Ошибочный расчет на 57 миллиардов долларов – предупреждает NVIDIA, как никакая другая компания: индустрия ИИ сделала ставку не на ту лошадь – Изображение: Xpert.Digital
Забудьте о гигантах ИИ: почему будущее за компактными, децентрализованными и гораздо более дешевыми решениями
### Небольшие языковые модели: ключ к истинной автономии бизнеса ### От крупных компаний обратно к пользователям: смена власти в мире ИИ ### Ошибка в 57 миллиардов долларов: почему настоящая революция ИИ происходит не в облаке ### Тихая революция ИИ: децентрализация вместо централизации ### Технологические гиганты на неверном пути: будущее ИИ — за бережливым и локальным подходом ### От крупных компаний обратно к пользователям: смена власти в мире ИИ ###
Миллиарды долларов потраченных впустую инвестиций: почему небольшие модели ИИ обгоняют большие
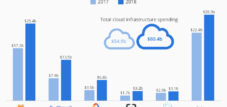
Мир искусственного интеллекта переживает землетрясение, масштабы которого напоминают коррекцию в эпоху доткомов. В основе этого потрясения лежит колоссальная ошибка в расчетах: в то время как такие технологические гиганты, как Microsoft, Google и Meta, инвестируют сотни миллиардов в централизованную инфраструктуру для масштабных языковых моделей (Large Language Models, LLM), реальный рынок их применения значительно отстает. Новаторский анализ, проведенный, в частности, самим лидером отрасли NVIDIA, показывает, что разрыв составляет 57 миллиардов долларов инвестиций в инфраструктуру по сравнению с реальным рынком всего в 5,6 миллиарда долларов — десятикратное расхождение.
Эта стратегическая ошибка проистекает из предположения, что будущее ИИ лежит исключительно в постоянно увеличивающихся, всё более ресурсоёмких и централизованно управляемых моделях. Но теперь эта парадигма рушится. Тихая революция, движимая децентрализованными, более компактными языковыми моделями (SLM), переворачивает устоявшийся порядок с ног на голову. Эти модели не только во много раз дешевле и эффективнее, но и позволяют компаниям достичь новых уровней автономии, суверенитета данных и гибкости — вдали от дорогостоящей зависимости от нескольких крупных облачных провайдеров. В этом тексте анализируется структура этих многомиллиардных инвестиций и демонстрируется, почему настоящая революция в области ИИ происходит не в гигантских центрах обработки данных, а децентрализованно и на компактном оборудовании. Это история фундаментального сдвига власти от поставщиков инфраструктуры обратно к пользователям технологии.
В связи с этим:


Исследование NVIDIA о неэффективном распределении капитала в сфере ИИ
Представленные вами данные взяты из исследовательской работы NVIDIA, опубликованной в июне 2025 года. Полный источник:
«Небольшие языковые модели — это будущее агентного ИИ»
- Авторы: Питер Белчак, Грег Генрих, Шиже Дяо, Юнган Фу, Синь Донг, Саурав Муралидхаран, Йингян Селин Линь, Павел Молчанов
- Дата выпуска: 2 июня 2025 г. (Версия 1), последнее обновление: 15 сентября 2025 г. (Версия 2)
- Место публикации: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Официальная страница NVIDIA Research: https://research.nvidia.com/labs/lpr/slm-agents/
Главный посыл относительно нерационального распределения капитала
Исследование выявило принципиальное несоответствие между инвестициями в инфраструктуру и фактическим объемом рынка: в 2024 году отрасль инвестировала 57 миллиардов долларов в облачную инфраструктуру для поддержки API-сервисов больших языковых моделей (LLM), в то время как фактический рынок этих сервисов составлял всего 5,6 миллиарда долларов. Это десятикратное расхождение в исследовании интерпретируется как признак стратегической ошибки, поскольку отрасль вложила значительные средства в централизованную инфраструктуру для крупномасштабных моделей, хотя 40-70% текущих рабочих нагрузок LLM можно было бы заменить более мелкими, специализированными малыми языковыми моделями (SLM) с затратами в 30 раз меньшей стоимости.
Контекст исследования и авторство
Данное исследование представляет собой аналитическую записку исследовательской группы по эффективности глубокого обучения в NVIDIA Research. Ведущий автор, Питер Белчак, — исследователь в области искусственного интеллекта в NVIDIA, специализирующийся на надежности и эффективности систем на основе агентов. В статье изложены три основных положения:
SLMs — это
- достаточно мощный
- хирургически пригодный и
- экономически необходимо
для множества вариантов использования в агентных системах искусственного интеллекта.
Исследователи особо подчеркивают, что изложенные в данной статье взгляды принадлежат авторам и не обязательно отражают позицию компании NVIDIA. NVIDIA приглашает к критическому обсуждению и обязуется публиковать всю соответствующую переписку на прилагаемом веб-сайте.
Почему децентрализованные модели для небольших языков делают ставку на централизованную инфраструктуру устаревшей
Искусственный интеллект находится на переломном этапе, последствия которого напоминают потрясения, произошедшие во время пузыря доткомов. Исследование NVIDIA выявило фундаментальную ошибку в распределении капитала, которая подрывает основы текущей стратегии компании в области ИИ. В то время как технологическая индустрия инвестировала 57 миллиардов долларов в централизованную инфраструктуру для крупномасштабных языковых моделей, фактический рынок их использования вырос всего до 5,6 миллиардов долларов. Это десятикратное расхождение не только свидетельствует о переоценке спроса, но и выявляет фундаментальную стратегическую ошибку в отношении будущего искусственного интеллекта.
Неудачная инвестиция? Миллиарды потрачены на инфраструктуру ИИ — что делать с избыточными мощностями?
Цифры говорят сами за себя. По данным различных анализов, в 2024 году глобальные расходы на инфраструктуру ИИ достигли от 80 до 87 миллиардов долларов, причем подавляющая часть пришлась на центры обработки данных и ускорители. Microsoft объявила об инвестициях в размере 80 миллиардов долларов на 2025 финансовый год, Google повысила свой прогноз до 91–93 миллиардов долларов, а Meta планирует инвестировать до 70 миллиардов долларов. Только эти три крупных игрока представляют собой объем инвестиций более 240 миллиардов долларов. По оценкам McKinsey, общие расходы на инфраструктуру ИИ могут достичь от 3,7 до 7,9 триллионов долларов к 2030 году.
Напротив, реальность со стороны спроса отрезвляет. Рынок корпоративных больших языковых моделей оценивался всего в 4–6,7 миллиарда долларов на 2024 год, а прогнозы на 2025 год варьируются от 4,8 до 8 миллиардов долларов. Даже самые оптимистичные оценки рынка генеративного ИИ в целом составляют от 28 до 44 миллиардов долларов на 2024 год. Фундаментальное несоответствие очевидно: инфраструктура была создана для рынка, который не существует в таком виде и масштабе.
Эта неэффективная инвестиция проистекает из предположения, которое все чаще оказывается ложным: что будущее ИИ лежит в постоянно увеличивающихся, централизованных моделях. Крупные провайдеры проводили стратегию масштабного масштабирования, руководствуясь убеждением, что количество параметров и вычислительная мощность являются решающими конкурентными факторами. GPT-3, с 175 миллиардами параметров, считался прорывом в 2020 году, а GPT-4, с более чем триллионом параметров, установил новые стандарты. Отрасль слепо следовала этой логике и инвестировала в инфраструктуру, разработанную для нужд моделей, которые слишком велики для большинства сценариев использования.
Структура инвестиций наглядно демонстрирует нерациональное распределение ресурсов. Во втором квартале 2025 года 98 процентов из 82 миллиардов долларов, потраченных на инфраструктуру ИИ, были направлены на серверы, причем 91,8 процента из них — на системы с ускорением на графических процессорах (GPU) и процессорах XPU. Гипермасштабные компании и создатели облачных сервисов поглотили 86,7 процента этих расходов, что составляет примерно 71 миллиард долларов за один квартал. Такая концентрация капитала в высокоспециализированном, чрезвычайно энергоемком оборудовании для обучения и вывода масштабных моделей игнорирует фундаментальную экономическую реальность: большинству корпоративных приложений такая мощность не требуется.
Парадигма меняется: от централизованного к децентрализованному управлению
Сама компания NVIDIA, главный бенефициар недавнего инфраструктурного бума, теперь предоставляет анализ, который бросает вызов этой парадигме. Исследование малых языковых моделей как будущего агентного ИИ утверждает, что модели с менее чем 10 миллиардами параметров не только достаточны, но и превосходят их по производительности в подавляющем большинстве приложений ИИ. Исследование трех крупных систем агентного ИИ с открытым исходным кодом показало, что от 40 до 70 процентов обращений к большим языковым моделям можно заменить специализированными малыми моделями без потери производительности.
Эти результаты ставят под сомнение фундаментальные предположения существующей инвестиционной стратегии. Если MetaGPT может заменить 60 процентов своих вызовов LLM, Open Operator — 40 процентов, а Cradle — 70 процентов на SLM, то инфраструктурные мощности созданы для удовлетворения потребностей, которых в таком масштабе не существует. Экономическая ситуация кардинально меняется: эксплуатация малой языковой модели Llama 3.1B обходится в десять-тридцать раз дешевле, чем её более крупной версии, Llama 3.3 405B. Тонкая настройка может быть выполнена за несколько часов работы графического процессора вместо недель. Многие SLM работают на потребительском оборудовании, полностью исключая зависимость от облачных сервисов.
Стратегический сдвиг носит фундаментальный характер. Контроль переходит от поставщиков инфраструктуры к операторам. Если предыдущая архитектура вынуждала компании зависеть от нескольких крупных провайдеров, то децентрализация через SLM-системы обеспечивает новую автономию. Модели могут работать локально, данные остаются внутри компании, исключаются затраты на API, и преодолевается зависимость от конкретного поставщика. Это не просто технологическая трансформация, а трансформация политической власти.
Предыдущая ставка на централизованные крупномасштабные модели основывалась на предположении об экспоненциальном масштабировании. Однако эмпирические данные все чаще противоречат этому. Microsoft Phi-3 с 7 миллиардами параметров достигает производительности генерации кода, сравнимой с моделями с 70 миллиардами параметров. NVIDIA Nemotron Nano 2 с 9 миллиардами параметров превосходит Qwen3-8B в тестах на логическое мышление, демонстрируя в шесть раз большую пропускную способность. Эффективность на параметр возрастает с уменьшением размера моделей, в то время как большие модели часто активируют лишь часть своих параметров для заданного входного сигнала — это неизбежная неэффективность.
Экономическое превосходство моделей для изучения малых языков
Структура затрат наглядно демонстрирует экономическую реальность. Обучение моделей класса GPT-4 оценивается более чем в 100 миллионов долларов, а Gemini Ultra потенциально может обойтись в 191 миллион долларов. Даже тонкая настройка больших моделей для конкретных областей может стоить десятки тысяч долларов в виде времени работы графического процессора. В отличие от этого, SLM можно обучить и доработать всего за несколько тысяч долларов, часто на одном высокопроизводительном графическом процессоре.
Затраты на вывод данных показывают еще более существенные различия. GPT-4 обходится примерно в 0,03 доллара за 1000 входных токенов и 0,06 доллара за 1000 выходных токенов, что в сумме составляет 0,09 доллара за средний запрос. Mistral 7B, например, в качестве SLM, обходится в 0,0001 доллара за 1000 входных токенов и 0,0003 доллара за 1000 выходных токенов, или 0,0004 доллара за запрос. Это представляет собой снижение затрат в 225 раз. При миллионах запросов эта разница в сумме дает существенные результаты, которые напрямую влияют на прибыльность.
Общая стоимость владения раскрывает дополнительные аспекты. Самостоятельное размещение модели с 7 миллиардами параметров на физических серверах с графическими процессорами L40S обходится примерно в 953 доллара в месяц. Тонкая настройка в облаке с помощью AWS SageMaker на экземплярах g5.2xlarge стоит 1,32 доллара в час, а потенциальные затраты на обучение для моделей меньшего размера начинаются от 13 долларов. Круглосуточное развертывание для вывода результатов обойдется примерно в 950 долларов в месяц. По сравнению со стоимостью API для непрерывного использования больших моделей, которая может легко достигать десятков тысяч долларов в месяц, экономическое преимущество становится очевидным.
Скорость внедрения — часто недооцениваемый экономический фактор. В то время как тонкая настройка большой языковой модели может занять недели, SLM готовы к использованию за несколько часов или дней. Гибкость в быстром реагировании на новые требования, добавлении новых возможностей или адаптации поведения становится конкурентным преимуществом. На быстро меняющихся рынках эта разница во времени может стать решающим фактором между успехом и неудачей.
Экономика масштаба меняется. Традиционно экономия масштаба рассматривалась как преимущество гипермасштабируемых компаний, которые поддерживают огромные мощности и распределяют их между множеством клиентов. Однако с помощью SLM даже небольшие организации могут эффективно масштабироваться, поскольку требования к оборудованию значительно ниже. Стартап может создать специализированный SLM с ограниченным бюджетом, который превзойдет крупную универсальную модель для решения конкретной задачи. Демократизация разработки ИИ становится экономической реальностью.
Технические основы прорывных технологий
Технологические инновации, обеспечивающие работу SLM, столь же значимы, как и их экономические последствия. Дистилляция знаний, метод, при котором уменьшенная модель-ученик поглощает знания большей модели-учителя, доказала свою высокую эффективность. DistilBERT успешно сжал BERT, а TinyBERT использовал аналогичные принципы. Современные подходы позволяют упростить возможности больших генеративных моделей, таких как GPT-3, до значительно меньших версий, демонстрирующих сопоставимую или лучшую производительность в конкретных задачах.
В этом процессе используются как мягкие метки (вероятностные распределения) модели-учителя, так и жесткие метки исходных данных. Такое сочетание позволяет меньшей модели улавливать тонкие закономерности, которые были бы утеряны в простых парах «вход-выход». Передовые методы дистилляции, такие как пошаговая дистилляция, показали, что небольшие модели могут достигать лучших результатов, чем LLM, даже при меньшем объеме обучающих данных. Это коренным образом меняет экономику: вместо дорогостоящих и длительных циклов обучения на тысячах графических процессоров достаточно целевых процессов дистилляции.
Квантование снижает точность числового представления весов модели. Вместо 32-битных или 16-битных чисел с плавающей запятой квантованные модели используют 8-битные или даже 4-битные целочисленные представления. Требования к памяти пропорционально снижаются, скорость вывода увеличивается, а энергопотребление падает. Современные методы квантования минимизируют потерю точности, часто оставляя производительность практически неизменной. Это позволяет развертывать модели на периферийных устройствах, смартфонах и встроенных системах, что было бы невозможно при использовании полностью точных больших моделей.
Обрезка удаляет избыточные связи и параметры из нейронных сетей. Подобно редактированию слишком длинного текста, выявляются и удаляются несущественные элементы. Структурированная обрезка удаляет целые нейроны или слои, в то время как неструктурированная обрезка удаляет отдельные веса. Полученная структура сети более эффективна, требует меньше памяти и вычислительной мощности, но при этом сохраняет свои основные возможности. В сочетании с другими методами сжатия обрезанные модели достигают впечатляющего повышения эффективности.
Низкоранговая факторизация разлагает большие матрицы весов на произведения меньших матриц. Вместо одной матрицы с миллионами элементов система хранит и обрабатывает две значительно меньшие матрицы. Математическая операция остается приблизительно той же, но вычислительные затраты значительно снижаются. Этот метод особенно эффективен в трансформерных архитектурах, где механизмы внимания доминируют в умножении больших матриц. Экономия памяти позволяет использовать более крупные контекстные окна или пакеты данных при том же аппаратном бюджете.
Сочетание этих методов в современных SLM, таких как серия Microsoft Phi, Google Gemma или NVIDIA Nemotron, демонстрирует потенциал. Phi-2, имея всего 2,7 миллиарда параметров, превосходит модели Mistral и Llama-2 с 7 и 13 миллиардами параметров соответственно в совокупных тестах и показывает лучшие результаты, чем в 25 раз большая Llama-2-70B в задачах многошагового рассуждения. Этого удалось достичь благодаря стратегическому выбору данных, генерации высококачественных синтетических данных и инновационным методам масштабирования. Вывод очевиден: размер больше не является показателем возможностей.
Динамика рынка и потенциал замещения
Эмпирические данные, полученные в реальных условиях, подтверждают теоретические соображения. Анализ NVIDIA платформы разработки программного обеспечения MetaGPT, предназначенной для работы с многоагентными системами, показал, что примерно 60 процентов запросов LLM являются взаимозаменяемыми. К таким задачам относятся генерация шаблонного кода, создание документации и структурированный вывод — все это области, где специализированные SLM работают быстрее и экономичнее, чем универсальные крупномасштабные модели.
Система автоматизации рабочих процессов Open Operator, демонстрируя свой потенциал замещения на 40%, показывает, что даже в сложных сценариях оркестровки многие подзадачи не требуют полной мощности моделей с большим объемом данных (LLM). Анализ намерений, вывод на основе шаблонов и решения по маршрутизации могут обрабатываться более эффективно с помощью тонко настроенных небольших моделей. Оставшиеся 60%, которые фактически требуют глубокого анализа или обширных знаний об окружающем мире, оправдывают использование больших моделей.
Система автоматизации графического интерфейса пользователя Cradle демонстрирует наибольший потенциал замещения — 70 процентов. Повторяющиеся взаимодействия с пользовательским интерфейсом, последовательности кликов и заполнение форм идеально подходят для моделей управления обучением. Задачи четко определены, вариативность ограничена, а требования к пониманию контекста невелики. Специализированная модель, обученная на взаимодействиях с графическим интерфейсом, превосходит универсальную модель управления обучением по скорости, надежности и стоимости.
Эти закономерности повторяются в различных областях применения. Чат-боты для обслуживания клиентов, отвечающие на часто задаваемые вопросы, классификация документов, анализ настроений, распознавание именованных сущностей, простые переводы, запросы к базам данных на естественном языке — все эти задачи выигрывают от использования SLM. По оценкам одного исследования, в типичных корпоративных развертываниях ИИ от 60 до 80 процентов запросов попадают в категории, для которых достаточно SLM. Последствия для спроса на инфраструктуру значительны.
Концепция маршрутизации моделей приобретает все большее значение. Интеллектуальные системы анализируют входящие запросы и направляют их в соответствующую модель. Простые запросы обрабатываются экономически эффективными моделями машинного обучения (SLM), а сложные задачи — высокопроизводительными моделями машинного обучения (LLM). Такой гибридный подход оптимизирует баланс между качеством и стоимостью. Первые реализации показывают экономию средств до 75 процентов при той же или даже лучшей общей производительности. Сама логика маршрутизации может представлять собой небольшую модель машинного обучения, учитывающую сложность запроса, контекст и предпочтения пользователя.
Распространение платформ тонкой настройки как услуги ускоряет внедрение. Компании, не обладающие глубокими знаниями в области машинного обучения, могут создавать специализированные системы управления безопасностью процессов (SLM), которые включают в себя их собственные данные и специфику предметной области. Затраты времени сокращаются с месяцев до дней, а стоимость — с сотен тысяч долларов до тысяч. Такая доступность коренным образом демократизирует инновации в области ИИ и переносит создание ценности от поставщиков инфраструктуры к разработчикам приложений.
Новое измерение цифровой трансформации с помощью «управляемого ИИ» (искусственного интеллекта) — платформа и B2B-решение | Xpert Consulting

Новое измерение цифровой трансформации с помощью «управляемого ИИ» (искусственного интеллекта) – платформа и B2B-решение | Xpert Consulting - Изображение: Xpert.Digital
Здесь вы узнаете, как ваша компания может быстро, безопасно и без высоких барьеров для входа внедрить индивидуальные решения на основе искусственного интеллекта.
Управляемая платформа искусственного интеллекта — это комплексное и беззаботное решение для вашего бизнеса в сфере искусственного интеллекта. Вместо того чтобы возиться со сложными технологиями, дорогостоящей инфраструктурой и длительными процессами разработки, вы получаете готовое решение, адаптированное под ваши потребности, от специализированного партнера — зачастую всего за несколько дней.
Основные преимущества с первого взгляда:
⚡ Быстрая реализация: от идеи до готового к использованию приложения за считанные дни, а не месяцы. Мы предлагаем практические решения, которые создают немедленную добавленную стоимость.
🔒 Максимальная безопасность данных: Ваши конфиденциальные данные остаются с вами. Мы гарантируем безопасную и соответствующую законодательству обработку данных без их передачи третьим лицам.
💸 Отсутствие финансового риска: вы платите только за результат. Полностью исключаются высокие первоначальные инвестиции в оборудование, программное обеспечение или персонал.
🎯 Сосредоточьтесь на своем основном бизнесе: сконцентрируйтесь на том, что у вас получается лучше всего. Мы берем на себя всю техническую реализацию, эксплуатацию и обслуживание вашего решения на основе ИИ.
📈 Перспективность и масштабируемость: ваш ИИ растет вместе с вами. Мы обеспечиваем непрерывную оптимизацию и масштабируемость, а также гибко адаптируем модели к новым требованиям.
Более подробная информация здесь:
Как децентрализованный ИИ экономит компаниям миллиарды долларов на затратах
Скрытые издержки централизованных архитектур
Сосредоточение внимания исключительно на прямых затратах на вычисления недооценивает общую стоимость централизованных архитектур LLM. Зависимости от API создают структурные недостатки. Каждый запрос влечет за собой затраты, которые масштабируются в зависимости от использования. Для успешных приложений с миллионами пользователей плата за API становится доминирующим фактором затрат, снижая рентабельность. Компании оказываются в ловушке структуры затрат, которая растет пропорционально успеху, без соответствующей экономии за счет масштаба.
Нестабильность цен у поставщиков API представляет собой бизнес-риск. Повышение цен, ограничения квот или изменения условий обслуживания могут в одночасье подорвать прибыльность приложения. Недавно объявленные крупными поставщиками ограничения пропускной способности, которые вынуждают пользователей нормировать свои ресурсы, иллюстрируют уязвимость этой зависимости. Выделенные SLM-серверы полностью исключают этот риск.
Суверенитет данных и соблюдение нормативных требований приобретают все большее значение. GDPR в Европе, аналогичные правила во всем мире и растущие требования к локализации данных создают сложные правовые рамки. Передача конфиденциальных корпоративных данных внешним API, которые могут работать в иностранных юрисдикциях, сопряжена с регуляторными и правовыми рисками. В секторах здравоохранения, финансов и государственного управления часто действуют строгие требования, которые исключают или существенно ограничивают использование внешних API. Локальные системы управления безопасностью данных (SLM) коренным образом решают эти проблемы.
Проблемы, связанные с интеллектуальной собственностью, вполне реальны. Каждый запрос, отправленный поставщику API, потенциально раскрывает конфиденциальную информацию. Бизнес-логика, разработки продуктов, информация о клиентах — всё это теоретически может быть извлечено и использовано поставщиком. Договорные положения обеспечивают лишь ограниченную защиту от случайных утечек или действий злоумышленников. Единственное действительно безопасное решение — никогда не передавать данные за пределы организации.
Задержка и надежность снижаются из-за зависимости от сети. Каждый запрос к облачному API проходит через интернет-инфраструктуру, подверженную сетевым колебаниям, потере пакетов и переменному времени кругового пути. Для приложений реального времени, таких как разговорный ИИ или системы управления, эти задержки неприемлемы. Локальные SLM отвечают за миллисекунды вместо секунд, независимо от состояния сети. Пользовательский опыт значительно улучшается.
Стратегическая зависимость от нескольких крупных поставщиков концентрирует власть и создает системные риски. AWS, Microsoft Azure, Google Cloud и еще несколько компаний доминируют на рынке. Сбои в работе этих сервисов имеют каскадный эффект, затрагивающий тысячи зависимых приложений. Иллюзия избыточности исчезает, если учесть, что большинство альтернативных сервисов в конечном итоге полагаются на один и тот же ограниченный набор поставщиков. Истинная устойчивость требует диверсификации, в идеале включающей собственные мощности.
В связи с этим:

Граничные вычисления как стратегический поворотный момент
Сближение SLM и граничных вычислений создает революционную динамику. Развертывание граничных вычислений переносит вычисления туда, где возникают данные — к датчикам IoT, мобильным устройствам, промышленным контроллерам и транспортным средствам. Сокращение задержки является существенным: от секунд до миллисекунд, от обмена данными с облаком до локальной обработки. Для автономных систем, дополненной реальности, промышленной автоматизации и медицинских устройств это не только желательно, но и необходимо.
Экономия полосы пропускания существенна. Вместо непрерывных потоков данных в облако, где они обрабатываются и результаты отправляются обратно, обработка происходит локально. Передается только релевантная, агрегированная информация. В сценариях с тысячами периферийных устройств это сокращает сетевой трафик на порядки. Снижаются затраты на инфраструктуру, предотвращается перегрузка сети и повышается надежность.
Конфиденциальность защищена по своей сути. Данные больше не покидают устройство. Видеопотоки с камер, аудиозаписи, биометрическая информация, данные о местоположении — все это может обрабатываться локально, без обращения к центральным серверам. Это решает основные проблемы конфиденциальности, возникающие при использовании облачных решений на основе ИИ. Для потребительских приложений это становится отличительной чертой; для регулируемых отраслей — требованием.
Энергоэффективность улучшается на нескольких уровнях. Специализированные чипы для обработки ИИ на периферии сети, оптимизированные для вывода результатов небольших моделей, потребляют лишь малую часть энергии по сравнению с графическими процессорами центров обработки данных. Исключение передачи данных экономит энергию в сетевой инфраструктуре. Для устройств с батарейным питанием это становится ключевой функцией. Смартфоны, носимые устройства, дроны и датчики IoT могут выполнять функции ИИ без существенного влияния на время работы батареи.
Возможность работы в автономном режиме обеспечивает надежность. Edge AI также работает без подключения к интернету. Функциональность сохраняется в удаленных регионах, объектах критической инфраструктуры или в условиях стихийных бедствий. Эта независимость от доступности сети имеет важное значение для многих приложений. Автономный автомобиль не может полагаться на облачное подключение, а медицинское устройство не должно выходить из строя из-за нестабильного Wi-Fi.
Модели учета затрат смещаются от операционных к капитальным. Вместо постоянных затрат на облачные сервисы, происходит единовременное инвестирование в периферийное оборудование. Это становится экономически привлекательным для долгосрочных приложений с большим объемом данных. Предсказуемые затраты улучшают планирование бюджета и снижают финансовые риски. Компании восстанавливают контроль над расходами на инфраструктуру искусственного интеллекта.
Примеры демонстрируют потенциал. NVIDIA ChatRTX позволяет выполнять локальный вывод LLM на потребительских графических процессорах. Apple интегрирует встроенный ИИ в iPhone и iPad, при этом более компактные модели работают непосредственно на устройстве. Qualcomm разрабатывает NPU для смартфонов специально для периферийного ИИ. Google Coral и аналогичные платформы ориентированы на приложения для Интернета вещей и промышленности. Динамика рынка демонстрирует явную тенденцию к децентрализации.
Гетерогенные архитектуры ИИ как модель будущего
Будущее за абсолютной децентрализацией, а за интеллектуальными гибридными архитектурами. Гетерогенные системы сочетают в себе периферийные SLM-модули для рутинных задач, чувствительных к задержкам, с облачными LLM-модулями для сложных задач логического вывода. Такая взаимодополняемость максимизирует эффективность, сохраняя при этом гибкость и возможности.
Архитектура системы состоит из нескольких уровней. На периферийном уровне высокооптимизированные SLM-модели обеспечивают мгновенный отклик. Ожидается, что они будут обрабатывать от 60 до 80 процентов запросов автономно. Для неоднозначных или сложных запросов, которые не соответствуют локальным пороговым значениям достоверности, происходит эскалация на уровень туманных вычислений — региональные серверы со средними по мощности моделями. Только действительно сложные случаи достигают центральной облачной инфраструктуры с крупными универсальными моделями.
Маршрутизация на основе моделей становится критически важным компонентом. Маршрутизаторы, использующие машинное обучение, анализируют характеристики запроса: длину текста, показатели сложности, сигналы предметной области и историю пользователя. На основе этих характеристик запрос назначается соответствующей модели. Современные маршрутизаторы достигают точности оценки сложности более 95%. Они постоянно оптимизируются на основе фактического соотношения производительности и качества.
Механизмы перекрестного внимания в современных системах маршрутизации явно моделируют взаимодействие запросов и моделей. Это позволяет принимать взвешенные решения: достаточно ли Mistral-7B, или требуется GPT-4? Справится ли с этим Phi-3, или необходим Claude? Тонкий характер этих решений, применяемых к миллионам запросов, обеспечивает существенную экономию средств при сохранении или повышении удовлетворенности пользователей.
Характеристика рабочей нагрузки имеет фундаментальное значение. Агентные системы искусственного интеллекта состоят из оркестровки, рассуждений, вызовов инструментов, операций с памятью и генерации выходных данных. Не все компоненты требуют одинаковой вычислительной мощности. Оркестровка и вызовы инструментов часто основаны на правилах или требуют минимального интеллекта — идеально для SLM. Рассуждения могут быть гибридными: простой вывод на SLM, сложные многошаговые рассуждения на LLM. Генерация выходных данных для шаблонов использует SLM, генерация креативного текста — LLM.
Оптимизация общей стоимости владения (TCO) учитывает неоднородность оборудования. Для критически важных задач LLM используются высокопроизводительные графические процессоры H100, для моделей среднего уровня — A100 или L40S, а для SLM — экономичные чипы T4 или оптимизированные для вывода данных. Такая детализация позволяет точно сопоставлять требования к рабочей нагрузке с возможностями оборудования. Первоначальные исследования показывают снижение TCO на 40–60 процентов по сравнению с однородными высокопроизводительными развертываниями.
Для оркестровки требуются сложные программные стеки. Системы управления кластерами на основе Kubernetes, дополненные планировщиками, специально разработанными для ИИ и учитывающими характеристики моделей, имеют решающее значение. Балансировка нагрузки учитывает не только количество запросов в секунду, но и длину токенов, объем памяти, занимаемый моделью, и целевые показатели задержки. Автомасштабирование реагирует на изменения спроса, выделяя дополнительную мощность или уменьшая ее в периоды низкой загрузки.
Устойчивое развитие и энергоэффективность
Экологическое воздействие инфраструктуры искусственного интеллекта становится центральной проблемой. Обучение одной крупной языковой модели может потреблять столько же энергии, сколько небольшой город за год. К 2028 году на центры обработки данных, работающие с задачами ИИ, может приходиться от 20 до 27 процентов мирового потребления энергии. По прогнозам, к 2030 году центрам обработки данных, занимающимся ИИ, может потребоваться 8 гигаватт для отдельных циклов обучения. Углеродный след будет сопоставим с углеродным следом авиационной промышленности.
Энергоемкость крупных моделей растет непропорционально. Потребление энергии графическими процессорами за три года удвоилось — с 400 до более чем 1000 ватт. Системы NVIDIA GB300 NVL72, несмотря на инновационную технологию сглаживания энергопотребления, которая снижает пиковую нагрузку на 30 процентов, потребляют огромное количество энергии. Инфраструктура охлаждения добавляет еще 30–40 процентов к энергопотреблению. Общие выбросы CO2 от инфраструктуры ИИ могут увеличиться на 220 миллионов тонн к 2030 году, даже при оптимистичных предположениях о декарбонизации энергосистемы.
Малые языковые модели (SLM) обеспечивают существенное повышение эффективности. Для обучения требуется от 30 до 40 процентов вычислительной мощности сопоставимых LLM. Обучение BERT стоит приблизительно 10 000 евро, по сравнению с сотнями миллионов евро для моделей класса GPT-4. Энергопотребление при выводе пропорционально ниже. Запрос SLM может потреблять в 100–1000 раз меньше энергии, чем запрос LLM. При обработке миллионов запросов это приводит к огромной экономии.
Периферийные вычисления усиливают эти преимущества. Локальная обработка исключает энергопотребление при передаче данных по сетям и магистральной инфраструктуре. Специализированные чипы для ИИ на периферии сети достигают показателей энергоэффективности на порядки выше, чем графические процессоры в центрах обработки данных. Смартфоны и устройства IoT с нейронными процессорами мощностью в милливатт вместо сотен ватт серверов иллюстрируют разницу в масштабе.
Использование возобновляемых источников энергии становится приоритетом. Google стремится к 100-процентному использованию безуглеродной энергии к 2030 году, а Microsoft — к достижению углеродной нейтральности. Однако огромные масштабы спроса на энергию создают проблемы. Даже при использовании возобновляемых источников остаются вопросы пропускной способности сети, хранения энергии и нестабильности. Системы управления энергопотреблением снижают абсолютный спрос, делая переход к экологически чистому искусственному интеллекту более осуществимым.
Вычисления с учетом выбросов углерода оптимизируют планирование рабочих нагрузок на основе углеродоемкости энергосети. Обучение начинается, когда доля возобновляемой энергии в сети достигает максимума. Запросы на вывод направляются в регионы с более чистой энергией. Такая временная и географическая гибкость в сочетании с эффективностью SLM может сократить выбросы CO2 на 50–70 процентов.
Нормативно-правовая база становится все более жесткой. Закон ЕС об искусственном интеллекте включает обязательную оценку воздействия на окружающую среду для определенных систем ИИ. Отчетность по выбросам углерода становится стандартом. Компании с неэффективной, энергоемкой инфраструктурой рискуют столкнуться с проблемами соблюдения нормативных требований и ущербом для репутации. Внедрение систем управления безопасностью процессов (SLM) и граничных вычислений превращается из желательного дополнения в необходимость.
Демократизация против концентрации
В прошлом развитие событий привело к концентрации власти в сфере искусственного интеллекта в руках нескольких ключевых игроков. «Великолепная семерка» — Microsoft, Google, Meta, Amazon, Apple, NVIDIA и Tesla — доминирует. Эти гиганты контролируют инфраструктуру, модели и, все чаще, всю цепочку создания стоимости. Их совокупная рыночная капитализация превышает 15 триллионов долларов. На их долю приходится почти 35 процентов рыночной капитализации S&P 500, что представляет собой беспрецедентный исторический риск концентрации.
Такая концентрация имеет системные последствия. Несколько компаний устанавливают стандарты, определяют API и контролируют доступ. Более мелкие игроки и развивающиеся страны становятся зависимыми. Цифровой суверенитет государств оказывается под угрозой. Европа, Азия и Латинская Америка реагируют на это, разрабатывая национальные стратегии в области ИИ, но доминирование американских гипермасштабных компаний остается подавляющим.
Малые языковые модели (SLM) и децентрализация меняют эту динамику. Открытые SLM, такие как Phi-3, Gemma, Mistral и Llama, демократизируют доступ к передовым технологиям. Университеты, стартапы и средние предприятия могут разрабатывать конкурентоспособные приложения без ресурсов крупных компаний. Барьер для инноваций значительно снижается. Небольшая команда может создать специализированную SLM, которая превзойдет Google или Microsoft в своей нише.
Экономическая целесообразность смещается в пользу более мелких игроков. В то время как разработка программ LLM требует бюджетов в сотни миллионов долларов, программы SLM осуществимы при пяти- и шестизначных суммах. Демократизация облачных технологий обеспечивает доступ к инфраструктуре обучения по запросу. Услуги тонкой настройки абстрагируют от сложности. Барьер для входа в инновации в области ИИ снижается с непомерно высокого до приемлемого.
Суверенитет данных становится реальностью. Компании и правительства могут размещать модели, которые никогда не попадают на внешние серверы. Конфиденциальные данные остаются под их собственным контролем. Соблюдение GDPR упрощается. Закон ЕС об искусственном интеллекте, который устанавливает строгие требования к прозрачности и подотчетности, становится более управляемым благодаря использованию собственных моделей вместо «черных ящиков» API.
Разнообразие инноваций растет. Вместо монокультуры моделей, подобных GPT, появляются тысячи специализированных SLM для конкретных областей, языков и задач. Это разнообразие устойчиво к систематическим ошибкам, усиливает конкуренцию и ускоряет прогресс. Инновационный ландшафт становится полицентричным, а не иерархическим.
Риски концентрации становятся очевидными. Зависимость от нескольких поставщиков создает единые точки отказа. Сбои в работе AWS или Azure парализуют глобальные сервисы. Политические решения гипермасштабируемых компаний, такие как ограничения использования или региональные блокировки, имеют каскадный эффект. Децентрализация посредством SLM принципиально снижает эти системные риски.
Стратегическая перестройка
Для компаний этот анализ подразумевает фундаментальные стратегические корректировки. Приоритеты инвестиций смещаются от централизованной облачной инфраструктуры к гетерогенным распределенным архитектурам. Вместо максимальной зависимости от API гипермасштабируемых компаний цель состоит в обеспечении автономности за счет собственных систем управления безопасностью. Развитие навыков сосредоточено на тонкой настройке моделей, развертывании на периферии сети и гибридной оркестрации.
