Date structurate (marcaj) în era inteligenței artificiale cu Schema.org: Ce cred cu adevărat inginerii Google – Imagine: Xpert.Digital
Secretul SEO al Google: De ce inteligența artificială eșuează fără date structurate
În ciuda ChatGPT și a companiilor similare: De ce inginerii Google continuă să jure pe Schema.org
Actualizare SEO: De ce Schema.org înlocuiește acum Open Graph pe Google
Un mit persistent circulă în lumea SEO: În era modelelor lingvistice inteligente bazate pe inteligență artificială, care înțeleg fără efort chiar și textul nestructurat, datele structurate, întreținute cu meticulozitate, precum Schema.org, au devenit pur și simplu învechite. Dar realitatea este cu totul alta. La evenimentul Google Search Central Live, inginerul Google Ryan Levering a demontat această concepție greșită și a clarificat-o fără echivoc: marcajul structurat nu este o relicvă a trecutului, ci mai degrabă coloana vertebrală fundamentală a noii căutări bazate pe inteligență artificială.
De la noile prezentări generale ale inteligenței artificiale la agenții de cumpărături autonomi, modelele lingvistice au nevoie de îndrumări precise, lizibile de mașini, pentru a evita halucinațiile și pentru a funcționa eficient din punct de vedere computațional. Cei care doresc să rămână vizibili pe web-ul modern trebuie să ajute mașinile să înțeleagă contextul fără ambiguitate. Acest articol examinează realinierea strategică a Google, prezintă inovații revoluționare pentru comerțul electronic și conținutul generat de utilizatori și arată de ce SEO tehnic este acum avantajul competitiv decisiv în bătălia pentru vizibilitatea mașinilor.
Mașinile pot citi internetul – dar numai dacă le ajuți să îl înțeleagă
Pe 21 aprilie 2026, a avut loc la Toronto primul eveniment Google Search Central Live de pe teritoriul canadian – și nu a fost o reuniune obișnuită din partea industriei. Ryan Levering, inginer la Google Search Engineering, a susținut ceea ce a fost probabil cea mai densă din punct de vedere tehnic și cea mai semnificativă din punct de vedere strategic prezentare a zilei: „Date structurate, calitate și inteligență artificială”. Ceea ce a prezentat a fost mai mult decât o analiză tehnică. A fost o declarație clară despre viitorul webului semantic într-o eră în care inteligența artificială își asumă din ce în ce mai mult rolul de intermediar între utilizatori și informații.
Între două extreme: greșitul „ori-ori”
La începutul prezentării sale, Ryan Levering a pus în contrast două opinii diametral opuse care circulă în comunitatea SEO. Pe de o parte, există convingerea că datele structurate sunt pur și simplu superflue în era modelelor lingvistice puternice: Dacă modelele de inteligență artificială pot interpreta cu ușurință text nestructurat, de ce să ne mai deranjăm să adăugăm cu ușurință markup-ul schema.org la codul sursă? Pe de altă parte, unii entuziaști propagă ideea că datele structurate reprezintă viitorul internetului - un protocol universal de comunicare semantică între agenți de inteligență artificială autonomi, care va înlocui în mare măsură web-ul tradițional.
Levering a respins ambele extreme și a prezentat în schimb o perspectivă nuanțată, fundamentată empiric. Ambele poziții conțineau un sâmbure de adevăr, a concluzionat el, dar niciuna nu descria pe deplin realitatea. Această nuanță este caracteristică abordării actuale a Google asupra subiectului: nu este vorba despre dogmă, ci despre eficiență pragmatică.
