
Искусственный интеллект и SEO с использованием BERT – двунаправленных кодировщиков на основе трансформеров – модели в области обработки естественного языка (NLP)

Доступно на 27 языках 📢
Предпочитаю Xper.Digital в GoogleⓘОпубликовано: 4 октября 2024 г. / Обновлено: 4 октября 2024 г. – Автор: Konrad Wolfenstein

Искусственный интеллект и SEO с использованием BERT – двунаправленных кодировщиков на основе трансформеров – модели в области обработки естественного языка (NLP) – Изображение: Xpert.Digital
🚀💬 Разработано Google: BERT и его значение для обработки естественного языка — почему двустороннее понимание текста имеет решающее значение
🔍🗣️ BERT, сокращение от Bidirectional Encoder Representations from Transformers (двунаправленные представления кодировщика из трансформеров), — это важная модель в области обработки естественного языка (NLP), разработанная Google. Она произвела революцию в том, как машины понимают язык. В отличие от предыдущих моделей, которые анализировали текст последовательно слева направо или наоборот, BERT обеспечивает двунаправленную обработку. Это означает, что она улавливает контекст слова как из предшествующей, так и из последующей последовательности текста. Эта возможность значительно улучшает понимание сложных лингвистических связей.
🔍 Архитектура BERT
В последние годы одним из наиболее значительных достижений в области обработки естественного языка (NLP) стало внедрение модели Transformer, описанной в статье 2017 года «Внимание — это все, что вам нужно» (Википедия). Эта модель коренным образом изменила область, отказавшись от ранее использовавшихся структур, таких как машинный перевод. Вместо этого она опирается исключительно на механизмы внимания. С тех пор модель Transformer легла в основу многих моделей, представляющих собой передовые достижения в различных областях, включая генерацию речи, перевод и многое другое.
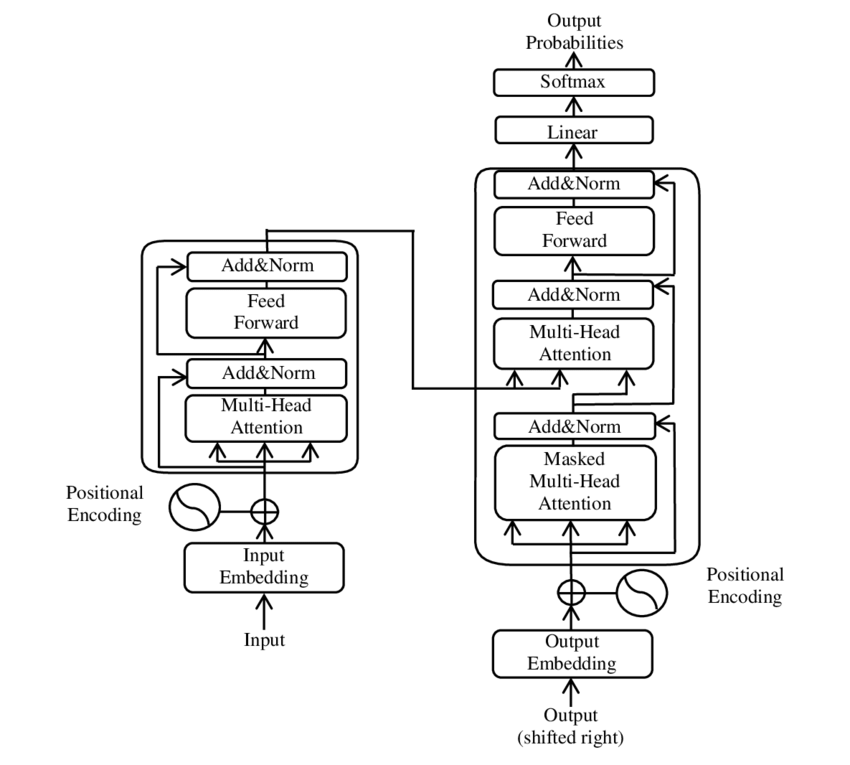
Иллюстрация основных компонентов модели Трансформатора – Изображение: Google
BERT основан на этой трансформерной архитектуре. Эта архитектура использует так называемые механизмы самовнимания для анализа связей между словами в предложении. Каждому слову уделяется внимание в контексте всего предложения, что приводит к более точному пониманию синтаксических и семантических связей.
Авторами статьи «Внимание — это всё, что вам нужно» являются:
- Ашиш Васвани (Google Brain)
- Ноам Шазир (Google Brain)
- Ники Пармар (Google Research)
- Якоб Ушкорейт (Google Research)
- Лайон Джонс (Google Research)
- Эйдан Н. Гомес (Университет Торонто, часть работы выполнена в Google Brain)
- Лукаш Кайзер (Google Brain)
- Илья Полосухин (независимый исследователь, ранее работал в Google Research)
Эти авторы внесли значительный вклад в разработку модели трансформатора, представленной в данной статье.
🔄 Двунаправленная обработка
Ключевой особенностью BERT является его способность обрабатывать текст в обоих направлениях. В то время как традиционные модели, такие как рекуррентные нейронные сети (RNN) или сети с долговременной кратковременной памятью (LSTM), обрабатывают текст только в одном направлении, BERT анализирует контекст слова в обоих направлениях. Это позволяет модели лучше улавливать тонкие нюансы значения и, следовательно, делать более точные прогнозы.
🕵️♂️ Моделирование речи в маскировке
Еще одним инновационным аспектом BERT является метод маскированной языковой модели (MLM). В этом методе случайно выбранные слова в предложении маскируются, и модель обучается предсказывать эти слова на основе окружающего контекста. Этот метод заставляет BERT глубоко понимать контекст и значение каждого слова в предложении.
🚀 Обучение и адаптация BERT
Модель BERT проходит двухэтапный процесс обучения: предварительное обучение и тонкую настройку.
📚 Предварительное обучение
На этапе предварительного обучения BERT тренируется на больших объемах текста для изучения общих языковых закономерностей. Это включает статьи из Википедии и другие обширные текстовые корпуса. На этом этапе модель изучает основные лингвистические структуры и контексты.
🔧 Тонкая настройка
После предварительного обучения BERT адаптируется для решения конкретных задач обработки естественного языка, таких как классификация текста или анализ настроений. Модель обучается на меньших по размеру, соответствующих задачам наборах данных, чтобы оптимизировать ее производительность для конкретных приложений.
🌍 Области применения BERT
BERT доказал свою исключительную полезность во многих областях обработки естественного языка:
Оптимизация для поисковых систем
Google использует BERT для лучшего понимания поисковых запросов и отображения более релевантных результатов. Это значительно улучшает пользовательский опыт.
Классификация текста
BERT может классифицировать документы по темам или анализировать настроение в текстах.
Распознавание именованных сущностей (NER)
Данная модель идентифицирует и классифицирует именованные сущности в текстах, такие как имена людей, названия мест или организаций.
Системы вопросов и ответов
BERT используется для предоставления точных ответов на поставленные вопросы.
🧠 Значение BERT для будущего ИИ
BERT установил новые стандарты для моделей обработки естественного языка и проложил путь для дальнейших инноваций. Благодаря своей способности к двунаправленной обработке и глубокому пониманию языкового контекста, он значительно повысил эффективность и точность приложений искусственного интеллекта.
🔜 Будущие разработки
Дальнейшее развитие BERT и подобных моделей, как ожидается, будет направлено на создание еще более мощных систем. Они смогут обрабатывать более сложные языковые задачи и использоваться в самых разных новых областях применения. Интеграция таких моделей в повседневные технологии может коренным образом изменить наше взаимодействие с компьютерами.
🌟 Знаковый этап в развитии искусственного интеллекта
BERT — это важная веха в развитии искусственного интеллекта, совершившая революцию в способе обработки естественного языка машинами. Его двунаправленная архитектура позволяет глубже понимать лингвистические связи, что делает его незаменимым для широкого спектра приложений. По мере развития исследований модели, подобные BERT, будут продолжать играть центральную роль в совершенствовании систем ИИ и открытии новых возможностей для их использования.
📣 Похожие темы
- 📚 Введение в BERT: революционная модель обработки естественного языка
- 🔍 BERT и роль двунаправленности в НЛП
- 🧠 Модель Трансформера: Основа BERT
- 🚀 Маскированное языковое моделирование: ключ к успеху BERT
- 📈 Настройка BERT: от предварительного обучения до тонкой настройки
- 🌐 Области применения BERT в современных технологиях
- 🤖 Влияние BERT на будущее искусственного интеллекта
- 💡 Перспективы на будущее: дальнейшее развитие BERT
- 🏆 BERT как важный этап в развитии искусственного интеллекта
- 📰 Авторы статьи Transformer «Внимание — это все, что вам нужно»: создатели BERT
#️⃣ Хэштеги: #NLP #ИскусственныйИнтеллект #МоделированиеЯзыка #Трансформер #МашинноеОбучение
🎯🎯🎯 Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в одном комплексном пакете услуг | Развитие бизнеса, НИОКР, XR, PR и оптимизация цифровой видимости

Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в рамках комплексного пакета услуг | НИОКР, XR, PR и оптимизация цифровой видимости - Изображение: Xpert.Digital
Компания Xpert.Digital обладает глубокими знаниями в различных отраслях. Это позволяет нам разрабатывать индивидуальные стратегии, точно соответствующие требованиям и задачам вашего конкретного сегмента рынка. Благодаря постоянному анализу рыночных тенденций и мониторингу отраслевых разработок мы можем действовать на опережение и предлагать инновационные решения. Сочетание опыта и экспертных знаний создает добавленную стоимость и обеспечивает нашим клиентам решающее конкурентное преимущество.
Более подробная информация здесь:
BERT: Революционная 🌟 технология обработки естественного языка
🚀 BERT, сокращение от Bidirectional Encoder Representations from Transformers (двунаправленные кодировщики на основе трансформеров), — это продвинутая языковая модель, разработанная Google, которая с момента своего появления в 2018 году стала значительным прорывом в обработке естественного языка (NLP). Она основана на архитектуре трансформеров, которая произвела революцию в том, как машины понимают и обрабатывают текст. Но что именно делает BERT таким особенным и для чего он используется? Чтобы ответить на этот вопрос, нам нужно внимательнее рассмотреть технические основы BERT, принцип его работы и области применения.
📚 1. Основы обработки естественного языка
Для полного понимания значимости BERT полезно кратко рассмотреть основы обработки естественного языка (NLP). NLP занимается взаимодействием компьютеров и человеческого языка. Его цель — научить машины анализировать, понимать и реагировать на текстовые данные. До появления таких моделей, как BERT, обработка машинного языка часто сталкивалась со значительными трудностями, особенно из-за неоднозначности, зависимости от контекста и сложной структуры человеческого языка.
📈 2. Разработка моделей НЛП
До появления BERT большинство моделей обработки естественного языка были основаны на так называемых однонаправленных архитектурах. Это означало, что эти модели читали текст либо слева направо, либо справа налево, что позволяло им учитывать лишь ограниченный контекст при обработке слова в предложении. Это ограничение часто приводило к тому, что модели не могли в полной мере уловить семантический контекст предложения. Это затрудняло точную интерпретацию неоднозначных или контекстно-зависимых слов.
Еще одним важным достижением в исследованиях в области обработки естественного языка до появления BERT стала модель word2vec, которая позволяла компьютерам преобразовывать слова в векторы, отражающие семантическое сходство. Однако даже здесь контекст ограничивался непосредственным окружением слова. Позже были разработаны рекуррентные нейронные сети (RNN) и, в частности, модели с долговременной кратковременной памятью (LSTM), которые позволили лучше понимать текстовые последовательности, сохраняя информацию по нескольким словам. Однако эти модели также имели свои ограничения, особенно при работе с длинными текстами и одновременном понимании контекста в обоих направлениях.
🔄 3. Революция посредством архитектуры трансформаторов
Прорыв произошел с появлением архитектуры Transformer в 2017 году, которая лежит в основе BERT. Модели Transformer разработаны для обеспечения параллельной обработки текста с учетом контекста слова как из предшествующего, так и из последующего текста. Это достигается с помощью так называемых механизмов самовнимания, которые присваивают каждому слову в предложении весовое значение в зависимости от его важности по отношению к другим словам в предложении.
В отличие от предыдущих подходов, трансформерные модели являются не однонаправленными, а двунаправленными. Это означает, что они могут извлекать информацию как из левого, так и из правого контекста слова, чтобы создать более полное и точное представление слова и его значения.
🧠 4. BERT: Двунаправленная модель
BERT выводит производительность архитектуры Transformer на новый уровень. Модель разработана таким образом, чтобы улавливать контекст слова не только слева направо или справа налево, но и одновременно в обоих направлениях. Это позволяет BERT учитывать полный контекст слова в предложении, что приводит к значительному повышению точности в задачах обработки естественного языка.
Ключевой особенностью BERT является использование так называемой модели маскированного языка (MLM). Во время обучения BERT случайно выбранные слова в предложении заменяются маской, и модель обучается угадывать эти замаскированные слова на основе контекста. Этот метод позволяет BERT изучать более глубокие и точные взаимосвязи между словами в предложении.
Кроме того, BERT использует метод, называемый предсказанием следующего предложения (NSP), в котором модель учится предсказывать, следует ли одно предложение за другим. Это улучшает способность BERT понимать более длинные тексты и распознавать более сложные взаимосвязи между предложениями.
🌐 5. Практическое применение BERT
BERT оказался чрезвычайно полезным для решения самых разнообразных задач обработки естественного языка. Вот некоторые из наиболее важных областей его применения:
📊 а) Классификация текста
Одно из наиболее распространенных применений BERT — это классификация текста, где тексты делятся на предопределенные категории. Примеры включают анализ настроения (например, определение положительного или отрицательного содержания текста) или категоризацию отзывов клиентов. Благодаря глубокому пониманию контекста слов, BERT может давать более точные результаты, чем предыдущие модели.
❓ b) Системы вопросов и ответов
BERT также используется в системах ответов на вопросы, где модель извлекает ответы на заданные вопросы из текста. Эта возможность особенно важна в таких приложениях, как поисковые системы, чат-боты и виртуальные помощники. Благодаря своей двунаправленной архитектуре BERT может извлекать релевантную информацию из текста, даже если вопрос сформулирован косвенно.
🌍 c) Перевод текста
Хотя BERT сам по себе не предназначен для непосредственного использования в качестве модели перевода, его можно применять в сочетании с другими технологиями для улучшения машинного перевода. Благодаря лучшему пониманию семантических связей внутри предложения, BERT может помочь в создании более точных переводов, особенно в случае неоднозначных или сложных фраз.
🏷️ d) Распознавание именованных сущностей (NER)
Еще одна область применения — распознавание именованных сущностей (NER), которое включает в себя идентификацию конкретных сущностей, таких как имена, места или организации, в тексте. BERT оказался особенно эффективным в этой задаче, поскольку он полностью учитывает контекст предложения и, следовательно, может лучше распознавать сущности, даже если они имеют разное значение в разных контекстах.
✂️ e) Краткое содержание текста
Способность BERT понимать весь контекст текста также делает его мощным инструментом для автоматического составления кратких резюме. Его можно использовать для извлечения наиболее важной информации из длинного текста и создания краткого резюме.
🌟 6. Важность BERT для исследований и промышленности
Внедрение BERT ознаменовало начало новой эры в исследованиях в области обработки естественного языка. Это была одна из первых моделей, в полной мере использовавших возможности двунаправленной архитектуры трансформеров, задав стандарт для многих последующих моделей. Многочисленные компании и исследовательские институты интегрировали BERT в свои конвейеры обработки естественного языка для повышения производительности своих приложений.
Кроме того, BERT проложил путь для дальнейших инноваций в области языковых моделей. Например, впоследствии были разработаны такие модели, как GPT (Generative Pretrained Transformer) и T5 (Text-to-Text Transfer Transformer), которые основаны на схожих принципах, но предлагают конкретные улучшения для различных сценариев использования.
🚧 7. Проблемы и ограничения BERT
Несмотря на многочисленные преимущества, BERT также имеет некоторые проблемы и ограничения. Одной из самых больших проблем является высокая вычислительная сложность, необходимая для обучения и применения модели. Поскольку BERT — это очень большая модель с миллионами параметров, она требует мощного оборудования и значительных вычислительных ресурсов, особенно при обработке больших наборов данных.
Ещё одна проблема — потенциальная предвзятость, которая может присутствовать в обучающих данных. Поскольку BERT обучается на больших объёмах текстовых данных, он иногда отражает предрассудки и стереотипы, присутствующие в этих данных. Однако исследователи постоянно работают над выявлением и устранением этих проблем.
🔍 Незаменимый инструмент для современных приложений обработки речи
BERT значительно улучшил понимание машинами человеческого языка. Благодаря своей двунаправленной архитектуре и инновационным методам обучения он способен глубоко и точно улавливать контекст слов в предложении, что приводит к повышению точности во многих задачах обработки естественного языка. Будь то классификация текста, системы ответов на вопросы или распознавание сущностей, BERT зарекомендовал себя как незаменимый инструмент для современных приложений обработки естественного языка.
Исследования в области обработки естественного языка, несомненно, будут продолжать развиваться, и BERT заложил основу для многих будущих инноваций. Несмотря на существующие проблемы и ограничения, BERT впечатляюще демонстрирует, как далеко продвинулась технология за короткое время и какие захватывающие возможности еще откроются в будущем.
🌀 Трансформер: революция в обработке естественного языка
🌟 В последние годы одним из наиболее значительных достижений в области обработки естественного языка (NLP) стало внедрение модели Transformer, описанной в статье 2017 года «Attention Is All You Need». Эта модель коренным образом изменила область, отказавшись от ранее использовавшихся рекуррентных или сверточных структур для задач преобразования последовательностей, таких как машинный перевод. Вместо этого она опирается исключительно на механизмы внимания. С тех пор модель Transformer легла в основу многих моделей, представляющих собой передовые достижения в различных областях, включая генерацию речи, перевод и многое другое.
🔄 Трансформатор: Смена парадигмы
До появления трансформера большинство моделей для задач обработки последовательностей основывались на рекуррентных нейронных сетях (RNN) или сетях с долговременной кратковременной памятью (LSTM), которые по своей природе работают последовательно. Эти модели обрабатывают входные данные шаг за шагом, создавая скрытые состояния, которые распространяются вдоль последовательности. Хотя этот метод эффективен, он вычислительно затратен и сложен для распараллеливания, особенно для длинных последовательностей. Кроме того, RNN испытывают трудности с изучением долговременных зависимостей из-за проблемы исчезающего градиента.
Ключевое нововведение Transformer заключается в использовании механизмов самовнимания, которые позволяют модели оценивать важность различных слов в предложении относительно друг друга, независимо от их положения. Это позволяет модели более эффективно, чем RNN или LSTM, улавливать связи между словами, расположенными на значительном расстоянии друг от друга, и делать это параллельно, а не последовательно. Это не только повышает эффективность обучения, но и улучшает производительность в таких задачах, как машинный перевод.
🧩 Модель архитектуры
Трансформатор состоит из двух основных компонентов: кодировщика и декодера, каждый из которых имеет несколько слоев и в значительной степени опирается на многоголовочные механизмы внимания.
⚙️ Кодировщик
Кодировщик состоит из шести идентичных слоев, каждый из которых имеет два подуровня:
1. Многоголовочная система самовнимания
Этот механизм позволяет модели фокусироваться на разных частях входного предложения при обработке каждого слова. Вместо вычисления внимания в одном пространстве, многоголовочное внимание проецирует входные данные в несколько разных пространств, тем самым улавливая различные типы связей между словами.
2. Позиционно полностью связанные сети прямого распространения
После слоя внимания на каждой позиции независимо применяется полносвязная нейронная сеть прямого распространения. Это помогает модели обрабатывать каждое слово в контексте и использовать информацию, полученную от механизма внимания.
Для сохранения структуры входной последовательности модель также включает позиционные кодировки. Поскольку трансформер не обрабатывает слова последовательно, эти кодировки имеют решающее значение для предоставления модели информации о порядке слов в предложении. Позиционные кодировки добавляются к векторным представлениям слов, чтобы модель могла различать разные позиции в последовательности.
🔍 Декодер
Подобно кодировщику, декодер также состоит из шести слоев, каждый из которых имеет дополнительный механизм внимания, позволяющий модели фокусироваться на релевантных частях входной последовательности при генерации выходных данных. Декодер также использует метод маскирования, чтобы предотвратить рассмотрение будущих позиций, тем самым сохраняя авторегрессивный характер генерации последовательности.
🧠 Многоканальное внимание и скалярное внимание к продукту
В основе Transformer лежит механизм многоголовочного внимания, являющийся расширением более простого механизма внимания на основе скалярного произведения. Функцию внимания можно рассматривать как отображение между запросом и набором пар ключ-значение, где каждый ключ представляет собой слово в последовательности, а значение — соответствующую контекстную информацию.
Механизм многоголовочного внимания позволяет модели одновременно фокусироваться на разных частях последовательности. Проецируя входные данные в несколько подпространств, модель может улавливать более богатый набор взаимосвязей между словами. Это особенно полезно для таких задач, как машинный перевод, где понимание контекста слова требует учета множества различных факторов, таких как синтаксическая структура и семантическое значение.
Формула для скалярного произведения внимания выглядит следующим образом:
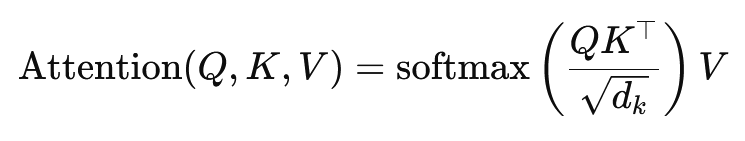
Здесь (Q) — матрица запросов, (K) — матрица ключей, а (V) — матрица значений. Член (sqrt{d_k}) — масштабный коэффициент, предотвращающий чрезмерное увеличение скалярных произведений, что привело бы к очень малым градиентам и замедлению обучения. Функция softmax применяется для обеспечения того, чтобы сумма весов внимания равнялась единице.
🚀 Преимущества трансформатора
Трансформер обладает рядом важных преимуществ перед традиционными моделями, такими как рекуррентные нейронные сети (RNN) и сети LSTM:
1. Параллелизация
Поскольку трансформер обрабатывает все токены последовательности одновременно, его можно сильно распараллелить, и поэтому он обучается намного быстрее, чем рекуррентные нейронные сети (RNN) или сети LSTM, особенно при работе с большими наборами данных.
2. Долгосрочные зависимости
Механизм самовнимания позволяет модели более эффективно, чем рекуррентные нейронные сети (RNN), улавливать взаимосвязи между отдаленными словами, что обусловлено последовательностью вычислений.
3. Масштабируемость
Трансформатор легко масштабируется до очень больших наборов данных и более длинных последовательностей, не страдая от узких мест в производительности, характерных для рекуррентных нейронных сетей.
🌍 Применение и эффекты
С момента своего появления трансформер стал основой для широкого спектра моделей обработки естественного языка (NLP). Одним из наиболее ярких примеров является BERT (Bidirectional Encoder Representations from Transformers), который использует модифицированную архитектуру трансформера для достижения передовых результатов во многих задачах NLP, включая ответы на вопросы и классификацию текста.
Еще одним важным достижением является GPT (Generative Pretrained Transformer), который использует версию трансформера с ограниченными возможностями декодера для генерации текста. Модели GPT, включая GPT-3, теперь используются в многочисленных приложениях, от создания контента до автозавершения кода.
🔍 Мощная и гибкая модель
Трансформер коренным образом изменил наш подход к задачам обработки естественного языка. Он предлагает мощную и гибкую модель, применимую к широкому кругу проблем. Его способность обрабатывать долгосрочные зависимости и эффективность обучения сделали его предпочтительным архитектурным подходом для многих современных моделей. По мере развития исследований мы, вероятно, увидим дальнейшие улучшения и адаптации Трансформера, особенно в таких областях, как обработка изображений и речи, где механизмы внимания демонстрируют многообещающие результаты.
Мы здесь для вас — Консультации — Планирование — Внедрение — Управление проектами
☑️ Эксперт отрасли, автор собственного отраслевого портала Xpert.Digital, содержащего более 2500 специализированных статей

Konrad Wolfenstein
Я с удовольствием стану вашим личным консультантом.
Вы можете связаться со мной, заполнив форму обратной связи ниже, или просто позвонить мне по номеру +49 7348 4088 965 .
Я с нетерпением жду начала нашего совместного проекта.
Напишите мне

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital — это центр для предприятий, специализирующийся на цифровизации, машиностроении, логистике/внутрипроизводственной логистике и фотовольтаике.
С помощью нашего комплексного решения для развития бизнеса мы поддерживаем известные компании на всех этапах, от привлечения новых клиентов до послепродажного обслуживания.
Анализ рынка, маркетинговый маркетинг, автоматизация маркетинга, разработка контента, PR, почтовые рассылки, персонализированные кампании в социальных сетях и работа с потенциальными клиентами — все это входит в число наших цифровых инструментов.
Более подробную информацию можно найти по ссылкам: www.xpert.digital - www.xpert.solar - www.xpert.plus
Поддерживать связь


















