


IA și SEO cu BERT – Reprezentări bidirecționale ale encoderului din Transformers – Model în domeniul procesării limbajului natural (NLP) – Imagine: Xpert.Digital
🚀💬 Dezvoltat de Google: BERT și importanța sa pentru NLP - De ce este crucială înțelegerea bidirecțională a textului
🔍🗣️ BERT, prescurtare de la Bidirectional Encoder Representations from Transformers (Reprezentări Codificatoare Bidirecționale de la Transformers), este un model semnificativ în domeniul procesării limbajului natural (NLP) dezvoltat de Google. Acesta a revoluționat modul în care mașinile înțeleg limbajul. Spre deosebire de modelele anterioare care analizau textul secvențial de la stânga la dreapta sau invers, BERT permite procesarea bidirecțională. Aceasta înseamnă că înțelege contextul unui cuvânt atât din secvența de text precedentă, cât și din cea următoare. Această capacitate îmbunătățește semnificativ înțelegerea relațiilor lingvistice complexe.
🔍 Arhitectura BERT
În ultimii ani, una dintre cele mai semnificative evoluții în domeniul procesării limbajului natural (NLP) a avut loc odată cu introducerea modelului Transformer, așa cum este descris în lucrarea PDF din 2017 „Attention is all you need” (Wikipedia). Acest model a schimbat fundamental domeniul prin eliminarea structurilor utilizate anterior, cum ar fi traducerea automată. În schimb, se bazează exclusiv pe mecanisme de atenție. Designul Transformer a stat la baza multor modele care reprezintă stadiul actual al tehnicii în diverse domenii, inclusiv generarea vorbirii, traducerea și nu numai.
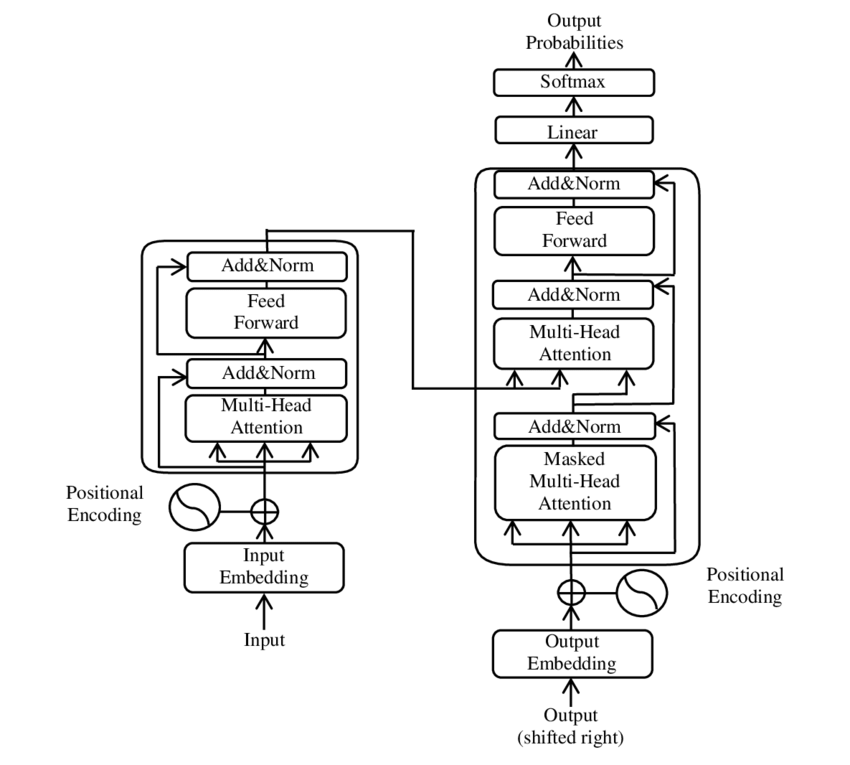
O ilustrare a principalelor componente ale modelului Transformer – Imagine: Google
BERT se bazează pe această arhitectură de transformare. Această arhitectură folosește așa-numitele mecanisme de autoatenție pentru a analiza relațiile dintre cuvintele dintr-o propoziție. Fiecărui cuvânt i se acordă atenție în contextul întregii propoziții, ceea ce duce la o înțelegere mai precisă a relațiilor sintactice și semantice.
Autorii lucrării „Atenția este tot ce ai nevoie” sunt:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Creierul Google)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Google Research)
- Aidan N. Gomez (Universitatea din Toronto, muncă realizată parțial la Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (Independentă, activitate anterioară la Google Research)
Acești autori au adus contribuții semnificative la dezvoltarea modelului Transformer prezentat în această lucrare.
🔄 Procesare bidirecțională
O caracteristică cheie a BERT este capacitatea sa de a procesa text bidirecțional. În timp ce modelele tradiționale, cum ar fi rețelele neuronale recurente (RNN) sau rețelele de memorie pe termen scurt (LSTM), procesează textul într-o singură direcție, BERT analizează contextul unui cuvânt în ambele direcții. Acest lucru permite modelului să surprindă mai bine nuanțele subtile ale sensului și, prin urmare, să facă predicții mai precise.
🕵️♂️ Modelare a vorbirii mascate
Un alt aspect inovator al BERT este tehnica Modelului de Limbaj Mascat (MLM). Aici, cuvinte selectate aleatoriu dintr-o propoziție sunt mascate, iar modelul este antrenat să prezică aceste cuvinte pe baza contextului înconjurător. Această metodă obligă BERT să dezvolte o înțelegere profundă a contextului și semnificației fiecărui cuvânt din propoziție.
🚀 Antrenament și adaptare BERT
BERT trece printr-un proces de antrenament în două etape: pre-antrenament și reglaj fin.
📚 Pre-antrenament
În faza de pre-antrenament, BERT este antrenat cu volume mari de text pentru a învăța modele lingvistice generale. Acestea includ articole Wikipedia și alte corpusuri de text extinse. În această fază, modelul învață structuri și contexte lingvistice de bază.
🔧 Reglaj fin
După pre-antrenament, BERT este adaptat pentru sarcini NLP specifice, cum ar fi clasificarea textului sau analiza sentimentelor. Modelul este antrenat cu seturi de date mai mici, legate de sarcină, pentru a-i optimiza performanța pentru aplicații specifice.
🌍 Domenii de aplicare ale BERT
BERT s-a dovedit extrem de util în numeroase domenii ale procesării limbajului natural:
Optimizarea pentru motoarele de căutare
Google folosește BERT pentru a înțelege mai bine interogările de căutare și pentru a afișa rezultate mai relevante. Acest lucru îmbunătățește semnificativ experiența utilizatorului.
Clasificarea textului
BERT poate clasifica documentele după subiect sau poate analiza starea de spirit din texte.
Recunoașterea Entității Denumite (NER)
Modelul identifică și clasifică entități numite în texte, cum ar fi numele de persoane, locuri sau organizații.
Sisteme de întrebare-răspuns
BERT este utilizat pentru a oferi răspunsuri precise la întrebările puse.
🧠 Importanța BERT pentru viitorul inteligenței artificiale
BERT a stabilit noi standarde pentru modelele NLP și a deschis calea pentru inovații ulterioare. Prin capacitatea sa de procesare bidirecțională și înțelegerea profundă a contextelor lingvistice, a crescut semnificativ eficiența și precizia aplicațiilor de inteligență artificială.
🔜 Dezvoltări viitoare
Dezvoltarea ulterioară a BERT și a modelelor similare este așteptată să vizeze crearea de sisteme și mai puternice. Acestea ar putea gestiona sarcini lingvistice mai complexe și ar putea fi utilizate într-o gamă largă de noi domenii de aplicare. Integrarea unor astfel de modele în tehnologiile de zi cu zi ar putea schimba fundamental modul în care interacționăm cu computerele.
🌟 O piatră de hotar în dezvoltarea inteligenței artificiale
BERT reprezintă o piatră de hotar în dezvoltarea inteligenței artificiale și a revoluționat modul în care mașinile procesează limbajul natural. Arhitectura sa bidirecțională permite o înțelegere mai profundă a relațiilor lingvistice, făcând-o indispensabilă pentru o gamă largă de aplicații. Pe măsură ce cercetarea progresează, modele precum BERT vor continua să joace un rol central în îmbunătățirea sistemelor de inteligență artificială și în deschiderea de noi posibilități pentru utilizarea acestora.
📣 Subiecte similare
- 📚 Introducere în BERT: Modelul NLP revoluționar
- 🔍 BERT și rolul bidirecționalității în NLP
- 🧠 Modelul Transformer: Fundația BERT
- 🚀 Modelarea limbajului mascat: Cheia succesului BERT
- 📈 Personalizare BERT: De la pre-antrenament la reglaj fin
- 🌐 Domeniile de aplicare ale BERT în tehnologia modernă
- 🤖 Influența lui BERT asupra viitorului inteligenței artificiale
- 💡 Perspective de viitor: Dezvoltări ulterioare ale BERT
- 🏆 BERT ca o piatră de hotar în dezvoltarea inteligenței artificiale
- 📰 Autorii lucrării Transformer „Atenția este tot ce ai nevoie”: Mințile din spatele BERT
#️⃣ Hashtag-uri: #NLP #InteligențăArtificială #ModelareLimbaj #Transformator #ÎnvățareAutomată
🎯🎯🎯 Beneficiați de expertiza extinsă, în cinci domenii, a Xpert.Digital într-un pachet complet de servicii | BD, R&D, XR, PR și optimizare a vizibilității digitale


Beneficiați de expertiza extinsă, în cinci domenii, a Xpert.Digital într-un pachet complet de servicii | Cercetare și dezvoltare, XR, PR și optimizare a vizibilității digitale - Imagine: Xpert.Digital
Xpert.Digital deține cunoștințe aprofundate în diverse industrii. Acest lucru ne permite să dezvoltăm strategii personalizate, aliniate cu precizie cerințelor și provocărilor segmentului dumneavoastră specific de piață. Prin analiza continuă a tendințelor pieței și monitorizarea evoluțiilor din industrie, putem acționa proactiv și oferi soluții inovatoare. Combinația dintre experiență și expertiză generează valoare adăugată și oferă clienților noștri un avantaj competitiv decisiv.
Mai multe informații aici:
BERT: Tehnologie NLP revoluționară 🌟
🚀 BERT, prescurtare de la Bidirectional Encoder Representations from Transformers (Reprezentări Codificatoare Bidirecționale de la Transformers), este un model lingvistic avansat dezvoltat de Google, care a reprezentat o descoperire semnificativă în procesarea limbajului natural (NLP) încă de la introducerea sa în 2018. Se bazează pe arhitectura Transformer, care a revoluționat modul în care mașinile înțeleg și procesează textul. Dar ce anume face ca BERT să fie atât de special și la ce se folosește? Pentru a răspunde la această întrebare, trebuie să aruncăm o privire mai atentă asupra fundamentelor tehnice ale BERT, a modului în care funcționează și a aplicațiilor sale.
📚 1. Noțiunile de bază ale procesării limbajului natural
Pentru a înțelege pe deplin importanța BERT, este util să trecem pe scurt în revistă elementele fundamentale ale procesării limbajului natural (NLP). NLP se ocupă de interacțiunea dintre computere și limbajul uman. Scopul său este de a învăța mașinile să analizeze, să înțeleagă și să răspundă la date textuale. Înainte de introducerea unor modele precum BERT, procesarea limbajului automat era adesea plină de provocări semnificative, în special din cauza ambiguității, dependenței de context și structurii complexe a limbajului uman.
📈 2. Dezvoltarea modelelor NLP
Înainte de apariția BERT, majoritatea modelelor NLP se bazau pe așa-numitele arhitecturi unidirecționale. Aceasta însemna că aceste modele citeau textul fie de la stânga la dreapta, fie de la dreapta la stânga, ceea ce însemna că puteau lua în considerare doar o cantitate limitată de context atunci când procesau un cuvânt dintr-o propoziție. Această limitare ducea adesea la incapacitatea modelelor de a surprinde pe deplin contextul semantic al unei propoziții. Acest lucru a făcut dificilă interpretarea corectă a cuvintelor ambigue sau sensibile la context.