Выбор между разработкой и покупкой решений меняется. Если раньше приобретение доступа к API считалось рациональным решением, то разработка собственных специализированных систем управления безопасностью труда становится все более привлекательной. Общая стоимость владения за три-пять лет явно говорит в пользу внутренних моделей. Стратегический контроль, безопасность данных и адаптивность добавляют дополнительные качественные преимущества.
Для инвесторов такое неэффективное распределение ресурсов сигнализирует о необходимости проявлять осторожность в отношении инвестиций исключительно в инфраструктуру. REIT-компании, специализирующиеся на центрах обработки данных, производители графических процессоров и гипермасштабные компании могут столкнуться с избытком мощностей и снижением загрузки, если спрос не оправдает прогнозов. Происходит миграция стоимости в сторону поставщиков технологий SLM, чипов для периферийного ИИ, программного обеспечения для оркестрации и специализированных приложений ИИ.
Геополитический аспект имеет большое значение. Страны, которые ставят во главу угла национальный суверенитет в области ИИ, выигрывают от перехода к модели многополярного управления. Китай инвестирует 138 миллиардов долларов в отечественные технологии, а Европа — 200 миллиардов долларов в InvestAI. Эти инвестиции будут более эффективными, когда решающим фактором перестанет быть абсолютный масштаб, а станут более важными интеллектуальные, эффективные и специализированные решения. Многополярный мир ИИ становится реальностью.
Параллельно развивается и нормативно-правовая база. Защита данных, алгоритмическая подотчетность, экологические стандарты — все это способствует созданию децентрализованных, прозрачных и эффективных систем. Компании, которые внедряют SLM и граничные вычисления на ранних этапах, имеют благоприятные условия для соблюдения будущих нормативных требований.
Ситуация с талантами меняется. Если раньше ресурсы для исследований в области магистратуры по праву (LLM) были доступны только элитным университетам и ведущим технологическим компаниям, то теперь практически любая организация может разрабатывать программы управления знаниями (SLM). Дефицит квалифицированных кадров, который мешает 87% организаций нанимать специалистов по искусственному интеллекту, компенсируется снижением сложности и улучшением инструментов. Повышение производительности благодаря разработке с использованием ИИ усиливает этот эффект.
Способ измерения рентабельности инвестиций в ИИ меняется. Вместо того чтобы фокусироваться на вычислительной мощности, ключевым показателем становится эффективность выполнения задач. Предприятия сообщают о средней рентабельности инвестиций в ИИ на уровне 5,9%, что значительно ниже ожиданий. Причина часто кроется в использовании громоздких и дорогостоящих решений для простых задач. Переход к оптимизированным для конкретных задач модулям SLM может значительно повысить этот показатель рентабельности.
Анализ показывает, что отрасль находится на переломном этапе. Неправильные инвестиции в размере 57 миллиардов долларов — это не просто переоценка спроса. Это фундаментальный стратегический просчет в отношении архитектуры искусственного интеллекта. Будущее принадлежит не централизованным гигантам, а децентрализованным, специализированным и эффективным системам. Небольшие языковые модели не уступают большим — они превосходят их в подавляющем большинстве реальных приложений. Экономические, технические, экологические и стратегические аргументы сходятся в одном: революция в области ИИ будет децентрализованной.
Смещение баланса сил от поставщиков к операторам, от крупных компаний к разработчикам приложений, от централизации к распределению знаменует собой новый этап в эволюции ИИ. Те, кто осознает и примет этот переход на раннем этапе, окажутся в выигрыше. Те, кто цепляется за старую логику, рискуют тем, что их дорогостоящая инфраструктура превратится в бесполезные активы, вытесненные более гибкими и эффективными альтернативами. 57 миллиардов долларов не просто потрачены впустую — это начало конца для парадигмы, которая уже устарела.
Ваш глобальный партнер по маркетингу и развитию бизнеса
☑️ Язык ведения нашего бизнеса — английский или немецкий
☑️ НОВИНКА: Переписка на вашем родном языке!

Konrad Wolfenstein
Я и моя команда будем рады быть вашими личными консультантами.
Вы можете связаться со мной, заполнив контактную форму здесь wolfenstein@xpert.digital:или просто позвонив по номеру +49 7348 4088 965. Мой адрес электронной почты
Я с нетерпением жду начала нашего совместного проекта.
☑️ Поддержка малых и средних предприятий в области стратегии, консалтинга, планирования и реализации проектов
☑️ Разработка или корректировка цифровой стратегии и цифровизации
☑️ Расширение и оптимизация международных процессов продаж
☑️ Глобальные и цифровые торговые платформы B2B
☑️ Развитие бизнеса / Маркетинг / PR / Выставки от компании Pioneer
🎯🎯🎯 Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в одном комплексном пакете услуг | Развитие бизнеса, НИОКР, XR, PR и оптимизация цифровой видимости

Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в рамках комплексного пакета услуг | НИОКР, XR, PR и оптимизация цифровой видимости - Изображение: Xpert.Digital
Компания Xpert.Digital обладает глубокими знаниями в различных отраслях. Это позволяет нам разрабатывать индивидуальные стратегии, точно соответствующие требованиям и задачам вашего конкретного сегмента рынка. Благодаря постоянному анализу рыночных тенденций и мониторингу отраслевых разработок мы можем действовать на опережение и предлагать инновационные решения. Сочетание опыта и экспертных знаний создает добавленную стоимость и обеспечивает нашим клиентам решающее конкурентное преимущество.
Более подробная информация здесь: