


AI i SEO z BERT – Dwukierunkowe reprezentacje enkoderów od Transformers – Model w dziedzinie przetwarzania języka naturalnego (NLP) – Zdjęcie: Xpert.Digital
🚀💬 Opracowane przez Google: BERT i jego znaczenie dla NLP - Dlaczego dwukierunkowe zrozumienie tekstu jest kluczowe
🔍🗣️ BERT, skrót od Bilateral Encoder Representations from Transformers, to główny model w dziedzinie przetwarzania języka naturalnego (NLP) opracowany przez Google. Zrewolucjonizowało to sposób, w jaki maszyny rozumieją język. W przeciwieństwie do poprzednich modeli, które analizowały tekst sekwencyjnie od lewej do prawej i odwrotnie, BERT umożliwia przetwarzanie dwukierunkowe. Oznacza to, że przechwytuje kontekst słowa zarówno z poprzedzającej, jak i kolejnej sekwencji tekstowej. Umiejętność ta znacząco poprawia rozumienie złożonych kontekstów językowych.
🔍 Architektura BERT
W ostatnich latach jeden z najważniejszych osiągnięć w dziedzinie przetwarzania języka naturalnego (NLP) nastąpił wraz z wprowadzeniem modelu Transformer, co przedstawiono w pliku PDF 2017 - Uwaga to wszystko, czego potrzebujesz - papier ( Wikipedia ). Model ten zasadniczo zmienił dziedzinę, odrzucając wcześniej używane struktury, takie jak tłumaczenie maszynowe. Zamiast tego opiera się wyłącznie na mechanizmach uwagi. Od tego czasu konstrukcja Transformera stała się podstawą wielu modeli reprezentujących najnowocześniejszy stan wiedzy w różnych obszarach, takich jak generowanie języka, tłumaczenie i nie tylko.
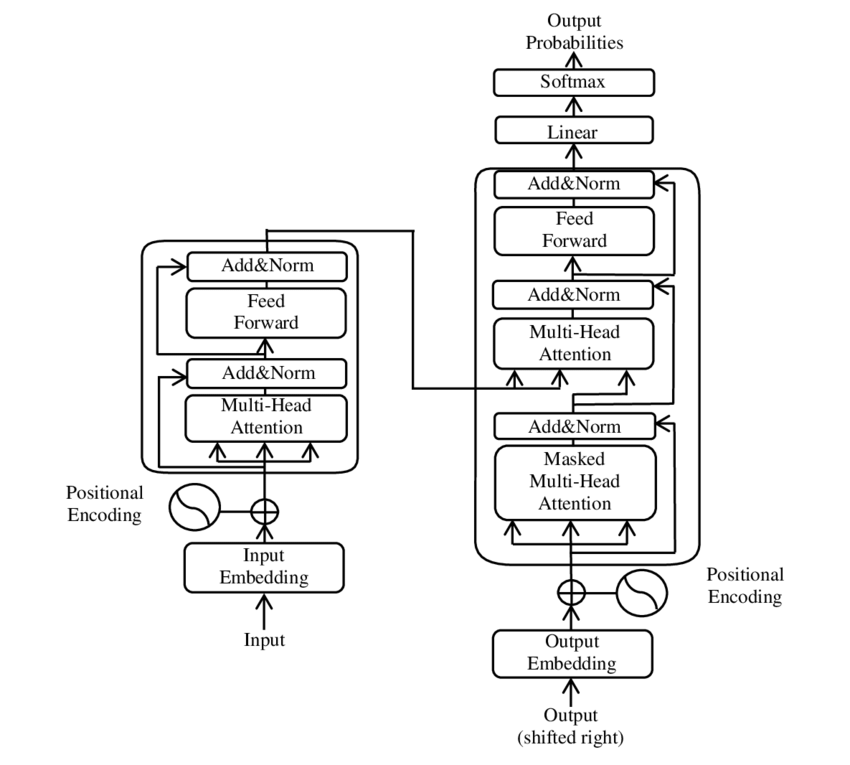
Ilustracja głównych podzespołów modelu Transformer – Zdjęcie: Google
BERT opiera się na architekturze Transformera. Architektura ta wykorzystuje tak zwane mechanizmy samouważności do analizy relacji między słowami w zdaniu. Zwrócono uwagę na każde słowo w kontekście całego zdania, co skutkuje dokładniejszym zrozumieniem zależności syntaktycznych i semantycznych.
Autorzy artykułu „Uwaga jest wszystkim, czego potrzebujesz” to:
- Ashish Vaswani (Mózg Google)
- Noam Shazeer (Mózg Google)
- Niki Parmar (badania Google)
- Jakob Uszkoreit (badania Google)
- Lion Jones (badania Google)
- Aidan N. Gomez (Uniwersytet w Toronto, praca częściowo wykonana w Google Brain)
- Łukasz Kaiser (mózg Google)
- Illia Polosukhin (niezależna, poprzednia praca w Google Research)
Autorzy ci wnieśli znaczący wkład w rozwój prezentowanego w artykule modelu Transformera.
🔄 Przetwarzanie dwukierunkowe
Wyróżniającą cechą BERT jest zdolność przetwarzania dwukierunkowego. Podczas gdy tradycyjne modele, takie jak rekurencyjne sieci neuronowe (RNN) lub sieci o długiej pamięci krótkotrwałej (LSTM), przetwarzają tekst tylko w jednym kierunku, BERT analizuje kontekst słowa w obu kierunkach. Dzięki temu model może lepiej uchwycić subtelne niuanse znaczenia, a tym samym dokonać dokładniejszych przewidywań.
🕵️♂️ Modelowanie języka zamaskowanego
Kolejnym innowacyjnym aspektem BERT jest technika Masked Language Model (MLM). Polega na maskowaniu losowo wybranych słów w zdaniu i trenowaniu modelu w celu przewidywania tych słów na podstawie otaczającego kontekstu. Metoda ta zmusza BERT do głębokiego zrozumienia kontekstu i znaczenia każdego słowa w zdaniu.
🚀 Szkolenia i personalizacja BERT
BERT przechodzi dwuetapowy proces szkoleniowy: szkolenie wstępne i dostrajanie.
📚 Trening przedtreningowy
Podczas szkolenia wstępnego BERT jest szkolony z dużą ilością tekstu, aby nauczyć się ogólnych wzorców językowych. Obejmuje to teksty Wikipedii i inne obszerne korpusy tekstowe. Na tym etapie model uczy się podstawowych struktur i kontekstów językowych.
🔧 Dostrajanie
Po wstępnym szkoleniu BERT jest dostosowywany do konkretnych zadań NLP, takich jak klasyfikacja tekstu lub analiza nastrojów. Model jest szkolony przy użyciu mniejszych, związanych z zadaniami zestawów danych, aby zoptymalizować jego wydajność dla określonych aplikacji.
🌍 Obszary zastosowania BERT
BERT okazał się niezwykle przydatny w wielu obszarach przetwarzania języka naturalnego:
Optymalizacja wyszukiwarek
Google korzysta z BERT, aby lepiej rozumieć wyszukiwane hasła i wyświetlać trafniejsze wyniki. To znacznie poprawia komfort użytkowania.
Klasyfikacja tekstu
BERT może kategoryzować dokumenty tematycznie lub analizować nastrój w tekstach.
Rozpoznawanie nazwanych podmiotów (NER)
Model identyfikuje i klasyfikuje nazwane podmioty w tekstach, takie jak nazwy osobowe, miejsca lub nazwy organizacji.
Systemy pytań i odpowiedzi
BERT służy do udzielania precyzyjnych odpowiedzi na zadawane pytania.
🧠 Znaczenie BERT dla przyszłości AI
BERT wyznaczył nowe standardy dla modeli NLP i utorował drogę dalszym innowacjom. Dzięki możliwościom dwukierunkowego przetwarzania i głębokiemu zrozumieniu kontekstu językowego znacznie zwiększył wydajność i dokładność aplikacji AI.
🔜 Przyszły rozwój
Dalszy rozwój BERT i podobnych modeli będzie prawdopodobnie miał na celu stworzenie jeszcze potężniejszych systemów. Mogą one obsługiwać bardziej złożone zadania językowe i być wykorzystywane w wielu nowych obszarach zastosowań. Włączenie takich modeli do codziennych technologii może zasadniczo zmienić sposób, w jaki współdziałamy z komputerami.
🌟Kamień milowy w rozwoju sztucznej inteligencji
BERT jest kamieniem milowym w rozwoju sztucznej inteligencji i zrewolucjonizował sposób, w jaki maszyny przetwarzają język naturalny. Jego dwukierunkowa architektura umożliwia głębsze zrozumienie relacji językowych, co czyni go niezbędnym do różnych zastosowań. W miarę postępu badań modele takie jak BERT będą nadal odgrywać kluczową rolę w ulepszaniu systemów sztucznej inteligencji i otwieraniu nowych możliwości ich wykorzystania.
📣 Podobne tematy
- 📚 Przedstawiamy BERT: przełomowy model NLP
- 🔍 BERT i rola dwukierunkowości w NLP
- 🧠 Model Transformer: kamień węgielny BERT
- 🚀 Modelowanie języka zamaskowanego: klucz do sukcesu BERT
- 📈 Personalizacja BERT: od treningu wstępnego po dostrojenie
- 🌐 Obszary zastosowania BERT w nowoczesnych technologiach
- 🤖Wpływ BERT-a na przyszłość sztucznej inteligencji
- 💡 Perspektywy na przyszłość: Dalszy rozwój BERT
- 🏆 BERT kamieniem milowym w rozwoju AI
- 📰 Autorzy artykułu o Transformatorze „Uwaga to wszystko, czego potrzebujesz”: umysły stojące za BERT
#️⃣ Hashtagi: #NLP #Sztuczna Inteligencja #Modelowanie Języka #Transformer #MachineLearning
🎯🎯🎯 Skorzystaj z bogatej, pięciokrotnej wiedzy eksperckiej Xpert.Digital w ramach kompleksowego pakietu usług | BD, R&D, XR, PR i optymalizacja widoczności cyfrowej


Skorzystaj z bogatej, pięciokrotnej wiedzy specjalistycznej Xpert.Digital w ramach kompleksowego pakietu usług | Badania i rozwój, XR, PR i optymalizacja widoczności cyfrowej — Zdjęcie: Xpert.Digital
Xpert.Digital posiada dogłębną wiedzę na temat różnych branż. Dzięki temu możemy opracowywać strategie „szyte na miarę”, które są dokładnie dopasowane do wymagań i wyzwań konkretnego segmentu rynku. Dzięki ciągłej analizie trendów rynkowych i śledzeniu rozwoju branży możemy działać dalekowzrocznie i oferować innowacyjne rozwiązania. Dzięki połączeniu doświadczenia i wiedzy generujemy wartość dodaną i dajemy naszym klientom zdecydowaną przewagę konkurencyjną.
Więcej na ten temat tutaj:
BERT: Rewolucyjna 🌟 technologia NLP
🚀 BERT, skrót od Bilateral Encoder Representations from Transformers, to zaawansowany model językowy opracowany przez Google, który od czasu jego premiery w 2018 roku stał się znaczącym przełomem w dziedzinie przetwarzania języka naturalnego (NLP). Opiera się na architekturze Transformer, która zrewolucjonizowała sposób, w jaki maszyny rozumieją i przetwarzają tekst. Ale co dokładnie sprawia, że BERT jest tak wyjątkowy i do czego dokładnie się go używa? Aby odpowiedzieć na to pytanie, musimy głębiej zagłębić się w zasady techniczne, funkcjonalność i obszary zastosowań BERT.
📚 1. Podstawy przetwarzania języka naturalnego
Aby w pełni zrozumieć znaczenie BERT, warto pokrótce przejrzeć podstawy przetwarzania języka naturalnego (NLP). NLP zajmuje się interakcją między komputerami a ludzkim językiem. Celem jest nauczenie maszyn analizowania, rozumienia i reagowania na dane tekstowe. Przed wprowadzeniem modeli takich jak BERT maszynowe przetwarzanie języka często stwarzało poważne wyzwania, szczególnie ze względu na niejednoznaczność, zależność od kontekstu i złożoną strukturę języka ludzkiego.
📈 2. Rozwój modeli NLP
Zanim BERT pojawił się na scenie, większość modeli NLP opierała się na tak zwanych architekturach jednokierunkowych. Oznacza to, że modele te czytają tekst tylko od lewej do prawej lub od prawej do lewej, co oznacza, że podczas przetwarzania słowa w zdaniu mogą uwzględniać jedynie ograniczoną ilość kontekstu. To ograniczenie często powodowało, że modele nie w pełni oddawały pełny kontekst semantyczny zdania. Utrudniało to dokładną interpretację słów niejednoznacznych lub kontekstowych.
Kolejnym ważnym osiągnięciem w badaniach NLP przed BERT był model word2vec, który umożliwiał komputerom tłumaczenie słów na wektory odzwierciedlające podobieństwa semantyczne. Ale i tutaj kontekst ograniczał się do bezpośredniego otoczenia słowa. Później opracowano rekurencyjne sieci neuronowe (RNN), a w szczególności modele długiej pamięci krótkotrwałej (LSTM), które umożliwiły lepsze zrozumienie sekwencji tekstowych poprzez przechowywanie informacji w wielu słowach. Jednak modele te miały również swoje ograniczenia, szczególnie w przypadku długich tekstów i rozumienia kontekstu w obu kierunkach jednocześnie.
🔄 3. Rewolucja poprzez architekturę Transformers
Przełom nastąpił wraz z wprowadzeniem w 2017 roku architektury Transformer, która stanowi podstawę BERT. Modele transformatorowe zaprojektowano tak, aby umożliwić równoległe przetwarzanie tekstu z uwzględnieniem kontekstu słowa zarówno z tekstu poprzedzającego, jak i kolejnego. Odbywa się to poprzez tak zwane mechanizmy samouważności, które przypisują każdemu słowu w zdaniu wagę w oparciu o jego znaczenie w stosunku do pozostałych słów w zdaniu.
W przeciwieństwie do poprzednich podejść, modele transformatorów nie są jednokierunkowe, ale dwukierunkowe. Oznacza to, że mogą wyciągnąć informacje z lewego i prawego kontekstu słowa, tworząc pełniejszą i dokładniejszą reprezentację słowa i jego znaczenia.
🧠 4. BERT: Model dwukierunkowy
BERT przenosi wydajność architektury Transformer na nowy poziom. Model został zaprojektowany tak, aby uchwycić kontekst słowa nie tylko od lewej do prawej lub od prawej do lewej, ale w obu kierunkach jednocześnie. Dzięki temu BERT może uwzględnić pełny kontekst słowa w zdaniu, co skutkuje znacznie większą dokładnością w zadaniach związanych z przetwarzaniem języka.
Główną cechą BERT jest wykorzystanie tak zwanego modelu języka maskowanego (MLM). Podczas szkolenia BERT losowo wybrane słowa w zdaniu są zastępowane maską, a model jest szkolony w odgadywaniu tych zamaskowanych słów na podstawie kontekstu. Technika ta pozwala BERTowi nauczyć się głębszych i bardziej precyzyjnych relacji między słowami w zdaniu.
Dodatkowo BERT wykorzystuje metodę zwaną przewidywaniem następnego zdania (NSP), w której model uczy się przewidywać, czy jedno zdanie następuje po drugim, czy nie. Poprawia to zdolność BERT do rozumienia dłuższych tekstów i rozpoznawania bardziej złożonych relacji między zdaniami.
🌐 5. Zastosowanie BERT w praktyce
BERT okazał się niezwykle przydatny w różnorodnych zadaniach NLP. Oto niektóre z głównych obszarów zastosowań:
📊 a) Klasyfikacja tekstu
Jednym z najczęstszych zastosowań BERT jest klasyfikacja tekstów, w ramach której teksty są dzielone na predefiniowane kategorie. Przykładami tego mogą być analiza nastrojów (np. rozpoznawanie, czy tekst jest pozytywny, czy negatywny) lub kategoryzacja opinii klientów. BERT może zapewnić dokładniejsze wyniki niż poprzednie modele dzięki głębokiemu zrozumieniu kontekstu słów.
❓ b) Systemy pytanie-odpowiedź
BERT jest również używany w systemach pytanie-odpowiedź, w których model wyodrębnia z tekstu odpowiedzi na zadane pytania. Możliwość ta jest szczególnie istotna w aplikacjach takich jak wyszukiwarki, chatboty czy wirtualni asystenci. Dzięki swojej dwukierunkowej architekturze BERT może wydobyć istotne informacje z tekstu, nawet jeśli pytanie jest sformułowane pośrednio.
🌍 c) Tłumaczenie tekstu
Chociaż sam BERT nie został bezpośrednio zaprojektowany jako model tłumaczenia, można go stosować w połączeniu z innymi technologiami w celu ulepszenia tłumaczenia maszynowego. Dzięki lepszemu zrozumieniu relacji semantycznych w zdaniu BERT może pomóc w generowaniu dokładniejszych tłumaczeń, zwłaszcza w przypadku sformułowań niejednoznacznych lub złożonych.
🏷️ d) Rozpoznawanie podmiotów nazwanych (NER)
Innym obszarem zastosowań jest rozpoznawanie nazwanych podmiotów (NER), które polega na identyfikacji w tekście konkretnych podmiotów, takich jak nazwy, miejsca czy organizacje. BERT okazał się szczególnie skuteczny w tym zadaniu, ponieważ w pełni uwzględnia kontekst zdania, dzięki czemu lepiej rozpoznaje byty, nawet jeśli mają one różne znaczenia w różnych kontekstach.
✂️ e) Podsumowanie tekstowe
Zdolność BERT do zrozumienia całego kontekstu tekstu czyni go również potężnym narzędziem do automatycznego podsumowywania tekstu. Można go wykorzystać do wydobycia najważniejszych informacji z długiego tekstu i stworzenia zwięzłego podsumowania.
🌟 6. Znaczenie BERT dla nauki i przemysłu
Wprowadzenie BERT zapoczątkowało nową erę w badaniach NLP. Był to jeden z pierwszych modeli, który w pełni wykorzystał moc dwukierunkowej architektury Transformer, wyznaczając poprzeczkę dla wielu kolejnych modeli. Wiele firm i instytutów badawczych zintegrowało BERT ze swoimi procesami NLP, aby poprawić wydajność swoich aplikacji.
Ponadto BERT utorował drogę dalszym innowacjom w obszarze modeli językowych. Na przykład później opracowano modele takie jak GPT (generatywny transformator wstępnie przeszkolony) i T5 (transformator transferu tekstu na tekst), które opierają się na podobnych zasadach, ale oferują specyficzne ulepszenia dla różnych przypadków użycia.
🚧 7. Wyzwania i ograniczenia BERT
Pomimo wielu zalet BERT ma również pewne wyzwania i ograniczenia. Jedną z największych przeszkód jest duży wysiłek obliczeniowy wymagany do wytrenowania i zastosowania modelu. Ponieważ BERT jest bardzo dużym modelem z milionami parametrów, wymaga potężnego sprzętu i znacznych zasobów obliczeniowych, szczególnie przy przetwarzaniu dużych ilości danych.
Inną kwestią jest potencjalna stronniczość, która może występować w danych szkoleniowych. Ponieważ BERT jest szkolony na dużych ilościach danych tekstowych, czasami odzwierciedla to uprzedzenia i stereotypy obecne w tych danych. Jednak badacze nieustannie pracują nad identyfikacją i rozwiązaniem tych problemów.
🔍 Niezbędne narzędzie do nowoczesnych aplikacji do przetwarzania języka
BERT znacznie poprawił sposób, w jaki maszyny rozumieją ludzki język. Dzięki dwukierunkowej architekturze i innowacyjnym metodom szkoleniowym jest w stanie głęboko i dokładnie uchwycić kontekst słów w zdaniu, co skutkuje większą dokładnością w wielu zadaniach NLP. Niezależnie od tego, czy chodzi o klasyfikację tekstu, systemy pytań i odpowiedzi, czy rozpoznawanie jednostek – BERT stał się niezbędnym narzędziem w nowoczesnych aplikacjach do przetwarzania języka.
Badania nad przetwarzaniem języka naturalnego niewątpliwie będą się rozwijać, a BERT położył podwaliny pod wiele przyszłych innowacji. Pomimo istniejących wyzwań i ograniczeń BERT w imponujący sposób pokazuje, jak daleko zaszła ta technologia w krótkim czasie i jakie ekscytujące możliwości otworzą się jeszcze w przyszłości.
🌀 Transformator: rewolucja w przetwarzaniu języka naturalnego
🌟 W ostatnich latach jednym z najważniejszych osiągnięć w dziedzinie przetwarzania języka naturalnego (NLP) było wprowadzenie modelu Transformer, zgodnie z opisem w artykule z 2017 r. „Attention Is All You Need”. Model ten zasadniczo zmienił dziedzinę, odrzucając wcześniej używane struktury rekurencyjne lub splotowe do zadań transdukcji sekwencji, takich jak translacja maszynowa. Zamiast tego opiera się wyłącznie na mechanizmach uwagi. Od tego czasu konstrukcja Transformera stała się podstawą wielu modeli reprezentujących najnowocześniejszy stan wiedzy w różnych obszarach, takich jak generowanie języka, tłumaczenie i nie tylko.
