
Структурированные данные (разметка) в эпоху ИИ с помощью Schema.org: что на самом деле думают инженеры Google
Предварительная версия Xpert

Available in 27 languages 📢
Предпочитаю Xper.Digital в GoogleⓘОпубликовано: 7 мая 2026 г. / Обновлено: 7 мая 2026 г. – Автор: Konrad Wolfenstein
Структурированные данные (разметка) в эпоху ИИ с помощью Schema.org: что на самом деле думают инженеры Google – Изображение: Xpert.Digital
Секрет SEO от Google: почему ИИ терпит неудачу без структурированных данных
Несмотря на ChatGPT и подобные сервисы: почему инженеры Google продолжают отдавать предпочтение Schema.org
Обновление по SEO: почему Schema.org вытесняет Open Graph в Google
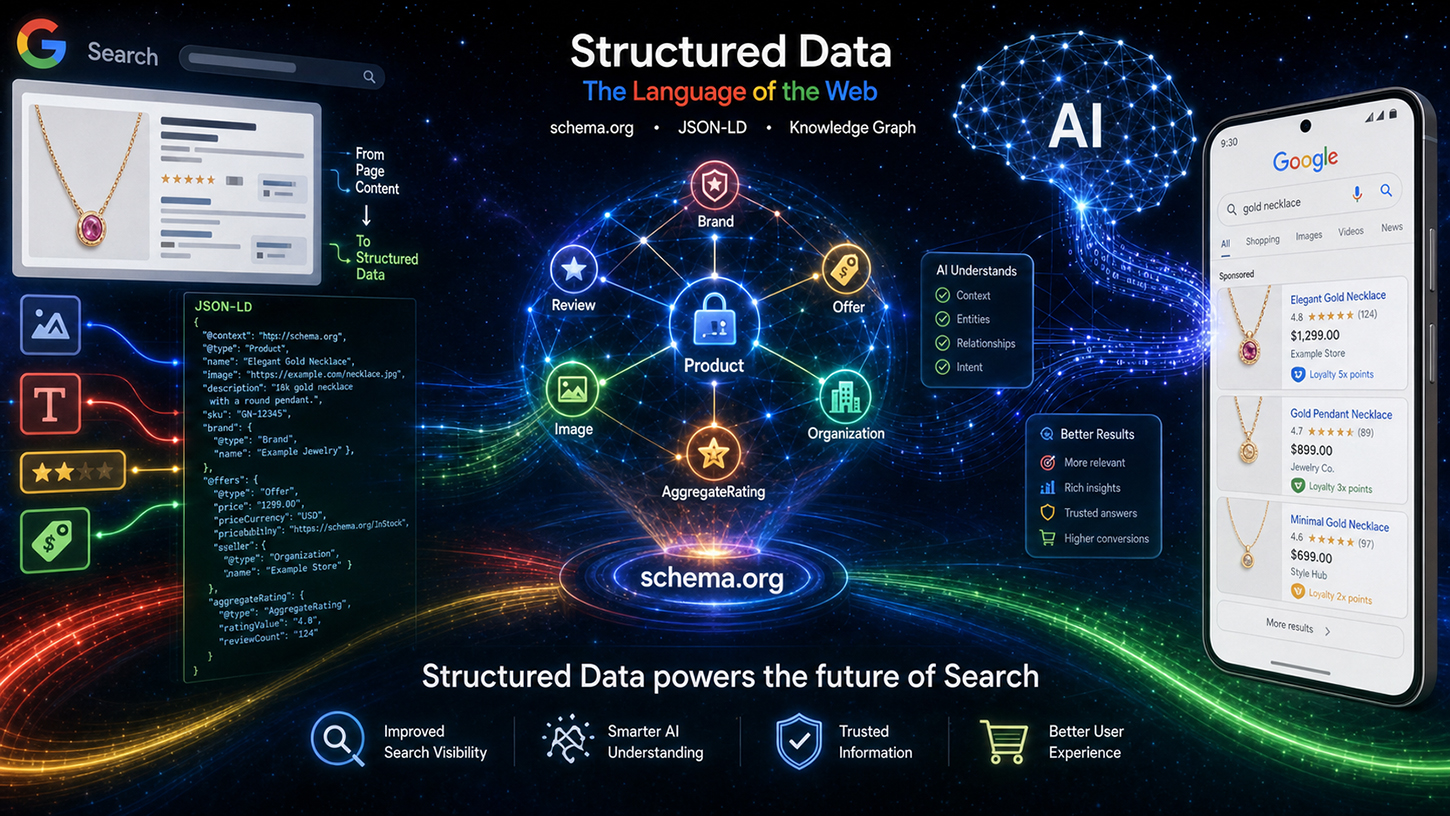
В мире SEO бытует устойчивый миф: в эпоху блестящих языковых моделей ИИ, которые без труда понимают даже неструктурированный текст, тщательно поддерживаемые структурированные данные, такие как Schema.org, просто устарели. Но реальность совершенно иная. На мероприятии Google Search Central Live инженер Google Райан Леверинг развеял это заблуждение и недвусмысленно заявил: структурированная разметка — это не пережиток прошлого, а фундаментальная основа нового поиска на основе ИИ.
От новых обзоров ИИ до автономных агентов для покупок — языковым моделям необходимы точные, машиночитаемые инструкции, чтобы избежать ошибок и работать с высокой вычислительной эффективностью. Те, кто хочет оставаться заметным в современном интернете, должны помочь машинам понимать контекст без двусмысленности. В этой статье рассматривается стратегическая перестройка Google, представлены революционные инновации для электронной коммерции и пользовательского контента, а также показано, почему техническая SEO-оптимизация теперь является решающим конкурентным преимуществом в борьбе за машинную видимость.
Машины могут читать интернет, но только если вы поможете им его понять
21 апреля 2026 года в Торонто состоялось первое мероприятие Google Search Central Live на канадской земле – и это было не обычное отраслевое собрание. Райан Леверинг, инженер Google Search Engineering, представил, пожалуй, самую технически насыщенную и стратегически значимую презентацию дня: «Структурированные данные, качество и ИИ». Его доклад был не просто техническим обзором. Это было четкое заявление о будущем семантической сети в эпоху, когда искусственный интеллект все чаще берет на себя роль посредника между пользователями и информацией.
Между двумя крайностями: неправильный выбор между двумя крайностями
В начале своей презентации Райан Леверинг противопоставил две диаметрально противоположные точки зрения, циркулирующие в SEO-сообществе. С одной стороны, существует убеждение, что структурированные данные просто излишни в эпоху мощных языковых моделей: если модели ИИ легко интерпретируют неструктурированный текст, зачем утруждать себя трудоемким добавлением разметки schema.org в исходный код? С другой стороны, некоторые энтузиасты распространяют идею о том, что структурированные данные — это будущее интернета — универсальный протокол семантической связи между автономными агентами ИИ, который в значительной степени заменит традиционную сеть.
Леверинг отверг обе крайности и вместо этого представил тонкую, эмпирически обоснованную точку зрения. Обе позиции содержали зерно истины, заключил он, но ни одна из них полностью не описывала реальность. Эта тонкость характерна для нынешнего подхода Google к этой теме: речь идет не о догмах, а о прагматической эффективности.
Четыре аргумента, которые всё объясняют
Основной аргумент Леверинга можно резюмировать в четырех ключевых пунктах, которые он подробно изложил в статье под названием «Ценность структурированных данных». Первый пункт — точность: структурированные данные обеспечивают значительно более высокую точность для сложных схем, таких как цены продаж или программы лояльности, чем извлечение информации из свободного текста на основе языковых моделей. Языковые модели могут вводить в заблуждение — они заполняют недостающие атрибуты, неправильно вкладывают данные или получают доступ к информации вне контекста. При извлечении цен на товары с крупного сайта электронной коммерции с десятками похожих товаров частота ошибок значительно выше при использовании искусственного интеллекта, чем при использовании правильно реализованной структурированной разметки.
Второй момент касается дополнительного контента: структурированные данные часто содержат невидимые метаданные, которые просто отсутствуют в отображаемом HTML-коде страницы. Полные форматы дат ISO, стабильные идентификаторы для пользовательского контента или внутренние идентификаторы сущностей — эта информация существует исключительно в разметке. Ни одна языковая модель не может извлечь то, чего нет в тексте.
В-третьих, эффективность: анализ структурированной разметки обходится во много раз дешевле, чем обработка большой языковой модели для извлечения сложных данных. Google ежедневно индексирует миллиарды страниц. Расчет прост: обычный парсер, обрабатывающий JSON-LD, потребляет лишь малую часть вычислительных ресурсов, необходимых для этапа вывода LLM. Таким образом, структурированные данные не только семантически превосходят традиционные методы, но и значительно эффективнее с точки зрения бизнеса. Этот момент имеет прямое отношение к инфраструктуре Google.
Четвертый, и, пожалуй, наиболее недооцененный аспект — это фокусировка: структурированные данные явно выделяют релевантную информацию на странице, предотвращая тем самым выбор нерелевантных данных системами искусственного интеллекта. На странице товара с основным товаром, несколькими связанными товарами и панелью навигации с ценами языковая модель без явных аннотаций не может с уверенностью определить, на какую цену следует ссылаться. Структурированная разметка решает эту проблему за счет однозначного присваивания.
Как на самом деле обрабатываются структурированные данные
Использование разметки Schema.org также сделало технический процесс обработки данных прозрачным. Данные Schema.org сначала обрабатываются с помощью специальной очистки и фильтрации, прежде чем классифицироваться как индексированные данные — разделенные на такие области, как события, покупки и отзывы. Затем эти подготовленные данные поступают в два разных канала вывода: с одной стороны, на классическую страницу результатов поиска (SRP), а с другой — в качестве контекста для систем Google на основе ИИ, в частности, так называемых обзоров ИИ (AIO) и режимов ИИ (AIM). Таким образом, структурированные данные больше не являются просто инструментом для получения подробных результатов, а представляют собой прямой ввод для генеративных ответов ИИ. Это представляет собой фундаментальный сдвиг в стратегической важности разметки Schema.org.
🎯🎯🎯 Центр B2B-индустрии, основанный на данных, как своего рода внутреннее решение

Практически внутреннее решение: как Xpert.Digital устраняет операционные пробелы в B2B-маркетинге и продажах – Умный бизнес, основанный на контенте - Изображение: Xpert.Digital
Xpert.Digital — это ориентированный на данные B2B-индустрионный центр, возглавляемый Konrad Wolfenstein . Компания выступает в качестве внешнего, частично внутреннего решения для отраслевых партнеров, устраняя операционные пробелы в маркетинге, контенте и продажах — без необходимости привлечения дополнительных ресурсов со стороны клиента.
Более подробная информация здесь:
Почему структурированные данные становятся инфраструктурой для агентов искусственного интеллекта
Покупки в центре внимания: доставка, программы лояльности и разнообразие товаров
Значительная часть презентации была посвящена инновациям в электронной коммерции. Леверинг объяснил, что, согласно данным Института Baymard, неожиданная информация о доставке занимает второе и третье места среди наиболее распространенных причин отказа от покупки. Структурированная разметка для служб доставки может напрямую решить эту проблему: теперь продавцы могут точно определять регионы отправления и назначения, размеры и вес, пороговые значения стоимости заказа, время обработки и принадлежность к программам лояльности непосредственно в коде.
Модель расчета времени доставки, используемая Google, разделена на два этапа: время обработки заказа, то есть время от получения заказа до передачи его перевозчику, и фактическое время доставки. Оба этапа могут быть аннотированы отдельно и с высокой степенью детализации — вплоть до времени окончания приема заказов и того, осуществляется ли обработка также в будние дни. Соответствующие примеры JSON-LD показывают, как тип `ShippingConditions` может использоваться для определения бесплатной доставки для определенных стран (например, Франции и Германии) и минимальной суммы заказа (например, 50 евро).
Интеграция служб доставки с программами лояльности является особенно инновационной. Используя свойство `validForMemberTier`, службу доставки можно явно связать с программой лояльности и конкретным уровнем. Это позволяет напрямую указывать в разметке преимущества доставки для участников премиум-класса — функция, ранее доступная только через Google Merchant Center. Сама связанная программа лояльности определяется как объект `MemberProgram` в сущности `Organization`, с уровнями, такими как «Золотой» или «Серебряный», и связанными с ними преимуществами, такими как награды за лояльность или баллы.
Программы лояльности как семантические сущности
Внедрение надбавки за участие в программах лояльности имеет важное экономическое значение. Организации могут определять несколько независимых программ членства, каждая из которых имеет несколько уровней и дифференцированных преимуществ — баллы, цены для участников, условия возврата, бонусы за доставку. Эта информация затем отображается непосредственно в результатах поиска Google, как продемонстрировал Леверинг на реальных примерах, включая предложение Sephora, которое отображало 30-процентную скидку для участников непосредственно в сниппете товаров. По словам Леверинга, следующим запланированным шагом является межстраничная идентификация (Cross-page ID linking), возможность ссылаться на определения программ лояльности с других страниц. В настоящее время этот шаг называется «Прокладывая путь для межстраничной идентификации по @id». Цель: более надежные организационные ссылки между страницами товаров и политикой компании.
Пользовательский контент: проблема разметки с помощью ИИ
Еще одной важной темой стало дальнейшее развитие типов схем для пользовательского контента (UGC). Здесь особенно актуальны две новые функции. Во-первых, поддерживаются встроенные сообщения и репосты в разметке форумов и вопросов и ответов, что позволяет более точно семантически представлять структуру обсуждений. Во-вторых — и это имеет еще большее стратегическое значение — введено свойство `so#digitalSourceType` для явной идентификации контента, созданного машинным способом.
Это нововведение является прямым ответом на поток контента, сгенерированного ИИ, на таких платформах, как форумы и сайты вопросов и ответов. Веб-мастера теперь могут указывать, был ли пост сгенерирован алгоритмически или языковой моделью. Те, кто не указывает это, по умолчанию считаются Google авторами-людьми — правило, которое стимулирует прозрачную маркировку. Свойство `digitalSourceType` основано на кодах IPTC для цифровых источников и различает, среди прочего, контент, сгенерированный алгоритмически, и контент, сгенерированный моделью.
Выбор изображений: Schema превосходит Open Graph
Менее заметное, но практически эффективное обновление касается логики выбора изображений в Google. Система консолидируется внутри компании с четкой иерархией приоритетов: приоритет отдается разметке Schema.org, в частности свойствам `primaryImageOfPage` и `mainEntity → image`. Только после этого следует метатег `og:image` из Open Graph. Это изменение означает, что для владельцев веб-сайтов чистая реализация основного изображения в Schema.org напрямую влияет на его отображение в результатах поиска Google и обзорах AI – конкретное, измеримое преимущество.
Сама компания Schema.org получает инвестиции
Также заслуживает внимания объявленное Google возобновление инвестиций в schema.org как в открытую спецификацию. Были упомянуты три конкретных меры: публикация статистики частоты использования отдельных терминов схемы (данные о распространенности, как показано на слайде, уже доступны для таких терминов, как `digitalSourceType`, с информацией примерно о 10 000 доменах), публикация собственных правил валидации Google в машиночитаемых стандартных форматах, таких как SHACL или ShEx, и улучшенная поддержка правил порядка. Это важно, поскольку позволит сторонним разработчикам создавать собственные инструменты валидации на основе стандартов Google — независимо от официальных инструментов тестирования, которые иногда дают сбои под нагрузкой.
Валидация: два инструмента, одна цель
Компания Levering представила два инструмента проверки, которые дополняют друг друга, но применяют разные критерии тестирования. Инструмент проверки расширенных результатов поиска (Rich Result Test Tool) по адресу `search.google.com/test/rich-results` принимает URL-адреса или чистый JSON и проверяет, подходит ли разметка для расширенных результатов поиска Google — таким образом, он основан на специфических требованиях Google, а не на самом стандарте schema.org. `validator.schema.org`, с другой стороны, проверяет, соответствует ли разметка стандарту schema.org, то есть, открытому словарю, независимо от того, генерирует ли Google на её основе расширенные результаты. Это приводит к четкой рекомендации для веб-разработчиков: следует использовать оба инструмента, поскольку разметка может соответствовать стандарту schema, но не быть пригодной для расширенных результатов — и наоборот.
Более широкая картина: структурированные данные как инфраструктура для искусственного интеллекта
Рассматривая мероприятие в Торонто в целом, можно заметить сдвиг, выходящий далеко за рамки традиционной SEO-оптимизации. Структурированные данные эволюционируют от инструмента для создания расширенных сниппетов к фундаментальному стандарту уровня данных для систем искусственного интеллекта. Google AI Overviews и AI Mode активно используют разметку schema.org в качестве контекста для генерации ответов и проверки сущностей. Те, кто внедряет корректные, полные и точные структурированные данные, не только повышают свои шансы на визуальное выделение в результатах поиска, но и позиционируют свой контент как надежный первоисточник для ответов ИИ.
Упоминание в данном контексте протокола Universal Commerce Protocol (UCP) и WebMCP не случайно. Оба стандарта связи на основе агентов, которые Google выпустил в ранних версиях в 2026 году, требуют семантического описания веб-сайтов. Основой для этого служит Schema.org. В мире, где агенты ИИ действуют автономно в сети, осуществляя поиск, сравнение и инициируя транзакции, машинная читаемость контента перестала быть необязательной и стала необходимым условием экономической значимости. Поэтому презентация Райана Леверинга в Торонто была не просто техническим обзором, а взглядом на инфраструктуру будущего интернета.
Вы сами сможете в этом убедиться за 10 секунд
Если вы хотите узнать, насколько хорошо и полно ваш или другой веб-сайт использует структурированные данные, вы можете воспользоваться именно теми двумя инструментами, которые рекомендовал Райан Леверинг из Google (см. наш текст выше):
Тест расширенных результатов поиска Google (с упором на видимость в Google):
Перейдите по ссылке search.google.com/test/rich-results, скопируйте URL любой статьи с сайта xpert.digital и нажмите «Проверить URL». Инструмент покажет вам, какие именно разметки распознает Google на этой странице и не содержат ли они ошибок.
Валидатор схем (с упором на соответствие стандартам):
Перейдите на сайт validator.schema.orgи вставьте тот же URL-адрес. Здесь вы сможете увидеть непосредственно в исходном коде, выделенном цветом, какие JSON-LD скрипты (структурированные данные) были включены в xpert.digital.
Ваш глобальный партнер по маркетингу и развитию бизнеса
☑️ Язык ведения нашего бизнеса — английский или немецкий
☑️ НОВИНКА: Переписка на вашем родном языке!

Konrad Wolfenstein
Я и моя команда будем рады быть вашими личными консультантами.
Вы можете связаться со мной, заполнив контактную форму здесь просто позвонив по номеру +49 7348 4088 965. Мой адрес электронной почты [email protected]:или
Я с нетерпением жду начала нашего совместного проекта.
☑️ Поддержка малых и средних предприятий в области стратегии, консалтинга, планирования и реализации проектов
☑️ Разработка или корректировка цифровой стратегии и цифровизации
☑️ Расширение и оптимизация международных процессов продаж
☑️ Глобальные и цифровые торговые платформы B2B
☑️ Развитие бизнеса / Маркетинг / PR / Выставки от компании Pioneer
Поддержка B2B и SaaS-решение для SEO и GEO (поиск с использованием ИИ): комплексное решение для B2B-компаний

Поддержка B2B и SaaS-решение для SEO и GEO (поиск с использованием ИИ): комплексное решение для B2B-компаний. — Изображение: Xpert.Digital
Поиск с использованием ИИ меняет всё: как это SaaS-решение навсегда изменит ваши позиции в B2B-рейтинге.
Цифровое пространство для B2B-компаний стремительно меняется. Под влиянием искусственного интеллекта правила онлайн-видимости переписываются. Для компаний всегда было непросто не только быть заметными в цифровом пространстве, но и оставаться актуальными для нужных лиц, принимающих решения. Традиционные стратегии SEO и управление локальным присутствием (геомаркетинг) сложны, трудоемки и часто представляют собой борьбу с постоянно меняющимися алгоритмами и жесткой конкуренцией.
Но что, если бы существовало решение, которое не только упростило бы этот процесс, но и сделало бы его умнее, более предсказуемым и гораздо более эффективным? Именно здесь вступает в игру сочетание специализированной B2B-поддержки с мощной платформой SaaS (программное обеспечение как услуга), специально разработанной для удовлетворения потребностей SEO и GEO в эпоху поиска с использованием искусственного интеллекта.
Новое поколение инструментов больше не полагается исключительно на ручной анализ ключевых слов и стратегии построения обратных ссылок. Вместо этого оно использует искусственный интеллект для более точного понимания поисковых намерений, автоматической оптимизации факторов локального ранжирования и проведения конкурентного анализа в режиме реального времени. Результатом является проактивная, основанная на данных стратегия, которая дает компаниям B2B решающее преимущество: их не только находят, но и воспринимают как ведущих экспертов в своей нише и регионе.
Вот симбиоз B2B-поддержки и SaaS-технологий на базе искусственного интеллекта, который трансформирует SEO и геомаркетинг, и как ваша компания может извлечь из этого выгоду для устойчивого роста в цифровом пространстве.
Более подробная информация здесь:

