O altă dezvoltare importantă în cercetarea NLP înainte de BERT a fost modelul word2vec, care permitea computerelor să traducă cuvintele în vectori care reflectă similarități semantice. Cu toate acestea, chiar și aici, contextul era limitat la împrejurimile imediate ale unui cuvânt. Ulterior, au fost dezvoltate Rețelele Neuronale Recurente (RNN) și, în special, modelele de memorie pe termen scurt (LSTM), care au făcut posibilă o mai bună înțelegere a secvențelor de text prin stocarea informațiilor în mai multe cuvinte. Cu toate acestea, aceste modele aveau și limitările lor, în special atunci când se lucrau cu texte lungi și înțelegeau simultan contextul în ambele direcții.
🔄 3. Revoluția prin arhitectura transformatoare
Descoperirea a venit odată cu introducerea arhitecturii Transformer în 2017, care stă la baza BERT. Modelele Transformer sunt concepute pentru a permite procesarea paralelă a textului, luând în considerare contextul unui cuvânt atât din textul precedent, cât și din cel următor. Acest lucru se realizează prin așa-numitele mecanisme de autoatenție, care atribuie o valoare de pondere fiecărui cuvânt dintr-o propoziție, în funcție de importanța sa în raport cu celelalte cuvinte din propoziție.
Spre deosebire de abordările anterioare, modelele transformatoare nu sunt unidirecționale, ci bidirecționale. Aceasta înseamnă că pot extrage informații atât din contextul stâng, cât și din cel drept al unui cuvânt pentru a crea o reprezentare mai completă și mai precisă a cuvântului și a semnificației sale.
🧠 4. BERT: Un model bidirecțional
BERT duce performanța arhitecturii Transformer la un nou nivel. Modelul este conceput pentru a surprinde contextul unui cuvânt nu doar de la stânga la dreapta sau de la dreapta la stânga, ci simultan în ambele direcții. Acest lucru permite BERT să ia în considerare contextul complet al unui cuvânt dintr-o propoziție, rezultând o precizie semnificativ îmbunătățită în sarcinile de procesare a limbajului natural.
O caracteristică cheie a BERT este utilizarea așa-numitului Model de Limbaj Mascat (MLM). În timpul antrenamentului BERT, cuvinte selectate aleatoriu dintr-o propoziție sunt înlocuite cu o mască, iar modelul este antrenat să ghicească aceste cuvinte mascate pe baza contextului. Această tehnică permite BERT să învețe relații mai profunde și mai precise dintre cuvintele dintr-o propoziție.
În plus, BERT folosește o metodă numită Next Sentence Prediction (NSP), în care modelul învață să prezică dacă o propoziție urmează după alta. Acest lucru îmbunătățește capacitatea BERT de a înțelege texte mai lungi și de a recunoaște relații mai complexe între propoziții.
🌐 5. Aplicarea practică a BERT
BERT s-a dovedit extrem de util pentru o gamă largă de sarcini NLP. Iată câteva dintre cele mai importante domenii de aplicare:
📊 a) Clasificarea textului
Una dintre cele mai comune aplicații ale BERT este clasificarea textului, unde textele sunt împărțite în categorii predefinite. Exemplele includ analiza sentimentelor (de exemplu, recunoașterea dacă un text este pozitiv sau negativ) sau clasificarea feedback-ului clienților. Datorită înțelegerii sale profunde a contextului cuvintelor, BERT poate oferi rezultate mai precise decât modelele anterioare.
❓ b) Sisteme de întrebare-răspuns
BERT este utilizat și în sistemele de întrebări-răspuns, unde modelul extrage răspunsuri la întrebările puse dintr-un text. Această capacitate este deosebit de importantă în aplicații precum motoarele de căutare, chatbot-urile și asistenții virtuali. Datorită arhitecturii sale bidirecționale, BERT poate extrage informații relevante dintr-un text chiar dacă întrebarea este formulată indirect.
🌍 c) Traducerea textului
Deși BERT în sine nu este conceput direct ca un model de traducere, acesta poate fi utilizat în combinație cu alte tehnologii pentru a îmbunătăți traducerea automată. Printr-o mai bună înțelegere a relațiilor semantice dintr-o propoziție, BERT poate ajuta la generarea de traduceri mai precise, în special în cazul formulărilor ambigue sau complexe.
