
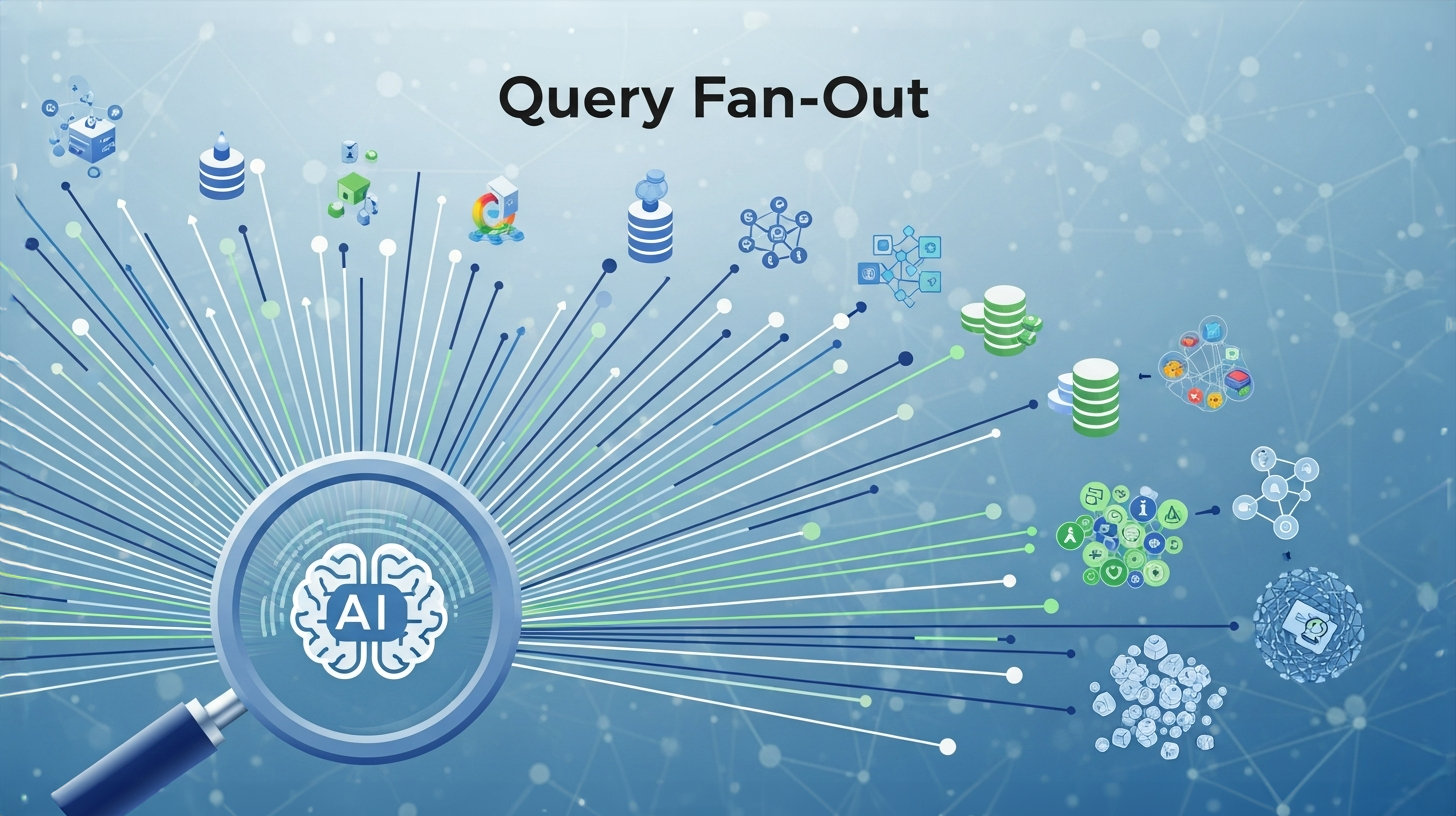
Расширение поискового запроса: подробное объяснение этой революционной техники поиска с использованием искусственного интеллекта – Изображение: Xpert.Digital
Патент Google, который меняет всё: что «тематический поиск» говорит о будущем SEO
Новое чудо-оружие Google: почему Query Fan-Out переворачивает вашу SEO-стратегию с ног на голову
Эпоха простых поисков по ключевым словам и десяти синих ссылок подходит к концу. В основе этого развития лежит революционная техника, называемая «рассеиванием запросов», которая незаметно меняет принципы работы поисковых систем, таких как Google. Вместо того чтобы рассматривать поисковый запрос как единую, изолированную задачу, этот подход систематически разветвляет пользовательский запрос на целую сеть связанных подзапросов. Цель состоит в том, чтобы понять не только то, что вы явно спрашиваете, но и то, что вы неявно хотите узнать, чтобы предвидеть последующие вопросы и синтезировать исчерпывающий ответ непосредственно в интерфейсе поиска.
Этот парадигматический сдвиг, обусловленный моделями искусственного интеллекта, такими как Google Gemini, — это не просто технологическая инновация, а переопределение правил игры в области поисковой оптимизации (SEO), создания контента и всего процесса сбора цифровой информации. Для создателей контента и маркетологов это означает смещение акцента с отдельных ключевых слов на комплексные тематические кластеры и создание контента, который одновременно отвечает различным намерениям пользователей. В этой всеобъемлющей статье мы подробно рассмотрим мир веерного поиска. Мы объясним его техническую функциональность, принципиальное отличие от традиционного поиска, его решающую роль в контент-стратегиях и то, как вы можете оптимизировать свой контент уже сегодня для будущего поиска.
Что такое Query Fan-Out?
Метод «разветвления запроса» (query fan-out) — это сложный способ поиска информации, при котором один поисковый запрос пользователя систематически разбивается на несколько связанных подзапросов. Этот метод особенно часто используется в современных поисковых системах на основе искусственного интеллекта, таких как Google AI Mode, ChatGPT и другие крупные языковые модели. Термин «разветвление запроса» (fan-out) первоначально пришел из электроники и информатики и описывает распределение потока сигнала или данных от одного источника к нескольким адресатам.
В контексте поисковой оптимизации и искусственного интеллекта, «расширение запроса» означает, что система не только ищет точную формулировку запроса пользователя, но и семантически анализирует этот запрос, разбивает его на компоненты и одновременно генерирует несколько тематически связанных поисковых запросов. Затем эти подзапросы выполняются одновременно в разных источниках данных, что позволяет получить более полный и контекстно-ориентированный ответ.
Метод основан на понимании того, что пользователи часто не формулируют точно то, что они на самом деле ищут, или что их запрос содержит несколько неявных информационных потребностей. Метод Query Fan-Out пытается распознать эти скрытые намерения и заблаговременно решить их до того, как пользователю потребуется задать дополнительные вопросы.
Как технически работает механизм Fan-Out запроса?
Техническая реализация алгоритма Query Fan-Out осуществляется в несколько последовательных этапов, требующих сложного взаимодействия различных компонентов искусственного интеллекта.
Процесс начинается с анализа исходного поискового запроса. Большая языковая модель, такая как Gemini, сначала интерпретирует ввод пользователя и определяет основное намерение и семантический контекст. Это включает в себя выявление лингвистических особенностей, сущностей и скрытого намерения пользователя. Этот этап называется декомпозицией запроса и составляет основу для всех последующих шагов.
Затем происходит фактическое расширение запроса. Система генерирует от пяти до пятнадцати связанных подзапросов, охватывающих различные аспекты исходной информационной потребности. Эти синтетические запросы создаются в соответствии со структурированными шаблонами, основанными на разнообразии намерений, лексических вариациях и переформулировках на основе сущностей. Например, если пользователь ищет «лучшие Bluetooth-наушники», система может одновременно сгенерировать такие запросы, как «лучшие накладные Bluetooth-наушники», «самые удобные Bluetooth-наушники до 200 евро», «Bluetooth-наушники для спорта» и «шумоподавление против обычных Bluetooth-наушников».
Сгенерированные подзапросы затем выполняются параллельно в различных источниках данных. Это включает в себя веб-индекс в реальном времени, граф знаний, специализированные базы данных, такие как Google Shopping Graph, и другие вертикальные поисковые индексы. Эта параллельная обработка является ключевым элементом архитектуры с разветвленной обработкой данных и позволяет системе собирать обширную информационную базу за очень короткое время.
На следующем этапе собранные результаты анализируются и оцениваются. Система использует сигналы ранжирования и качества Google для оценки релевантности и достоверности каждого найденного фрагмента информации. Это включает в себя не только рассмотрение целых веб-страниц, но и изучение отдельных текстовых фрагментов на предмет их пригодности для ответа на конкретные подвопросы.
Наконец, вся собранная информация синтезируется в связный ответ. Генеративная языковая модель объединяет наиболее релевантную информацию из различных источников и создает исчерпывающий, контекстно-обогащенный ответ на исходный запрос. Этот ответ учитывает как явные, так и неявные аспекты намерений пользователя и часто предоставляет дополнительную информацию, которая может понадобиться пользователю в дальнейшем.
Какие типы вариантов запросов генерируются?
Метод расширения запросов систематически генерирует различные типы подзапросов для охвата разных аспектов необходимой информации.
Семантические расширения образуют первую категорию и включают синонимы, а также альтернативные формулировки исходного запроса. Если кто-то ищет «автомобиль», система также рассмотрит такие варианты, как «машина», «легковой автомобиль» или «транспортное средство».
Варианты запросов, основанные на намерениях пользователя, ориентированы на различные намерения. К ним относятся сравнительные запросы, которые сравнивают различные варианты; исследовательские запросы, которые углубляют базовое понимание темы; и запросы, ориентированные на принятие решений, которые призваны помочь в принятии конкретных решений о покупке. Оригинальный запрос, такой как «Python Threading», может генерировать как запросы-уроки по программированию, так и биологические запросы о поведении змей.
Еще одна важная категория — это диалоговые и последующие запросы. Система предугадывает, какие последующие вопросы, скорее всего, задаст пользователь, и заблаговременно интегрирует ответы в первоначальный ответ. Это создает поиск, похожий на диалог, где пользователю не нужно отправлять несколько последовательных запросов.
Переформулировки запросов на основе сущностей фокусируются на конкретных брендах, продуктах, местах или людях, которые могут быть релевантны в контексте исходного запроса. Если кто-то ищет «программное обеспечение для управления проектами», в подзапрос будут включены конкретные сущности, такие как «Asana», «Trello» или «Monday.com».
Региональные и контекстуальные различия учитывают географические особенности и временные аспекты. Например, запрос «рестораны рядом со мной» в 11:45 утра в будний день будет отдавать приоритет вариантам для обеда, а тот же запрос вечером — вариантам для ужина.
Чем отличается алгоритм поиска с расширением поискового запроса от традиционного поиска?
Разница между алгоритмом расширения поисковой выдачи и традиционной поисковой оптимизацией является принципиальной и меняет подход к созданию и оптимизации контента.
Традиционные поисковые системы работают по принципу прямого сопоставления ключевых слов. Поисковый запрос рассматривается как единый, изолированный запрос, и система ищет веб-страницы, содержащие эти точные термины или их близкие вариации. Результаты представляются в виде ранжированного списка ссылок, по которым пользователь должен перейти одну за другой, чтобы найти нужную информацию.
В свою очередь, метод Query Fan-Out расширяет один поисковый запрос в сеть связанных поисковых запросов. Вместо поиска точных совпадений система анализирует семантическое значение и контекст запроса. Она пытается понять скрытое намерение и одновременно рассматривает различные возможные интерпретации.
Способ представления результатов также принципиально отличается. В то время как традиционный поиск выдает список синих ссылок, система расширения запроса представляет собой синтезированный, диалоговый ответ непосредственно в интерфейсе поиска. Этот ответ объединяет информацию из нескольких источников и структурирован таким образом, чтобы всесторонне удовлетворить информационные потребности пользователя, не требуя от него посещения нескольких веб-сайтов.
Еще одно ключевое различие заключается в обработке намерений. Традиционный поиск фокусируется на явных ключевых словах и может лишь в ограниченной степени учитывать неявные намерения. Поиск с расширением запроса, с другой стороны, учитывает как явные, так и неявные намерения пользователя и может предвидеть последующие вопросы еще до того, как они будут заданы.
Функция Query Fan-Out выводит персонализацию на новый уровень. В то время как традиционный поиск в основном опирается на историю поиска, Query Fan-Out учитывает всесторонний контекст, такой как местоположение, текущие задачи календаря, модели общения и тип устройства. Поиск по запросу «тимьян» даст разные результаты для пользователя, который в данный момент готовит, и для человека, интересующегося ботаникой.
Какова роль механизма разветвления запросов в системах RAG?
Распределение запросов является неотъемлемой частью современных систем генерации поисковых запросов с расширенными возможностями и функционирует как высокоэффективный механизм поиска.
Системы RAG сочетают в себе преимущества информационного поиска и генеративного ИИ. Вместо того чтобы полагаться исключительно на предварительно обученные знания языковой модели, они дополняют их за счет доступа к внешним источникам данных в режиме реального времени. Это уменьшает проблему «галлюцинаций», когда системы ИИ генерируют правдоподобно звучащую, но фактически неверную информацию.
В этой системе алгоритм поиска с разветвлением запросов функционирует как многоэтапный процесс поиска. Вместо одного простого запроса, в рамках которого система ищет документы, соответствующие исходному запросу, алгоритм с разветвлением запросов выполняет многоуровневый параллельный процесс сбора информации. Разложив запрос на составляющие, система определяет все необходимые информационные аспекты, а затем собирает значительно более богатый и разнообразный набор контекстных документов и данных.
Расширенная контекстная база затем передается в генеративный компонент системы RAG. Языковая модель получает не только информацию об исходном запросе, но и предварительно обработанный многогранный контекст, охватывающий различные точки зрения и аспекты темы. Это значительно повышает качество, точность и полноту окончательного ответа.
Пошаговый подход также позволяет системам RAG отвечать на сложные многоуровневые запросы, на которые ранее не было дано однозначных ответов в режиме онлайн. Объединение нескольких источников информации позволяет делать новые выводы, выходящие за рамки анализа отдельных источников.
Еще одно преимущество заключается в улучшенной оперативности. В то время как предварительно обученные знания языковой модели привязаны к определенному моменту времени, их сочетание с алгоритмом расширения запросов позволяет получать доступ к актуальной информации из работающей сети Интернет, графов знаний и специализированных баз данных.
В чём заключается значение патента Google на тематический поиск?
Патент, поданный Google в декабре 2024 года и озаглавленный «Тематический поиск», содержит важные сведения о технической реализации метода расширения поискового запроса.
В патенте описывается система тематического поиска, которая организует связанные результаты поиска по запросу в категории, называемые темами. Для каждой из этих тем генерируется краткое описание, позволяющее пользователям понять ответы на свои вопросы, не переходя по ссылкам на различные веб-сайты.
Особенно инновационным является автоматическое определение тем в результатах традиционного поиска с использованием искусственного интеллекта. Система генерирует информативные резюме для каждой темы, учитывая как содержание, так и контекст результатов поиска.
Ключевым аспектом патента является генерация подзапросов. Один пользовательский запрос может инициировать несколько поисковых запросов, основанных на конкретных подтемах исходного запроса. Например, если кто-то ищет «проживание в городе X», система может автоматически сгенерировать подтемы, такие как «район A», «район B», «район C», «стоимость жизни», «досуг» и «преимущества и недостатки».
В патенте также описывается итеративный процесс. Выбор подтемы может привести к тому, что система получит другой набор результатов поиска и сгенерирует еще более конкретные темы. Это позволяет постепенно исследовать все более специфические аспекты предмета.
Параллели с официальным описанием Google техники Query Fan-Out поразительны. Оба подхода предполагают одновременное выполнение нескольких связанных поисковых запросов по различным подтемам и источникам данных, за которым следует синтез результатов в легко понятный ответ.
Патент также демонстрирует, как принципиально меняется представление результатов поиска. Вместо отображения ссылок, упорядоченных в соответствии с традиционными факторами ранжирования, результаты группируются по тематическим кластерам. Это означает, что веб-сайт, который мог бы не занимать первое место в результатах поиска по исходному запросу, все равно может быть заметно отображен, если он вносит вклад в соответствующую подтему.
Поддержка B2B и SaaS-решение для SEO и GEO (поиск с использованием ИИ): комплексное решение для B2B-компаний


Поддержка B2B и SaaS-решение для SEO и GEO (поиск с использованием ИИ): комплексное решение для B2B-компаний. — Изображение: Xpert.Digital
Поиск с использованием ИИ меняет всё: как это SaaS-решение навсегда изменит ваши позиции в B2B-рейтинге.
Цифровое пространство для B2B-компаний стремительно меняется. Под влиянием искусственного интеллекта правила онлайн-видимости переписываются. Для компаний всегда было непросто не только быть заметными в цифровом пространстве, но и оставаться актуальными для нужных лиц, принимающих решения. Традиционные стратегии SEO и управление локальным присутствием (геомаркетинг) сложны, трудоемки и часто представляют собой борьбу с постоянно меняющимися алгоритмами и жесткой конкуренцией.
Но что, если бы существовало решение, которое не только упростило бы этот процесс, но и сделало бы его умнее, более предсказуемым и гораздо более эффективным? Именно здесь вступает в игру сочетание специализированной B2B-поддержки с мощной платформой SaaS (программное обеспечение как услуга), специально разработанной для удовлетворения потребностей SEO и GEO в эпоху поиска с использованием искусственного интеллекта.
Новое поколение инструментов больше не полагается исключительно на ручной анализ ключевых слов и стратегии построения обратных ссылок. Вместо этого оно использует искусственный интеллект для более точного понимания поисковых намерений, автоматической оптимизации факторов локального ранжирования и проведения конкурентного анализа в режиме реального времени. Результатом является проактивная, основанная на данных стратегия, которая дает компаниям B2B решающее преимущество: их не только находят, но и воспринимают как ведущих экспертов в своей нише и регионе.
Вот симбиоз B2B-поддержки и SaaS-технологий на базе искусственного интеллекта, который трансформирует SEO и геомаркетинг, и как ваша компания может извлечь из этого выгоду для устойчивого роста в цифровом пространстве.
Более подробная информация здесь:
Объяснение концепции «распространения запросов»: почему в вашей контент-стратегии теперь нужны темы, а не ключевые слова
Как алгоритм Query Fan-Out влияет на контент-стратегию?
Влияние алгоритмов поисковой оптимизации на контентные стратегии огромно и требует переосмысления подхода к поисковой оптимизации.
Наиболее значительный сдвиг парадигмы связан с переходом от отдельных ключевых слов к тематическим кластерам. Если традиционная SEO-оптимизация концентрировалась на ранжировании по конкретным ключевым словам, то теперь создателям контента необходимо всесторонне освещать целые тематические области. Одна статья должна не только отвечать на главный вопрос, но и предвосхищать вероятные последующие вопросы и связанные с ними аспекты.
Значение основных страниц и тематических кластеров значительно возрастает. Основная страница всесторонне освещает ключевую тему, в то время как связанный контент кластера углубляется в конкретные подтемы. Такая структура естественным образом отражает то, как поисковые запросы организуют и извлекают информацию.
Теперь контент должен отвечать на запросы, содержащие несколько намерений пользователя. Вместо оптимизации под одно намерение пользователя, контент должен одновременно отвечать на различные намерения. Например, статья о «программном обеспечении для управления проектами» должна охватывать сравнения, ценовые структуры, варианты интеграции, внедрение пользователями и сценарии использования для команд разного размера.
Структурирование контента приобретает все большее значение. Четкие заголовки, разделы часто задаваемых вопросов, таблицы и маркированные списки помогают системам искусственного интеллекта быстро извлекать конкретную информацию. Контент должен быть организован таким образом, чтобы отдельные разделы могли служить самостоятельными ответами на подвопросы.
Сущности и их взаимосвязи приобретают все большее значение. Контент должен четко указывать на релевантные сущности и явно описывать их взаимосвязи. Это помогает системам искусственного интеллекта правильно определять местоположение контента в графе знаний и учитывать его при выполнении соответствующих подзапросов.
Глубина охвата темы становится важнее, чем плотность ключевых слов. Основное внимание следует уделять ответам на как можно больше ожидаемых вопросов по теме, а не частому повторению конкретного ключевого слова. Предпочтение отдается всестороннему, хорошо изученному контенту, рассматривающему тему с разных точек зрения.
Это представляет собой особую проблему для B2B-маркетологов. Поскольку решения о покупке часто принимаются множеством заинтересованных сторон с различными приоритетами, контент должен одновременно отвечать на вопросы различных лиц, принимающих решения. Финансовый директор заинтересован в ценовых структурах, ИТ-отдел — в интеграциях, а руководители высшего звена — в аспектах рентабельности инвестиций.
Какова роль структурированных данных и разметки схемы?
Структурированные данные и разметка схемы играют центральную роль в оптимизации в среде с разветвленной структурой запросов.
Разметка Schema выступает в качестве кода, который идентифицирует и классифицирует контент для систем искусственного интеллекта. В то время как люди могут читать текст и понимать его смысл, системам ИИ необходимы явные подсказки для различения различных типов информации. Если отзыв о продукте размечен с помощью Schema, система ИИ понимает «это отзыв», а не просто текст.
Схема FAQ особенно ценна для структурирования часто задаваемых вопросов, поскольку она структурирует часто задаваемые вопросы и ответы на них. Исследования показывают, что схема FAQ присутствует в 73 процентах ответов, сгенерированных ИИ, поскольку она точно соответствует тому, как системы ИИ обрабатывают многоцелевые запросы. Этот формат позволяет системам ИИ быстро идентифицировать релевантные пары вопрос-ответ и интегрировать их в синтезированные ответы.
Схема, описывающая процесс, структурирует пошаговые инструкции и идеально подходит для поисковых запросов, ориентированных на конкретные процессы. Такая схема должна включать четкое описание шагов, приблизительное время обработки, необходимые инструменты и ожидаемые результаты.
Схема продукта определяет технические характеристики, цены и рейтинги продукта, а также помогает системам искусственного интеллекта извлекать подробную информацию для сравнительных запросов. В схему должны быть включены все соответствующие атрибуты продукта – характеристики, размеры, совместимость и ценовые категории.
Организационная схема определяет детали бизнеса и области компетенции, а также формирует сигналы авторитета, которые системы искусственного интеллекта используют для оценки достоверности источников. Она должна указывать области компетенции, контактную информацию и отраслевую специализацию.
Схема отзывов выделяет обратную связь от клиентов, которой платформы ИИ отдают приоритет, поскольку они предпочитают источники с подтвержденным социальным доказательством. Схема статей помогает системам ИИ понимать тип контента, дату публикации и экспертность автора.
Для достижения максимального эффекта на соответствующих страницах можно комбинировать несколько типов схем. Например, страницы товаров могут одновременно содержать схемы «Товар», «Отзывы» и «Организация», чтобы предоставить исчерпывающую информацию, на которую могут ссылаться системы искусственного интеллекта.
Исследования показывают, что 61 процент страниц, цитируемых ChatGPT, используют разметку Schema. Это подчеркивает важность структурированных данных для обеспечения видимости в поисковых системах на основе искусственного интеллекта.
Как оптимизировать алгоритм обработки запросов с учетом расхождения ключевых слов?
Оптимизация для оптимизации потока запросов требует комплексного подхода, сочетающего технические, контентные и стратегические элементы.
Основой является всестороннее освещение темы. Контент должен не просто поверхностно затрагивать тему, а глубоко изучать ее и исследовать различные аспекты. Это означает создание основных страниц, которые всесторонне рассматривают ключевую тему, дополненных кластерным контентом, подробно описывающим конкретные подтемы.
Разделы часто задаваемых вопросов (FAQ) следует использовать стратегически для ответа на связанные вопросы и подвопросы. Они не должны быть произвольными, а должны систематически предвосхищать вероятные последующие вопросы, которые могут возникнуть у пользователя. Каждая комбинация вопроса и ответа должна предоставлять полную, самодостаточную информацию, которую системы искусственного интеллекта могут легко извлечь и процитировать.
Необходимо создать семантическую инфраструктуру. Контент следует оптимизировать с учетом смысла, контекста и намерений, а не только ключевых слов. Это означает изучение подтем, ответы на связанные вопросы и обеспечение максимально полного охвата информации.
Четкая структура контента имеет важное значение. Использование понятных заголовков (H2, H3), маркированных списков, коротких абзацев и таблиц для сравнения упрощает обработку информации системами искусственного интеллекта. Контент должен быть организован таким образом, чтобы инструменты ИИ могли быстро находить конкретные ответы.
Определение сущностей и отображение связей помогают системам ИИ правильно понимать и находить контент. Соответствующие сущности должны быть четко названы, а их связи друг с другом должны быть явно указаны. Это позволяет системам ИИ учитывать контент в различных связанных подзапросах.
Ответы должны быть максимально информативными в начале. Самая важная информация должна быть в начале, без длинных вступлений или ненужных деталей. Прямой подход, например: «Для продления паспорта вам потребуется заполненная форма DS-82, недавняя фотография и оплата. Вот полный процесс:», позволяет сразу перейти к сути.
Внедрение комплексной схемы разметки на всем веб-сайте — это не просто желательная, а стратегическая необходимость. Это включает в себя схему FAQ для часто задаваемых вопросов, схему HowTo для инструкций, схему Product для информации о продуктах и схему Organization для сведений о компании.
