


Попытка объяснить принцип работы ИИ: как работает искусственный интеллект и как он обучается? – Изображение: Xpert.Digital
📊 От ввода данных до прогнозирования модели: процесс искусственного интеллекта
Как работает искусственный интеллект (ИИ)? 🤖
Функционирование искусственного интеллекта (ИИ) можно разделить на несколько четко определенных этапов. Каждый из этих этапов имеет решающее значение для конечного результата, получаемого ИИ. Процесс начинается с ввода данных и заканчивается прогнозированием модели, а также обратной связью или дальнейшими раундами обучения. Эти фазы описывают процесс, через который проходят почти все модели ИИ, независимо от того, являются ли они простыми наборами правил или высокосложными нейронными сетями.
1. Ввод данных 📊
Основой любого искусственного интеллекта являются данные, с которыми он работает. Эти данные могут существовать в различных формах, таких как изображения, текст, аудиофайлы или видео. ИИ использует эти необработанные данные для распознавания закономерностей и принятия решений. Качество и количество данных играют здесь решающую роль, поскольку они существенно влияют на то, насколько хорошо или плохо в конечном итоге будет работать модель.
Чем полнее и точнее данные, тем лучше ИИ может учиться. Например, при обучении ИИ обработке изображений ему требуется большое количество изображений для правильной идентификации различных объектов. Для языковых моделей это текстовые данные, которые помогают ИИ понимать и генерировать человеческую речь. Ввод данных — это первый и один из важнейших шагов, поскольку качество прогнозов зависит от качества исходных данных. Известный принцип в информатике описывает это поговоркой «мусор на входе — мусор на выходе» — плохие данные приводят к плохим результатам.
2. Предварительная обработка данных 🧹
После ввода данных их необходимо подготовить, прежде чем они смогут быть переданы в саму модель. Этот процесс называется предварительной обработкой данных. Цель состоит в том, чтобы преобразовать данные в формат, который модель сможет оптимально обрабатывать.
Распространенным этапом предварительной обработки является нормализация данных. Это означает приведение данных в единый диапазон значений, чтобы модель обрабатывала их согласованно. Например, можно масштабировать все значения пикселей изображения до диапазона от 0 до 1, а не от 0 до 255.
Еще одним важным этапом предварительной обработки является извлечение признаков. Это включает в себя извлечение из исходных данных конкретных признаков, которые особенно важны для модели. В обработке изображений это могут быть границы или определенные цветовые узоры, а в обработке текста извлекаются релевантные ключевые слова или структуры предложений. Предварительная обработка имеет решающее значение для повышения эффективности и точности процесса обучения ИИ.
3. Модель 🧩
Модель — это ядро любого искусственного интеллекта. В ней данные анализируются и обрабатываются на основе алгоритмов и математических вычислений. Модель может существовать в различных формах. Одна из наиболее известных моделей — это нейронная сеть, основанная на работе человеческого мозга.
Нейронные сети состоят из множества слоев искусственных нейронов, которые обрабатывают и передают информацию. Каждый слой принимает выходные данные предыдущего слоя и обрабатывает их дальше. Процесс обучения нейронной сети включает в себя корректировку весов связей между этими нейронами, чтобы сеть могла делать все более точные прогнозы или классификации. Эта корректировка достигается посредством обучения, в ходе которого сеть получает доступ к большим объемам примеров данных и итеративно улучшает свои внутренние параметры (веса).
Помимо нейронных сетей, в моделях ИИ используются многие другие алгоритмы. К ним относятся деревья решений, случайные леса, машины опорных векторов и многие другие. Выбор алгоритма зависит от конкретной задачи и имеющихся данных.
4. Модель прогноза 🔍
После обучения модели на данных она способна делать прогнозы. Этот этап называется прогнозированием модели. Искусственный интеллект получает входные данные и, основываясь на изученных закономерностях, возвращает выходные данные, то есть прогноз или решение.
Это предсказание может принимать различные формы. Например, в модели классификации изображений ИИ может предсказать, какой объект изображен на картинке. В языковой модели он может предсказать, какое слово будет следующим в предложении. В финансовых прогнозах ИИ может предсказать, как будет вести себя фондовый рынок.
Важно подчеркнуть, что точность прогнозов в значительной степени зависит от качества обучающих данных и архитектуры модели. Модель, обученная на недостаточных или предвзятых данных, с высокой вероятностью будет делать неверные прогнозы.
5. Обратная связь и обучение (по желанию) ♻️
Еще одним важным аспектом работы ИИ является механизм обратной связи. В этом механизме модель регулярно проверяется и дополнительно оптимизируется. Этот процесс происходит либо во время обучения, либо после того, как модель сделает предсказание.
Если модель делает неверные прогнозы, она может научиться распознавать эти ошибки с помощью обратной связи и соответствующим образом корректировать свои внутренние параметры. Это делается путем сравнения прогнозов модели с фактическими результатами (например, с известными данными, для которых уже существуют правильные ответы). Типичным методом в этом контексте является так называемое контролируемое обучение, при котором ИИ обучается на примерах данных, которые уже содержат правильные ответы.
Распространенным методом обратной связи является алгоритм обратного распространения ошибки, используемый в нейронных сетях. В этом случае ошибки, допущенные моделью, распространяются обратно по сети для корректировки весов нейронных связей. Таким образом, модель учится на своих ошибках и становится все более точной в своих прогнозах.
Роль обучения 🏋️♂️
Обучение ИИ — это итеративный процесс. Чем больше данных получает модель и чем чаще она обучается на этих данных, тем точнее становятся её прогнозы. Однако существуют ограничения: переобученная модель может столкнуться с так называемой проблемой «переобучения». Это означает, что она настолько хорошо запоминает обучающие данные, что выдаёт худшие результаты на новых, неизвестных данных. Поэтому важно обучать модель таким образом, чтобы она была обобщающей, то есть могла делать хорошие прогнозы и на новых данных.
Помимо обычного обучения, существуют также такие методы, как трансферное обучение. В этом случае модель, уже обученная на большом наборе данных, используется для решения новой, аналогичной задачи. Это экономит время и вычислительные мощности, поскольку модель не нужно обучать с нуля.
Максимально используйте свои сильные стороны 🚀
Работа искусственного интеллекта (ИИ) основана на сложном взаимодействии различных этапов. От ввода и предварительной обработки данных до обучения модели, прогнозирования и обратной связи — на точность и эффективность ИИ влияют многие факторы. Хорошо обученный ИИ может предложить огромные преимущества во многих областях жизни — от автоматизации простых задач до решения сложных проблем. Однако не менее важно понимать ограничения и потенциальные подводные камни ИИ, чтобы наилучшим образом использовать его сильные стороны.
🤖📚 Простым языком: как обучается ИИ?