Patru argumente care explică totul
Argumentul central al lui Levering poate fi rezumat în patru puncte cheie, pe care le-a elaborat sub titlul „Valoarea datelor structurate”. Primul punct este precizia: datele structurate oferă o acuratețe semnificativ mai mare pentru scheme complexe, cum ar fi prețurile de vânzare sau programele de fidelizare, decât extragerea bazată pe LLM din text liber. Modelele lingvistice pot fi înșelătoare - acestea completează atributele lipsă, imbricau datele incorect sau accesează informațiile în afara contextului. Atunci când se extrag prețurile produselor de pe un site de comerț electronic mare, cu zeci de articole similare, rata de eroare este semnificativ mai mare cu inferența AI decât cu markup structurat, implementat curat.
Al doilea punct se referă la conținutul suplimentar: datele structurate conțin adesea metadate invizibile care pur și simplu nu sunt prezente în HTML-ul redat al unei pagini. Formate de dată ISO complete, identificatori stabili pentru conținutul generat de utilizatori sau ID-uri de entități interne - aceste informații există exclusiv în markup. Niciun model lingvistic nu poate extrage ceea ce nu se află în text.
În al treilea rând, eficiența: Analiza markup-ului structurat este de multe ori mai ieftină decât procesarea unui model lingvistic mare pentru a extrage date complexe. Google indexează miliarde de pagini zilnic. Calculul este simplu: un parser obișnuit care procesează JSON-LD consumă o fracțiune din resursele de calcul ale unui pas de inferență LLM. Prin urmare, datele structurate nu sunt doar superioare semantic, ci sunt și semnificativ mai eficiente din perspectiva afacerii. Acest aspect are o relevanță directă pentru infrastructura Google.
Al patrulea aspect, și poate cel mai subestimat, este focalizarea: datele structurate evidențiază explicit ce informații sunt relevante pe o pagină, împiedicând astfel sistemele de inteligență artificială să identifice date irelevante. Pe o pagină de produs cu un articol principal, mai multe produse conexe și o bară de navigare plină de prețuri, un model lingvistic fără adnotare explicită nu poate fi sigur la ce preț să se refere. Marcajul structurat rezolvă această problemă printr-o atribuire lipsită de ambiguitate.
Cum sunt procesate efectiv datele structurate
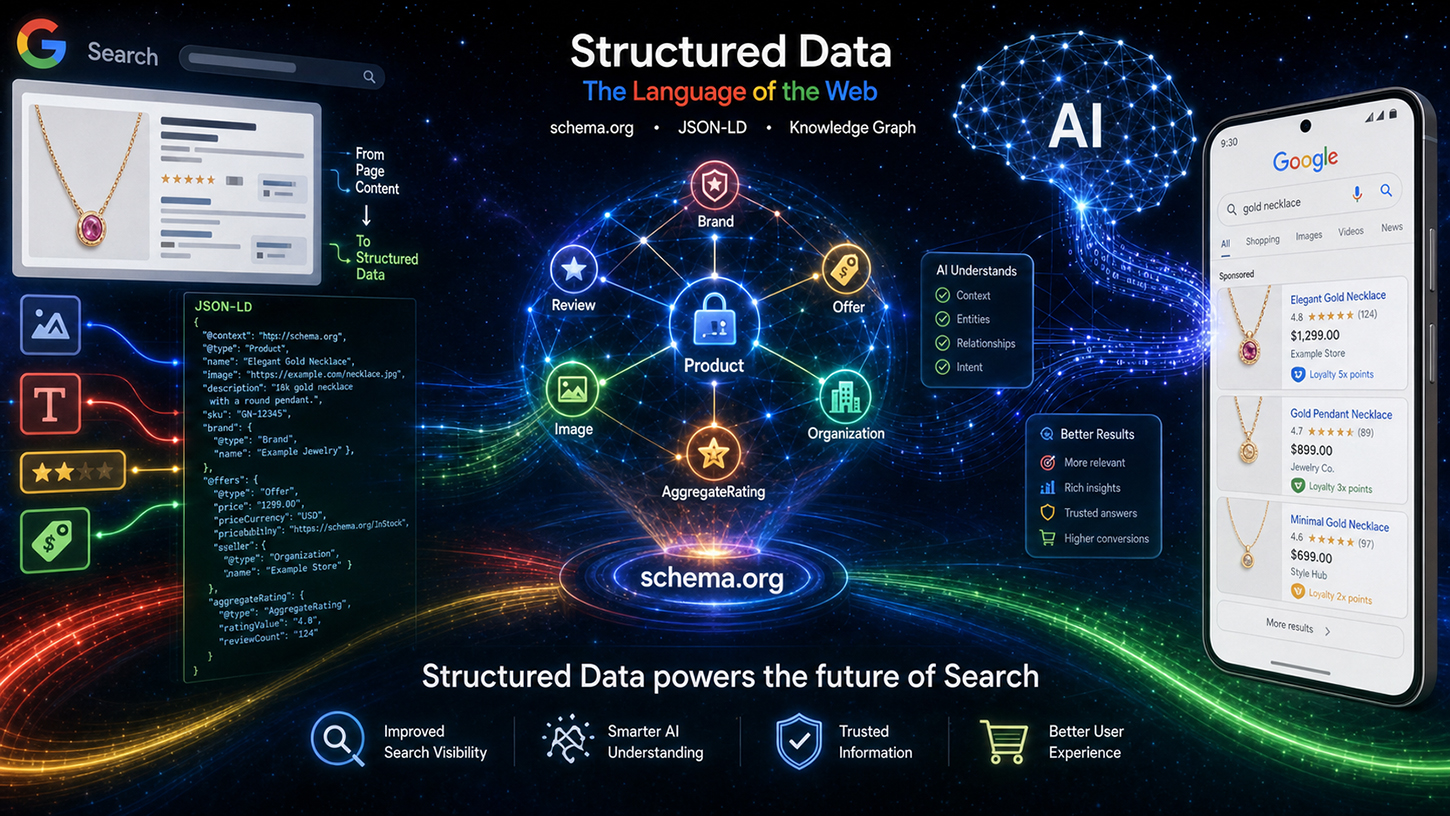
De asemenea, utilizarea levering-ului a făcut transparent fluxul de procesare tehnică. Datele Schema.org sunt mai întâi procesate prin curățare și filtrare specifice înainte de a fi clasificate ca date indexate - împărțite în domenii precum evenimente, cumpărături și recenzii. Aceste date pregătite curg apoi în două canale de ieșire diferite: pe de o parte, pagina clasică cu rezultatele căutării (SRP), iar pe de altă parte, ca context pentru sistemele bazate pe inteligență artificială ale Google, în special așa-numitele AI Overviews (AIO) și AI Mode (AIM). Prin urmare, datele structurate nu mai sunt doar un instrument bogat în rezultate, ci o intrare directă pentru răspunsuri generative bazate pe inteligență artificială. Aceasta reprezintă o schimbare fundamentală în importanța strategică a markup-ului schema.org.
🎯🎯🎯 Hub industrial B2B bazat pe date, ca soluție cvasi-internă


Soluția cvasi-internă: Cum acoperă Xpert.Digital lacunele operaționale în marketingul și vânzările B2B – Smart Content-Driven Business - Imagine: Xpert.Digital
Xpert.Digital este un hub industrial B2B bazat pe date, condus de Konrad Wolfenstein . Compania acționează ca o soluție externă, cvasi-internă, pentru partenerii industriali, eliminând lacunele operaționale în marketing, conținut și vânzări – fără a necesita resurse suplimentare din partea clientului.
Mai multe informații aici:
De ce datele structurate devin infrastructura pentru agenții de inteligență artificială
Cumpărături în centrul atenției: Livrare, fidelizare și variante
O parte semnificativă a prezentării s-a concentrat pe inovațiile din comerțul electronic. Levering a explicat că, conform datelor de la Institutul Baymard, informațiile neașteptate privind livrarea se clasează pe locul doi și trei printre cele mai frecvente motive pentru abandonul coșului de cumpărături. Marcajul structurat pentru serviciile de livrare poate aborda direct această problemă: Comercianții pot acum defini cu precizie regiunile de origine și destinație, dimensiunile și greutățile, pragurile valorii comenzilor, timpii de procesare și afilierile la programele de fidelitate direct în cod.
Modelul de timp de livrare utilizat de Google este împărțit în două faze: timpul de manipulare, adică timpul de la primirea comenzii până la predarea către transportator, și timpul de livrare efectiv. Ambele faze pot fi adnotate separat și cu o granularitate ridicată - până la orele limită de procesare a comenzii și dacă procesarea are loc și în timpul săptămânii. Exemplele JSON-LD corespunzătoare arată cum poate fi utilizat tipul „ShippingConditions” pentru a defini livrarea gratuită pentru anumite țări (de exemplu, Franța și Germania) și valori minime ale comenzilor (de exemplu, 50 EUR).
Integrarea serviciilor de livrare cu programele de fidelitate este deosebit de inovatoare. Folosind proprietatea `validForMemberTier`, un serviciu de livrare poate fi legat explicit de un program de membru și de un anumit nivel. Acest lucru face posibilă declararea beneficiilor de livrare pentru membrii premium direct în markup – o funcție configurabilă anterior doar prin Google Merchant Center. Programul de fidelitate asociat în sine este definit ca un obiect `MemberProgram` sub entitatea `Organization`, cu niveluri precum „Gold” sau „Silver” și beneficii asociate, cum ar fi premii de fidelitate sau recompense în puncte.
Programele de fidelizare ca entități semantice
Introducerea markup-ului programelor de fidelizare este semnificativă din punct de vedere economic. Organizațiile pot defini mai multe programe de membru independente, fiecare cu mai multe niveluri și beneficii diferențiate - puncte, prețuri pentru membri, politici de returnare, bonusuri de livrare. Aceste informații apar apoi direct în rezultatele căutării Google, așa cum a demonstrat Levering cu exemple din lumea reală, inclusiv o ofertă Sephora care afișa o reducere de 30% pentru membri direct în fragmentul de cumpărături. Legătura ID-urilor între pagini, capacitatea de a face legătura cu definițiile programelor de fidelizare de pe alte pagini, este, potrivit lui Levering, următorul pas planificat, intitulat în prezent „Deschiderea drumului pentru legătura @id între pagini”. Scopul: referințe organizaționale mai puternice între paginile de produse și politicile companiei.
Conținut generat de utilizatori: Problema etichetării prin inteligență artificială
Un alt subiect important a fost dezvoltarea în continuare a tipurilor de scheme pentru conținutul generat de utilizatori (UGC). Două caracteristici noi sunt deosebit de relevante aici. În primul rând, postările și repostările încorporate sunt acceptate în markup-ul forumurilor și al secțiunilor de întrebări și răspunsuri, permițând o reprezentare semantică mai precisă a structurilor de discuții. În al doilea rând - și acest lucru este de o importanță strategică și mai mare - este introdusă proprietatea `so#digitalSourceType` pentru a identifica în mod explicit conținutul generat de mașini.
Această dezvoltare este un răspuns direct la avalanșa de conținut generat de inteligența artificială pe platforme precum forumuri și site-uri de întrebări și răspunsuri. Administratorii web pot acum declara dacă o postare a fost generată algoritmic sau de un model lingvistic. Cei care nu specifică acest lucru sunt implicit considerați de Google ca fiind autori umani - o regulă care stimulează etichetarea transparentă. Proprietatea `digitalSourceType` se bazează pe codurile IPTC pentru sursele digitale și face distincție, printre altele, între conținutul generat algoritmic și cel generat de modele.
Selecția imaginilor: Schema este cea mai bună opțiune pentru Open Graph
O actualizare mai puțin observată, dar eficientă din punct de vedere practic, privește logica de selecție a imaginilor la Google. Sistemul este consolidat intern, cu o ierarhie clară de prioritizare: markup-ul Schema.org, în special proprietățile `primaryImageOfPage` și `mainEntity → image`, are prioritate. Abia atunci urmează metaeticheta `og:image` din Open Graph. Această modificare înseamnă că, pentru operatorii de site-uri web, o implementare schema.org curată a imaginii principale influențează direct afișarea acesteia în rezultatele căutării Google și în AI Overviews – un avantaj concret și măsurabil.
Schema.org în sine primește investiții
De asemenea, este demnă de remarcat anunțul Google privind reinvestiția în schema.org ca specificație deschisă. Au fost menționate trei măsuri concrete: publicarea statisticilor privind frecvența de utilizare a termenilor individuali din schemă (datele de prevalență, așa cum se arată în diapozitive, sunt deja disponibile pentru termeni individuali precum „digitalSourceType” cu informații despre aproximativ 10.000 de domenii), publicarea propriilor reguli de validare Google în formate standard lizibile de mașini, cum ar fi SHACL sau ShEx, și un suport îmbunătățit pentru regulile de ordine. Acest lucru este semnificativ deoarece ar permite dezvoltatorilor externi să își construiască propriile instrumente de validare bazate pe standardele Google - independent de instrumentele oficiale de testare, care se blochează ocazional sub sarcină.
Validare: Două instrumente, un singur obiectiv
Levering a prezentat două instrumente de validare care se completează reciproc, dar aplică criterii de testare diferite. Instrumentul de testare a rezultatelor îmbogățite (Rich Result Test Tool) de la `search.google.com/test/rich-results` acceptă URL-uri sau JSON pur și verifică dacă markup-ul este potrivit pentru rezultatele îmbogățite ale căutării Google - prin urmare, se bazează pe cerințele specifice ale Google, nu pe standardul schema.org în sine. `validator.schema.org`, pe de altă parte, verifică dacă markup-ul este compatibil cu schema.org, adică aderă la vocabularul deschis, indiferent dacă Google generează sau nu rezultate îmbogățite din acesta. Acest lucru duce la o recomandare clară pentru dezvoltatorii web: ambele instrumente ar trebui utilizate, deoarece markup-ul poate fi compatibil cu schema, dar nu poate genera rezultate îmbogățite - și invers.
Imaginea de ansamblu: Datele structurate ca infrastructură de inteligență artificială
Privind evenimentul de la Toronto în ansamblu, este evidentă o schimbare care se extinde mult dincolo de optimizarea SEO tradițională. Datele structurate evoluează de la un instrument pentru obținerea de rich snippets la un standard fundamental al stratului de date pentru sistemele de inteligență artificială. AI Overviews și AI Mode de la Google utilizează în mod activ markup-ul schema.org ca și context pentru generarea de răspunsuri și verificarea entităților. Cei care implementează date structurate corecte, complete și precise nu numai că își îmbunătățesc șansele de a obține evidențieri vizuale în rezultatele căutării, dar își poziționează conținutul ca o sursă primară fiabilă pentru răspunsuri bazate pe inteligență artificială.
Menționarea Protocolului Universal de Comerț (UCP) și a WebMCP în acest context nu este o coincidență. Ambele standarde de comunicare bazate pe agenți, lansate de Google în versiuni timpurii în 2026, impun ca site-urile web să fie descrise semantic. Schema.org stă la baza acestui lucru. Într-o lume în care agenții IA acționează autonom pe web, căutând, comparând și inițiind tranzacții, lizibilitatea automată a conținutului nu mai este opțională, ci o condiție prealabilă pentru relevanța economică. Prin urmare, prezentarea lui Ryan Levering din Toronto nu a fost doar un raport de actualizare tehnică - a fost o privire asupra infrastructurii următorului web.
Poți afla singur în 10 secunde
Dacă vrei să știi cât de bine și cuprinzător folosește site-ul tău web sau un alt site web datele structurate, poți folosi exact cele două instrumente recomandate de Ryan Levering de la Google (din textul nostru de mai sus):
Testul Rezultate Rich Google (concentrare pe vizibilitatea pe Google):
Accesați search.google.com/test/rich-results, copiați adresa URL a oricărui articol xpert.digital și faceți clic pe „Test URL”. Instrumentul vă va arăta exact ce markup-uri recunoaște Google pe pagina respectivă și dacă acestea nu conțin erori.
Validator de scheme (concentrat pe conformitatea pură cu standardele):
Accesați validator.schema.orgși lipiți aceeași adresă URL. Aici puteți vedea direct în codul sursă, evidențiat cu culoare, ce scripturi JSON-LD (date structurate) a încorporat xpert.digital.
Partenerul dumneavoastră global de marketing și dezvoltare a afacerilor
☑️ Limba noastră de afaceri este engleza sau germana
☑️ NOU: Corespondență în limba ta maternă!

Konrad Wolfenstein
Eu și echipa mea suntem bucuroși să vă fim la dispoziție în calitate de consilier personal.
Mă puteți contacta completând formularul de contact de aici wolfenstein@xpert.digital:sau pur și simplu sunându-mă la +49 7348 4088 965. Adresa mea de e-mail este
Aștept cu nerăbdare proiectul nostru comun.
☑️ Suport pentru IMM-uri în strategie, consultanță, planificare și implementare
☑️ Crearea sau realinierea strategiei digitale și a digitalizării
☑️ Extinderea și optimizarea proceselor de vânzări internaționale
☑️ Platforme de tranzacționare B2B globale și digitale
☑️ Dezvoltare Afaceri Pioneer / Marketing / PR / Târguri Comerciale
Suport B2B și SaaS pentru SEO și GEO (căutare AI) combinate: Soluția all-in-one pentru companiile B2B


Suport B2B și SaaS pentru SEO și GEO (căutare AI) combinate: Soluția all-in-one pentru companiile B2B - Imagine: Xpert.Digital
Căutarea cu inteligență artificială schimbă totul: Cum această soluție SaaS vă va revoluționa pentru totdeauna clasamentul B2B.
Peisajul digital pentru companiile B2B trece printr-o schimbare rapidă. Sub impulsul inteligenței artificiale, regulile vizibilității online sunt rescrise. Pentru companii, a fost întotdeauna o provocare nu doar să fie vizibile în masa digitală, ci și să fie relevante pentru factorii de decizie potriviți. Strategiile SEO tradiționale și gestionarea prezenței locale (geo-marketing) sunt complexe, consumatoare de timp și adesea o luptă împotriva algoritmilor în continuă schimbare și a concurenței intense.
Dar ce-ar fi dacă ar exista o soluție care nu numai că simplifică acest proces, ci îl face și mai inteligent, mai predictiv și mult mai eficient? Aici intervine combinația dintre asistența specializată B2B și o platformă SaaS (Software as a Service) puternică, special concepută pentru cerințele SEO și GEO în era căutării bazate pe inteligență artificială.
Această nouă generație de instrumente nu se mai bazează exclusiv pe analiza manuală a cuvintelor cheie și pe strategiile de backlink. În schimb, utilizează inteligența artificială pentru a înțelege mai precis intenția de căutare, a optimiza automat factorii de clasare locali și a efectua analize competitive în timp real. Rezultatul este o strategie proactivă, bazată pe date, care oferă companiilor B2B un avantaj decisiv: nu sunt doar găsite, ci percepute ca autoritate principală în nișa și locația lor.
Iată simbioza dintre suportul B2B și tehnologia SaaS bazată pe inteligență artificială care transformă marketingul SEO și GEO și cum poate compania dvs. să beneficieze de aceasta pentru a crește sustenabil în spațiul digital.
Mai multe informații aici: