
Uma tentativa de explicar a IA: como funciona e funciona a inteligência artificial – como é treinada?

Seleção de voz 📢
Publicado em: 8 de setembro de 2024 / atualização de: 9 de setembro de 2024 - Autor: Konrad Wolfenstein

Uma tentativa de explicar a IA: como funciona a inteligência artificial e como é treinada? – Imagem: Xpert.Digital
📊 Da entrada de dados à previsão do modelo: O processo de IA
Como funciona a inteligência artificial (IA)? 🤖
O funcionamento da inteligência artificial (IA) pode ser dividido em várias etapas claramente definidas. Cada uma dessas etapas é crítica para o resultado final que a IA oferece. O processo começa com a entrada de dados e termina com a previsão do modelo e possível feedback ou rodadas de treinamento adicionais. Essas fases descrevem o processo pelo qual passam quase todos os modelos de IA, independentemente de serem simples conjuntos de regras ou redes neurais altamente complexas.
1. A entrada de dados 📊
A base de toda inteligência artificial são os dados com os quais ela trabalha. Esses dados podem estar em vários formatos, por exemplo, imagens, texto, arquivos de áudio ou vídeos. A IA usa esses dados brutos para reconhecer padrões e tomar decisões. A qualidade e a quantidade dos dados desempenham um papel central aqui, porque têm uma influência significativa sobre quão bem ou mal o modelo funciona posteriormente.
Quanto mais extensos e precisos forem os dados, melhor a IA poderá aprender. Por exemplo, quando uma IA é treinada para processamento de imagens, é necessária uma grande quantidade de dados de imagem para identificar corretamente diferentes objetos. Com os modelos de linguagem, são os dados de texto que ajudam a IA a compreender e gerar a linguagem humana. A entrada de dados é a primeira e uma das etapas mais importantes, pois a qualidade das previsões só pode ser tão boa quanto a dos dados subjacentes. Um famoso princípio da ciência da computação descreve isso com o ditado “Entra lixo, sai lixo” – dados ruins levam a resultados ruins.
2. Pré-processamento de dados 🧹
Depois que os dados forem inseridos, eles precisam ser preparados antes de serem inseridos no modelo real. Este processo é chamado de pré-processamento de dados. O objetivo aqui é colocar os dados em um formato que possa ser processado de maneira otimizada pelo modelo.
Uma etapa comum no pré-processamento é a normalização de dados. Isso significa que os dados são colocados em um intervalo uniforme de valores para que o modelo os trate de maneira uniforme. Um exemplo seria dimensionar todos os valores de pixel de uma imagem para um intervalo de 0 a 1 em vez de 0 a 255.
Outra parte importante do pré-processamento é a chamada extração de características. Certos recursos são extraídos dos dados brutos que são particularmente relevantes para o modelo. No processamento de imagens, por exemplo, podem ser bordas ou certos padrões de cores, enquanto em textos são extraídas palavras-chave ou estruturas de frases relevantes. O pré-processamento é crucial para tornar o processo de aprendizagem da IA mais eficiente e preciso.
3. O modelo 🧩
O modelo é o coração de toda inteligência artificial. Aqui os dados são analisados e processados com base em algoritmos e cálculos matemáticos. Um modelo pode existir em diferentes formas. Um dos modelos mais conhecidos é a rede neural, que se baseia no funcionamento do cérebro humano.
As redes neurais consistem em várias camadas de neurônios artificiais que processam e transmitem informações. Cada camada pega as saídas da camada anterior e as processa posteriormente. O processo de aprendizagem de uma rede neural consiste em ajustar os pesos das conexões entre esses neurônios para que a rede possa fazer previsões ou classificações cada vez mais precisas. Essa adaptação ocorre por meio de treinamento, no qual a rede acessa grandes quantidades de dados amostrais e melhora iterativamente seus parâmetros internos (pesos).
Além das redes neurais, também existem muitos outros algoritmos usados em modelos de IA. Estes incluem árvores de decisão, florestas aleatórias, máquinas de vetores de suporte e muitos outros. Qual algoritmo é usado depende da tarefa específica e dos dados disponíveis.
4. A previsão do modelo 🔍
Depois que o modelo é treinado com dados, ele é capaz de fazer previsões. Esta etapa é chamada de previsão do modelo. A IA recebe uma entrada e retorna uma saída, ou seja, uma previsão ou decisão, com base nos padrões que aprendeu até agora.
Esta previsão pode assumir diferentes formas. Por exemplo, num modelo de classificação de imagens, a IA poderia prever qual objeto é visível em uma imagem. Num modelo de linguagem, poderia fazer uma previsão sobre qual palavra vem a seguir numa frase. Nas previsões financeiras, a IA poderia prever o desempenho do mercado de ações.
É importante ressaltar que a precisão das previsões depende muito da qualidade dos dados de treinamento e da arquitetura do modelo. Um modelo treinado com dados insuficientes ou tendenciosos provavelmente fará previsões incorretas.
5. Feedback e treinamento (opcional) ♻️
Outra parte importante do trabalho de uma IA é o mecanismo de feedback. O modelo é verificado regularmente e otimizado ainda mais. Este processo ocorre durante o treinamento ou após a previsão do modelo.
Se o modelo fizer previsões incorretas, ele poderá aprender por meio de feedback a detectar esses erros e ajustar seus parâmetros internos de acordo. Isto é feito comparando as previsões do modelo com os resultados reais (por exemplo, com dados conhecidos para os quais já existem respostas corretas). Um procedimento típico neste contexto é o chamado aprendizado supervisionado, no qual a IA aprende a partir de dados de exemplo que já são fornecidos com as respostas corretas.
Um método comum de feedback é o algoritmo de retropropagação usado em redes neurais. Os erros cometidos pelo modelo são propagados para trás pela rede para ajustar os pesos das conexões dos neurônios. O modelo aprende com seus erros e se torna cada vez mais preciso em suas previsões.
O papel do treinamento 🏋️♂️
Treinar uma IA é um processo iterativo. Quanto mais dados o modelo vê e quanto mais frequentemente ele é treinado com base nesses dados, mais precisas se tornam suas previsões. No entanto, também existem limites: um modelo excessivamente treinado pode ter os chamados problemas de “overfitting”. Isso significa que ele memoriza tão bem os dados de treinamento que produz resultados piores em dados novos e desconhecidos. Portanto, é importante treinar o modelo para que ele generalize e faça boas previsões mesmo com dados novos.
Além do treinamento regular, também existem procedimentos como a aprendizagem por transferência. Aqui, um modelo que já foi treinado em uma grande quantidade de dados é usado para uma tarefa nova e semelhante. Isso economiza tempo e poder de computação porque o modelo não precisa ser treinado do zero.
Aproveite ao máximo seus pontos fortes 🚀
O trabalho de uma inteligência artificial baseia-se numa interação complexa de várias etapas. Desde a entrada de dados, pré-processamento, treinamento de modelo, previsão e feedback, há muitos fatores que influenciam a precisão e a eficiência da IA. Uma IA bem treinada pode proporcionar enormes benefícios em muitas áreas da vida – desde a automatização de tarefas simples até a resolução de problemas complexos. Mas é igualmente importante compreender as limitações e potenciais armadilhas da IA, a fim de aproveitar ao máximo os seus pontos fortes.
🤖📚 Explicado de forma simples: como uma IA é treinada?
🤖📊 Processo de aprendizagem de IA: capturar, vincular e salvar
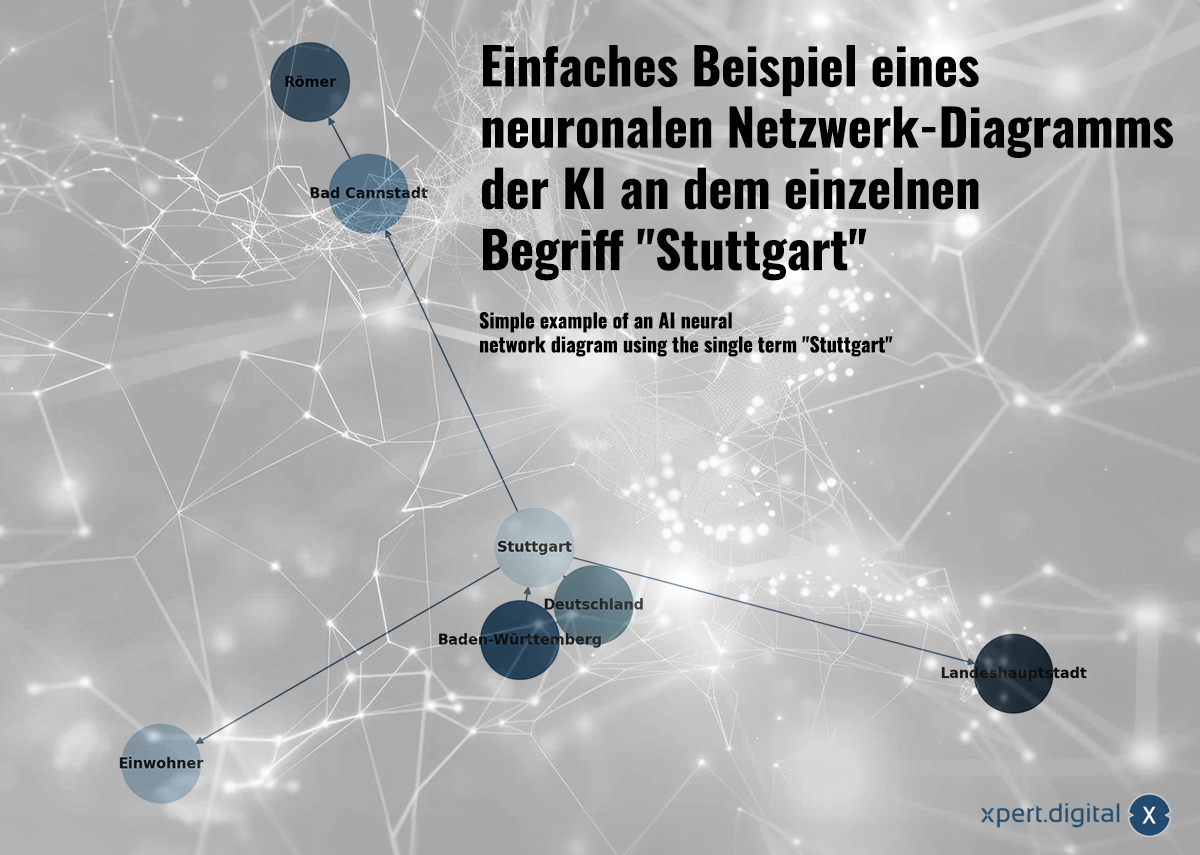
Exemplo simples de um diagrama de rede neuronal da IA no termo individual “Stuttgart” -image: xpert.digital
🌟 Colete e prepare dados
A primeira etapa do processo de aprendizagem de IA é coletar e preparar os dados. Esses dados podem vir de diversas fontes, como bancos de dados, sensores, textos ou imagens.
🌟 Relacionando dados (Rede Neural)
Os dados coletados estão relacionados entre si em uma rede neural. Cada pacote de dados é mostrado por conexões em uma rede de "neurônios" (nó). Um exemplo simples da cidade de Stuttgart poderia ficar assim:
a) Stuttgart é uma cidade em Baden-Württemberg
b) Baden-Württemberg é um estado federal na Alemanha
c) Stuttgart é uma cidade na Alemanha
d) Stuttgart tem uma população de 633.484 em 2023
e) Bad Cannstatt é um distrito de Stuttgart
f) Bad Cannstatt foi fundada pelos romanos
g) Stuttgart é a capital do estado de Baden-Württemberg
Dependendo do tamanho do volume de dados, os parâmetros para possíveis gastos são criados usando o modelo de IA utilizado. Por exemplo: o GPT-3 possui aproximadamente 175 bilhões de parâmetros!
🌟 Armazenamento e personalização (aprendizagem)
Os dados são alimentados na rede neural. Eles passam pelo modelo de IA e são processados por meio de conexões (semelhantes às sinapses). Os pesos (parâmetros) entre os neurônios são ajustados para treinar o modelo ou realizar uma tarefa.
Em contraste com os formulários de memória convencionais, como acesso direto, acesso indicado, armazenamento sequencial ou de pilha, as redes neurais armazenam os dados de maneira não convencional. Os "dados" são armazenados nos pesos e vieses das conexões entre os neurônios.
O "armazenamento" real das informações em uma rede neuronal ocorre, adaptando os pesos da conexão entre os neurônios. O modelo de IA “aprende” adaptando constantemente esses pesos e vieses com base nos dados de entrada e em um algoritmo de aprendizado definido. Este é um processo contínuo no qual o modelo pode fazer previsões precisas devido a ajustes recorrentes.
O modelo de IA pode ser considerado um tipo de programação porque é criado através de algoritmos definidos e cálculos matemáticos e melhora continuamente o ajuste de seus parâmetros (pesos) para fazer previsões precisas. Este é um processo contínuo.
Vieses são parâmetros adicionais em redes neurais que são adicionados aos valores de entrada ponderados de um neurônio. Eles permitem que os parâmetros sejam ponderados (importantes, menos importantes, importantes, etc.), tornando a IA mais flexível e precisa.
As redes neurais podem não apenas armazenar fatos individuais, mas também reconhecer conexões entre os dados através do reconhecimento de padrões. O exemplo de Estugarda ilustra como o conhecimento pode ser introduzido numa rede neural, mas as redes neurais não aprendem através do conhecimento explícito (como neste exemplo simples), mas através da análise de padrões de dados. As redes neurais podem não apenas armazenar fatos individuais, mas também aprender pesos e relacionamentos entre os dados de entrada.
Este fluxo fornece uma introdução compreensível sobre como a IA e as redes neurais funcionam em particular, sem se aprofundar muito em detalhes técnicos. Mostra que o armazenamento de informações em redes neurais não é feito como nos bancos de dados tradicionais, mas sim ajustando as conexões (pesos) dentro da rede.
🤖📚 Mais detalhado: Como uma IA é treinada?
🏋️♂️ O treinamento de uma IA, especialmente um modelo de aprendizado de máquina, ocorre em várias etapas. O treinamento de uma IA é baseado na otimização contínua dos parâmetros do modelo por meio de feedback e ajuste até que o modelo mostre o melhor desempenho nos dados fornecidos. Aqui está uma explicação detalhada de como esse processo funciona:
1. 📊 Colete e prepare dados
Os dados são a base do treinamento em IA. Eles normalmente consistem em milhares ou milhões de exemplos para o sistema analisar. Exemplos são imagens, textos ou dados de série temporal.
Os dados devem ser limpos e normalizados para evitar fontes desnecessárias de erros. Freqüentemente, os dados são convertidos em recursos que contêm informações relevantes.
2. 🔍 Definir modelo
Um modelo é uma função matemática que descreve os relacionamentos nos dados. Nas redes neurais, frequentemente usadas para IA, o modelo consiste em múltiplas camadas de neurônios conectados entre si.
Cada neurônio realiza uma operação matemática para processar os dados de entrada e então passa um sinal para o próximo neurônio.
3. 🔄 Inicializar pesos
As conexões entre os neurônios possuem pesos que são inicialmente definidos aleatoriamente. Esses pesos determinam a intensidade com que um neurônio responde a um sinal.
O objetivo do treinamento é ajustar esses pesos para que o modelo faça melhores previsões.
4. ➡️ Propagação direta
A passagem direta passa os dados de entrada através do modelo para produzir uma previsão.
Cada camada processa os dados e os passa para a próxima camada até que a última camada entregue o resultado.
5. ⚖️ Calcular função de perda
A função de perda mede a qualidade das previsões do modelo em comparação com os valores reais (os rótulos). Uma medida comum é o erro entre a resposta prevista e a real.
Quanto maior a perda, pior foi a previsão do modelo.
6. 🔙 Retropropagação
Na passagem para trás, o erro é realimentado da saída do modelo para as camadas anteriores.
O erro é redistribuído pelos pesos das ligações e o modelo ajusta os pesos para que os erros se tornem menores.
Isso é feito usando gradiente descendente: é calculado o vetor gradiente, que indica como os pesos devem ser alterados para minimizar o erro.
7. 🔧 Atualizar pesos
Após o cálculo do erro, os pesos das conexões são atualizados com um pequeno ajuste baseado na taxa de aprendizado.
A taxa de aprendizagem determina o quanto os pesos são alterados em cada etapa. Mudanças muito grandes podem tornar o modelo instável, e mudanças muito pequenas levam a um processo de aprendizagem lento.
8. 🔁 Repetir (Época)
Este processo de avanço, cálculo de erros e atualização de peso é repetido, muitas vezes ao longo de várias épocas (passagens por todo o conjunto de dados), até que o modelo atinja uma precisão aceitável.
A cada época, o modelo aprende um pouco mais e ajusta ainda mais seus pesos.
9. 📉 Validação e testes
Depois que o modelo é treinado, ele é testado em um conjunto de dados validado para verificar se ele é generalizado. Isso garante que ele não apenas “memorizou” os dados de treinamento, mas também faz boas previsões sobre dados desconhecidos.
Os dados de teste ajudam a medir o desempenho final do modelo antes de ele ser usado na prática.
10. 🚀 Otimização
Etapas adicionais para melhorar o modelo incluem ajuste de hiperparâmetros (por exemplo, ajuste da taxa de aprendizagem ou estrutura da rede), regularização (para evitar ajuste excessivo) ou aumento da quantidade de dados.
📊🔙 Inteligência artificial: torne a caixa preta da IA compreensível, compreensível e explicável com IA explicável (XAI), mapas de calor, modelos substitutos ou outras soluções

Inteligência artificial: Tornar a caixa preta da IA compreensível, compreensível e explicável com IA explicável (XAI), mapas de calor, modelos substitutos ou outras soluções - Imagem: Xpert.Digital
A chamada “caixa negra” da inteligência artificial (IA) representa um problema significativo e atual. Mesmo os especialistas enfrentam frequentemente o desafio de não serem capazes de compreender completamente como os sistemas de IA tomam as suas decisões. Esta falta de transparência pode causar problemas significativos, especialmente em áreas críticas como a economia, a política ou a medicina. Um médico ou profissional médico que depende de um sistema de IA para diagnosticar e recomendar terapia deve ter confiança nas decisões tomadas. No entanto, se a tomada de decisões de uma IA não for suficientemente transparente, surgem incertezas e potencialmente falta de confiança – em situações em que vidas humanas podem estar em risco.
Mais sobre isso aqui:
Estamos à sua disposição - aconselhamento - planejamento - implementação - gerenciamento de projetos
☑️ Apoio às PME em estratégia, consultoria, planeamento e implementação
☑️ Criação ou realinhamento da estratégia digital e digitalização
☑️ Expansão e otimização dos processos de vendas internacionais
☑️ Plataformas de negociação B2B globais e digitais
☑️ Desenvolvimento de negócios pioneiro

Konrad Wolfenstein
Ficarei feliz em servir como seu conselheiro pessoal.
Você pode entrar em contato comigo preenchendo o formulário de contato abaixo ou simplesmente ligando para +49 89 89 674 804 (Munique) .
Estou ansioso pelo nosso projeto conjunto.
Escreva para mim

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital é um hub para a indústria com foco em digitalização, engenharia mecânica, logística/intralogística e energia fotovoltaica.
Com nossa solução de desenvolvimento de negócios 360°, apoiamos empresas conhecidas, desde novos negócios até o pós-venda.
Inteligência de mercado, smarketing, automação de marketing, desenvolvimento de conteúdo, PR, campanhas por email, mídias sociais personalizadas e nutrição de leads fazem parte de nossas ferramentas digitais.
Você pode descobrir mais em: www.xpert.digital - www.xpert.solar - www.xpert.plus
Mantenha contato


