🔄 Transformator: zmiana paradygmatu
Przed wprowadzeniem Transformera większość modeli zadań sekwencjonowania opierała się na sieciach neuronowych rekurencyjnych (RNN) lub sieciach pamięci krótkotrwałej (LSTM), które z natury są sekwencyjne. Modele te przetwarzają dane wejściowe krok po kroku, tworząc ukryte stany, które są propagowane wzdłuż sekwencji. Chociaż ta metoda jest skuteczna, jest kosztowna obliczeniowo i trudna do zrównoleglenia, szczególnie w przypadku długich sekwencji. Ponadto sieci RNN mają trudności z uczeniem się zależności długoterminowych ze względu na tak zwany problem „zanikającego gradientu”.
Główną innowacją Transformera jest wykorzystanie mechanizmów samouważności, które pozwalają modelowi wyważyć względem siebie znaczenie różnych słów w zdaniu, niezależnie od ich położenia. Dzięki temu model może skuteczniej uchwycić relacje między szeroko rozstawionymi słowami niż RNN czy LSTM i zrobić to równolegle, a nie sekwencyjnie. Poprawia to nie tylko efektywność szkolenia, ale także wydajność zadań takich jak tłumaczenie maszynowe.
🧩 Modeluj architekturę
Transformator składa się z dwóch głównych elementów: kodera i dekodera, przy czym oba składają się z wielu warstw i w dużym stopniu opierają się na mechanizmach uwagi wielu głów.
⚙️ Koder
Koder składa się z sześciu identycznych warstw, każda z dwiema podwarstwami:
1. Wielogłowa samouważność
Mechanizm ten pozwala modelowi skupić się na różnych częściach zdania wejściowego podczas przetwarzania każdego słowa. Zamiast skupiać uwagę na jednej przestrzeni, uwaga wielogłowa rzutuje dane wejściowe na kilka różnych przestrzeni, umożliwiając uchwycenie różnych typów relacji między słowami.
2. W pełni połączone sieci wyprzedzające pozycyjnie
Po warstwie uwagi zastosowano w pełni połączoną sieć wyprzedzającą, niezależnie na każdej pozycji. Pomaga to modelowi przetwarzać każde słowo w kontekście i wykorzystywać informacje z mechanizmu uwagi.
Aby zachować strukturę sekwencji wejściowej, model zawiera również wejścia pozycyjne (kodowanie pozycyjne). Ponieważ Transformer nie przetwarza słów sekwencyjnie, kodowanie to ma kluczowe znaczenie w przekazywaniu modelowi informacji o kolejności słów w zdaniu. Dane wejściowe dotyczące pozycji są dodawane do osadzonych słów, dzięki czemu model może rozróżnić różne pozycje w sekwencji.
🔍Dekodery
Podobnie jak koder, dekoder również składa się z sześciu warstw, przy czym każda warstwa posiada dodatkowy mechanizm uwagi, który pozwala modelowi skupić się na odpowiednich częściach sekwencji wejściowej podczas generowania sygnału wyjściowego. Dekoder wykorzystuje również technikę maskowania, aby zapobiec uwzględnianiu przyszłych pozycji, zachowując autoregresywny charakter generowania sekwencji.
🧠 Uwaga wielogłowa i uwaga na produkt punktowy
Sercem Transformera jest mechanizm Multi-Head Attention, będący rozwinięciem prostszego produktu punktowego. Funkcję uwagi można postrzegać jako odwzorowanie zapytania i zestawu par klucz-wartość (kluczy i wartości), gdzie każdy klucz reprezentuje słowo w sekwencji, a wartość reprezentuje powiązane informacje kontekstowe.
Mechanizm uwagi wielogłowej pozwala modelowi skupić się na różnych częściach sekwencji w tym samym czasie. Projektując dane wejściowe na wiele podprzestrzeni, model może uchwycić bogatszy zestaw relacji między słowami. Jest to szczególnie przydatne w zadaniach takich jak tłumaczenie maszynowe, gdzie zrozumienie kontekstu słowa wymaga wielu różnych czynników, takich jak struktura składniowa i znaczenie semantyczne.
Wzór na uwagę iloczynu kropkowego to:
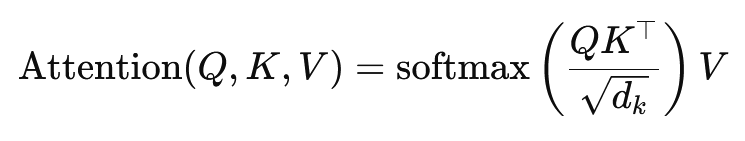
Tutaj (Q) jest macierzą zapytań, (K) jest macierzą kluczy, a (V) jest macierzą wartości. Termin (sqrt{d_k}) to współczynnik skalowania, który zapobiega nadmiernemu zwiększaniu się iloczynów skalarnych, co prowadziłoby do bardzo małych gradientów i wolniejszego uczenia się. Aby zapewnić, że wagi uwagi sumują się do jednego, stosowana jest funkcja softmax.
🚀 Zalety Transformatora
Transformer oferuje kilka kluczowych zalet w porównaniu z tradycyjnymi modelami, takimi jak RNN i LSTM:
1. Równoległość
Ponieważ Transformer przetwarza wszystkie tokeny w sekwencji w tym samym czasie, może być w dużym stopniu zrównoleglony i dlatego jego uczenie jest znacznie szybsze niż RNN lub LSTM, szczególnie w przypadku dużych zestawów danych.
2. Zależności długoterminowe
Mechanizm samouważności pozwala modelowi skuteczniej uchwycić relacje między odległymi słowami niż RNN, które są ograniczone przez sekwencyjny charakter ich obliczeń.
3. Skalowalność
Transformator można z łatwością skalować do bardzo dużych zbiorów danych i dłuższych sekwencji, nie odczuwając wąskich gardeł wydajności związanych z sieciami RNN.
🌍Zastosowania i efekty
Od momentu wprowadzenia Transformer stał się podstawą szerokiej gamy modeli NLP. Jednym z najbardziej godnych uwagi przykładów jest BERT (Bilateral Encoder Representations from Transformers), który wykorzystuje zmodyfikowaną architekturę Transformera, aby osiągnąć najnowocześniejszy poziom w wielu zadaniach NLP, w tym w odpowiadaniu na pytania i klasyfikacji tekstu.
Kolejnym znaczącym osiągnięciem jest GPT (Generative Pretrained Transformer), który wykorzystuje wersję Transformera z ograniczoną liczbą dekoderów do generowania tekstu. Modele GPT, w tym GPT-3, są obecnie używane w różnych zastosowaniach, od tworzenia treści po uzupełnianie kodu.
🔍 Mocny i elastyczny model
Transformer zasadniczo zmienił sposób, w jaki podchodzimy do zadań NLP. Zapewnia potężny i elastyczny model, który można zastosować do różnych problemów. Jego zdolność do radzenia sobie z długoterminowymi zależnościami i efektywność uczenia sprawiły, że jest to preferowane podejście architektoniczne w wielu najnowocześniejszych modelach. W miarę postępu badań prawdopodobnie zobaczymy dalsze ulepszenia i dostosowania Transformera, szczególnie w obszarach takich jak przetwarzanie obrazu i języka, gdzie mechanizmy uwagi dają obiecujące wyniki.
Jesteśmy do Twojej dyspozycji - doradztwo - planowanie - realizacja - zarządzanie projektami
☑️ Ekspert branżowy, tutaj z własnym centrum branżowym Xpert.Digital z ponad 2500 artykułami specjalistycznymi

Konrad Wolfenstein
Chętnie będę Twoim osobistym doradcą.
Możesz się ze mną skontaktować wypełniając poniższy formularz kontaktowy lub po prostu dzwoniąc pod numer +49 89 89 674 804 (Monachium) .
Nie mogę się doczekać naszego wspólnego projektu.
Napisz do mnie




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital to centrum przemysłu skupiające się na cyfryzacji, inżynierii mechanicznej, logistyce/intralogistyce i fotowoltaice.
Dzięki naszemu rozwiązaniu do rozwoju biznesu 360° wspieramy znane firmy od rozpoczęcia nowej działalności po sprzedaż posprzedażną.
Wywiad rynkowy, smarketing, automatyzacja marketingu, tworzenie treści, PR, kampanie pocztowe, spersonalizowane media społecznościowe i pielęgnacja leadów to część naszych narzędzi cyfrowych.
Więcej informacji znajdziesz na: www.xpert.digital - www.xpert.solar - www.xpert.plus
Pozostajemy w kontakcie











