
O încercare de a explica IA: Cum funcționează și funcționează inteligența artificială – cum este antrenată?

Selectarea limbii 📢
Publicat pe: 8 septembrie 2024 / Actualizat pe: 9 septembrie 2024 – Autor: Konrad Wolfenstein

O încercare de a explica IA: Cum funcționează inteligența artificială și cum este antrenată? – Imagine: Xpert.Digital
📊 De la introducerea datelor la predicția modelului: Procesul IA
Cum funcționează inteligența artificială (IA)? 🤖
Funcționarea inteligenței artificiale (IA) poate fi împărțită în mai multe etape clar definite. Fiecare dintre aceste etape este crucial pentru rezultatul final livrat de IA. Procesul începe cu introducerea datelor și se termină cu predicția modelului și orice feedback sau runde ulterioare de antrenament. Aceste faze descriu procesul prin care trec aproape toate modelele de IA, indiferent dacă sunt seturi simple de reguli sau rețele neuronale extrem de complexe.
1. Introducerea datelor 📊
Fundamentul oricărei inteligențe artificiale sunt datele cu care lucrează. Aceste date pot exista sub diverse forme, cum ar fi imagini, text, fișiere audio sau videoclipuri. IA folosește aceste date brute pentru a recunoaște tipare și a lua decizii. Calitatea și cantitatea datelor joacă un rol crucial aici, deoarece influențează semnificativ cât de bine sau de rău va performa în cele din urmă modelul.
Cu cât datele sunt mai cuprinzătoare și mai precise, cu atât mai bine poate învăța inteligența artificială. De exemplu, atunci când o inteligență artificială antrenează pentru procesarea imaginilor, aceasta are nevoie de o cantitate mare de date de imagine pentru a identifica corect diferite obiecte. Pentru modelele lingvistice, datele text sunt cele care ajută inteligența artificială să înțeleagă și să genereze vorbirea umană. Introducerea datelor este primul și unul dintre cei mai importanți pași, deoarece calitatea predicțiilor poate fi la fel de bună ca și datele subiacente. Un principiu celebru în informatică descrie acest lucru prin zicala „dacă intrăm gunoi, ieșim gunoi” - datele proaste duc la rezultate proaste.
2. Preprocesarea datelor 🧹
Odată ce datele au fost introduse, acestea trebuie pregătite înainte de a putea fi introduse în modelul propriu-zis. Acest proces se numește preprocesare a datelor. Scopul este de a transforma datele într-un format pe care modelul îl poate procesa optim.
O etapă comună în preprocesare este normalizarea datelor. Aceasta înseamnă aducerea datelor într-un interval uniform de valori, astfel încât acestea să fie tratate în mod consecvent de către model. Un exemplu ar fi scalarea tuturor valorilor pixelilor unei imagini la un interval de la 0 la 1, în loc de 0 la 255.
O altă parte importantă a preprocesării este extragerea caracteristicilor. Aceasta implică extragerea unor caracteristici specifice din datele brute, care sunt deosebit de relevante pentru model. În procesarea imaginilor, acestea pot fi margini sau modele de culoare specifice, în timp ce în procesarea textului sunt extrase cuvinte cheie relevante sau structuri de propoziții. Preprocesarea este crucială pentru a face procesul de învățare al inteligenței artificiale mai eficient și mai precis.
3. Modelul 🧩
Modelul este nucleul oricărei inteligențe artificiale. Aici, datele sunt analizate și procesate pe baza unor algoritmi și calcule matematice. Un model poate exista în diverse forme. Unul dintre cele mai cunoscute modele este rețeaua neuronală, care se bazează pe funcționarea creierului uman.
Rețelele neuronale sunt alcătuite din mai multe straturi de neuroni artificiali care procesează și transmit informații. Fiecare strat preia ieșirile de la stratul anterior și le procesează mai departe. Procesul de învățare al unei rețele neuronale implică ajustarea ponderilor conexiunilor dintre acești neuroni, astfel încât rețeaua să poată face predicții sau clasificări din ce în ce mai precise. Această ajustare se realizează prin antrenament, în care rețeaua accesează cantități mari de date exemplificative și își îmbunătățește iterativ parametrii interni (ponderile).
Pe lângă rețelele neuronale, în modelele de inteligență artificială sunt utilizați mulți alți algoritmi. Aceștia includ arbori de decizie, păduri aleatorii, mașini cu vectori de suport și mulți alții. Algoritmul utilizat depinde de sarcina specifică și de datele disponibile.