Основное внимание следует уделить оптимизации на уровне кластеров. Вместо того чтобы ориентироваться на отдельные ключевые слова, следует работать с более широкими группами ключевых слов и общими темами. Это создаст более прочную контентную основу, менее подверженную изменениям отдельных ключевых слов и изменчивости распространения информации.
Крайне важно избегать каннибализации контента. По мере создания всё большего количества контента необходимо следить за тем, чтобы страницы не конкурировали за одни и те же ключевые слова. Это сбивает с толку поисковые системы и снижает авторитет.
Какие проблемы возникают при использовании алгоритма расширения запросов?
Распределение запросов по сети представляет собой серьезную проблему как для создателей контента, так и для технических реализаций.
Ключевой проблемой является непредсказуемый характер запросов с расширенным поиском. Генерируемые подзапросы могут различаться даже для одного и того же запроса на одном и том же устройстве. Эта изменчивость означает, что, в отличие от традиционных SEO-рейтингов, которые относительно стабильны, видимость при расширенном поиске может значительно колебаться от пользователя к пользователю и от запроса к запросу.
Прогнозирование позиций в поисковой выдаче становится принципиально сложнее. В то время как традиционная SEO-оптимизация позволяет относительно точно оценивать позицию по конкретным ключевым словам за счет непрерывного мониторинга, анализ поисковых запросов значительно усложняет этот процесс. Контент может не занимать видное место по исходному запросу, но при этом цитироваться по конкретному подзапросу.
Увеличение задержки может наблюдаться при синхронном разветвлении, поскольку общее время ответа зависит от самого медленного запроса, поступающего ниже по потоку. Если один из параллельных подзапросов занимает особенно много времени, весь ответ будет задержан.
Распространение ошибок представляет собой риск. Одна ошибка в последующем запросе может вызвать каскадную реакцию и повлиять на весь запрос. Это требует надежных механизмов обработки ошибок, таких как автоматические выключатели и тайм-ауты.
Сложность мониторинга значительно возрастает. Отслеживание и отладка многоветвевых деревьев запросов становятся более трудными. Это требует сквозной трассировки и передовых инструментов мониторинга, таких как OpenTelemetry, Jaeger или Zipkin.
Проблема каннибализации контента становится все более актуальной. В связи с необходимостью создания более широких контентных кластеров возрастает риск конкуренции между различными сайтами по схожим темам, что приводит к перехвату видимости друг у друга.
Измерение успеха становится все сложнее. Традиционные SEO-метрики, такие как позиции по ключевым словам и органический трафик, больше не дают полной картины. Необходимо разработать новые метрики, которые позволят оценить ситуацию в различных сценариях распространения контента.
Затраты ресурсов возрастают. Создание действительно всеобъемлющего контента, отвечающего на различные подвопросы, требует больше времени, опыта и бюджета, чем оптимизация по отдельным ключевым словам. Организациям необходимо соответствующим образом адаптировать свои контент-стратегии и процессы.
Персонализация добавляет еще один уровень сложности. Поскольку запросы на отображение контента могут различаться в зависимости от контекста пользователя, местоположения, типа устройства и других факторов, становится еще сложнее предсказать, какой контент будет виден какой группе пользователей.
Как технология Query Fan-Out изменит будущее поиска?
Технология Query Fan-Out представляет собой фундаментальный сдвиг парадигмы в эволюции поисковых систем и имеет далеко идущие последствия для будущего информационного поиска.
Переход от сопоставления ключевых слов к пониманию намерений уже идет полным ходом. В будущем поисковые системы станут еще лучше понимать скрытые намерения, лежащие в основе запросов, даже если они неточны или неполны. Это означает, что пользователи будут тратить меньше времени на уточнение своих запросов и быстрее получать полезные ответы.
Интеграция личного контекста будет углубляться. Поисковые системы будут все чаще предоставлять персонализированные результаты, основанные не только на истории поиска, но и на всестороннем понимании пользователя, включая текущие задачи, местоположение, предпочтения и социальный контекст. Это сделает результаты поиска еще более динамичными и индивидуализированными.
Роль брендов и авторитета изменится. Если традиционно первостепенное значение имело ранжирование по конкретным ключевым словам, то теперь акцент будет все больше смещаться на утверждение себя в качестве надежного источника информации по всей тематической области. Бренды, предоставляющие всесторонний, высококачественный контент по различным тематическим кластерам, будут иметь преимущество в сценариях распространения контента.
Видимость становится все более фрагментированной и разнообразной. Вместо того чтобы занимать высокие позиции по нескольким основным ключевым словам, успешные веб-сайты упоминаются по множеству различных подзапросов. Это требует более широкой контент-стратегии и делает нишевый контент более ценным.
Поведение пользователей будет продолжать меняться. В связи с всё более прямыми и обобщенными ответами в поисковом интерфейсе пользователи будут реже переходить на сторонние веб-сайты. Это имеет последствия для посещаемости веб-сайтов и моделей монетизации, которые должны адаптироваться к этой новой реальности.
Мультимодальный поиск приобретает все большее значение. В будущем системы, ориентированные на обработку большого объема информации, будут учитывать не только текст, но и интегрировать изображения, видео, аудио и другие медиаформаты в свои подзапросы и синтез. Это требует контентных стратегий, выходящих за рамки чисто текстового поиска.
Слияние поиска и диалога будет продолжаться. Функция «расширения запроса» уже позволяет создавать поисковые системы, похожие на диалог, с предвосхищением последующих вопросов. В будущем грань между поисковыми системами и разговорными ИИ-помощниками станет еще более размытой.
Важность структурированных данных и семантической сети будет расти экспоненциально. Чем лучше контент семантически аннотирован и структурирован, тем эффективнее системы искусственного интеллекта смогут использовать его в сценариях распространения. Это сделает такие стандарты, как Schema.org, еще более важными.
Таким образом, технология Query Fan-Out представляет собой не только техническую инновацию, но и фундаментальный сдвиг во взаимоотношениях между пользователями, информацией и технологиями. Способность предвидеть и заблаговременно удовлетворять сложные информационные потребности определит следующее поколение интеллектуальных поисковых систем.
Ваш глобальный партнер по маркетингу и развитию бизнеса
☑️ Язык ведения нашего бизнеса — английский или немецкий
☑️ НОВИНКА: Переписка на вашем родном языке!

Konrad Wolfenstein
Я и моя команда будем рады быть вашими личными консультантами.
Вы можете связаться со мной, заполнив контактную форму здесь wolfenstein@xpert.digital:или просто позвонив по номеру +49 7348 4088 965. Мой адрес электронной почты
Я с нетерпением жду начала нашего совместного проекта.
☑️ Поддержка малых и средних предприятий в области стратегии, консалтинга, планирования и реализации проектов
☑️ Разработка или корректировка цифровой стратегии и цифровизации
☑️ Расширение и оптимизация международных процессов продаж
☑️ Глобальные и цифровые торговые платформы B2B
☑️ Развитие бизнеса / Маркетинг / PR / Выставки от компании Pioneer
Наш глобальный отраслевой и экономический опыт в области развития бизнеса, продаж и маркетинга

Наш глобальный отраслевой и экономический опыт в области развития бизнеса, продаж и маркетинга. — Изображение: Xpert.Digital
Основные отраслевые направления: B2B, цифровизация (от ИИ до XR), машиностроение, логистика, возобновляемые источники энергии и промышленность
Более подробная информация здесь:
Тематический центр, предлагающий аналитические материалы и экспертные знания:
- Информационная платформа, охватывающая глобальную и региональную экономику, инновации и отраслевые тенденции
- Сборник аналитических материалов, выводов и справочной информации по нашим ключевым направлениям деятельности
- Место, где можно найти экспертные знания и информацию о текущих событиях в бизнесе и технологиях
- Центр для компаний, стремящихся получить информацию о рынках, цифровизации и отраслевых инновациях
🎯🎯🎯 Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в одном комплексном пакете услуг | Развитие бизнеса, НИОКР, XR, PR и оптимизация цифровой видимости

Воспользуйтесь обширным пятисторонним опытом Xpert.Digital в рамках комплексного пакета услуг | НИОКР, XR, PR и оптимизация цифровой видимости - Изображение: Xpert.Digital
Компания Xpert.Digital обладает глубокими знаниями в различных отраслях. Это позволяет нам разрабатывать индивидуальные стратегии, точно соответствующие требованиям и задачам вашего конкретного сегмента рынка. Благодаря постоянному анализу рыночных тенденций и мониторингу отраслевых разработок мы можем действовать на опережение и предлагать инновационные решения. Сочетание опыта и экспертных знаний создает добавленную стоимость и обеспечивает нашим клиентам решающее конкурентное преимущество.
Более подробная информация здесь: