
Ki en SEO met Bert - Bidirectionele encoderrepresentaties van Transformers - Model op het gebied van natuurlijke taalverwerking (NLP)

Spraakselectie 📢
Gepubliceerd op: 4 oktober 2024 / UPDATE VAN: 4 oktober 2024 - Auteur: Konrad Wolfenstein

Ki en SEO met Bert - Bidirectionele encoderrepresentaties van Transformers - Model op het gebied van natuurlijke taalverwerking (NLP) - Afbeelding: Xpert.Digital
🚀💬 Ontwikkeld door Google: Bert en het belang ervan voor NLP - waarom bidirectioneel begrip van tekst beslissend is
🔍🗣️ Bert, kort voor bidirectionele encoderrepresentaties van transformatoren, is een belangrijk model op het gebied van natuurlijke taalverwerking (NLP), dat is ontwikkeld door Google. Het heeft een revolutie teweeggebracht in de manier waarop machines taal begrijpen. In tegenstelling tot eerdere modellen die teksten opeenvolgend van links naar rechts of vice versa analyseerden, maakt Bert bidirectionele verwerking mogelijk. Dit betekent dat het de context van een woord van zowel de vorige als de volgende tekstreeks vastlegt. Dit vermogen verbetert het begrip van complexe taalrelaties aanzienlijk.
🔍 De architectuur van Bert
In de voorgaande jaren was er een van de belangrijkste ontwikkelingen op het gebied van verwerking van natuurlijke taal (natuurlijke taalverwerking, NLP) door het transformatormodel te introduceren, zoals het was in PDF 2017-etsing is alles wat je nodig hebt, paper ( Wikipedia ). Dit model heeft het veld fundamenteel veranderd door de eerder gebruikte structuren af te wijzen, zoals de machine -vertaling. In plaats daarvan is het alleen afhankelijk van aandachtsmechanismen. Sindsdien is het ontwerp van de transformator de basis geweest voor veel modellen die de stand van de kunst vertegenwoordigen op verschillende gebieden zoals taalgeneratie, vertaling en verder.
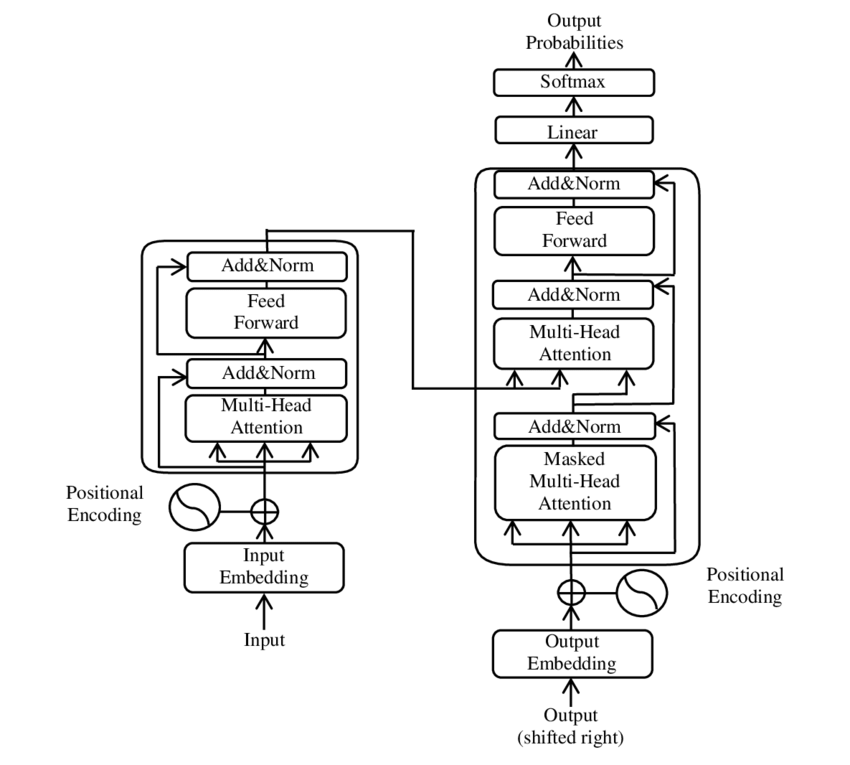
Een toewijzing van de belangrijkste componenten van het transformator modelbeeld: Google
Bert is gebaseerd op deze transformatorarchitectuur. Deze architectuur maakt gebruik van zogenaamde zelfvoorziening mechanismen (zelfstation) om relaties tussen de woorden in één zin te analyseren. Elk woord in de context van de hele zin wordt aandacht besteed, wat leidt tot een beter begrip van syntactische en semantische relaties.
De auteurs van het artikel "Aandacht is alles wat je nodig hebt" zijn:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Llion Jones (Google Research)
- Aidan N. Gomez (Universiteit van Toronto, gedeeltelijk uitgevoerd op Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (onafhankelijk, eerder werk aan Google Research)
Deze auteurs hebben aanzienlijk bijgedragen aan de ontwikkeling van het transformatormodel, dat in dit artikel werd gepresenteerd.
🔄 Bidirectionele verwerking
Een uitstekend kenmerk van Bert is zijn vermogen om met bidirection te werken. Terwijl traditionele modellen zoals recidiverende neuronale netwerken (RNN's) of langetermijnnetwerken (LSTM) netwerken van netwerken slechts in één richting worden verwerkt, analyseert Bert de context van een woord in beide richtingen. Dit stelt het model in staat om subtiele nuances beter vast te leggen en dus precieze voorspellingen te doen.
🕵️️ gemaskeerde spraakmodellering
Een ander innovatief aspect van Bert is de technologie van het gemaskeerde taalmodel (MLM). Willekeurig geselecteerde woorden worden in één zin gemaskeerd en het model wordt getraind om deze woorden te voorspellen op basis van de omliggende context. Deze methode dwingt Bert om een diep begrip van de context en de betekenis van elk woord in de zin te ontwikkelen.
🚀 Training en aanpassing van Bert
Bert doorloopt een tweetraps trainingsproces: pre-training en fijnafstemming.
📚 Pre-training
Bij pre-training wordt Bert getraind met grote hoeveelheden tekst om algemene taalpatronen te leren. Dit omvat Wikipedia -teksten en andere uitgebreide tekstcorpora. In deze fase leert het model fundamentele taalstructuren en contexten kennen.
🔧 Fijne afstemming
Na pre-training wordt BERT aangepast voor specifieke NLP-taken, zoals tekstclassificatie of sentimentanalyse. Het model is getraind met kleinere, taakgerelateerde gegevensrecords om de prestaties voor bepaalde toepassingen te optimaliseren.
🌍 Toepassingsgebieden van Bert
Bert is uiterst nuttig gebleken op tal van gebieden van natuurlijke taalverwerking:
Zoekmachineoptimalisatie
Google gebruikt Bert om zoekopdrachten beter te begrijpen en meer relevante resultaten weer te geven. Dit verbetert de gebruikerservaring aanzienlijk.
Tekstclassificatie
Bert kan documenten categoriseren volgens onderwerpen of de stemming in teksten analyseren.
Genoemde entiteitsherkenning (NER)
Het model identificeert en classificeert genoemde entiteiten in teksten zoals persoonlijke, plaats- of organisatorische namen.
Vraag-antwoordsystemen
Bert wordt gebruikt om precieze antwoorden te geven op vragen gesteld.
🧠 De betekenis van Bert voor de toekomst van de AI
Bert heeft nieuwe normen vastgesteld voor NLP -modellen en heeft de weg vrijgemaakt voor verdere innovaties. Vanwege het vermogen om bidirection en het diepe begrip van taalcontexten te verwerken, heeft het de efficiëntie en nauwkeurigheid van AI -toepassingen aanzienlijk verhoogd.
🔜 Toekomstige ontwikkelingen
De verdere ontwikkeling van BERT en vergelijkbare modellen zal naar verwachting zijn gericht op het creëren van nog krachtigere systemen. Deze kunnen omgaan met complexere spraaktaken en worden gebruikt in verschillende nieuwe toepassingsgebieden. De integratie van dergelijke modellen in alledaagse technologieën kan onze interactie met computers fundamenteel veranderen.
🌟 mijlpaal bij de ontwikkeling van kunstmatige intelligentie
Bert is een mijlpaal in de ontwikkeling van kunstmatige intelligentie en heeft een revolutie teweeggebracht in de manier waarop machines de natuurlijke taal verwerken. De bidirectionele architectuur maakt een dieper begrip van taalrelaties mogelijk, waardoor het onmisbaar is voor verschillende toepassingen. Met progressief onderzoek zullen modellen zoals Bert een centrale rol blijven spelen bij het verbeteren van AI -systemen en het openen van nieuwe kansen voor het gebruik ervan.
📣 Soortgelijke onderwerpen
- 📚 Inleiding tot Bert: het baanbrekende NLP -model
- 🔍 Bert en de rol van bidirectionaliteit in NLP
- 🧠 Het transformatormodel: case steen van Bert
- 🚀 Maskeerde spraakmodellering: Bert's sleutel tot succes
- 📈 aanpassing van Bert: van pre-training tot verfijning
- 🌐 Bert's toepassingsgebieden in moderne technologie
- 🤖 Bert's invloed op de toekomst van kunstmatige intelligentie
- 💡 toekomstperspectieven: verdere ontwikkelingen door Bert
- 🏆 Bert als mijlpaal in AI -ontwikkeling
- 📰 Auteurs van het transformatorpapier "De aandacht is alles wat je nodig hebt": de hoofden achter Bert
#️⃣ Hashtags: #nlp #Artificial EditionStz #Language Modellering #TransFormer #MaSchinelslernen
🎯🎯🎯 Hoofd van de uitgebreide, vijf -time expertise van Xpert.Digital in een uitgebreid servicepakket | R&D, XR, PR & SEM

AI & XR-3D-renderingmachine: vijf keer expertise van Xpert.Digital in een uitgebreid servicepakket, R&D XR, PR & SEM-beeld: Xpert.Digital
Xpert.Digital heeft diepe kennis in verschillende industrieën. Dit stelt ons in staat om op maat gemaakte strategieën te ontwikkelen die zijn afgestemd op de vereisten en uitdagingen van uw specifieke marktsegment. Door continu markttrends te analyseren en de ontwikkelingen in de industrie na te streven, kunnen we handelen met vooruitziende blik en innovatieve oplossingen bieden. Met de combinatie van ervaring en kennis genereren we extra waarde en geven onze klanten een beslissend concurrentievoordeel.
Meer hierover hier:
Bert: Revolutionaire 🌟 NLP -technologie
🚀 Bert, kort voor bidirectionele encoderrepresentaties van Transformers, is een geavanceerd spraakmodel dat is ontwikkeld door Google en heeft zich ontwikkeld tot een aanzienlijke doorbraak op het gebied van natuurlijke taalverwerking (Natural Language Processing, NLP) sinds de introductie in 2018. Het is gebaseerd op de transformatorarchitectuur die een revolutie teweeggebracht in de manier waarop machines worden begrepen en procestekst. Maar wat maakt Bert precies zo speciaal en waar wordt het voor gebruikt? Om deze vraag te beantwoorden, hebben we te maken met de technische basisprincipes, het functioneren en de toepassingsgebieden van Bert.
📚 1. De basisprincipes van de verwerking van natuurlijke taal
Om de betekenis van Bert volledig te begrijpen, is het nuttig om kort te reageren op de basisprincipes van natuurlijke taalverwerking (NLP). NLP gaat over de interactie tussen computers en menselijke taal. Het doel is om machines te leren, tekstgegevens te analyseren, te begrijpen en erop te reageren. Vóór de introductie van modellen zoals Bert werd de mechanische verwerking van taal vaak geassocieerd met aanzienlijke uitdagingen, met name vanwege de dubbelzinnigheid, contextafhankelijkheid en de complexe structuur van de menselijke taal.
📈 2. De ontwikkeling van NLP -modellen
Voordat Bert op het toneel verscheen, waren de meeste NLP-modellen gebaseerd op zogenaamde unidirectionele architecturen. Dit betekent dat deze modellen de tekst van links naar rechts of van rechts naar links lezen, wat betekende dat ze slechts rekening konden houden met een beperkte hoeveelheid context bij het verwerken van een woord in één zin. Deze beperking leidde vaak tot de modellen die de volledige semantische context van een zin niet volledig registreerde. Dit maakte de nauwkeurige interpretatie van dubbelzinnige of context -gevoelige woorden.
Een andere belangrijke ontwikkeling in NLP -onderzoek voor Bert was het Word2VEC -model, waardoor het mogelijk was om computers in vectoren te vertalen die semantische overeenkomsten weerspiegelden. Maar ook hier was de context beperkt tot de directe omgeving van een woord. Latere terugkerende neurale netwerken (RNN's) en in het bijzonder werden modellen voor lange termijn geheugen (LSTM) ontwikkeld die het mogelijk maakten om tekstsequenties beter te begrijpen door informatie over verschillende woorden op te slaan. Deze modellen hadden echter ook hun grenzen, vooral bij het omgaan met lange teksten en het gelijktijdige begrip van de context in beide richtingen.
🔄 3. De revolutie door de transformatorarchitectuur
De doorbraak kwam met de introductie van de transformatorarchitectuur in 2017, die de basis vormt voor Bert. Transformatormodellen zijn ontworpen om parallelle verwerking van tekst mogelijk te maken en rekening te houden met de context van een woord van zowel de vorige als uit de volgende tekst. Dit gebeurt door zogenaamde zelfvoorziening mechanismen (zelfpostmethoden), die een wegingwaarde toewijzen aan elk woord in één zin, gebaseerd op hoe belangrijk het is in relatie tot de andere woorden in de zin.
In tegenstelling tot eerdere benaderingen zijn transformatiemodellen niet unidirectioneel, maar bidirectioneel. Dit betekent dat u informatie van links en de juiste context van een woord kunt putten om een completere en preciezere weergave van het woord en de betekenis ervan te creëren.
🧠 4. Bert: een bidirectioneel model
Bert verhoogt de prestaties van de transformatorarchitectuur naar een nieuw niveau. Het model is ontworpen om de context van een woord vast te leggen, niet alleen van links naar rechts of van rechts naar links, maar in beide richtingen tegelijkertijd. Hierdoor kan Bert rekening houden met de volledige context van een woord binnen een zin, wat leidt tot een aanzienlijk verbeterde nauwkeurigheid in het geval van taalverwerking.
Een centraal kenmerk van BERT is het gebruik van het So -Called Masked Voice Model (Masked Language Model, MLM). In de training van Bert worden willekeurig geselecteerde woorden vervangen door een masker in één zin en wordt het model getraind om deze gemaskerde woorden te raden op basis van de context. Met deze technologie kan Bert diepere en preciezere relaties tussen de woorden in één zin leren.
Bovendien gebruikt Bert een methode met de naam volgende zinvoorspelling (NSP) waarin het model leert te voorspellen of de ene zin een andere volgt of niet. Dit verbetert het vermogen van Bert om langere teksten te begrijpen en meer complexe relaties tussen zinnen te herkennen.
🌐 5. Gebruik van Bert in de praktijk
Bert is uiterst nuttig gebleken voor verschillende NLP -taken. Hier zijn enkele van de belangrijkste toepassingsgebieden:
📊 a) tekstclassificatie
Een van de meest voorkomende doeleinden van Bert is de tekstclassificatie, waarin teksten worden verdeeld in vooraf gedefinieerde categorieën. Voorbeelden hiervan zijn de sentimentele analyse (bijvoorbeeld erkennen of een tekst positief of negatief is) of de categorisatie van feedback van klanten. Door zijn diepe begrip van de context van woorden, kan Bert precies meer resultaten opleveren dan eerdere modellen.
❓ b) Vraag-antwoordsystemen
Bert wordt ook gebruikt in vraag-antwoordsystemen waarin het model antwoorden op vragen uit een tekst extraheert. Deze mogelijkheid is vooral belangrijk in applicaties zoals zoekmachines, chatbots of virtuele assistenten. Dankzij de bidirectionele architectuur kan Bert relevante informatie uit een tekst halen, zelfs als de vraag indirect is geformuleerd.
🌍 c) tekstvertaling
Hoewel Bert zelf niet direct is ontworpen als een vertaalmodel, kan het worden gebruikt in combinatie met andere technologieën om de machinevertaling te verbeteren. Door een beter begrip van semantische relaties in één zin, kan Bert helpen bij het genereren van precieze vertalingen, vooral met dubbelzinnige of complexe formuleringen.
🏷️ D) Noemde entiteitherkenning (NER)
Een ander toepassingsgebied is de genoemde Entity Recognition (NER), die gaat over het identificeren van bepaalde entiteiten zoals namen, plaatsen of organisaties in een tekst. Bert is in deze taak bijzonder effectief gebleken, omdat het volledig rekening houdt met de context van een zin en dus entiteiten beter kan herkennen, zelfs als ze verschillende betekenissen in verschillende contexten hebben.
✂️ e) tekst
Bert's vermogen om de hele context van een tekst te begrijpen, maakt het ook een krachtig hulpmiddel voor de automatische tekst van de tekst. Het kan worden gebruikt om de belangrijkste informatie uit een lange tekst te halen en een beknopte samenvatting te maken.
🌟 6. Het belang van Bert voor onderzoek en industrie
De introductie van Bert heeft een nieuw tijdperk in NLP -onderzoek aangekondigd. Het was een van de eerste modellen die de prestaties van de bidirectionele transformatorarchitectuur volledig gebruikten en dus de maatstaf voor veel volgende modellen plaatste. Veel bedrijven en onderzoeksinstituten hebben Bert in hun NLP -pijpleidingen geïntegreerd om de prestaties van hun applicaties te verbeteren.
Bert maakte ook de weg vrij voor verdere innovaties op het gebied van taalmodellen. Er zijn bijvoorbeeld modellen zoals GPT (generatieve pretaed transformator) en T5 (tekst-naar-tekstoverdrachttransformator) ontwikkeld die zijn gebaseerd op vergelijkbare principes, maar bieden bijvoorbeeld specifieke verbeteringen voor verschillende toepassingen.
🚧 7. Uitdagingen en grenzen van Bert
Ondanks zijn vele voordelen heeft Bert ook enkele uitdagingen en beperkingen. Een van de grootste hindernissen is de hoge computerinspanning die nodig is voor training en het gebruik van het model. Aangezien Bert een zeer groot model is met miljoenen parameters, vereist het krachtige hardware en aanzienlijke rekenmiddelen, vooral bij het verwerken van grote hoeveelheden gegevens.
Een ander probleem is de potentiële bias (bias), die aanwezig kan zijn in de trainingsgegevens. Aangezien BERT is getraind op grote hoeveelheden tekstgegevens, weerspiegelt het soms de vooroordelen en stereotypen die beschikbaar zijn in deze gegevens. Onderzoekers werken echter continu aan het identificeren en verwijderen van deze problemen.
🔍 onmisbare tool voor moderne taalverwerkingstoepassingen
Bert heeft de manier waarop machines de menselijke taal begrijpen aanzienlijk verbeterd. Met zijn bidirectionele architectuur en de innovatieve trainingsmethoden is het in staat om de context van woorden in één zin diep en precies te begrijpen, wat leidt tot een hogere nauwkeurigheid in veel NLP -taken. Of de classificatie van tekst, in vraag-responsystemen of bij de detectie van entiteiten-BERT zich heeft gevestigd als een onmisbaar hulpmiddel voor moderne taalverwerkingstoepassingen.
Onderzoek op het gebied van natuurlijke taalverwerking is ongetwijfeld vordert en Bert heeft de basis gelegd voor vele toekomstige innovaties. Ondanks de bestaande uitdagingen en grenzen laat Bert indrukwekkend zien hoe ver de technologie in korte tijd is gekomen en welke opwindende mogelijkheden in de toekomst zullen openen.
🌀 De transformator: een revolutie op het gebied van verwerking van natuurlijke taal
🌟 In de afgelopen jaren is een van de belangrijkste ontwikkelingen op het gebied van verwerking van natuurlijke taal (natuurlijke taalverwerking, NLP) de introductie van het transformatormodel geweest, zoals beschreven in het artikel van 2017 "Aandacht is alles wat je nodig hebt". Dit model heeft het veld fundamenteel veranderd door de eerder gebruikte terugkerende of convolutiestructuren voor taken van sequentietransductie, zoals de machinevertaling te weigeren. In plaats daarvan is het alleen afhankelijk van aandachtsmechanismen. Sindsdien is het ontwerp van de transformator de basis geweest voor veel modellen die de stand van de kunst vertegenwoordigen op verschillende gebieden zoals taalgeneratie, vertaling en verder.
🔄 De transformator: een paradigmaverschuiving
Vóór de introductie van de transformator waren de meeste modellen voor sequentietaken gebaseerd op recidiverende neuronale netwerken (RNN's) of "Long Short-Term Memory" Networks (LSTMS), die van nature sequentieel werken. Deze modellen verwerken invoergegevens stapsgewijze invoergegevens en creëren verborgen omstandigheden die langs de volgorde worden doorgegeven. Hoewel deze methode effectief is, is het wiskundig complex en moeilijk te paralleleren, vooral met lange sequenties. Bovendien zijn de moeilijkheden van RNN om langdurige afhankelijkheden te leren, omdat het zogenaamde "verdwijnende gradiënt" -probleem optreedt.
De centrale innovatie van de transformator ligt in het gebruik van zelf-endmechanismen, waardoor het model het belang van verschillende woorden in één zin kan wegen, ongeacht hun positie. Hierdoor kan het model relaties tussen zeer uit elkaar geplaatste woorden effectiever begrijpen dan RNN's of LSTM's, en dit parallel in plaats van sequentieel. Dit verbetert niet alleen de trainingsefficiëntie, maar ook prestaties voor taken zoals machinevertaling.
🧩 Modelarchitectuur
De transformator bestaat uit twee hoofdcomponenten: een encoder en een decoder, die beide uit verschillende lagen bestaan en sterk afhankelijk zijn van multi-hoofdstationmechanismen.
⚙️ Encoder
De encoder bestaat uit zes identieke lagen, elk hebben twee lagere klassen:
1. Multi-head zelfbeschadiging
Dit mechanisme stelt het model in staat om zich te concentreren op verschillende delen van de invoersnelheid bij het verwerken van elk woord. In plaats van de aandacht te berekenen in een enkele kamer, projecteert het multi-hoofdstation de input in verschillende kamers, wat betekent dat verschillende soorten relaties tussen woorden kunnen worden opgenomen.
2. volledig verbonden feedforward -netwerken
Volgens de aanvalslaag wordt een volledig verbonden feedforward -netwerk op elke positie onafhankelijk toegepast. Dit helpt het model om elk woord in context te verwerken en de informatie uit het aandachtsmechanisme te gebruiken.
Om de structuur van de invoersequentie te behouden, bevat het model ook positie -invoer (positionele coderingen). Aangezien de transformator de woorden niet opeenvolgend verwerkt, zijn deze coderingen cruciaal om de modelinformatie over de volgorde van de woorden in één zin te geven. De positie-ingangen worden toegevoegd aan het woord van de bedden zodat het model onderscheid kan maken tussen de verschillende posities in de reeks.
🔍 Decoder
Net als de encoder bestaat de decoder ook uit zes lagen, met elke laag heeft een extra aandachtsmechanisme waarmee het model zich kan concentreren op relevante delen van de invoersequentie terwijl deze de output genereert. De decoder gebruikt ook een maskeertechniek om te voorkomen dat toekomstige posities rekening houden met wat de auteur -compressieve aard van sequentieverlening behoudt.
🧠 Multi-hoofdstation en scalair productstation
Het hart van de transformator is het multi-head post-mechanisme, dat een uitbreiding is van het eenvoudiger scalaire productstation. De aanvalsfunctie kan worden beschouwd als een illustratie tussen een query (query) en een zin van sleutelwaardeparen (toetsen en waarden), elke sleutel vertegenwoordigt een woord in de reeks en de waarde vertegenwoordigt de bijbehorende contextuele informatie.
Met het multi-head stationmechanisme kan het model zich tegelijkertijd op verschillende delen van de reeks concentreren. Door de input van de input in verschillende subkamers, kan het model een meer rijke hoeveelheid relaties tussen woorden vastleggen. Dit is met name nuttig voor taken zoals machinevertaling, waarin het begrip van de context van een woord veel verschillende factoren vereist, zoals de syntactische structuur en de semantische betekenis.
De formule voor het scalaire productstation is:
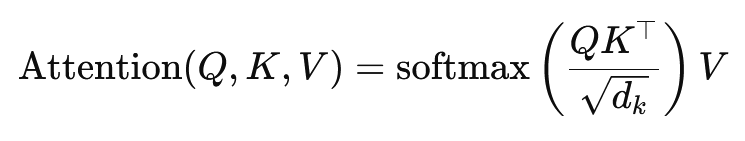
Hier (q) De fragematrix, (k) de sleutelmatrix en (v) de waardematrix. De term (sqrt {d_k}) is een schaalfactor die voorkomt dat de scalaire producten te groot worden, wat zou leiden tot zeer kleine gradiënten en langzamer leren. De SoftMax -functie wordt gebruikt om ervoor te zorgen dat de aandachtsgewichten resulteren in een som van één.
🚀 Voordelen van de transformator
De transformator biedt verschillende cruciale voordelen ten opzichte van traditionele modellen zoals RNNS en LSTM's:
1. Parallellisatie
Omdat de transformator alle volgorde tegelijkertijd verwerkt, kan deze sterk parallel worden geparalleteerd en is het daarom veel sneller om te trainen dan RNN's of LSTM's, vooral met grote gegevenssets.
2. Lange termijnafhankelijkheid
Met het zelfpostingsmechanisme kan het model relaties tussen verre woorden effectiever vastleggen dan RNN's, die worden beperkt door de sequentiële aard van hun berekeningen.
3. Schaalbaarheid
De transformator kan eenvoudig worden geschaald op zeer grote gegevensrecords en langere sequenties zonder te lijden aan de knelpunten van de prestaties die zijn geassocieerd met RNS.
🌍 Toepassingen en effecten
Sinds de introductie is de transformator de basis geworden voor een breed scala aan NLP -modellen. Een van de meest opmerkelijke voorbeelden is Bert (bidirectionele encoder representatie van transformatoren), die een gemodificeerde transformatorarchitectuur gebruikt om de stand van de kunst te bereiken in veel NLP -taken, waaronder vragen en tekstclassificatie.
Een andere belangrijke ontwikkeling is GPT (generatieve proprained transformator), die een versie van de transformator gebruikt om tekst te genereren. GPT-modellen, waaronder GPT-3, worden nu gebruikt voor tal van applicaties, van het maken van inhoud tot het voltooien van de code.
🔍 Een krachtig en flexibel model
De transformator heeft de manier waarop we NLP -taken aanpakken fundamenteel veranderd. Het biedt een krachtig en flexibel model dat op verschillende problemen kan worden toegepast. Zijn vermogen om afhankelijkheden op lange termijn te behandelen, en zijn efficiëntie in training heeft hem voor veel van de meest moderne modellen de favoriete architecturale benadering gemaakt. Met progressief onderzoek zullen we waarschijnlijk verdere verbeteringen en aanpassingen aan de transformator zien, vooral op gebieden zoals beeld- en taalverwerking, waar aandachtsmechanismen veelbelovende resultaten tonen.
Wij zijn er voor u - Advies - Planning - Implementatie - Projectbeheer
☑️ Industrie -expert, hier met een eigen Xpert.Digital Industrial Hub van meer dan 2500 gespecialiseerde bijdragen

Konrad Wolfenstein
Ik help u graag als een persoonlijk consultant.
U kunt contact met mij opnemen door het onderstaande contactformulier in te vullen of u gewoon bellen op +49 89 674 804 (München) .
Ik kijk uit naar ons gezamenlijke project.
Schrijf me

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital is een hub voor de industrie met een focus, digitalisering, werktuigbouwkunde, logistiek/intralogistiek en fotovoltaïsche.
Met onze 360 ° bedrijfsontwikkelingsoplossing ondersteunen we goed bekende bedrijven, van nieuwe bedrijven tot na verkoop.
Marktinformatie, smarketing, marketingautomatisering, contentontwikkeling, PR, e -mailcampagnes, gepersonaliseerde sociale media en lead koestering maken deel uit van onze digitale tools.
U kunt meer vinden op: www.xpert.Digital - www.xpert.solar - www.xpert.plus
Contact houden



















