
Próba wyjaśnienia AI: Jak działa i funkcjonuje sztuczna inteligencja – jak się ją szkoli?

Available in 27 languages 📢
Preferuj Xpert.Digital w GoogleⓘOpublikowano: 8 września 2024 / Aktualizacja z: 9 września 2024 - Autor: Konrad Wolfenstein

Próba wyjaśnienia AI: Jak działa sztuczna inteligencja i jak się ją szkoli? – Zdjęcie: Xpert.Digital
📊 Od wprowadzania danych do przewidywania modelu: proces AI
Jak działa sztuczna inteligencja (AI)? 🤖
Sposób działania sztucznej inteligencji (AI) można podzielić na kilka jasno określonych etapów. Każdy z tych kroków ma kluczowe znaczenie dla wyniku końcowego zapewnianego przez sztuczną inteligencję. Proces rozpoczyna się od wprowadzenia danych, a kończy na przewidywaniu modelu i ewentualnych informacjach zwrotnych lub dalszych rundach szkoleniowych. Fazy te opisują proces, przez który przechodzą prawie wszystkie modele sztucznej inteligencji, niezależnie od tego, czy są to proste zestawy reguł, czy bardzo złożone sieci neuronowe.
1. Wprowadzanie danych 📊
Podstawą wszelkiej sztucznej inteligencji są dane, z którymi współpracuje. Dane te mogą mieć różną formę, na przykład obrazy, tekst, pliki audio lub filmy. Sztuczna inteligencja wykorzystuje te surowe dane do rozpoznawania wzorców i podejmowania decyzji. Jakość i ilość danych odgrywają tutaj kluczową rolę, ponieważ mają one znaczący wpływ na to, jak dobrze lub źle model działa później.
Im bardziej rozbudowane i precyzyjne są dane, tym lepiej sztuczna inteligencja może się uczyć. Na przykład, gdy sztuczna inteligencja jest szkolona w zakresie przetwarzania obrazów, potrzebuje dużej ilości danych obrazu, aby poprawnie zidentyfikować różne obiekty. W przypadku modeli językowych to dane tekstowe pomagają sztucznej inteligencji rozumieć i generować ludzki język. Wprowadzanie danych to pierwszy i jeden z najważniejszych kroków, ponieważ jakość prognoz może być tak dobra, jak dane leżące u ich podstaw. Słynna zasada informatyki opisuje to powiedzeniem „Śmieci na wejściu, śmieci na zewnątrz” – złe dane prowadzą do złych wyników.
2. Wstępne przetwarzanie danych 🧹
Po wprowadzeniu danych należy je przygotować, zanim będzie można je wprowadzić do rzeczywistego modelu. Proces ten nazywany jest wstępnym przetwarzaniem danych. Celem jest tutaj umieszczenie danych w formie, która może być optymalnie przetworzona przez model.
Typowym krokiem w przetwarzaniu wstępnym jest normalizacja danych. Oznacza to, że dane zostają doprowadzone do jednolitego zakresu wartości, dzięki czemu model traktuje je równomiernie. Przykładem może być skalowanie wszystkich wartości pikseli obrazu do zakresu od 0 do 1 zamiast od 0 do 255.
Kolejną ważną częścią przetwarzania wstępnego jest tak zwana ekstrakcja cech. Z surowych danych wyodrębnia się pewne cechy, które są szczególnie istotne dla modelu. Na przykład podczas przetwarzania obrazu mogą to być krawędzie lub określone wzory kolorów, podczas gdy w przypadku tekstu wyodrębniane są odpowiednie słowa kluczowe lub struktury zdań. Przetwarzanie wstępne ma kluczowe znaczenie dla zwiększenia wydajności i precyzji procesu uczenia się sztucznej inteligencji.
3. Modelka 🧩
Model jest sercem każdej sztucznej inteligencji. Tutaj dane są analizowane i przetwarzane w oparciu o algorytmy i obliczenia matematyczne. Model może występować w różnych formach. Jednym z najbardziej znanych modeli jest sieć neuronowa, która opiera się na działaniu ludzkiego mózgu.
Sieci neuronowe składają się z kilku warstw sztucznych neuronów, które przetwarzają i przekazują informacje. Każda warstwa pobiera dane wyjściowe poprzedniej warstwy i przetwarza je dalej. Proces uczenia się sieci neuronowej polega na dostosowaniu wag połączeń między tymi neuronami, tak aby sieć mogła dokonywać coraz dokładniejszych przewidywań lub klasyfikacji. Dostosowanie to następuje poprzez uczenie, podczas którego sieć uzyskuje dostęp do dużej ilości przykładowych danych i iteracyjnie poprawia swoje wewnętrzne parametry (wagi).
Oprócz sieci neuronowych w modelach AI wykorzystuje się także wiele innych algorytmów. Należą do nich drzewa decyzyjne, lasy losowe, maszyny wektorów nośnych i wiele innych. Wybór algorytmu zależy od konkretnego zadania i dostępnych danych.
4. Predykcja modelu 🔍
Po przeszkoleniu modelu na danych można dokonywać prognoz. Ten etap nazywa się przewidywaniem modelu. Sztuczna inteligencja otrzymuje dane wejściowe i zwraca dane wyjściowe, czyli prognozę lub decyzję, na podstawie wyuczonych dotychczas wzorców.
Przewidywanie to może przybierać różne formy. Na przykład w modelu klasyfikacji obrazu sztuczna inteligencja może przewidzieć, który obiekt jest widoczny na obrazie. W modelu językowym mógłby przewidzieć, które słowo będzie następne w zdaniu. W prognozach finansowych sztuczna inteligencja może przewidzieć, jak zachowa się giełda.
Należy podkreślić, że dokładność przewidywań zależy w dużym stopniu od jakości danych szkoleniowych i architektury modelu. Model wyszkolony na niewystarczających lub stronniczych danych prawdopodobnie będzie dokonywał błędnych przewidywań.
5. Informacje zwrotne i szkolenie (opcjonalnie) ♻️
Kolejną ważną częścią pracy sztucznej inteligencji jest mechanizm sprzężenia zwrotnego. Model jest regularnie sprawdzany i dalej optymalizowany. Proces ten zachodzi albo podczas uczenia, albo po przewidywaniu modelu.
Jeśli model dokonuje błędnych przewidywań, może uczyć się na podstawie informacji zwrotnych, wykrywać te błędy i odpowiednio dostosowywać swoje parametry wewnętrzne. Odbywa się to poprzez porównanie przewidywań modelu z rzeczywistymi wynikami (np. ze znanymi danymi, dla których istnieją już prawidłowe odpowiedzi). Typową procedurą w tym kontekście jest tzw. uczenie nadzorowane, podczas którego sztuczna inteligencja uczy się na przykładowych danych, do których już dołączono prawidłowe odpowiedzi.
Powszechną metodą sprzężenia zwrotnego jest algorytm propagacji wstecznej stosowany w sieciach neuronowych. Błędy popełniane przez model są propagowane wstecz w sieci w celu dostosowania wag połączeń neuronowych. Model uczy się na swoich błędach i staje się coraz bardziej precyzyjny w swoich przewidywaniach.
Rola treningu 🏋️♂️
Szkolenie sztucznej inteligencji to proces iteracyjny. Im więcej danych widzi model i im częściej jest trenowany na ich podstawie, tym dokładniejsze stają się jego przewidywania. Istnieją jednak również ograniczenia: nadmiernie wytrenowany model może powodować tak zwane problemy z „przeuczeniem”. Oznacza to, że zapamiętuje dane treningowe tak dobrze, że daje gorsze wyniki na nowych, nieznanych danych. Dlatego ważne jest, aby wytrenować model tak, aby uogólniał i zapewniał dobre przewidywania nawet w przypadku nowych danych.
Oprócz regularnych szkoleń istnieją również procedury takie jak nauka transferowa. Tutaj model, który został już przeszkolony na dużej ilości danych, zostaje wykorzystany do nowego, podobnego zadania. Oszczędza to czas i moc obliczeniową, ponieważ modelu nie trzeba uczyć się od zera.
Wykorzystaj w pełni swoje mocne strony 🚀
Praca sztucznej inteligencji opiera się na złożonej interakcji różnych etapów. Od wprowadzania danych, wstępnego przetwarzania, uczenia modeli, przewidywania i informacji zwrotnych – istnieje wiele czynników wpływających na dokładność i wydajność sztucznej inteligencji. Dobrze wyszkolona sztuczna inteligencja może zapewnić ogromne korzyści w wielu obszarach życia – od automatyzacji prostych zadań po rozwiązywanie złożonych problemów. Jednak równie ważne jest zrozumienie ograniczeń i potencjalnych pułapek sztucznej inteligencji, aby w pełni wykorzystać jej mocne strony.
🤖📚 Po prostu wyjaśnione: w jaki sposób szkoli się sztuczną inteligencję?
🤖📊 Proces uczenia się AI: przechwytywanie, łączenie i zapisywanie
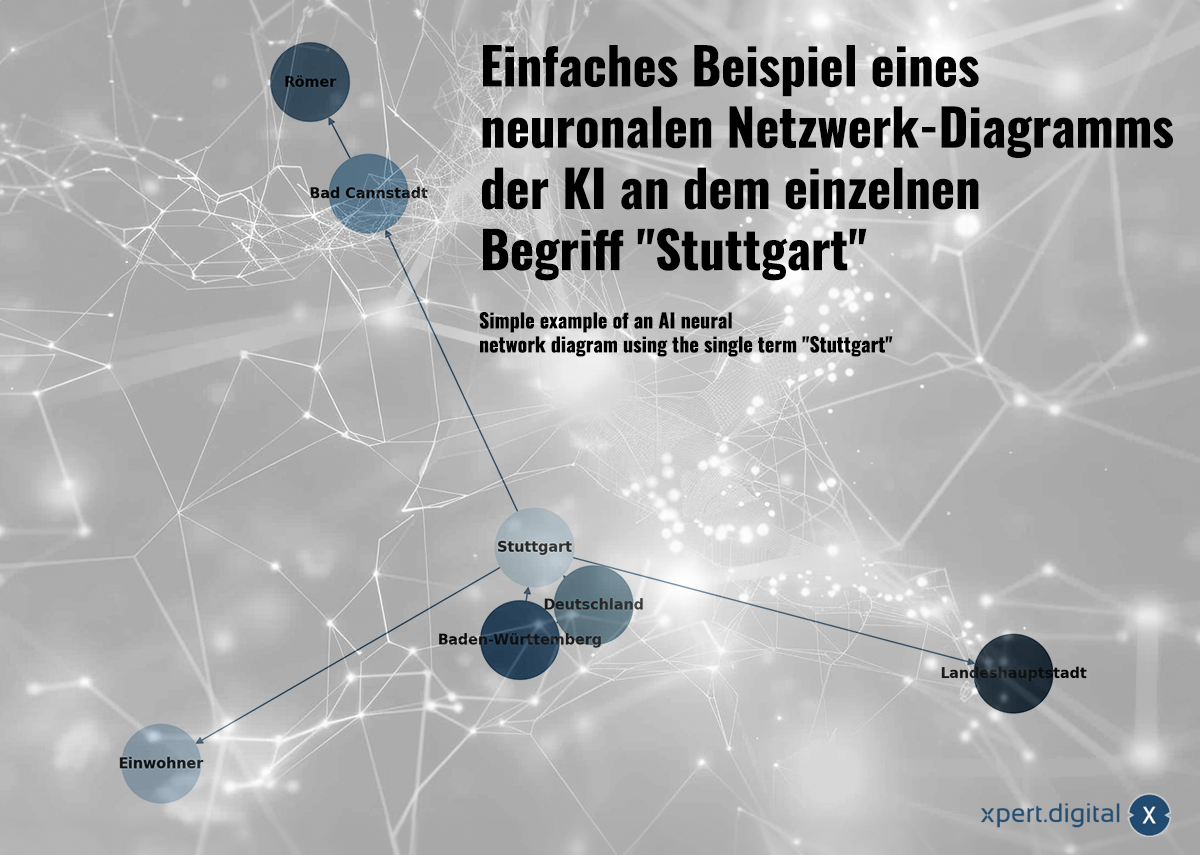
Prosty przykład schematu sieci neuronalnej AI na poszczególnych terminach „Stuttgart” -image: xpert.digital
🌟 Zbieraj i przygotowuj dane
Pierwszym krokiem w procesie uczenia się AI jest zebranie i przygotowanie danych. Dane te mogą pochodzić z różnych źródeł, takich jak bazy danych, czujniki, teksty lub obrazy.
🌟 Powiązanie danych (sieć neuronowa)
Zebrane dane są ze sobą powiązane w sieci neuronowej. Każdy pakiet danych jest pokazany przez połączenia w sieci „neuronów” (węzeł). Prosty przykład miasta Stuttgart może wyglądać tak:
a) Stuttgart to miasto w Badenii-Wirtembergii
b) Badenia-Wirtembergia to kraj związkowy w Niemczech
c) Stuttgart to miasto w Niemczech
d) Stuttgart liczy 633 484 mieszkańców w 2023 roku
e) Bad Cannstatt to dzielnica Stuttgartu
f) Bad Cannstatt zostało założone przez Rzymian
g) Stuttgart jest stolicą stanu Badenia-Wirtembergia
W zależności od wielkości wolumenu danych parametry potencjalnych wydatków tworzone są z wykorzystaniem zastosowanego modelu AI. Przykładowo: GPT-3 ma około 175 miliardów parametrów!
🌟 Przechowywanie i dostosowywanie (nauka)
Dane przesyłane są do sieci neuronowej. Przechodzą przez model AI i są przetwarzane poprzez połączenia (podobnie jak synapsy). Wagi (parametry) pomiędzy neuronami są dostosowywane w celu wytrenowania modelu lub wykonania zadania.
W przeciwieństwie do konwencjonalnych formularzy pamięci, takich jak bezpośredni dostęp, wskazany dostęp, magazyn sekwencyjny lub stosu, sieci neuronowe przechowują dane w niekonwencjonalny sposób. „Dane” są przechowywane w wagach i uprzedzeniach połączeń między neuronami.
Rzeczywiste „przechowywanie” informacji w sieci neuronalnej odbywa się poprzez dostosowanie wag połączeń między neuronami. Model AI „uczy się” poprzez stale dostosowywanie tych wag i uprzedzeń w oparciu o dane wejściowe i zdefiniowany algorytm uczenia się. Jest to ciągły proces, w którym model może dokonać precyzyjnych prognoz z powodu powtarzających się korekt.
Model AI można uznać za rodzaj programowania, ponieważ tworzony jest poprzez zdefiniowane algorytmy i obliczenia matematyczne oraz stale doskonali dostosowanie jego parametrów (wag) w celu uzyskania dokładnych przewidywań. Jest to proces ciągły.
Odchylenia to dodatkowe parametry w sieciach neuronowych, które są dodawane do ważonych wartości wejściowych neuronu. Umożliwiają ważenie parametrów (ważne, mniej ważne, ważne itp.), dzięki czemu sztuczna inteligencja jest bardziej elastyczna i dokładna.
Sieci neuronowe mogą nie tylko przechowywać pojedyncze fakty, ale także rozpoznawać powiązania między danymi poprzez rozpoznawanie wzorców. Przykład ze Stuttgartu ilustruje, jak wiedzę można wprowadzić do sieci neuronowej, jednak sieci neuronowe nie uczą się poprzez wiedzę jawną (jak w tym prostym przykładzie), ale poprzez analizę wzorców danych. Sieci neuronowe potrafią nie tylko przechowywać pojedyncze fakty, ale także uczyć się wag i zależności pomiędzy danymi wejściowymi.
Ten przepływ zapewnia zrozumiałe wprowadzenie do działania sztucznej inteligencji i sieci neuronowych, bez zbytniego zagłębiania się w szczegóły techniczne. Pokazuje, że przechowywanie informacji w sieciach neuronowych nie odbywa się jak w tradycyjnych bazach danych, ale poprzez dostosowanie połączeń (wag) w obrębie sieci.
🤖📚 Bardziej szczegółowo: W jaki sposób szkoli się sztuczną inteligencję?
🏋️♂️ Szkolenie sztucznej inteligencji, zwłaszcza modelu uczenia maszynowego, odbywa się w kilku etapach. Szkolenie sztucznej inteligencji opiera się na ciągłej optymalizacji parametrów modelu poprzez przesyłanie informacji zwrotnych i dostosowywanie, aż model wykaże najlepszą wydajność na podstawie dostarczonych danych. Poniżej znajduje się szczegółowe wyjaśnienie działania tego procesu:
1. 📊 Zbieraj i przygotowuj dane
Dane są podstawą szkolenia AI. Zwykle składają się z tysięcy lub milionów przykładów do analizy przez system. Przykładami są obrazy, teksty lub dane szeregów czasowych.
Dane należy oczyścić i znormalizować, aby uniknąć niepotrzebnych źródeł błędów. Często dane są konwertowane na funkcje zawierające odpowiednie informacje.
2. 🔍 Zdefiniuj model
Model to funkcja matematyczna opisująca zależności między danymi. W sieciach neuronowych, które są często wykorzystywane w sztucznej inteligencji, model składa się z wielu warstw połączonych ze sobą neuronów.
Każdy neuron wykonuje operację matematyczną w celu przetworzenia danych wejściowych, a następnie przekazuje sygnał do następnego neuronu.
3. 🔄 Zainicjuj ciężary
Połączenia między neuronami mają wagi, które są początkowo ustalane losowo. Wagi te określają, jak silnie neuron reaguje na sygnał.
Celem uczenia jest dostosowanie tych wag, tak aby model zapewniał lepsze przewidywania.
4. ➡️ Propagacja do przodu
Przebieg w przód przekazuje dane wejściowe przez model w celu uzyskania prognozy.
Każda warstwa przetwarza dane i przekazuje je kolejnej warstwie, aż ostatnia warstwa dostarczy wynik.
5. ⚖️ Oblicz funkcję straty
Funkcja straty mierzy, jak dobre są przewidywania modelu z wartościami rzeczywistymi (etykietami). Powszechną miarą jest błąd między przewidywaną a rzeczywistą odpowiedzią.
Im większa strata, tym gorsze przewidywania modelu.
6. 🔙 Propagacja wsteczna
W przebiegu wstecznym błąd jest przekazywany z danych wyjściowych modelu do poprzednich warstw.
Błąd rozkłada się na wagi połączeń, a model dostosowuje wagi tak, aby błędy stały się mniejsze.
Odbywa się to za pomocą opadania gradientowego: obliczany jest wektor gradientu, który wskazuje, jak należy zmieniać wagi, aby zminimalizować błąd.
7. 🔧 Zaktualizuj ciężary
Po obliczeniu błędu wagi połączeń są aktualizowane z niewielką korektą w oparciu o szybkość uczenia się.
Szybkość uczenia się określa, jak bardzo wagi zmieniają się w każdym kroku. Zmiany, które są zbyt duże, mogą spowodować, że model będzie niestabilny, a zmiany, które są zbyt małe, spowodują powolny proces uczenia się.
8. 🔁 Powtórzenie (Epoka)
Ten proces przekazywania w przód, obliczania błędów i aktualizacji wagi jest powtarzany, często w wielu epokach (przechodzi przez cały zestaw danych), aż model osiągnie akceptowalną dokładność.
Z każdą epoką model uczy się nieco więcej i dalej dostosowuje swoje wagi.
9. 📉 Walidacja i testowanie
Po wytrenowaniu modelu jest on testowany na zweryfikowanym zbiorze danych, aby sprawdzić, jak dobrze generalizuje. Dzięki temu nie tylko „zapamiętał” dane szkoleniowe, ale także dokonał dobrych przewidywań na podstawie nieznanych danych.
Dane testowe pomagają zmierzyć ostateczną wydajność modelu przed jego zastosowaniem w praktyce.
10. 🚀 Optymalizacja
Dodatkowe kroki mające na celu ulepszenie modelu obejmują dostrajanie hiperparametrów (np. Dostosowywanie szybkości uczenia się lub struktury sieci), regularyzację (aby uniknąć nadmiernego dopasowania) lub zwiększanie ilości danych.
📊🔙 Sztuczna inteligencja: spraw, aby czarna skrzynka sztucznej inteligencji była zrozumiała, zrozumiała i możliwa do wyjaśnienia dzięki wyjaśnionej sztucznej inteligencji (XAI), mapom cieplnym, modelom zastępczym lub innym rozwiązaniom

Sztuczna inteligencja: uczynienie czarnej skrzynki sztucznej inteligencji zrozumiałą, zrozumiałą i dającą się wyjaśnić za pomocą wyjaśnialnej sztucznej inteligencji (XAI), map cieplnych, modeli zastępczych lub innych rozwiązań - Zdjęcie: Xpert.Digital
Tak zwana „czarna skrzynka” sztucznej inteligencji (AI) stanowi istotny i aktualny problem. Nawet eksperci często stają przed wyzwaniem polegającym na tym, że nie są w stanie w pełni zrozumieć, w jaki sposób systemy AI podejmują decyzje. Ten brak przejrzystości może powodować poważne problemy, szczególnie w kluczowych obszarach, takich jak ekonomia, polityka czy medycyna. Lekarz lub specjalista medyczny, który stawia diagnozę i zaleca terapię w oparciu o system sztucznej inteligencji, musi mieć zaufanie do podjętych decyzji. Jeżeli jednak proces podejmowania decyzji przez sztuczną inteligencję nie jest wystarczająco przejrzysty, pojawia się niepewność i potencjalnie brak zaufania – w sytuacjach, gdy stawką może być życie ludzkie.
Więcej na ten temat tutaj:
Jesteśmy do Twojej dyspozycji - doradztwo - planowanie - realizacja - zarządzanie projektami
☑️ Wsparcie MŚP w zakresie strategii, doradztwa, planowania i wdrażania
☑️ Stworzenie lub dostosowanie strategii cyfrowej i cyfryzacji
☑️Rozbudowa i optymalizacja procesów sprzedaży międzynarodowej
☑️ Globalne i cyfrowe platformy handlowe B2B
☑️ Pionierski rozwój biznesu

Konrada Wolfensteina
Chętnie będę Twoim osobistym doradcą.
Możesz się ze mną skontaktować wypełniając poniższy formularz kontaktowy lub po prostu dzwoniąc pod numer +49 7348 4088 965 (Monachium) .
Nie mogę się doczekać naszego wspólnego projektu.
Napisz do mnie

Xpert.Digital – Konrad Wolfenstein
Xpert.Digital to centrum przemysłu skupiające się na cyfryzacji, inżynierii mechanicznej, logistyce/intralogistyce i fotowoltaice.
Dzięki naszemu rozwiązaniu do rozwoju biznesu 360° wspieramy znane firmy od rozpoczęcia nowej działalności po sprzedaż posprzedażną.
Wywiad rynkowy, smarketing, automatyzacja marketingu, tworzenie treści, PR, kampanie pocztowe, spersonalizowane media społecznościowe i pielęgnacja leadów to część naszych narzędzi cyfrowych.
Więcej informacji znajdziesz na: www.xpert.digital - www.xpert.solar - www.xpert.plus
Pozostajemy w kontakcie


















