versionsveröffentlichung intern als „Knall“. Die Community übernahm den Begriff, als Kimi K2 am 11. Juli 2025 die Benchmark-Listen stürmte und auf Hugging Face in Rekordzeit die Download-Charts anführte.
Was war der erste „DeepSeek-Moment“?
Der Ausdruck beschreibt den Schock, als DeepSeek R1 im Januar 2025 erstmals als offenes Modell die Reasoning-Leistung proprietärer Systeme erreichte. Analysten verglichen diesen Schritt mit einem „Sputnik-Moment“ für KI-Open-Source.
Passend dazu:

Warum spricht man nun von einem zweiten DeepSeek-Moment?
Kimi K2 wiederholt und verstärkt das Narrativ: Ein chinesisches Startup publiziert ein frei herunterladbares LLM, das nicht nur mithalten, sondern in einzelnen Disziplinen dominieren kann – diesmal jedoch mit MoE-Architektur, Tool-Usage-Fokus und nochmals niedrigeren Betriebskosten.
Wie ist Kimi K2 aufgebaut?
- Architektur: Mixture-of-Experts-Transformer mit 1 Billion Gesamtparametern, von denen 32 Mrd. pro Inferenz aktiviert sind.
- Kontextfenster: 128 k Tokens, optimiert durch Multi-Head-Latent-Attention (MLA).
- Optimierer: MuonClip reduziert Trainingsinstabilitäten und halbiert den Rechenaufwand gegenüber AdamW.
- Tool-Aufrufe: Das Instruct-Checkpoint enthält nativ implementierte Function-Calling-Schemas.
Welche Hardware benötigt ein Selbsthoster?
Ohne Quantisierung belaufen sich die Gewichte auf ≈1 TB. Ein Thread im Subreddit /r/LocalLLaMA kalkuliert eine CPU-RAM-Konfiguration mit 1,152 GB DDR5 und einer RTX 5090 für unter $10,000. Für produktive Latenzen empfiehlt Moonshot GPUs mit TensorRT-LLM oder vLLM-Back-End.
Wie schlägt sich Kimi K2 in Kern-Benchmarks?
Moonshot meldet 87.8% auf MMLU, 92.1% auf GSM-8k und 26.3% Pass@1 auf LiveCodeBench. VentureBeat bestätigt 65.8% auf SWE-Bench Verified, womit Kimi K2 viele proprietäre Systeme übertrifft.
Welche KI-Modelle stehen zum Vergleich?
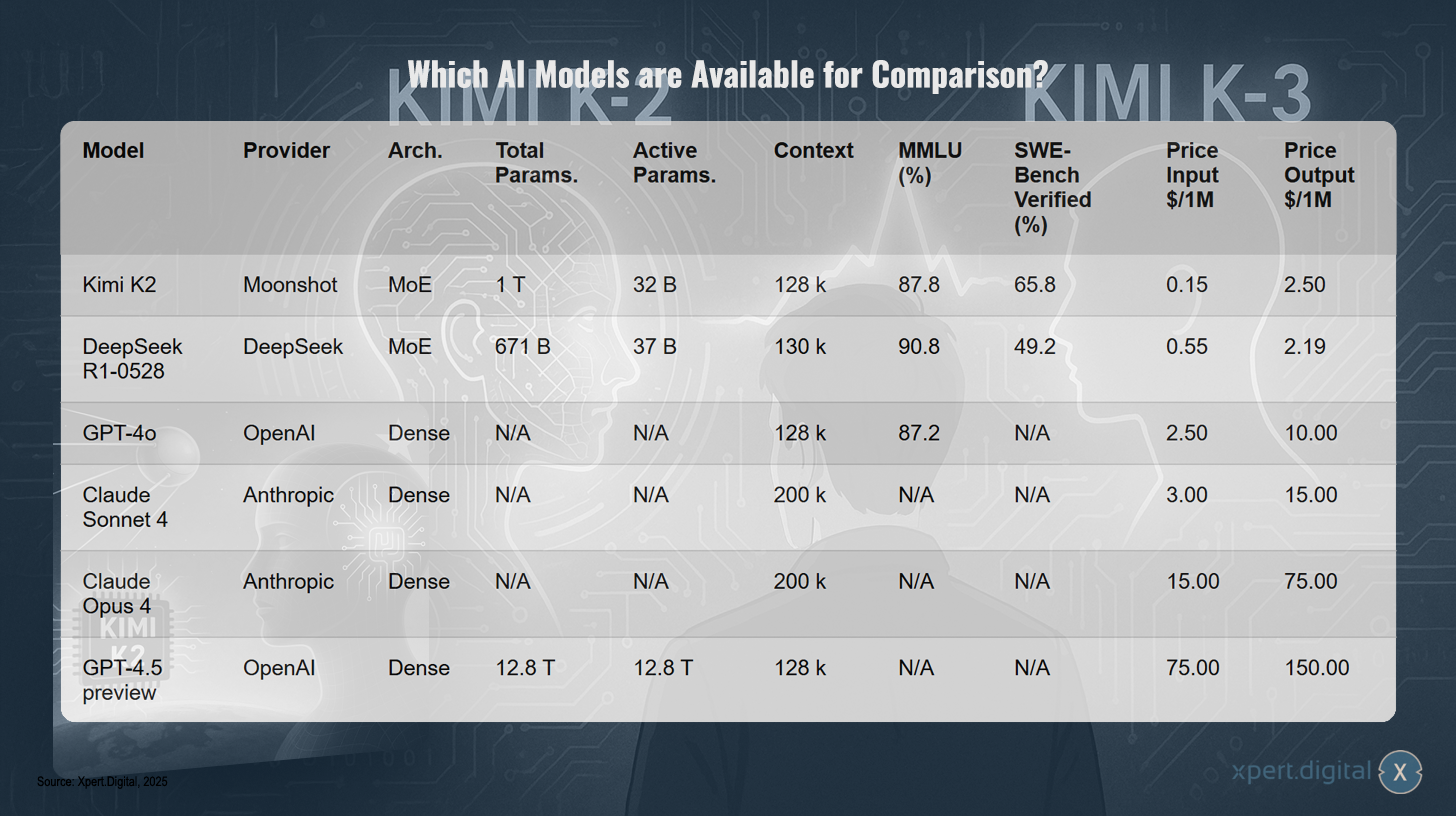
Welche KI-Modelle stehen zum Vergleich? – Bild: Xpert.Digital
In der aktuellen Landschaft der KI-Modelle gibt es eine beeindruckende Vielfalt an Systemen, die sich durch unterschiedliche Eigenschaften auszeichnen. Die vergleichende Übersicht zeigt Modelle verschiedener Anbieter wie Moonshot, DeepSeek, OpenAI und Anthropic, die jeweils eigene Architekturen und Leistungsmerkmale aufweisen.
Das Modell Kimi K2 von Moonshot basiert auf einer Mixed-of-Experts-Architektur (MoE) mit insgesamt 1 Billion Parameter, wovon 32 Milliarden aktiv sind. Es bietet einen Kontextumfang von 128.000 Zeichen und erreicht beachtliche 87,8% im MMLU-Benchmark sowie 65,8% in der SWE-Bench Verified-Bewertung. Die Kosten liegen bei 0,15 Dollar pro Million Input-Token und 2,50 Dollar pro Million Output-Token.
DeepSeek’s R1-0528 Modell zeigt ähnliche Charakteristiken mit MoE-Architektur, 671 Milliarden Gesamtparametern und 37 Milliarden aktiven Parametern. Es übertrifft Kimi K2 mit 90,8% im MMLU-Test, hat aber einen etwas höheren Preis von 0,55 Dollar pro Million Input-Token.
Die Modelle von OpenAI und Anthropic wie GPT-4o, Claude Sonnet 4, Claude Opus 4 und der GPT-4.5 Preview unterscheiden sich durch ihre Dense-Architektur und teilweise nicht veröffentlichte Parameteranzahlen. Besonders auffällig sind die deutlich höheren Preise, insbesondere beim GPT-4.5 Preview Modell mit 75 Dollar pro Million Input-Token und 150 Dollar pro Million Output-Token.
Was fällt am Vergleich besonders auf?
- Kimi K2 erreicht fast identische MMLU-Scores wie GPT-4o, braucht aber pro Antwort nur 32 B aktive Parameter.
- DeepSeek R1 schlägt Kimi K2 auf MMLU, ist jedoch schwächer in Software-Engineering-Benchmarks.
- Preislich liegt Kimi K2 um Faktor 10 unter GPT-4o und um Faktor 5 unter Claude Sonnet 4.
Wie radikal ist die Preisdifferenz?
Die Preisunterschiede zwischen verschiedenen KI-Modellen sind bemerkenswert und verdeutlichen eine dramatische Verschiebung im Kosten-Leistungs-Verhältnis. Eine Beispielkalkulation für 1 Million Token zeigt die signifikanten Preisunterschiede: Während Modelle wie Kimi K2 und DeepSeek R1 mit Kosten um die 2,65-2,74 Dollar pro Million Token sehr günstig sind, liegen die Preise für GPT-4o bei 12,50 Dollar, Claude Sonnet 4 bei 9,00 Dollar und Claude Opus 4 bei 45,00 Dollar. Besonders auffällig sind die Kosten für GPT-4.5 mit 112,50 Dollar pro Million Token. Diese Kalkulation unterstreicht, dass sich das Kosten-Leistungs-Verhältnis zunehmend zugunsten offener MoE-Modelle (Mixture of Experts) aus China verschiebt, die deutlich kostengünstiger sind als etablierte westliche KI-Modelle.
Welche Auswirkung hat das auf Start-ups und Forschung?
Günstige Tokenpreise ermöglichen längere Kontextfenster und mehr Iterationen pro Experiment, was Forschung günstiger macht. Gleichzeitig verdrängen hohe westliche Preise low-margin-Anwender in Richtung Kimi K2-Infrastruktur, etwa SiliconFlow oder Groq.
Was bedeutet der Kimi-Knall für den transatlantischen Wettbewerb?
Laut Golem-Analysten stellt Moonshot AI OpenAI offen heraus und zwingt US-Unternehmen, Preisschritte weiter zu beschleunigen. Fachmagazine vergleichen den Effekt mit einer „KI-Sputnik-Serie“, nachdem DeepSeek das Narrativ eingeleitet hatte. Investoren in Europa mahnen, dass regulatorische Trägheit zu weiterer technologischer Abwanderung führt.
Wie reagieren Marktführer?
OpenAI kündigte im April 2025 erstmals ein eigenes Open-Weight-Modell an, um dem Open-Source-Druck zu begegnen. Anthropic offeriert inzwischen aggressive Cache-Rabatte bis 90%, bleibt jedoch preislich hinter Kimi K2.
Warum ist MuonClip entscheidend?
Moonshot und UCLA zeigen, dass MuonClip Instabilitäten in Milliarden-Skalen minimiert und den Speicherverbrauch gegenüber AdamW halbiert. Das ermöglicht 15.5 Billionen Token Training ohne Abbrüche.
Welche Rolle spielt das Mixture-of-Experts-Design?
MoE aktiviert pro Token nur eine Teilmenge spezialisierter Experten. Das senkt Rechenzeit und Stromverbrauch, während die Gesamtparameterzahl hoch bleibt. GPT-4o und Claude nutzen hingegen dichte Architekturen und müssen alle Gewichte berechnen, was Kosten treibt.
Was beinhaltet die modifizierte MIT-Lizenz?
Sie erlaubt kommerzielle Nutzung, Weitergabe und Sublizenzierung, verpflichtet jedoch zu Quell- und Lizenzhinweisen. Damit kann Kimi K2 in On-Prem-Umgebungen eingesetzt werden, was besonders europäische Datenschutzanforderungen adressiert.
Gibt es Schattenseiten?
Forscher kritisieren, dass Kimi K2 historische Ereignisse der chinesischen Geschichte glossiert und somit Bias aufweist. Zudem befürchtet man, dass die Offenheit unerwünschte Anwendungen erleichtert, etwa automatisierte Desinformation.
Agentic Intelligence: Ist Kimi K2 ein Schritt zu autonomen KI-Agenten?
Ja. Moonshot trainierte explizit Tool-Use und Function-Calling, sodass Kimi K2 eigenständig APIs orchestrieren kann. VentureBeat betont die Agentic-Fähigkeiten als Alleinstellungsmerkmal. Das unterscheidet Kimi K2 von DeepSeek R1, das primär Reasoning offenlegt, aber Tool-Use vom Agent-Framework abhängig macht.
Integration in Workflows: Wie integriere ich Kimi K2 in bestehende OpenAI-Pipelines?
Moonshot bietet OpenAI-kompatible Endpunkte, wobei die angeforderte Temperatur intern auf 0.6 skaliert wird. Entwickler müssen lediglich den Base-URL tauschen und können Tools wie LangChain oder LlamaIndex ohne Änderungen nutzen.
Welche Best Practices gibt es für Tool-Calling?
- Funktionen als JSON-Schema übergeben.
- Temperatur 0.6 halten, um deterministische Tool-Aufrufe zu forcieren.
- Ergebnisse mit Reflection Prompts überprüfen, um Halluzinationen zu minimieren.
Welche Cloud-Anbieter hosten Kimi K2?
SiliconFlow, Fireworks AI und Groq bieten pay-per-token Zugänge mit Durchsatz bis 100 k TPM.
Wie kann Europa aufholen?
Analysten fordern eine „KI-Gigafactory“ nach US-Vorbild, um eigene Modelle mit günstiger Stromversorgung zu trainieren. Bis dahin könnte Europa auf offene Modelle wie Kimi K2 setzen und sich auf vertikale Finetunes konzentrieren.
Welche konkreten Anwendungsfelder profitieren zuerst?
- Code-Assistenz: Kimi-Dev-72B nutzt Kimi-K2-Daten und erreicht 60.4% SWE-Bench.
- Dokumentanalyse: 128 k Kontextfenster ermöglicht juristische Langgutachten.
- Daten-Pipelines: Niedrige Latenz von 0.54 s First-Token macht Echtzeit-Chatbots realistisch.
Was sind die Hauptrisiken?
- Bias und Zensur in kritischen Themen.
- Datenabfluss über öffentliche APIs.
- Hardware-Kosten für On-Prem Inferenz trotz MoE nach wie vor hoch.
Wird Kimi K2 westliche Preise dauerhaft drücken?
Der Preisdruck hat bereits eingesetzt: OpenAI senkte GPT-4o in weniger als zwölf Monaten dreimal. Claude unterbietet frühere Tarife durch Cache-Mechanismen. Analysten sehen Kimi K2 als Katalysator für einen „Race to the Bottom“ bei Tokenpreisen, ähnlich wie AWS den Cloud-Markt 2010 prägte.
Kommt bald Kimi K3?
Moonshot nennt als nächste Meilensteine multimodale Weltmodelle und selbstverbessernde Architekturen. Insider-Leaks sprechen von einem Kontextfenster über 512 k Tokens und einer Pegasus-Optimierung. Offiziell kommentiert das Unternehmen jedoch keine Roadmap.
Was bleibt vom „zweiten DeepSeek-Moment“?
Kimi K2 beweist, dass offene Modelle nicht nur mithalten, sondern auch preislich dominieren können. Das verschiebt Machtbalance, treibt Innovation und zwingt alle Anbieter zu mehr Transparenz. Für Unternehmen entsteht eine neue Kostenbasis, für Forscher ein reichhaltiges Testfeld, und für Regulierer der Druck, mit der Geschwindigkeit offener Entwicklung Schritt zu halten.
Der Kimi-Knall markiert damit eine Wegscheide: Wer Offenheit und Effizienz verbindet, setzt künftig die Standards der KI-Ökonomie.
Passend dazu:
Ihr AI-Transformation, AI-Integration und AI-Plattform Branchenexperte
☑️ Unsere Geschäftssprache ist Englisch oder Deutsch
☑️ NEU: Schriftverkehr in Ihrer Landessprache!

Konrad Wolfenstein
Gerne stehe ich Ihnen und mein Team als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie hier das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 89 89 674 804 (München) an. Meine E-Mail Adresse lautet: wolfenstein∂xpert.digital
Ich freue mich auf unser gemeinsames Projekt.








