
IA e SEO com BERT – Representações de codificador bidirecional de transformadores – modelo na área de processamento de linguagem natural (PNL)

Seleção de voz 📢
Publicado em: 4 de outubro de 2024 / Atualização de: 4 de outubro de 2024 - Autor: Konrad Wolfenstein

IA e SEO com BERT – Representações de codificadores bidirecionais de transformadores – Modelo na área de processamento de linguagem natural (PNL) – Imagem: Xpert.Digital
🚀💬 Desenvolvido pelo Google: BERT e sua importância para PNL - Por que a compreensão bidirecional de texto é crucial
🔍🗣️ BERT, abreviação de Representações de codificador bidirecional de transformadores, é um modelo importante na área de processamento de linguagem natural (PNL) desenvolvido pelo Google. Revolucionou a maneira como as máquinas entendem a linguagem. Ao contrário dos modelos anteriores que analisavam o texto sequencialmente da esquerda para a direita ou vice-versa, o BERT permite o processamento bidirecional. Isso significa que ele captura o contexto de uma palavra da sequência de texto anterior e subsequente. Essa habilidade melhora significativamente a compreensão de contextos linguísticos complexos.
🔍 A arquitetura do BERT
Nos últimos anos, um dos desenvolvimentos mais significativos na área de Processamento de Linguagem Natural (PNL) ocorreu com a introdução do modelo Transformer, conforme apresentado no PDF 2017 - Atenção é tudo que você precisa - papel ( Wikipedia ). Este modelo mudou fundamentalmente o campo ao descartar as estruturas anteriormente utilizadas, como a tradução automática. Em vez disso, depende exclusivamente de mecanismos de atenção. Desde então, o design do Transformer serviu de base para muitos modelos que representam o que há de mais moderno em diversas áreas, como geração de idiomas, tradução e muito mais.
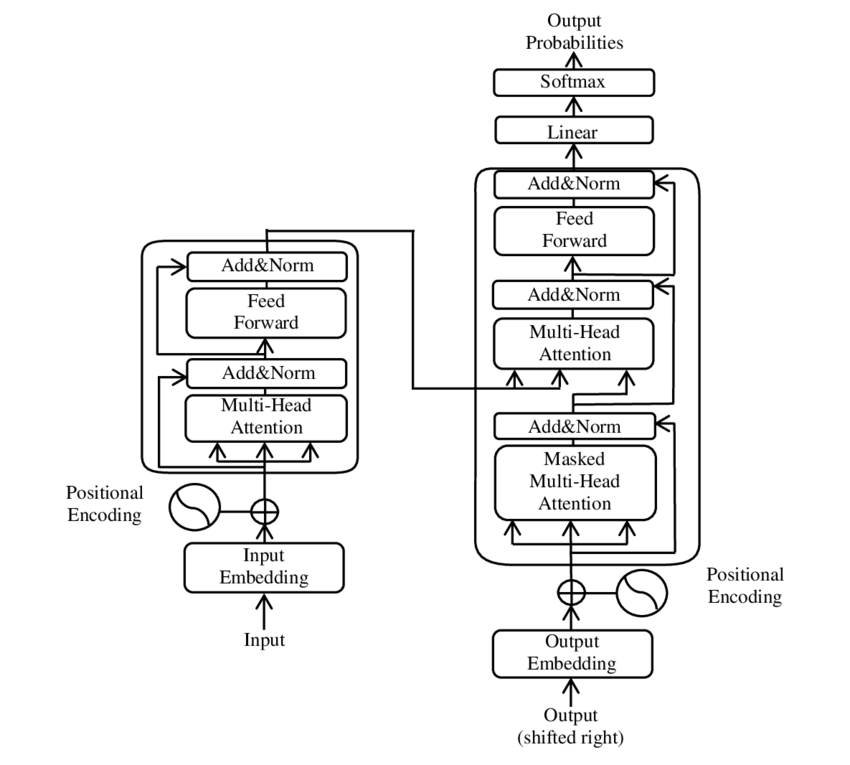
Uma ilustração dos principais componentes do modelo Transformer – Imagem: Google
BERT é baseado nesta arquitetura Transformer. Essa arquitetura usa os chamados mecanismos de autoatenção para analisar as relações entre as palavras em uma frase. É dada atenção a cada palavra no contexto de toda a frase, resultando em uma compreensão mais precisa das relações sintáticas e semânticas.
Os autores do artigo "Atenção é tudo que você precisa" são:
- Ashish Vaswani (Google Cérebro)
- Noam Shazeer (Google Cérebro)
- Niki Parmar (Pesquisa Google)
- Jakob Uszkoreit (Google Research)
- Leão Jones (Pesquisa Google)
- Aidan N. Gomez (Universidade de Toronto, trabalho parcialmente realizado no Google Brain)
- Lukasz Kaiser (Google Cérebro)
- Illia Polosukhin (Independente, trabalho anterior no Google Research)
Esses autores contribuíram significativamente para o desenvolvimento do modelo Transformer apresentado neste artigo.
🔄 Processamento bidirecional
Uma característica marcante do BERT é sua capacidade de processamento bidirecional. Enquanto modelos tradicionais, como redes neurais recorrentes (RNNs) ou redes Long Short-Term Memory (LSTM), processam texto apenas em uma direção, o BERT analisa o contexto de uma palavra em ambas as direções. Isso permite que o modelo capture melhor nuances sutis de significado e, portanto, faça previsões mais precisas.
🕵️♂️ Modelagem de linguagem mascarada
Outro aspecto inovador do BERT é a técnica Masked Language Model (MLM). Envolve mascarar palavras selecionadas aleatoriamente em uma frase e treinar o modelo para prever essas palavras com base no contexto circundante. Este método força o BERT a desenvolver uma compreensão profunda do contexto e do significado de cada palavra da frase.
🚀 Treinamento e customização de BERT
O BERT passa por um processo de treinamento em duas etapas: pré-treinamento e ajuste fino.
📚 Pré-treino
No pré-treinamento, o BERT é treinado com grandes quantidades de texto para aprender padrões gerais de linguagem. Isso inclui textos da Wikipédia e outros corpora de texto extensos. Nesta fase, o modelo aprende estruturas e contextos linguísticos básicos.
🔧 Ajuste fino
Após o pré-treinamento, o BERT é customizado para tarefas específicas de PNL, como classificação de texto ou análise de sentimento. O modelo é treinado com conjuntos de dados menores relacionados a tarefas para otimizar seu desempenho para aplicações específicas.
🌍 Áreas de aplicação do BERT
O BERT provou ser extremamente útil em diversas áreas do processamento de linguagem natural:
Otimização de mecanismos de pesquisa
O Google usa o BERT para entender melhor as consultas de pesquisa e mostrar resultados mais relevantes. Isso melhora muito a experiência do usuário.
Classificação de texto
O BERT pode categorizar documentos por tópico ou analisar o clima dos textos.
Reconhecimento de Entidade Nomeada (NER)
O modelo identifica e classifica entidades nomeadas em textos, como nomes de pessoas, locais ou organizações.
Sistemas de perguntas e respostas
O BERT é usado para fornecer respostas precisas às perguntas feitas.
🧠 A importância do BERT para o futuro da IA
O BERT estabeleceu novos padrões para modelos de PNL e abriu caminho para novas inovações. Através da sua capacidade de processamento bidirecional e compreensão profunda do contexto da linguagem, aumentou significativamente a eficiência e a precisão das aplicações de IA.
🔜 Desenvolvimentos futuros
O desenvolvimento adicional do BERT e de modelos semelhantes provavelmente terá como objetivo criar sistemas ainda mais poderosos. Eles poderiam lidar com tarefas linguísticas mais complexas e ser usados em uma variedade de novas áreas de aplicação. A integração de tais modelos nas tecnologias cotidianas poderia mudar fundamentalmente a forma como interagimos com os computadores.
🌟 Marco no desenvolvimento da inteligência artificial
O BERT é um marco no desenvolvimento da inteligência artificial e revolucionou a forma como as máquinas processam a linguagem natural. Sua arquitetura bidirecional permite uma compreensão mais profunda das relações linguísticas, tornando-a indispensável para diversas aplicações. À medida que a investigação avança, modelos como o BERT continuarão a desempenhar um papel central na melhoria dos sistemas de IA e na abertura de novas possibilidades para a sua utilização.
📣 Tópicos semelhantes
- 📚 Apresentando BERT: o modelo inovador de PNL
- 🔍 BERT e o papel da bidirecionalidade na PNL
- 🧠 O modelo Transformer: pedra angular do BERT
- 🚀 Modelagem de linguagem mascarada: a chave para o sucesso do BERT
- 📈 Personalização do BERT: Do pré-treinamento ao ajuste fino
- 🌐 As áreas de aplicação do BERT na tecnologia moderna
- 🤖 A influência do BERT no futuro da inteligência artificial
- 💡 Perspectivas futuras: Novos desenvolvimentos do BERT
- 🏆 BERT como um marco no desenvolvimento de IA
- 📰 Autores do artigo do Transformer “Attention Is All You Need”: As mentes por trás do BERT
#️⃣ Hashtags: #PNL #InteligênciaArtificial #Modelagem de Linguagem #Transformador #MachineLearning
🎯🎯🎯 Beneficie-se da extensa e quíntupla experiência do Xpert.Digital em um pacote de serviços abrangente | P&D, XR, RP e SEM

Máquina de renderização 3D AI e XR: experiência quíntupla da Xpert.Digital em um pacote de serviços abrangente, R&D XR, PR e SEM - Imagem: Xpert.Digital
A Xpert.Digital possui conhecimento profundo de diversos setores. Isso nos permite desenvolver estratégias sob medida, adaptadas precisamente às necessidades e desafios do seu segmento de mercado específico. Ao analisar continuamente as tendências do mercado e acompanhar os desenvolvimentos da indústria, podemos agir com visão e oferecer soluções inovadoras. Através da combinação de experiência e conhecimento, geramos valor acrescentado e damos aos nossos clientes uma vantagem competitiva decisiva.
Mais sobre isso aqui:
BERT: Tecnologia revolucionária 🌟 de PNL
🚀 BERT, abreviação de Representações de codificador bidirecional de transformadores, é um modelo de linguagem avançado desenvolvido pelo Google que se tornou um avanço significativo no campo de Processamento de Linguagem Natural (PNL) desde seu lançamento em 2018. É baseado na arquitetura Transformer, que revolucionou a forma como as máquinas entendem e processam texto. Mas o que exatamente torna o BERT tão especial e para que ele é usado exatamente? Para responder a esta pergunta, precisamos nos aprofundar nos princípios técnicos, funcionalidades e áreas de aplicação do BERT.
📚 1. Noções básicas de processamento de linguagem natural
Para compreender totalmente o significado do BERT, é útil revisar brevemente os fundamentos do processamento de linguagem natural (PNL). A PNL trata da interação entre computadores e a linguagem humana. O objetivo é ensinar máquinas a analisar, compreender e responder a dados de texto. Antes da introdução de modelos como o BERT, o processamento automático da linguagem apresentava frequentemente desafios significativos, especialmente devido à ambiguidade, à dependência do contexto e à estrutura complexa da linguagem humana.
📈 2. O desenvolvimento de modelos de PNL
Antes do BERT entrar em cena, a maioria dos modelos de PNL eram baseados nas chamadas arquiteturas unidirecionais. Isso significa que esses modelos leem o texto apenas da esquerda para a direita ou da direita para a esquerda, o que significa que eles só podem levar em consideração uma quantidade limitada de contexto ao processar uma palavra em uma frase. Esta limitação muitas vezes resultava em que os modelos não capturassem totalmente o contexto semântico completo de uma frase. Isso dificultou a interpretação precisa de palavras ambíguas ou sensíveis ao contexto.
Outro desenvolvimento importante na pesquisa em PNL antes do BERT foi o modelo word2vec, que permitia aos computadores traduzir palavras em vetores que refletissem semelhanças semânticas. Mas também aqui o contexto estava limitado ao entorno imediato de uma palavra. Posteriormente, foram desenvolvidas Redes Neurais Recorrentes (RNNs) e, em particular, modelos de Long Short-Term Memory (LSTM), que permitiram compreender melhor as sequências de texto, armazenando informações em múltiplas palavras. No entanto, esses modelos também tinham suas limitações, principalmente ao lidar com textos longos e compreender o contexto em ambas as direções ao mesmo tempo.
🔄 3. A revolução através da arquitetura Transformer
O avanço veio com a introdução da arquitetura Transformer em 2017, que constitui a base do BERT. Os modelos de transformador são projetados para permitir o processamento paralelo de texto, levando em consideração o contexto de uma palavra do texto anterior e subsequente. Isso é feito por meio dos chamados mecanismos de autoatenção, que atribuem um valor de peso a cada palavra de uma frase com base na importância dela em relação às demais palavras da frase.
Em contraste com as abordagens anteriores, os modelos Transformer não são unidirecionais, mas bidirecionais. Isso significa que eles podem extrair informações do contexto esquerdo e direito de uma palavra, produzindo uma representação mais completa e precisa da palavra e de seu significado.
🧠 4. BERT: Um modelo bidirecional
O BERT leva o desempenho da arquitetura Transformer a um novo nível. O modelo foi projetado para capturar o contexto de uma palavra não apenas da esquerda para a direita ou da direita para a esquerda, mas em ambas as direções simultaneamente. Isso permite que o BERT considere o contexto completo de uma palavra dentro de uma frase, resultando em uma precisão significativamente melhorada nas tarefas de processamento de linguagem.
Uma característica central do BERT é o uso do chamado Masked Language Model (MLM). No treinamento do BERT, palavras selecionadas aleatoriamente em uma frase são substituídas por uma máscara e o modelo é treinado para adivinhar essas palavras mascaradas com base no contexto. Esta técnica permite que o BERT aprenda relações mais profundas e precisas entre as palavras de uma frase.
Além disso, o BERT utiliza um método denominado Next Sentence Prediction (NSP), onde o modelo aprende a prever se uma frase segue a outra ou não. Isto melhora a capacidade do BERT de compreender textos mais longos e reconhecer relações mais complexas entre frases.
🌐 5. Aplicação do BERT na prática
O BERT provou ser extremamente útil para uma variedade de tarefas de PNL. Aqui estão algumas das principais áreas de aplicação:
📊 a) Classificação do texto
Um dos usos mais comuns do BERT é a classificação de textos, onde os textos são divididos em categorias predefinidas. Exemplos disso incluem a análise de sentimento (por exemplo, reconhecer se um texto é positivo ou negativo) ou a categorização do feedback do cliente. O BERT pode fornecer resultados mais precisos do que os modelos anteriores através da sua profunda compreensão do contexto das palavras.
❓ b) Sistemas de perguntas e respostas
O BERT também é utilizado em sistemas de perguntas e respostas, onde o modelo extrai respostas às questões colocadas de um texto. Esta capacidade é particularmente importante em aplicações como motores de busca, chatbots ou assistentes virtuais. Graças à sua arquitetura bidirecional, o BERT pode extrair informações relevantes de um texto, mesmo que a questão seja formulada indiretamente.
🌍 c) Tradução de texto
Embora o BERT em si não seja diretamente concebido como um modelo de tradução, ele pode ser usado em combinação com outras tecnologias para melhorar a tradução automática. Ao compreender melhor as relações semânticas numa frase, o BERT pode ajudar a gerar traduções mais precisas, especialmente para formulações ambíguas ou complexas.
🏷️ d) Reconhecimento de Entidade Nomeada (NER)
Outra área de aplicação é o Named Entity Recognition (NER), que envolve a identificação de entidades específicas como nomes, lugares ou organizações em um texto. O BERT revelou-se particularmente eficaz nesta tarefa porque tem plenamente em conta o contexto de uma frase, tornando-o melhor no reconhecimento de entidades, mesmo que tenham significados diferentes em contextos diferentes.
✂️ e) Resumo do texto
A capacidade do BERT de compreender todo o contexto de um texto também o torna uma ferramenta poderosa para resumo automático de texto. Pode ser usado para extrair as informações mais importantes de um texto longo e criar um resumo conciso.
🌟 6. A importância do BERT para a pesquisa e a indústria
A introdução do BERT inaugurou uma nova era na pesquisa em PNL. Foi um dos primeiros modelos a aproveitar ao máximo o poder da arquitetura do Transformer bidirecional, estabelecendo o padrão para muitos modelos subsequentes. Muitas empresas e institutos de pesquisa integraram o BERT em seus pipelines de PNL para melhorar o desempenho de suas aplicações.
Além disso, o BERT abriu caminho para novas inovações na área de modelos de linguagem. Por exemplo, modelos como GPT (Generative Pretrained Transformer) e T5 (Text-to-Text Transfer Transformer) foram posteriormente desenvolvidos, que se baseiam em princípios semelhantes, mas oferecem melhorias específicas para diferentes casos de uso.
🚧 7. Desafios e limitações do BERT
Apesar das suas muitas vantagens, o BERT também apresenta alguns desafios e limitações. Um dos maiores obstáculos é o alto esforço computacional necessário para treinar e aplicar o modelo. Como o BERT é um modelo muito grande, com milhões de parâmetros, ele requer hardware poderoso e recursos computacionais significativos, especialmente ao processar grandes quantidades de dados.
Outra questão é o viés potencial que pode existir nos dados de treinamento. Como o BERT é treinado em grandes quantidades de dados de texto, às vezes reflete os preconceitos e estereótipos presentes nesses dados. No entanto, os pesquisadores estão trabalhando continuamente para identificar e resolver esses problemas.
🔍 Ferramenta essencial para aplicativos modernos de processamento de linguagem
O BERT melhorou significativamente a forma como as máquinas entendem a linguagem humana. Com sua arquitetura bidirecional e métodos de treinamento inovadores, ele é capaz de capturar com profundidade e precisão o contexto das palavras em uma frase, resultando em maior precisão em muitas tarefas de PNL. Seja na classificação de textos, sistemas de perguntas e respostas ou reconhecimento de entidades – o BERT estabeleceu-se como uma ferramenta indispensável para aplicações modernas de processamento de linguagem.
A investigação em processamento de linguagem natural continuará, sem dúvida, a avançar e o BERT lançou as bases para muitas inovações futuras. Apesar dos desafios e limitações existentes, o BERT mostra de forma impressionante o quão longe a tecnologia avançou num curto espaço de tempo e que oportunidades interessantes ainda se abrirão no futuro.
🌀 O transformador: uma revolução no processamento de linguagem natural
🌟 Nos últimos anos, um dos desenvolvimentos mais significativos no campo do Processamento de Linguagem Natural (PNL) foi a introdução do modelo Transformer, conforme descrito no artigo de 2017 “Atenção é tudo que você precisa”. Este modelo mudou fundamentalmente o campo ao descartar as estruturas recorrentes ou convolucionais usadas anteriormente para tarefas de transdução de sequência, como tradução automática. Em vez disso, depende exclusivamente de mecanismos de atenção. Desde então, o design do Transformer serviu de base para muitos modelos que representam o que há de mais moderno em diversas áreas, como geração de idiomas, tradução e muito mais.
🔄 O Transformador: Uma mudança de paradigma
Antes da introdução do Transformer, a maioria dos modelos para tarefas de sequenciamento eram baseados em redes neurais recorrentes (RNNs) ou redes de memória de longo e curto prazo (LSTMs), que são inerentemente sequenciais. Esses modelos processam os dados de entrada passo a passo, criando estados ocultos que são propagados ao longo da sequência. Embora este método seja eficaz, é computacionalmente caro e difícil de paralelizar, especialmente para sequências longas. Além disso, os RNNs têm dificuldade em aprender dependências de longo prazo devido ao chamado problema do “gradiente de desaparecimento”.
A inovação central do Transformer reside na utilização de mecanismos de autoatenção, que permitem ao modelo ponderar a importância das diferentes palavras numa frase umas em relação às outras, independentemente da sua posição. Isso permite que o modelo capture relações entre palavras amplamente espaçadas de forma mais eficaz do que RNNs ou LSTMs, e faça isso de maneira paralela, em vez de sequencialmente. Isto não só melhora a eficiência do treinamento, mas também o desempenho em tarefas como a tradução automática.
🧩 Arquitetura modelo
O Transformer consiste em dois componentes principais: um codificador e um decodificador, ambos compostos por múltiplas camadas e dependem fortemente de mecanismos de atenção com múltiplas cabeças.
⚙️ Codificador
O codificador consiste em seis camadas idênticas, cada uma com duas subcamadas:
1. Autoatenção com múltiplas cabeças
Este mecanismo permite que o modelo se concentre em diferentes partes da frase de entrada à medida que processa cada palavra. Em vez de computar a atenção em um único espaço, a atenção multicabeças projeta a entrada em vários espaços diferentes, permitindo que diferentes tipos de relações entre palavras sejam capturadas.
2. Redes feedforward totalmente conectadas em termos de posição
Após a camada de atenção, uma rede feedforward totalmente conectada é aplicada independentemente em cada posição. Isso ajuda o modelo a processar cada palavra no contexto e a utilizar as informações do mecanismo de atenção.
Para preservar a estrutura da sequência de entrada, o modelo também contém entradas posicionais (codificações posicionais). Como o Transformer não processa as palavras sequencialmente, essas codificações são cruciais para fornecer ao modelo informações sobre a ordem das palavras em uma frase. As entradas de posição são adicionadas aos embeddings de palavras para que o modelo possa distinguir entre as diferentes posições na sequência.
🔍 Decodificadores
Assim como o codificador, o decodificador também consiste em seis camadas, com cada camada possuindo um mecanismo de atenção adicional que permite ao modelo focar em partes relevantes da sequência de entrada enquanto gera a saída. O decodificador também utiliza uma técnica de mascaramento para evitar que considere posições futuras, preservando a natureza autoregressiva da geração de sequência.
🧠 Atenção multicabeças e atenção ao produto escalar
O coração do Transformer é o mecanismo Multi-Head Attention, que é uma extensão da atenção de produto escalar mais simples. A função de atenção pode ser vista como um mapeamento entre uma consulta e um conjunto de pares chave-valor (chaves e valores), onde cada chave representa uma palavra na sequência e o valor representa a informação contextual associada.
O mecanismo de atenção multicabeças permite que o modelo foque em diferentes partes da sequência ao mesmo tempo. Ao projetar a entrada em múltiplos subespaços, o modelo pode capturar um conjunto mais rico de relações entre palavras. Isto é particularmente útil em tarefas como tradução automática, onde a compreensão do contexto de uma palavra requer muitos fatores diferentes, como estrutura sintática e significado semântico.
A fórmula para atenção ao produto escalar é:

Aqui (Q) é a matriz de consulta, (K) é a matriz chave e (V) é a matriz de valor. O termo (sqrt{d_k}) é um fator de escala que evita que os produtos escalares se tornem muito grandes, o que levaria a gradientes muito pequenos e a um aprendizado mais lento. A função softmax é aplicada para garantir que os pesos de atenção somam um.
🚀 Vantagens do Transformador
O Transformer oferece várias vantagens importantes em relação aos modelos tradicionais, como RNNs e LSTMs:
1. Paralelização
Como o Transformer processa todos os tokens em uma sequência ao mesmo tempo, ele pode ser altamente paralelizado e, portanto, é muito mais rápido de treinar do que RNNs ou LSTMs, especialmente em grandes conjuntos de dados.
2. Dependências de longo prazo
O mecanismo de autoatenção permite que o modelo capture relações entre palavras distantes de forma mais eficaz do que os RNNs, que são limitados pela natureza sequencial de seus cálculos.
3. Escalabilidade
O Transformer pode ser facilmente dimensionado para conjuntos de dados muito grandes e sequências mais longas sem sofrer com os gargalos de desempenho associados aos RNNs.
🌍 Aplicações e efeitos
Desde a sua introdução, o Transformer tornou-se a base para uma ampla gama de modelos de PNL. Um dos exemplos mais notáveis é o BERT (Representações de codificador bidirecional de transformadores), que usa uma arquitetura de transformador modificada para alcançar o que há de mais moderno em muitas tarefas de PNL, incluindo resposta a perguntas e classificação de texto.
Outro desenvolvimento significativo é o GPT (Generative Pretrained Transformer), que usa uma versão limitada por decodificador do Transformer para geração de texto. Os modelos GPT, incluindo o GPT-3, são agora usados para uma variedade de aplicações, desde a criação de conteúdo até a conclusão de código.
🔍 Um modelo poderoso e flexível
O Transformer mudou fundamentalmente a forma como abordamos as tarefas da PNL. Ele fornece um modelo poderoso e flexível que pode ser aplicado a uma variedade de problemas. Sua capacidade de lidar com dependências de longo prazo e eficiência de treinamento tornaram-no a abordagem arquitetônica preferida para muitos dos modelos mais modernos. À medida que a investigação avança, provavelmente veremos mais melhorias e ajustes no Transformer, particularmente em áreas como o processamento de imagens e linguagem, onde os mecanismos de atenção mostram resultados promissores.
Estamos à sua disposição - aconselhamento - planejamento - implementação - gerenciamento de projetos
☑️ Especialista do setor, aqui com seu próprio centro industrial Xpert.Digital com mais de 2.500 artigos especializados

Konrad Wolfenstein
Ficarei feliz em servir como seu conselheiro pessoal.
Você pode entrar em contato comigo preenchendo o formulário de contato abaixo ou simplesmente ligando para +49 89 89 674 804 (Munique) .
Estou ansioso pelo nosso projeto conjunto.
Escreva para mim

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital é um hub para a indústria com foco em digitalização, engenharia mecânica, logística/intralogística e energia fotovoltaica.
Com nossa solução de desenvolvimento de negócios 360°, apoiamos empresas conhecidas, desde novos negócios até o pós-venda.
Inteligência de mercado, smarketing, automação de marketing, desenvolvimento de conteúdo, PR, campanhas por email, mídias sociais personalizadas e nutrição de leads fazem parte de nossas ferramentas digitais.
Você pode descobrir mais em: www.xpert.digital - www.xpert.solar - www.xpert.plus
Mantenha contato




















