
Попытка объяснить ИИ: как работает и функционирует искусственный интеллект – как его обучают?

Выбор голоса 📢
Опубликовано по телефону: 8 сентября 2024 г. / Обновление с: 9 сентября 2024 г. - Автор: Конрад Вольфенштейн

Попытка объяснить ИИ: как работает искусственный интеллект и как его обучают? – Изображение: Xpert.Digital
📊 От ввода данных до прогнозирования модели: процесс ИИ
Как работает искусственный интеллект (ИИ)? 🤖
Принцип работы искусственного интеллекта (ИИ) можно разделить на несколько четко определенных этапов. Каждый из этих шагов имеет решающее значение для конечного результата, который дает ИИ. Процесс начинается с ввода данных и заканчивается прогнозированием модели и возможной обратной связью или дальнейшими раундами обучения. Эти этапы описывают процесс, через который проходят почти все модели ИИ, независимо от того, представляют ли они собой простые наборы правил или очень сложные нейронные сети.
1. Ввод данных 📊
Основой всего искусственного интеллекта являются данные, с которыми он работает. Эти данные могут быть в различных формах, например изображения, текст, аудиофайлы или видео. ИИ использует эти необработанные данные для распознавания закономерностей и принятия решений. Качество и количество данных играют здесь центральную роль, поскольку они оказывают существенное влияние на то, насколько хорошо или плохо модель будет работать в дальнейшем.
Чем обширнее и точнее данные, тем лучше сможет учиться ИИ. Например, когда ИИ обучается обработке изображений, ему требуется большой объем данных изображения для правильной идентификации различных объектов. В языковых моделях именно текстовые данные помогают ИИ понимать и генерировать человеческий язык. Ввод данных — это первый и один из наиболее важных шагов, поскольку качество прогнозов может быть настолько хорошим, насколько хорошими являются базовые данные. Известный принцип информатики описывает это поговоркой «Мусор на входе, мусор на выходе»: плохие данные приводят к плохим результатам.
2. Предварительная обработка данных 🧹
После ввода данных их необходимо подготовить, прежде чем их можно будет ввести в реальную модель. Этот процесс называется предварительной обработкой данных. Целью здесь является приведение данных в форму, которая может быть оптимально обработана моделью.
Распространенным шагом предварительной обработки является нормализация данных. Это означает, что данные приводятся в единый диапазон значений, чтобы модель обрабатывала их равномерно. Примером может быть масштабирование всех значений пикселей изображения в диапазоне от 0 до 1 вместо 0 до 255.
Другой важной частью предварительной обработки является так называемое извлечение признаков. Из необработанных данных извлекаются определенные функции, которые особенно важны для модели. Например, при обработке изображений это могут быть края или определенные цветовые узоры, а в текстах извлекаются соответствующие ключевые слова или структуры предложений. Предварительная обработка имеет решающее значение для повышения эффективности и точности процесса обучения ИИ.
3. Модель 🧩
Модель — это сердце любого искусственного интеллекта. Здесь данные анализируются и обрабатываются на основе алгоритмов и математических расчетов. Модель может существовать в разных формах. Одной из самых известных моделей является нейронная сеть, основанная на том, как работает человеческий мозг.
Нейронные сети состоят из нескольких слоев искусственных нейронов, которые обрабатывают и передают информацию. Каждый уровень принимает результаты предыдущего уровня и обрабатывает их дальше. Процесс обучения нейронной сети состоит из корректировки весов связей между этими нейронами, чтобы сеть могла делать все более точные прогнозы или классификации. Эта адаптация происходит посредством обучения, при котором сеть получает доступ к большим объемам выборочных данных и итеративно улучшает свои внутренние параметры (веса).
Помимо нейронных сетей, в моделях ИИ используется множество других алгоритмов. К ним относятся деревья решений, случайные леса, машины опорных векторов и многие другие. Какой алгоритм используется, зависит от конкретной задачи и имеющихся данных.
4. Прогноз модели 🔍
После обучения модели на данных она может делать прогнозы. Этот шаг называется прогнозированием модели. ИИ получает входные данные и возвращает выходные данные, то есть прогноз или решение, на основе шаблонов, которые он изучил на данный момент.
Это предсказание может принимать разные формы. Например, в модели классификации изображений ИИ может предсказать, какой объект виден на изображении. В языковой модели он может прогнозировать, какое слово будет следующим в предложении. В финансовых прогнозах ИИ может предсказать, как будет работать фондовый рынок.
Важно подчеркнуть, что точность прогнозов сильно зависит от качества обучающих данных и архитектуры модели. Модель, обученная на недостаточных или предвзятых данных, скорее всего, будет давать неверные прогнозы.
5. Обратная связь и обучение (по желанию) ♻️
Еще одна важная часть работы ИИ — механизм обратной связи. Модель регулярно проверяется и оптимизируется. Этот процесс происходит либо во время обучения, либо после прогнозирования модели.
Если модель делает неправильные прогнозы, она может научиться с помощью обратной связи обнаруживать эти ошибки и соответствующим образом корректировать свои внутренние параметры. Это делается путем сравнения прогнозов модели с фактическими результатами (например, с известными данными, для которых уже существуют правильные ответы). Типичной процедурой в этом контексте является так называемое обучение с учителем, при котором ИИ учится на примерах данных, на которые уже предоставлены правильные ответы.
Распространенным методом обратной связи является алгоритм обратного распространения ошибки, используемый в нейронных сетях. Ошибки, допускаемые моделью, распространяются по сети в обратном направлении, чтобы корректировать веса нейронных связей. Модель учится на своих ошибках и становится все более и более точными в своих прогнозах.
Роль обучения 🏋️♂️
Обучение ИИ — это итеративный процесс. Чем больше данных видит модель и чем чаще она обучается на основе этих данных, тем точнее становятся ее прогнозы. Однако есть и ограничения: у чрезмерно обученной модели могут возникнуть так называемые проблемы «переобучения». Это означает, что он настолько хорошо запоминает обучающие данные, что дает худшие результаты на новых, неизвестных данных. Поэтому важно обучить модель так, чтобы она обобщала и делала хорошие прогнозы даже на новых данных.
Помимо обычного обучения, существуют еще такие процедуры, как трансферное обучение. Здесь для новой аналогичной задачи используется модель, уже обученная на большом объеме данных. Это экономит время и вычислительные мощности, поскольку модель не нужно обучать с нуля.
Используйте свои сильные стороны по максимуму 🚀
Работа искусственного интеллекта основана на сложном взаимодействии различных этапов. От ввода данных, предварительной обработки, обучения модели, прогнозирования и обратной связи — существует множество факторов, влияющих на точность и эффективность ИИ. Хорошо обученный ИИ может принести огромную пользу во многих сферах жизни — от автоматизации простых задач до решения сложных проблем. Но не менее важно понимать ограничения и потенциальные ловушки ИИ, чтобы максимально использовать его сильные стороны.
🤖📚 Объясняем просто: как обучается ИИ?
🤖📊 Процесс обучения ИИ: захватите, свяжите и сохраните
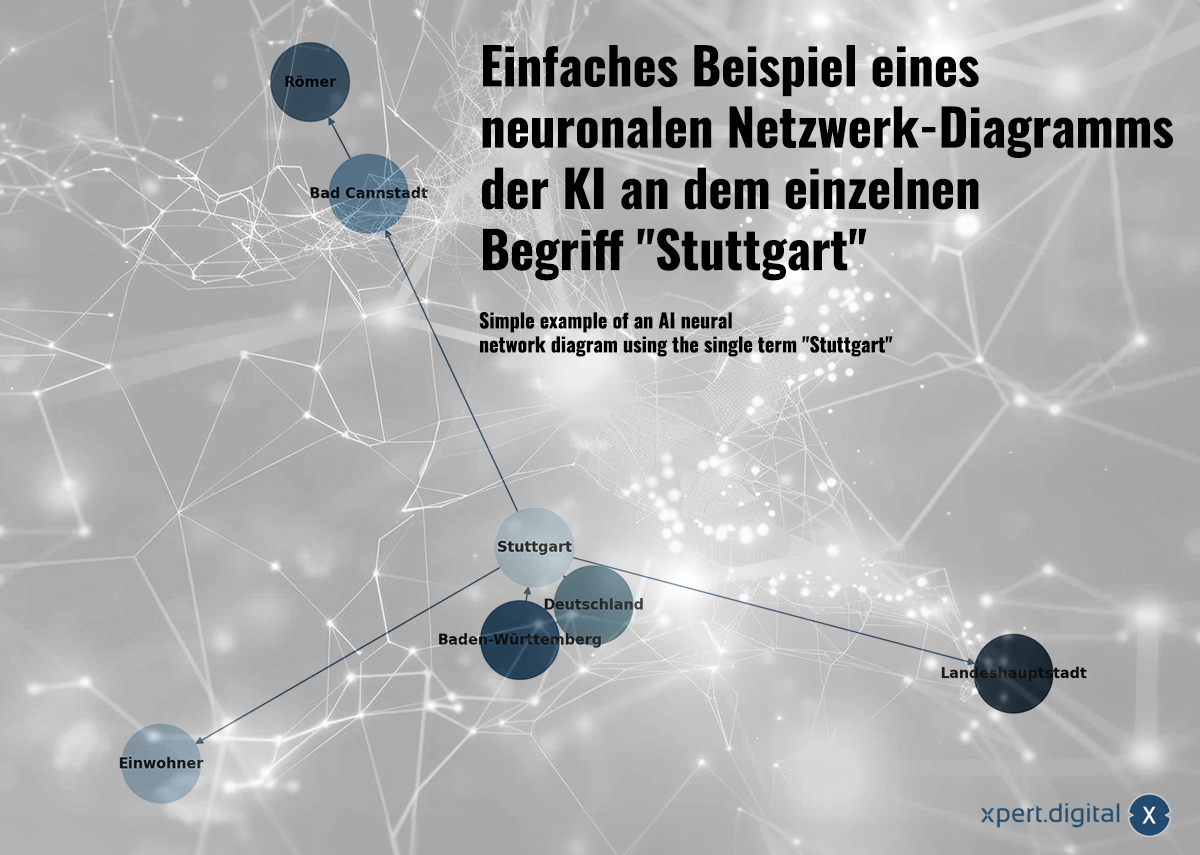
Простой пример нейрональной сетевой диаграммы ИИ на отдельном термине «Штутгарт» -майм: Xpert.Digital
🌟 Соберите и подготовьте данные
Первым шагом в процессе обучения ИИ является сбор и подготовка данных. Эти данные могут поступать из различных источников, таких как базы данных, датчики, тексты или изображения.
🌟 Связывание данных (нейронная сеть)
Собранные данные связаны друг с другом в нейронной сети. Каждый пакет данных показан подключениями в сети «нейронов» (узел). Простой пример с городом Штутгарт может выглядеть так:
а) Штутгарт — город в земле Баден-Вюртемберг
б) Баден-Вюртемберг — федеральная земля в Германии
в) Штутгарт — город в Германии г
) Население Штутгарта в 2023 году составляет 633 484 человека
д) Бад-Каннштатт — район Штутгарта
е) Бад-Канштатт был основан римлянами
ж) Штутгарт — столица земли Баден-Вюртемберг.
В зависимости от размера объема данных параметры потенциальных расходов создаются с использованием используемой модели ИИ. Например: GPT-3 имеет примерно 175 миллиардов параметров!
🌟 Хранение и настройка (обучение)
Данные подаются в нейронную сеть. Они проходят через модель ИИ и обрабатываются через соединения (аналогично синапсам). Веса (параметры) между нейронами корректируются для обучения модели или выполнения задачи.
В отличие от обычных форм памяти, таких как прямой доступ, указанный доступ, последовательное или стековое хранилище, нейронные сети хранят данные нетрадиционным образом. «Данные» хранятся в весах и смещениях соединений между нейронами.
Фактическое «хранение» информации в нейрональной сети происходит путем адаптации весов соединения между нейронами. Модель ИИ «учится», постоянно адаптируя эти веса и смещения на основе входных данных и определенного алгоритма обучения. Это непрерывный процесс, в котором модель может делать точные прогнозы из -за повторяющихся корректировок.
Модель ИИ можно считать разновидностью программирования, поскольку она создается с помощью определенных алгоритмов и математических расчетов и постоянно совершенствует настройку своих параметров (весов) для получения точных прогнозов. Это непрерывный процесс.
Смещения — это дополнительные параметры в нейронных сетях, которые добавляются к взвешенным входным значениям нейрона. Они позволяют взвешивать параметры (важные, менее важные, важные и т. д.), делая ИИ более гибким и точным.
Нейронные сети могут не только хранить отдельные факты, но и распознавать связи между данными посредством распознавания образов. Пример Штутгарта иллюстрирует, как знания могут быть введены в нейронную сеть, но нейронные сети обучаются не посредством явных знаний (как в этом простом примере), а посредством анализа шаблонов данных. Нейронные сети могут не только хранить отдельные факты, но также изучать веса и взаимосвязи между входными данными.
Этот поток обеспечивает понятное введение в то, как работают ИИ и нейронные сети, в частности, без слишком глубокого погружения в технические детали. Он показывает, что хранение информации в нейронных сетях осуществляется не так, как в традиционных базах данных, а путем корректировки связей (весов) внутри сети.
🤖📚 Подробнее: Как обучается ИИ?
🏋️♂️ Обучение ИИ, особенно модели машинного обучения, происходит в несколько этапов. Обучение ИИ основано на постоянной оптимизации параметров модели посредством обратной связи и корректировок до тех пор, пока модель не покажет наилучшую производительность на предоставленных данных. Вот подробное объяснение того, как работает этот процесс:
1. 📊 Соберите и подготовьте данные
Данные — это основа обучения ИИ. Обычно они состоят из тысяч или миллионов примеров, которые система может проанализировать. Примерами являются изображения, тексты или данные временных рядов.
Данные необходимо очистить и нормализовать, чтобы избежать ненужных источников ошибок. Часто данные преобразуются в функции, содержащие соответствующую информацию.
2. 🔍 Определить модель
Модель — это математическая функция, описывающая взаимосвязи в данных. В нейронных сетях, которые часто используются для искусственного интеллекта, модель состоит из нескольких слоев нейронов, соединенных вместе.
Каждый нейрон выполняет математическую операцию по обработке входных данных, а затем передает сигнал следующему нейрону.
3. 🔄 Инициализировать веса
Связи между нейронами имеют веса, которые изначально задаются случайным образом. Эти веса определяют, насколько сильно нейрон реагирует на сигнал.
Цель обучения — скорректировать эти веса, чтобы модель давала более точные прогнозы.
4. ➡️ Прямое распространение
Прямой проход передает входные данные через модель для создания прогноза.
Каждый уровень обрабатывает данные и передает их следующему уровню, пока последний уровень не предоставит результат.
5. ⚖️ Рассчитать функцию потерь
Функция потерь измеряет, насколько хороши прогнозы модели по сравнению с фактическими значениями (метками). Обычной мерой является ошибка между прогнозируемым и фактическим ответом.
Чем выше потери, тем хуже был прогноз модели.
6. 🔙 Обратное распространение ошибки
При обратном проходе ошибка передается обратно из выходных данных модели на предыдущие слои.
Ошибка перераспределяется по весам связей, и модель корректирует веса так, чтобы ошибки стали меньше.
Это делается с помощью градиентного спуска: вычисляется вектор градиента, который указывает, как следует изменить веса, чтобы минимизировать ошибку.
7. 🔧 Обновление весов
После расчета ошибки веса соединений обновляются с небольшой корректировкой в зависимости от скорости обучения.
Скорость обучения определяет, насколько веса меняются с каждым шагом. Слишком большие изменения могут сделать модель нестабильной, а слишком маленькие изменения приводят к медленному процессу обучения.
8. 🔁 Повтор (Эпоха)
Этот процесс прямого прохода, расчета ошибок и обновления веса повторяется, часто в течение нескольких эпох (проходит через весь набор данных), пока модель не достигнет приемлемой точности.
С каждой эпохой модель узнает немного больше и дополнительно корректирует свои веса.
9. 📉 Валидация и тестирование
После обучения модели она тестируется на проверенном наборе данных, чтобы проверить, насколько хорошо она обобщает. Это гарантирует, что он не только «запомнит» обучающие данные, но и сделает хорошие прогнозы на основе неизвестных данных.
Данные испытаний помогают оценить окончательную производительность модели перед ее использованием на практике.
10. 🚀 Оптимизация
Дополнительные шаги по улучшению модели включают настройку гиперпараметров (например, настройку скорости обучения или структуры сети), регуляризацию (во избежание переобучения) или увеличение объема данных.
📊🔙 Искусственный интеллект: сделайте черный ящик ИИ понятным, понятным и объяснимым с помощью объяснимого ИИ (XAI), тепловых карт, суррогатных моделей или других решений.

Искусственный интеллект: делаем черный ящик ИИ понятным, понятным и объяснимым с помощью объяснимого ИИ (XAI), тепловых карт, суррогатных моделей или других решений. Изображение: Xpert.Digital
Так называемый «черный ящик» искусственного интеллекта (ИИ) представляет собой серьезную и актуальную проблему. Даже эксперты часто сталкиваются с проблемой неспособности полностью понять, как системы ИИ приходят к своим решениям. Отсутствие прозрачности может вызвать серьезные проблемы, особенно в таких важных областях, как экономика, политика или медицина. Врач или медицинский работник, который полагается на систему искусственного интеллекта для диагностики и рекомендации лечения, должен быть уверен в принимаемых решениях. Однако если процесс принятия решений ИИ недостаточно прозрачен, возникает неопределенность и, возможно, отсутствие доверия – в ситуациях, когда на карту могут быть поставлены человеческие жизни.
Подробнее об этом здесь:
Мы здесь для вас - советы - планирование - реализация - управление проектами
☑️ Поддержка МСП в разработке стратегии, консультировании, планировании и реализации.
☑️ Создание или корректировка цифровой стратегии и цифровизации.
☑️ Расширение и оптимизация процессов международных продаж.
☑️ Глобальные и цифровые торговые платформы B2B
☑️ Пионерское развитие бизнеса

Конрад Вольфенштейн
Буду рад стать вашим личным консультантом.
Вы можете связаться со мной, заполнив контактную форму ниже, или просто позвонить мне по телефону +49 89 89 674 804 (Мюнхен) .
Я с нетерпением жду нашего совместного проекта.
Напиши мне

Xpert.Digital - Конрад Вольфенштейн
Xpert.Digital — это промышленный центр с упором на цифровизацию, машиностроение, логистику/внутреннюю логистику и фотоэлектрическую энергетику.
С помощью нашего решения для развития бизнеса на 360° мы поддерживаем известные компании, начиная с нового бизнеса и заканчивая послепродажным обслуживанием.
Аналитика рынка, маркетинг, автоматизация маркетинга, разработка контента, PR, почтовые кампании, персонализированные социальные сети и привлечение потенциальных клиентов являются частью наших цифровых инструментов.
Дополнительную информацию можно узнать на сайте: www.xpert.digital - www.xpert.solar - www.xpert.plus
Оставаться на связи


