🏷️ d) Recunoașterea entității denumite (NER)
Un alt domeniu de aplicare este recunoașterea entităților denumite (NER), care implică identificarea entităților specifice, cum ar fi nume, locuri sau organizații, într-un text. BERT s-a dovedit a fi deosebit de eficient în această sarcină, deoarece ia în considerare pe deplin contextul unei propoziții și, prin urmare, poate recunoaște mai bine entitățile, chiar dacă acestea au semnificații diferite în contexte diferite.
✂️ e) Rezumat textual
Capacitatea BERT de a înțelege întregul context al unui text îl face, de asemenea, un instrument puternic pentru sumarizarea automată a textului. Poate fi folosit pentru a extrage cele mai importante informații dintr-un text lung și a crea un rezumat concis.
🌟 6. Importanța BERT pentru cercetare și industrie
Introducerea BERT a inaugurat o nouă eră în cercetarea NLP. A fost unul dintre primele modele care au valorificat pe deplin puterea arhitecturii transformatorului bidirecțional, stabilind standardul pentru multe modele ulterioare. Numeroase companii și instituții de cercetare au integrat BERT în proiectele lor NLP pentru a îmbunătăți performanța aplicațiilor lor.
În plus, BERT a deschis calea pentru inovații ulterioare în domeniul modelelor lingvistice. De exemplu, au fost dezvoltate ulterior modele precum GPT (Generative Pretrained Transformer) și T5 (Text-to-Text Transfer Transformer), care se bazează pe principii similare, dar oferă îmbunătățiri specifice pentru diferite cazuri de utilizare.
🚧 7. Provocări și limite ale BERT
În ciuda numeroaselor sale avantaje, BERT are și unele provocări și limitări. Unul dintre cele mai mari obstacole este efortul de calcul ridicat necesar pentru antrenarea și aplicarea modelului. Deoarece BERT este un model foarte mare, cu milioane de parametri, necesită hardware puternic și resurse de calcul semnificative, în special atunci când se procesează seturi mari de date.
O altă problemă este potențiala eroare care poate fi prezentă în datele de antrenament. Deoarece BERT este antrenat pe baza unor cantități mari de date textuale, uneori reflectă prejudecățile și stereotipurile prezente în aceste date. Cu toate acestea, cercetătorii lucrează continuu pentru a identifica și a aborda aceste probleme.
🔍 Un instrument indispensabil pentru aplicațiile moderne de procesare a vorbirii
BERT a îmbunătățit semnificativ modul în care mașinile înțeleg limbajul uman. Cu arhitectura sa bidirecțională și metodele inovatoare de antrenament, este capabil să înțeleagă contextul cuvintelor dintr-o propoziție în profunzime și cu acuratețe, ceea ce duce la o precizie mai mare în multe sarcini NLP. Fie că este vorba de clasificarea textului, sistemele de întrebări-răspuns sau recunoașterea entităților, BERT s-a impus ca un instrument indispensabil pentru aplicațiile moderne de procesare a limbajului natural.
Cercetările în domeniul procesării limbajului natural vor continua, fără îndoială, să avanseze, iar BERT a pus bazele multor inovații viitoare. În ciuda provocărilor și limitărilor existente, BERT demonstrează în mod impresionant cât de departe a evoluat tehnologia într-un timp scurt și ce oportunități interesante se vor deschide în continuare în viitor.
🌀 Transformatorul: O revoluție în procesarea limbajului natural
🌟 În ultimii ani, una dintre cele mai semnificative evoluții în domeniul procesării limbajului natural (NLP) a fost introducerea modelului Transformer, așa cum este descris în lucrarea din 2017 „Attention Is All You Need” (Atenția este tot ce aveți nevoie). Acest model a schimbat fundamental domeniul prin eliminarea structurilor recurente sau convoluționale utilizate anterior pentru sarcinile de transducție secvențială, cum ar fi traducerea automată. În schimb, se bazează exclusiv pe mecanisme atenționale. Designul Transformer a format de atunci baza pentru multe modele care reprezintă stadiul actual al tehnicii în diverse domenii, inclusiv generarea vorbirii, traducerea și nu numai.
🔄 Transformatorul: O schimbare de paradigmă
Înainte de introducerea Transformer, majoritatea modelelor pentru sarcini secvențiale se bazau pe rețele neuronale recurente (RNN) sau rețele de memorie pe termen scurt (LSTM), care funcționează în mod inerent secvențial. Aceste modele procesează datele de intrare pas cu pas, creând stări ascunse care se propagă de-a lungul secvenței. Deși această metodă este eficientă, este costisitoare din punct de vedere computațional și dificil de paralelizat, în special pentru secvențe lungi. În plus, RNN-urile se luptă să învețe dependențele pe termen lung din cauza problemei gradientului de dispariție.
Inovația cheie a Transformer constă în utilizarea mecanismelor de autoatenție, care permit modelului să evalueze importanța diferitelor cuvinte dintr-o propoziție unele în raport cu altele, indiferent de poziția lor. Acest lucru permite modelului să surprindă relațiile dintre cuvinte separate larg mai eficient decât RNN-urile sau LSTM-urile și să facă acest lucru în paralel, mai degrabă decât secvențial. Acest lucru nu numai că îmbunătățește eficiența antrenării, ci și performanța în sarcini precum traducerea automată.
🧩 Arhitectură model
Transformatorul este alcătuit din două componente principale: un codificator și un decodificator, ambele fiind alcătuite din mai multe straturi și bazându-se în mare măsură pe mecanisme de atenție cu mai multe capete.
⚙️ Encoder
Codificatorul este alcătuit din șase straturi identice, fiecare cu câte două substraturi:
1. Autoatenție cu mai multe capete
Acest mecanism permite modelului să se concentreze pe diferite părți ale propoziției de intrare atunci când procesează fiecare cuvânt. În loc să calculeze atenția într-un singur spațiu, atenția cu mai multe capete proiectează intrarea în mai multe spații diferite, surprinzând astfel diverse tipuri de relații dintre cuvinte.
2. Rețele feedforward complet conectate pozițional
După stratul de atenție, o rețea de feedback complet conectată este aplicată independent la fiecare poziție. Acest lucru ajută modelul să proceseze fiecare cuvânt în context și să utilizeze informațiile din mecanismul de atenție.
Pentru a păstra structura secvenței de intrare, modelul include și codificări poziționale. Deoarece transformatorul nu procesează cuvintele secvențial, aceste codificări sunt cruciale pentru a oferi modelului informații despre ordinea cuvintelor într-o propoziție. Codificările poziționale sunt adăugate la încorporările cuvintelor, astfel încât modelul să poată distinge între diferitele poziții din secvență.
🔍 Decodor
La fel ca codificatorul, decodificatorul este alcătuit din șase straturi, fiecare cu un mecanism suplimentar de atenție care permite modelului să se concentreze asupra părților relevante ale secvenței de intrare în timp ce generează ieșirea. Decodificatorul folosește, de asemenea, o tehnică de mascare pentru a împiedica luarea în considerare a pozițiilor viitoare, păstrând astfel natura autoregresivă a generării secvenței.
🧠 Atenție multi-head și atenție scalară asupra produsului
Nucleul Transformer este mecanismul de atenție cu mai multe capete, care este o extensie a produsului scalar mai simplu. Funcția de atenție poate fi privită ca o mapare între o interogare și un set de perechi cheie-valoare, unde fiecare cheie reprezintă un cuvânt din secvență, iar valoarea reprezintă informațiile contextuale corespunzătoare.
Mecanismul de atenție cu mai multe capete permite modelului să se concentreze simultan pe diferite părți ale secvenței. Prin proiectarea datelor de intrare în mai multe subspații, modelul poate surprinde un set mai bogat de relații dintre cuvinte. Acest lucru este util în special pentru sarcini precum traducerea automată, unde înțelegerea contextului unui cuvânt necesită mulți factori diferiți, cum ar fi structura sintactică și semnificația semantică.
Formula pentru atenția la produsul scalar este:
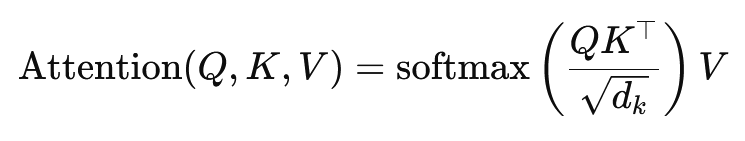
Aici, (Q) este matricea de interogare, (K) matricea cheie și (V) matricea valorilor. Termenul (sqrt{d_k}) este un factor de scalare care împiedică produsele scalare să devină prea mari, ceea ce ar duce la gradienți foarte mici și la o învățare mai lentă. Funcția softmax este aplicată pentru a se asigura că suma ponderilor atenției este egală cu unu.
🚀 Avantajele transformatorului
Transformatorul oferă câteva avantaje cruciale față de modelele tradiționale, cum ar fi RNN-urile și LSTM-urile:
1. Paralelizare
Deoarece transformatorul procesează simultan toate token-urile unei secvențe, acesta poate fi puternic paralelizat și, prin urmare, este mult mai rapid de antrenat decât RNN-urile sau LSTM-urile, în special cu seturi de date mari.
2. Dependențe pe termen lung
Mecanismul de autoatenție permite modelului să surprindă relațiile dintre cuvinte îndepărtate mai eficient decât RNN-urile, care sunt limitate de natura secvențială a calculelor lor.
3. Scalabilitate
Transformatorul se poate scala cu ușurință la seturi de date foarte mari și secvențe mai lungi, fără a suferi de blocajele de performanță asociate cu RNN-urile.
🌍 Aplicații și efecte
De la introducerea sa, Transformer a devenit fundamentul pentru o gamă largă de modele NLP. Unul dintre cele mai notabile exemple este BERT (Bidirectional Encoder Representations from Transformers), care utilizează o arhitectură Transformer modificată pentru a obține performanțe de ultimă generație în multe sarcini NLP, inclusiv răspunsuri la întrebări și clasificarea textului.
O altă dezvoltare semnificativă este GPT (Generative Pretrained Transformer), care folosește o versiune limitată de decodor a transformatorului pentru generarea de text. Modelele GPT, inclusiv GPT-3, sunt utilizate acum pentru numeroase aplicații, de la crearea de conținut până la completarea codului.
🔍 Un model puternic și flexibil
Transformerul a schimbat fundamental modul în care abordăm sarcinile NLP. Acesta oferă un model puternic și flexibil care poate fi aplicat unei game largi de probleme. Capacitatea sa de a gestiona dependențele pe termen lung și eficiența sa în antrenament l-au transformat în abordarea arhitecturală preferată pentru multe dintre cele mai moderne modele. Pe măsură ce cercetarea progresează, vom vedea probabil îmbunătățiri și adaptări suplimentare ale Transformerului, în special în domenii precum procesarea imaginilor și a vorbirii, unde mecanismele atenționale prezintă rezultate promițătoare.
Suntem aici pentru tine - Consultanță - Planificare - Implementare - Management de proiect
☑️ Expert în industrie, aici cu propriul hub Xpert.Digital, cu peste 2.500 de articole de specialitate

Konrad Wolfenstein
Aș fi bucuros să vă servesc drept consilier personal.
Mă puteți contacta completând formularul de contact de mai jos sau pur și simplu sunându-mă la +49 7348 4088 965 .
Aștept cu nerăbdare proiectul nostru comun.
Scrie-mi




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital este un hub pentru industrie, axat pe digitalizare, inginerie mecanică, logistică/intralogistică și fotovoltaică.
Cu soluția noastră de Dezvoltare Afaceri 360°, sprijinim companii renumite, de la achiziții noi până la post-vânzare.
Inteligența de piață, smarketing-ul, automatizarea marketingului, dezvoltarea de conținut, PR-ul, campaniile de e-mail, social media personalizate și cultivarea lead-urilor fac parte din instrumentele noastre digitale.
Puteți găsi mai multe informații la: www.xpert.digital - www.xpert.solar - www.xpert.plus
Păstrăm legătura