🤖📊 Процесс обучения ИИ: сбор, связывание и хранение данных
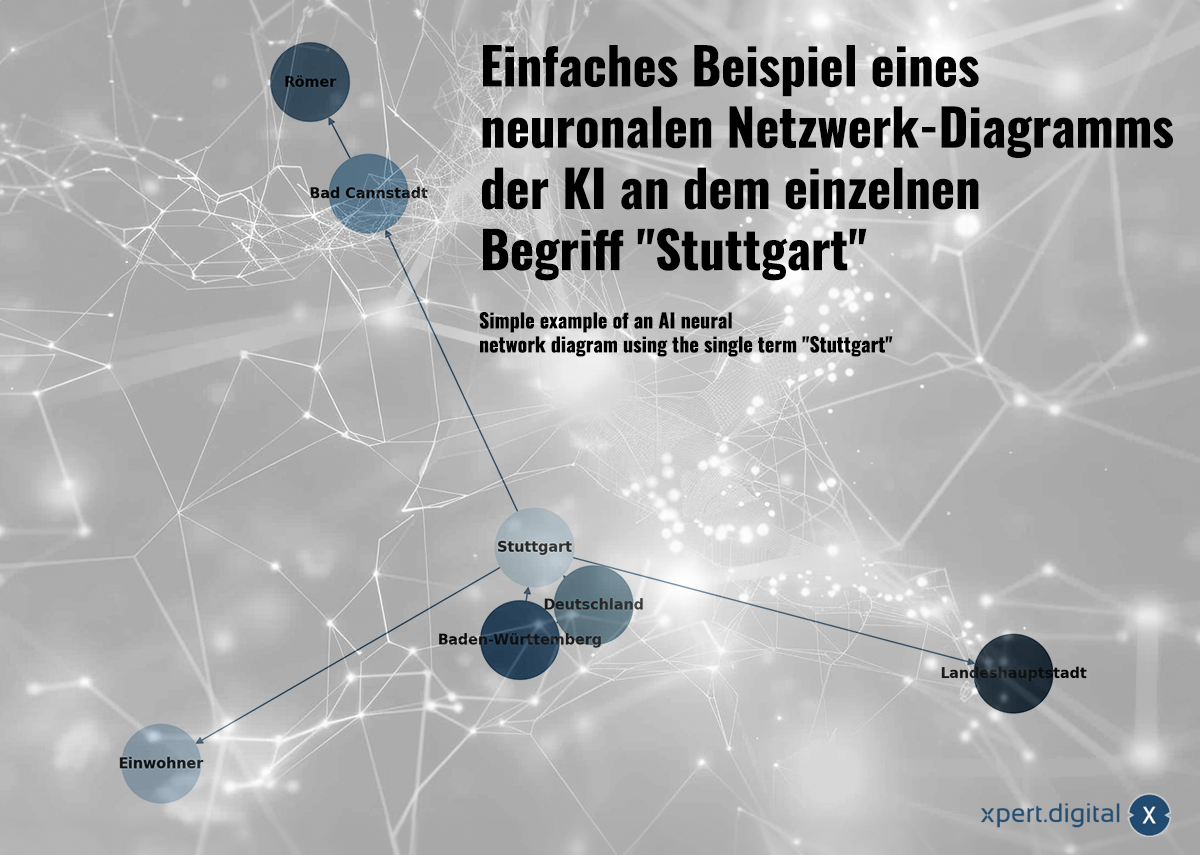
Простой пример диаграммы нейронной сети ИИ с использованием одного слова «Штутгарт» – Изображение: Xpert.Digital
🌟 Сбор и подготовка данных
Первым шагом в процессе обучения искусственного интеллекта является сбор и подготовка данных. Эти данные могут поступать из различных источников, таких как базы данных, датчики, тексты или изображения.
🌟 Данные о взаимоотношениях (нейронная сеть)
Собранные данные объединены в нейронную сеть. Каждый пакет данных представлен соединениями в сети «нейронов» (узлов). Простой пример с городом Штутгарт может выглядеть так:
a) Штутгарт — город в Баден-Вюртемберге
b) Баден-Вюртемберг — федеральная земля Германии
c) Штутгарт — город в Германии
d) Население Штутгарта в 2023 году составляло 633 484 человека
e) Бад-Каннштатт — район Штутгарта
f) Бад-Каннштатт был основан римлянами
g) Штутгарт — столица земли Баден-Вюртемберг
В зависимости от объема данных параметры для потенциальных выходных результатов генерируются с помощью модели ИИ. Например, модель GPT-3 имеет приблизительно 175 миллиардов параметров!
🌟 Сохранение и настройка (обучение)
Данные поступают в нейронную сеть. Они проходят через модель ИИ и обрабатываются посредством связей (подобно синапсам). Веса (параметры) между нейронами корректируются для обучения модели или выполнения задачи.
В отличие от традиционных методов хранения данных, таких как прямой доступ, индексированный доступ, последовательное или пакетное хранение, нейронные сети хранят данные нетрадиционным способом. «Данные» хранятся в весах и смещениях связей между нейронами.
Фактическое «хранение» информации в нейронной сети происходит за счет корректировки весовых коэффициентов связей между нейронами. Модель ИИ «обучается», непрерывно корректируя эти веса и смещения на основе входных данных и определенного алгоритма обучения. Это непрерывный процесс, в котором модель может делать более точные прогнозы за счет многократных корректировок.
Модель искусственного интеллекта можно рассматривать как своего рода программирование, поскольку она создается с помощью определенных алгоритмов и математических вычислений, а корректировка ее параметров (весов) постоянно совершенствуется для получения точных прогнозов. Это непрерывный процесс.
Смещения — это дополнительные параметры в нейронных сетях, которые добавляются к взвешенным входным значениям нейрона. Они позволяют присваивать параметрам весовые коэффициенты (важные, менее важные и т. д.), что делает ИИ более гибким и точным.
Нейронные сети могут не только хранить отдельные факты, но и распознавать взаимосвязи между данными посредством распознавания образов. Пример со Штутгартом иллюстрирует, как знания могут подаваться в нейронную сеть, но нейронные сети обучаются не на основе явных знаний (как в этом простом примере), а путем анализа закономерностей в данных. Следовательно, нейронные сети могут не только хранить отдельные факты, но и обучаться весам и взаимосвязям между входными данными.
Этот процесс дает понятное представление о том, как работает искусственный интеллект, и нейронные сети в частности, не углубляясь слишком сильно в технические детали. Он демонстрирует, что информация хранится в нейронных сетях не так, как в обычных базах данных, а путем корректировки связей (весов) внутри сети.
🤖📚 Подробнее: Как обучается ИИ?
🏋️♂️ Обучение ИИ, особенно модели машинного обучения, включает в себя несколько этапов. Обучение ИИ основано на непрерывной оптимизации параметров модели посредством обратной связи и корректировки до тех пор, пока модель не покажет наилучшие результаты на предоставленных данных. Вот подробное объяснение того, как работает этот процесс:
1. 📊 Сбор и подготовка данных
Данные являются основой обучения ИИ. Обычно они состоят из тысяч или миллионов примеров, которые система должна анализировать. Примеры включают изображения, текст или временные ряды.
Данные необходимо очистить и нормализовать, чтобы избежать ненужных источников ошибок. Часто данные преобразуются в признаки, содержащие релевантную информацию.
2. 🔍 Определить модель
Модель — это математическая функция, описывающая взаимосвязи в данных. В нейронных сетях, которые часто используются в искусственном интеллекте, модель состоит из множества взаимосвязанных слоев нейронов.
Каждый нейрон выполняет математическую операцию для обработки входных данных, а затем передает сигнал следующему нейрону.
3. 🔄 Инициализация весов
Связи между нейронами имеют весовые коэффициенты, которые изначально устанавливаются случайным образом. Эти весовые коэффициенты определяют, насколько сильно нейрон реагирует на сигнал.
Цель обучения — скорректировать эти веса таким образом, чтобы модель делала более точные прогнозы.
4. ➡️ Прямое распространение
В ходе прямого прохода входные данные обрабатываются моделью для получения прогноза.
Каждый слой обрабатывает данные и передает их следующему слою, пока последний слой не выдаст результат.
5. ⚖️ Рассчитайте функцию потерь
Функция потерь измеряет, насколько хорошо предсказания модели соответствуют фактическим значениям (меткам). Распространенной мерой является ошибка между предсказанным и фактическим откликом.
Чем выше значение функции потерь, тем хуже прогноз модели.
6. 🔙 Обратное распространение
При обратной итерации ошибка отслеживается от выходных данных модели до предыдущих слоев.
Ошибка перераспределяется между весами связей, и модель корректирует веса таким образом, чтобы ошибки становились меньше.
Это делается с помощью градиентного спуска: вычисляется градиентный вектор, который указывает, как следует изменять веса для минимизации ошибки.
7. 🔧 Обновить веса
После вычисления ошибки веса связей обновляются с небольшой корректировкой, основанной на скорости обучения.
Скорость обучения определяет, насколько изменяются веса на каждом шаге. Слишком большие изменения могут сделать модель нестабильной, а слишком малые — замедлить процесс обучения.
8. 🔁 Повтор (эпохи)
Этот процесс прямого прохода, вычисления ошибки и обновления весов повторяется, часто в течение нескольких эпох (проходов по всему набору данных), пока модель не достигнет приемлемой точности.
С каждой новой эпохой модель немного лучше усваивает информацию и дополнительно корректирует свои веса.
9. 📉 Валидация и тестирование
После обучения модель тестируется на проверенном наборе данных, чтобы оценить её обобщающую способность. Это гарантирует, что модель не только «запомнила» обучающие данные, но и делает точные прогнозы на неизвестных данных.
Тестовые данные помогают оценить конечную эффективность модели до ее практического применения.
10. 🚀 Оптимизация
Дальнейшие шаги по улучшению модели включают настройку гиперпараметров (например, корректировку скорости обучения или структуры сети), регуляризацию (для предотвращения переобучения) или увеличение объема данных.
📊🔙 Искусственный интеллект: Как сделать «черный ящик» ИИ понятным, доступным для понимания и объяснения с помощью объяснимого ИИ (XAI), тепловых карт, суррогатных моделей и других решений


Искусственный интеллект: Как сделать «черный ящик» ИИ понятным, доступным и объяснимым с помощью объяснимого ИИ (XAI), тепловых карт, суррогатных моделей и других решений – Изображение: Xpert.Digital
Так называемый «черный ящик» искусственного интеллекта (ИИ) представляет собой значительную и насущную проблему. Даже эксперты часто сталкиваются с проблемой неполного понимания того, как системы ИИ принимают свои решения. Эта непрозрачность может вызывать значительные проблемы, особенно в таких важных областях, как экономика, политика и медицина. Врач, который полагается на систему ИИ для диагностики и выработки рекомендаций по лечению, должен быть уверен в принятых решениях. Однако, если процесс принятия решений ИИ недостаточно прозрачен, возникает неопределенность, потенциально приводящая к потере доверия — и это в ситуациях, когда на кону могут стоять человеческие жизни.
Более подробная информация здесь:
Мы здесь для вас — Консультации — Планирование — Внедрение — Управление проектами
☑️ Поддержка малых и средних предприятий в области стратегии, консалтинга, планирования и реализации проектов
☑️ Разработка или корректировка цифровой стратегии и цифровизации
☑️ Расширение и оптимизация международных процессов продаж
☑️ Глобальные и цифровые торговые платформы B2B
☑️ Развитие новаторского бизнеса

Konrad Wolfenstein
Я с удовольствием стану вашим личным консультантом.
Вы можете связаться со мной, заполнив форму обратной связи ниже, или просто позвонить мне по номеру +49 7348 4088 965 .
Я с нетерпением жду начала нашего совместного проекта.
Напишите мне




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital — это центр для предприятий, специализирующийся на цифровизации, машиностроении, логистике/внутрипроизводственной логистике и фотовольтаике.
С помощью нашего комплексного решения для развития бизнеса мы поддерживаем известные компании на всех этапах, от привлечения новых клиентов до послепродажного обслуживания.
Анализ рынка, маркетинговый маркетинг, автоматизация маркетинга, разработка контента, PR, почтовые рассылки, персонализированные кампании в социальных сетях и работа с потенциальными клиентами — все это входит в число наших цифровых инструментов.
Более подробную информацию можно найти по ссылкам: www.xpert.digital - www.xpert.solar - www.xpert.plus
Поддерживать связь