4. Prognoza modelului 🔍
Odată ce modelul a fost antrenat cu date, acesta este capabil să facă predicții. Acest pas se numește predicție a modelului. Inteligența artificială primește o intrare și, pe baza tiparelor pe care le-a învățat până în prezent, returnează o ieșire, adică o predicție sau o decizie.
Această predicție poate lua diferite forme. Într-un model de clasificare a imaginilor, de exemplu, inteligența artificială ar putea prezice ce obiect este afișat într-o imagine. Într-un model lingvistic, ar putea prezice ce cuvânt va urma într-o propoziție. În predicțiile financiare, inteligența artificială ar putea prognoza cum se va comporta piața bursieră.
Este important de subliniat faptul că acuratețea predicțiilor depinde în mare măsură de calitatea datelor de antrenament și de arhitectura modelului. Un model antrenat pe date insuficiente sau distorsionate are o probabilitate mare de a face predicții incorecte.
5. Feedback și instruire (opțional) ♻️
Un alt aspect important al modului în care funcționează o inteligență artificială este mecanismul de feedback. Aici, modelul este verificat periodic și optimizat în continuare. Acest proces are loc fie în timpul antrenamentului, fie după predicția modelului.
Dacă modelul face predicții incorecte, acesta poate învăța prin feedback să recunoască aceste erori și să își ajusteze parametrii interni în consecință. Acest lucru se realizează prin compararea predicțiilor modelului cu rezultatele reale (de exemplu, cu date cunoscute pentru care există deja răspunsuri corecte). O metodă tipică în acest context este așa-numita învățare supravegheată, în care inteligența artificială învață din date exemplificative care conțin deja răspunsurile corecte.
O metodă comună de feedback este algoritmul de backpropagation utilizat în rețelele neuronale. Aici, erorile făcute de model sunt propagate înapoi prin rețea pentru a ajusta ponderile conexiunilor neuronale. În acest fel, modelul învață din greșelile sale și devine din ce în ce mai precis în predicțiile sale.
Rolul antrenamentului 🏋️♂️
Antrenarea unei inteligențe artificiale este un proces iterativ. Cu cât modelul vede mai multe date și cu cât este antrenat mai des pe baza acestor date, cu atât predicțiile sale devin mai precise. Există însă limite: un model supraantrenat poate dezvolta așa-numitele probleme de „supraadaptare”. Aceasta înseamnă că memorează datele de antrenament atât de bine încât oferă rezultate mai slabe pe date noi, necunoscute. Prin urmare, este important să antrenăm modelul în așa fel încât să generalizeze, adică să poată face și predicții bune pe date noi.
Pe lângă antrenamentul obișnuit, există și metode precum învățarea prin transfer. Aici, un model care a fost deja antrenat pe un set mare de date este utilizat pentru o sarcină nouă, similară. Acest lucru economisește timp și putere de calcul, deoarece modelul nu trebuie antrenat complet de la zero.
Profită la maximum de punctele tale forte 🚀
Funcționarea inteligenței artificiale (IA) se bazează pe o interacțiune complexă a diverșilor pași. De la introducerea și preprocesarea datelor până la antrenarea modelului, predicție și feedback, mulți factori influențează acuratețea și eficiența IA. O IA bine antrenată poate oferi avantaje enorme în multe domenii ale vieții - de la automatizarea sarcinilor simple până la rezolvarea problemelor complexe. Cu toate acestea, este la fel de important să înțelegem limitele și potențialele capcane ale IA pentru a utiliza la maximum punctele sale forte.
🤖📚 Simplu explicat: Cum este antrenată o inteligență artificială?
🤖📊 Procesul de învățare prin inteligență artificială: Capturați, conectați și stocați
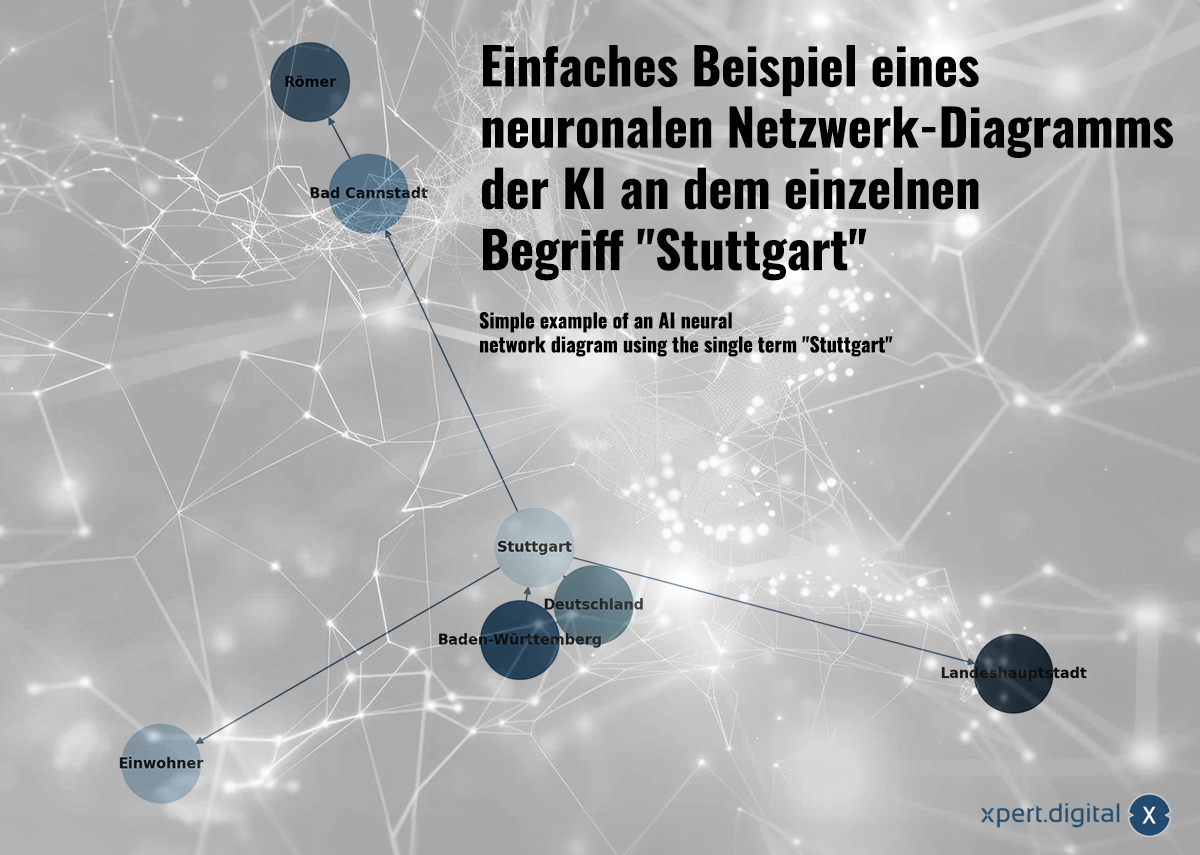
Exemplu simplu de diagramă a unei rețele neuronale de inteligență artificială folosind un singur termen „Stuttgart” – Imagine: Xpert.Digital
🌟 Colectarea și pregătirea datelor
Primul pas în procesul de învățare a inteligenței artificiale este colectarea și pregătirea datelor. Aceste date pot proveni din diverse surse, cum ar fi baze de date, senzori, texte sau imagini.
🌟 Date de relaționare (rețea neuronală)
Datele colectate sunt legate între ele într-o rețea neuronală. Fiecare pachet de date este reprezentat de conexiuni într-o rețea de „neuroni” (noduri). Un exemplu simplu care utilizează orașul Stuttgart ar putea arăta astfel:
a) Stuttgart este un oraș din Baden-Württemberg
b) Baden-Württemberg este un stat federal din Germania
c) Stuttgart este un oraș din Germania
d) Stuttgart avea o populație de 633.484 de locuitori în 2023
e) Bad Cannstatt este un district al orașului Stuttgart
f) Bad Cannstatt a fost fondat de romani
g) Stuttgart este capitala statului Baden-Württemberg
În funcție de dimensiunea volumului de date, parametrii pentru potențialele ieșiri sunt generați folosind modelul AI. De exemplu, GPT-3 are aproximativ 175 de miliarde de parametri!
🌟 Salvare și personalizare (învățare)
Datele sunt introduse în rețeaua neuronală. Acestea trec prin modelul de inteligență artificială și sunt procesate prin conexiuni (similar sinapselor). Ponderile (parametrii) dintre neuroni sunt ajustate pentru a antrena modelul sau pentru a îndeplini o sarcină.
Spre deosebire de metodele convenționale de stocare, cum ar fi accesul direct, accesul indexat, stocarea secvențială sau în loturi, rețelele neuronale stochează datele într-un mod neconvențional. „Datele” sunt stocate în ponderile și tendințele conexiunilor dintre neuroni.
„Stocarea” propriu-zisă a informațiilor într-o rețea neuronală are loc prin ajustarea ponderilor conexiunilor dintre neuroni. Modelul de inteligență artificială „învață” prin ajustarea continuă a acestor ponderi și erori pe baza datelor de intrare și a unui algoritm de învățare definit. Acesta este un proces continuu în care modelul poate face predicții mai precise prin ajustări repetate.
Modelul de inteligență artificială poate fi considerat un fel de programare, deoarece este creat prin algoritmi definiți și calcule matematice, iar ajustarea parametrilor (ponderilor) acestuia este îmbunătățită continuu pentru a face predicții precise. Acesta este un proces continuu.
Biasurile sunt parametri suplimentari în rețelele neuronale care sunt adăugați la valorile de intrare ponderate ale unui neuron. Acestea permit ponderarea parametrilor (importanți, mai puțin importanți etc.), făcând IA mai flexibilă și mai precisă.
Rețelele neuronale nu pot doar stoca fapte individuale, ci pot și recunoaște relațiile dintre date prin recunoașterea tiparelor. Exemplul cu Stuttgart ilustrează modul în care cunoștințele pot fi introduse într-o rețea neuronală, însă rețelele neuronale nu învață prin cunoștințe explicite (ca în acest exemplu simplu), ci mai degrabă prin analiza tiparelor de date. Prin urmare, rețelele neuronale nu pot doar stoca fapte individuale, ci pot și învăța ponderi și relații dintre datele de intrare.
Acest proces oferă o introducere ușor de înțeles în modul în care funcționează inteligența artificială, și în special rețelele neuronale, fără a intra prea mult în detalii tehnice. Demonstrează că informațiile nu sunt stocate în rețele neuronale ca în bazele de date convenționale, ci mai degrabă prin ajustarea conexiunilor (ponderilor) din cadrul rețelei.
🤖📚 Mai detaliat: Cum este antrenată o inteligență artificială?
🏋️♂️ Antrenarea unei inteligențe artificiale, în special a unui model de învățare automată, implică mai mulți pași. Antrenarea inteligenței artificiale se bazează pe optimizarea continuă a parametrilor modelului prin feedback și ajustări, până când modelul are cele mai bune performanțe pe baza datelor furnizate. Iată o explicație detaliată a modului în care funcționează acest proces:
1. 📊 Colectați și pregătiți datele
Datele reprezintă fundamentul antrenamentului în domeniul inteligenței artificiale. Acestea constau de obicei din mii sau milioane de exemple pe care sistemul este menit să le analizeze. Exemplele includ imagini, text sau date din serii temporale.
Datele trebuie curățate și normalizate pentru a evita sursele inutile de erori. Adesea, datele sunt transformate în elemente care conțin informațiile relevante.
2. 🔍 Definiți modelul
Un model este o funcție matematică care descrie relațiile din date. În rețelele neuronale, care sunt frecvent utilizate pentru inteligența artificială, modelul constă din mai multe straturi de neuroni interconectați.
Fiecare neuron efectuează o operație matematică pentru a procesa datele de intrare și apoi transmite un semnal următorului neuron.
3. 🔄 Inițializați ponderile
Conexiunile dintre neuroni au ponderi stabilite inițial aleatoriu. Aceste ponderi determină cât de puternic răspunde un neuron la un semnal.
Scopul antrenamentului este de a ajusta aceste ponderi astfel încât modelul să facă predicții mai bune.
4. ➡️ Propagare înainte
În timpul trecerii înainte, datele de intrare sunt procesate de model pentru a obține o predicție.
Fiecare strat procesează datele și le transmite următorului strat până când ultimul strat furnizează rezultatul.
5. ⚖️ Calculați funcția de pierdere
Funcția de pierdere măsoară cât de bine se compară predicțiile modelului cu valorile reale (etichetele). O măsură comună este eroarea dintre răspunsul prezis și cel real.
Cu cât pierderea este mai mare, cu atât predicția modelului este mai proastă.
6. 🔙 Propagare inversă
În iterația inversă, eroarea este urmărită înapoi de la rezultatul modelului către straturile anterioare.
Eroarea este redistribuită ponderilor conexiunilor, iar modelul ajustează ponderile astfel încât erorile să devină mai mici.
Acest lucru se realizează folosind coborârea în gradient: se calculează vectorul gradient, care indică modul în care ar trebui modificate ponderile pentru a minimiza eroarea.
7. 🔧 Actualizați ponderile
După ce eroarea a fost calculată, ponderile conexiunilor sunt actualizate cu o mică ajustare bazată pe rata de învățare.
Rata de învățare determină cât de mult se modifică ponderile la fiecare pas. Modificările prea mari pot face modelul instabil, în timp ce modificările prea mici duc la un proces de învățare lent.
8. 🔁 Repetare (Epoci)
Acest proces de trecere înainte, calcul al erorii și actualizare a ponderilor se repetă, adesea pe parcursul mai multor epoci (treceri prin întregul set de date), până când modelul atinge o precizie acceptabilă.
Cu fiecare eră, modelul învață puțin mai multe și își ajustează în continuare ponderile.
9. 📉 Validare și testare
După ce modelul a fost antrenat, acesta este testat pe un set de date validat pentru a verifica cât de bine generalizează. Acest lucru asigură nu numai că a „memorat” datele de antrenament, ci și că face predicții bune pe date necunoscute.
Datele de testare ajută la măsurarea performanței finale a modelului înainte de utilizarea acestuia în practică.
10. 🚀 Optimizare
Alte etape pentru îmbunătățirea modelului includ reglarea hiperparametrilor (de exemplu, ajustarea ratei de învățare sau a structurii rețelei), regularizarea (pentru a evita supraadaptarea) sau creșterea cantității de date.
📊🔙 Inteligență Artificială: Cum să facem cutia neagră a IA inteligibilă, ușor de înțeles și explicată cu ajutorul IA Explainable (XAI), hărților termice, modelelor surogat sau altor soluții

Inteligența artificială: Cum să facem cutia neagră a IA ușor de înțeles, de înțeles și de explicat cu ajutorul IA explicabilă (XAI), hărților termice, modelelor surogat sau altor soluții – Imagine: Xpert.Digital
Așa-numita „cutie neagră” a inteligenței artificiale (IA) reprezintă o problemă semnificativă și presantă. Chiar și experții se confruntă adesea cu provocarea de a nu putea înțelege pe deplin modul în care sistemele de IA ajung la deciziile lor. Această lipsă de transparență poate cauza probleme considerabile, în special în domenii critice precum economia, politica și medicina. Un medic care se bazează pe un sistem de IA pentru diagnostic și recomandări de tratament trebuie să aibă încredere în deciziile luate. Cu toate acestea, dacă procesul decizional al unei IA nu este suficient de transparent, apare incertitudinea, ceea ce poate duce la o lipsă de încredere - și aceasta în situații în care vieți omenești ar putea fi în pericol.
Mai multe informații aici:
Suntem aici pentru tine - Consultanță - Planificare - Implementare - Management de proiect
☑️ Suport pentru IMM-uri în strategie, consultanță, planificare și implementare
☑️ Crearea sau realinierea strategiei digitale și a digitalizării
☑️ Extinderea și optimizarea proceselor de vânzări internaționale
☑️ Platforme de tranzacționare B2B globale și digitale
☑️ Dezvoltare de afaceri pionieră

Konrad Wolfenstein
Aș fi bucuros să vă servesc drept consilier personal.
Mă puteți contacta completând formularul de contact de mai jos sau pur și simplu sunându-mă la +49 89 89 674 804 (München) .
Aștept cu nerăbdare proiectul nostru comun.
Scrie-mi

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital este un hub pentru industrie, axat pe digitalizare, inginerie mecanică, logistică/intralogistică și fotovoltaică.
Cu soluția noastră de Dezvoltare Afaceri 360°, sprijinim companii renumite, de la achiziții noi până la post-vânzare.
Inteligența de piață, smarketing-ul, automatizarea marketingului, dezvoltarea de conținut, PR-ul, campaniile de e-mail, social media personalizate și cultivarea lead-urilor fac parte din instrumentele noastre digitale.
Puteți găsi mai multe informații la: www.xpert.digital - www.xpert.solar - www.xpert.plus
Păstrăm legătura
















